
Course
Working with Hugging Face
2 hr
32.9K
As described by Hugging Face’s announcement blog, smolagents is “a very simple library that unlocks agentic capabilities for language models.” But why do we need libraries to build agents?
At their heart, agents are powered by LLMs to dynamically solve a task by observing their environments, making plans, and executing those plans given their toolbox. Building these agents, while not impossible, requires you to write from scratch many components. These components ensure that the agents function properly without burning through your API credit and execution time. Agentic frameworks make this easier so you don’t have to reinvent the wheels.
AI agent frameworks are often criticized with two points:
On the other hand, smolagents has qualities that make it very promising for these agentic applications:
These qualities are what, on paper, make smolagents a plug-and-play with AI agents with little effort, so let’s see if they hold in practice.
In this section, we will build a simple demo with smolagents. Our application will have an agent get the most upvoted paper on the Hugging Face Daily Papers page. We build our custom tools for the agent and see it work in action.
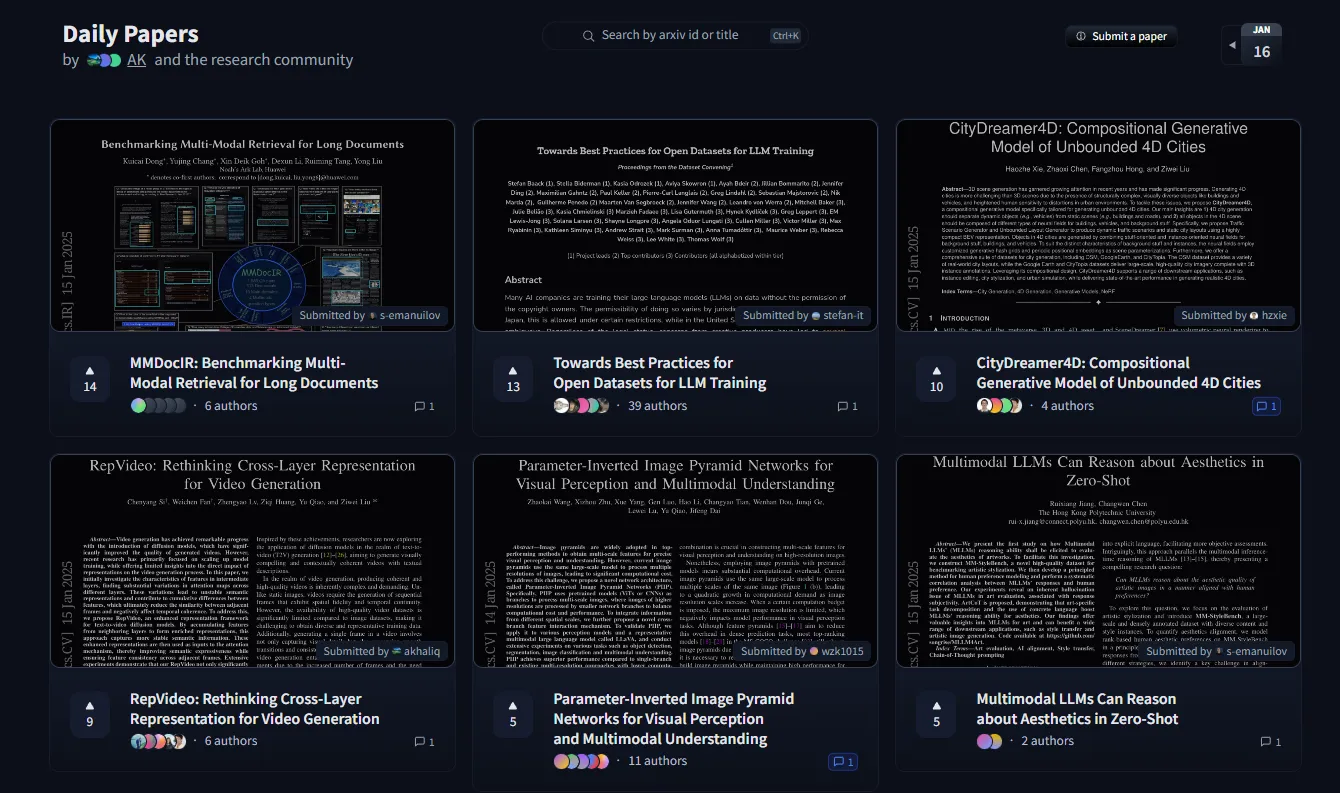
Daily Papers, a good source to stay on top of the top daily research papers.
To use smolagents, you only need to install the library and provide a Hugging Face token. The framework's ease of setup is a positive point.
To install the package, run:
pip install smolagentsWhile the framework provides built-in tools that you can use straight out of the box (e.g. DuckDuckGoSearchTool), building your custom tools is just as straightforward. For our purpose, we build four tools, each for a particular purpose:
One common cause of agent errors is tool usage. To optimize tools for agentic purposes, it’s important to ensure agents clearly understand which tool to use and how to use it. To achieve this, be as explicit as possible when defining these tools:
Now let’s build our first custom tool to parse the daily papers page and get the title of the top paper:
from smolagents import tool
# import packages that are used in our tools
import requests
from bs4 import BeautifulSoup
import json
@tool
def get_hugging_face_top_daily_paper() -> str:
"""
This is a tool that returns the most upvoted paper on Hugging Face daily papers.
It returns the title of the paper
"""
try:
url = "<https://huggingface.co/papers>"
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title element from the JSON-like data in the "data-props" attribute
containers = soup.find_all('div', class_='SVELTE_HYDRATER contents')
top_paper = ""
for container in containers:
data_props = container.get('data-props', '')
if data_props:
try:
# Parse the JSON-like string
json_data = json.loads(data_props.replace('"', '"'))
if 'dailyPapers' in json_data:
top_paper = json_data['dailyPapers'][0]['title']
except json.JSONDecodeError:
continue
return top_paper
except requests.exceptions.RequestException as e:
print(f"Error occurred while fetching the HTML: {e}")
return NoneNotice the @tool decorator, the clear naming of the tool, the type hints, and the docstring. Similarly, we define the get_paper_id_by_title tool to get the paper ID by its title, so we can download it from arXiv. For this tool, we utilize the Hugging Face’s API.
from huggingface_hub import HfApi
@tool
def get_paper_id_by_title(title: str) -> str:
"""
This is a tool that returns the arxiv paper id by its title.
It returns the title of the paper
Args:
title: The paper title for which to get the id.
"""
api = HfApi()
papers = api.list_papers(query=title)
if papers:
paper = next(iter(papers))
return paper.id
else:
return NoneDownloading the paper using its ID can be done using the Python arxiv package. We save the paper locally with a particular name, which we use then for reading it:
import arxiv
@tool
def download_paper_by_id(paper_id: str) -> None:
"""
This tool gets the id of a paper and downloads it from arxiv. It saves the paper locally
in the current directory as "paper.pdf".
Args:
paper_id: The id of the paper to download.
"""
paper = next(arxiv.Client().results(arxiv.Search(id_list=[paper_id])))
paper.download_pdf(filename="paper.pdf")
return NoneTo read a PDF file, you can use the pypdf package. We will only read the first three pages of the paper to save on token usage.
from pypdf import PdfReader
@tool
def read_pdf_file(file_path: str) -> str:
"""
This function reads the first three pages of a PDF file and returns its content as a string.
Args:
file_path: The path to the PDF file.
Returns:
A string containing the content of the PDF file.
"""
content = ""
reader = PdfReader('paper.pdf')
print(len(reader.pages))
pages = reader.pages[:3]
for page in pages:
content += page.extract_text()
return contentIf you define custom tools and the agent struggles to use them correctly or pass the right arguments, consider making the function and variable names, as well as the tool descriptions, more clear and explicit.
With our tools set up, we can now initialize and run our agent. We use the Qwen2.5-Coder-32B-Instruct model, which is free to use. The tools an agent needs can be passed while defining the agent. You can see the process of defining and running an agent requires minimum code:
from smolagents import CodeAgent, HfApiModel
model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = HfApiModel(model_id=model_id, token=<YOUR-API>)
agent = CodeAgent(tools=[get_hugging_face_top_daily_paper,
get_paper_id_by_title,
download_paper_by_id,
read_pdf_file],
model=model,
add_base_tools=True)
agent.run(
"Summarize today's top paper on Hugging Face daily papers by reading it.",
)As the agent operates, it outputs its process step by step. This allows us to see how it defines its actions in code while utilizing the custom tools we’ve provided:
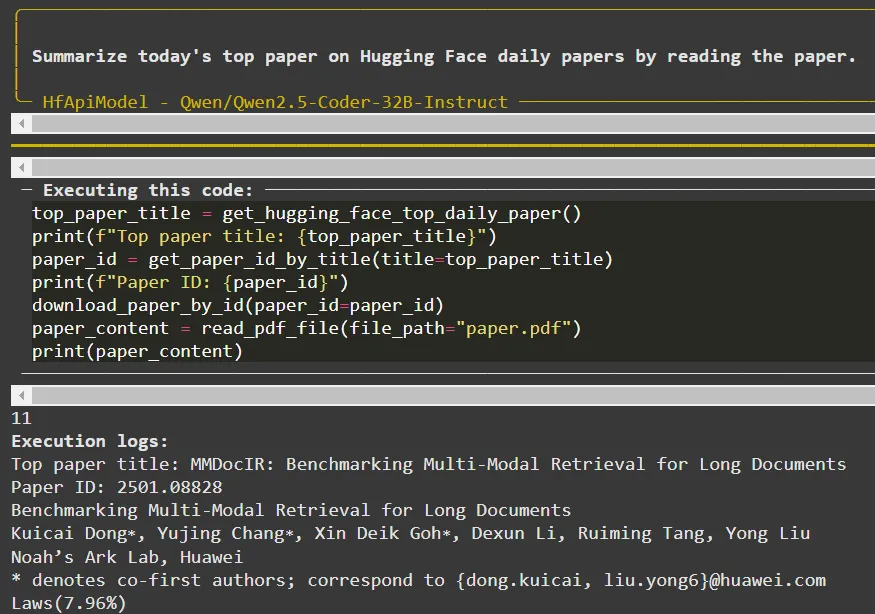
Agent output in step 0
The agent can finish reading the paper in the first step (Step 0). In the second step, the model lists the key points of the paper, again, in a Python list.
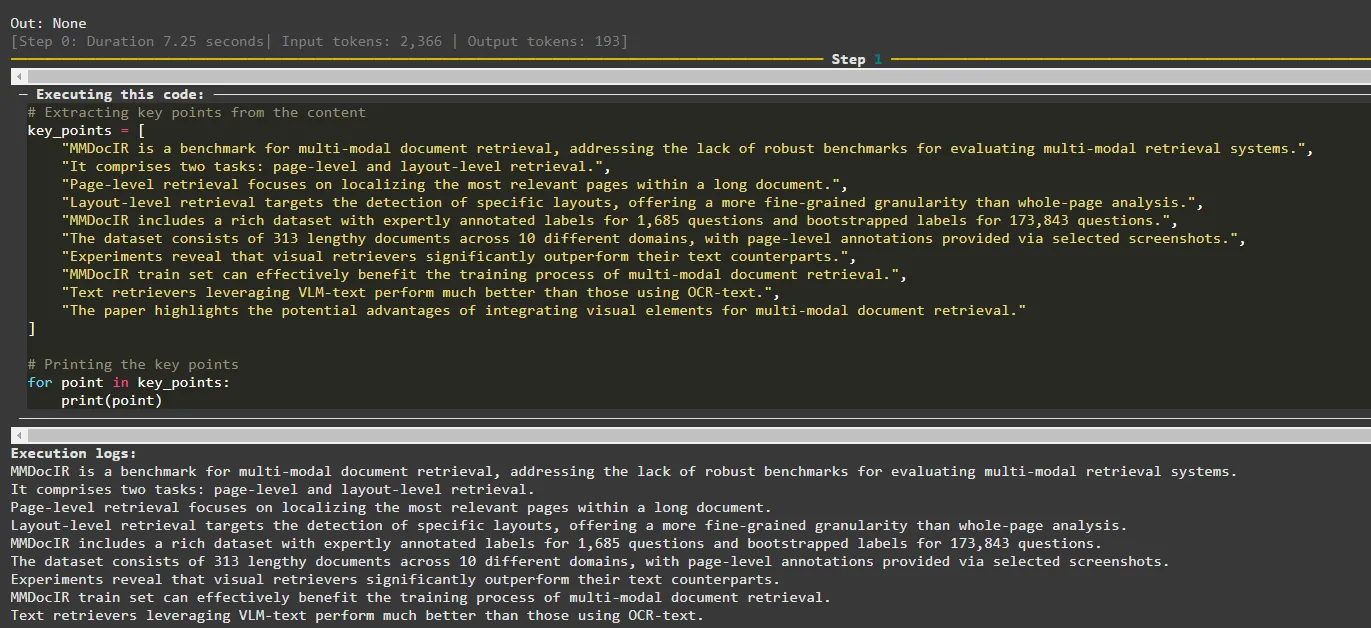
Agent output in step 1
In the third step (Step 2), the agent creates a summary of the key points and prints it in the final step (Step 3).
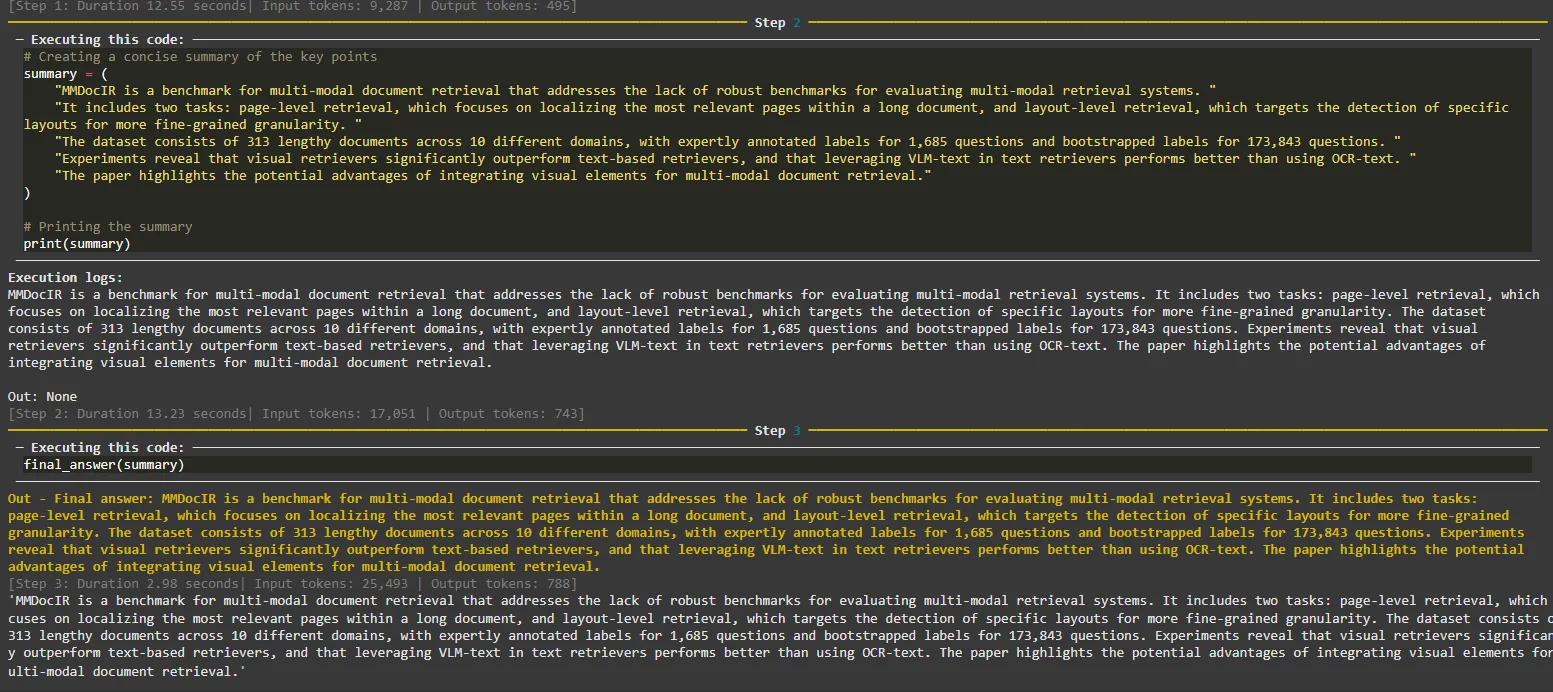
Agent output in steps 2, 3.
The agent was able to identify which tools to use at each step and finished the task with no errors. Note that the whole pipeline could be optimized to use fewer tools, but I was curious to check how the agent utilizes multiple tool calls.
In more challenging tasks, that require more complex reasoning or tool use, you can also use more capable models as the backbone of your agents, such as those offered by OpenAI or Claude.
What is it that you look for in an agentic framework? Your answer makes it clear which one to use, but if it is a simple framework that is not bloated by abstractions, gives you control, has good integrations, and provides the basics without taking the wheel, then smolagents is a good option to try.
Being integrated well into the Hugging Face ecosystem means more models and tools at hand, plus the support of the open-source community. The framework works well in what it promises. It could benefit from more built-in tools, and we can cross our fingers to see that happen as it’s being developed.
If you are curious to read more about AI agents and smolagents, don’t miss out on these resources:
Learn AI with these courses!
Course
Course
Course
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
code-along
Jacob Marquez
code-along
Alara Dirik
code-along
Priyanka Asnani



