




Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
Recentemente, o DuckDB saiu da versão beta e lançou sua versão estável, ganhando popularidade rapidamente à medida que várias estruturas de dados o integram em seus ecossistemas. Isso faz com que seja o momento ideal para aprender DuckDB para que você possa acompanhar o mundo em constante mudança dos dados e da IA.
Neste tutorial, aprenderemos sobre o DuckDB e seus principais recursos com exemplos de código. Nosso foco principal será como podemos integrá-lo às estruturas atuais de IA. Para isso, trabalharemos em dois projetos. Primeiro, vamos bconstruir um aplicativo Retrieval-Augmented Generation (RAG) usando o DuckDB como um banco de dados vetorial. Em seguida,usaremos o DuckDB como um mecanismo de consulta de IA para analisar dados usando linguagem natural em vez de SQL .
DuckDB é um sistema de gerenciamento de banco de dados analítico (DBMS) moderno, de alto desempenho e na memória, projetado para suportar consultas analíticas complexas. É um DBMS relacional (orientado por tabela) que oferece suporte à linguagem de consulta estruturada (SQL).
O DuckDB combina a simplicidade e a facilidade de uso do SQLite com os recursos de alto desempenho necessários para cargas de trabalho analíticas, o que o torna uma excelente opção para cientistas e analistas de dados.
Nesta seção, aprenderemos a configurar o DuckDB, carregar arquivos CSV, realizar análise de dados e aprender sobre relações e funções de consulta.
Começaremos instalando o pacote Python do DuckDB.
pip install duckdb --upgradePara criar o banco de dados persistente, você só precisa usar a função connect e fornecer o nome do banco de dados.
import duckdb
con = duckdb.connect("datacamp.duckdb")Ele criará um arquivo de base de dados em seu diretório local.
Carregaremos um arquivo CSV e criaremos uma tabela de "banco". O conjunto de dados que estamos usando está disponível no DataLab e se chama Marketing bancário. Consiste em campanhas de marketing direto de uma instituição bancária portuguesa usando chamadas telefônicas.
Para carregar o arquivo CSV, você precisa primeiro criar uma tabela usando o SQL e, em seguida, usar a função read_csv() no script SQL para carregar o arquivo. É simples assim.
Em seguida, validaremos nossa tabela executando o script SQL que mostra todas as tabelas do banco de dados e usando a função fetchdf para exibir o resultado como um DataFrame pandas.
Observação: Estamos usando o DataCamp's DataLab como editor de código. O DataLab é um Jupyter Notebook na nuvem que você pode acessar gratuitamente se tiver uma conta no DataCamp.
con.execute("""
CREATE TABLE IF NOT EXISTS bank AS
SELECT * FROM read_csv('bank-marketing.csv')
""")
con.execute("SHOW ALL TABLES").fetchdf()
Agora que criamos nossa primeira tabela com sucesso, executaremos uma consulta de nível iniciante para analisar os dados e exibir o resultado como um DataFrame.
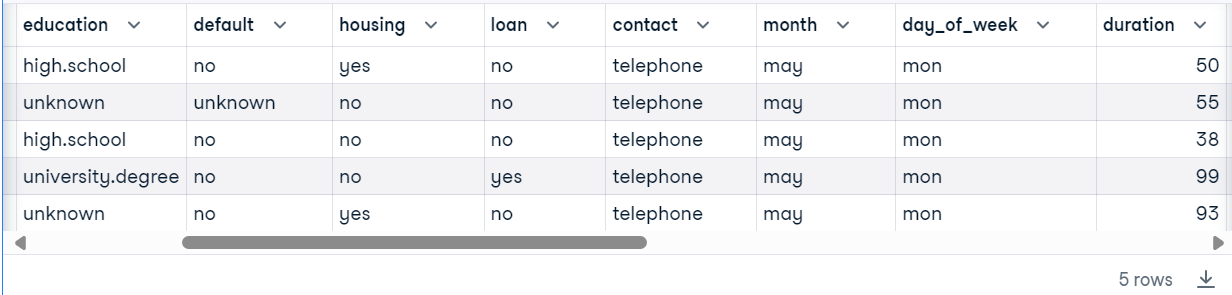
con.execute("SELECT * FROM bank WHERE duration < 100 LIMIT 5").fetchdf()
O DuckDB está integrado de forma nativa ao novo DataLab da DataCamp. Saiba mais sobre isso lendo o blog "DuckDB faz do SQL um cidadão de primeira classe no DataLab" e usando a célula SQL interativa para analisar dados.
As relações do DuckDB são essencialmente tabelas que podem ser consultadas usando a API relacional. Essa API permite que você encadeie várias operações de consulta em fontes de dados, como os DataFrames do Pandas. Em vez de usar consultas SQL, você encadeará várias funções Python para analisar os dados.
Por exemplo, carregaremos um arquivo CSV para criar a relação DuckDB. Para analisar a tabela, você pode encadear as funções de filtro e limite.
bank_duck = duckdb.read_csv("bank-marketing.csv",sep=";")
bank_duck.filter("duration < 100").limit(3).df()
Você também pode criar relações carregando a tabela do banco de dados DuckDB.
rel = con.table("bank")
rel.columns['age',
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'day_of_week',
'duration',
'campaign',
'pdays',
'previous',
'poutcome',
'emp.var.rate',
'cons.price.idx',
'cons.conf.idx',
'euribor3m',
'nr.employed',
'y']Vamos escrever uma relação que use várias funções para analisar os dados.
rel.filter("duration < 100").project("job,education,loan").order("job").limit(3).df()Temos três linhas e colunas classificadas por cargo e filtradas pela coluna de duração.
A função de consulta do DuckDB permite que as consultas SQL sejam executadas no banco de dados, retornando resultados que podem ser convertidos em vários formatos para análise posterior.
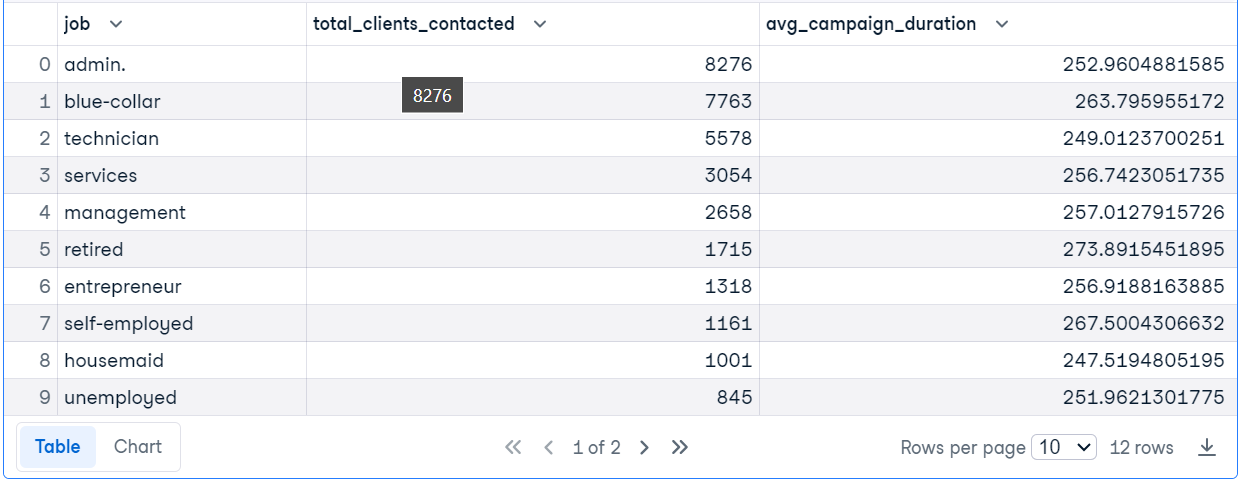
No exemplo de código, estamos executando a consulta SQL para descobrir os cargos dos clientes com mais de 30 anos, contar o número de clientes contatados para cada cargo e calcular a duração média da campanha.
Faça o curso Fundamentos de SQL para que você aprenda a gerenciar um banco de dados relacional e a executar consultas para análise simples de dados.
res = duckdb.query("""SELECT
job,
COUNT(*) AS total_clients_contacted,
AVG(duration) AS avg_campaign_duration,
FROM
'bank-marketing.csv'
WHERE
age > 30
GROUP BY
job
ORDER BY
total_clients_contacted DESC;""")
res.df()
Agora, fecharemos a conexão com o banco de dados e liberaremos todos os recursos associados a essa conexão, evitando possíveis vazamentos de memória e de manipulador de arquivo.
con.close()Se você estiver enfrentando problemas ao executar o código acima, dê uma olhada na seção Primeiros passos com o DuckDB para você.
No primeiro projeto, aprenderemos a criar um aplicativo RAG com o LlamaIndex e a usar o DuckDB como um banco de dados Vector e retriever.
Instale todos os pacotes Python necessários que serão usados para criar e recuperar o índice.
%%capture
%pip install duckdb
%pip install llama-index
%pip install llama-index-vector-stores-duckdbImporte o pacote Python necessário com as funções.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.duckdb import DuckDBVectorStore
from llama_index.core import StorageContext
from IPython.display import Markdown, displayPara um modelo de idioma, usaremos o modelo GPT4o mais recente e a API OpenAI. Para criar o cliente de modelo de linguagem grande (LLM), você só precisa fornecer um nome de modelo e uma chave de API.
import os
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o",api_key=os.environ["OPENAI_API_KEY"])Em seguida, criaremos o cliente do modelo incorporado usando o modelo text-embedding-3-small da OpenAI.
Observação: O fornecimento de uma chave de API OpenAI é opcional se a variável de ambiente estiver definida com o nome "OPENAI_API_KEY" em seu ambiente de desenvolvimento.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
)Tornaremos os modelos OpenAI LLM e Embedding globais para que todas as funções do LlamaIndex sejam usadas. Em resumo, esses modelos serão definidos como padrão.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelPara o nosso projeto, carregaremos os arquivos PDF da pasta de dados. Esses arquivos PDF são tutoriais da DataCamp que são salvos como arquivos PDF usando a função de impressão do navegador.
Forneça o diretório da pasta para a função SimpleDirectoryReader e carregue os dados.
documents = SimpleDirectoryReader("Data").load_data()
Em seguida, crie o armazenamento de vetores chamado "blog" usando um banco de dados existente chamado "datacamp.duckdb". Depois disso, converta os dados do PDF em embeddings e armazene-os no armazenamento de vetores.
vector_store = DuckDBVectorStore(database_name = "datacamp.duckdb",table_name = "blog",persist_dir="./", embed_dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)Para verificar se nosso armazenamento de vetores foi criado com êxito, conectaremos o banco de dados usando a API Python do DuckDB e executaremos a consulta SQL para exibir todas as tabelas do banco de dados.
import duckdb
con = duckdb.connect("datacamp.duckdb")
con.execute("SHOW ALL TABLES").fetchdf()Temos duas tabelas: uma tabela promocional de "banco" e uma tabela de "blog", que é uma loja de vetores. Na tabela "blog", você tem uma coluna "embedding" em que todas as embeddings são armazenadas.
Converta o índice no mecanismo de consulta, que primeiro pesquisará automaticamente o banco de dados de vetores em busca de documentos semelhantes e usará o contexto adicional para gerar a resposta.
Para testar o mecanismo de consulta RAG, faremos a pergunta sobre o tutorial.
query_engine = index.as_query_engine()
response = query_engine.query("Who wrote 'GitHub Actions and MakeFile: A Hands-on Introduction'?")
display(Markdown(f"<b>{response}</b>"))E a resposta está correta.
The author of "GitHub Actions and MakeFile: A Hands-on Introduction" is Abid Ali Awan.Agora, vamos criar um aplicativo RAG avançado que usa o histórico de conversas para gerar a resposta. Para isso, temos que criar um buffer de memória de bate-papo e, em seguida, um mecanismo de bate-papo com memória, LLM e recuperador de armazenamento de vetores.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm
)
response = chat_engine.chat(
"What is the easiest way of finetuning the Llama 3 model? Please provide step-by-step instructions."
)
display(Markdown(response.response))Perguntamos ao mecanismo de bate-papo como fazer o ajuste fino do modelo Llama 3, e ele usou o armazenamento de vetores para dar uma resposta altamente precisa.

Para verificar se o buffer de memória está funcionando corretamente, faremos uma pergunta de acompanhamento.
response = chat_engine.chat(
"Could you please provide more details about the Post Fine-Tuning Steps?"
)
display(Markdown(response.response))O mecanismo de bate-papo lembrava a conversa anterior e respondia de acordo.

Se você estiver enfrentando problemas ao executar o código acima, dê uma olhada na seção Como criar um aplicativo RAG com o DuckDB para você.
No segundo projeto, usaremos o DuckDB como um mecanismo de consulta SQL. Isso envolve a integração do mecanismo de banco de dados com o modelo GPT-4o para gerar respostas em linguagem natural a perguntas sobre o banco de dados.
Instale o duckdb-engine para criar um mecanismo de banco de dados usando o SQLAlchemy.
%pip install duckdb-engine -qCarregaremos o banco de dados DuckDB usando a função create_engine e, em seguida, escreveremos uma consulta SQL simples para verificar se o carregamento foi bem-sucedido.
from sqlalchemy import create_engine
engine = create_engine("duckdb:///datacamp.duckdb")
with engine.connect() as connection:
cursor = connection.exec_driver_sql("SELECT * FROM bank LIMIT 3")
print(cursor.fetchall())Prefeito. Nosso mecanismo de banco de dados DuckDB está pronto para ser usado.
[(56, 'housemaid', 'married', 'basic.4y', 'no', 'no', 'no', 'telephone', 'may', 'mon', 261, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (57, 'services', 'married', 'high.school', 'unknown', 'no', 'no', 'telephone', 'may', 'mon', 149, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (37, 'services', 'married', 'high.school', 'no', 'yes', 'no', 'telephone', 'may', 'mon', 226, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no')]Agora, temos que criar uma ferramenta de banco de dados usando a função SQLDatabase. Forneça a ele um objeto de mecanismo e o nome da tabela.
from llama_index.core import SQLDatabase
sql_database = SQLDatabase(engine, include_tables=["bank"])Crie o mecanismo de consulta SQL usando a função NLSQLTableQueryEngine, fornecendo a ele o objeto de banco de dados SQL LlamaIndex.
from llama_index.core.query_engine import NLSQLTableQueryEngine
query_engine = NLSQLTableQueryEngine(sql_database)Faça a pergunta ao mecanismo de consulta sobre a tabela "banco" na linguagem natural.
response = query_engine.query("Which is the longest running campaign?")
print(response.response)Em resposta, obteremos a resposta para sua consulta em idiomas naturais. Isso é incrível, você não acha?
The longest running campaign in the database has a duration of 4918 days.Vamos fazer uma pergunta complexa.
response = query_engine.query("Which type of job has the most housing loan?")
print(response.response)A resposta é precisa, com informações adicionais.
The job type with the most housing loans is 'admin.' with 5559 housing loans. This is followed by 'blue-collar' with 4710 housing loans and 'technician' with 3616 housing loans. Other job types with significant housing loans include 'services', 'management', 'retired', 'entrepreneur', and 'self-employed'.Para verificar o que está acontecendo no back-end, imprimiremos os metadados.
print(response.metadata)Como podemos ver, o GPT-4o primeiro gera a consulta SQL, executa a consulta para obter o resultado e usa o resultado para gerar a resposta. Esse processo de várias etapas é realizado por meio de duas linhas de código.
{'d4ddf03c-337e-4ee6-957a-5fd2cfaa4b1c': {}, 'sql_query': "SELECT job, COUNT(housing) AS housing_loan_count\nFROM bank\nWHERE housing = 'yes'\nGROUP BY job\nORDER BY housing_loan_count DESC;", 'result': [('admin.', 5559), ('blue-collar', 4710), ('technician', 3616), ('services', 2050), ('management', 1490), ('retired', 892), ('entrepreneur', 779), ('self-employed', 740), ('unemployed', 557), ('housemaid', 540), ('student', 471), ('unknown', 172)], 'col_keys': ['job', 'housing_loan_count']}Feche o motor quando você terminar o projeto.
engine.close()Se você estiver enfrentando problemas ao executar o código acima, dê uma olhada no Mecanismo de consulta SQL do DuckDB do DuckDB.
O DuckDB é rápido, fácil de usar e se integra perfeitamente a várias estruturas de dados e IA. Como cientista de dados, você descobrirá que leva apenas alguns minutos para se acostumar com a API e começar a usá-la como qualquer outro pacote Python. Um dos melhores recursos do DuckDB é que ele não tem dependências, o que significa que você pode usá-lo praticamente em qualquer lugar sem se preocupar com hospedagem ou configuração adicional.
Neste tutorial, aprendemos sobre o DuckDB e seus principais recursos. Também exploramos a API Python do DuckDB, usando-a para criar uma tabela e realizar análises de dados simples. A segunda metade do tutorial abordou dois projetos: um envolvendo um aplicativo RAG (Retrieval-Augmented Generation) com o DuckDB como banco de dados vetorial e o outro demonstrando o DuckDB como um mecanismo de consulta SQL.
Antes de começar a usar um mecanismo de consulta SQL ou integrar um banco de dados com IA, você precisa ter um conhecimento básico de SQL e análise de dados. Você pode escrever a consulta, mas como saberia que pergunta fazer? É aqui que entra um conhecimento básico de análise de dados e SQL. Você pode obter esse conhecimento concluindo o curso Analista de dados associado em SQL para que você possa se qualificar para o programa de carreira.
Principais cursos da DataCamp
Curso
Curso
Curso