
programa
Tratamiento de imágenes en Python
12 h
Extraer texto de imágenes y documentos manualmente puede ser muy tedioso y llevar mucho tiempo. Afortunadamente, el OCR (Reconocimiento Óptico de Caracteres) puede automatizar este proceso, permitiéndote convertir esas imágenes en archivos de texto editables y con capacidad de búsqueda.
Las técnicas que vas a aprender pueden aplicarse en muchos ámbitos:
El tutorial se centrará en el motor Tesseract OCR y su API Python - PyTesseract. Antes de empezar a escribir código, repasemos brevemente algunas de las bibliotecas populares dedicadas al OCR.
Dado que el OCR es un problema actual muy popular, muchas bibliotecas de código abierto intentan resolverlo. En esta sección, trataremos las que han ganado más popularidad debido a su alto rendimiento y precisión.
Tesseract OCR es un motor de reconocimiento óptico de caracteres de código abierto que es el más popular entre los desarrolladores. Como otras herramientas de esta lista, Tesseract puede tomar imágenes de texto y convertirlas en texto editable.
EasyOCR es una biblioteca Python diseñada para el Reconocimiento Óptico de Caracteres (OCR) sin esfuerzo. Hace honor a su nombre ofreciendo un enfoque fácil de usar para la extracción de texto de imágenes.
Keras-OCR es una biblioteca de Python construida sobre Keras, un popular marco de aprendizaje profundo. Proporciona modelos de OCR listos para usar y un proceso de formación integral para crear nuevos modelos de OCR.
Aquí tienes una tabla que resume sus diferencias, ventajas e inconvenientes:
|
Nombre del paquete |
Ventaja |
Desventajas |
|
Teseracto (pytesseract) |
Maduro, ampliamente utilizado, amplio apoyo |
Más lento, menor precisión en trazados complejos |
|
EasyOCR |
Fácil de usar, múltiples modelos |
Menor precisión, personalización limitada |
|
Keras-OCR |
Mayor precisión, personalizable |
Requiere GPU, curva de aprendizaje más pronunciada |
En este tutorial, nos centraremos en PyTesseract, que es la API Python de Tesseract. Aprenderemos a extraer texto de imágenes sencillas, a dibujar cuadros delimitadores alrededor del texto y realizaremos un caso práctico con un documento escaneado.
PyTesseract funciona sobre el motor oficial de Tesseract, que es un software CLI independiente. Antes de instalar pytesseract, debes tener instalado el motor. A continuación encontrarás instrucciones de instalación para diferentes plataformas.
Para Ubuntu o WSL2 (mi elección):
$ sudo apt update && sudo apt upgrade
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
Para Mac utilizando Homebrew:
$ brew install tesseract
Para Windows, sigue las instrucciones de esta página de GitHub.
A continuación, crea un nuevo entorno virtual. Utilizaré Conda:
$ conda create -n ocr python==3.9 -y
$ conda activate ocr
Después, debes instalar pytesseract para hacer OCR y opencv para manipular imágenes:
$ pip install pytesseract
$ pip install opencv-python
Si estás siguiendo este tutorial en Jupyter, ejecuta estos comandos en la misma sesión de terminal para que tu nuevo entorno virtual se añada como núcleo:
$ pip install ipykernel
$ ipython kernel install --user --name=ocr
Ahora, podemos empezar a escribir código.
Comenzamos importando las bibliotecas necesarias:
import cv2
import pytesseract
Nuestra tarea consiste en leer el texto de la siguiente imagen:

En primer lugar, definimos la trayectoria de la imagen y la introducimos en la función cv2.imread:
# Read image
easy_text_path = "images/easy_text.png"
easy_img = cv2.imread(easy_text_path)
A continuación, pasamos la imagen cargada a la función image_to_string de pytesseract para extraer el texto:
# Convert to text
text = pytesseract.image_to_string(easy_img)
print(text)
This text is
easy to extract.
¡Así de fácil! Convirtamos lo que acabamos de hacer en una función:
def image_to_text(input_path):
"""
A function to read text from images.
"""
img = cv2.imread(input_path)
text = pytesseract.image_to_string(img)
return text.strip()
Utilicemos la función en una imagen más difícil:

La imagen ofrece un mayor desafío, ya que hay más símbolos de puntuación y texto en distintos tipos de letra.
# Define image path
medium_text_path = "images/medium_text.png"
# Extract text
extracted_text = image_to_text(medium_text_path)
print(extracted_text)
Home > Tutorials » Data Engineering
Snowflake Tutorial For Beginners:
From Architecture to Running
Databases
Learn the fundamentals of cloud data warehouse management using
Snowflake. Snowflake is a cloud-based platform that offers significant
benefits for companies wanting to extract as much insight from their data as
quickly and efficiently as possible.
Jan 2024 - 12 min read
Nuestra función funcionó casi a la perfección. Confundió uno de los puntos y signos ">", pero por lo demás el resultado es aceptable.
Una operación habitual en OCR es dibujar cuadros delimitadores alrededor del texto. Esta operación está soportada en PyTesseract.
Primero, pasamos una imagen cargada a la función image_to_data:
from pytesseract import Output
# Extract recognized data from easy text
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
La parte Output.DICT garantiza que los detalles de la imagen se devuelvan como un diccionario. Echemos un vistazo al interior:
data{'level': [1, 2, 3, 4, 5, 5, 5, 4, 5, 5, 5],
'page_num': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'block_num': [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
'word_num': [0, 0, 0, 0, 1, 2, 3, 0, 1, 2, 3],
'left': [0, 41, 41, 236, 236, 734, 1242, 41, 41, 534, 841],
'top': [0, 68, 68, 68, 68, 80, 68, 284, 309, 284, 284],
'width': [1658, 1550, 1550, 1179, 380, 383, 173, 1550, 381, 184, 750],
'height': [469, 371, 371, 128, 128, 116, 128, 155, 130, 117, 117],
'conf': [-1, -1, -1, -1, 96, 95, 95, -1, 96, 96, 96],
'text': ['', '', '', '', 'This', 'text', 'is', '', 'easy', 'to', 'extract.']}
El diccionario contiene mucha información sobre la imagen. En primer lugar, fíjate en las teclas conf y text. Ambos tienen una longitud de 11:
len(data["text"])11Esto significa que pytesseract dibujó 11 casillas. El conf significa confianza. Si es igual a -1, el recuadro correspondiente se dibuja alrededor de bloques de texto y no de palabras sueltas.
Por ejemplo, si te fijas en los cuatro primeros valores de width y height, son grandes en comparación con el resto, porque esos recuadros se dibujan alrededor de todo el texto en el centro, y luego para cada línea de texto y la propia imagen en general.
Also:
left es la distancia desde la esquina superior izquierda del cuadro delimitador hasta el borde izquierdo de la imagen.top es la distancia desde la esquina superior izquierda del cuadro delimitador hasta el borde superior de la imagen.width y height son la anchura y la altura del cuadro delimitador.Utilizando estos datos, vamos a dibujar los recuadros encima de la imagen en OpenCV.
En primer lugar, extraemos de nuevo los datos y su longitud:
from pytesseract import Output
# Extract recognized data
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
n_boxes = len(data["text"])
A continuación, creamos un bucle para el número de cajas encontradas:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
Dentro del bucle, creamos una condición que se salta la iteración actual del bucle si conf es igual a -1. Omitir las cajas delimitadoras más grandes mantendrá limpia nuestra imagen.
A continuación, definimos las coordenadas de la caja actual, concretamente las ubicaciones de las esquinas superior izquierda e inferior derecha:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
Tras definir algunos parámetros de la caja, como el color de la caja y el grosor en píxeles, pasamos toda la información a la función cv2.rectangle:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 3 # pixels
cv2.rectangle(
img=easy_img, pt1=top_left, pt2=bottom_right, color=green, thickness=thickness
)
La función dibujará los recuadros encima de las imágenes originales. Guardemos la imagen y echemos un vistazo:
# Save the image
output_image_path = "images/text_with_boxes.jpg"
cv2.imwrite(output_image_path, easy_img)
True
¡El resultado es justo lo que queríamos!
Ahora, volvamos a poner todo lo que hicimos en una función:
def draw_bounding_boxes(input_img_path, output_path):
img = cv2.imread(input_img_path)
# Extract data
data = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(data["text"])
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 1 # The function-version uses thinner lines
cv2.rectangle(img, top_left, bottom_right, green, thickness)
# Save the image with boxes
cv2.imwrite(output_path, img)
Y utiliza la función en el texto semiduro:
output_path = "images/medium_text_with_boxes.png"
draw_bounding_boxes(medium_text_path, output_path)

Incluso para la imagen más difícil, ¡el resultado es perfecto!
Hagamos un estudio de caso sobre un archivo PDF escaneado de muestra. En la práctica, es muy probable que trabajes con PDF escaneados en lugar de con imágenes, como ésta:
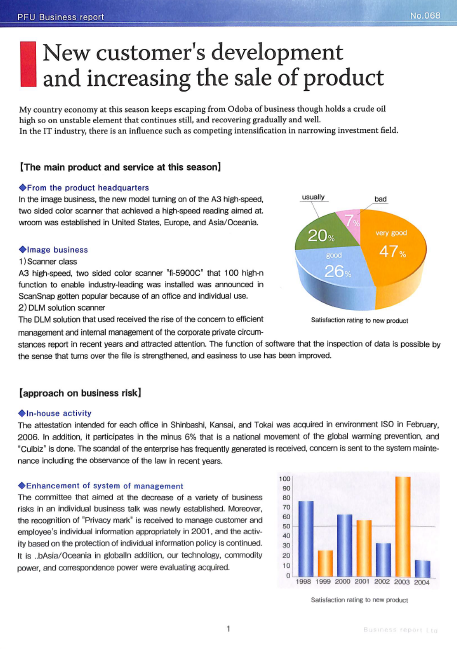
Puedes descargar el PDF desde esta página de mi GitHub.
El siguiente paso es instalar la biblioteca pdf2image, que requiere un software de procesamiento de PDF llamado Poppler. Aquí tienes instrucciones específicas para cada plataforma:
Para Mac:
$ brew install poppler
$ pip install pdf2image
Para Linux y WSL2:
$ sudo apt-get install -y poppler-utils
$ pip install pdf2image
Para Windows, puedes seguir las instrucciones de la documentación de PDF2Image.
Tras la instalación, importamos los módulos correspondientes:
import pathlib
from pathlib import Path
from pdf2image import convert_from_path
La función convert_from_path convierte un PDF dado en una serie de imágenes. Aquí tienes una función que guarda cada página de un archivo PDF como una imagen en un directorio determinado:
def pdf_to_image(pdf_path, output_folder: str = "."):
"""
A function to convert PDF files to images
"""
# Create the output folder if it doesn't exist
if not Path(output_folder).exists():
Path(output_folder).mkdir()
pages = convert_from_path(pdf_path, output_folder=output_folder, fmt="png")
return pages
Vamos a ejecutarlo en nuestro documento:
pdf_path = "scanned_document.pdf"
pdf_to_image(pdf_path, output_folder="documents")
[<PIL.PngImagePlugin.PngImageFile image mode=RGB size=1662x2341>]
La salida es una lista que contiene un único objeto de imagen PngImageFile. Echemos un vistazo al directorio documents:
$ ls documents
2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png
La imagen está ahí, así que alimentemos nuestra función image_to_text que creamos al principio e imprimamos los primeros cientos de caracteres del texto extraído:
scanned_img_path = "documents/2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png"
print(image_to_text(scanned_img_path)[:377])
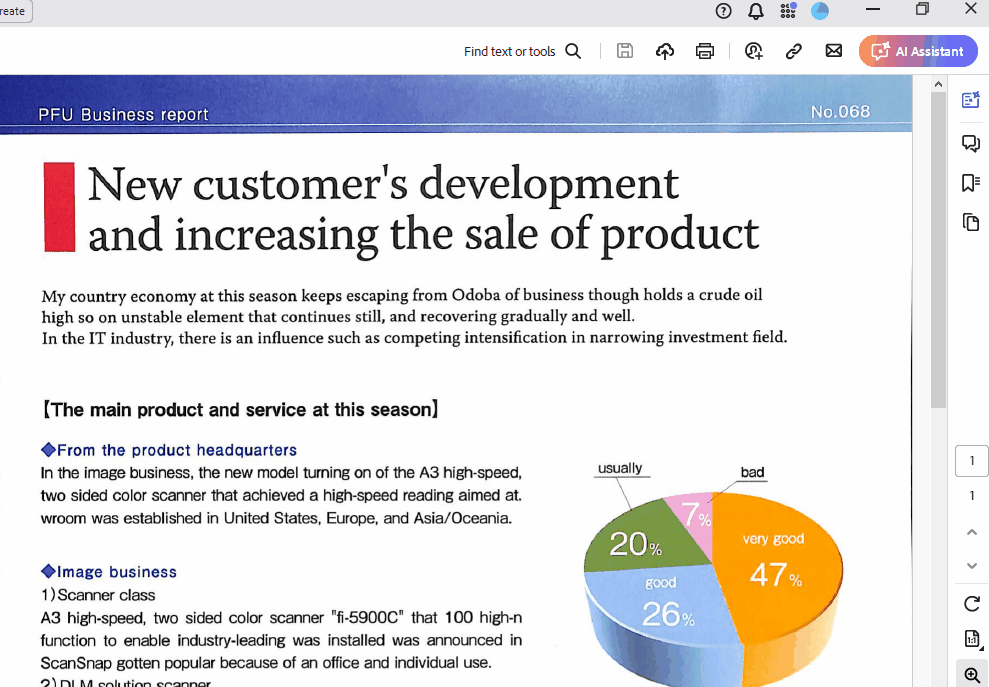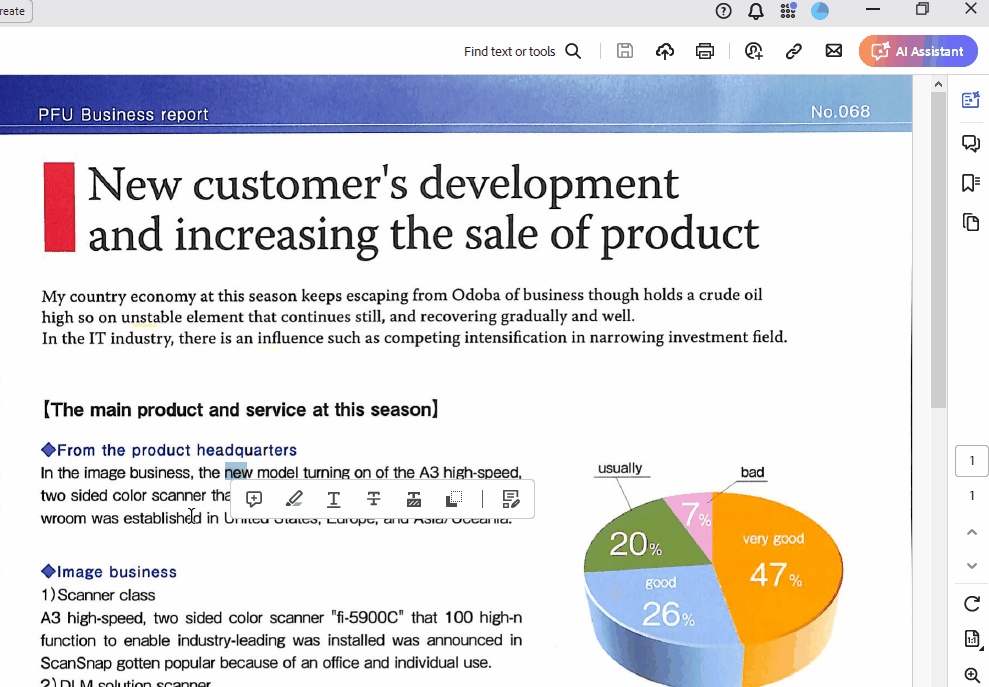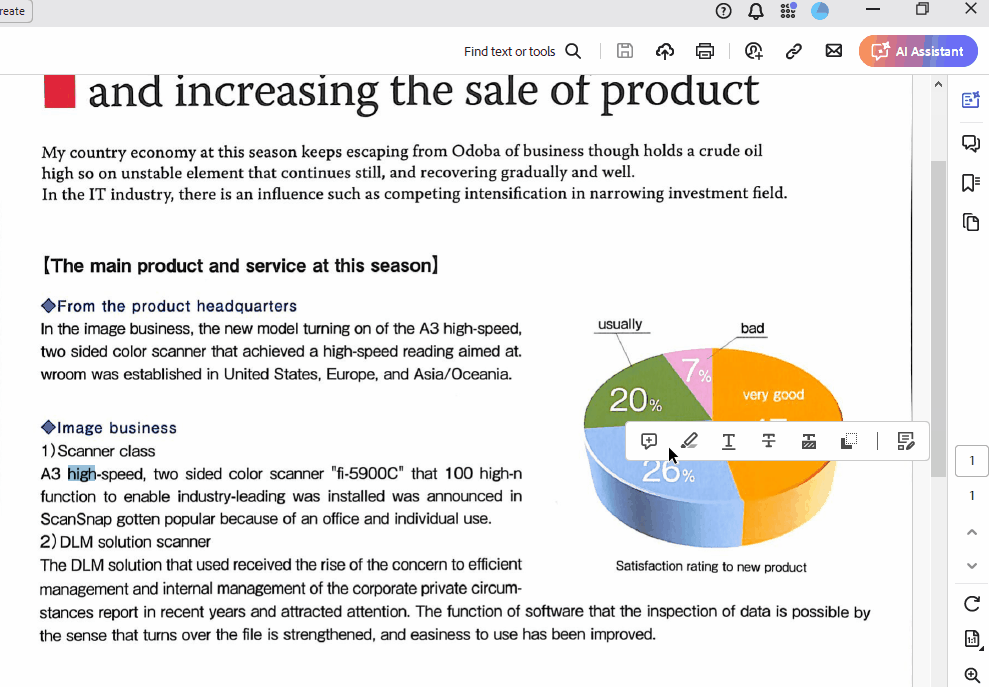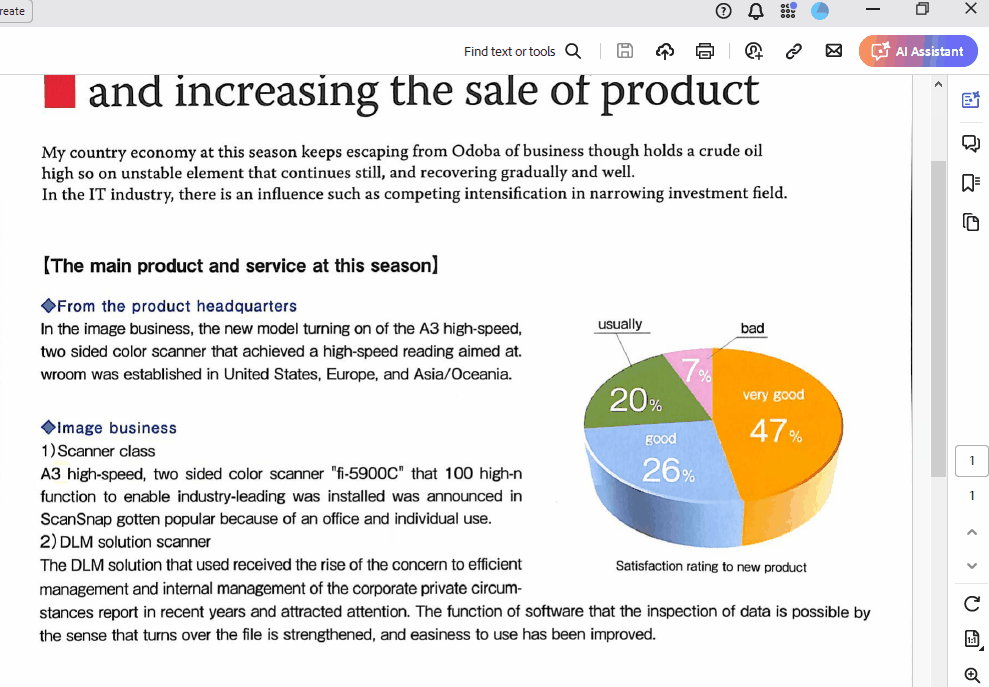
PEU Business report
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
Si comparamos el texto con el archivo, todo funciona bien: se conserva el formato y el espaciado, y el texto es preciso. Entonces, ¿cómo compartimos el texto extraído?
Pues bien, ¡el mejor formato para compartir un texto PDF extraído es otro archivo PDF! PyTesseract tiene una función image_to_pdf_or_hocr que toma cualquier imagen con texto y la convierte en un archivo PDF sin procesar, en el que se puede buscar texto. Utilicémoslo en nuestra imagen escaneada:
raw_pdf = pytesseract.image_to_pdf_or_hocr(scanned_img_path)
with open("searchable_pdf.pdf", "w+b") as f:
f.write(bytearray(raw_pdf))
Y éste es el aspecto de searchable_pdf:
Como puedes ver, puedo resaltar y copiar texto del archivo. Además, se conservan todos los elementos del PDF original.
No existe un enfoque único para el OCR. Las técnicas que hemos tratado hoy pueden no funcionar con otros tipos de imágenes. Te recomiendo que experimentes con distintas técnicas de preprocesamiento de imágenes y configuraciones de Tesseract para encontrar los ajustes óptimos para imágenes concretas.
El factor más importante en el OCR es la calidad de la imagen. Las imágenes correctamente escaneadas, totalmente verticales y de alto contraste (blanco y negro) suelen funcionar mejor con cualquier programa de OCR. Recuerda que el hecho de que tú puedas leer el texto no significa que tu ordenador pueda hacerlo.
Si tus imágenes no satisfacen los altos estándares de calidad de Tesseract y el resultado es un galimatías, hay algunos pasos de preprocesamiento que puedes realizar.
Primero, empieza por convertir las imágenes en color a escala de grises. Esto puede mejorar la precisión al eliminar las variaciones de color que podrían confundir el proceso de reconocimiento. En OpenCV, esto tendrá el siguiente aspecto:
def grayscale(image):
"""Converts an image to grayscale.
Args:
image: The input image in BGR format.
Returns:
The grayscale image.
"""
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
No todas las imágenes, especialmente los documentos escaneados, vienen con fondos prístinos y uniformes. Además, algunas imágenes pueden proceder de documentos antiguos en los que las páginas se han deteriorado por el paso del tiempo. He aquí un ejemplo:

Aplica técnicas como filtros de eliminación de ruido (por ejemplo, desenfoque medio) para reducir los artefactos de ruido en la imagen que pueden dar lugar a interpretaciones erróneas durante el OCR. En OpenCV, puedes utilizar la función medianBlur:
def denoise(image):
"""Reduces noise in the image using a median blur filter.
Args:
image: The input grayscale image.
Returns:
The denoised image.
"""
return cv2.medianBlur(image, 5) # Adjust kernel size as needed
En algunos casos, afinar la imagen puede realzar los bordes y mejorar el reconocimiento de caracteres, especialmente en el caso de imágenes borrosas o de baja resolución. El afilado puede realizarse aplicando un filtro Laplaciano en OpenCV:
def sharpen(image):
"""Sharpens the image using a Laplacian filter.
Args:
image: The input grayscale image.
Returns:
The sharpened image (be cautious with sharpening).
"""
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
return cv2.filter2D(image, -1, kernel)
Para determinadas imágenes, la binarización (convertir la imagen a blanco y negro) puede ser beneficiosa. Experimenta con distintas técnicas de umbralización para encontrar la separación óptima entre el primer plano (texto) y el fondo.
Sin embargo, la binarización puede ser sensible a las variaciones de iluminación y no siempre es necesaria. Aquí tienes un ejemplo del aspecto de una imagen binarizada:

Para realizar la binarización en OpenCV, puedes utilizar la función adaptiveThreshold:
def binarize(image):
"""Binarizes the image using adaptive thresholding.
Args:
image: The input grayscale image.
Returns:
The binary image.
"""
thresh = cv2.adaptiveThreshold(
image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2
)
return thresh
Existen muchas otras técnicas de preprocesamiento, como:
Puedes obtener más información sobre las mejoras de la calidad de imagen en esta página de la documentación de Tesseract.
En este artículo, has dado los primeros pasos para conocer el problema dinámico que es el OCR. Primero cubrimos cómo extraer texto de imágenes sencillas, y luego pasamos a imágenes más difíciles con formato complejo.
También hemos aprendido un flujo de trabajo integral para extraer texto de PDF escaneados y cómo volver a guardar el texto extraído como PDF para que se pueda buscar en él. Hemos completado el artículo con algunos consejos para mejorar la calidad de la imagen con OpenCV antes de pasarla a Tesseract.
Si quieres aprender más sobre la resolución de problemas relacionados con las imágenes, aquí tienes algunos recursos sobre visión por ordenador que puedes consultar:
¡Continúa tu viaje de aprendizaje de Python!
programa
programa
Curso
Tutorial
Natassha Selvaraj
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Théo Vanderheyden
