Course
Introduction to Natural Language Processing in Python
4 hr
141K
Natural language processing (NLP) improves the way humans and computers communicate with each other by using machine learning to indicate the structure and meaning of the text. With natural language processing applications, organizations can increase productivity and reduce costs by analyzing text and extracting more meaningful information to improve customer experience.
We can't say that we often think about the subtleties of our language. It is an intuitive behavior that relies on semantic cues such as words, signs, or images to convey information and meaning. It is sometimes said that learning a language is easier in adolescence because it is a repeatable behavior that can be instilled, much like walking. Also, languages do not follow strict rules and have many exceptions.
Language acquisition, while natural for humans, is extremely complex for computers because it has a lot of unstructured data, a lack of strict rules, and no concrete perspective or context. Yet, humans increasingly rely on computer systems to communicate and perform tasks. This is why machine learning (ML) and artificial intelligence (AI) are gaining so much attention and popularity. Natural language processing is following the development of AI. Although these two terms may conjure up images of futuristic robots, there are already simple applications of natural language processing in everyday life.
NLP is a component of AI that focuses on understanding human language as it is written and/or spoken. To do this, specific computer programs are developed; a typical computer requires instructions to be conveyed in a very precise, marked-out, structured, and unambiguous programming language. Unfortunately, natural human language is imprecise, equivocal, and confusing. To enble a program to understand the meaning of words, it is necessary to use algorithms capable of analyzing the meaning and structure to make the words understandable, recognize certain references, and then generate the language.
NLP algorithms perform various syntactic and semantic analyses to evaluate the meaning of sentences based on grammatical rules. They do this by:
Common NLP techniques include:
NLP is used in a wide variety of applications. Here are some of the most common areas.
Messaging filters are one of the first basic online natural language processing applications. The technique was first used to create spam filters to identify unwanted messages based on certain words or phrases. As natural language processing evolved, so did the filters.
One of the most common and recent applications of this technique is Gmail's classification of emails. This system can classify an email into three categories (Main, Social Networks, or Promotions) based on its content. This allows Gmail users to manage their inboxes better to view and respond to important emails quickly.
Intelligent assistants such as Siri (Apple) and Alexa (Amazon) use voice recognition to identify speech patterns, infer meaning, and suggest a useful response. Today, it seems normal to ask Siri a question and for her to understand us and answer in a relevant way. Similarly, we are getting used to interacting with Siri or Alexa daily through our thermostat, lights, car, etc.
We now expect assistants like Alexa and Siri to pick up on contextual cues to help us in our daily lives and perform certain tasks (e.g., ordering items). We even enjoy their funny responses or when they tell us about themselves. Our interactions become more personal as they get to know us. According to the New York Times article Why We May Soon Be Living in Alexa's World, "A major shift is coming. Alexa will most likely become the third major consumer platform of this decade."
Search engines use natural language processing to display relevant results based on similar search behaviors or user intent. This allows everyone to find what they need without having any special skills.
For example, when you start typing a query, Google shows you popular related searches, but it can also recognize the general meaning of your query beyond the exact wording. If you type a flight number into Google, you'll know its status. You'll get a stock report if you type in a stock symbol. If you type in a math equation, you'll get a calculator. Your search can offer a variety of results because the natural language processing technique it uses associates an ambiguous query with a given entity to offer useful results.
Features such as autocorrect, autocomplete, and intuitive input are so common on our smartphones today that we take them for granted. Auto-typing and intuitive typing are comparable to search engines in that they rely on what is typed to suggest the end of a word or phrase. Autocorrect sometimes even changes some words to improve the overall meaning of your message.
In addition, these functions evolve as you do. For example, intuitive typing adapts over time to your specific turns of phrase. This sometimes results in funny message exchanges, with sentences based entirely on intuitive input. The result can be surprisingly personal and informative and has even attracted some media attention at times.
If your foreign language exercise is full of grammatical errors, your teacher will likely know that you cheated by using natural language processing technology. Unfortunately, many languages do not lend themselves to direct translation because they have different sentence constructions, which have sometimes been overlooked by translation services. However, these systems have come a long way.
Thanks to natural language processing, online translation tools offer more accurate and grammatically correct translations. Therefore, they are extremely useful if you need to communicate with someone who does not speak your language. If you need to translate a foreign text, these tools can even recognize the language of the text entered for translation.
When calling some companies, most of us will likely have heard the announcement "this call may be recorded for training purposes". While these recordings can be used for training purposes (e.g., to analyse an exchange with a disgruntled customer), they are usually stored in a database that allows a natural language processing system to learn and grow. Automated systems redirect customer calls to an agent or online chatbot, which will provide relevant information to answer their requests. This natural language processing technique is already used by many companies, including major telephone operators.
Digital phone call technology also allows a computer to imitate the human voice. It is thus possible to plan automated phone calls to make an appointment at the garage or the hairdresser.
Natural language capabilities are now integrated into analytical workflows. Indeed, more and more BI vendors are offering a natural language interface for their data visualizations. More intelligent visual coding allows, for example, to propose the best possible visualization for a specific task, depending on the semantics of the data. Anyone can explore the data using natural language statements or fragments of questions whose keywords are interpreted and understood.
Exploring data using language makes data more accessible and opens up analytics to the entire enterprise beyond the usual circle of IT analysts and developers.
Text analytics converts unstructured textual data into analyzable data using various linguistic, statistical, and machine learning techniques.
Sentiment analysis can seem like a daunting challenge for brands (especially in the case of a large customer base). However, a natural language processing-based tool can typically look at customer interactions (such as comments or reviews on social media, or even mentions of brand names) to see what they are. Then, brands can analyze these interactions to assess the effectiveness of their marketing campaign or monitor the evolution of customer issues. They can then decide how to respond, or improve their service to provide a better experience.
Natural language processing also contributes to text analytics by extracting keywords and identifying patterns or trends in unstructured text data. What are the main NLP models?
While NLP has been around for a while, recent advancements have been remarkable, particularly with the rise of transformer-based models and large-scale language models developed by leading tech companies. Some of the most advanced models include:
Transformer-based models:
Large language models (LLMs):
In this tutorial, we’ll take a closer look at how BERT is used for NLP.
BERT, from the acronym "Bidirectional Encoder Representations from Transformers", is a model released by Google AI. This innovative technique is based on natural language processing (NLP).
The algorithm essentially uses machine learning and artificial intelligence to understand the queries made by internet users. Thus, it tries to interpret their search intentions, i.e., the natural language they use.
In this sense, BERT is associated with personal voice assistants such as Google Home. The tool is no longer based on each word entered by the user, but considers the entire expression and the context in which it is situated. This is done in order to refine the results. It is more efficient at handling complex searches, regardless of the medium used.
More concretely, BERT allows the search engine to :
For other applications, BERT is used in :
Thus, the impact of Google BERT would be about 10% on the longest queries, typed in a natural way.
Natural language processing focuses on the analysis of words typed by the user. The keyword, its predecessors, and its successors are all examined to better understand the query. This is the principle of analysis adopted by "transformers".
The algorithm is particularly effective for long-tail searches, where prepositions influence the meaning. On the other hand, its impact on generic queries is less important, since they are already well understood by Google. The other comprehension tools, therefore, remain functional.
Whether the query is formulated in a disordered or precise way, the search engine is still able to process it. But for more efficiency, it is better to use more appropriate terms.
Context plays an important role in the analysis performed by BERT. Machine translation and linguistic modeling are optimized. Significant improvements are also noted in the generation of quality texts.
To use this model, let’s first import the necessary libraries and packages, as shown here:
Next, let's download and extract the Large Movie Review Dataset, then explore the directory’s structure.
To create a labeled tf.data.Dataset we’ll use the text_dataset_from_directory as shown below. Next, we’ll create a validation set using an 80:20 split of the training data by using the validation_split argument.
It’s important to specify a random seed while using the validation_split so that the validation and training splits have no overlap.
The next step will be choosing which BERT model you’d like to load and fine-tune from Tensorflow Hub, you can use the hub.KerasLayer to compose your fine-tuned model. Then, we’ll try the preprocessing model on some text and see the output.
Next, you will build a simple model composed of the preprocessing model, the BERT model that you selected in the previous steps, a dense layer, and a Dropout layer.
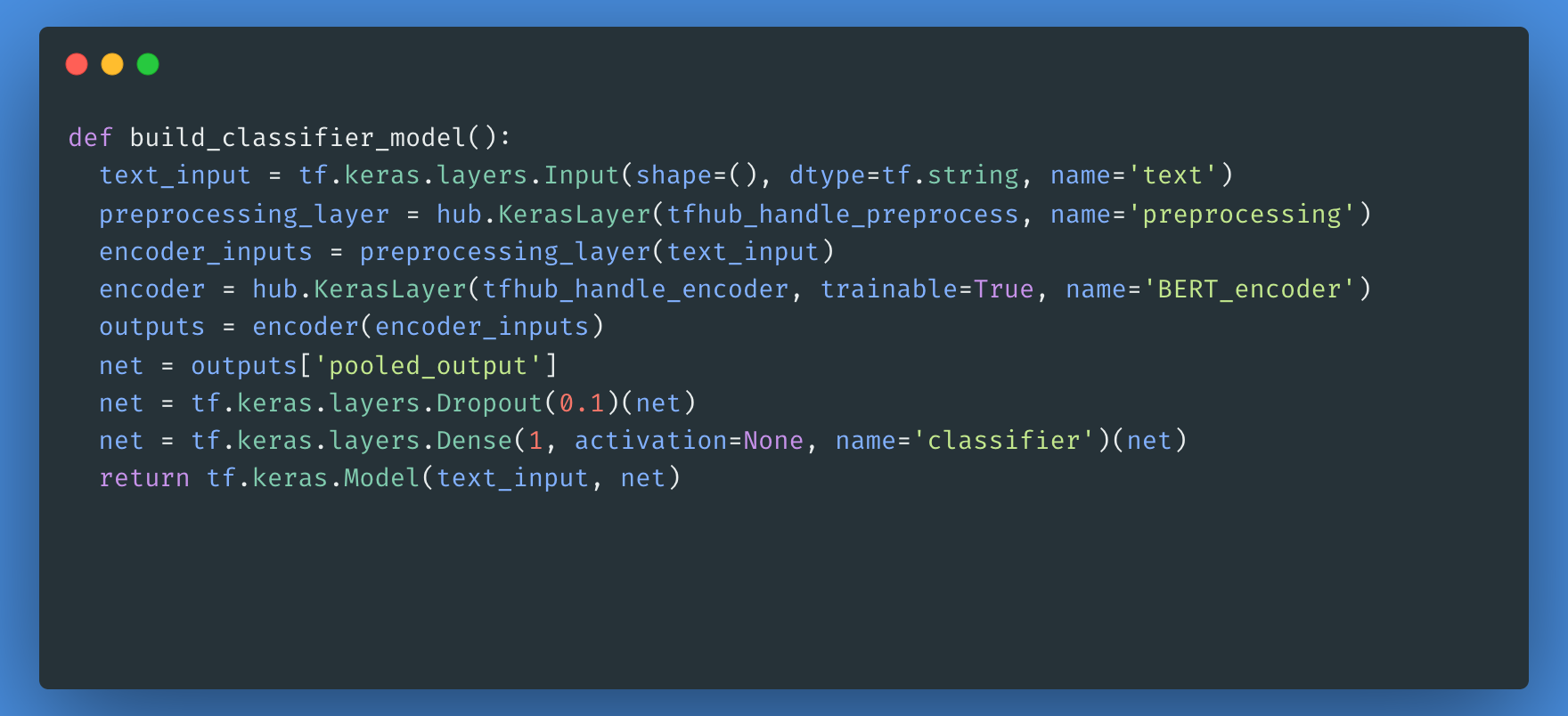
Now, you can check if your model runs with the output of the preprocessing model.

The loss function is a necessary step here, we’ll opt for the losses.BinaryCrossentropy loss function as we are dealing with a binary classification problem.

For fine-tuning, let's use the same optimizer that BERT was originally trained with: the "Adaptive Moments" (Adam). This optimizer minimizes the prediction loss and does regularization by weight decay, which is also known as AdamW.

Using the classifier_model you created earlier, you can compile the model with the loss, metric, and optimizer.

Note that your model might take less or more time to train depending on the complexity of the BERT model you chose.

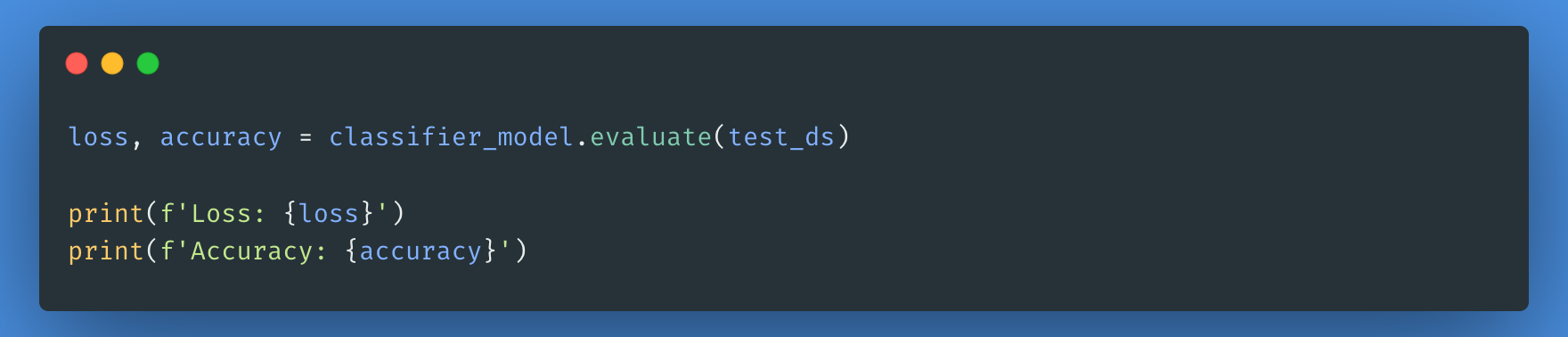
Now, we’ll evaluate how our model performed by checking the loss and accuracy of the model.
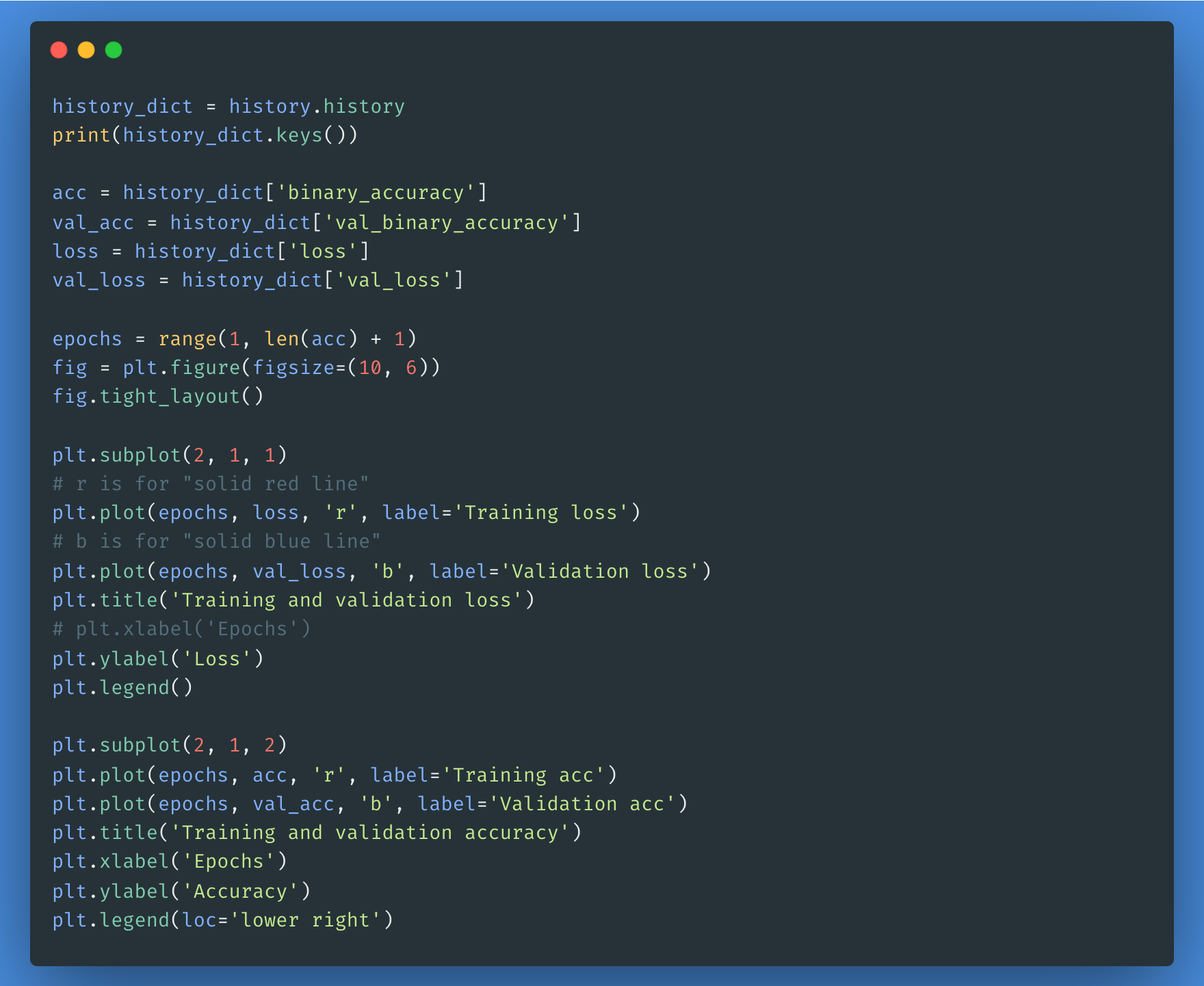
You can use the history object if you’d like to plot loss and accuracy for training and validation sets:
All of the above steps are detailed in this notebook. You can practice the above steps and run the code to see the outputs for each BERT model in the list.
Natural language processing is already well established in the digital world. Its applications will multiply as companies and industries discover its benefits and adopt it. While human intervention will continue to be essential for more complex communication problems, natural language processing will be our everyday ally, managing and automating minor tasks at first and then handling increasingly complex ones as technology advances.
To learn more about how NLP works and how to use it, check out our Deep Learning for NLP in Python course.
Learn more about NLP with these courses!
Course
Course
Course
blog
Matt Crabtree
11 min
blog
Laiba Siddiqui
13 min
blog
Travis Tang
15 min
blog
Dimitri Didmanidze
7 min
code-along
Richie Cotton
code-along
Jacob Marquez

