
Curso
Marketing Analytics: Predicción de churn de clientes en Python
4 h
18.4K
Este año ha sido un año de innovación en el campo de la ciencia de datos, con la inteligencia artificial y el aprendizaje automático dominando los titulares. Aunque no cabe duda de los progresos realizados en 2023, es importante reconocer que muchos de estos avances del aprendizaje automático sólo han sido posibles gracias a los correctos procesos de evaluación a los que se someten los modelos. Los profesionales de los datos tienen la tarea de garantizar que se realizan evaluaciones y procesos precisos para medir el rendimiento de un modelo de aprendizaje automático. Esto no es beneficioso, es esencial.
Si quieres adentrarte en el arte de la ciencia de datos, este artículo te guiará a través de los pasos cruciales de la evaluación de modelos mediante la matriz de confusión, una herramienta relativamente sencilla pero potente que se utiliza mucho en la evaluación de modelos.
Así que vamos a sumergirnos y aprender más sobre la matriz de confusión.
La matriz de confusión es una herramienta utilizada para evaluar el rendimiento de un modelo y se representa visualmente en forma de tabla. Proporciona una visión más profunda a los profesionales de los datos sobre el rendimiento, los errores y los puntos débiles del modelo. Esto permite a los profesionales de los datos seguir analizando su modelo mediante el ajuste fino.
Vamos a conocer la estructura básica de una matriz de confusión, utilizando el ejemplo de identificar un correo electrónico como spam o no spam.
Para comprender realmente el concepto de matriz de confusión, echa un vistazo a la siguiente visualización:
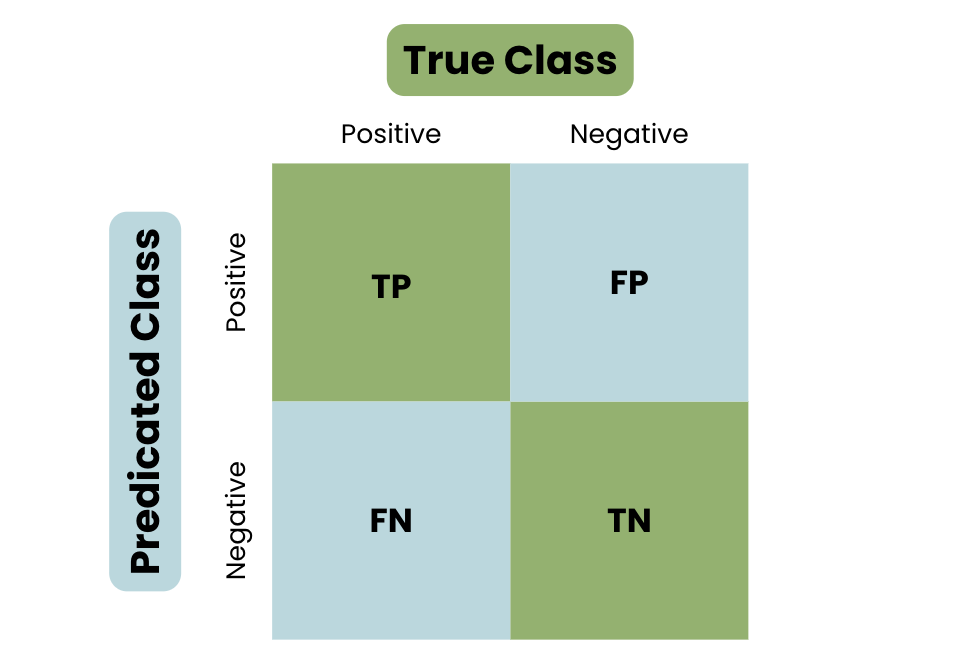
Estructura básica de una matriz de confusión
Para comprender en profundidad la Matriz de Confusión, es esencial entender las métricas importantes que se utilizan para medir el rendimiento de un modelo.
Definamos las métricas importantes:
La precisión mide el número total de clasificaciones correctas dividido por el número total de casos.
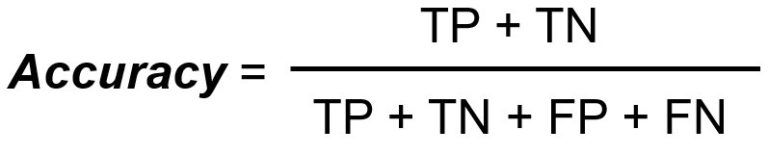
El recuerdo/sensibilidad mide el número total de verdaderos positivos dividido por el número total de verdaderos positivos.
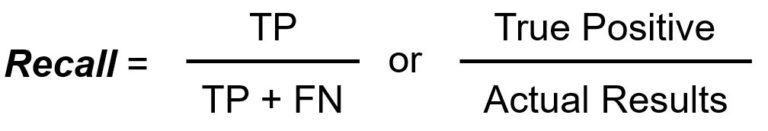
La precisión mide el número total de positivos verdaderos dividido por el número total de positivos predichos.

La especificidad mide el número total de verdaderos negativos dividido por el número total de verdaderos negativos.
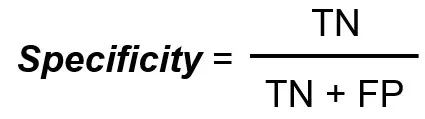
La puntuación F1 es una métrica única que es una media armónica de la precisión y la recuperación.

Para comprender mejor la matriz de confusión, debes entender el objetivo y por qué se utiliza ampliamente.
Cuando se trata de medir el rendimiento de un modelo o de cualquier cosa en general, la gente se centra en la precisión. Sin embargo, depender en gran medida de la métrica de precisión puede conducir a decisiones incorrectas. Para entenderlo, repasaremos las limitaciones de utilizar la precisión como métrica independiente.
Como se ha definido anteriormente, la precisión mide el número total de clasificaciones correctas dividido por el número total de casos. Sin embargo, utilizar esta métrica de forma independiente tiene limitaciones, como por ejemplo
A través de estas limitaciones, la matriz de confusión, junto con la variedad de métricas, ofrece una visión más detallada sobre cómo mejorar el rendimiento de un modelo.
Como se ve en la estructura básica de una matriz de confusión, las predicciones se dividen en cuatro categorías: Verdadero positivo, Verdadero negativo, Falso positivo y Falso negativo.
Este desglose detallado ofrece información valiosa y soluciones para mejorar el rendimiento de un modelo:
Ahora que ya conocemos bien una matriz de confusión básica, su terminología y su uso, pasemos a calcular manualmente una matriz de confusión, seguido de un ejemplo práctico.
Aquí tienes una guía paso a paso sobre cómo calcular manualmente una Matriz de Confusión.
El primer paso será identificar los dos posibles resultados de tu tarea: Positivo o Negativo.
Una vez definidos tus posibles resultados, el siguiente paso será recopilar todas las predicciones del modelo, incluyendo cuántas veces predijo el modelo cada clase y su ocurrencia.
Una vez cotejadas todas las predicciones, el siguiente paso es clasificar los resultados en las cuatro categorías:
Una vez clasificados los resultados, el siguiente paso es presentarlos en una tabla matricial, para analizarlos posteriormente utilizando diversas métricas.
Veamos un ejemplo práctico para demostrar este proceso.
Siguiendo con el mismo ejemplo de identificar un correo electrónico como spam o no spam, vamos a crear un hipotético conjunto de datos en el que el spam sea Positivo y el no spam sea Negativo. Tenemos los siguientes datos:
Llegados a este punto, hemos definido el resultado y recogido los datos; el siguiente paso es clasificar los resultados en las cuatro categorías:
El siguiente paso es convertir esto en una Matriz de Confusión:
|
Real / Previsto |
Spam (Positivo) |
No Spam (Negativo) |
|
Spam (Positivo) |
60 (TP) |
20 (FN) |
|
No Spam (Negativo) |
20 (FP) |
100 (TN) |
Entonces, ¿qué nos dice la Matriz de la Confusión?
Utilizando esta matriz de confusión, podemos calcular las distintas métricas: Exactitud, Recall/Sensibilidad, Precisión, Especificidad y Puntuación F1.

Resultado de la métrica de la matriz de confusión
Quizá te preguntes por qué la puntuación F1 incluye la precisión y la recuperación en su fórmula. La métrica de puntuación F1 es crucial cuando se trata de datos desequilibrados o cuando quieres equilibrar el compromiso entre precisión y recuperación.
La precisión mide la exactitud de la predicción positiva. Responde a la pregunta "cuando el modelo predijo VERDADERO, ¿con qué frecuencia acertó? La precisión, en particular, es importante cuando el coste de un falso positivo es elevado.
La recuperación o sensibilidad mide el número de positivos reales identificados correctamente por el modelo. Responde a la pregunta de "Cuando la clase era realmente VERDADERA, ¿con qué frecuencia acertó el clasificador?".
La recuperación es importante cuando se demuestra que omitir una instancia positiva (FN) es significativamente peor que etiquetar incorrectamente las instancias negativas como positivas.
Para poner esto en perspectiva, vamos a crear una matriz de confusión con Scikit-learn en Python, utilizando un clasificador Random Forest.
El primer paso será importar las bibliotecas necesarias y construir tu conjunto de datos sintéticos.
# Import Libraries
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Synthetic Dataset
X, y = make_classification(n_samples=1000, n_features=20,
n_classes=2, random_state=42)
# Split into Training and Test Sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)El siguiente paso es entrenar el modelo utilizando un clasificador de bosque aleatorio simple
# Train the Model
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)Como hicimos con el ejemplo práctico, tendremos que clasificar los resultados y convertirlo en una matriz de confusión. Para ello, primero predecimos sobre los datos de prueba y luego generamos una Matriz de Confusión:
# Predict on the Test Data
y_pred = model.predict(X_test)
# Generate the confusion matrix
cm = confusion_matrix(y_test, y_pred)Ahora queremos generar una representación visual de la matriz de confusión:
# Create a Confusion Matrix
plt.figure(figsize=(8, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Greens')
plt.title('Confusion Matrix')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()Este es el resultado:
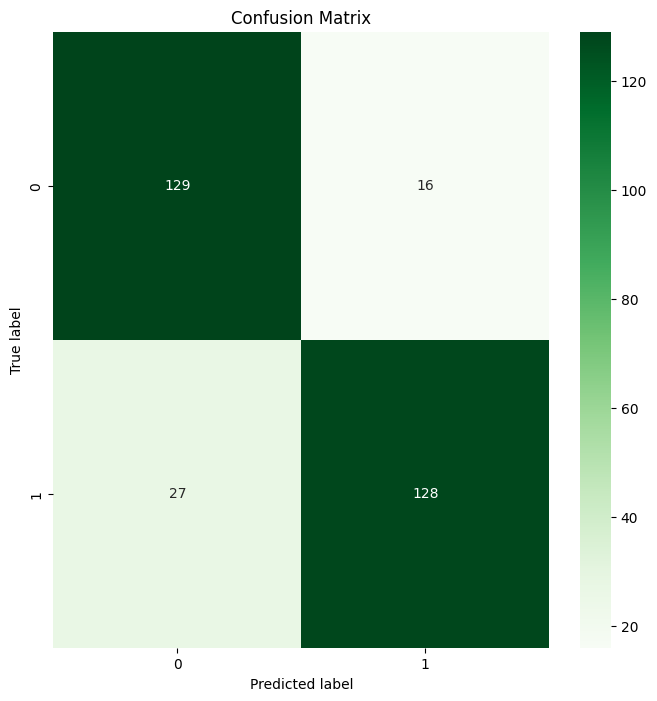
Salida de la matriz de confusión del bosque aleatorio
Tada 🎉 ¡Has creado con éxito tu primera Matriz de Confusión utilizando Scikit-learn!
En este artículo, hemos explorado la definición de Matriz de Confusión, la terminología importante que rodea a la herramienta de evaluación, y las limitaciones e importancia de las distintas métricas. Ser capaz de calcular manualmente una Matriz de Confusión es importante para tu base de conocimientos de ciencia de datos, así como ser capaz de ejecutarla utilizando bibliotecas como Scikit-learn.
Si quieres profundizar más en la Matriz de Confusión, practica las matrices de confusión en R con Comprender la Matriz de Confusión en R. Sumérgete un poco más con nuestro curso Validación de Modelos en Python, donde aprenderás los fundamentos de la validación de modelos, las técnicas de validación y empezarás a crear modelos validados y de alto rendimiento.
Más información sobre la matriz de confusión
Curso
Curso
Curso