




Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.2K
Recientemente, DuckDB salió de beta y lanzó su versión estable, ganando popularidad rápidamente a medida que varios marcos de datos lo integran en sus ecosistemas. Esto hace que sea un buen momento para aprender DuckDB, de modo que puedas mantenerte al día en el siempre cambiante mundo de los datos y la IA.
En este tutorial, aprenderemos sobre DuckDB y sus principales características con ejemplos de código. Nos centraremos principalmente en cómo podemos integrarlo con los marcos actuales de IA. Para ello, trabajaremos en dos proyectos. En primer lugar, bedificaremos una aplicación de Generación Mejorada por Recuperación (RAG) utilizando DuckDB como base de datos vectorial. A continuación, utilizaremos DuckDB como motor de consulta de IA para analizar datos utilizando lenguaje natural en lugar de SQL .
DuckDB es un sistema de gestión de bases de datos analíticas (SGBD) en memoria, moderno y de alto rendimiento, diseñado para soportar consultas analíticas complejas. Es un SGBD relacional (orientado a tablas) que admite el Lenguaje de Consulta Estructurado (SQL).
DuckDB combina la sencillez y facilidad de uso de SQLite con las capacidades de alto rendimiento necesarias para las cargas de trabajo analíticas, lo que lo convierte en una opción excelente para los científicos y analistas de datos.
En esta sección, aprenderemos a configurar DuckDB, cargar archivos CSV, realizar análisis de datos y conocer las relaciones y las funciones de consulta.
Empezaremos instalando el paquete DuckDB Python.
pip install duckdb --upgradePara crear la base de datos persistente, sólo tienes que utilizar la función connect y proporcionarle el nombre de la base de datos.
import duckdb
con = duckdb.connect("datacamp.duckdb")Creará un archivo de base de datos en tu directorio local.
Cargaremos un archivo CSV y crearemos una tabla "banco". El conjunto de datos que estamos utilizando está disponible en DataLab y se llama Marketing bancario. Se trata de campañas de marketing directo de una entidad bancaria portuguesa mediante llamadas telefónicas.
Para cargar el archivo CSV, primero tienes que crear una Tabla utilizando SQL y luego utilizar la función read_csv() dentro del script SQL para cargar el archivo. Es así de sencillo.
A continuación, validaremos nuestra tabla ejecutando el script SQL que muestra todas las tablas de la base de datos y utilizando la función fetchdf para mostrar el resultado como un DataFrame pandas.
Nota: Estamos utilizando DataLab de DataCamp como editor de código. DataLab es un cuaderno Jupyter en la nube al que puedes acceder gratuitamente si tienes una cuenta en DataCamp.
con.execute("""
CREATE TABLE IF NOT EXISTS bank AS
SELECT * FROM read_csv('bank-marketing.csv')
""")
con.execute("SHOW ALL TABLES").fetchdf()
Ahora que hemos creado con éxito nuestra primera tabla, ejecutaremos una consulta de nivel principiante para analizar los datos y mostrar el resultado como un DataFrame.
con.execute("SELECT * FROM bank WHERE duration < 100 LIMIT 5").fetchdf()
DuckDB está integrado de forma nativa en el nuevo DataLab de DataCamp. Obtén más información leyendo el blog "DuckDB hace de SQL un ciudadano de primera clase en DataLab"y utiliza la celda SQL interactiva para analizar datos.
Las relaciones DuckDB son esencialmente tablas que pueden consultarse utilizando la API Relacional. Esta API permite encadenar varias operaciones de consulta sobre fuentes de datos como Pandas DataFrames. En lugar de utilizar consultas SQL, lo harás encadenando varias funciones de Python para analizar los datos.
Por ejemplo, cargaremos un archivo CSV para crear la relación DuckDB. Para analizar la tabla, puedes encadenar las funciones de filtro y límite.
bank_duck = duckdb.read_csv("bank-marketing.csv",sep=";")
bank_duck.filter("duration < 100").limit(3).df()
También podemos crear relaciones cargando la tabla desde la base de datos DuckDB.
rel = con.table("bank")
rel.columns['age',
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'day_of_week',
'duration',
'campaign',
'pdays',
'previous',
'poutcome',
'emp.var.rate',
'cons.price.idx',
'cons.conf.idx',
'euribor3m',
'nr.employed',
'y']Escribamos una relación que utilice varias funciones para analizar los datos.
rel.filter("duration < 100").project("job,education,loan").order("job").limit(3).df()Tenemos tres filas y columnas ordenadas por trabajo y filtradas por la columna de duración.
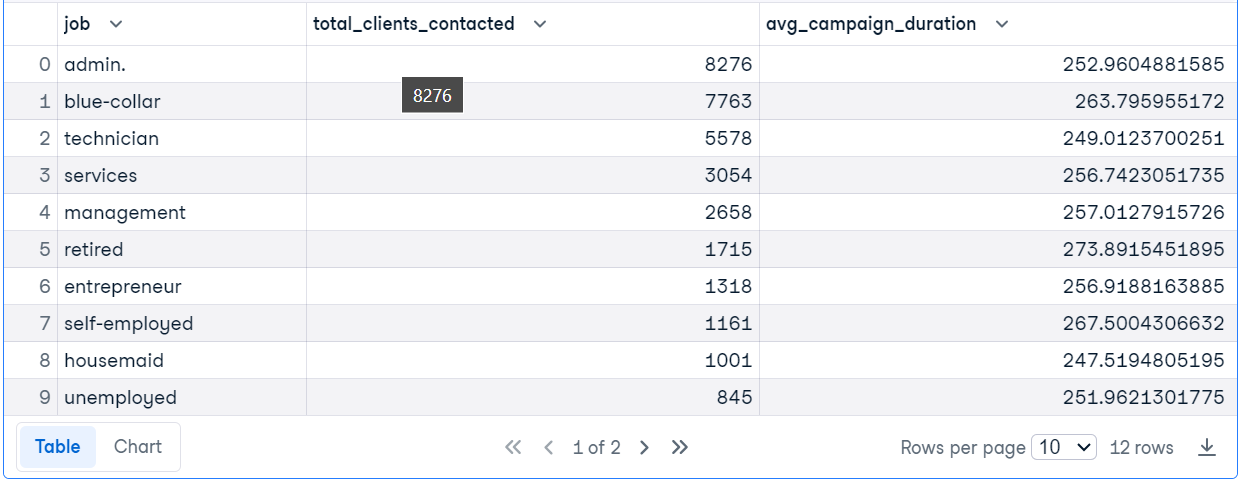
La función de consulta de DuckDB permite ejecutar consultas SQL dentro de la base de datos, devolviendo resultados que pueden convertirse en varios formatos para su posterior análisis.
En el ejemplo de código, estamos ejecutando la consulta SQL para averiguar los puestos de trabajo de los clientes mayores de 30 años, contar el número de clientes contactados para cada puesto de trabajo y calcular la duración media de la campaña.
Toma el examen Fundamentos de SQL para aprender a gestionar una base de datos relacional y ejecutar consultas para análisis de datos sencillos.
res = duckdb.query("""SELECT
job,
COUNT(*) AS total_clients_contacted,
AVG(duration) AS avg_campaign_duration,
FROM
'bank-marketing.csv'
WHERE
age > 30
GROUP BY
job
ORDER BY
total_clients_contacted DESC;""")
res.df()
Ahora cerraremos la conexión a la base de datos y liberaremos todos los recursos asociados a esa conexión, evitando posibles fugas de memoria y de manejadores de archivo.
con.close()Si tienes problemas para ejecutar el código anterior, consulta la sección Introducción a DuckDB espacio de trabajo.
En el primer proyecto, aprenderemos a construir una aplicación RAG con LlamaIndex y a utilizar DuckDB como base de datos vectorial y recuperador.
Instala todos los paquetes Python necesarios que se utilizarán para crear y recuperar el índice.
%%capture
%pip install duckdb
%pip install llama-index
%pip install llama-index-vector-stores-duckdbImporta el paquete Python necesario con las funciones.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.duckdb import DuckDBVectorStore
from llama_index.core import StorageContext
from IPython.display import Markdown, displayPara el modelo lingüístico, utilizaremos el último modelo GPT4o y la API OpenAI. Para crear el cliente del gran modelo lingüístico (LLM), sólo tienes que proporcionar un nombre de modelo y clave API.
import os
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o",api_key=os.environ["OPENAI_API_KEY"])A continuación, crearemos el cliente del modelo de incrustación utilizando el modelo OpenAI text-embedding-3-small.
Nota: Proporcionar una clave de la API de OpenAI es opcional si la variable de entorno se establece con el nombre "OPENAI_API_KEY" en tu entorno de desarrollo.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
)Haremos que los modelos LLM e Incrustación de OpenAI sean globales para que los utilicen todas las funciones de LlamaIndex. En resumen, estos modelos se establecerán por defecto.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelPara nuestro proyecto, cargaremos los archivos PDF desde la carpeta de datos. Estos archivos PDF son tutoriales de DataCamp que se guardan como archivos PDF utilizando la función de impresión del navegador.
Proporciona el directorio de carpetas a la función SimpleDirectoryReader y carga los datos.
documents = SimpleDirectoryReader("Data").load_data()
A continuación, crea el almacén vectorial llamado "blog" utilizando una base de datos existente llamada "datacamp.duckdb". Después, convierte los datos del PDF en incrustaciones y almacénalos en el almacén vectorial.
vector_store = DuckDBVectorStore(database_name = "datacamp.duckdb",table_name = "blog",persist_dir="./", embed_dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)Para comprobar si nuestro almacén vectorial se ha creado correctamente, conectaremos la base de datos utilizando la API Python de DuckDB y ejecutaremos la consulta SQL para mostrar todas las tablas de la base de datos.
import duckdb
con = duckdb.connect("datacamp.duckdb")
con.execute("SHOW ALL TABLES").fetchdf()Tenemos dos tablas: una tabla promocional "banco" y una tabla "blog", que es un almacén de vectores. La tabla "blog" tiene una columna "incrustación" donde se almacenan todas las incrustaciones.
Convierte el índice en el motor de consulta, que primero buscará automáticamente documentos similares en la base de datos vectorial y utilizará el contexto adicional para generar la respuesta.
Para probar el motor de consulta RAG, haremos la pregunta sobre el tutorial.
query_engine = index.as_query_engine()
response = query_engine.query("Who wrote 'GitHub Actions and MakeFile: A Hands-on Introduction'?")
display(Markdown(f"<b>{response}</b>"))Y la respuesta es correcta.
The author of "GitHub Actions and MakeFile: A Hands-on Introduction" is Abid Ali Awan.Ahora, vamos a crear una aplicación RAG avanzada que utilice el historial de conversaciones para generar la respuesta. Para ello, tenemos que crear un búfer de memoria de chat y luego un motor de chat con memoria, LLM y recuperador de almacenes vectoriales.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm
)
response = chat_engine.chat(
"What is the easiest way of finetuning the Llama 3 model? Please provide step-by-step instructions."
)
display(Markdown(response.response))Preguntamos al motor de chat cómo afinar el modelo Llama 3, y utilizó el almacén vectorial para dar una respuesta muy precisa.

Para comprobar si el búfer de memoria funciona correctamente, haremos una pregunta complementaria.
response = chat_engine.chat(
"Could you please provide more details about the Post Fine-Tuning Steps?"
)
display(Markdown(response.response))El motor del chat recordaba la conversación anterior y respondía en consecuencia.

Si tienes problemas para ejecutar el código anterior, echa un vistazo a la sección Crear una aplicación RAG con DuckDB espacio de trabajo.
En el segundo proyecto, utilizaremos DuckDB como motor de consulta SQL. Se trata de integrar el motor de la base de datos con el modelo GPT-4o para generar respuestas en lenguaje natural a preguntas sobre la base de datos.
Instala duckdb-engine para crear un motor de base de datos utilizando SQLAlchemy.
%pip install duckdb-engine -qCargaremos la base de datos DuckDB utilizando la función create_engine y luego escribiremos una consulta SQL sencilla para comprobar si se ha cargado correctamente.
from sqlalchemy import create_engine
engine = create_engine("duckdb:///datacamp.duckdb")
with engine.connect() as connection:
cursor = connection.exec_driver_sql("SELECT * FROM bank LIMIT 3")
print(cursor.fetchall())Prefecto. Nuestro motor de base de datos DuckDB está listo para ser utilizado.
[(56, 'housemaid', 'married', 'basic.4y', 'no', 'no', 'no', 'telephone', 'may', 'mon', 261, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (57, 'services', 'married', 'high.school', 'unknown', 'no', 'no', 'telephone', 'may', 'mon', 149, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (37, 'services', 'married', 'high.school', 'no', 'yes', 'no', 'telephone', 'may', 'mon', 226, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no')]Ahora, tenemos que crear una Herramienta de base de datos utilizando la función SQLDatabase. Proporciónale un objeto motor y un nombre de tabla.
from llama_index.core import SQLDatabase
sql_database = SQLDatabase(engine, include_tables=["bank"])Crea el motor de consultas SQL utilizando la función NLSQLTableQueryEngine proporcionándole el objeto de base de datos SQL LlamaIndex.
from llama_index.core.query_engine import NLSQLTableQueryEngine
query_engine = NLSQLTableQueryEngine(sql_database)Haz la pregunta del motor de consulta sobre la tabla "banco" en lenguaje natural.
response = query_engine.query("Which is the longest running campaign?")
print(response.response)En respuesta, obtendremos la respuesta a tu consulta en lenguaje natural. Esto es impresionante, ¿no crees?
The longest running campaign in the database has a duration of 4918 days.Formulemos una pregunta compleja.
response = query_engine.query("Which type of job has the most housing loan?")
print(response.response)La respuesta es precisa, con información adicional.
The job type with the most housing loans is 'admin.' with 5559 housing loans. This is followed by 'blue-collar' with 4710 housing loans and 'technician' with 3616 housing loans. Other job types with significant housing loans include 'services', 'management', 'retired', 'entrepreneur', and 'self-employed'.Para comprobar lo que ocurre en el back end, imprimiremos los metadatos.
print(response.metadata)Como vemos, GPT-4o genera primero la consulta SQL, ejecuta la consulta para obtener el resultado y utiliza el resultado para generar la respuesta. Este proceso de varios pasos se consigue mediante dos líneas de código.
{'d4ddf03c-337e-4ee6-957a-5fd2cfaa4b1c': {}, 'sql_query': "SELECT job, COUNT(housing) AS housing_loan_count\nFROM bank\nWHERE housing = 'yes'\nGROUP BY job\nORDER BY housing_loan_count DESC;", 'result': [('admin.', 5559), ('blue-collar', 4710), ('technician', 3616), ('services', 2050), ('management', 1490), ('retired', 892), ('entrepreneur', 779), ('self-employed', 740), ('unemployed', 557), ('housemaid', 540), ('student', 471), ('unknown', 172)], 'col_keys': ['job', 'housing_loan_count']}Cierra el motor cuando hayas terminado con el proyecto.
engine.close()Si tienes problemas para ejecutar el código anterior, echa un vistazo a la página Motor de consultas SQL DuckDB espacio de trabajo.
DuckDB es rápido, fácil de usar y se integra perfectamente con numerosos marcos de datos e IA. Como científico de datos, descubrirás que sólo te llevará unos minutos acostumbrarte a su API y empezar a utilizarlo como cualquier otro paquete de Python. Una de las mejores características de DuckDB es que no tiene dependencias, lo que significa que puedes utilizarlo prácticamente en cualquier sitio sin preocuparte del alojamiento o de configuraciones adicionales.
En este tutorial, hemos aprendido sobre DuckDB y sus principales características. También hemos explorado la API Python de DuckDB, utilizándola para crear una tabla y realizar análisis de datos sencillos. La segunda mitad del tutorial abarcó dos proyectos: uno sobre una aplicación de Generación Mejorada por Recuperación (RAG) con DuckDB como base de datos vectorial y otro demostrando DuckDB como motor de consulta SQL.
Antes de lanzarte a utilizar un motor de consulta SQL o a integrar una base de datos con la IA, necesitas unos conocimientos básicos de SQL y análisis de datos. Puedes escribir la consulta, pero ¿cómo sabrías qué pregunta hacer? Aquí es donde entran en juego unos conocimientos básicos de análisis de datos y SQL. Puedes adquirir estos conocimientos completando el Analista de Datos Asociado en SQL en SQL.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Kurtis Pykes
Tutorial
Moez Ali




