
Curso
Understanding Machine Learning
2 h
293.4K
La Integración Continua (IC) y el Despliegue Continuo (DC) son prácticas utilizadas habitualmente en el desarrollo de software para automatizar el proceso de integrar los cambios de código, probarlos y desplegar rápidamente la aplicación actualizada. Inicialmente, estas prácticas se desarrollaron para las aplicaciones de software tradicionales, pero ahora son cada vez más relevantes también en los proyectos de aprendizaje automático (AM).
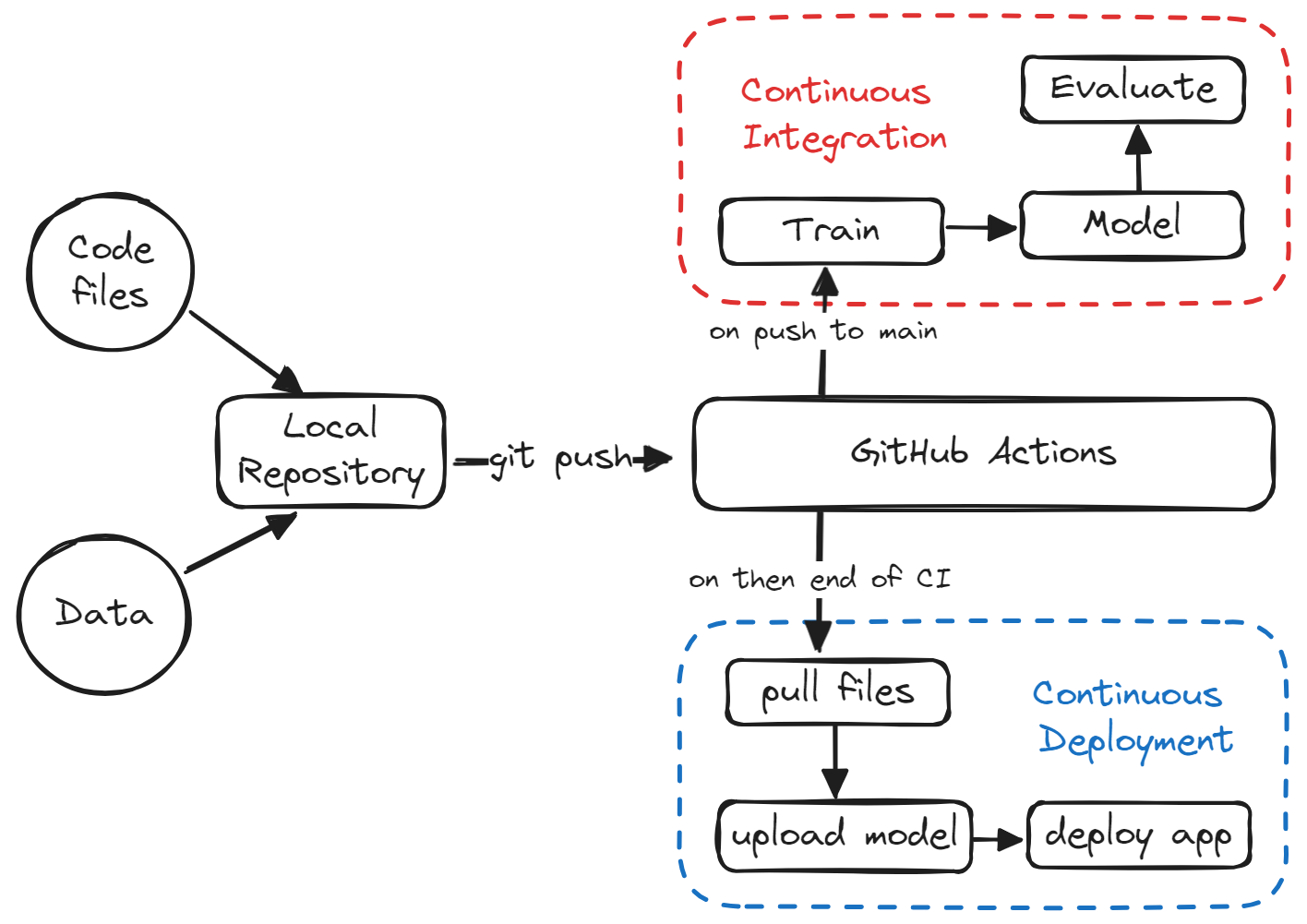
En esta completa guía, echaremos un vistazo a CI/CD para ML y aprenderemos a construir nuestro propio pipeline de aprendizaje automático que automatizará el proceso de entrenamiento, evaluación y despliegue del modelo.
Esta guía presenta un proyecto sencillo que sólo utiliza acciones de GitHub para automatizar todo el proceso. La mayoría de las cosas que discutiremos son bien conocidas por los ingenieros de aprendizaje automático y los científicos de datos. Lo único que aprenderán aquí es a utilizar GitHub Actions, Makefile, CML y Hugging Face CLI.
Inscríbete en el curso Conceptos de MLOps para aprender a llevar los modelos de aprendizaje automático de los cuadernos locales a modelos de producción que generen valor empresarial.
CI/CD cambia las reglas del juego cuando se trata de hacer operativo tu modelo y utilizarlo para desarrollar un producto. Racionalizar el proceso de automatización proporciona una solución sin errores, rápida y escalable para tu proyecto de ML, lo que te permite centrarte en mejorar el modelo en lugar de gestionar y desplegar la solución.
En concreto, el CI/CD para el aprendizaje automático ayuda en lo siguiente:
Con CI/CD, puedes reentrenar automáticamente tus modelos con nuevos datos de forma regular, ahorrando tiempo en comparación con el reentrenamiento manual.
Las herramientas de CI ejecutan pruebas y comprobaciones para cada confirmación de código, lo que ayuda a detectar errores, problemas de integración y disminuciones en el rendimiento del modelo.
CI/CD ayuda a garantizar que los modelos se puedan reconstruir y volver a entrenar exactamente de la misma manera, permitiendo la reproducibilidad de los resultados. Se codifican los entornos, las versiones de modelos y datos, y las configuraciones.
CI/CD permite realizar pruebas automatizadas de los nuevos modelos antes de su despliegue para comprobar si hay problemas. También permite una mejor supervisión de los modelos después de su despliegue mediante la integración con herramientas de supervisión.
Las nuevas versiones de modelos o experimentos pueden entrenarse, probarse y desplegarse rápidamente de forma automatizada con CI/CD. Acelera el desarrollo y la mejora de los sistemas de ML.
A medida que el proyecto de ML crece en tamaño y complejidad, gestionar manualmente todo el ciclo de vida resulta poco práctico. Los pipelines CI/CD proporcionan una solución escalable que puede manejar grandes volúmenes de datos, numerosos modelos y diversas dependencias, manteniendo la eficiencia y la fiabilidad.
En esta guía, te guiaremos a través del proceso de configuración de cuentas y entornos, la creación de una canalización CI/CD y la optimización de todo el proceso.
Utilizaremos pipelines de scikit-learn para entrenar nuestro algoritmo de bosque aleatorio y construir un clasificador de fármacos. Tras el entrenamiento, automatizaremos el proceso de evaluación utilizando CML. Por último, construiremos y desplegaremos la aplicación web en Hugging Face Hub.
Desde la formación hasta la evaluación, todo el proceso se automatizará utilizando acciones de GitHub. Todo lo que tienes que hacer es enviar el código a tu repositorio de GitHub y, en dos minutos, el modelo se actualizará en Hugging Face con la aplicación, el modelo y los resultados actualizados.
Si quieres aprender más utilizando ejercicios interactivos, prueba a seguir el curso CI/CD para Aprendizaje Automático de DataCamp para elevar tu desarrollo de aprendizaje automático con Acciones de GitHub y Control de Versiones de Datos.
En esta sección, crearemos un repositorio de GitHub, los archivos y carpetas necesarios y un Espacio en Cara de Abrazo.
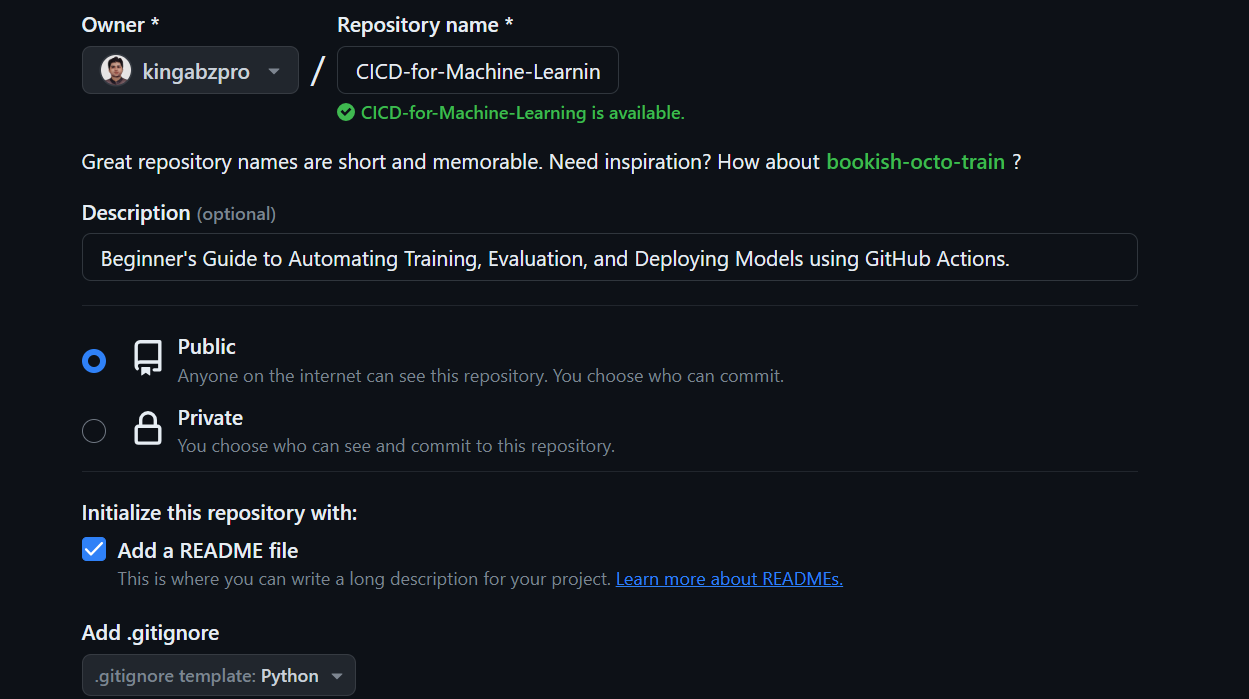
Haz clic en el botón "+" de la parte superior derecha de la página principal de GitHub y selecciona "Nuevo repositorio".
Añade el nombre y la descripción del repositorio, comprueba el archivo README y establece .gitignore como Python.
Después de crear el repositorio, tenemos que copiar su URL. A continuación, abre el terminal o bash y navega hasta el directorio donde queremos guardar la carpeta del proyecto.
Por último, clona el repositorio ejecutando el siguiente comando:
git clone https://github.com/kingabzpro/CICD-for-Machine-Learning.gitPara empezar, utiliza tu IDE preferido para abrir el repositorio local. Recomendamos utilizar VSCode para este proyecto. Una vez que inicies tu IDE, verás un espacio de trabajo VSCode que contiene archivos como README y LICENSE.
Vamos a crear un Espacio Cara Abrazada que utilizaremos para desplegar nuestra aplicación con el archivo modelo.
1. Haz clic en la imagen de tu pantalla y selecciona "Nuevo espacio".
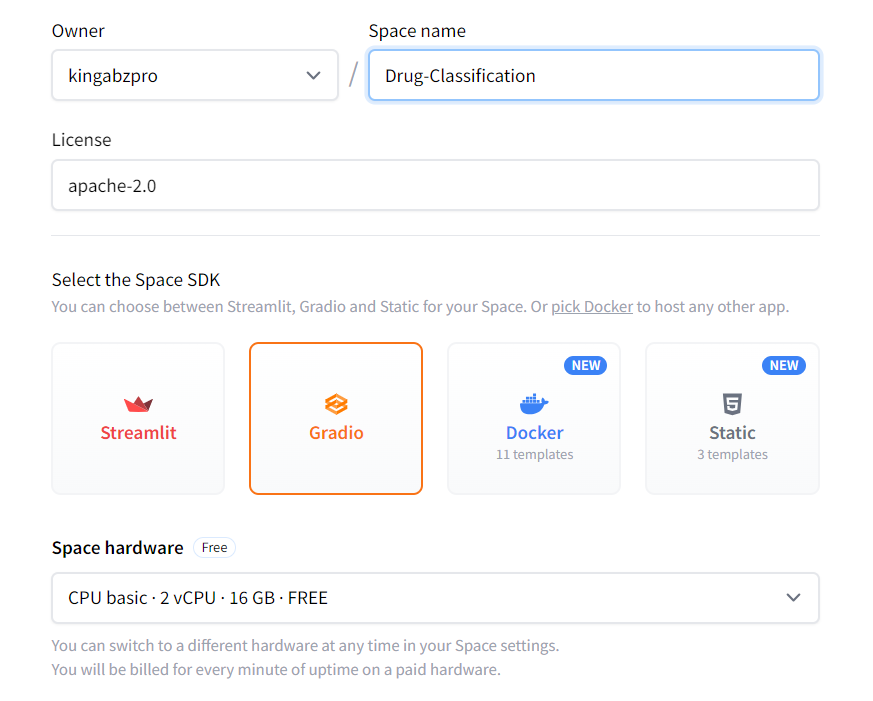
2. Añade el nombre del Espacio, la Licencia, el tipo de SDK y Crear Espacio.
3. Para editar el archivo README.md, haz clic en los tres puntos de la parte superior izquierda, selecciona Archivos y realiza los cambios necesarios.
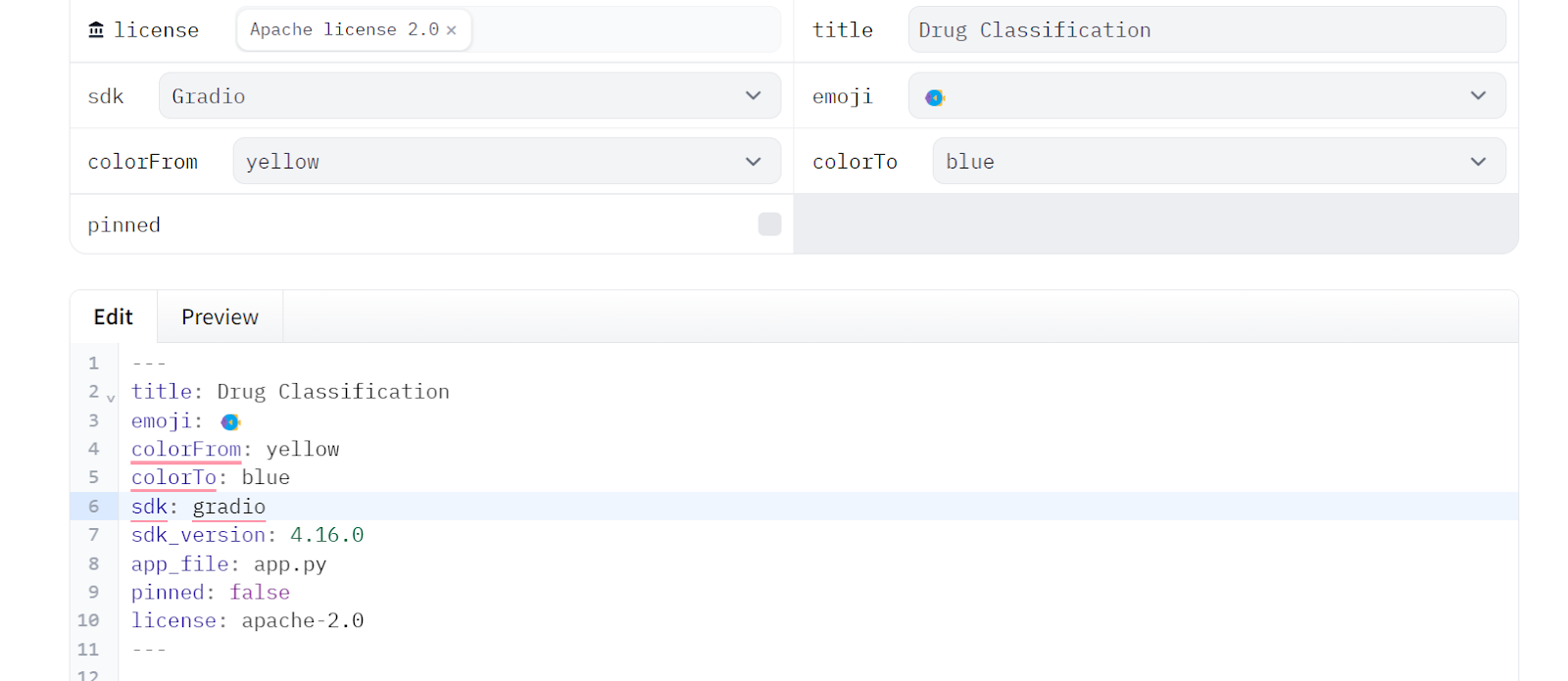
4. Copiaremos los metadatos del archivo README del Espacio y los pegaremos en nuestro archivo README local que permanecerá en la carpeta App.
Tenemos que crear la carpeta y el archivo necesarios antes de empezar a experimentar y construir canalizaciones. Esto nos ayudará a largo plazo a mantener limpio el espacio de trabajo.
Crea un archivo Python llamado drug_app.py, junto con un archivo README.md y un archivo requirements.txt, y mueve todos estos archivos a la carpeta App. Esto nos ayudará a organizar mejor todos los archivos necesarios para ejecutar la aplicación.
A continuación, edita el archivo README.md de la carpeta App y asegúrate de que todas las versiones de los metadatos se han modificado en consecuencia. Esto te permitirá señalar fácilmente la ubicación de los archivos de la aplicación, cambiar los colores, establecer la versión del SDK y añadir información sobre licencias.
---
title: Drug Classification
emoji: 💊
colorFrom: yellow
colorTo: red
sdk: gradio
sdk_version: 4.16.0
app_file: drug_app.py
pinned: false
license: apache-2.0
---Edita el archivo requirement.txt de la carpeta App proporcionando los paquetes de Python que faltan:
scikit-learn
skopsNota: los archivos de requisitos y LÉAME serán diferentes para el repositorio de GitHub y para Hugging Face Space.
Descarga el conjunto de datos de Clasificación de fármacos de Kaggle, extrae el archivo CSV y muévelo a la carpeta Datos.
Tanto la carpeta Modelo como la de Resultados permanecerán vacías, ya que serán rellenadas por el script de Python que ejecutemos.
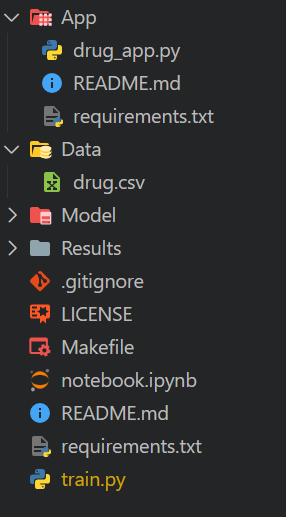
Makefile para simplificar la ejecución del script en GitHub Action workflow.notebook.ipynb. En este cuaderno, experimentaremos con nuestros algoritmos y cadenas de procesamiento.requirements.txt. Se utilizará para configurar el entorno mientras se ejecutan los trabajos del flujo de trabajo CI.train.py. Contendrá código Python para cargar y procesar datos, así como para entrenar, evaluar y guardar el modelo y las métricas de rendimiento.Este es el aspecto que debería tener nuestro directorio:
En esta parte, experimentaremos con la creación de código Python que procese datos y entrene un modelo utilizando un pipeline de scikit-learn. Después lo evaluaremos y guardaremos los resultados y el modelo.
Utilizaremos pandas para cargar nuestro archivo CSV, mezclarlo mediante la función sample y mostrar las tres filas superiores.
import pandas as pd
drug_df = pd.read_csv("Data/drug.csv")
drug_df = drug_df.sample(frac=1)
drug_df.head(3)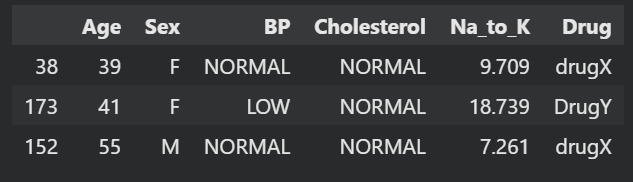
Crea una variable dependiente y una variable independiente. A continuación, divídelos en conjuntos de entrenamiento y de prueba. Esto te ayudará a evaluar el rendimiento de tu modelo.
from sklearn.model_selection import train_test_split
X = drug_df.drop("Drug", axis=1).values
y = drug_df.Drug.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Construiremos una cadena de procesamiento utilizando ColumnTransformer, que convertirá los valores categóricos en números, rellenará los valores que falten y escalará las columnas numéricas.
Después, crearemos un canal de entrenamiento que tomará los datos transformados y entrenará un clasificador de bosque aleatorio.
Por último, entrenaremos el modelo.
Utilizando canalizaciones, podemos garantizar la reproducibilidad, la modularidad y la claridad de nuestro código.
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OrdinalEncoder, StandardScaler
cat_col = [1,2,3]
num_col = [0,4]
transform = ColumnTransformer(
[
("encoder", OrdinalEncoder(), cat_col),
("num_imputer", SimpleImputer(strategy="median"), num_col),
("num_scaler", StandardScaler(), num_col),
]
)
pipe = Pipeline(
steps=[
("preprocessing", transform),
("model", RandomForestClassifier(n_estimators=100, random_state=125)),
]
)
pipe.fit(X_train, y_train)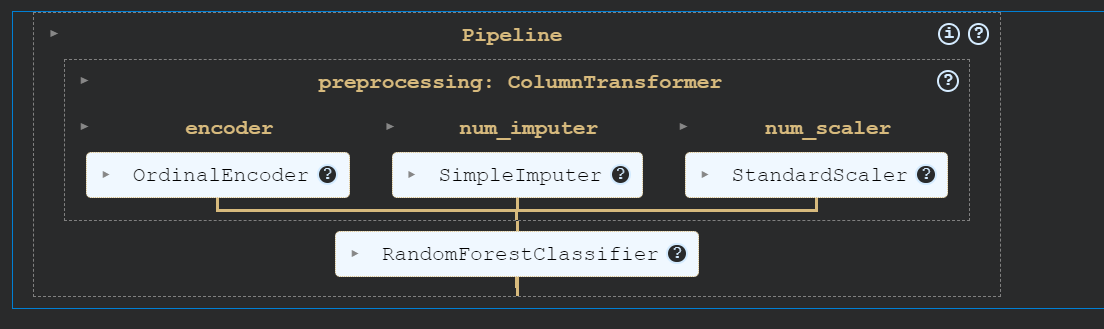
Evalúa el rendimiento del modelo calculando tanto la precisión como la puntuación F1.
from sklearn.metrics import accuracy_score, f1_score
predictions = pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))Nuestro modelo ha funcionado excepcionalmente bien.
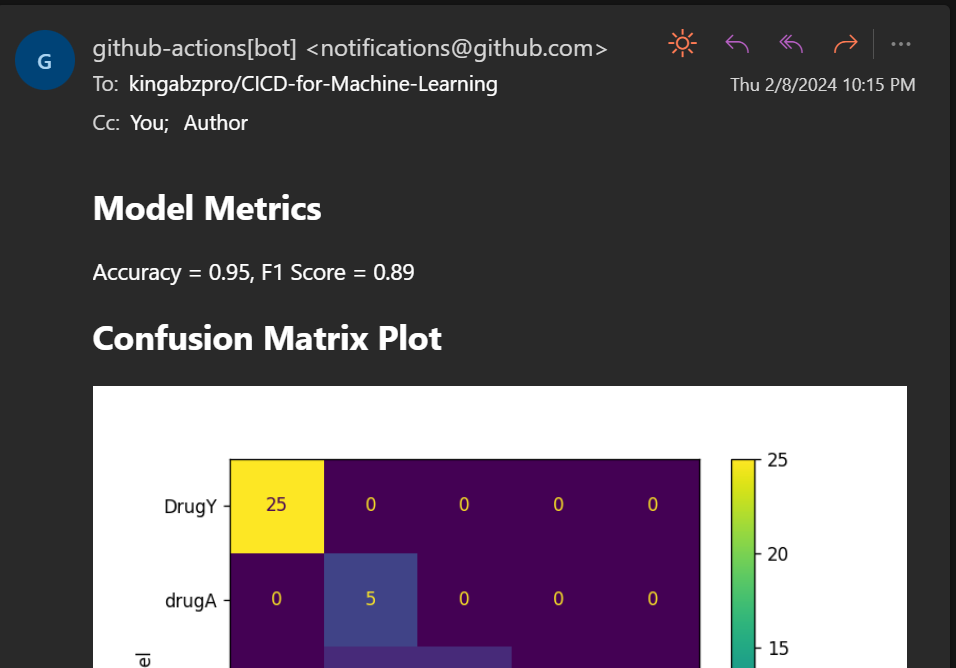
Accuracy: 95.0% F1: 0.91Crea el archivo de métricas y guárdalo en la carpeta Resultados.
with open("Results/metrics.txt", "w") as outfile:
outfile.write(f"\nAccuracy = {accuracy.round(2)}, F1 Score = {f1.round(2)}.")A continuación, crearemos la matriz de confusión y guardaremos el archivo de imagen en la carpeta Resultados.
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
cm = confusion_matrix(y_test, predictions, labels=pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=pipe.classes_)
disp.plot()
plt.savefig("Results/model_results.png", dpi=120)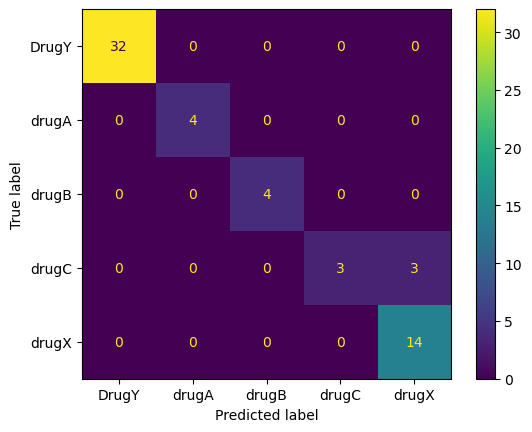
Ahora guardaremos nuestro modelo utilizando el paquete skops de Python. Esto nos ayudará a guardar tanto el pipeline de scikit-learn como el modelo.
import skops.io as sio
sio.dump(pipe, "Model/drug_pipeline.skops")Puedes cargar todo el canal y funcionará sin necesidad de procesar los datos ni modificar el código.
sio.load("Model/drug_pipeline.skops", trusted=True)
Copia y pega todo el código en el archivo 'train.py'. Éste será el script de entrenamiento estandarizado que se ejecutará en el flujo de trabajo CI siempre que haya un cambio en los datos o en el código.
Antes de iniciar tu carrera de ingeniero MLOps, lee la hoja de ruta MLOps Roadmap: Guía profesional completa.
En esta sección, cubriremos CML, Makefile y la configuración de los flujos de trabajo de GitHub Action para automatizar la formación, la evaluación y el versionado de nuestro proyecto.
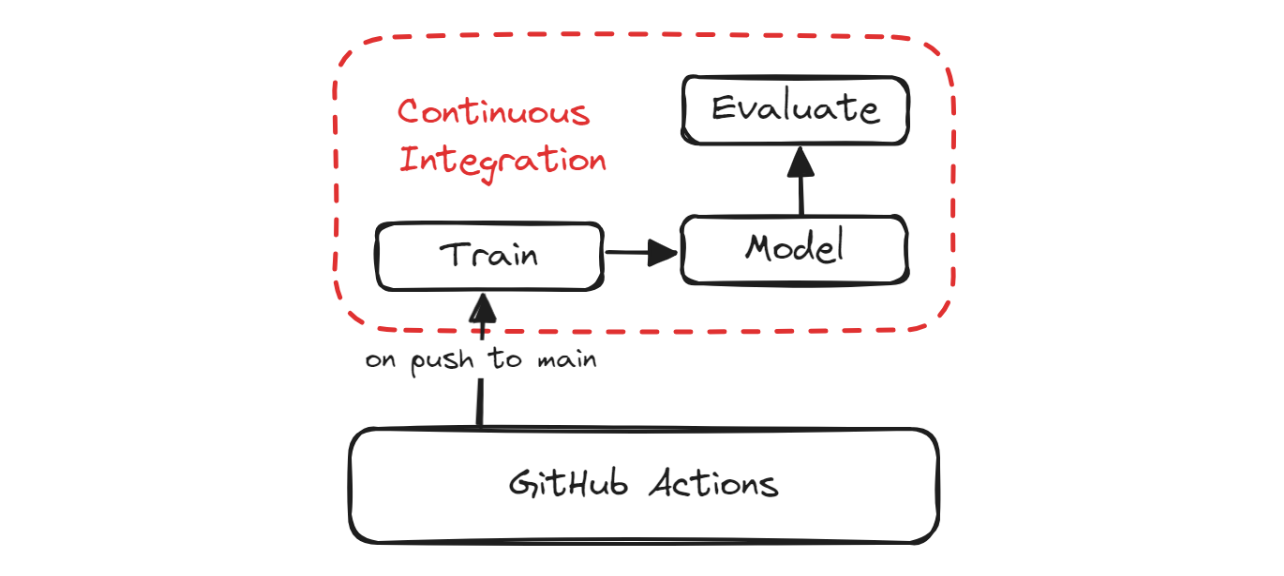
CI Pipeline
El Aprendizaje Automático Continuo(AMC) es una biblioteca de código abierto que te permite implementar la integración continua en tus proyectos de aprendizaje automático. Utilizaremos la Acción GitHub "iterative/setup-cml" que utiliza funciones CML en el flujo de trabajo para automatizar la generación del informe de evaluación del modelo.
¿Qué significa esto? Cada vez que envíes cambios a GitHub, generará un informe bajo la confirmación y te enviará un correo electrónico con métricas de rendimiento y una matriz de confusión.
Un Makefile es un archivo que consiste en un conjunto de instrucciones utilizadas por el comando make para automatizar diversas tareas, como compilar código, ejecutar pruebas, configurar entornos, preprocesar datos, entrenar y evaluar modelos, y desplegar modelos.
Podemos utilizar los comandos make para ejecutar varios scripts y hacer que el archivo de flujo de trabajo CI sea limpio y sencillo. El Makefile contiene el nombre del conjunto de comandos y el script para ejecutar esos comandos.
Aquí está nuestro Makefile:
install:
pip install --upgrade pip &&\
pip install -r requirements.txt
format:
black *.py
train:
python train.py
eval:
echo "## Model Metrics" > report.md
cat ./Results/metrics.txt >> report.md
echo '\n## Confusion Matrix Plot' >> report.md
echo '' >> report.md
cml comment create report.mdTenemos comandos para instalar paquetes Python (install), formatear código (format), entrenar scripts (train) y generar informes CML (eval).
Después, añadiremos los cambios, crearemos un commit y empujaremos los cambios al servidor remoto de GitHub.
git commit -am "new changes"
git push origin mainPara automatizar la formación y la evaluación, necesitamos crear un flujo de trabajo de acciones de GitHub. Para ello, ve a la pestaña "Acciones" de nuestro repositorio kingabzpro/CICD-for-Machine-Learning y haz clic en el texto azul "configura tú mismo un flujo de trabajo".
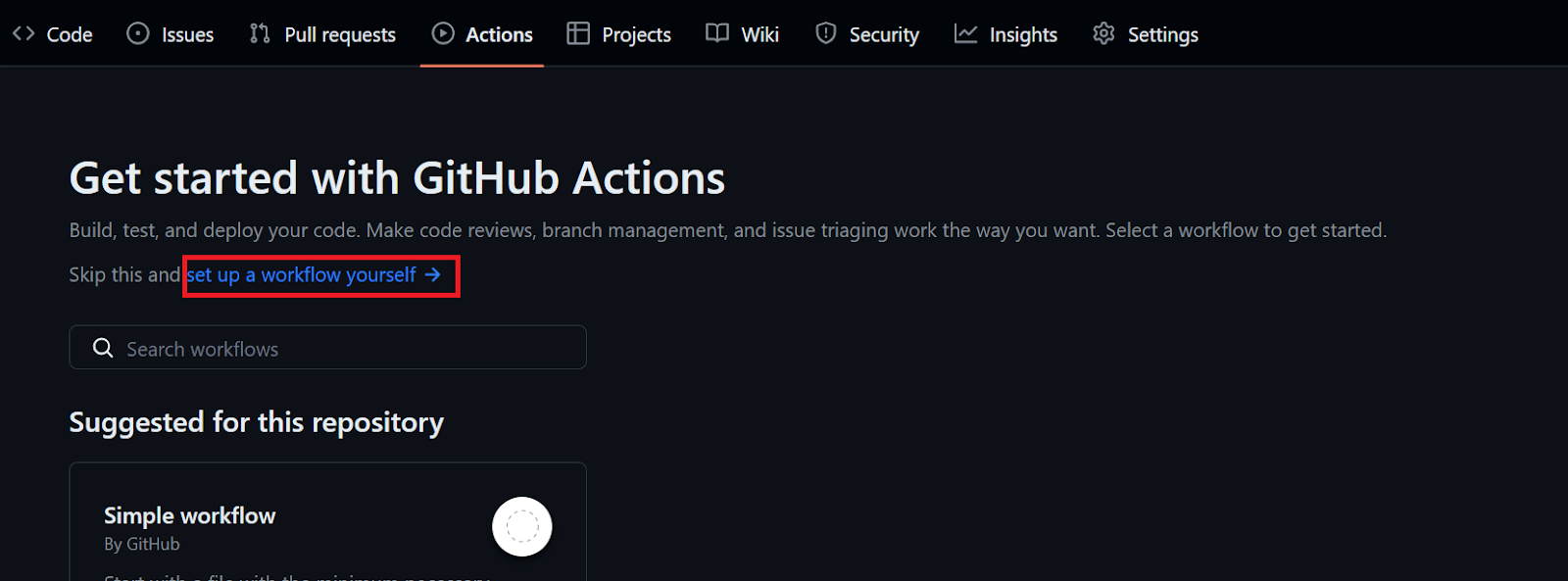
Cambia el nombre del archivo .yml por "ci" y empieza a añadir el comando de acción de GitHub.
Te encontrarás con fallos mientras averiguas los errores y la sintaxis, por eso es importante que leas la Sintaxis del flujo de trabajo para las acciones de GitHub antes de lanzarte a la acción de GitHub.
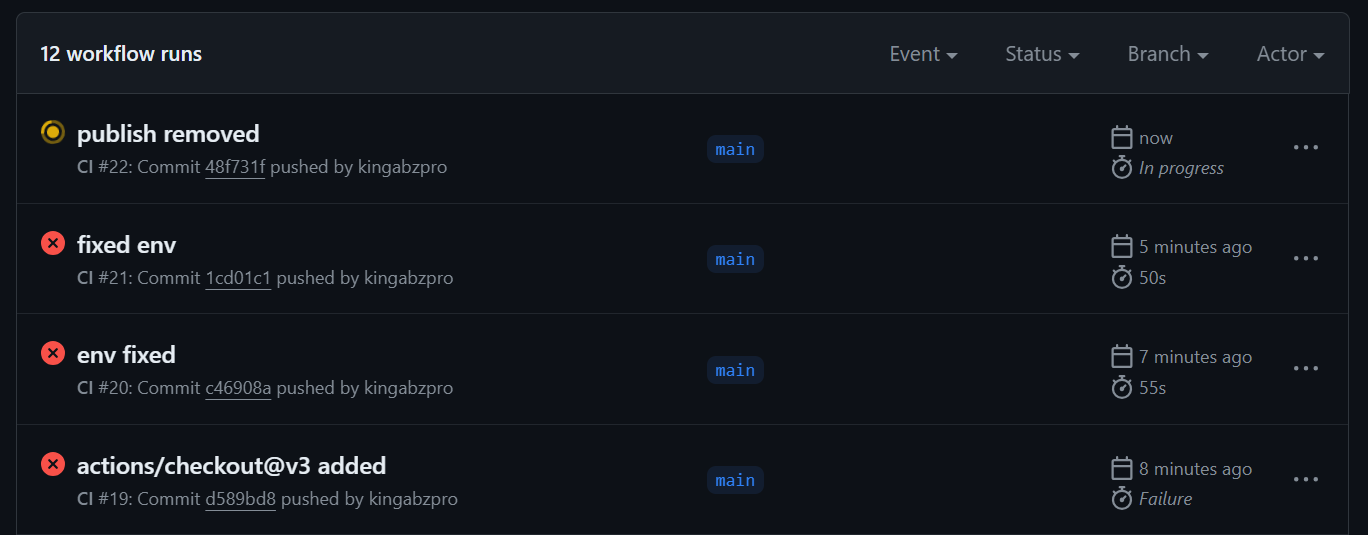
Hemos solucionado con éxito todos los errores y problemas del flujo de trabajo, y ahora tenemos la versión final del archivo `ci.yml` que funciona sin problemas.
Como puedes ver, el flujo de trabajo primero configurará el entorno y cargará las acciones necesarias. A continuación, ejecutamos cada paso uno a uno mediante el comando make, que invoca varios scripts Python y Bash en el backend.
Sin embargo, hay dos cosas importantes que debes tener en cuenta cuando trabajes con acciones de LMC. En primer lugar, tenemos que establecer el permiso de escritura al principio. En segundo lugar, proporciona un token de GitHub a un trabajo CML, al que podremos acceder utilizando los secretos.
name: Continuous Integration
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
workflow_dispatch:
permissions: write-all
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: iterative/setup-cml@v2
- name: Install Packages
run: make install
- name: Format
run: make format
- name: Train
run: make train
- name: Evaluation
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: make eval
Las métricas y los resultados se muestran bajo el mensaje de confirmación.
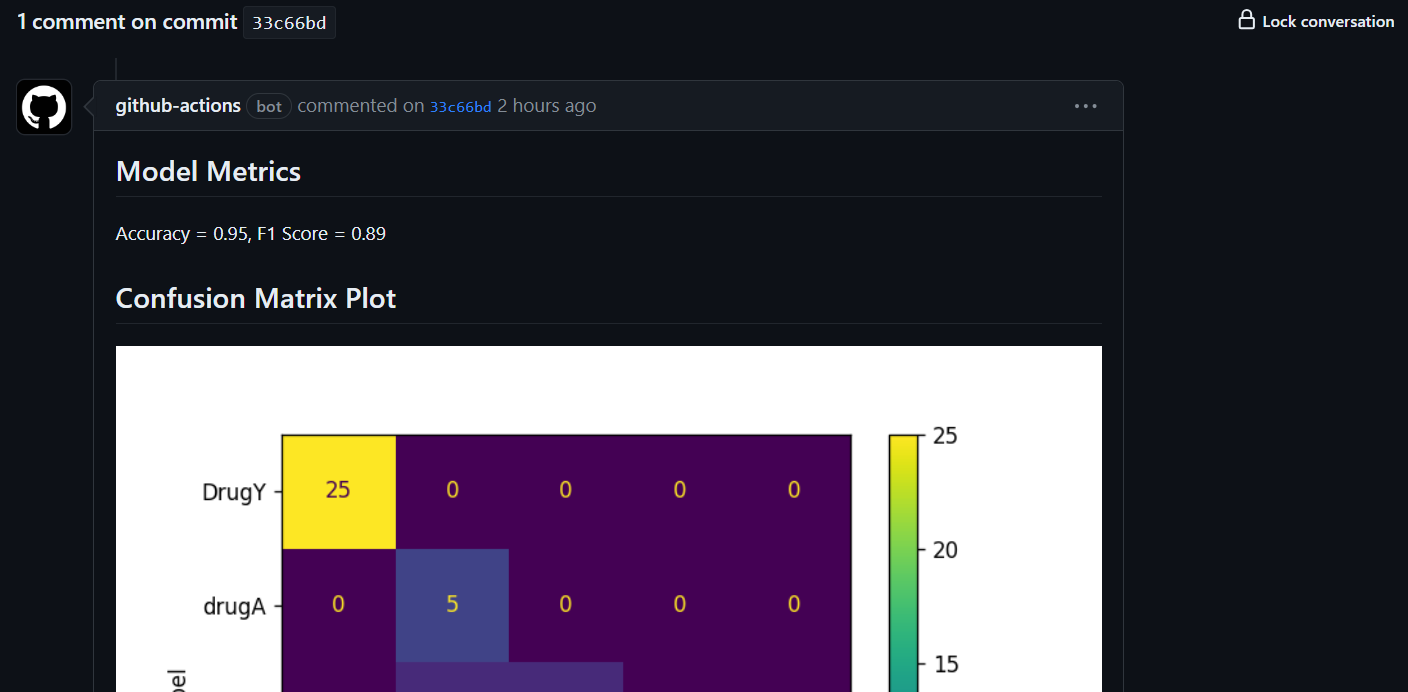
También te enviará el correo electrónico con los resultados.
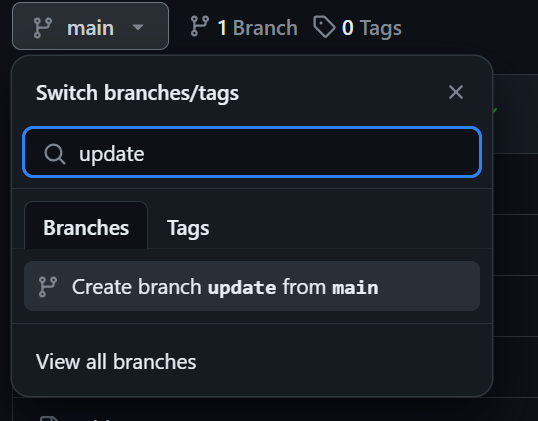
Estamos generando el informe de evaluación, pero no estamos versionando el modelo ni los resultados. Para guardar los cambios, crearemos una nueva rama llamada "actualización" y le enviaremos el modelo y los resultados actualizados.
Crea la rama "actualizar" haciendo clic en el botón de la rama principal, escribiendo "actualizar" como nombre de la rama y seleccionando "crear rama actualizar desde principal".
Para confirmar y enviar cambios mediante el comando Git, necesitamos proporcionar un nombre de usuario y un correo electrónico. Puedes añadirlos directamente, pero utilizar los secretos de GitHub es una mejor opción. Sigue estos pasos:
Eso es.

Para automatizar el guardado de los cambios en la nueva rama, tenemos que actualizar las páginas Makefile y ci.yml.
Makefile:
Estamos configurando el nombre de usuario y el correo electrónico, confirmando los cambios y guardándolos en la rama update.
update-branch:
git config --global user.name $(USER_NAME)
git config --global user.email $(USER_EMAIL)
git commit -am "Update with new results"
git push --force origin HEAD:update
ci.yml:
Makefile está utilizando una variable de entorno para ejecutar el script. Para ello, primero tenemos que extraer el valor de la variable de entorno de los secretos, y luego establecer la variable de entorno al final del comando make.
- name: Update Branch
env:
NAME: ${{ secrets.USER_NAME }}
EMAIL: ${{ secrets.USER_EMAIL }}
run: make update-branch USER_NAME=$NAME USER_EMAIL=$EMAIL
Una vez que hayas actualizado los archivos y enviado los cambios a la rama principal, podrás ver cómo se produce la magia en tiempo real. Se generará un informe analítico, junto con un modelo actualizado que podrá desplegarse en Cara de Abrazo en la parte de despliegue continuo.
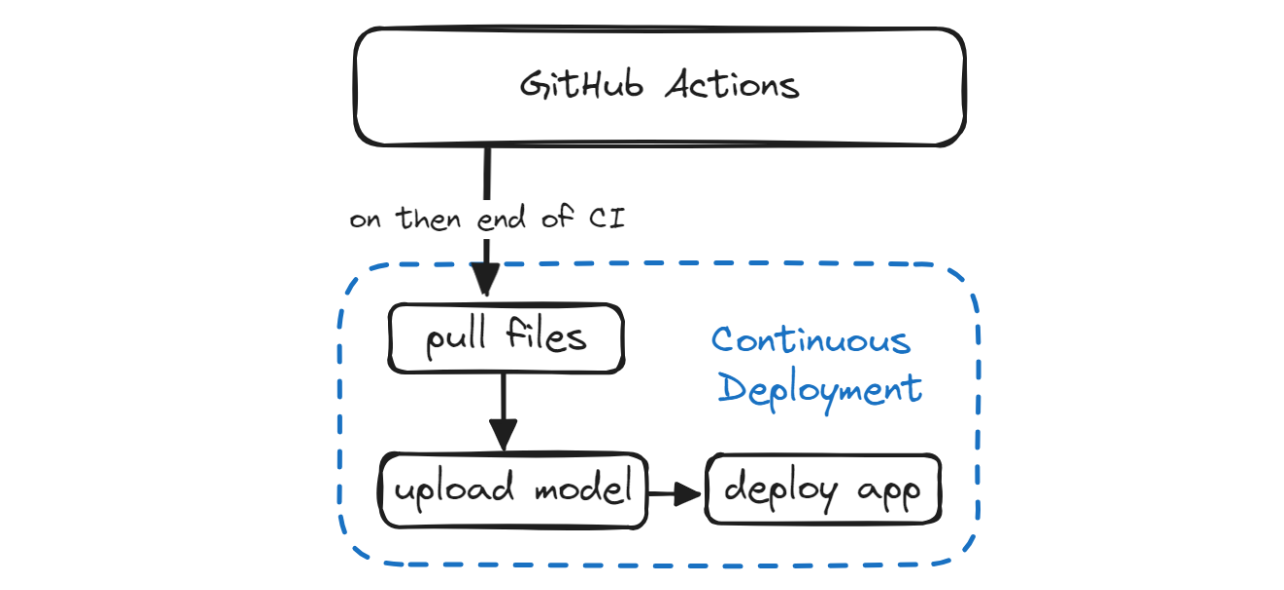
En la sección Despliegue continuo, descubriremos cómo automatizar el proceso de despliegue tanto del modelo como de la aplicación. Esto implica extraer el modelo actualizado y el archivo de la aplicación de la rama `update`, iniciar sesión en la CLI de Hugging Face utilizando un token, enviar los archivos del modelo y de la aplicación y, por último, desplegar la aplicación.
Para desplegar nuestro modelo y acceder a él, necesitamos crear una app Gradio. Esta aplicación incluirá:
Interface y la lanzaremos.import gradio as gr
import skops.io as sio
pipe = sio.load("./Model/drug_pipeline.skops", trusted=True)
def predict_drug(age, sex, blood_pressure, cholesterol, na_to_k_ratio):
""Predict drugs based on patient features.
Args:
age (int): Age of patient
sex (str): Sex of patient
blood_pressure (str): Blood pressure level
cholesterol (str): Cholesterol level
na_to_k_ratio (float): Ratio of sodium to potassium in blood
Returns:
str: Predicted drug label
"""
features = [age, sex, blood_pressure, cholesterol, na_to_k_ratio]
predicted_drug = pipe.predict([features])[0]
label = f"Predicted Drug: {predicted_drug}"
return label
inputs = [
gr.Slider(15, 74, step=1, label="Age"),
gr.Radio(["M", "F"], label="Sex"),
gr.Radio(["HIGH", "LOW", "NORMAL"], label="Blood Pressure"),
gr.Radio(["HIGH", "NORMAL"], label="Cholesterol"),
gr.Slider(6.2, 38.2, step=0.1, label="Na_to_K"),
]
outputs = [gr.Label(num_top_classes=5)]
examples = [
[30, "M", "HIGH", "NORMAL", 15.4],
[35, "F", "LOW", "NORMAL", 8],
[50, "M", "HIGH", "HIGH", 34],
]
title = "Drug Classification"
description = "Enter the details to correctly identify Drug type?"
article = "This app is a part of the Beginner's Guide to CI/CD for Machine Learning. It teaches how to automate training, evaluation, and deployment of models to Hugging Face using GitHub Actions."
gr.Interface(
fn=predict_drug,
inputs=inputs,
outputs=outputs,
examples=examples,
title=title,
description=description,
article=article,
theme=gr.themes.Soft(),
).launch()
Abre el terminal y ejecuta la aplicación localmente para solucionar los problemas antes de enviar los cambios al repositorio remoto.
python ./App/drug_app.py Running on local URL: http://127.0.0.1:7860
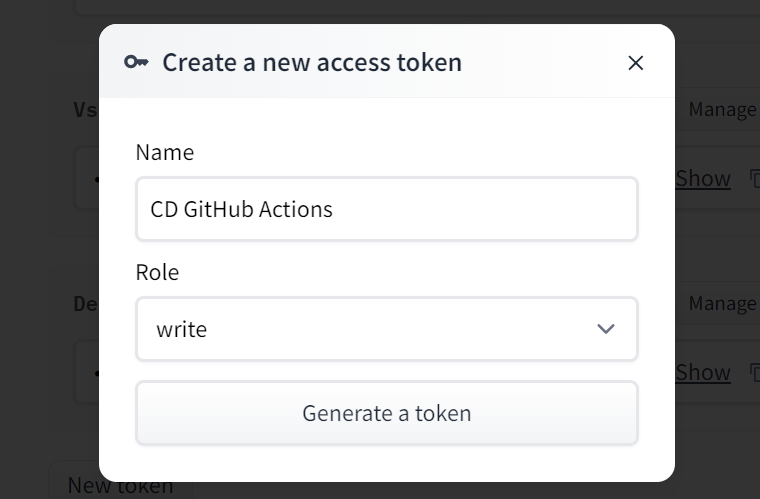
To create a public link, set `share=True` in `launch()`.Ahora generaremos el token Cara Abrazada y se lo proporcionaremos a nuestro script Makefile. Sin embargo, debemos asegurarnos de que el token se mantenga confidencial y no se filtre a nadie. Para ello, utilizaremos los secretos de GitHub.
En primer lugar, haz clic en tu foto de perfil de Cara de abrazo y selecciona la opción de configuración. A continuación, elige la opción "Tokens de acceso" y haz clic en el botón "Nuevo Token" para generar el token. Al generar el token, asegúrate de que tiene permiso de escritura.
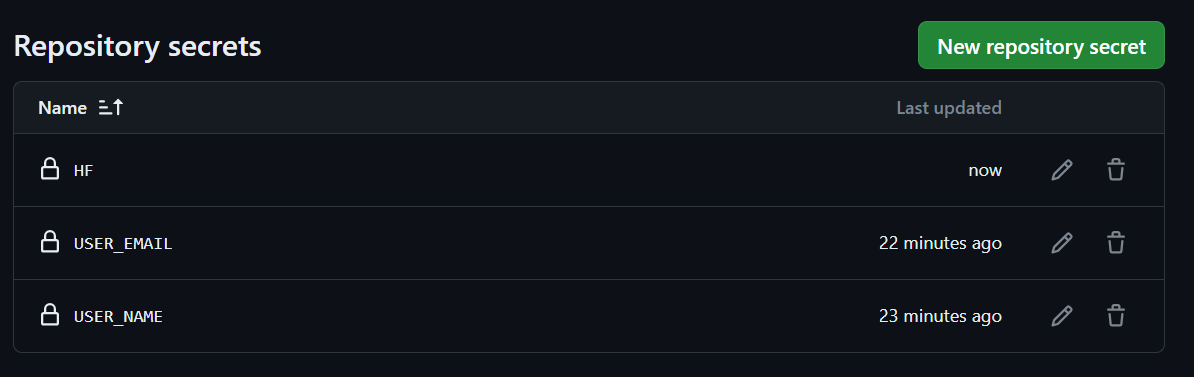
Copia el token y crea un secreto de Repositorio, igual que hicimos con los nombres de usuario y el correo electrónico.
En esta sección, añadiremos tres nuevos comandos para crear archivos y crearemos otro flujo de trabajo de GitHub llamado "Despliegue Continuo". Este flujo de trabajo te ayudará a automatizar el proceso de extracción y despliegue de archivos.
update y cambia a la rama update.deploy ejecutará primero hf-login y después push-hub.hf-login:
git pull origin update
git switch update
pip install -U "huggingface_hub[cli]"
huggingface-cli login --token $(HF) --add-to-git-credential
push-hub:
huggingface-cli upload kingabzpro/Drug-Classification ./App --repo-type=space --commit-message="Sync App files"
huggingface-cli upload kingabzpro/Drug-Classification ./Model /Model --repo-type=space --commit-message="Sync Model"
huggingface-cli upload kingabzpro/Drug-Classification ./Results /Metrics --repo-type=space --commit-message="Sync Model"
deploy: hf-login push-hubNuestra aplicación tendrá acceso a un modelo actualizado, a un archivo de aplicación y a los resultados, lo que nos permitirá seguir los cambios en el espacio de Cara Abrazada.
Para que nuestro flujo de trabajo sea realmente CI/CD, necesitamos crear otro archivo llamado cd.yml similar a nuestro archivo ci.yml . Una vez que se haya completado la canalización CI, iniciará el flujo de trabajo cd.yml utilizando el argumento on con el parámetro workflow_run.
Este flujo de trabajo creará el entorno y ejecutará el comando make deploy utilizando el token de Hugging Face para desplegar los últimos cambios en el Hub de Hugging Face.
name: Continuous Deployment
on:
workflow_run:
workflows: ["Continuous Integration"]
types:
- completed
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Deployment To Hugging Face
env:
HF: ${{ secrets.HF }}
run: make deploy HF=$HFCuando empujemos los cambios a la rama principal, se iniciará con el flujo de trabajo CI.
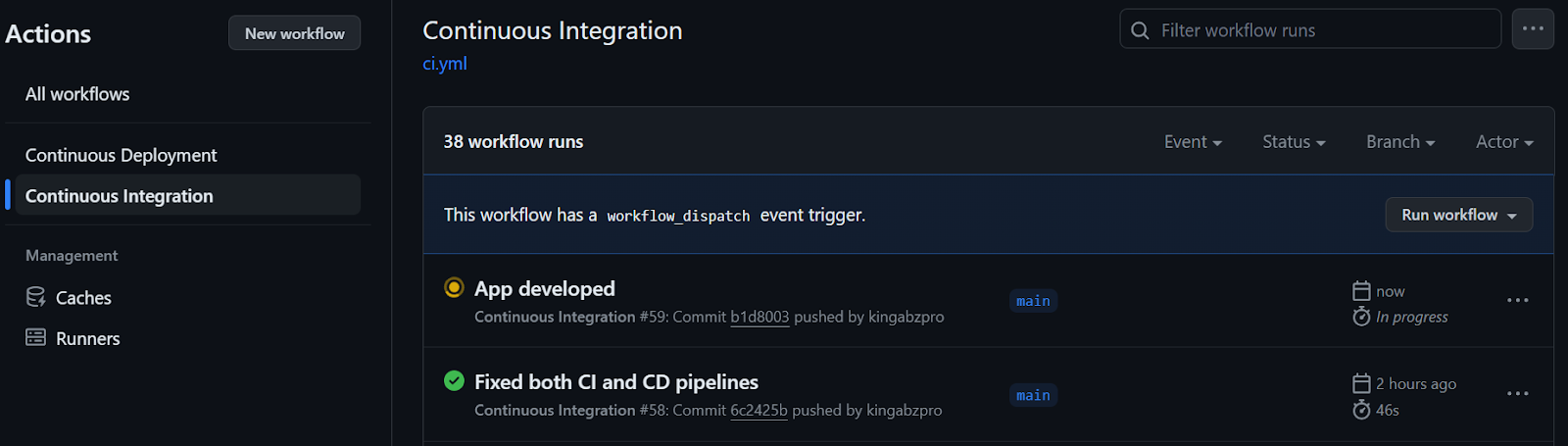
Una vez completado el flujo de trabajo CI, comenzará el flujo de trabajo CD, como se muestra a continuación.
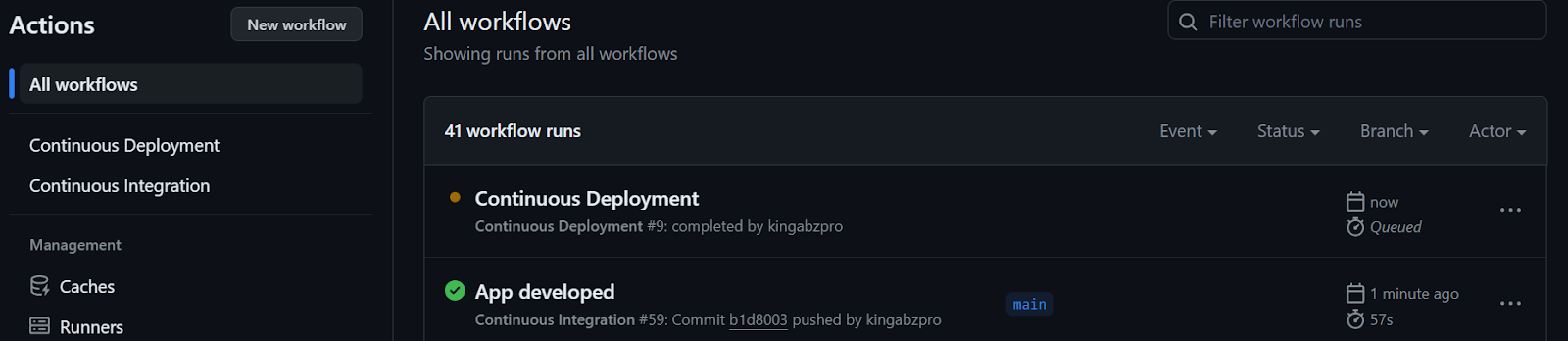
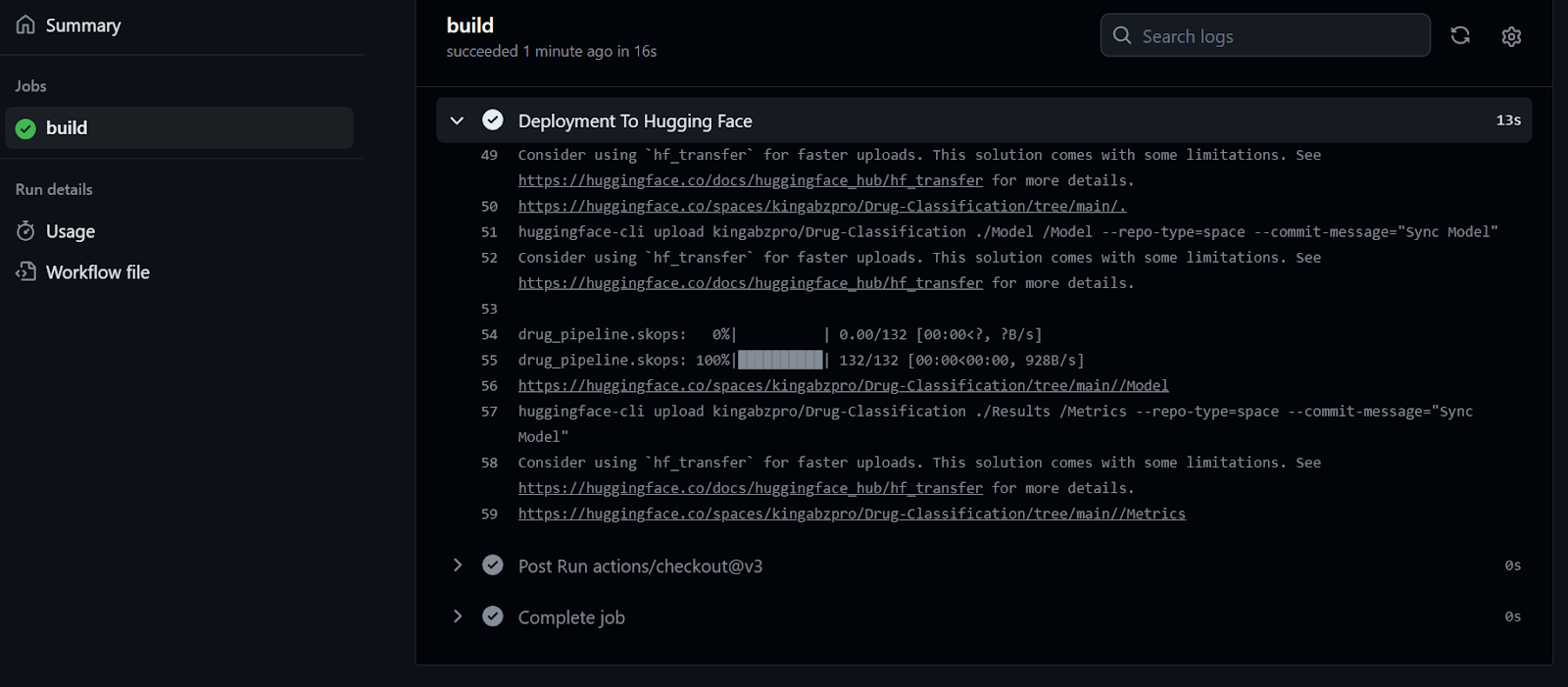
Podemos observar los registros en vivo de cada función seleccionando la opción de ejecución en la construcción del flujo de trabajo. Nuestros archivos se han cargado correctamente en el servidor de Cara Abrazada.
Tras recibir el archivo actualizado, el Espacio Cara Abrazada empezará a construir el entorno, y la aplicación comenzará a funcionar en unos segundos.
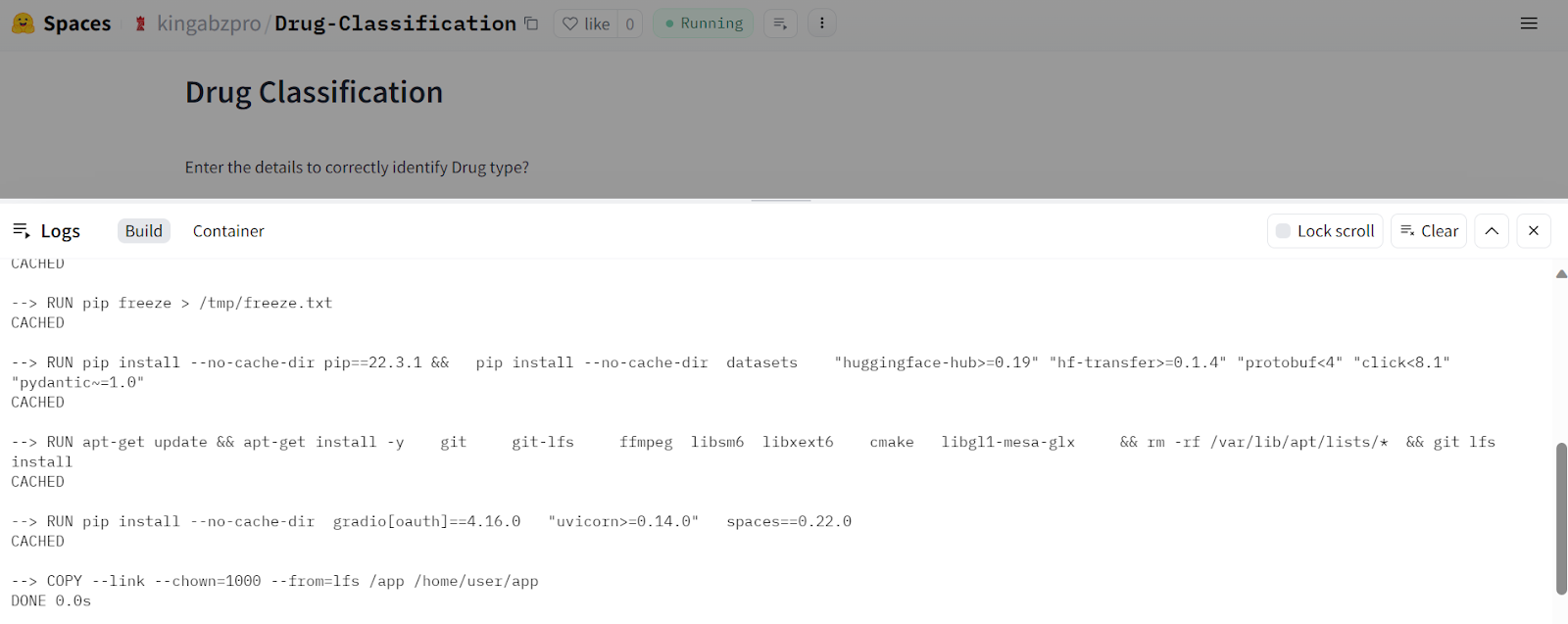
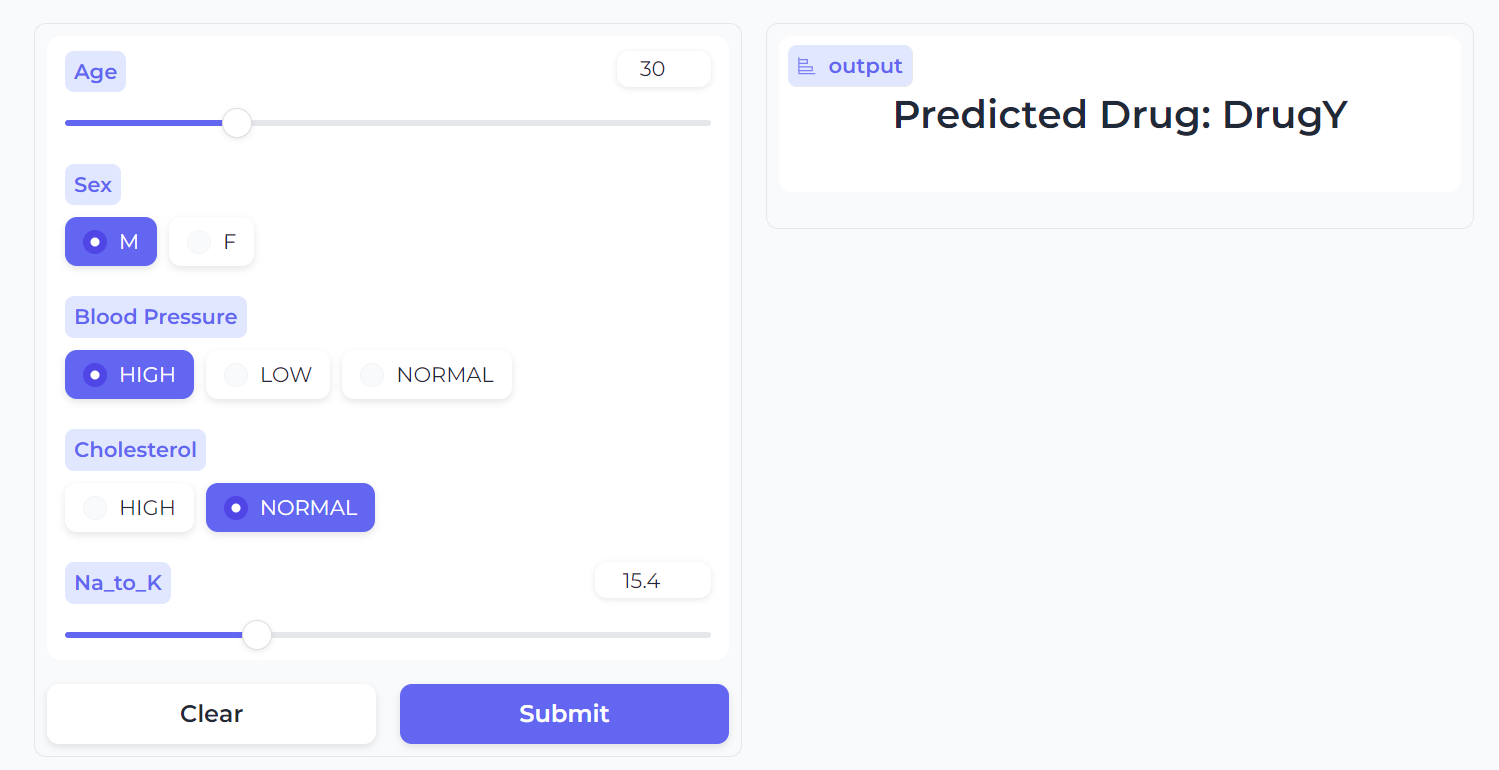
Nuestra aplicación de Clasificación de medicamentos funciona perfectamente y tiene una bonita interfaz.
Prueba a introducir datos diferentes para experimentar el rendimiento del modelo.
Fuente de la imagen
Esta guía describe cómo hemos automatizado los procesos de formación, evaluación, versionado y despliegue, garantizando que cualquier cambio en los datos o algoritmos activará automáticamente este proceso sin ningún error. Este enfoque nos ayuda a crear aplicaciones rápidas, escalables y listas para la producción.
Ten en cuenta que utilizamos múltiples herramientas MLOps en proyectos del mundo real para orquestar, versionar, desplegar y supervisar aplicaciones de aprendizaje automático. Para saber más sobre estas herramientas, echa un vistazo a Top MLOps Tools You Need to Know, que describe tecnologías populares utilizadas por grandes empresas tecnológicas para agilizar sus aplicaciones de aprendizaje automático.
Para optimizar tu canalización CI/CD, es crucial aprender herramientas como Docker, Kubernetes, Azure Cloud y otras tecnologías MLOps. Sigue un tutorial de Aprendizaje Automático, Pipelines, Despliegue y MLOps para familiarizarte con las prácticas estándar del sector y trabajar en proyectos avanzados.
¡Comienza hoy tu viaje de aprendizaje automático!
Curso
Curso
Curso