
Lernpfad
Grundlagen der KI
10 Std.
Im Moment ist Veo 3 nur in den USA und nur über Flow, Googles neuer KI-gestützter Schnittstelle zum Filmen. Um darauf zuzugreifen, brauchst du einen AI Ultra-Tarif, der $250/Monat kostet (etwa $272 mit Steuern).
Lasst uns anfangen zu bauen!
Für meinen ersten Test wollte ich eine einmalige Anzeige für eine fiktive Münzmarke namens Mintro erstellen . Die Idee: etwas Kurzes, Schlagkräftiges und Einprägsames. Ich stellte mir einen peinlichen, nachvollziehbaren Moment vor - etwas, das als schneller Scroll-Stopper funktionieren könnte.
So sieht es aus: Zwei Arbeitskollegen sitzen in einem überfüllten Aufzug fest, von Angesicht zu Angesicht, in einem Raum, in dem Vertrauen (und frischer Atem) wichtig sind. Um die Spannung zu brechen, lässt man eine Zeile fallen, die gleichermaßen tragisch und lustig ist:
"Ich habe einmal in der All-Hands geniest und gleichzeitig auf 'Bildschirm freigeben' geklickt. Keine Überlebenden."
Dann wurde der Spot auf das Mintro-Logo und den Slogan geschnitten:
"Zugelassen für Fahrstuhlgespräche."
Wenn du mitmachen willst, benutze die visuelle Anleitung in diesem Bild, um ein Video mit Veo 3 zu erstellen:
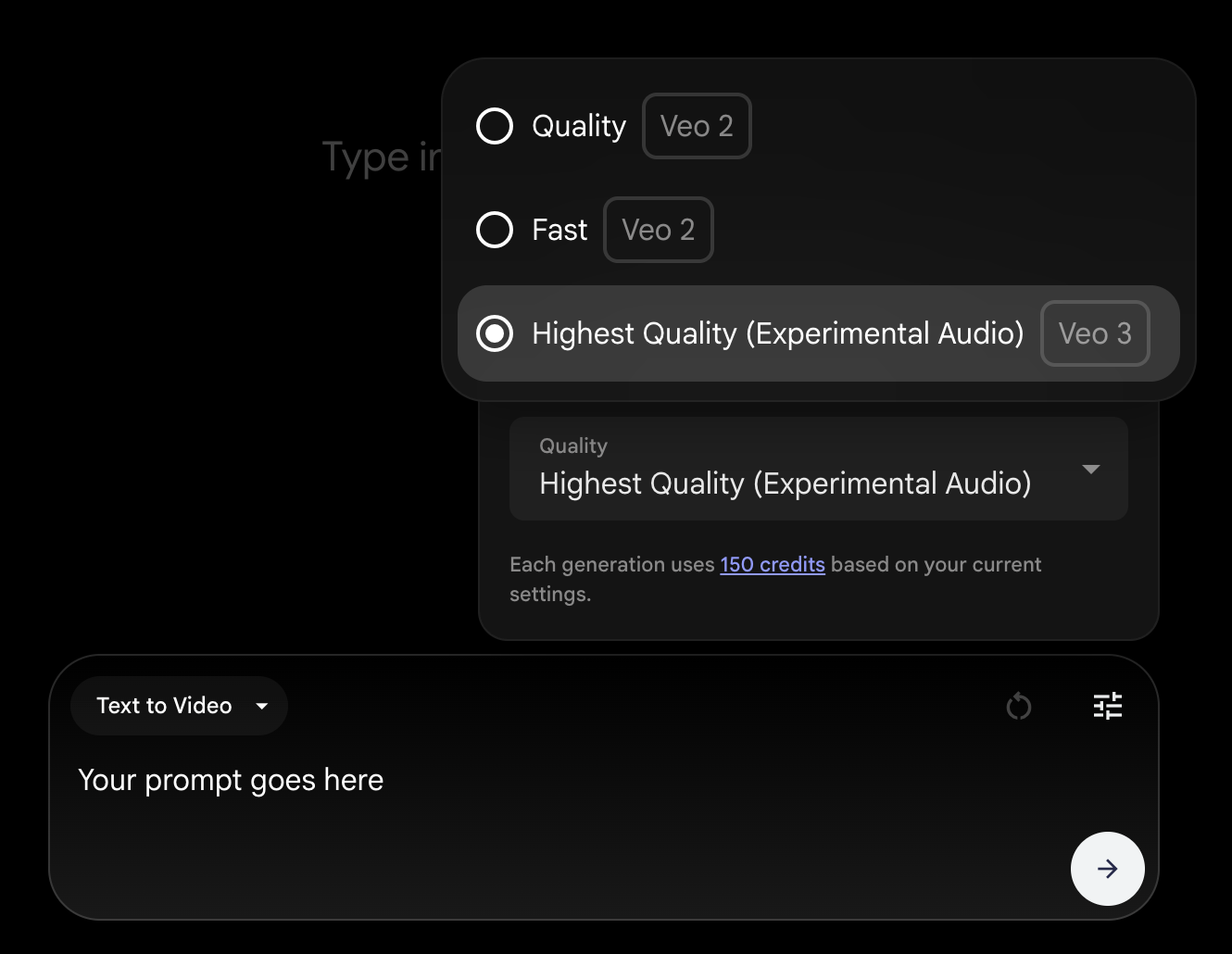
Beginnen wir mit dieser Aufforderung und schauen wir, was wir bekommen:
Aufforderung:
Ein überfüllter Firmenaufzug während der morgendlichen Rushhour. Zwei gut gekleidete Kollegen stehen sich Auge in Auge gegenüber, unangenehm nah, weil der Raum so voll ist. Einer, der sein Gesicht nicht verzieht, beugt sich leicht vor und sagt: "Ich habe einmal im All-Hands geniest und gleichzeitig auf 'Bildschirm freigeben' geklickt. Keine Überlebenden." Der andere versucht, ein Lachen zu unterdrücken. Der Aufzug klingelt und die Türen öffnen sich zu einer belebten Büroetage.
Gar nicht mal schlecht. Ich mag den Rahmen, die Farbe und der Ton ist in Ordnung. Die schauspielerische Leistung ist nicht großartig - es gibt nicht viele Emotionen, aber das ist auch nicht schlimm.
Nehmen wir an, wir wollen jetzt zur nächsten Aufnahme in der Küche übergehen. Unsere beste Chance, die Konsistenz der Charaktere zu erhalten - also dasselbe Gesicht, Outfit und allgemeine Aussehen - ist die Verwendung des Scene Builders.
Wenn du mit deiner ersten Aufnahme zufrieden bist, klicke auf Zur Szene hinzufügen:

Es öffnet sich eine Zeitleiste. Klicke auf das Pluszeichen und wähle dann zwischen:
In diesem Beispiel brauche ich einen Schnitt, also wähle ich Springen zu und benutze dann diese Eingabeaufforderung (ich habe das nach einigen Wiederholungen geschafft - diese Funktion muss unbedingt verbessert werden):
Aufforderung:
Ein paar Minuten später in der Küche. Das Sonnenlicht fällt sanft über die Tabelle und den Boden und schafft eine ruhige, stille Atmosphäre. Das leise Summen des Kühlschranks, das leise Knarren des Stuhls, das sanfte Klopfen auf dem Telefondisplay. Keine Musik oder externe Stimmen. Die Frau sitzt allein am Küchentisch, das Telefon in der Hand. Die Kamera hält einen ruhigen, mittelnahen Seitenwinkel. Sie legt die Babyschuhe auf die Tabelle neben sich und beginnt, eine Liste auf ihrem Handy zu tippen. Die Kamera schneidet auf eine Aufnahme über die Schulter oder eine enge Einstellung, die den Bildschirm des Telefons zeigt: "Zu verkaufen: Babyschuhe, nie getragen." Sie starrt einen langen Moment auf den Text, während ihr Daumen über dem Post-Button schwebt. Ihre Augen beginnen zu glitzern, aber sie blinzelt schnell zurück. Sie weint nicht - stattdessen schließt sie das Telefon, legt es mit dem Gesicht nach unten und atmet aus, um sich zu beruhigen. Ihr Gesichtsausdruck ist zurückhaltend und unlesbar, aber ihre Körpersprache sagt alles: Das ist nicht einfach. Füge keine Untertitel auf dem Bildschirm ein.
Für diesen Test wollte ich etwas Absurdes ausprobieren - einen lustigen, kafkaesken Kurzfilm:
Ein Käfer mit einem menschlichen Gesicht fährt einen SUV. Aber jetzt kommt der Clou (als ob das nicht schon genug wäre): Der Fahrersitz ist ein Königsstuhl.
Wählen wir zunächst die Option Zutaten zu Video:
Ich begann damit, die drei Zutaten nacheinander zu erzeugen: den Stuhl, den SUV und den Käfer.
Leider funktioniert diese Funktion derzeit nur auf Veo 2, nicht auf Veo 3. Technisch gesehen kannst du Veo 3 aus dem Dropdown-Menü auswählen, aber es schaltet während der Erstellung immer automatisch auf Veo 2 zurück und zeigt diese Warnung an:

Wie erwartet, war die Qualität der Ausgabe nicht besonders gut:
Aufforderung:
Ein Käfer mit menschlichem Gesicht fährt ruhig einen Geländewagen und sitzt auf einem übergroßen Königsthron.
Allerdings sahen zwei der drei Zutaten - vor allem der Käfer und der Stuhl - überraschend gut aus. Der SUV, nicht so sehr...
Mit den Fähigkeiten von Veo 3 wäre dieses Setup wahrscheinlich viel stärker gewesen. Im Moment ist dieser Modus zwar vielversprechend, aber noch nicht ganz ausgereift.
Die Idee hinter Frames to Video ist folgende: Du gibst dem Modell ein erstes und ein letztes Bild vor, und es versucht, einen Übergang zwischen diesen beiden Bildern zu animieren (durch eine Kamerabewegung, die du steuern kannst). Du kannst diese Rahmen entweder aus einer Eingabeaufforderung generieren oder (eventuell) selbst hochladen - der Upload von Bildern ist noch nicht möglich.
Wie die Funktion "Zutaten" ist auch dieser Modus automatisch auf Veo 2 voreingestellt, was die Qualität erheblich einschränkt. Ich konnte damit nichts besonders Nützliches erzeugen.
Am Ende habe ich es benutzt, um eine einzelne Aufnahme eines Chamäleons zu animieren. Ich habe dasselbe Bild als Start- und Endbild festgelegt und eine Dolly-Kamerabewegung angefordert, aber dieser Teil wurde im endgültigen Rendering nicht berücksichtigt.
Aufforderung:
Ein Chamäleon sitzt regungslos auf einem Ast, die Augen scannen langsam in verschiedene Richtungen, während es geduldig auf Beute wartet.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
