





Cours
Développement d'applications LLM avec LangChain
3 h
46.4K
Recently, DuckDB came out of beta and released its stable version, gaining popularity rapidly as various data frameworks integrate it into their ecosystems. This makes it a prime time to learn DuckDB so you can keep up with the ever-changing world of data and AI.
In this tutorial, we will learn about DuckDB and its key features with code examples. Our primary focus will be on how we can integrate it with current AI frameworks. For that, we will work on two projects. First, we'll build a Retrieval-Augmented Generation (RAG) application using DuckDB as a vector database. Then, we'll use DuckDB as an AI query engine to analyze data using natural language instead of SQL.
DuckDB is a modern, high-performance, in-memory analytical database management system (DBMS) designed to support complex analytical queries. It is a relational (table-oriented) DBMS that supports the Structured Query Language (SQL).
DuckDB combines the simplicity and ease of use of SQLite with the high-performance capabilities required for analytical workloads, making it an excellent choice for data scientists and analysts.
In this section, we will learn to set up DuckDB, load CSV files, perform data analysis, and learn about relations and query functions.
We will start by installing the DuckDB Python package.
pip install duckdb --upgradeTo create the persistent database, you just have to use the connect function and provide it with the database name.
import duckdb
con = duckdb.connect("datacamp.duckdb")It will create a database base file in your local directory.
We will load a CSV file and create a "bank" table. The dataset we are using is available on DataLab and is called Bank Marketing. It consists of direct marketing campaigns by a Portuguese banking institution using phone calls.
To load the CSV file, you have to create a Table first using SQL and then use the read_csv() function within the SQL script to load the file. It is that simple.
We will then validate our table by executing the SQL script that shows all of the tables within the database and using the fetchdf function to display the result as a pandas DataFrame.
Note: We are using DataCamp’s DataLab as a code editor. DataLab is a cloud Jupyter Notebook that you can access for free if you have a DataCamp account.
con.execute("""
CREATE TABLE IF NOT EXISTS bank AS
SELECT * FROM read_csv('bank-marketing.csv')
""")
con.execute("SHOW ALL TABLES").fetchdf()
Now that we have successfully created our first table, we will run a beginner-level query to analyze the data and display the result as a DataFrame.
con.execute("SELECT * FROM bank WHERE duration < 100 LIMIT 5").fetchdf()
DuckDB is natively integrated into the new DataLab by DataCamp. Learn more about it by reading the blog "DuckDB Makes SQL a First-Class Citizen on DataLab" and using the interactive SQL cell to analyze data.
DuckDB relations are essentially tables that can be queried using the Relational API. This API allows for the chaining of various query operations on data sources like Pandas DataFrames. Instead of using SQL queries, you will by chaining together various Python functions to analyze the data.
For example, we will load a CSV file to create the DuckDB relation. To analyze the table, you can chain the filter and limit functions.
bank_duck = duckdb.read_csv("bank-marketing.csv",sep=";")
bank_duck.filter("duration < 100").limit(3).df()
We can also create relations by loading the table from the DuckDB database.
rel = con.table("bank")
rel.columns['age',
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'day_of_week',
'duration',
'campaign',
'pdays',
'previous',
'poutcome',
'emp.var.rate',
'cons.price.idx',
'cons.conf.idx',
'euribor3m',
'nr.employed',
'y']Let’s write a relation that uses multiple functions to analyze the data.
rel.filter("duration < 100").project("job,education,loan").order("job").limit(3).df()We have three rows and columns sorted by job and filtered by duration column.
The DuckDB query function allows SQL queries to be executed within the database, returning results that can be converted into various formats for further analysis.
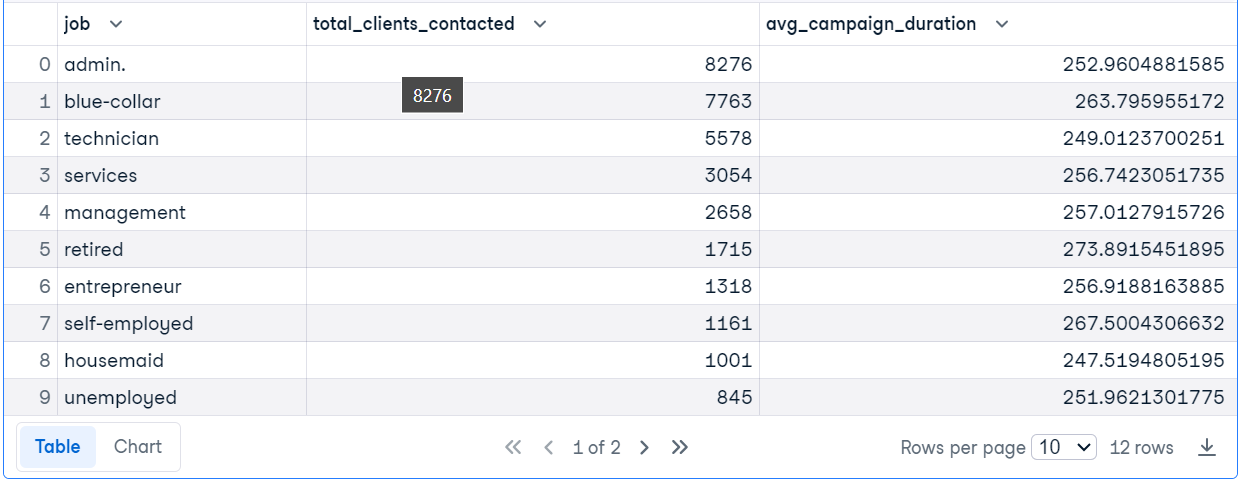
In the code example, we are running the SQL query to find out the job titles of clients over the age of 30, count the number of clients contacted for each job, and calculate the average duration of the campaign.
Take the SQL Fundamentals skill track to learn how to manage a relational database and execute queries for simple data analysis.
res = duckdb.query("""SELECT
job,
COUNT(*) AS total_clients_contacted,
AVG(duration) AS avg_campaign_duration,
FROM
'bank-marketing.csv'
WHERE
age > 30
GROUP BY
job
ORDER BY
total_clients_contacted DESC;""")
res.df()
We will now close the connection to the database and release any resources associated with that connection, preventing potential memory and file handle leaks.
con.close()If you are facing issues running the above code, please have a look at the Getting Started with DuckDB workspace.
In the first project, we will learn to build an RAG application with LlamaIndex and use DuckDB as a Vector database and retriever.
Install all the necessary Python packages that will be used to create and retrieve the index.
%%capture
%pip install duckdb
%pip install llama-index
%pip install llama-index-vector-stores-duckdbImport the necessary Python package with the functions.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.duckdb import DuckDBVectorStore
from llama_index.core import StorageContext
from IPython.display import Markdown, displayFor a language model, we will use the latest GPT4o model and the OpenAI API. To create the large language model (LLM) client, you just have to provide a model name and API key.
import os
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4o",api_key=os.environ["OPENAI_API_KEY"])Then, we will create the embed model client using the OpenAI text-embedding-3-small model.
Note: Providing an OpenAI API key is optional if the environment variable is set with the name “OPENAI_API_KEY” on your development environment.
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(
model="text-embedding-3-small",
)We will make OpenAI LLM and Embedding models global for all LlamaIndex functions to use. In short, these models will be set as default.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_modelFor our project, we will load the PDF files from the data folder. These PDF files are tutorials from DataCamp that are saved as PDF files using the browser’s print function.
Provide the folder directory to the SimpleDirectoryReader function and load the data.
documents = SimpleDirectoryReader("Data").load_data()
Then, create the vector store called “blog” using an existing database called “datacamp.duckdb.” After that, convert the PDF's data into embeddings and store them in the vector store.
vector_store = DuckDBVectorStore(database_name = "datacamp.duckdb",table_name = "blog",persist_dir="./", embed_dim=1536)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)To check if our vector store was successfully created, we will connect the database using the DuckDB Python API and run the SQL query to display all the tables in the database.
import duckdb
con = duckdb.connect("datacamp.duckdb")
con.execute("SHOW ALL TABLES").fetchdf()We have two tables: a “bank” promotional table and a “blog” table, which is a vector store. The “blog” table has an “embedding” column where all the embeddings are stored.
Convert the index into the query engine, which will automatically first search the vector database for similar documents and use the additional context to generate the response.
To test the RAG query engine, we will ask the question about the tutorial.
query_engine = index.as_query_engine()
response = query_engine.query("Who wrote 'GitHub Actions and MakeFile: A Hands-on Introduction'?")
display(Markdown(f"<b>{response}</b>"))And the answer is correct.
The author of "GitHub Actions and MakeFile: A Hands-on Introduction" is Abid Ali Awan.Now, let’s create an advanced RAG application that uses the conversation history to generate the response. For that, we have to create a chat memory buffer and then a chat engine with memory, LLM, and vector store retriever.
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.chat_engine import CondensePlusContextChatEngine
memory = ChatMemoryBuffer.from_defaults(token_limit=3900)
chat_engine = CondensePlusContextChatEngine.from_defaults(
index.as_retriever(),
memory=memory,
llm=llm
)
response = chat_engine.chat(
"What is the easiest way of finetuning the Llama 3 model? Please provide step-by-step instructions."
)
display(Markdown(response.response))We asked the chat engine how to fine-tune the Llama 3 model, and it used the vector store to give a highly accurate answer.

To check if the memory buffer is working correctly, we will ask a follow-up question.
response = chat_engine.chat(
"Could you please provide more details about the Post Fine-Tuning Steps?"
)
display(Markdown(response.response))The chat engine remembered the previous conversation and responded accordingly.

If you are facing issues running the above code, please have a look at the Building a RAG application with DuckDB workspace.
In the second project, we will use DuckDB as an SQL query engine. This involves integrating the database engine with the GPT-4o model to generate natural language responses to questions about the database.
Install duckdb-engine to create a database engine using SQLAlchemy.
%pip install duckdb-engine -qWe will load the DuckDB database using the create_engine function and then write a simple SQL query to check whether it is successfully loaded.
from sqlalchemy import create_engine
engine = create_engine("duckdb:///datacamp.duckdb")
with engine.connect() as connection:
cursor = connection.exec_driver_sql("SELECT * FROM bank LIMIT 3")
print(cursor.fetchall())Prefect. Our DuckDB database engine is ready to be used.
[(56, 'housemaid', 'married', 'basic.4y', 'no', 'no', 'no', 'telephone', 'may', 'mon', 261, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (57, 'services', 'married', 'high.school', 'unknown', 'no', 'no', 'telephone', 'may', 'mon', 149, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no'), (37, 'services', 'married', 'high.school', 'no', 'yes', 'no', 'telephone', 'may', 'mon', 226, 1, 999, 0, 'nonexistent', 1.1, 93.994, -36.4, 4.857, 5191.0, 'no')]Now, we have to create a database Tool using the SQLDatabase function. Provide it with an engine object and table name.
from llama_index.core import SQLDatabase
sql_database = SQLDatabase(engine, include_tables=["bank"])Create the SQL query engine using the NLSQLTableQueryEngine function by providing it with the LlamaIndex SQL database object.
from llama_index.core.query_engine import NLSQLTableQueryEngine
query_engine = NLSQLTableQueryEngine(sql_database)Ask the question from the query engine about the “bank” table in the natural language.
response = query_engine.query("Which is the longest running campaign?")
print(response.response)In response, we will get the answer to your query in natural languages. This is awesome, don't you think?
The longest running campaign in the database has a duration of 4918 days.Let's ask a complex question.
response = query_engine.query("Which type of job has the most housing loan?")
print(response.response)The answer is precise, with additional information.
The job type with the most housing loans is 'admin.' with 5559 housing loans. This is followed by 'blue-collar' with 4710 housing loans and 'technician' with 3616 housing loans. Other job types with significant housing loans include 'services', 'management', 'retired', 'entrepreneur', and 'self-employed'.To check what is going on on the back end, we will print the metadata.
print(response.metadata)As we can see, GPT-4o first generates the SQL query, runs the query to get the result, and uses the result to generate the response. This multi-step process is achieved through two lines of code.
{'d4ddf03c-337e-4ee6-957a-5fd2cfaa4b1c': {}, 'sql_query': "SELECT job, COUNT(housing) AS housing_loan_count\nFROM bank\nWHERE housing = 'yes'\nGROUP BY job\nORDER BY housing_loan_count DESC;", 'result': [('admin.', 5559), ('blue-collar', 4710), ('technician', 3616), ('services', 2050), ('management', 1490), ('retired', 892), ('entrepreneur', 779), ('self-employed', 740), ('unemployed', 557), ('housemaid', 540), ('student', 471), ('unknown', 172)], 'col_keys': ['job', 'housing_loan_count']}Close the engine when you are done with the project.
engine.close()If you are facing issues running the above code, please have a look at the DuckDB SQL Query Engine workspace.
DuckDB is fast, easy to use, and integrates seamlessly with numerous data and AI frameworks. As a data scientist, you will find that it takes only a few minutes to get accustomed to its API and start using it like any other Python package. One of the best features of DuckDB is that it has no dependencies, meaning you can use it virtually anywhere without worrying about hosting or additional setup.
In this tutorial, we have learned about DuckDB and its key features. We have also explored the DuckDB Python API, using it to create a table and perform simple data analysis. The second half of the tutorial covered two projects: one involving a Retrieval-Augmented Generation (RAG) application with DuckDB as a vector database and the other demonstrating DuckDB as an SQL query engine.
Before jumping into using a SQL query engine or integrating a database with AI, you need a basic understanding of SQL and data analysis. You can write the query, but how would you know what question to ask? This is where a basic knowledge of data analysis and SQL comes in. You can gain this knowledge by completing the Associate Data Analyst in SQL career track.
Top DataCamp Courses
Cours
Cours
Cours
blog
Kurtis Pykes
7 min
blog
Filip Schouwenaars
Tutoriel
Arunn Thevapalan
Tutoriel
Dr Ana Rojo-Echeburúa
Tutoriel
Bex Tuychiev
Tutoriel
Laiba Siddiqui




