Programa
Desenvolvimento de modelos de idiomas grandes
16 h
A implantação de um modelo de linguagem grande (LLM) na produção pode transformar seu aplicativo, oferecendo recursos avançados de compreensão e geração de linguagem natural. No entanto, esse processo é repleto de desafios que podem atrapalhar até mesmo os desenvolvedores mais experientes.
Neste guia, exploraremos como implantar aplicativos LLM usando o LangServe, uma ferramenta criada para simplificar e agilizar esse processo complexo. Da instalação à integração, você aprenderá as etapas essenciais para implementar com sucesso um LLM e liberar todo o seu potencial.
Criar um aplicativo baseado em LLM é mais complexo do que simplesmente chamar uma API. Embora a integração de um LLM ao seu projeto possa aprimorar significativamente seus recursos, ela vem com um conjunto exclusivo de desafios que exigem consideração cuidadosa. A seguir, detalharemos os principais obstáculos que você poderá encontrar e destacaremos os aspectos da implantação que precisam de atenção.
A seleção do modelo certo para sua aplicação é o primeiro obstáculo. A escolha depende de vários fatores, como a tarefa específica, a precisão necessária e os recursos computacionais disponíveis. Além disso, a personalização de um modelo pré-treinado para atender às necessidades do seu aplicativo pode ser complexa, envolvendo o ajuste fino com dados específicos do domínio.
Os LLMs são computacionalmente intensivos e exigem recursos substanciais. É fundamental garantir que sua infraestrutura possa lidar com os altos requisitos de memória e capacidade de processamento. Isso inclui o planejamento da escalabilidade para acomodar o crescimento futuro e possíveis aumentos no uso.
Conseguir baixa latência é vital para uma experiência de usuário perfeita. Os LLMs podem ser lentos para processar solicitações, especialmente sob cargas pesadas. A otimização do desempenho envolve estratégias como compactação de modelos, estruturas de serviço eficientes e, possivelmente, a transferência de algumas tarefas de processamento para dispositivos de borda.
Uma vez implantado, é necessário o monitoramento contínuo do aplicativo LLM. Isso inclui o acompanhamento de métricas de desempenho, a detecção de anomalias e o gerenciamento de desvios de modelos. A manutenção regular garante que o modelo permaneça preciso e eficiente ao longo do tempo, exigindo atualizações periódicas e retreinamento com novos dados.
A integração dos LLMs aos sistemas e fluxos de trabalho existentes pode ser um desafio. Garantir a compatibilidade com vários ambientes de software, APIs e formatos de dados exige planejamento e execução meticulosos. A integração perfeita é fundamental para que você aproveite todo o potencial dos LLMs em seu aplicativo.
As altas demandas computacionais dos LLMs podem levar a custos operacionais significativos. Equilibrar o desempenho com a eficiência de custo é uma consideração vital. As estratégias para gerenciar os custos incluem a otimização da alocação de recursos, o uso de serviços de nuvem econômicos e a revisão regular dos padrões de uso para identificar áreas de economia.
A implementação de um LLM na produção é um processo complexo que envolve a orquestração de vários sistemas e componentes. Isso vai além da simples integração de um modelo de linguagem avançado ao seu aplicativo; requer uma infraestrutura coesa em que cada parte desempenha um papel fundamental.
Para entender os meandros da implantação de aplicativos LLM, é fundamental explorar os vários componentes envolvidos e suas interações. O diagrama a seguir ilustra a arquitetura de um aplicativo LLM moderno, destacando os principais elementos e suas relações dentro do sistema.
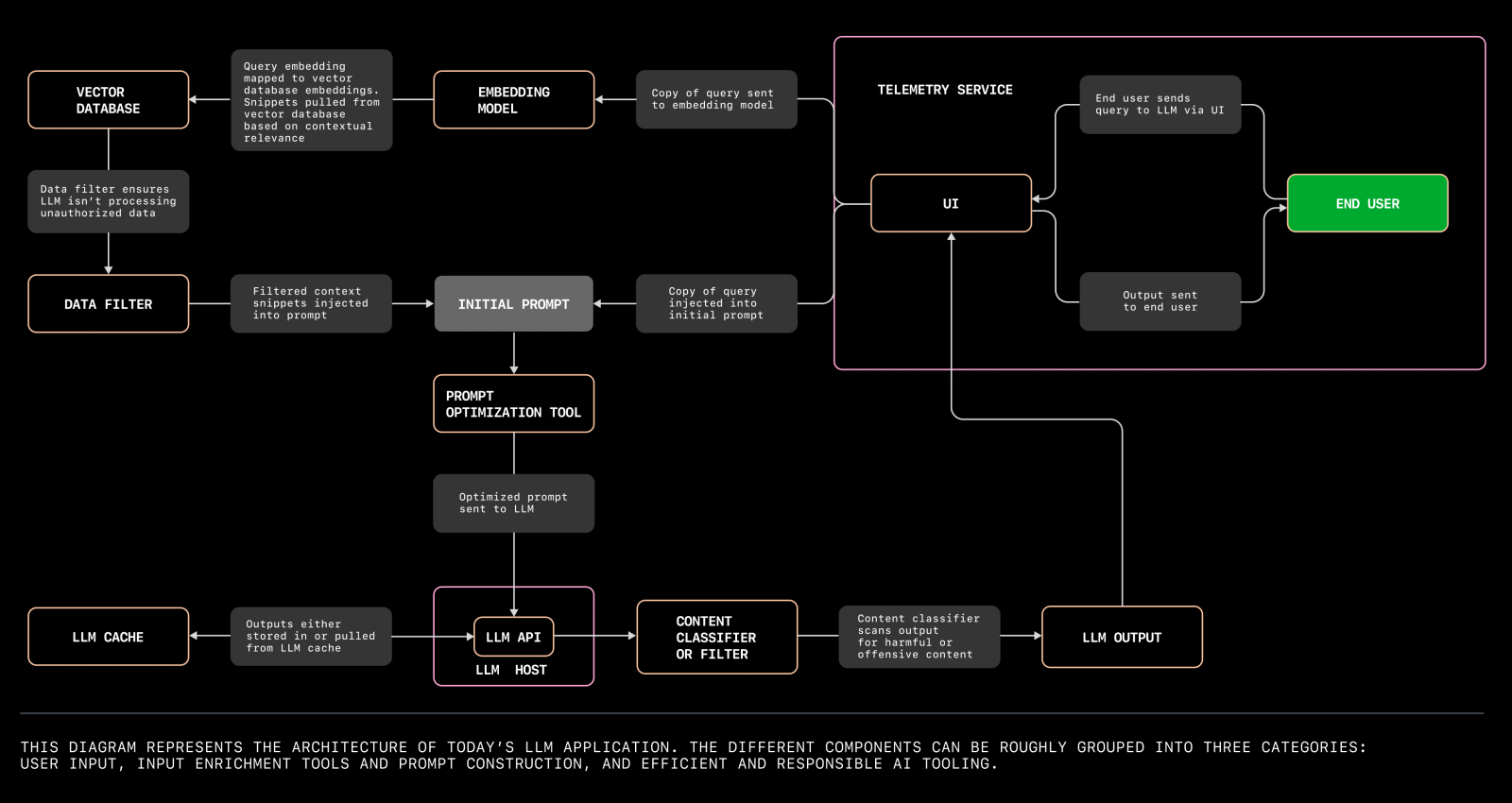
Um diagrama que ilustra a arquitetura de um aplicativo LLM moderno. Fonte
A arquitetura de um aplicativo LLM pode ser dividida em vários aspectos principais:
Os bancos de dados vetoriais são fundamentais para gerenciar os dados de alta dimensão gerados pelos LLMs. Esses bancos de dados armazenam e recuperam vetores de forma eficiente, permitindo pesquisas de similaridade rápidas e precisas. Eles são indispensáveis para aplicativos como pesquisa semântica, sistemas de recomendação e experiências de usuário personalizadas.
Ao implementar LLMs, a seleção de um banco de dados vetorial robusto que possa ser dimensionado com o aplicativo é fundamental para manter o desempenho e a capacidade de resposta.
Os modelos de prompt são estruturas predefinidas que ajudam a padronizar as interações com o LLM. Eles garantem consistência e confiabilidade nas respostas geradas pelo modelo.
A criação de modelos de prompt eficazes envolve a compreensão das nuances do modelo e dos requisitos específicos do seu aplicativo. Modelos bem elaborados podem melhorar significativamente a qualidade e a relevância dos resultados, levando a uma maior satisfação do usuário.
A implantação de um aplicativo LLM envolve a coordenação de várias tarefas, como o pré-processamento de dados, a inferência de modelos e o pós-processamento. As ferramentas de gerenciamento de fluxo de trabalho e as estruturas de orquestração, como o Apache Airflow ou o Kubernetes, ajudam a automatizar e otimizar esses processos. Eles garantem que cada componente opere de forma suave e eficiente, reduzindo o risco de erros e tempo de inatividade.
A infraestrutura que dá suporte ao seu aplicativo LLM deve ser robusta e escalonável. Isso inclui serviços de nuvem, aceleradores de hardware (como GPUs ou TPUs) e recursos de rede. A escalabilidade garante que seu aplicativo possa lidar com cargas e demandas de usuários cada vez maiores sem comprometer o desempenho.
A utilização de políticas de dimensionamento automático e estratégias de balanceamento de carga pode ajudar a gerenciar os recursos com eficiência e manter a qualidade do serviço.
O monitoramento e o registro contínuos são essenciais para manter a integridade e o desempenho do seu aplicativo LLM. As ferramentas de monitoramento fornecem informações em tempo real sobre o desempenho do sistema, padrões de uso e possíveis problemas.
Os mecanismos de registro capturam informações detalhadas sobre as operações do aplicativo, o que é inestimável para depuração e otimização. Juntos, eles ajudam a garantir que seu aplicativo seja executado sem problemas e possa se adaptar rapidamente a quaisquer alterações ou anomalias.
A implementação de LLMs também envolve a abordagem de requisitos de segurança e conformidade. Isso inclui a proteção de dados confidenciais, a implementação de controles de acesso e a garantia de conformidade com regulamentos relevantes, como GDPR ou HIPAA. As medidas de segurança devem ser integradas em todas as camadas do processo de implementação para proteger contra violações de dados e acesso não autorizado.
Seu aplicativo LLM deve se integrar perfeitamente aos sistemas e fluxos de trabalho existentes. Isso envolve garantir a compatibilidade com outras ferramentas de software, APIs e formatos de dados usados em sua organização.
A integração eficaz aprimora a funcionalidade e a eficiência gerais do seu aplicativo, permitindo que ele aproveite os recursos e a infraestrutura existentes.
Há várias abordagens para a implantação de LLMs na produção, cada uma com suas vantagens e desafios.
A implementação no local envolve a hospedagem do LLM em servidores ou data centers locais, oferecendo maior controle sobre os dados e a infraestrutura, mas exigindo um investimento significativo em hardware e manutenção.
A implementação baseada em nuvem aproveita os serviços de nuvem para hospedar o LLM, fornecendo escalabilidade, flexibilidade e custos iniciais reduzidos, embora possa trazer preocupações sobre a privacidade dos dados e os custos operacionais contínuos.
A implementação híbrida combina recursos no local e na nuvem, oferecendo um equilíbrio entre controle e escalabilidade, permitindo que as organizações otimizem o desempenho e o custo com base em suas necessidades específicas.
Compreender os prós e os contras de cada abordagem é essencial para que você tome uma decisão informada que se alinhe às metas e aos recursos da sua organização.
A implantação de grandes modelos de linguagem (LLMs) na produção requer um conjunto de ferramentas que possa lidar com vários aspectos do processo de implantação, desde o gerenciamento da infraestrutura até o monitoramento e a otimização. Nesta seção, discutiremos cinco ferramentas principais que são amplamente usadas para implantar LLMs na produção.
Cada ferramenta é avaliada com base na escalabilidade, facilidade de uso, recursos de integração e custo-benefício.
O LangServe foi projetado especificamente para a implantação de aplicativos LLM. Ele simplifica o processo de implementação, fornecendo ferramentas robustas para instalação, integração e otimização. O LangServe oferece suporte a vários LLMs e oferece uma integração perfeita com os sistemas existentes.
O Kubernetes é uma plataforma de orquestração de contêineres de código aberto que automatiza a implantação, o dimensionamento e o gerenciamento de aplicativos em contêineres. Ele é altamente flexível e pode ser usado para gerenciar a infraestrutura necessária para implementações do LLM.
O TensorFlow Serving é um sistema de serviço flexível e de alto desempenho para modelos de machine learning, projetado para ambientes de produção. Isso facilita a implementação de novos algoritmos e experimentos, mantendo a mesma arquitetura de servidor e APIs.
O Amazon SageMaker é um serviço totalmente gerenciado que oferece a todos os desenvolvedores e cientistas de dados a capacidade de criar, treinar e implementar modelos de machine learning rapidamente. Ele se integra a outros serviços do AWS, o que o torna uma ferramenta abrangente para a implementação do LLM.
O MLflow é uma plataforma de código aberto para gerenciar o ciclo de vida do ML, incluindo experimentação, reprodutibilidade e implantação. Ele fornece um repositório central para modelos e pode ser integrado a muitas bibliotecas de machine learning.
|
Ferramenta |
Escalabilidade |
Facilidade de uso |
Recursos de integração |
Eficácia de custo |
|
LangServe |
Alta |
Alta |
Excelente |
Moderado |
|
Kubernetes |
Alta |
Moderado |
Excelente |
Alta (código aberto) |
|
Serviço de TensorFlow |
Alta |
Moderado |
Excelente |
Alta (código aberto) |
|
Amazon SageMaker |
Alta |
Alta |
Excelente (com AWS) |
Moderado a alto |
|
MLflow |
Moderado a alto |
Moderado |
Excelente |
Alta (código aberto) |
O LangServe é uma ferramenta especializada projetada para simplificar o processo de implementação de aplicativos LLM. Nesta seção, apresentaremos um passo a passo técnico sobre como usar o LangServe para implantar um aplicativo chatGPT para resumir textos.
Para começar, precisamos instalar o LangServe. Você pode instalar os componentes do cliente e do servidor ou apenas um deles, dependendo de suas necessidades.
pip install "langserve[all]"Como alternativa, você pode instalar os componentes individualmente:
install "langserve[client]"install "langserve[server]"A CLI do LangChain é uma ferramenta útil para você iniciar rapidamente um projeto LangServe. Verifique se você tem uma versão recente instalada:
install -U langchain-cliUse a CLI do LangChain para criar um novo aplicativo e alterar o diretório de trabalho atual para my-app:
app new my-appmy-appA LangServe usa o Poetry para o gerenciamento de dependências. Se você não estiver familiarizado com o Poetry, consulte a documentação do Poetry para obter mais informações.
Para adicionar os pacotes relevantes, use:
add langchain-openai langchain langchain communityEsse comando garante que todas as dependências necessárias estejam disponíveis para o nosso projeto.
Certifique-se de que você configurou as variáveis de ambiente necessárias para o nosso aplicativo. Nesse caso, precisamos definir nossa chave de API da OpenAI para fazer solicitações válidas:
OPENAI_API_KEY="sk-..."Certifique-se de substituir "sk-..." pela sua chave de API real. Você pode criar uma chave de API por meio da plataforma OpenAI.
Navegue até o arquivo ```server.py``. Isso conterá a lógica principal do nosso aplicativo LangServe. Aqui está um exemplo de um aplicativo LangServe simples que inclui uma rota para resumir o texto usando o modelo de linguagem da OpenAI:
fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using Langchain's Runnable interfaces",
)
# Define a route for the OpenAI chat model
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
# Define a route with a custom prompt
summarize_prompt = ChatPromptTemplate.from_template("Summarize the following text: {text}")
add_routes(
app,
summarize_prompt | ChatOpenAI(),
path="/summarize",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)Vamos dar uma olhada mais de perto nos principais componentes do nosso aplicativo LangServe básico:
FastAPI é usado para criar o servidor da Web.ChatPromptTemplate e ChatOpenAI são usados na LangChain para definir prompts e modelos.add_routes do LangServe é usado para adicionar rotas ao aplicativo FastAPI.FastAPI é inicializado com metadados como título, versão e descrição.add_routes adiciona uma rota /openai que faz interface direta com o modelo de bate-papo da OpenAI.add_routes define uma rota de prompt personalizada /summarize. Essa rota recebe um texto de entrada e usa um prompt para gerar uma versão resumida do texto usando o modelo da OpenAI.A função uvicorn.run é usada para iniciar o servidor FastAPI em localhost na porta 8000.
Neste exemplo, adicionamos uma rota /summarize que usa um prompt para resumir o texto. Você também pode ampliar a funcionalidade do seu aplicativo LangServe definindo rotas e prompts adicionais. Por exemplo:
joke_prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
add_routes(
app,
joke_prompt | ChatOpenAI(),
path="/joke",
)
Por fim, use o Poetry para servir seu aplicativo na porta desejada:
run langchain serve --port=8100Se tudo estiver configurado corretamente, você deverá ver algo semelhante a isso no terminal:
 Saída do terminal mostrando a inicialização bem-sucedida do aplicativo LangServe.
Saída do terminal mostrando a inicialização bem-sucedida do aplicativo LangServe.
Agora você pode navegar para http://127.0.0.1:8100/summarize/playground/ em seu navegador. Esse URL fornece acesso a uma interface amigável na qual você pode testar seu aplicativo. T
O playground permite que você execute seu executável, visualize a saída de streaming e observe as etapas intermediárias, facilitando a interação e a depuração do seu aplicativo LLM implantado.
Exemplo da interface do usuário do playground do LangServe
Além disso, você pode visitar http://127.0.0.1:8100/docs para acessar a documentação da API gerada automaticamente fornecida pela FastAPI.
Essa documentação interativa permite que você explore e teste todos os endpoints disponíveis do seu aplicativo LangServe. Você pode ver informações detalhadas sobre cada endpoint, incluindo as entradas necessárias e as saídas esperadas, o que ajuda a entender como interagir com sua API e a verificar se todas as rotas estão funcionando corretamente.
É fundamental garantir a confiabilidade, o desempenho e a precisão de um aplicativo Large Language Model (LLM) em produção. Embora o LangServe não tenha recursos de monitoramento incorporados, ele se integra perfeitamente a ferramentas amplamente usadas para rastrear e analisar a integridade dos aplicativos.
Esta seção oferece um passo a passo técnico sobre como usar o LangServe em conjunto com essas ferramentas para manter e supervisionar um aplicativo LLM.
O registro é a primeira etapa do monitoramento do seu aplicativo LLM. Ele ajuda a rastrear o comportamento do aplicativo e a identificar anomalias. Veja como você pode configurar o registro em seu aplicativo FastAPI com o LangServe:
import logging
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("langchain_server")
app = FastAPI()
# Example of logging within a route
@app.get("/status")
async def status():
logger.info("Status endpoint was called")
return {"status": "Running"}
Com essa configuração, cada chamada para o ponto de extremidade /status registrará uma mensagem indicando que o ponto de extremidade foi acessado. Isso pode ser estendido para registrar outros eventos e erros significativos.
O Prometheus é uma ferramenta popular para monitoramento e emissão de alertas. Ele pode ser integrado ao FastAPI para coletar métricas e fornecer insights sobre o desempenho do aplicativo. Veja como você pode configurar o Prometheus com o LangServe:
install prometheus_clientimport time
from prometheus_client import start_http_server, Summary
from fastapi.middleware import Middleware
# Start Prometheus server
start_http_server(8001)
# Define a Prometheus metric
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
app = FastAPI()
# Middleware for tracking request processing time
@app.middleware("http")
async def add_prometheus_middleware(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
duration = time.time() - start_time
REQUEST_TIME.observe(duration)
return response
Essa configuração iniciará um servidor Prometheus na porta 8001 e registrará o tempo que você leva para processar cada solicitação.
O Prometheus pode ser configurado para acionar alertas com base em determinadas condições, e o Grafana pode ser usado para visualizar essas métricas. Aqui está um breve resumo para você configurar alertas:
Crie um arquivo chamado alert.rules:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: request_processing_seconds_bucket{le="0.5"} > 0.5
for: 5m
labels:
severity: page
annotations:
summary: High request latency
description: "Request latency is above 0.5 seconds for more than 5 minutes."Atualize a configuração do Prometheus (prometheus.yml):
rule_files:
- "alert.rules"
Para instalar e configurar o Grafana, consulte a documentação de instalação e configuração. Depois de configurado, você pode criar painéis e dashboards para visualizar métricas como latência de solicitação, taxas de erro etc.
As verificações de integridade são essenciais para monitorar a integridade do aplicativo e garantir que ele esteja sendo executado conforme o esperado. Veja como podemos fazer um endpoint simples de verificação de integridade:
@app.get("/health")
async def health():
return {"status": "Healthy"}
Esse ponto de extremidade pode ser chamado periodicamente por ferramentas de monitoramento para garantir que o aplicativo esteja íntegro.
Capturar e monitorar erros e exceções é fundamental para identificar problemas no aplicativo. Veja como você pode estender o registro em log para capturar exceções:
from fastapi import Request, HTTPException
from fastapi.responses import JSONResponse
@app.exception_handler(Exception)
async def global_exception_handler(request: Request, exc: Exception):
logger.error(f"An error occurred: {exc}")
return JSONResponse(status_code=500, content={"message": "Internal Server Error"})
@app.exception_handler(HTTPException)
async def http_exception_handler(request: Request, exc: HTTPException):
logger.error(f"HTTP error occurred: {exc.detail}")
return JSONResponse(status_code=exc.status_code, content={"message": exc.detail})Com essa configuração, qualquer exceção não tratada será registrada, fornecendo insights sobre possíveis problemas.
A implantação de grandes modelos de linguagem (LLMs) na produção pode transformar seus aplicativos, mas o processo envolve a navegação em complexidades como seleção de modelos, gerenciamento de recursos e integração. O LangServe simplifica esses desafios, permitindo que os desenvolvedores implantem, monitorem e mantenham aplicativos LLM com eficiência.
Com o LangServe, você pode agilizar a implantação, garantir um desempenho robusto e obter uma integração perfeita com seus sistemas.
Para se aprofundar na criação e implantação de aplicativos LLM, considere a possibilidade de explorar o curso Developing LLM Applications with LangChain no DataCamp. Esse recurso aborda tópicos essenciais, incluindo a criação de chatbot, a integração de dados externos usando a LangChain Expression Language (LCEL) e muito mais.
Continue aprendendo sobre LLMs
Programa
Programa
Curso
blog
Abid Ali Awan
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Moez Ali
