programa
Desarrollar grandes modelos lingüísticos
16 h
Desplegar un gran modelo de lenguaje (LLM) en producción puede transformar tu aplicación, ofreciendo funciones avanzadas de comprensión y generación del lenguaje natural. Sin embargo, este proceso está plagado de retos que pueden entorpecer incluso a los desarrolladores más experimentados.
En esta guía, exploraremos cómo desplegar aplicaciones LLM utilizando LangServe, una herramienta diseñada para simplificar y agilizar este complejo proceso. Desde la instalación hasta la integración, aprenderás los pasos esenciales para implantar con éxito un LLM y liberar todo su potencial.
Construir una aplicación basada en LLM es más complejo que simplemente llamar a una API. Aunque integrar un LLM en tu proyecto puede mejorar significativamente sus capacidades, conlleva un conjunto único de retos que requieren una cuidadosa consideración. A continuación, desglosaremos los principales obstáculos que puedes encontrar y destacaremos los aspectos de la implantación que requieren atención.
Seleccionar el modelo adecuado para tu aplicación es el primer obstáculo. La elección depende de varios factores, como la tarea específica, la precisión requerida y los recursos informáticos disponibles. Además, personalizar un modelo preentrenado para que se adapte a las necesidades de tu aplicación puede ser complejo, ya que implica un ajuste fino con datos específicos del dominio.
Los LLM son computacionalmente intensivos y exigen recursos sustanciales. Garantizar que tu infraestructura pueda hacer frente a los elevados requisitos de memoria y potencia de procesamiento es crucial. Esto incluye planificar la escalabilidad para adaptarse al crecimiento futuro y a los posibles aumentos de uso.
Conseguir una baja latencia es vital para que la experiencia del usuario sea fluida. Los LLM pueden ser lentos en procesar las peticiones, especialmente bajo cargas pesadas. Optimizar el rendimiento implica estrategias como la compresión de modelos, marcos de servicio eficientes y, posiblemente, la descarga de algunas tareas de procesamiento a dispositivos de borde.
Una vez desplegada, es necesaria una supervisión continua de la aplicación LLM. Esto incluye el seguimiento de las métricas de rendimiento, la detección de anomalías y la gestión de la deriva del modelo. Un mantenimiento regular garantiza que el modelo siga siendo preciso y eficaz a lo largo del tiempo, requiriendo actualizaciones periódicas y reentrenamiento con nuevos datos.
Integrar los LLM con los sistemas y flujos de trabajo existentes puede ser un reto. Garantizar la compatibilidad con diversos entornos de software, API y formatos de datos requiere una planificación y ejecución meticulosas. La integración perfecta es clave para aprovechar todo el potencial de los LLM en tu aplicación.
Las elevadas exigencias computacionales de los LLM pueden conllevar importantes costes operativos. Equilibrar el rendimiento con la rentabilidad es una consideración vital. Las estrategias para gestionar los costes incluyen la optimización de la asignación de recursos, el uso de servicios en la nube rentables y la revisión periódica de los patrones de uso para identificar áreas de ahorro.
Desplegar un LLM en producción es un proceso complejo que implica orquestar múltiples sistemas y componentes. Va más allá de la simple integración de un potente modelo lingüístico en tu aplicación; requiere una infraestructura cohesionada en la que cada parte desempeñe un papel fundamental.
Para comprender los entresijos del despliegue de aplicaciones LLM, es imprescindible explorar los distintos componentes implicados y sus interacciones. El siguiente diagrama ilustra la arquitectura de una aplicación LLM moderna, destacando los elementos clave y sus relaciones dentro del sistema.
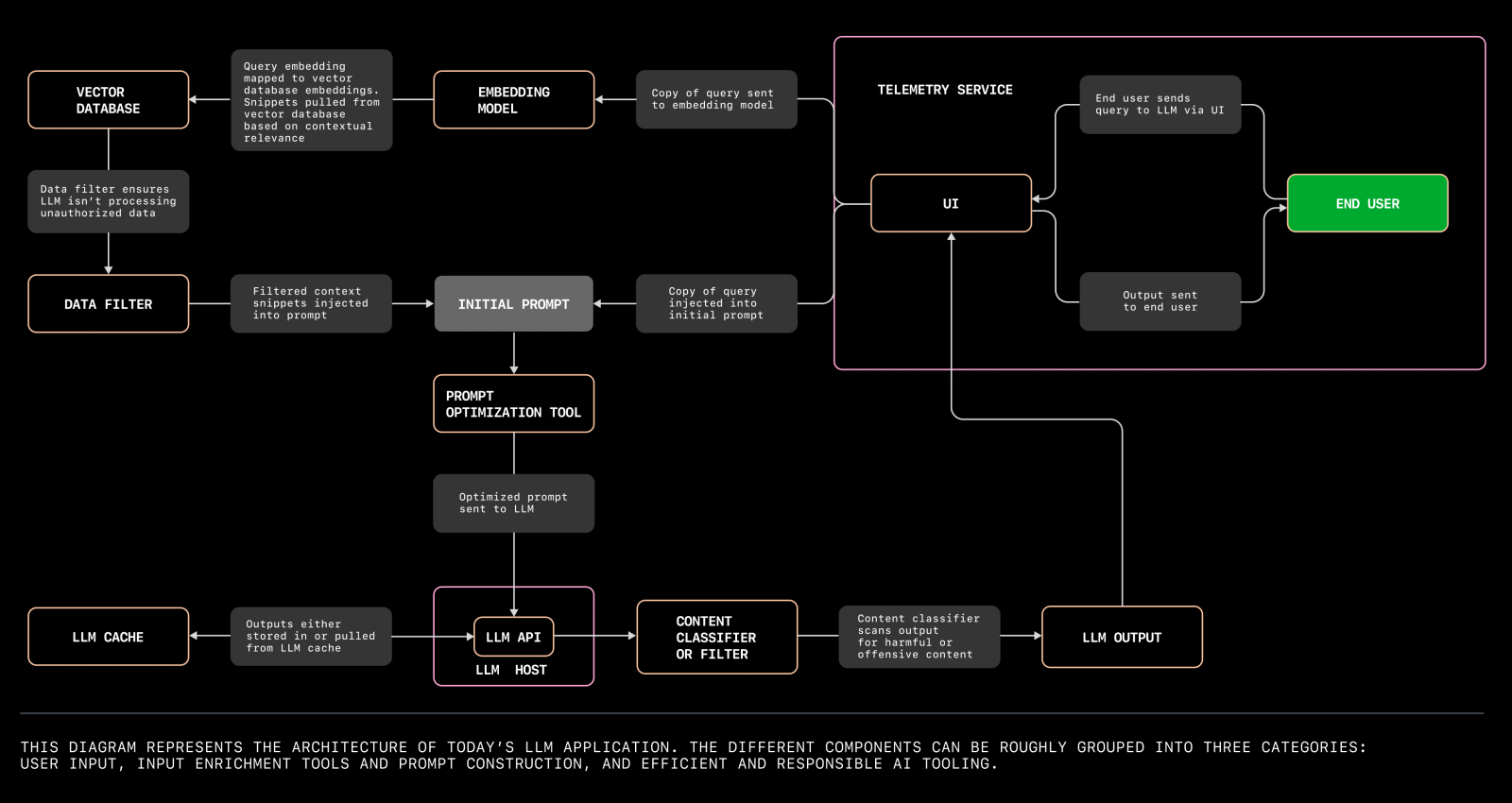
Diagrama que ilustra la arquitectura de una aplicación LLM moderna. Fuente
La arquitectura de una aplicación LLM puede dividirse en varios aspectos básicos:
Las bases de datos vectoriales son fundamentales para gestionar los datos de alta dimensión generados por los LLM. Estas bases de datos almacenan y recuperan vectores de forma eficiente, permitiendo búsquedas de similitud rápidas y precisas. Son indispensables para aplicaciones como la búsqueda semántica, los sistemas de recomendación y las experiencias de usuario personalizadas.
Al desplegar los LLM, seleccionar una base de datos vectorial robusta que pueda escalar con tu aplicación es clave para mantener el rendimiento y la capacidad de respuesta.
Las plantillas de instrucciones son estructuras predefinidas que ayudan a estandarizar las interacciones con el LLM. Garantizan la coherencia y fiabilidad de las respuestas generadas por el modelo.
Diseñar plantillas de avisos eficaces implica comprender los matices del modelo y los requisitos específicos de tu aplicación. Las plantillas bien elaboradas pueden mejorar significativamente la calidad y pertinencia de los resultados, lo que conduce a una mayor satisfacción de los usuarios.
Desplegar una aplicación LLM implica coordinar varias tareas, como el preprocesamiento de datos, la inferencia del modelo y el postprocesamiento. Las herramientas de gestión del flujo de trabajo y los marcos de orquestación como Apache Airflow o Kubernetes ayudan a automatizar y agilizar estos procesos. Garantizan que cada componente funcione con suavidad y eficacia, reduciendo el riesgo de errores y tiempos de inactividad.
La infraestructura que soporta tu aplicación LLM debe ser robusta y escalable. Esto incluye servicios en la nube, aceleradores de hardware (como GPUs o TPUs) y capacidades de red. La escalabilidad garantiza que tu aplicación pueda soportar cargas y demandas de usuarios cada vez mayores sin comprometer el rendimiento.
Utilizar políticas de autoescalado y estrategias de equilibrio de carga puede ayudar a gestionar los recursos con eficacia y mantener la calidad del servicio.
La supervisión y el registro continuos son fundamentales para mantener la salud y el rendimiento de tu aplicación LLM. Las herramientas de supervisión proporcionan información en tiempo real sobre el rendimiento del sistema, los patrones de uso y los posibles problemas.
Los mecanismos de registro capturan información detallada sobre las operaciones de la aplicación, lo que tiene un valor incalculable para la depuración y la optimización. Juntos, ayudan a garantizar que tu aplicación funcione sin problemas y pueda adaptarse rápidamente a cualquier cambio o anomalía.
El despliegue de los LLM también implica abordar los requisitos de seguridad y cumplimiento. Esto incluye salvaguardar los datos sensibles, implantar controles de acceso y garantizar el cumplimiento de las normativas pertinentes, como el GDPR o la HIPAA. Las medidas de seguridad deben integrarse en todas las capas del proceso de implantación para proteger contra las violaciones de datos y los accesos no autorizados.
Tu aplicación LLM debe integrarse perfectamente con los sistemas y flujos de trabajo existentes. Esto implica garantizar la compatibilidad con otras herramientas de software, API y formatos de datos utilizados en tu organización.
Una integración eficaz mejora la funcionalidad y eficacia generales de tu aplicación, permitiéndole aprovechar los recursos y la infraestructura existentes.
Existen varios enfoques para desplegar los LLM en la producción, cada uno con sus ventajas y retos.
El despliegue in situ implica alojar el LLM en servidores o centros de datos locales, lo que ofrece un mayor control sobre los datos y la infraestructura, pero requiere una inversión significativa en hardware y mantenimiento.
El despliegue basado en la nube aprovecha los servicios en la nube para alojar el LLM, lo que proporciona escalabilidad, flexibilidad y costes iniciales reducidos, aunque puede introducir preocupaciones sobre la privacidad de los datos y los costes operativos continuos.
El despliegue híbrido combina recursos locales y en la nube, ofreciendo un equilibrio entre control y escalabilidad, lo que permite a las organizaciones optimizar el rendimiento y el coste en función de sus necesidades específicas.
Comprender los pros y los contras de cada enfoque es esencial para tomar una decisión informada que se ajuste a los objetivos y recursos de tu organización.
El despliegue de grandes modelos lingüísticos (LLM) en producción requiere un conjunto de herramientas capaces de gestionar diversos aspectos del proceso de despliegue, desde la gestión de la infraestructura hasta la supervisión y la optimización. En esta sección, hablamos de cinco herramientas principales que se utilizan ampliamente para desplegar LLM en producción.
Cada herramienta se evalúa en función de su escalabilidad, facilidad de uso, capacidad de integración y rentabilidad.
LangServe está diseñado específicamente para desplegar aplicaciones LLM. Simplifica el proceso de implantación proporcionando herramientas sólidas para la instalación, integración y optimización. LangServe es compatible con varios LLM y ofrece una integración perfecta con los sistemas existentes.
Kubernetes es una plataforma de orquestación de contenedores de código abierto que automatiza el despliegue, escalado y gestión de aplicaciones en contenedores. Es muy flexible y puede utilizarse para gestionar la infraestructura necesaria para las implantaciones de LLM.
TensorFlow Serving es un sistema de servicio flexible y de alto rendimiento para modelos de aprendizaje automático, diseñado para entornos de producción. Facilita el despliegue de nuevos algoritmos y experimentos, manteniendo la misma arquitectura de servidor y las mismas API.
Amazon SageMaker es un servicio totalmente administrado que proporciona a todos los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar modelos de aprendizaje automático rápidamente. Se integra con otros servicios de AWS, lo que la convierte en una herramienta completa para el despliegue de LLM.
MLflow es una plataforma de código abierto para gestionar el ciclo de vida del ML, incluyendo la experimentación, la reproducibilidad y el despliegue. Proporciona un repositorio central de modelos y puede integrarse con muchas bibliotecas de aprendizaje automático.
|
Herramienta |
Escalabilidad |
Facilidad de uso |
Capacidades de integración |
Rentabilidad |
|
LangServe |
Alta |
Alta |
Excelente |
Moderado |
|
Kubernetes |
Alta |
Moderado |
Excelente |
Alto (Código abierto) |
|
TensorFlow Sirviendo |
Alta |
Moderado |
Excelente |
Alto (Código abierto) |
|
Amazon SageMaker |
Alta |
Alta |
Excelente (con AWS) |
Moderada a alta |
|
MLflow |
Moderada a alta |
Moderado |
Excelente |
Alto (Código abierto) |
LangServe es una herramienta especializada diseñada para simplificar el proceso de despliegue de aplicaciones LLM. En esta sección, proporcionaremos un recorrido técnico sobre el uso de LangServe para desplegar una aplicación chatGPT de resumen de texto.
Para empezar, tenemos que instalar LangServe. Puedes instalar los componentes cliente y servidor o sólo uno de ellos, según tus necesidades.
pip install "langserve[all]"También puedes instalar los componentes individualmente:
install "langserve[client]"install "langserve[server]"La CLI LangChain es una herramienta útil para arrancar rápidamente un proyecto LangServe. Asegúrate de que tienes instalada una versión reciente:
install -U langchain-cliUtiliza la CLI de LangChain para crear una nueva aplicación y cambia tu directorio de trabajo actual a my-app:
app new my-appmy-appLangServe utiliza Poetry para la gestión de dependencias. Si no estás familiarizado con Poesía, consulta la documentación de Poesía para obtener más información.
Para añadir los paquetes correspondientes, utiliza
add langchain-openai langchain langchain communityEste comando garantiza que todas las dependencias necesarias están disponibles para nuestro proyecto.
Asegúrate de configurar las variables de entorno necesarias para nuestra aplicación. En este caso, necesitamos establecer nuestra clave de la API de OpenAI para realizar peticiones válidas:
OPENAI_API_KEY="sk-..."Asegúrate de sustituir "sk-..." por tu clave API real. Puedes crear una clave API a través de la plataforma OpenAI.
Navega hasta el archivo ```server.py``. Contendrá la lógica principal de nuestra aplicación LangServe. Aquí tienes un ejemplo de una aplicación LangServe sencilla que incluye una ruta para resumir texto utilizando el modelo lingüístico de OpenAI:
fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using Langchain's Runnable interfaces",
)
# Define a route for the OpenAI chat model
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
# Define a route with a custom prompt
summarize_prompt = ChatPromptTemplate.from_template("Summarize the following text: {text}")
add_routes(
app,
summarize_prompt | ChatOpenAI(),
path="/summarize",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)Echemos un vistazo más de cerca a los componentes clave de nuestra aplicación básica LangServe:
FastAPI se utiliza para crear el servidor web.ChatPromptTemplate y ChatOpenAI se utilizan desde LangChain para definir las indicaciones y los modelos.add_routes de LangServe se utiliza para añadir rutas a la aplicación FastAPI.FastAPI se inicializa con metadatos como el título, la versión y la descripción.add_routes añade una ruta /openai que interactúa directamente con el modelo de chat de OpenAI.add_routes define una ruta de aviso personalizada /summarize. Esta ruta toma un texto de entrada y utiliza un indicador para generar una versión resumida del texto utilizando el modelo de OpenAI.La función uvicorn.run se utiliza para iniciar el servidor FastAPI en localhost en el puerto 8000.
En este ejemplo, hemos añadido una ruta /summarize que utiliza un indicador para resumir el texto. También puedes ampliar la funcionalidad de tu aplicación LangServe definiendo rutas y avisos adicionales. Por ejemplo:
joke_prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
add_routes(
app,
joke_prompt | ChatOpenAI(),
path="/joke",
)
Por último, utiliza Poesía para servir tu aplicación en el puerto deseado:
run langchain serve --port=8100Si todo está configurado correctamente, deberías ver algo parecido a esto en tu terminal:
 Salida del terminal que muestra el inicio correcto de la aplicación LangServe.
Salida del terminal que muestra el inicio correcto de la aplicación LangServe.
Ahora puedes navegar a http://127.0.0.1:8100/summarize/playground/ en tu navegador. Esta URL proporciona acceso a una interfaz fácil de usar donde puedes probar tu aplicación. T
l patio de recreo te permite ejecutar tu ejecutable, ver el flujo de salida y observar los pasos intermedios, lo que facilita la interacción y la depuración de tu aplicación LLM desplegada.
Ejemplo de la interfaz de usuario del patio de recreo de LangServe
Además, puedes visitar http://127.0.0.1:8100/docs para acceder a la documentación de la API generada automáticamente por FastAPI.
Esta documentación interactiva te permite explorar y probar todos los puntos finales disponibles de tu aplicación LangServe. Puedes ver información detallada sobre cada punto final, incluidas las entradas requeridas y las salidas esperadas, lo que ayuda a comprender cómo interactuar con tu API y para verificar que todas las rutas funcionan correctamente.
Garantizar la fiabilidad, el rendimiento y la precisión de una aplicación LLM (Large Language Model) en producción es crucial. Aunque LangServe carece de funciones de supervisión incorporadas, se integra perfectamente con herramientas muy utilizadas para el seguimiento y análisis del estado de las aplicaciones.
Esta sección ofrece un recorrido técnico sobre cómo utilizar LangServe junto con estas herramientas para mantener y supervisar una aplicación LLM.
El registro es el primer paso para supervisar tu solicitud de LLM. Ayuda a seguir el comportamiento de la aplicación e identificar cualquier anomalía. A continuación te explicamos cómo puedes configurar el registro en tu aplicación FastAPI con LangServe:
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("langchain_server")
app = FastAPI()
# Example of logging within a route
@app.get("/status")
async def status():
logger.info("Status endpoint was called")
return {"status": "Running"}
Con esta configuración, cada llamada al punto final /status registrará un mensaje indicando que se ha accedido al punto final. Esto puede ampliarse para registrar otros eventos y errores significativos.
Prometheus es una popular herramienta de supervisión y alerta. Puede integrarse con FastAPI para recopilar métricas y proporcionar información sobre el rendimiento de la aplicación. A continuación te explicamos cómo puedes configurar Prometheus con LangServe:
install prometheus_clientimport time
from prometheus_client import start_http_server, Summary
from fastapi.middleware import Middleware
# Start Prometheus server
start_http_server(8001)
# Define a Prometheus metric
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
app = FastAPI()
# Middleware for tracking request processing time
@app.middleware("http")
async def add_prometheus_middleware(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
duration = time.time() - start_time
REQUEST_TIME.observe(duration)
return response
Esta configuración iniciará un servidor Prometheus en el puerto 8001 y registrará el tiempo que tarda en procesar cada solicitud.
Prometheus puede configurarse para activar alertas en función de determinadas condiciones, y Grafana puede utilizarse para visualizar estas métricas. Aquí tienes un breve esquema para configurar las alertas:
Crea un archivo llamado alert.rules:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: request_processing_seconds_bucket{le="0.5"} > 0.5
for: 5m
labels:
severity: page
annotations:
summary: High request latency
description: "Request latency is above 0.5 seconds for more than 5 minutes."Actualiza la configuración de Prometheus (prometheus.yml):
rule_files:
- "alert.rules"
Para instalar y configurar Grafana, consulta la documentación de instalación y configuración. Una vez configurado, puedes proceder a crear cuadros de mando y paneles para visualizar métricas como la latencia de las peticiones, las tasas de error, etc.
Las comprobaciones de salud son esenciales para controlar la salud de la aplicación y garantizar que funciona como se espera. Así es como podemos hacer un simple punto final de comprobación de salud:
@app.get("/health")
async def health():
return {"status": "Healthy"}
Este punto final puede ser llamado periódicamente por herramientas de monitorización para asegurarse de que la aplicación está en buen estado.
Capturar y controlar los errores y excepciones es crucial para identificar problemas en la aplicación. A continuación te explicamos cómo puedes ampliar el registro para capturar excepciones:
from fastapi import Request, HTTPException
from fastapi.responses import JSONResponse
@app.exception_handler(Exception)
async def global_exception_handler(request: Request, exc: Exception):
logger.error(f"An error occurred: {exc}")
return JSONResponse(status_code=500, content={"message": "Internal Server Error"})
@app.exception_handler(HTTPException)
async def http_exception_handler(request: Request, exc: HTTPException):
logger.error(f"HTTP error occurred: {exc.detail}")
return JSONResponse(status_code=exc.status_code, content={"message": exc.detail})Con esta configuración, cualquier excepción no controlada se registrará, proporcionando información sobre posibles problemas.
Desplegar grandes modelos lingüísticos (LLM) en producción puede transformar tus aplicaciones, pero el proceso implica navegar por complejidades como la selección de modelos, la gestión de recursos y la integración. LangServe simplifica estos retos, permitiendo a los desarrolladores desplegar, supervisar y mantener aplicaciones LLM de forma eficiente.
Utilizando LangServe, puedes agilizar la implantación, garantizar un rendimiento sólido y lograr una integración perfecta con tus sistemas.
Para profundizar en la creación y despliegue de aplicaciones LLM, considera la posibilidad de explorar el curso Desarrollo de aplicaciones LLM con LangChain en DataCamp. Este recurso cubre temas esenciales, como la creación de chatbot, la integración de datos externos mediante el Lenguaje de Expresión LangChain (LCEL), y mucho más.
Sigue aprendiendo sobre los LLM
programa
programa
Curso