programa
Fundamentos de la IA
10 h
El auge del desarrollo de la Inteligencia Artificial (IA) ha creado un notable aumento de las demandas informáticas, impulsando la necesidad de soluciones de hardware robustas. Las Unidades de Procesamiento Gráfico (GPU) y las Unidades de Procesamiento Tensorial (TPU) han surgido como tecnologías fundamentales para dar respuesta a estas demandas.
Diseñadas originalmente para renderizar gráficos, las GPU han evolucionado hasta convertirse en procesadores versátiles capaces de manejar tareas de IA de forma eficiente gracias a su capacidad de procesamiento paralelo. En cambio, las TPU, desarrolladas por Google, están optimizadas específicamente para los cálculos de IA, ofreciendo un rendimiento superior adaptado a tareas como los proyectos de aprendizaje automático.
En este artículo, hablaremos de las GPU frente a las TPU y compararemos las dos tecnologías basándonos en métricas como el rendimiento, el coste, el ecosistema y mucho más. También te daremos un resumen de su eficiencia energética, impacto medioambiental y escalabilidad en aplicaciones empresariales.
Las GPU son procesadores especializados desarrollados inicialmente para renderizar imágenes y gráficos en ordenadores y consolas de videojuegos. Funcionan dividiendo los problemas complejos en varias tareas y trabajando en ellas simultáneamente en lugar de una a una, como ocurre en las CPU.
Debido a su potencia de procesamiento paralelo, sus capacidades han evolucionado significativamente más allá del procesamiento gráfico, convirtiéndose en componentes integrales de diversas aplicaciones informáticas, como el desarrollo de modelos de IA.
Pero rebobinemos un poco.
Las GPU aparecieron por primera vez en la década de 1980 como hardware especializado para acelerar el renderizado de gráficos. Empresas como NVIDIA y ATI (ahora parte de AMD) desempeñaron papeles fundamentales en su desarrollo. Sin embargo, no ganaron popularidad hasta finales de la década de 1990 y principios de la de 2000. Su adopción se debió a la introducción de los sombreadores programables, que permitían a los desarrolladores aprovechar el procesamiento paralelo para tareas más allá de los gráficos.
En la década de 2000, más investigaciones exploraron las GPU para tareas de cálculo de propósito general más allá de los gráficos. La arquitectura CUDA (Compute Unified Device Architecture) de NVIDIA y el SDK Stream de AMD permitieron a los desarrolladores aprovechar la potencia de procesamiento de la GPU para simulaciones científicas, análisis de datos y mucho más.
Luego llegó el auge de la IA y el aprendizaje profundo.
Las GPU se han convertido en herramientas indispensables para entrenar y desplegar modelos de aprendizaje profundo debido a su capacidad para manejar cantidades masivas de datos y realizar cálculos en paralelo.
Frameworks como TensorFlow y PyTorch utilizan la aceleración de la GPU, haciendo que el aprendizaje profundo sea accesible a investigadores y desarrolladores de todo el mundo.
Las Unidades de Procesamiento Tensorial (TPU) son un tipo de circuito integrado de aplicación específica (ASIC) creado por Google para hacer frente a las crecientes demandas computacionales del aprendizaje automático.
A diferencia de las GPU, que se crearon inicialmente para tareas de procesamiento gráfico y posteriormente se modificaron para adaptarse a las exigencias de la IA, las TPU se diseñaron específicamente para acelerar las cargas de trabajo de aprendizaje automático.
Dado que se diseñaron para el aprendizaje automático, las TPU están diseñadas específicamente para las operaciones tensoriales, que son fundamentales para los algoritmos de aprendizaje profundo.
Gracias a su arquitectura personalizada optimizada para la multiplicación de matrices, una operación clave en las redes neuronales, destacan en el procesamiento de grandes volúmenes de datos y en la ejecución eficaz de redes neuronales complejas, lo que permite tiempos de entrenamiento e inferencia rápidos.
Esta optimización especializada hace que las TPU sean indispensables para las aplicaciones de IA, impulsando los avances en la investigación y el despliegue del aprendizaje automático.
Las TPU y las GPU ofrecen ventajas distintas y están optimizadas para diferentes tareas computacionales. Aunque ambos pueden acelerar las cargas de trabajo de aprendizaje automático, sus arquitecturas y optimizaciones dan lugar a variaciones en el rendimiento dependiendo de la tarea específica.
Para empezar, tanto las GPU como las TPU son aceleradores de hardware especializados diseñados para mejorar el rendimiento en tareas de IA, pero difieren en sus arquitecturas computacionales, lo que influye significativamente en su eficiencia y eficacia a la hora de manejar tipos específicos de cálculos.
Las GPU están formadas por miles de núcleos pequeños y eficientes diseñados para el procesamiento paralelo.
Esta arquitectura les permite ejecutar múltiples tareas simultáneamente, lo que las hace muy eficaces para tareas que pueden paralelizarse, como el renderizado de gráficos y el aprendizaje profundo.
Las GPU son especialmente hábiles en las operaciones matriciales, que son frecuentes en los cálculos de redes neuronales. Su capacidad para manejar grandes volúmenes de datos y ejecutar cálculos en paralelo los hace muy adecuados para tareas de IA que impliquen el procesamiento de conjuntos de datos masivos y la ejecución de operaciones matemáticas complejas.
En cambio, las TPU dan prioridad a las operaciones tensoriales, lo que les permite realizar cálculos de forma eficiente. Aunque las TPU no tengan tantos núcleos como las GPU, su arquitectura especializada les permite superar a las GPU en ciertos tipos de tareas de IA, especialmente las que dependen en gran medida de operaciones tensoriales.
Dicho esto, las GPU destacan en tareas que se benefician del procesamiento paralelo y son muy adecuadas para diversos cálculos más allá de la IA, como el renderizado de gráficos y las simulaciones científicas.
Por otro lado, las TPU están optimizadas para el procesamiento tensorial, lo que las hace muy eficientes para las tareas de aprendizaje profundo que implican operaciones matriciales. Dependiendo de los requisitos específicos de la carga de trabajo de IA, las GPU o las TPU pueden ofrecer mejor rendimiento y eficiencia.
Las GPU son conocidas por su versatilidad en el manejo de diversas tareas de IA, incluido el entrenamiento de modelos de aprendizaje profundo y la realización de operaciones de inferencia. Esto se debe a que la arquitectura de la GPU, que se basa en el procesamiento paralelo, aumenta significativamente la velocidad de entrenamiento e inferencia en numerosos modelos de IA. Por ejemplo, procesar un lote de 128 secuencias con un modelo BERT lleva 3,8 milisegundos en una GPU V100, frente a 1,7 milisegundos en una TPU v3.
A la inversa, las TPU están afinadas para realizar operaciones tensoriales rápidas y eficaces, componentes cruciales de las redes neuronales. Esta especialización a menudo permite a las TPU superar a las GPU en tareas específicas de aprendizaje profundo, en particular las optimizadas por Google, como el entrenamiento extensivo de redes neuronales y modelos complejos de aprendizaje automático.
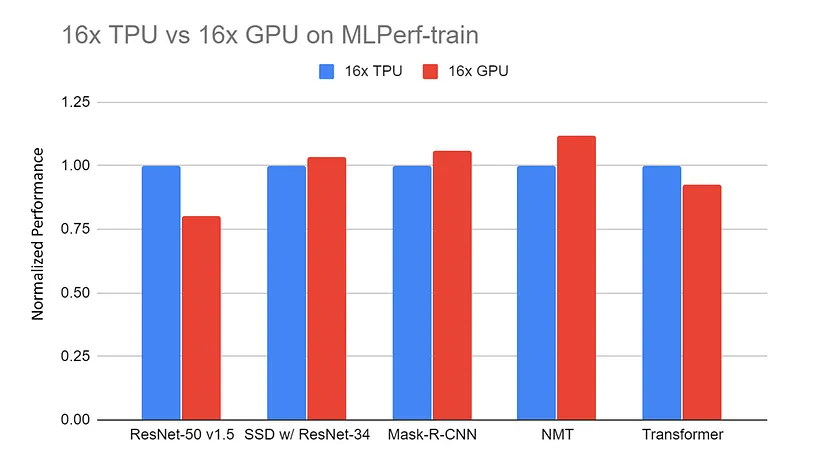
Rendimiento normalizado del servidor 16x GPU (DGX-2H) frente al servidor 16x TPU v3 en las pruebas de referencia MLPerf-train. Los datos se recogen del sitio web MLPerf. Todos los resultados de la TPU utilizan TensorFlow. Todos los resultados de la GPU utilizan Pytorch, excepto ResNet que utiliza MxNet |
Fuente: TPU vs. GPU vs Cerebras vs Graphcore: Una comparación justa entre el hardware de ML por Mahmoud Khairy
Las comparaciones entre TPUs y GPUs en tareas similares revelan con frecuencia que las TPUs superan a las GPUs en tareas específicamente adaptadas a su arquitectura, proporcionando duraciones de entrenamiento más rápidas y un procesamiento más eficaz.
Por ejemplo, entrenar un modelo ResNet-50 en el conjunto de datos CIFAR-10 durante 10 épocas utilizando una GPU NVIDIA Tesla V100 lleva aproximadamente 40 minutos, con una media de 4 minutos por época. En cambio, utilizando una TPU v3 de Google Cloud, el mismo entrenamiento sólo lleva 15 minutos, con una media de 1,5 minutos por epoch.
No obstante, las GPU conservan un rendimiento competitivo en un espectro más amplio de aplicaciones gracias a su adaptabilidad y a los considerables esfuerzos de optimización emprendidos por la comunidad.
La elección entre GPU y TPU depende del presupuesto, las necesidades informáticas y la disponibilidad. Cada opción ofrece ventajas únicas para distintas aplicaciones. En esta sección, veremos cómo se comparan las GPU y las TPU en términos de coste y accesibilidad al mercado.
Las GPU ofrecen mucha más flexibilidad que las TPU en cuanto a costes. Para empezar, las TPU no se venden individualmente; sólo están disponibles como servicio en la nube a través de proveedores como Google Cloud Platform (GCP). En cambio, las GPU se pueden comprar individualmente.
El coste aproximado de una GPU NVIDIA Tesla V100 oscila entre 8.000 y 10.000 dólares por unidad, y el de una GPU NVIDIA A100 entre 10.000 y 15.000 dólares. Pero también tienes la opción del precio en la nube bajo demanda.
Utilizar la GPU NVIDIA Tesla V100 para entrenar un modelo de aprendizaje profundo probablemente te costará unos 2,48 $ por hora, y la NVIDIA A100 unos 2,93 $. Por otro lado, la TPU V3 de Google Cloud costaría unos 4,50 $ por hora, y la TPU V4 de Google Cloud costará aproximadamente 8,00 $ por hora.
En otras palabras, las TPU son mucho menos flexibles que las GPU y, por lo general, tienen unos costes por hora de computación en la nube bajo demanda más elevados que las GPU. Sin embargo, las TPU suelen ofrecer un rendimiento más rápido, lo que puede reducir el tiempo total de cálculo necesario para las tareas de aprendizaje automático a gran escala, lo que puede suponer un ahorro de costes generales a pesar de las tarifas horarias más elevadas.
La disponibilidad de TPUs y GPUs en el mercado varía mucho, lo que influye en su adopción en diferentes industrias y regiones...
Las TPU, desarrolladas por Google, son accesibles principalmente a través de Google Cloud Platform (GCP) para tareas de IA basadas en la nube. Esto significa que son utilizados principalmente por personas que confían en GCP para sus necesidades informáticas, lo que podría hacerlos más populares en zonas e industrias grandes en computación en nube, como centros tecnológicos o lugares con fuertes conexiones a Internet.
Mientras tanto, las GPU las fabrican empresas como NVIDIA, AMD e Intel, y están disponibles en varias opciones tanto para consumidores como para empresas. Esta mayor disponibilidad hace que las GPU sean una opción popular en diversos sectores, como los juegos, la ciencia, las finanzas, la sanidad y la fabricación. Las GPU pueden instalarse en las propias instalaciones o en la nube, lo que da a los usuarios flexibilidad en su configuración informática.
En consecuencia, es más probable que las GPU se utilicen en distintos sectores y regiones, independientemente de su infraestructura tecnológica o sus necesidades informáticas. En general, la disponibilidad de TPU y GPU en el mercado influye en su adopción. Las TPU son más comunes en áreas y sectores centrados en la nube (por ejemplo, el aprendizaje automático), mientras que las GPU se utilizan ampliamente en distintos campos y lugares.
Las TPU de Google están estrechamente integradas con TensorFlow, su principal marco de aprendizaje automático de código abierto. JAX, otra biblioteca para la computación numérica de alto rendimiento, también es compatible con las TPU, lo que permite un aprendizaje automático y una computación científica eficientes.
Las TPU están perfectamente integradas en el ecosistema TensorFlow, lo que facilita a los usuarios de TensorFlow el aprovechamiento de las capacidades de las TPU. Por ejemplo, TensorFlow ofrece herramientas como el compilador TensorFlow XLA (Álgebra Lineal Acelerada), que optimiza los cálculos para las TPU.
En esencia, las TPU están diseñadas para acelerar las operaciones de TensorFlow, proporcionando un rendimiento optimizado para el entrenamiento y la inferencia. También son compatibles con las API de alto nivel de TensorFlow, lo que facilita la migración y optimización de modelos para su ejecución en TPU.
En cambio, las GPU se han adoptado ampliamente en diversas industrias y campos de investigación, lo que las hace populares para diversas aplicaciones de aprendizaje automático. Esto significa que tienen más integraciones que las GPU y son compatibles con una gama más amplia de marcos de aprendizaje profundo, como TensorFlow, PyTorch, Keras, MXNet y Caffe.
Las GPU también se benefician de amplias bibliotecas y herramientas como CUDA, cuDNN y RAPIDS, lo que aumenta aún más su versatilidad y facilidad de integración en diversos flujos de trabajo de aprendizaje automático y ciencia de datos.
En cuanto al apoyo de la comunidad, las GPU tienen un ecosistema más amplio con amplios foros, tutoriales y documentación disponible de diversas fuentes como NVIDIA, AMD y plataformas impulsadas por la comunidad. Los desarrolladores pueden acceder a vibrantes comunidades en línea, foros y grupos de usuarios para buscar ayuda, compartir conocimientos y colaborar en proyectos. Además, numerosos tutoriales, cursos y recursos de documentación cubren la programación en la GPU, los marcos de aprendizaje profundo y las técnicas de optimización.
El apoyo de la comunidad a las TPU está más centralizado en torno al ecosistema de Google, con recursos disponibles principalmente a través de la documentación, los foros y los canales de apoyo de GCP. Aunque Google proporciona documentación exhaustiva y tutoriales específicamente adaptados para utilizar las TPU con TensorFlow, el apoyo de la comunidad puede ser más limitado que el del ecosistema de GPU más amplio. Sin embargo, los canales de soporte oficiales de Google y los recursos para desarrolladores siguen ofreciendo una valiosa ayuda a los desarrolladores que utilizan las TPU para cargas de trabajo de IA.
La eficiencia energética de las GPUs y TPUs varía en función de sus arquitecturas y aplicaciones previstas. En general, las TPUs son más eficientes energéticamente que las GPUs, en particular la Google Cloud TPU v3, que es significativamente más eficiente energéticamente que las GPUs NVIDIA de gama alta.
Para más contexto:
El menor consumo de energía de las TPU puede contribuir a unos costes operativos mucho más bajos y a una mayor eficiencia energética, especialmente en despliegues de aprendizaje automático a gran escala.
Las TPUs y GPUs emplean optimizaciones específicas para mejorar la eficiencia energética al realizar operaciones de IA a gran escala.
Como se ha mencionado antes en el artículo, la arquitectura de la TPU está diseñada para dar prioridad a las operaciones tensoriales utilizadas habitualmente en las redes neuronales, lo que permite la ejecución eficiente de tareas de IA con un consumo mínimo de energía. Las TPU también incorporan jerarquías de memoria personalizadas y optimizadas para los cálculos de IA, lo que reduce la latencia de acceso a la memoria y la sobrecarga energética.
Aprovechan técnicas como la cuantización y la dispersión para optimizar las operaciones aritméticas, minimizando el consumo de energía sin sacrificar la precisión. Estos factores permiten a los TPU ofrecer un alto rendimiento conservando la energía.
Del mismo modo, las GPU implementan optimizaciones energéticamente eficientes para mejorar el rendimiento en las operaciones de IA. Las modernas arquitecturas de GPU incorporan funciones como el control de potencia y el escalado dinámico de voltaje y frecuencia (DVFS) para ajustar el consumo de energía en función de las demandas de la carga de trabajo. También utilizan técnicas de procesamiento paralelo para distribuir las tareas de cálculo entre varios núcleos, maximizando el rendimiento y minimizando la energía por operación.
Los fabricantes de GPU desarrollan arquitecturas de memoria y jerarquías de caché energéticamente eficientes para optimizar los patrones de acceso a la memoria y reducir el consumo de energía durante las transferencias de datos. Estas optimizaciones, combinadas con técnicas de software como la fusión de núcleos y el desenrollado de bucles, mejoran aún más la eficiencia energética en las cargas de trabajo de IA aceleradas por GPU.
Tanto las TPU como las GPU ofrecen escalabilidad para grandes proyectos de IA, pero lo enfocan de forma diferente. Las TPU están estrechamente integradas en la infraestructura de la nube, en particular a través de Google Cloud Platform (GCP), ofreciendo recursos escalables para cargas de trabajo de IA. Los usuarios pueden acceder a las TPU bajo demanda, ampliándolas o reduciéndolas en función de las necesidades computacionales, lo que resulta crucial para gestionar con eficacia proyectos de IA a gran escala. Google proporciona servicios gestionados y entornos preconfigurados para desplegar modelos de IA en las TPU, simplificando el proceso de integración en la infraestructura de la nube.
Por otro lado, las GPU también se escalan eficazmente para grandes proyectos de IA, con opciones de implantación local o utilización en entornos de nube ofrecidos por proveedores como Amazon Web Services (AWS) y Microsoft Azure. Las GPU ofrecen flexibilidad en el escalado, lo que permite a los usuarios instalar varias GPU en paralelo para aumentar la potencia de cálculo.
Además, las GPU destacan en el manejo de grandes conjuntos de datos gracias a su gran ancho de banda de memoria y capacidad de procesamiento paralelo. Esto permite un procesamiento eficaz de los datos y el entrenamiento de los modelos, lo que es esencial para los proyectos de IA a gran escala que trabajan con grandes conjuntos de datos.
En general, tanto las TPU como las GPU ofrecen escalabilidad para grandes proyectos de IA, con las TPU estrechamente integradas en la infraestructura de la nube y las GPU proporcionando flexibilidad para la implantación en las instalaciones o en la nube. Su capacidad para manejar grandes conjuntos de datos y escalar los recursos informáticos los hace inestimables para abordar tareas complejas de IA a escala.
| Función | GPUs | TPUs |
|---|---|---|
| Arquitectura computacional | Miles de núcleos pequeños y eficientes para el procesamiento paralelo | Priorizar las operaciones tensoriales, arquitectura especializada |
| Rendimiento | Versátil, sobresale en varias tareas de IA, incluido el aprendizaje profundo y la inferencia | Optimizados para operaciones tensoriales, a menudo superan a las GPU en tareas específicas de aprendizaje profundo |
| Velocidad y eficacia | Por ejemplo, 128 secuencias con el modelo BERT: 3,8 ms en la GPU V100 | Por ejemplo, 128 secuencias con el modelo BERT: 1,7 ms en TPU v3 |
| Puntos de referencia | ResNet-50 en CIFAR-10: 40 minutos para 10 épocas (4 minutos/época) en la GPU Tesla V100 | ResNet-50 en CIFAR-10: 15 minutos para 10 épocas (1,5 minutos/época) en Google Cloud TPU v3 |
| Coste | NVIDIA Tesla V100: 8.000 - 10.000 $/unidad, 2,48 $/hora; NVIDIA A100: 10.000 - 15.000 $/unidad, 2,93 $/hora | TPU v3 de Google Cloud: 4,50 $/hora; TPU v4: 8,00 $/hora |
| Disponibilidad | Ampliamente disponible en múltiples proveedores (NVIDIA, AMD, Intel), para consumidores y empresas | Principalmente accesible a través de Google Cloud Platform (GCP) |
| Ecosistema y herramientas de desarrollo | Compatible con muchos marcos (TensorFlow, PyTorch, Keras, MXNet, Caffe), amplias bibliotecas (CUDA, cuDNN, RAPIDS) | Integrado con TensorFlow, compatible con JAX, optimizado por el compilador TensorFlow XLA |
| Apoyo y recursos comunitarios | Amplio ecosistema con extensos foros, tutoriales y documentación de NVIDIA, AMD y las comunidades | Centralizado en torno al ecosistema de Google con documentación, foros y canales de soporte de GCP |
| Eficiencia Energética | NVIDIA Tesla V100: 250 vatios; NVIDIA A100: 400 vatios | Google Cloud TPU v3: 120-150 vatios; TPU v4: 200-250 vatios |
| Optimización de las tareas de IA | Optimizaciones energéticamente eficientes (power gating, DVFS, procesamiento paralelo, fusión de núcleos) | Jerarquías de memoria personalizadas, cuantificación y dispersión para un cálculo eficiente de la IA |
| Escalabilidad en las aplicaciones empresariales | Escalable para grandes proyectos de IA, en las instalaciones o en la nube (AWS, Azure), gran ancho de banda de memoria, procesamiento paralelo | Estrechamente integrado en la infraestructura de la nube (GCP), escalabilidad bajo demanda, servicios gestionados para desplegar modelos de IA |
Elige GPU cuando:
Elige TPU cuando:
Las GPU y las TPU son aceleradores de hardware especializados que se utilizan en aplicaciones de IA. Desarrolladas originalmente para el renderizado de gráficos, las GPU destacan en el procesamiento paralelo y se han adaptado a las tareas de IA, ofreciendo versatilidad en diversos sectores. Las TPU, en cambio, han sido creadas a medida por Google específicamente para cargas de trabajo de IA, dando prioridad a las operaciones tensoriales habituales en las redes neuronales.
Este artículo compara las tecnologías de GPU y TPU en función de su rendimiento, coste y disponibilidad, ecosistema y desarrollo, eficiencia energética e impacto medioambiental, y escalabilidad en aplicaciones de IA. Para seguir aprendiendo sobre TPUs y GPUs, consulta algunos de estos recursos para continuar tu aprendizaje:
Aprende habilidades de IA con DataCamp
programa
Curso
Curso
blog
Bhavishya Pandit
7 min
blog
Javier Canales Luna
10 min
blog
Austin Chia
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
8 min


