
Cursus
Développer des applications d'IA
21 h
Smolagents de Hugging Face est une nouvelle bibliothèque Python qui simplifie la création d' agents d'IAet les rend plus accessibles aux développeurs.
Dans ce blog, je vous présenterai la bibliothèque smolagents, j'expliquerai pourquoi elle est utile et je vous guiderai à travers un projet de démonstration pour montrer ses capacités.
Comme le décrit le blog d'annonce de Hugging Face blog d'annonce de Hugging Facesmolagents est "une bibliothèque très simple qui débloque les capacités agentiques des modèles de langage". Mais pourquoi avons-nous besoin de bibliothèques pour créer des agents ?
Au fond, les agents sont alimentés par des LLM pour résoudre dynamiquement une tâche en observant leur environnement, en élaborant des plans et en exécutant ces plans à l'aide de leur boîte à outils. La création de ces agents n'est pas impossible, mais elle nécessite l'écriture de nombreux composants à partir de zéro. Ces composants garantissent que les agents fonctionnent correctement sans épuiser votre crédit API et votre temps d'exécution. Les cadres agentiques facilitent cette tâche et vous évitent de réinventer la roue.
Les cadres d'agents d'IA sont souvent critiqués sur deux points :
D'autre part, les smolagents possèdent des qualités qui les rendent très prometteurs pour ces applications agentiques :
Ces qualités sont celles qui, sur le papier, font des smolagents des agents d'intelligence artificielle prêts à l'emploi avec peu d'efforts, alors voyons si elles se vérifient dans la pratique.
Dans cette section, nous allons construire une démo simple avec smolagents. Notre application permettra à un agent d'obtenir le papier le plus upvoté sur le Hugging Face. Articles quotidiens de Hugging Face. Nous construisons nos outils personnalisés pour l'agent et nous les voyons fonctionner en action.
Daily Papers, une bonne source pour rester au courant des meilleurs documents de recherche quotidiens.
Pour utiliser smolagents, il vous suffit d'installer la bibliothèque et de fournir un jeton Hugging Face. La facilité d'installation du cadre est un point positif.
Pour installer le paquet, exécutez :
pip install smolagentsBien que le cadre fournisse des outils intégrés que vous pouvez utiliser directement (par exemple, DuckDuckGoSearchTool), la création de vos propres outils est tout aussi simple. Pour notre objectif, nous construisons quatre outils, chacun pour un objectif particulier :
L'utilisation d'un outil est une cause fréquente d'erreur de la part des agents. Pour optimiser les outils à des fins agentiques, il est important de s'assurer que les agents comprennent clairement quel outil utiliser et comment l'utiliser. Pour ce faire, soyez aussi explicite que possible dans la définition de ces outils :
Construisons maintenant notre premier outil personnalisé pour analyser la page des quotidiens et obtenir le titre de l'article le plus important :
from smolagents import tool
# import packages that are used in our tools
import requests
from bs4 import BeautifulSoup
import json
@tool
def get_hugging_face_top_daily_paper() -> str:
"""
This is a tool that returns the most upvoted paper on Hugging Face daily papers.
It returns the title of the paper
"""
try:
url = "<https://huggingface.co/papers>"
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title element from the JSON-like data in the "data-props" attribute
containers = soup.find_all('div', class_='SVELTE_HYDRATER contents')
top_paper = ""
for container in containers:
data_props = container.get('data-props', '')
if data_props:
try:
# Parse the JSON-like string
json_data = json.loads(data_props.replace('"', '"'))
if 'dailyPapers' in json_data:
top_paper = json_data['dailyPapers'][0]['title']
except json.JSONDecodeError:
continue
return top_paper
except requests.exceptions.RequestException as e:
print(f"Error occurred while fetching the HTML: {e}")
return NoneRemarquez le décorateur @tool, le nom clair de l'outil, les indications de type et la docstring. De même, nous définissons l'outil get_paper_id_by_title pour obtenir l'identifiant de l'article à partir de son titre, afin de pouvoir le télécharger à partir d'arXiv. Pour cet outil, nous utilisons l'API de Hugging Face.
from huggingface_hub import HfApi
@tool
def get_paper_id_by_title(title: str) -> str:
"""
This is a tool that returns the arxiv paper id by its title.
It returns the title of the paper
Args:
title: The paper title for which to get the id.
"""
api = HfApi()
papers = api.list_papers(query=title)
if papers:
paper = next(iter(papers))
return paper.id
else:
return NoneLe téléchargement de l'article à l'aide de son identifiant peut être effectué à l'aide du paquet Python arxiv. Nous sauvegardons le papier localement sous un nom particulier, que nous utilisons ensuite pour le lire :
import arxiv
@tool
def download_paper_by_id(paper_id: str) -> None:
"""
This tool gets the id of a paper and downloads it from arxiv. It saves the paper locally
in the current directory as "paper.pdf".
Args:
paper_id: The id of the paper to download.
"""
paper = next(arxiv.Client().results(arxiv.Search(id_list=[paper_id])))
paper.download_pdf(filename="paper.pdf")
return NonePour lire un fichier PDF, vous pouvez utiliser le logiciel pypdf. Nous ne lirons que les trois premières pages du document afin d'économiser les jetons.
from pypdf import PdfReader
@tool
def read_pdf_file(file_path: str) -> str:
"""
This function reads the first three pages of a PDF file and returns its content as a string.
Args:
file_path: The path to the PDF file.
Returns:
A string containing the content of the PDF file.
"""
content = ""
reader = PdfReader('paper.pdf')
print(len(reader.pages))
pages = reader.pages[:3]
for page in pages:
content += page.extract_text()
return contentSi vous définissez des outils personnalisés et que l'agent a du mal à les utiliser correctement ou à transmettre les bons arguments, envisagez de rendre les noms des fonctions et des variables, ainsi que les descriptions des outils, plus clairs et plus explicites.
Une fois nos outils mis en place, nous pouvons maintenant initialiser et exécuter notre agent. Nous utilisons le modèle Qwen2.5-Coder-32B-Instruct, dont l'utilisation est gratuite. Les outils dont un agent a besoin peuvent être transmis lors de la définition de l'agent. Vous pouvez constater que le processus de définition et de fonctionnement d'un agent nécessite un minimum de code :
from smolagents import CodeAgent, HfApiModel
model_id = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = HfApiModel(model_id=model_id, token=<YOUR-API>)
agent = CodeAgent(tools=[get_hugging_face_top_daily_paper,
get_paper_id_by_title,
download_paper_by_id,
read_pdf_file],
model=model,
add_base_tools=True)
agent.run(
"Summarize today's top paper on Hugging Face daily papers by reading it.",
)Au fur et à mesure que l'agent opère, il produit son processus étape par étape. Cela nous permet de voir comment il définit ses actions dans le code tout en utilisant les outils personnalisés que nous avons fournis :
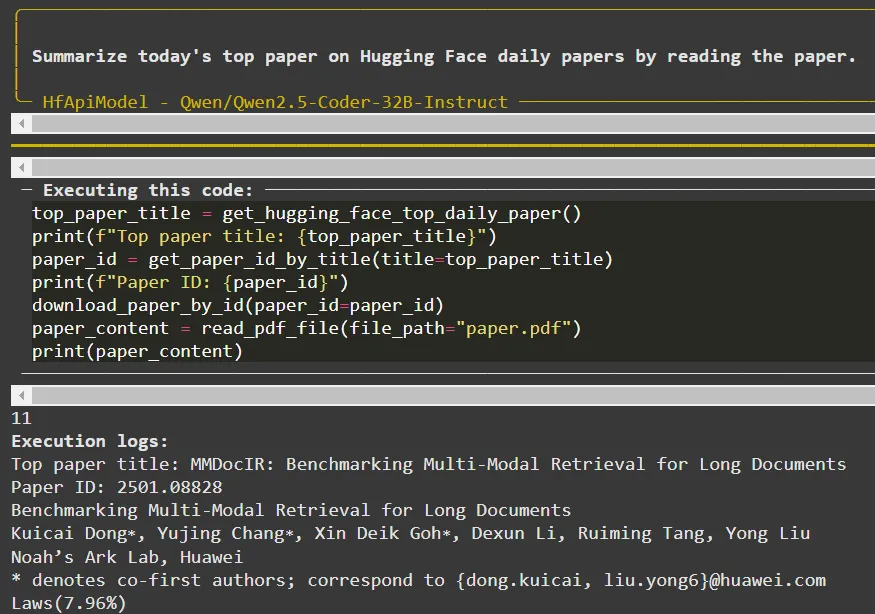
Résultat de l'agent à l'étape 0
L'agent peut terminer la lecture du document lors de la première étape (étape 0). Dans un deuxième temps, le modèle énumère les points clés du document, toujours sous la forme d'une liste Python.
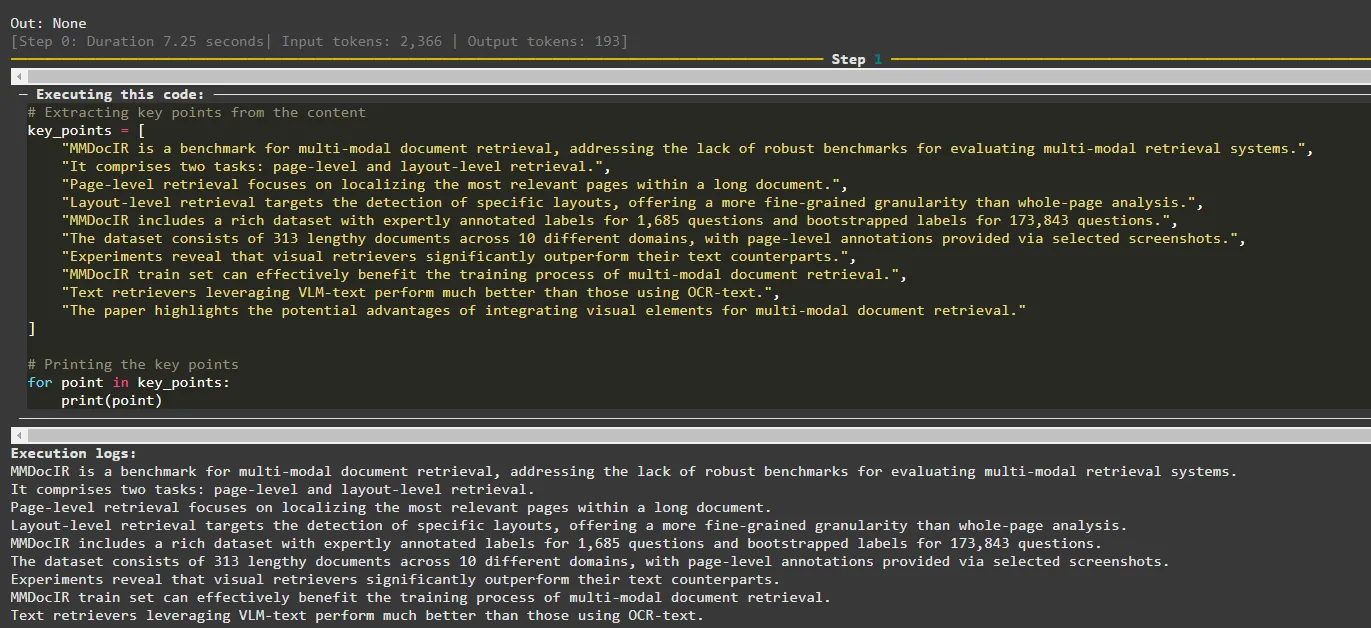
Résultat de l'agent à l'étape 1
Lors de la troisième étape (étape 2), l'agent crée un résumé des points clés et l'imprime lors de la dernière étape (étape 3).
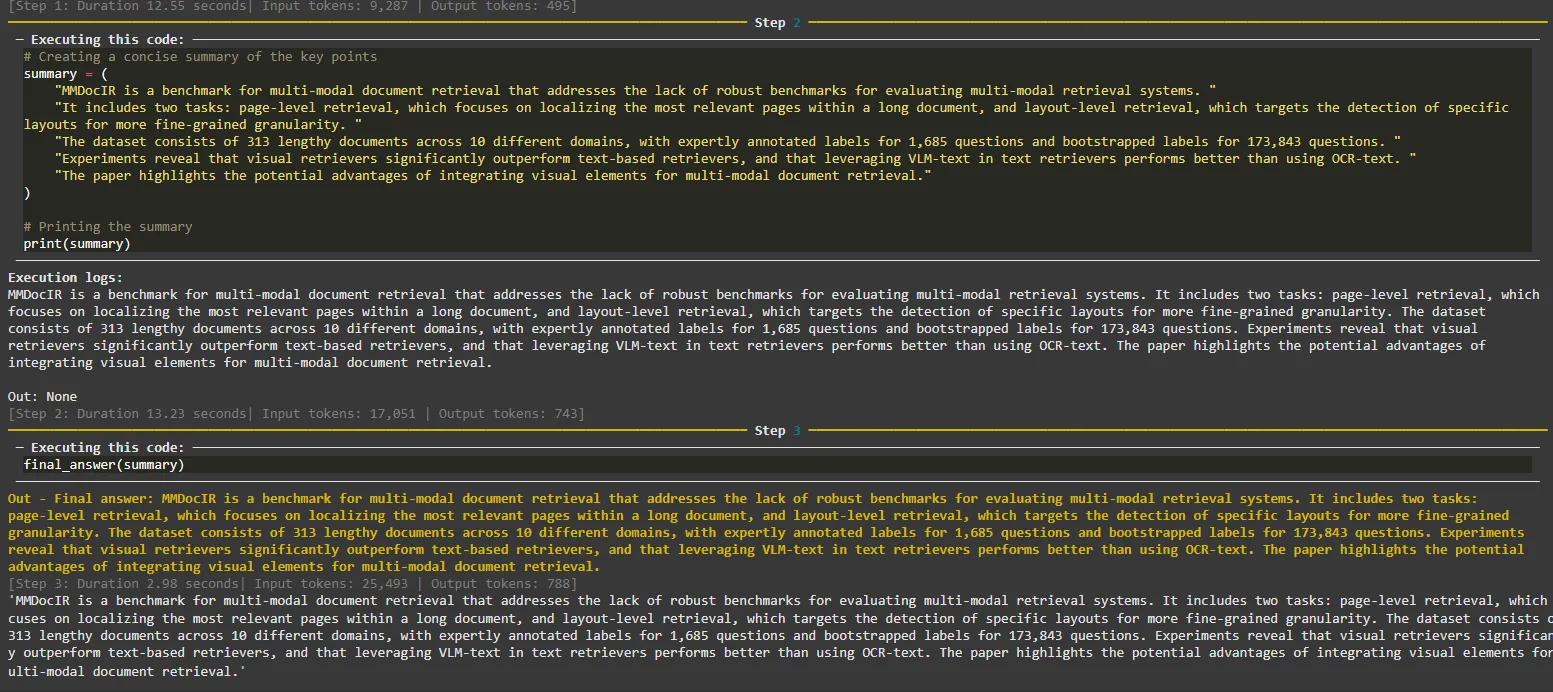
Résultats de l'agent aux étapes 2 et 3.
L'agent a pu identifier les outils à utiliser à chaque étape et a terminé la tâche sans erreur. Notez que l'ensemble du pipeline pourrait être optimisé pour utiliser moins d'outils, mais j'étais curieux de vérifier comment l'agent utilise les appels d'outils multiples.
Pour les tâches plus difficiles, qui nécessitent un raisonnement plus complexe ou l'utilisation d'outils, vous pouvez également utiliser des modèles plus performants comme colonne vertébrale de vos agents, tels que ceux proposés par OpenAI ou Claude.
Que recherchez-vous dans un cadre agentique ? Votre réponse indique clairement lequel utiliser, mais s'il s'agit d'un cadre simple qui n'est pas encombré d'abstractions, qui vous donne le contrôle, qui a de bonnes intégrations, et qui fournit les bases sans prendre la roue, alors smolagents est une bonne option à essayer.
Être bien intégré dans l'écosystème Hugging Face signifie plus de modèles et d'outils à portée de main, ainsi que le soutien de la communauté open-source. Le cadre fonctionne bien dans ce qu'il promet. Il pourrait bénéficier de plus d'outils intégrés, et nous pouvons croiser les doigts pour que cela se produise au fur et à mesure de son développement.
Si vous souhaitez en savoir plus sur les agents d'IA et les smolagents, ne manquez pas ces ressources :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Tutoriel
Derrick Mwiti
Tutoriel
DataCamp Team
Tutoriel
Moez Ali
Tutoriel
Mark Pedigo