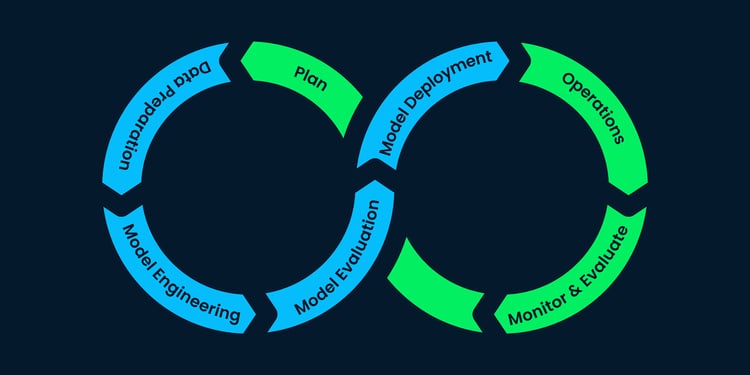
Introducción
Pipelines, Deployment y MLOps son algunos conceptos muy importantes para los científicos de datos hoy en día. Construir un modelo en Notebook no es suficiente. El despliegue de pipelines y la gestión de procesos integrales con las mejores prácticas de MLOps es un objetivo cada vez más importante para muchas empresas. Este tutorial trata varios conceptos importantes como Pipeline, CI/DI, API, Container, Docker, Kubernetes. También aprenderás sobre marcos y bibliotecas MLOps en Python. Por último, el tutorial muestra la implementación de principio a fin de contenerizar una aplicación web ML basada en Flask y desplegarla en la nube Microsoft Azure.
Conceptos clave
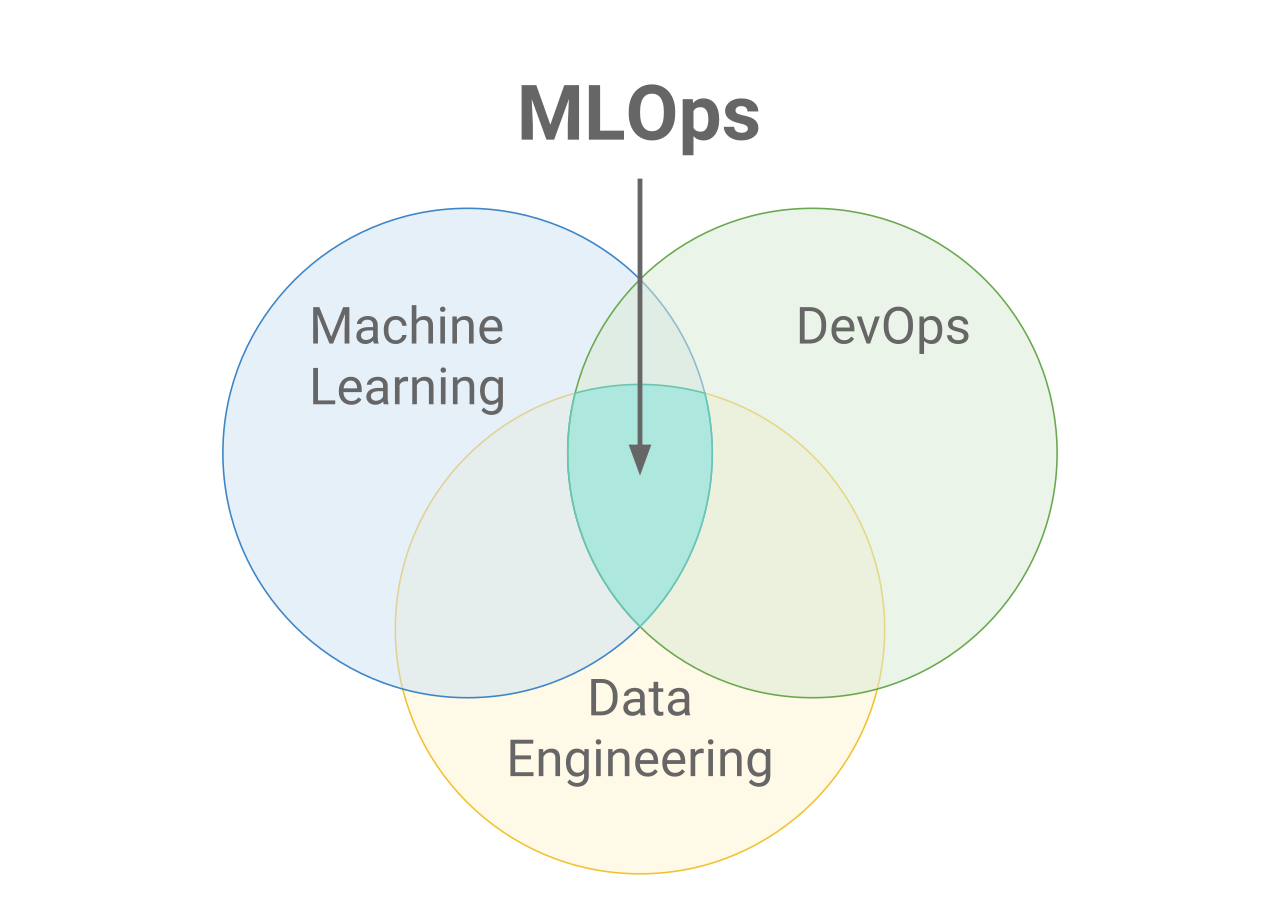
MLOps
MLOps significa Operaciones de Aprendizaje Automático. MLOps se centra en agilizar el proceso de despliegue de modelos de aprendizaje automático en producción, y luego en su mantenimiento y supervisión. MLOps es una función colaborativa, a menudo formada por científicos de datos, ingenieros de ML e ingenieros de DevOps. La palabra MLOps es un compuesto de dos campos diferentes, es decir, aprendizaje automático y DevOps de ingeniería de software.
Los MLOps pueden abarcarlo todo, desde la canalización de datos hasta la producción de modelos de aprendizaje automático. En algunos lugares, verás que la implementación de MLOps es sólo para el despliegue del modelo de aprendizaje automático, pero también encontrarás empresas con implementación de MLOps en muchas áreas diferentes del desarrollo del ciclo de vida ML, como el Análisis Exploratorio de Datos (EDA), el Preprocesamiento de Datos, el Entrenamiento del Modelo, etc.
Aunque MLOps empezó como un conjunto de buenas prácticas, está evolucionando lentamente hacia un enfoque independiente de la gestión del ciclo de vida del ML. MLOps se aplica a todo el ciclo de vida: desde la integración con la generación de modelos (ciclo de vida del desarrollo de software e integración continua/entrega continua), la orquestación y el despliegue, hasta la salud, el diagnóstico, la gobernanza y las métricas empresariales.
¿Por qué MLOps?
Hay muchos objetivos que las empresas quieren alcanzar mediante los MLOP. Algunos de los más comunes son:
- Automatización
- Escalabilidad
- Reproducibilidad
- Supervisión
- Gobernanza
MLOps vs DevOps
DevOps es un enfoque iterativo para enviar aplicaciones de software a producción. MLOps toma prestados los mismos principios para llevar los modelos de aprendizaje automático a la producción. Ya sea Devops o MLOps, el objetivo final es una mayor calidad y control de las aplicaciones de software/modelos ML.
CI/CD: integración continua, entrega continua y despliegue continuo.
CI/CD es una práctica derivada de DevOps y se refiere a un proceso continuo de reconocimiento de problemas, reevaluación y actualización automática de los modelos de aprendizaje automático. Los principales conceptos atribuidos al CI/CD son la integración continua, la entrega continua y el despliegue continuo. Automatiza la canalización del aprendizaje automático (construcción, pruebas y despliegue) y reduce en gran medida la necesidad de que los científicos de datos intervengan manualmente en el proceso, haciéndolo eficiente, rápido y menos propenso al error humano.
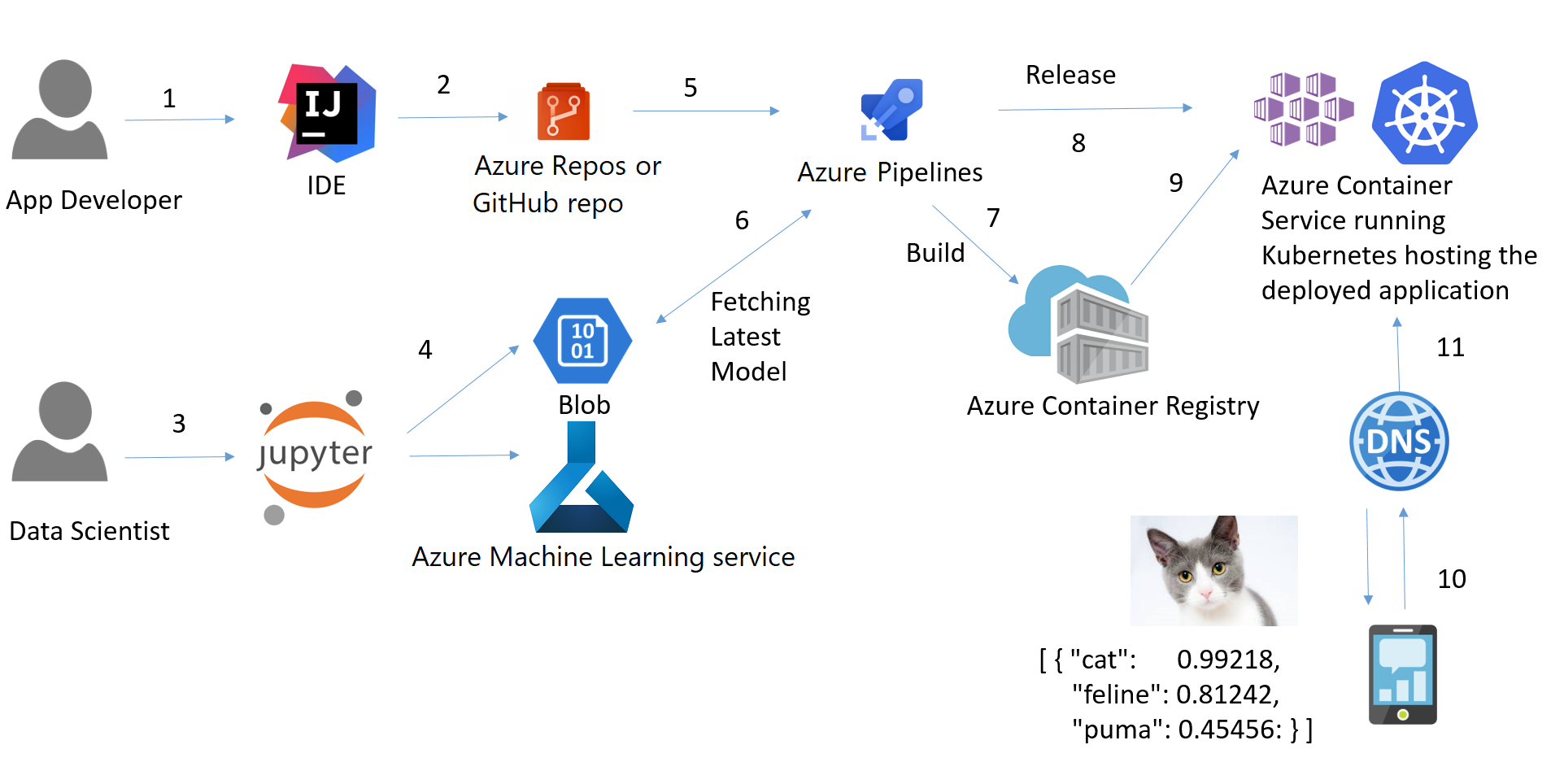
Tuberías
Un proceso de aprendizaje automático es una forma de controlar y automatizar el flujo de trabajo necesario para producir un modelo de aprendizaje automático. Los pipelines de aprendizaje automático consisten en múltiples pasos secuenciales que lo hacen todo, desde la extracción de datos y el preprocesamiento hasta el entrenamiento y despliegue del modelo.
Los conductos de aprendizaje automático son iterativos, ya que cada paso se repite para mejorar continuamente la precisión del modelo y alcanzar el objetivo final.
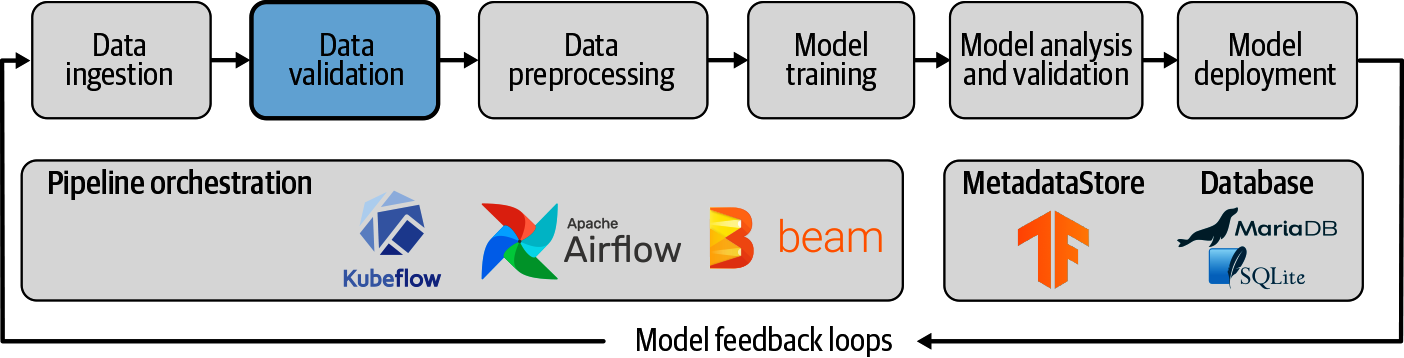
El término Pipeline se utiliza generalmente para describir la secuencia independiente de pasos que se organizan juntos para lograr una tarea. Esta tarea puede ser de aprendizaje automático o no. Las tuberías de aprendizaje automático son muy comunes, pero no es el único tipo de tubería que existe. Los conductos de orquestación de datos son otro ejemplo. Según los documentos de Microsoft, hay tres posibilidades:
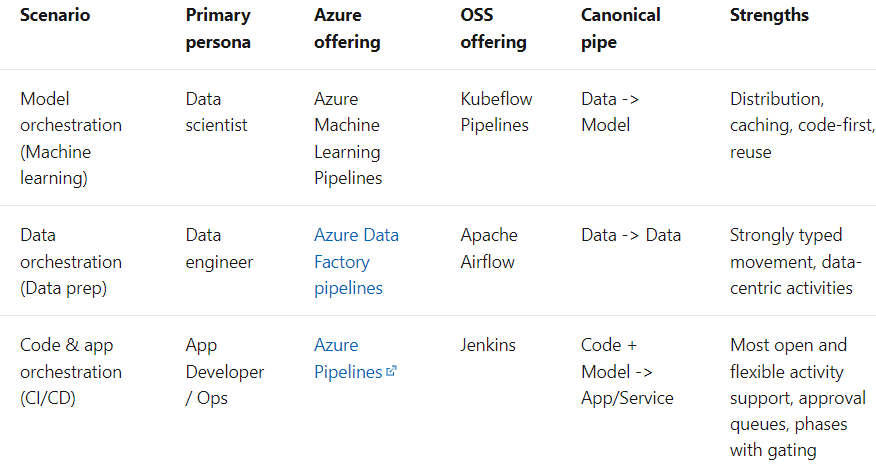
Despliegue
El despliegue de modelos de aprendizaje automático (o pipelines) es el proceso de hacer que los modelos estén disponibles en producción, donde las aplicaciones web, el software empresarial (ERPs) y las API puedan consumir el modelo entrenado proporcionando nuevos puntos de datos, y obtener las predicciones.
En resumen, el Despliegue en el Aprendizaje Automático es el método por el que integras un modelo de aprendizaje automático en un entorno de producción existente para tomar decisiones empresariales prácticas basadas en datos. Es la última etapa del ciclo de vida del aprendizaje automático.
Normalmente, el término Despliegue de Modelos de Aprendizaje Automático se utiliza para describir el despliegue de toda la Cadena de Aprendizaje Automático, en la que el modelo en sí es sólo un componente de la Cadena.
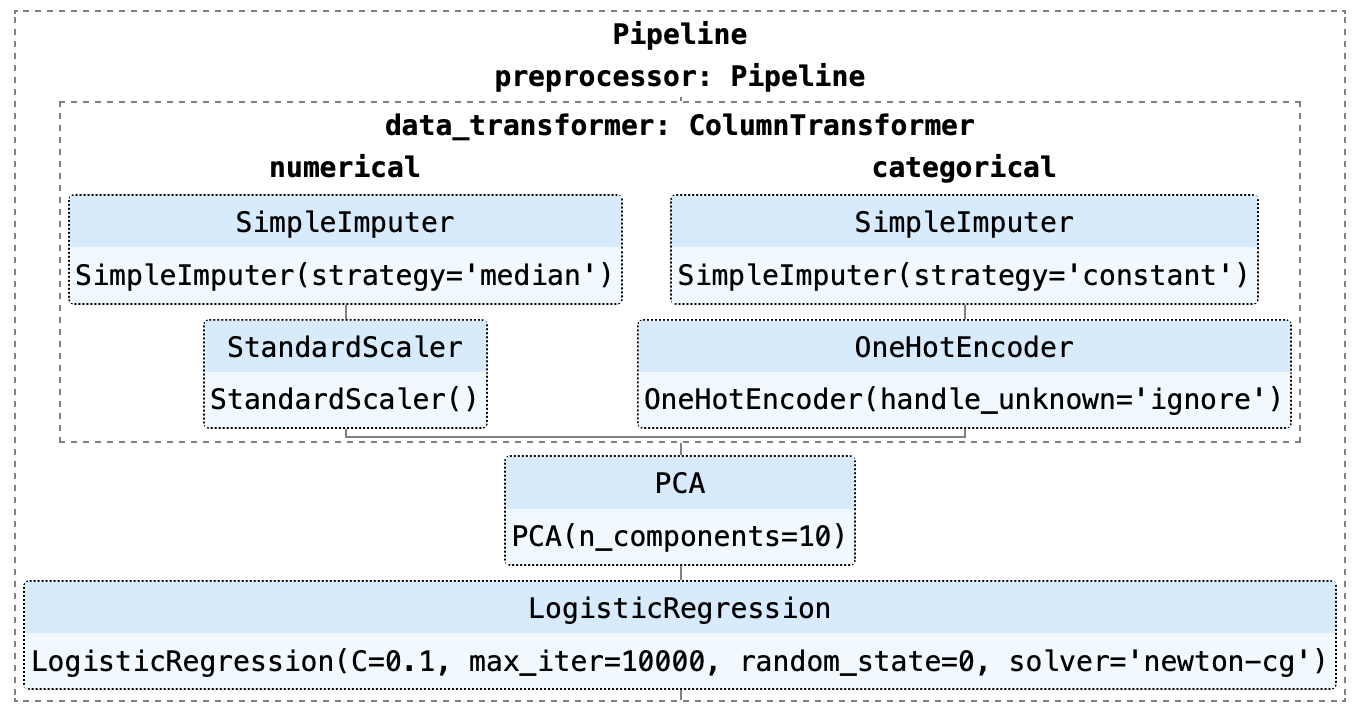
Como puedes ver en el ejemplo anterior, esta canalización consiste en un modelo de Regresión Logística. Hay varios pasos en la tubería que deben ejecutarse primero antes de que pueda comenzar el entrenamiento, como la Imputación de valores perdidos, la Codificación de una sola vez, el Escalado y el Análisis de Componentes Principales (ACP ).
Interfaz de programación de aplicaciones (API)
Interfaz de Programación de Aplicaciones (API), es un intermediario de software que permite que dos aplicaciones hablen entre sí. En palabras sencillas, una API es un contrato entre dos aplicaciones que dice que si el software del usuario proporciona una entrada en un formato predefinido, la API proporcionará el resultado al usuario. En otras palabras, la API es un punto final donde alojas los modelos / (pipelines) de aprendizaje automático entrenados para su uso. En la práctica se parece a esto:
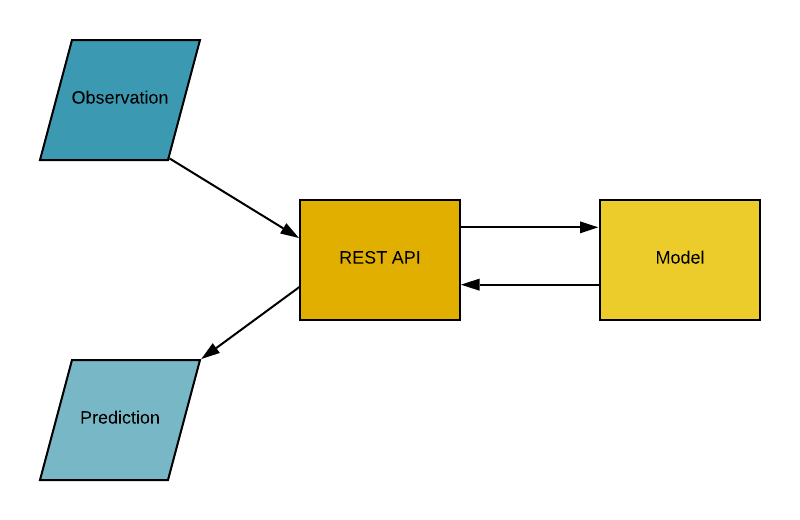
Contenedor
¿Has tenido alguna vez el problema de que tu código python (o cualquier otro código) funciona bien en tu ordenador, pero cuando tu amigo intenta ejecutar exactamente el mismo código, no funciona? Si tu amigo repite exactamente los mismos pasos, debería obtener los mismos resultados, ¿no? La respuesta sencilla a esto es que el entorno Python de tu amigo es diferente al tuyo.
¿Qué incluye un entorno?
Python (o cualquier otro lenguaje que hayas utilizado) y todas las bibliotecas y dependencias utilizadas para crear esa aplicación.
Si podemos crear de algún modo un entorno que podamos transferir a otras máquinas (por ejemplo, el ordenador de tu amigo o un proveedor de servicios en la nube como Microsoft Azure, AWS o GCP), podremos reproducir los resultados en cualquier lugar. Un contenedor es un tipo de software que empaqueta una aplicación y todas sus dependencias para que la aplicación pueda ejecutarse de forma fiable de un entorno informático a otro.
La forma más intuitiva de entender los contenedores en la ciencia de datos es pensar en los contenedores de un buque o barco. El objetivo es aislar el contenido de un recipiente de los demás para que no se mezclen. Esto es exactamente para lo que se utilizan los contenedores en la ciencia de datos.
Ahora que entendemos la metáfora que hay detrás de los contenedores, veamos opciones alternativas para crear un entorno aislado para nuestra aplicación. Una alternativa sencilla es tener una máquina distinta para cada una de tus aplicaciones.
Utilizar una máquina independiente es sencillo, pero no supera las ventajas de utilizar contenedores, ya que mantener varias máquinas para cada aplicación es caro, una pesadilla de mantener y difícil de escalar. En resumen, no es práctico en muchos escenarios de la vida real.
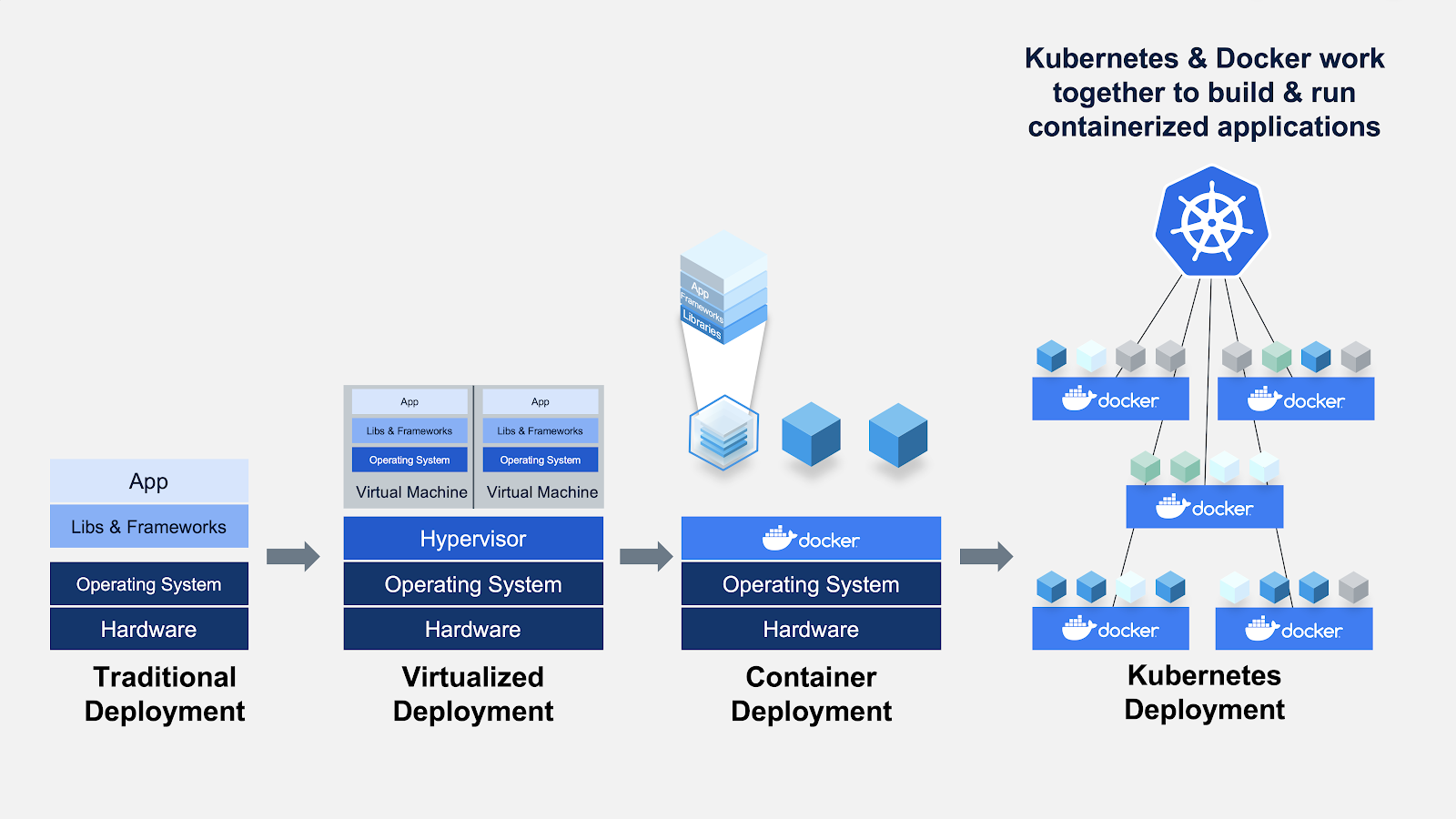
Otra alternativa para crear un entorno aislado es utilizar máquinas virtuales. En este caso también son preferibles los contenedores, porque requieren menos recursos, son muy portátiles y se activan más rápidamente.
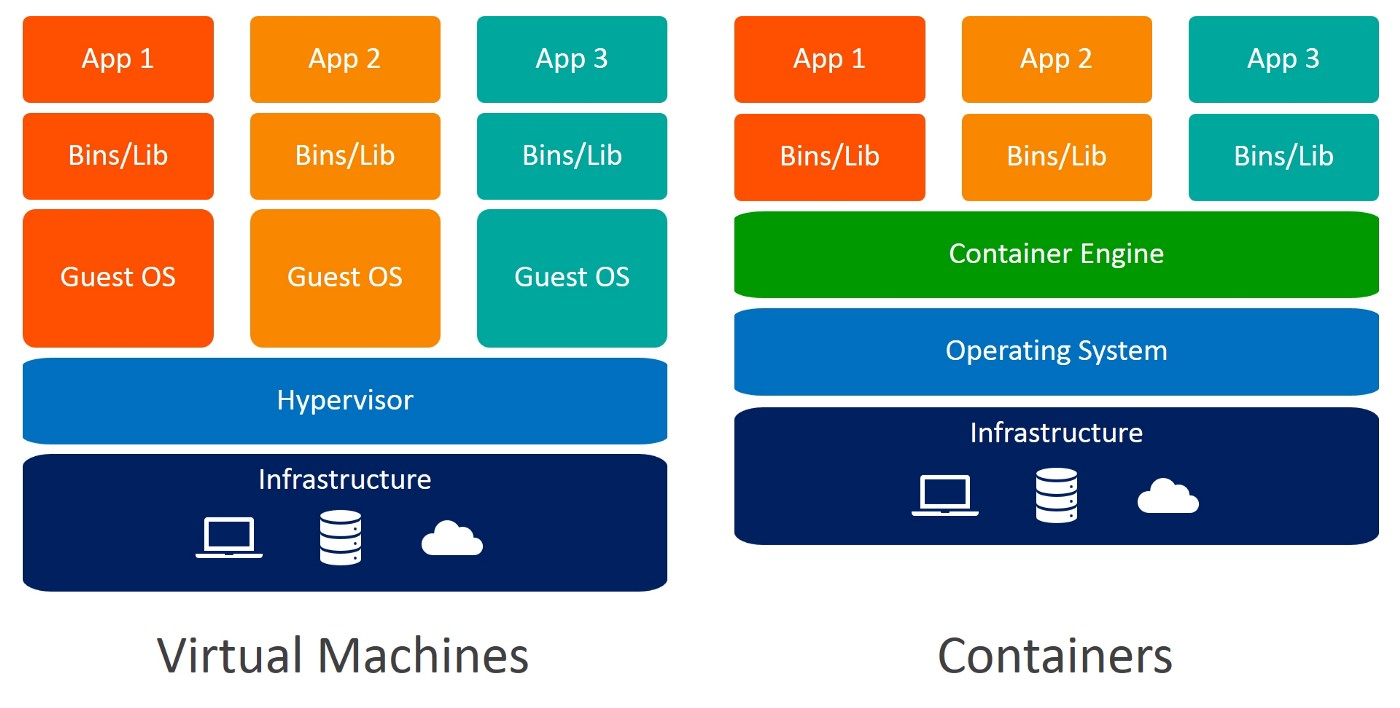
¿Puedes identificar las diferencias entre Máquinas Virtuales y Contenedores? Cuando utilizas contenedores, no necesitas sistemas operativos invitados. Imagina 10 aplicaciones ejecutándose en una máquina virtual. Esto requeriría 10 sistemas operativos invitados, frente a ninguno necesario cuando utilizas contenedores.
Docker
Docker es una empresa que proporciona software (también llamado Docker) que permite a los usuarios construir, ejecutar y gestionar contenedores. Aunque los contenedores de Docker son los más comunes, otras alternativas menos famosas como LXD y LXC también proporcionan soluciones de contenedores.
Docker es una herramienta diseñada para facilitar la creación, despliegue y ejecución de aplicaciones mediante el uso de contenedores. Los contenedores se utilizan para empaquetar una aplicación con todos sus componentes necesarios, como bibliotecas y otras dependencias, y enviarlo todo como un paquete.
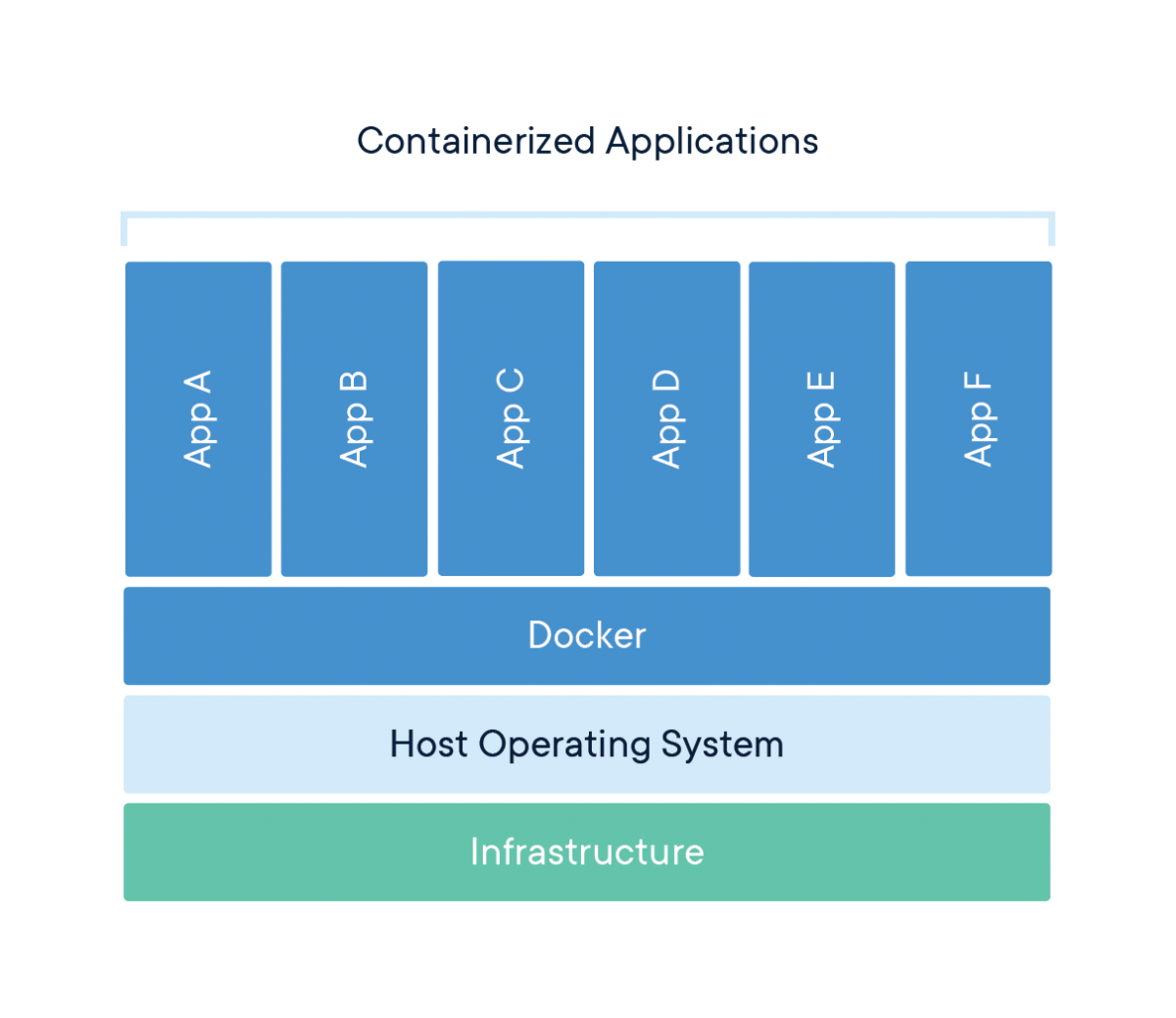
Romper el bombo
Al fin y al cabo, Docker no es más que un archivo con unas cuantas líneas de instrucciones que se guardan en la carpeta de tu proyecto con el nombre "Dockerfile".
Otra forma de pensar en los archivos Docker es que son como recetas que has inventado en tu propia cocina. Cuando compartes esas recetas con otra persona y ésta sigue exactamente las mismas instrucciones, es capaz de elaborar el mismo plato. Del mismo modo, puedes compartir tus archivos Docker con otras personas, que podrán crear imágenes y ejecutar contenedores basados en ese archivo Docker concreto.
Kubernetes
Desarrollado por Google en 2014, Kubernetes es un potente sistema de código abierto para gestionar aplicaciones en contenedores. En palabras sencillas, Kubernetes es un sistema para ejecutar y coordinar aplicaciones en contenedores en un clúster de máquinas. Es una plataforma diseñada para gestionar completamente el ciclo de vida de las aplicaciones en contenedores.
Características
- Equilibrio de carga: Distribuye automáticamente la carga entre los contenedores.
- Escala: Amplía o reduce automáticamente la escala añadiendo o eliminando contenedores cuando cambie la demanda, como en horas punta y durante fines de semana y vacaciones.
- Almacenamiento: Mantiene la coherencia del almacenamiento con múltiples instancias de una aplicación.
¿Por qué necesitas Kubernetes si tienes Docker?
Imagina un escenario en el que tienes que ejecutar varios contenedores Docker, en varias máquinas, para dar soporte a una aplicación ML de nivel empresarial con cargas de trabajo variadas día y noche. Aunque parezca sencillo, es mucho trabajo hacerlo manualmente.
Tienes que poner en marcha los contenedores adecuados en el momento oportuno, averiguar cómo pueden comunicarse entre sí, manejar las consideraciones de almacenamiento y hacer frente a los contenedores o el hardware que fallen. Este es el problema que resuelve Kubernetes, al permitir que un gran número de contenedores trabajen juntos en armonía, y reducir la carga operativa.
Google Kubernetes Engine es una implementación de Kubernetes de código abierto de Google en Google Cloud Platform. Otras alternativas populares a GKE son Amazon ECS y Microsoft Azure Kubernetes Service.
Resumen rápido de términos:
- Un Contenedor es un tipo de software que empaqueta una aplicación y todas sus dependencias para que la aplicación se ejecute de forma fiable de un entorno informático a otro.
- Docker es un software utilizado para construir y gestionar contenedores.
- Kubernetes es un sistema de código abierto para gestionar aplicaciones en contenedores en un entorno en clúster.
Marcos y bibliotecas MLOps en Python
MLflow
MLflow es una plataforma de código abierto para gestionar el ciclo de vida del ML, incluyendo experimentación, reproducibilidad, despliegue y un registro central de modelos. MLflow ofrece actualmente el seguimiento de MLflow, los Proyectos MLflow, los Modelos MLflow y el Registro de Modelos.
Metaflow
Metaflow es una biblioteca Python fácil de usar que ayuda a científicos e ingenieros a construir y gestionar proyectos de ciencia de datos de la vida real. Metaflow se desarrolló originalmente en Netflix para aumentar la productividad de los científicos de datos que trabajan en una amplia variedad de proyectos, desde la estadística clásica hasta el aprendizaje profundo más avanzado. Metaflow proporciona una API unificada a la pila de infraestructuras necesaria para ejecutar proyectos de ciencia de datos, desde el prototipo hasta la producción.
Kubeflow
Kubeflow es una plataforma de aprendizaje automático de código abierto, diseñada para permitir que los conductos de aprendizaje automático orquesten complicados flujos de trabajo que se ejecutan en Kubernetes. Kubeflow se basó en el método interno de Google para desplegar modelos TensorFlow, llamado TensorFlow Extended.
Kedro
Kedro es un marco Python de código abierto para crear código de ciencia de datos reproducible, mantenible y modular. Toma prestados conceptos de las mejores prácticas de ingeniería de software, y los aplica al código de aprendizaje automático; los conceptos aplicados incluyen la modularidad, la separación de preocupaciones y el versionado.
FastAPI
FastAPI es un marco web para desarrollar API RESTful en Python. FastAPI se basa en Pydantic y en sugerencias de tipo para validar, serializar y deserializar datos, y autogenerar automáticamente documentos OpenAPI.
ZenML
ZenML es un marco MLOps extensible y de código abierto para crear canalizaciones de aprendizaje automático listas para la producción. Construido para científicos de datos, tiene una sintaxis sencilla y flexible, es independiente de la nube y de las herramientas, y tiene interfaces/abstracciones que se adaptan a los flujos de trabajo de ML.
Ejemplo: Desarrollo, despliegue y MLOps de tuberías de extremo a extremo
Configuración del problema
Una compañía de seguros quiere mejorar sus previsiones de tesorería prediciendo mejor los gastos de los pacientes, utilizando métricas demográficas y de riesgo básico para la salud del paciente en el momento de la hospitalización.
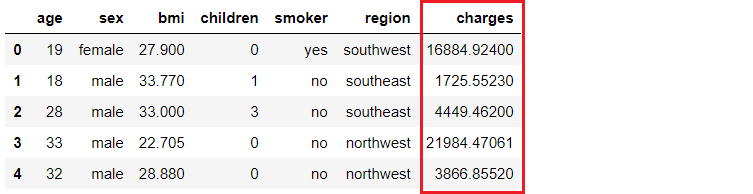
Nuestro objetivo es crear y desplegar una aplicación web en la que la información demográfica y sanitaria de un paciente se introduzca en un formulario basado en web, que a continuación emita un importe de cargo previsto. Para conseguirlo haremos lo siguiente
- Entrena y desarrolla un pipeline de aprendizaje automático para su despliegue (modelo de regresión lineal simple).
- Construye una aplicación web utilizando el framework Flask. Utilizará la canalización ML entrenada para generar predicciones sobre nuevos puntos de datos en tiempo real (el código front-end no es el objetivo de este tutorial).
- Crea una imagen Docker y un contenedor.
- Publica el contenedor en el Registro de Contenedores Azure (ACR).
- Despliega la aplicación web en el contenedor publicándola en ACR. Una vez desplegado, estará disponible públicamente y se podrá acceder a él a través de una URL Web.
Canal de aprendizaje automático
Utilizaré PyCaret en Python para entrenar y desarrollar una canalización de aprendizaje automático que se utilizará como parte de nuestra aplicación web. Puedes utilizar el framework que quieras, ya que los pasos posteriores no dependen de éste.
# load dataset
from pycaret.datasets import get_data
insurance = get_data('insurance')
# init environment
from pycaret.regression import *
r1 = setup(insurance, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
# train a model
lr = create_model('lr')
# save pipeline/model
save_model(lr, model_name = 'c:/username/pycaret-deployment-azure/deployment_28042020')
Cuando guardas un modelo en PyCaret, se crea toda la cadena de transformación, basándose en la configuración definida en la función de configuración. Todas las interdependencias se orquestan automáticamente. Consulta la canalización y el modelo almacenados en la variable 'deployment_28042020':

Aplicación Web Front-end
Este tutorial no se centra en la creación de una aplicación Flask. Sólo se comenta aquí para completar la información. Ahora que nuestro pipeline de aprendizaje automático está listo, necesitamos una aplicación web que pueda leer nuestro pipeline entrenado, para predecir nuevos puntos de datos. Esta solicitud consta de dos partes:
- Front-end (diseñado con HTML)
- Back-end (desarrollado con Flask)
Este es el aspecto del front-end:
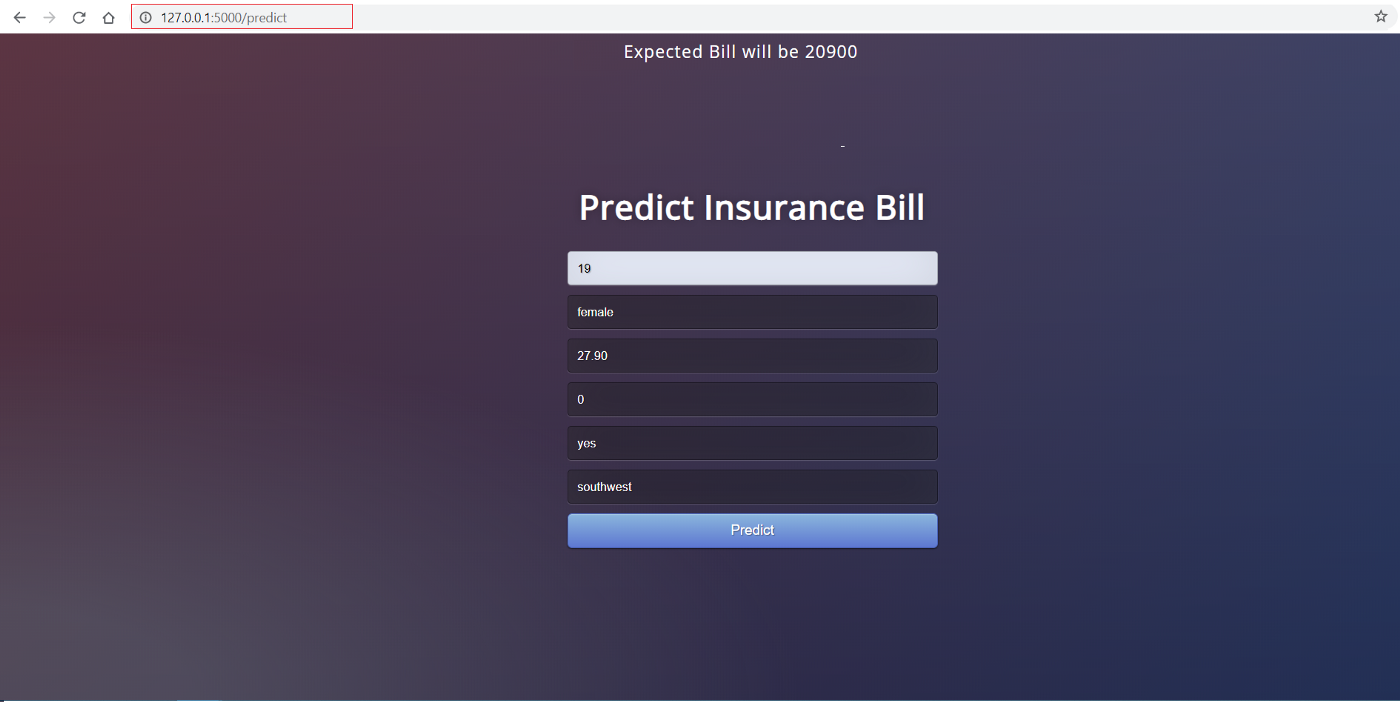
El front-end de esta aplicación es HTML muy sencillo con algunos estilos CSS. Si quieres ver el código, consulta este repositorio. Ahora que tenemos una aplicación web totalmente funcional, podemos empezar el proceso de contenerizar la aplicación utilizando Docker.
Back-end de la aplicación
El back-end de la aplicación es un archivo Python llamado app.py. Está construido utilizando el framework Flask.
from flask import Flask,request, url_for, redirect, render_template, jsonify
from pycaret.regression import *
import pandas as pd
import pickle
import numpy as np
app = Flask(__name__)
model = load_model('deployment_28042020')
cols = ['age', 'sex', 'bmi', 'children', 'smoker', 'region']
@app.route('/')
def home():
return render_template("home.html")
@app.route('/predict',methods=['POST'])
def predict():
int_features = [x for x in request.form.values()]
final = np.array(int_features)
data_unseen = pd.DataFrame([final], columns = cols)
prediction = predict_model(model, data=data_unseen, round = 0)
prediction = int(prediction.Label[0])
return render_template('home.html',pred='Expected Bill will be {}'.format(prediction))
@app.route('/predict_api',methods=['POST'])
def predict_api():
data = request.get_json(force=True)
data_unseen = pd.DataFrame([data])
prediction = predict_model(model, data=data_unseen)
output = prediction.Label[0]
return jsonify(output)
if __name__ == '__main__':
app.run(debug=True)
Contenedor Docker
Si utilizas Windows tendrás que instalar Docker para Windows. Si utilizas Ubuntu, Docker viene por defecto y no es necesario instalarlo.
El primer paso para contenerizar tu aplicación es escribir un archivo Dockerfile en la misma carpeta/directorio donde reside tu aplicación. Un Dockerfile no es más que un archivo con un conjunto de instrucciones. El Dockerfile de este proyecto tiene el siguiente aspecto:
FROM python:3.7
RUN pip install virtualenv
ENV VIRTUAL_ENV=/venv
RUN virtualenv venv -p python3
ENV PATH="VIRTUAL_ENV/bin:$PATH"
WORKDIR /app
ADD . /app
# install dependencies
RUN pip install -r requirements.txt
# expose port
EXPOSE 5000
# run application
CMD ["python", "app.py"]
Dockerfile distingue entre mayúsculas y minúsculas y debe estar en la carpeta del proyecto con los demás archivos del proyecto. Un Dockerfile no tiene extensión y puede crearse con cualquier editor. Hemos utilizado Visual Studio Code para crearlo.
Despliegue en la nube
Después de configurar Dockerfile correctamente, escribiremos algunos comandos para crear una imagen Docker a partir de este archivo, pero antes, necesitamos un servicio para alojar esa imagen. En este ejemplo, utilizaremos Microsoft Azure para alojar nuestra aplicación.
Registro de Contenedores Azure
Si no tienes una cuenta de Microsoft Azure o no la has utilizado antes, puedes registrarte gratuitamente. Cuando te inscribes por primera vez obtienes un crédito gratuito durante los primeros 30 días. Puedes utilizar ese crédito para crear y desplegar una aplicación web en Azure. Una vez que te hayas inscrito, sigue estos pasos:
- Conéctate en https://portal.azure.com
- Haz clic en Crear un recurso
- Busca Registro de Contenedores y haz clic en Crear
- Selecciona Suscripción, Grupo de recursos y Nombre de registro (en nuestro caso: pycaret.azurecr.io es nuestro nombre de registro).
Una vez creado un registro, el primer paso es crear una imagen Docker utilizando la línea de comandos. Navega hasta la carpeta del proyecto y ejecuta el siguiente código:
docker build -t pycaret.azurecr.io/pycaret-insurance:latest .
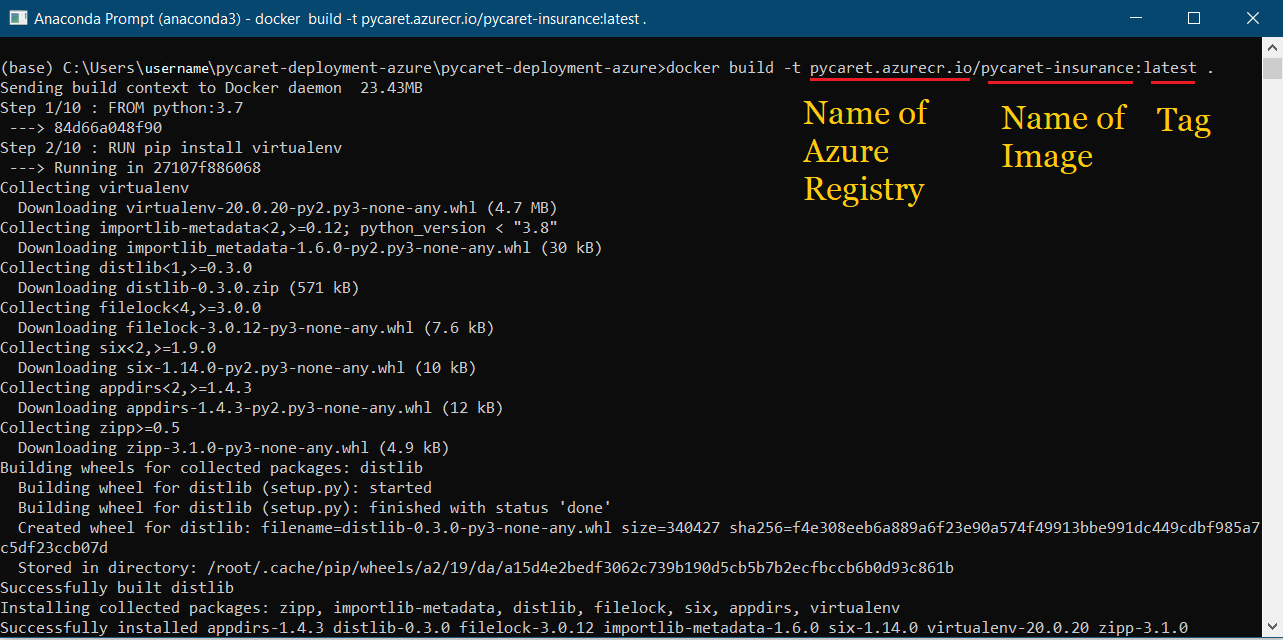
- pycaret.azurecr.io es el nombre del registro que obtienes cuando creas un recurso en el portal de Azure
- pycaret-seguro es el nombre de la imagen y la última es la etiqueta; puede ser lo que quieras
Ejecutar contenedor desde imagen Docker
Ahora que la imagen está creada, ejecutaremos un contenedor localmente y probaremos la aplicación antes de enviarla a Azure Container Registry. Para ejecutar el contenedor localmente, ejecuta el siguiente código:
docker run -d -p 5000:5000 pycaret.azurecr.io/pycaret-insurance
Puedes ver la aplicación en acción accediendo a localhost:5000 en tu navegador de Internet. Debería abrirse una aplicación web.
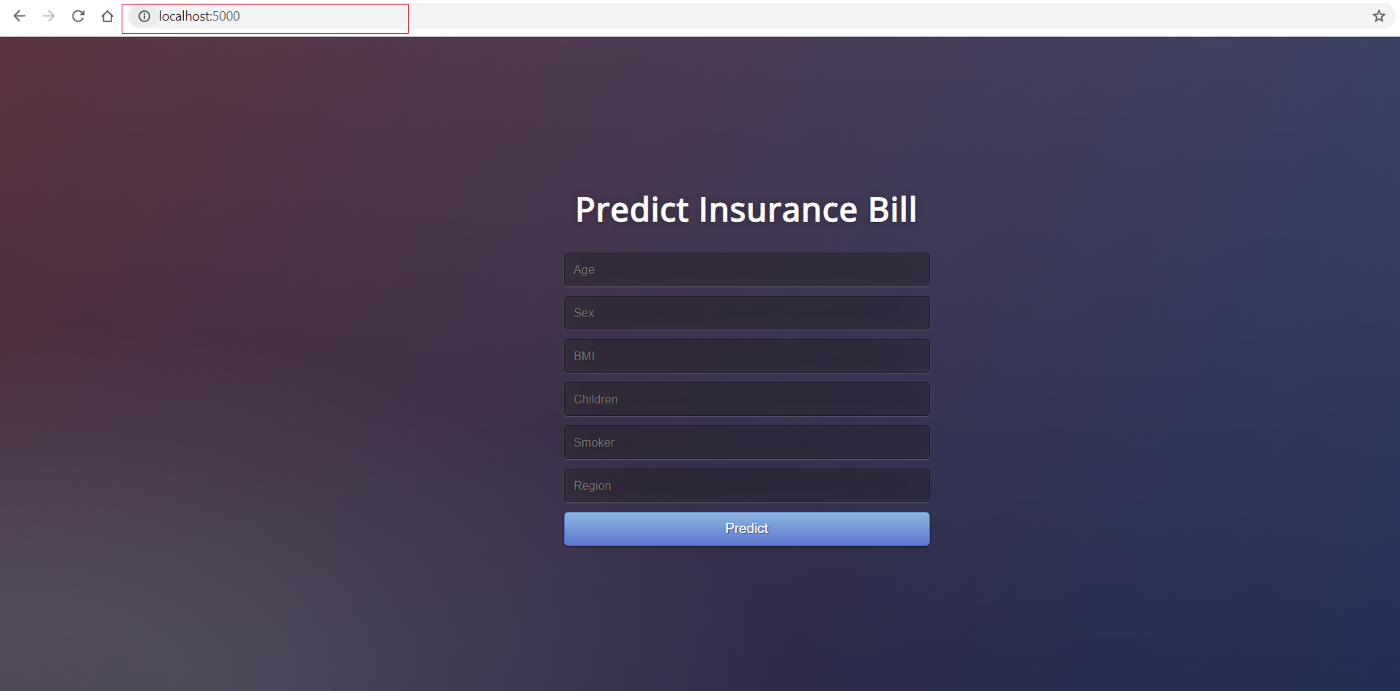
Si puedes ver esto, significa que la aplicación ya está funcionando en tu máquina local y ahora sólo es cuestión de subirla a la nube. Para la implantación en Azure, sigue leyendo:
Autenticar credenciales de Azure
Un último paso antes de que puedas subir el contenedor a ACR es autenticar las credenciales de Azure en tu máquina local. Ejecuta el siguiente código en la línea de comandos para hacerlo:
docker login pycaret.azurecr.io
Se te pedirá un nombre de usuario y una contraseña. El nombre de usuario es el nombre de tu registro (en este ejemplo el nombre de usuario es "pycaret"). Puedes encontrar tu contraseña en las claves de acceso del recurso Azure Container Registry que has creado.
Empujar el Contenedor al Registro de Contenedores de Azure
Ahora que te has autentificado en ACR, puedes enviar el contenedor que has creado a ACR ejecutando el siguiente código:
docker push pycaret.azurecr.io/pycaret-insurance:latest
Dependiendo del tamaño del contenedor, el comando push puede tardar algún tiempo en transferir el contenedor a la nube.
Aplicación Web
Para crear una aplicación web en Azure, sigue estos pasos:
- Inicia sesión en el portal Azure
- Haz clic en crear un recurso
- Busca la aplicación web y haz clic en crear
- Vincula tu imagen ACR a tu aplicación
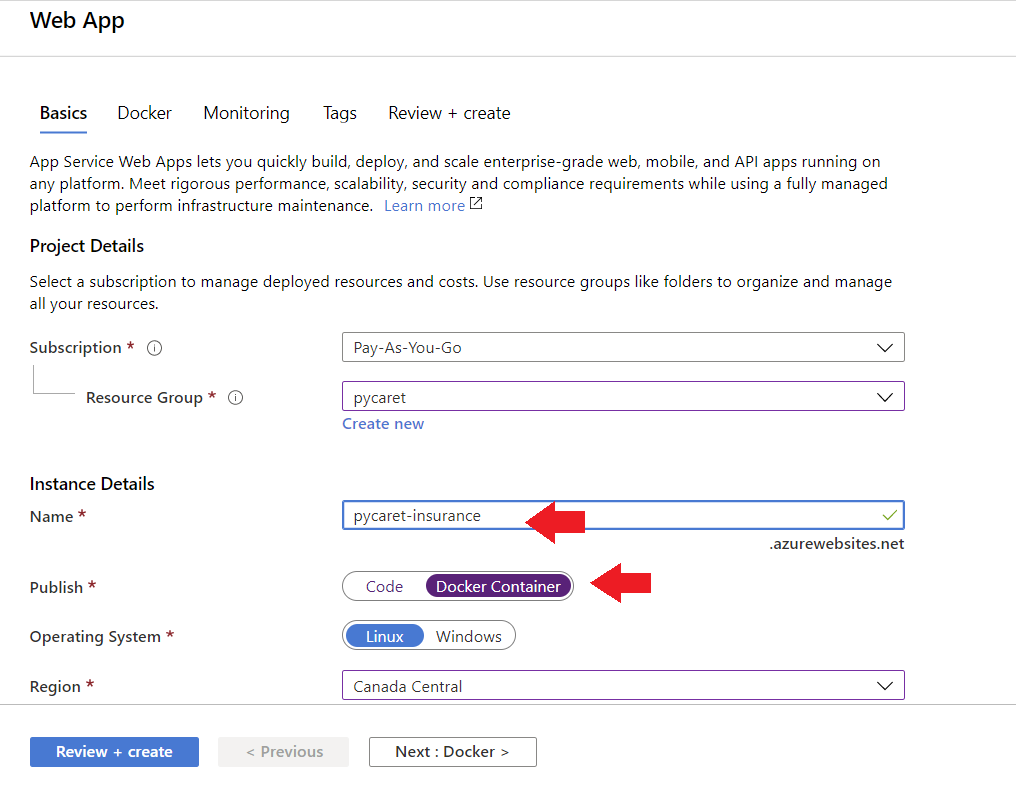
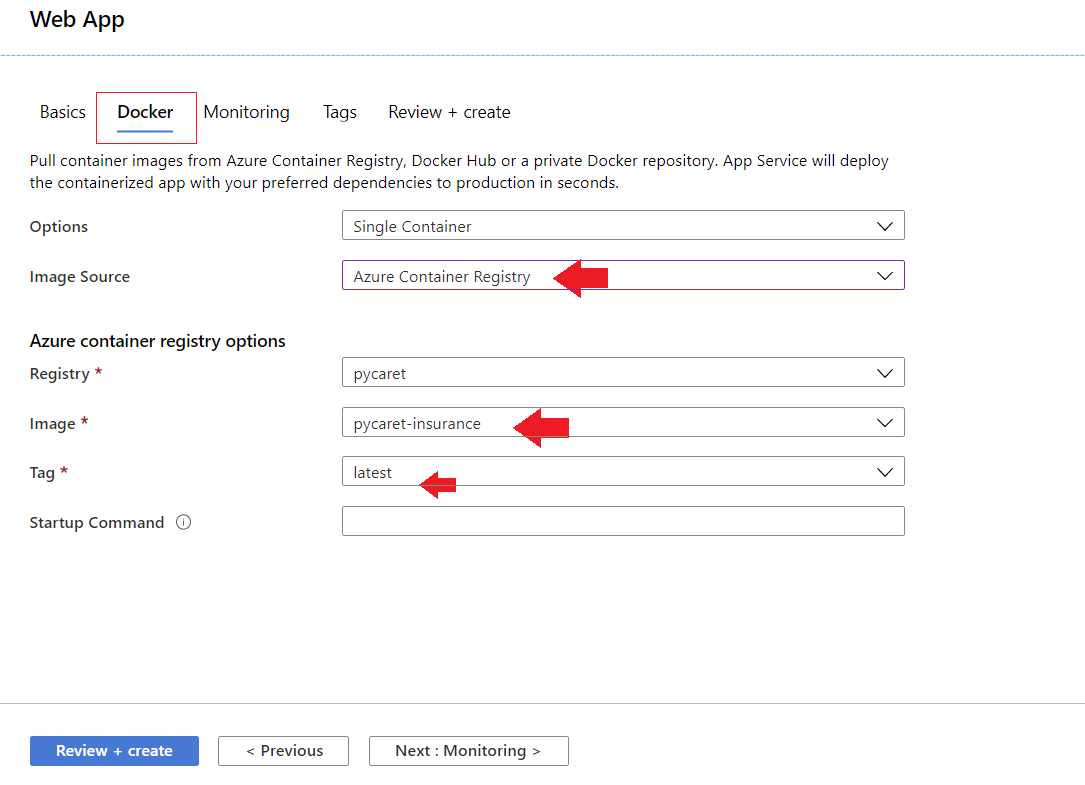
La aplicación ya está funcionando en Azure Web Services.

Conclusión
Los MLOP ayudan a garantizar que los modelos desplegados estén bien mantenidos, rindan como se espera y no tengan efectos adversos en el negocio. Este papel es crucial para proteger a la empresa de los riesgos debidos a modelos que se desvían con el tiempo, o que se despliegan pero no se mantienen o no se supervisan.
Los MLOP encabezan la clasificación de Empleos Emergentes de LinkedIn, con un crecimiento registrado de 9,8 veces en cinco años.
Puedes consultar la nueva Skill Track de Fundamentos de MLOps en DataCamp, que abarca el ciclo de vida completo de una aplicación de aprendizaje automático, desde la recopilación de requisitos empresariales hasta las fases de diseño, desarrollo, despliegue, funcionamiento y mantenimiento. Datacamp también tiene un curso increíble de Ingeniería de Datos. Inscríbete hoy para descubrir cómo los ingenieros de datos sientan las bases que hacen posible la ciencia de datos, sin necesidad de codificación.