
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
smolagents von Hugging Face ist eine neue Python-Bibliothek, die die Erstellung von KI-Agentenund macht sie für Entwickler leichter zugänglich.
In diesem Blog stelle ich dir die smolagents-Bibliothek vor, erkläre, warum sie nützlich ist, und führe dich durch ein Demoprojekt, um ihre Fähigkeiten zu zeigen.
Wie im Blog von Hugging Face beschrieben Ankündigungsblogbeschrieben, ist smolagents "eine sehr einfache Bibliothek, die Sprachmodellen agentechnische Fähigkeiten verleiht". Aber warum brauchen wir Bibliotheken, um Agenten zu bauen?
Im Kern werden Agenten von LLMs angetrieben, um eine Aufgabe dynamisch zu lösen, indem sie ihre Umgebung beobachten, Pläne machen und diese Pläne mit Hilfe ihres Werkzeugkastens ausführen. Der Aufbau dieser Agenten ist zwar nicht unmöglich, aber du musst viele Komponenten von Grund auf neu schreiben. Diese Komponenten stellen sicher, dass die Agenten ordnungsgemäß funktionieren, ohne dein API-Guthaben und deine Ausführungszeit zu verbrauchen. Agentische Frameworks machen das einfacher, damit du das Rad nicht neu erfinden musst.
KI-Agenten-Frameworks werden oft in zwei Punkten kritisiert:
Auf der anderen Seite hat Smolagents Eigenschaften, die es sehr vielversprechend für diese Wirkstoffanwendungen machen:
Diese Qualitäten machen smolagents auf dem Papier zu einem Plug-and-Play mit KI-Agenten ohne großen Aufwand, also schauen wir mal, ob sie in der Praxis funktionieren.
In diesem Abschnitt werden wir eine einfache Demo mit smolagents erstellen. Unsere Anwendung lässt einen Agenten die am meisten hochgevotete Zeitung auf dem Hugging Face bekommen Tageszeitungen Seite. Wir bauen unsere maßgeschneiderten Tools für den Agenten und sehen, wie sie in Aktion funktionieren.
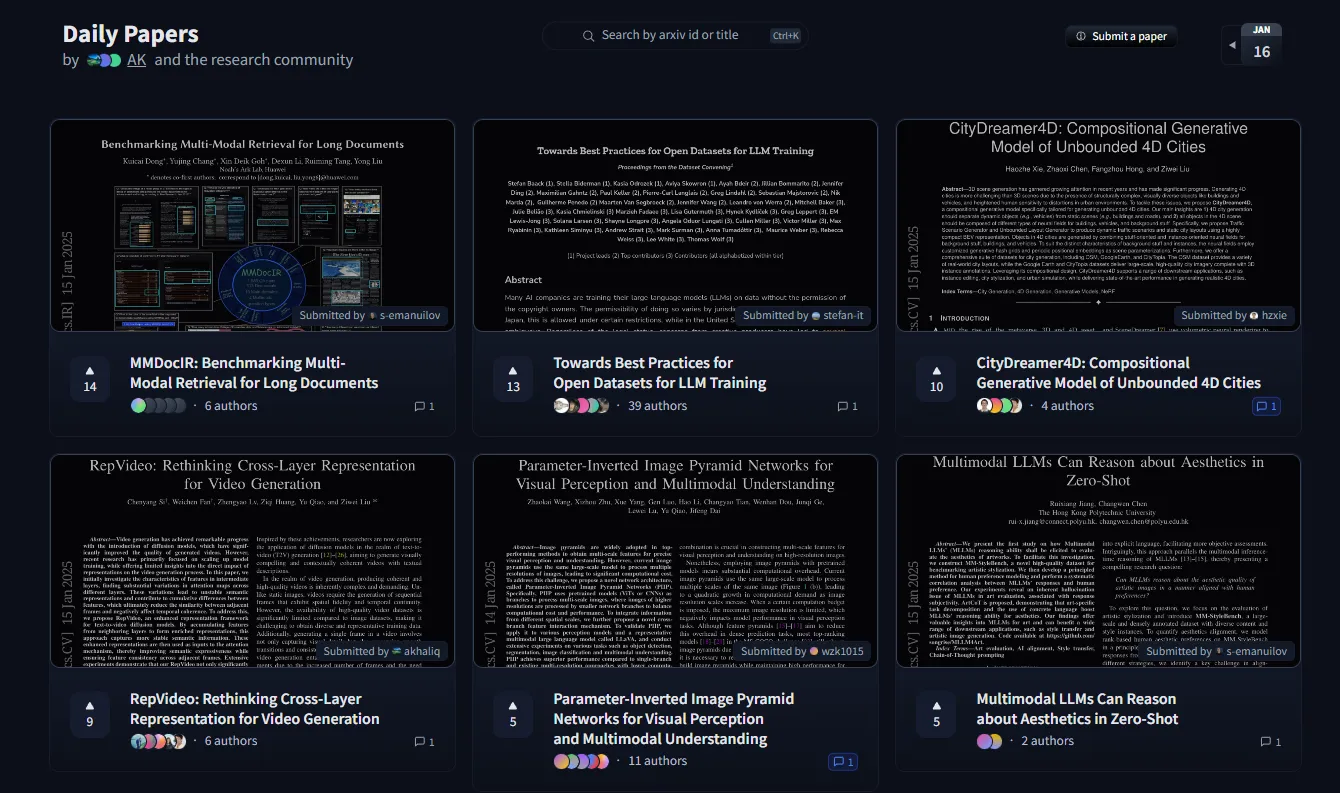
Daily Papers, eine gute Quelle, um über die besten Tageszeitungen auf dem Laufenden zu bleiben.
Um smolagents zu nutzen, musst du nur die Bibliothek installieren und ein Hugging Face Token bereitstellen. Die einfache Einrichtung des Frameworks ist ein positiver Punkt.
Um das Paket zu installieren, führe es aus:
pip install smolagentsDas Framework bietet integrierte Tools, die du sofort verwenden kannst (z. B. DuckDuckGoSearchTool). Aber du kannst auch ganz einfach eigene Tools erstellen. Für unseren Zweck bauen wir vier Werkzeuge, jedes für einen bestimmten Zweck:
Eine häufige Ursache für Agentenfehler ist die Verwendung von Tools. Um die Tools für den Einsatz von Agenten zu optimieren, ist es wichtig, dass die Agenten genau wissen, welches Tool sie verwenden und wie sie es einsetzen. Um dies zu erreichen, solltest du bei der Definition dieser Instrumente so explizit wie möglich sein:
Jetzt wollen wir unser erstes eigenes Tool erstellen, um die Tageszeitungsseite zu analysieren und den Titel der wichtigsten Zeitung zu ermitteln:
from smolagents import tool
# import packages that are used in our tools
import requests
from bs4 import BeautifulSoup
import json
@tool
def get_hugging_face_top_daily_paper() -> str:
"""
This is a tool that returns the most upvoted paper on Hugging Face daily papers.
It returns the title of the paper
"""
try:
url = "<https://huggingface.co/papers>"
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title element from the JSON-like data in the "data-props" attribute
containers = soup.find_all('div', class_='SVELTE_HYDRATER contents')
top_paper = ""
for container in containers:
data_props = container.get('data-props', '')
if data_props:
try:
# Parse the JSON-like string
json_data = json.loads(data_props.replace('"', '"'))
if 'dailyPapers' in json_data:
top_paper = json_data['dailyPapers'][0]['title']
except json.JSONDecodeError:
continue
return top_paper
except requests.exceptions.RequestException as e:
print(f"Error occurred while fetching the HTML: {e}")
return NoneBeachte den @tool Dekorator, die klare Benennung des Werkzeugs, die Typ-Hinweise und den Docstring. Auf ähnliche Weise definieren wir das Tool get_paper_id_by_title, um die ID des Papers anhand seines Titels zu ermitteln, damit wir es von arXiv herunterladen können. Für dieses Tool nutzen wir die API von Hugging Face.
from huggingface_hub import HfApi
@tool
def get_paper_id_by_title(title: str) -> str:
"""
This is a tool that returns the arxiv paper id by its title.
It returns the title of the paper
Args:
title: The paper title for which to get the id.
"""
api = HfApi()
papers = api.list_papers(query=title)
if papers:
paper = next(iter(papers))
return paper.id
else:
return NoneDas Herunterladen des Papiers mit seiner ID kann mit dem Python-Paket arxiv erfolgen. Wir speichern das Papier lokal unter einem bestimmten Namen, den wir dann zum Lesen verwenden:
import arxiv
@tool
def download_paper_by_id(paper_id: str) -> None:
"""
This tool gets the id of a paper and downloads it from arxiv. It saves the paper locally
in the current directory as "paper.pdf".
Args:
paper_id: The id of the paper to download.
"""
paper = next(arxiv.Client().results(arxiv.Search(id_list=[paper_id])))
paper.download_pdf(filename="paper.pdf")
return NoneUm eine PDF-Datei zu lesen, kannst du das Paket pypdf verwenden. Wir werden nur die ersten drei Seiten des Papiers lesen, um Token zu sparen.
from pypdf import PdfReader
@tool
def read_pdf_file(file_path: str) -> str:
"""
This function reads the first three pages of a PDF file and returns its content as a string.
Args:
file_path: The path to the PDF file.
Returns:
A string containing the content of the PDF file.
"""
content = ""
reader = PdfReader('paper.pdf')
print(len(reader.pages))
pages = reader.pages[:3]
for page in pages:
content += page.extract_text()
return contentWenn du benutzerdefinierte Werkzeuge definierst und der Agent Schwierigkeiten hat, sie korrekt zu verwenden oder die richtigen Argumente zu übergeben, solltest du die Funktions- und Variablennamen sowie die Werkzeugbeschreibungen klarer und eindeutiger formulieren.
Nachdem wir unsere Werkzeuge eingerichtet haben, können wir nun unseren Agenten initialisieren und starten. Wir verwenden das Modell Qwen2.5-Coder-32B-Instruct, das kostenlos genutzt werden kann. Die Werkzeuge, die ein Agent benötigt, können bei der Definition des Agenten übergeben werden. Du kannst sehen, dass die Definition und der Betrieb eines Agenten ein Minimum an Code erfordert:
from smolagents import CodeAgent, HfApiModel
model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = HfApiModel(model_id=model_id, token=<YOUR-API>)
agent = CodeAgent(tools=[get_hugging_face_top_daily_paper,
get_paper_id_by_title,
download_paper_by_id,
read_pdf_file],
model=model,
add_base_tools=True)
agent.run(
"Summarize today's top paper on Hugging Face daily papers by reading it.",
)Wenn der Agent arbeitet, gibt er seinen Prozess Schritt für Schritt aus. So können wir sehen, wie er seine Aktionen im Code definiert und gleichzeitig die benutzerdefinierten Werkzeuge nutzt, die wir bereitgestellt haben:
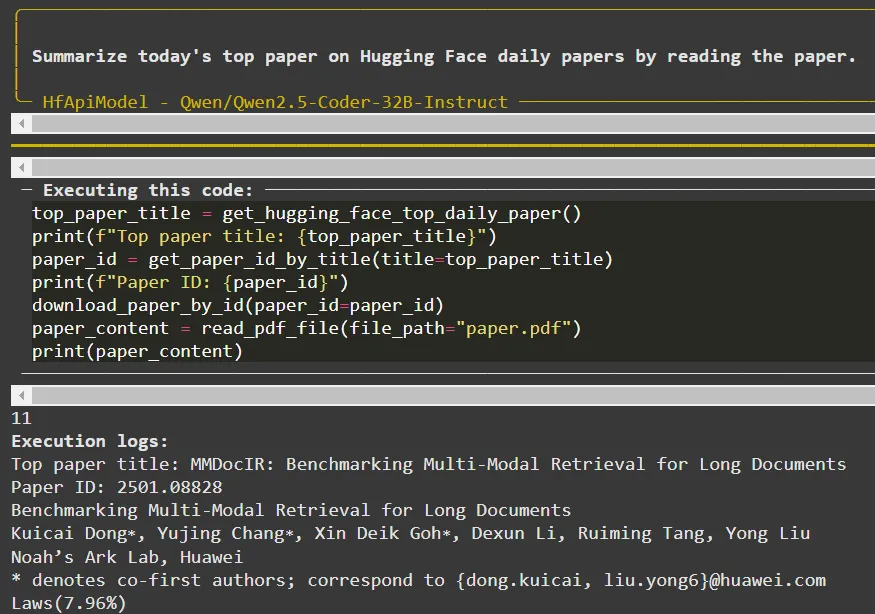
Ausgabe des Agenten in Schritt 0
Der Agent kann das Lesen des Papiers im ersten Schritt (Schritt 0) beenden. Im zweiten Schritt listet das Modell die wichtigsten Punkte des Papiers auf, wiederum in einer Python-Liste.
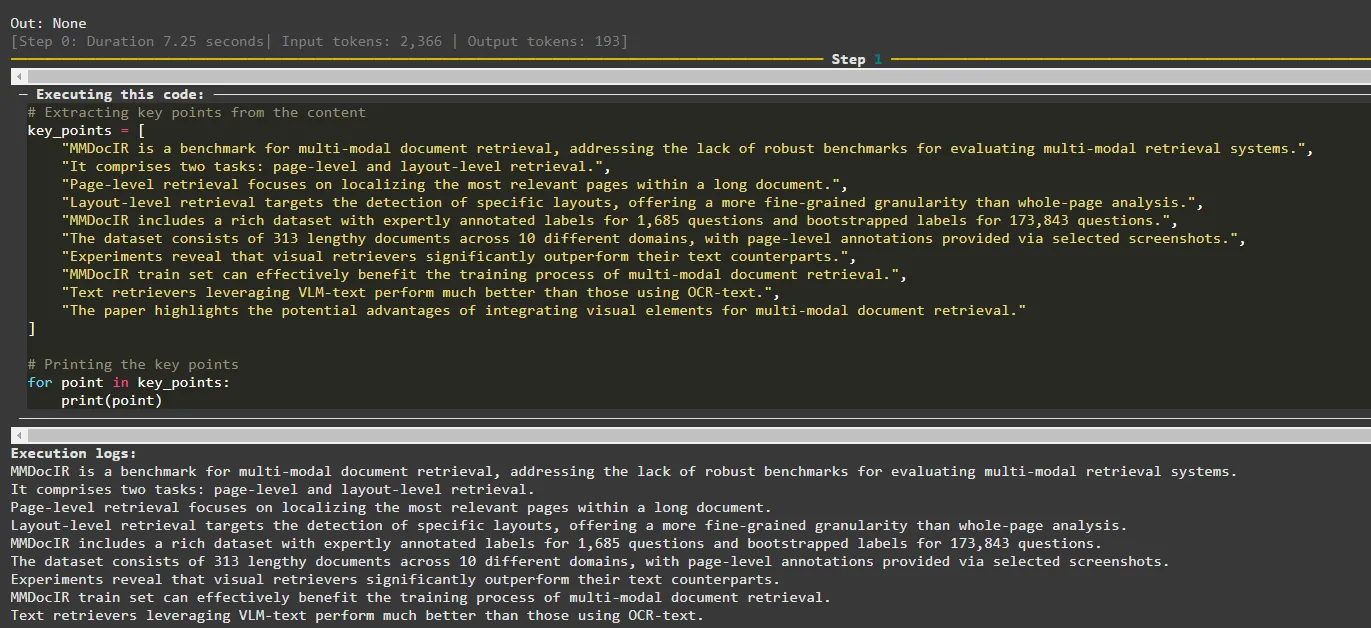
Ausgabe des Agenten in Schritt 1
Im dritten Schritt (Schritt 2) erstellt der Agent eine Zusammenfassung der wichtigsten Punkte und druckt sie im letzten Schritt (Schritt 3) aus.
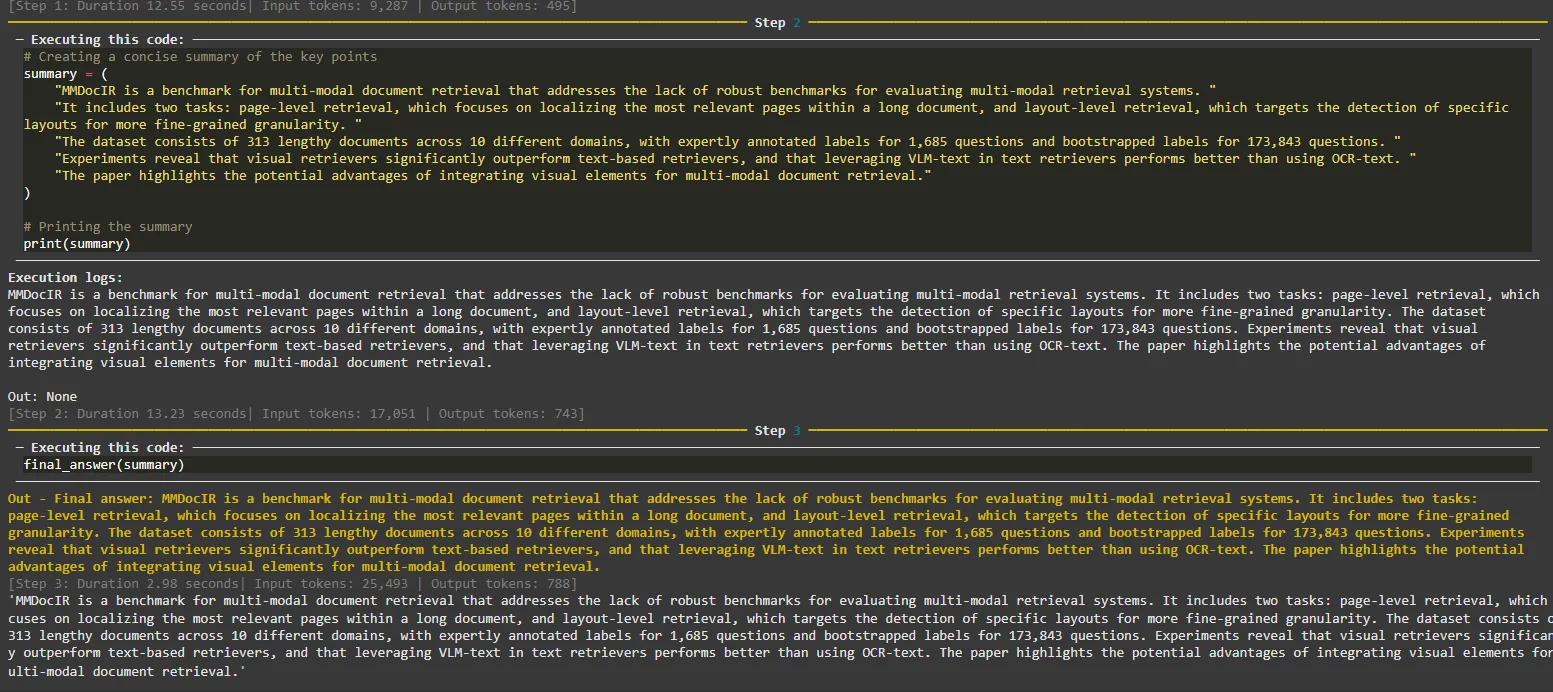
Ausgabe des Agenten in Schritt 2, 3.
Der Agent war in der Lage, bei jedem Schritt zu erkennen, welche Werkzeuge er verwenden muss, und beendete die Aufgabe ohne Fehler. Die gesamte Pipeline könnte so optimiert werden, dass weniger Tools verwendet werden, aber ich war neugierig darauf, zu sehen, wie der Agent mehrere Tool-Aufrufe nutzt.
Bei anspruchsvolleren Aufgaben, die komplexeres Denken oder den Einsatz von Werkzeugen erfordern, kannst du auch leistungsfähigere Modelle als Rückgrat deiner Agenten verwenden, wie z. B. die von OpenAI oder Claude.
Wonach suchst du in einem agenturischen Rahmen? Deine Antwort macht deutlich, welches Framework du verwenden solltest. Aber wenn es ein einfaches Framework ist, das nicht durch Abstraktionen aufgebläht ist, dir die Kontrolle gibt, gute Integrationen hat und die Grundlagen bietet, ohne das Rad zu übernehmen, dann ist smolagents eine gute Option, die du ausprobieren solltest.
Eine gute Einbindung in das Hugging Face-Ökosystem bedeutet, dass mehr Modelle und Werkzeuge zur Verfügung stehen und die Open-Source-Community uns unterstützt. Der Rahmen hält gut, was er verspricht. Es könnte von mehr eingebauten Tools profitieren, und wir können die Daumen drücken, dass das in der Entwicklungsphase passiert.
Wenn du neugierig bist und mehr über KI-Agenten und Smolagenten lesen möchtest, solltest du dir diese Ressourcen nicht entgehen lassen:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Tutorial
DataCamp Team
Tutorial
Derrick Mwiti
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree