
Lernpfad
Grundlagen der KI
10 Std.
Außerdem gibt es in Flow Werkzeuge für die Kamerasteuerung und Übergänge, die den Clips einen filmischen Charakter verleihen. Diese sind nützlich, aber nicht neu - Sora und Runway bieten bereits ähnliche Funktionen, also würde ich nicht sagen, dass es hier etwas Bahnbrechendes gibt.
Trotzdem lohnt es sich, darauf zu achten, wie sich solche Tools weiterentwickeln. Flow fühlt sich an wie die frühe Version eines KI-gestützten Videoeditors und es ist nicht schwer, sich eine Zukunft vorzustellen, in der diese Art von Workflow zum Standard wird. So wie wir heute Werkzeuge wie Premiere Pro oder DaVinci Resolve als selbstverständlich ansehen, könnte etwas wie Flow in ein paar Jahren zur Norm werden.
Flow ist derzeit nur in den USA verfügbar und du kannst es über Googles AI Pro- und AI Ultra-Abonnements nutzen.
Eine weitere wichtige Ankündigung war Imagen 4, Googles neuestes Modell zur Bilderzeugung. Du kannst es direkt in Gemini oder im Whisk, dem Design-Tool von Google, verwenden.
Google spricht von Verbesserungen in allen Bereichen - besserer Fotorealismus, sauberere Details bei Nahaufnahmen, mehr Vielfalt bei den Kunststilen. Das ist alles schön und gut, aber der Teil, der meine Aufmerksamkeit erregte, war das Versprechen einer fortschrittlichen Rechtschreibung und Typografie. Wenn du in letzter Zeit einen Bildgenerator benutzt hast, hast du wahrscheinlich gesehen, dass die meisten von ihnen immer noch Wörter durcheinander bringen oder Buchstaben komplett verzerren.
Schauen wir uns ein Bild an, das Imagen 4 erstellt hat:

Quelle: Google
Momentan würde ich sagen Die Bilderzeugung des GPT-4o ist die stärkste auf dem Markt. Allerdings hat sie manchmal noch Probleme mit dem Einhalten von Texten und Aufforderungen. Wenn Imagen 4 die Rechtschreibung richtig hinbekommt und sich an die Promptheit hält, hat es meiner Meinung nach eine Chance, die Führung bei der Bilderzeugung zu übernehmen.
Gemma 3n ist Googles neuestes und leistungsstärkstes On-Device-Modell. Falls du mit dem Begriff nicht vertraut bist: Ein On-Device-Modell läuft direkt auf deinem Telefon, Tablet oder Laptop - ohne dass Daten in die Cloud gesendet werden müssen. Das ist aus mehreren Gründen wichtig: geringere Latenzzeiten, besserer Datenschutz und Offline-Verfügbarkeit.
Aber damit das funktioniert, muss das Modell klein genug sein, um in den begrenzten Speicher zu passen, und trotzdem leistungsfähig genug, um echte Aufgaben zu bewältigen. Das ist die Herausforderung, die Gemma 3n zu meistern versucht.
Er basiert auf einer neuen Architektur, die er mit Gemini Nano teilt - und tatsächlich steht das "n" in "3n" für "nano". Diese Architektur ist für geringen Speicherbedarf, schnelle Reaktionszeiten und die Unterstützung verschiedener Eingabearten wie Text, Audio und Bilder optimiert.
Gemma 3n gibt es in zwei Varianten, mit den Parametergrößen 5B und 8B. Beide sind so konzipiert, dass sie dank einiger Optimierungen unter der Haube effizient laufen, wobei der Speicherbedarf eher bei 2B- und 4B-Modellen liegt.
Was mir aufgefallen ist, ist, dass er in der Chatbot-Arena fast gleichauf ist mit Claude 3.7 Sonneteinem viel größeren Modell.
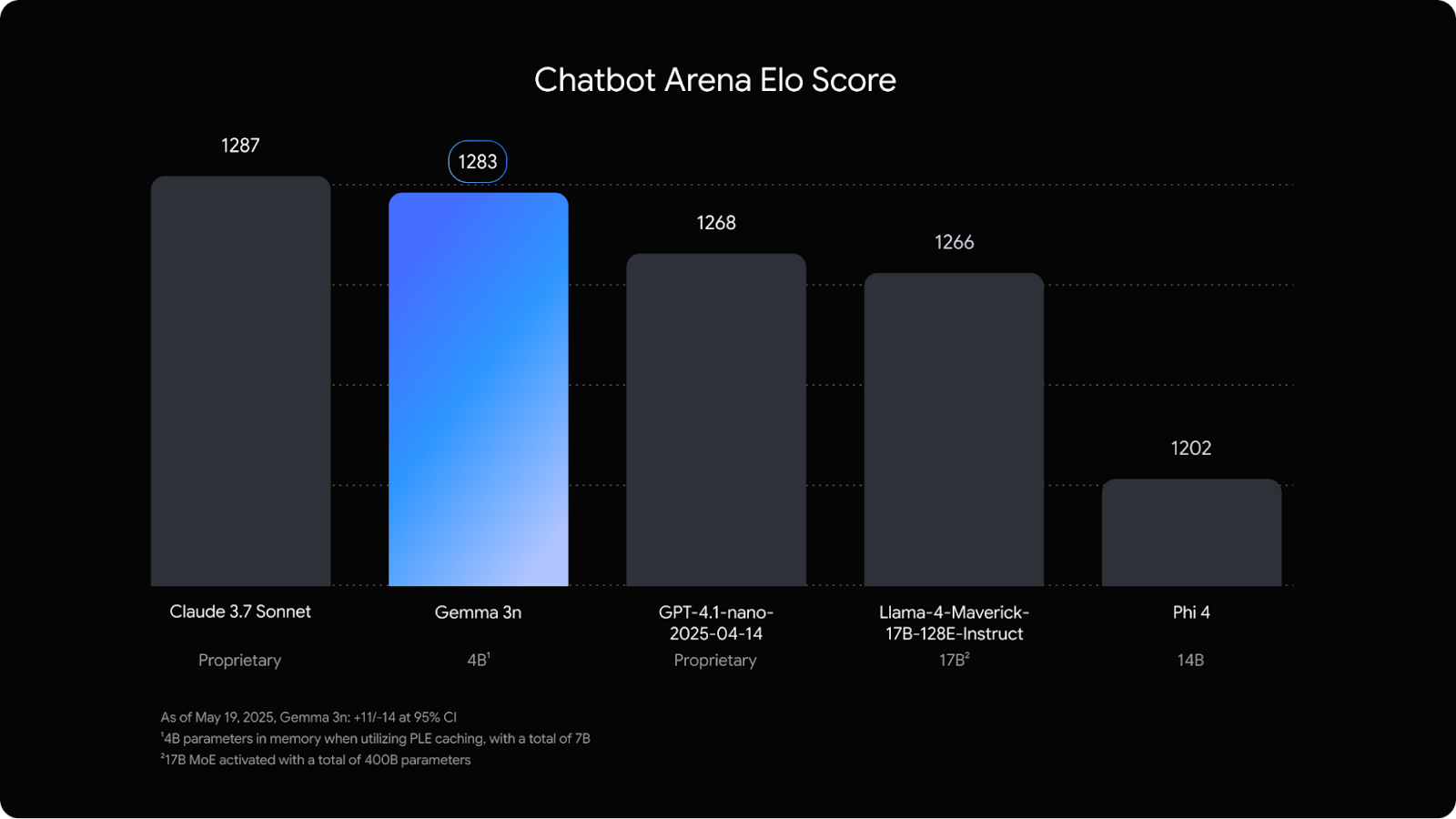
Quelle: Google
Diese Version richtet sich vor allem an Entwickler, die mobile oder eingebettete Anwendungen entwickeln, die von lokaler KI profitieren können. Während unser Team bei DataCamp an neuen Gemma 3n-Tutorials arbeitet, empfehle ich, mit diesen Gemma 3-Blogs zu beginnen:
Die Technologie, auf die ich am meisten gespannt bin, ist Gemini Difussion.
Gemini Diffusion ist eine neue experimentelle Modellarchitektur, die entwickelt wurde, um die Geschwindigkeit und Kohärenz bei der Texterstellung zu verbessern. Im Gegensatz zu traditionellen Sprachmodellen, die Token einzeln in einer festen Reihenfolge generieren, arbeiten Diffusionsmodelle mit der Verfeinerung von Rauschen in mehreren Schritten - eine Methode, die aus der Bilderzeugung stammt.
Anstatt das nächste Wort direkt vorherzusagen, beginnt Gemini Diffusion mit einer groben Annäherung und verbessert diese iterativ. Das macht es besser für Aufgaben, die von Verfeinerung und Fehlerkorrektur profitieren, wie Mathematik, Code und Bearbeitung.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
