Curso
Introducción a las bases de datos relacionales en SQL
4 h
192.8K
Si acabas de empezar con las bases de datos, es posible que no te hayas encontrado con el caos de los datos desordenados y redundantes, ni con la frustración de las consultas superlentas. Pero créeme, después de cinco años trabajando en varias startups y tratando con todo tipo de estructuras de bases de datos, puedo decirte que estos problemas surgen más a menudo de lo que te gustaría.
La normalización de las bases de datos es una de las mejores formas de abordar estos problemas, y todo empieza con la primera forma normal (1NF). 1NF es un concepto sencillo pero potente que ayuda a crear bases de datos eficientes, fiables y fáciles de mantener, al imponer la atomicidad en tus tablas. También es el paso básico para otras formas de normalización, como 2NF y 3NF.
En este artículo, te guiaré a través de todo lo que necesitas saber sobre 1NF: qué es, cómo aplicarlo en la práctica y por qué es importante. Tanto si eres nuevo en el diseño de bases de datos como si quieres mejorar tus conocimientos, esta guía te ayudará a actualizar tus tablas y a sentar unas bases sólidas para futuros pasos de normalización.
Cuando se desarrollaron por primera vez las bases de datos, sus estructuras distaban mucho de lo que hoy consideramos "normalizado". Los primeros sistemas de bases de datos solían basarse en archivos planos o estructuras jerárquicas, que hacían que la gestión y recuperación de datos fuera engorrosa. Estos diseños tenían importantes limitaciones, como la redundancia de datos, la incoherencia y la inflexibilidad. La evolución de la normalización de las bases de datos, a partir de la primera forma normal, abordó estos retos y revolucionó la forma en que almacenamos y gestionamos los datos.
El concepto de primera forma normal fue introducido por Edgar F. Codd, considerado el padre de las bases de datos relacionales. En los años 70, Codd propuso el modelo relacional como alternativa a los modelos jerárquico y de red que dominaban los primeros sistemas de bases de datos. Su motivación era clara: crear un enfoque sistemático para organizar los datos que redujera la redundancia, eliminara las anomalías y hiciera más eficaz la manipulación de los datos.
El núcleo de este modelo era 1NF, que establecía la regla fundamental de que cada celda de una tabla de base de datos debe contener un único valor atómico, y deben eliminarse los grupos repetidos. Este principio abordaba problemas comunes de los sistemas anteriores, como las actualizaciones incoherentes y las dificultades para consultar datos anidados o agrupados. El trabajo de Codd sobre la normalización no sólo resolvió problemas inmediatos, sino que allanó el camino para estructuras y operaciones de bases de datos más avanzadas.
La adopción de 1NF marcó un punto de inflexión en el desarrollo de las bases de datos. Formalizó el proceso de organizar los datos en tablas con relaciones claras, sentando las bases de los sistemas basados en SQL que dominan el panorama actual de las bases de datos.
Antes de 1NF, sistemas como el Sistema de Gestión de la Información (SGI) de IBM se basaban en estructuras jerárquicas, que requerían diseños rígidos en forma de árbol. Estos sistemas tenían dificultades para adaptarse a los cambios en los datos o en las necesidades empresariales. Con la introducción de 1NF y el modelo relacional, las bases de datos se hicieron más flexibles, permitiendo relaciones dinámicas entre tablas y una mayor escalabilidad.
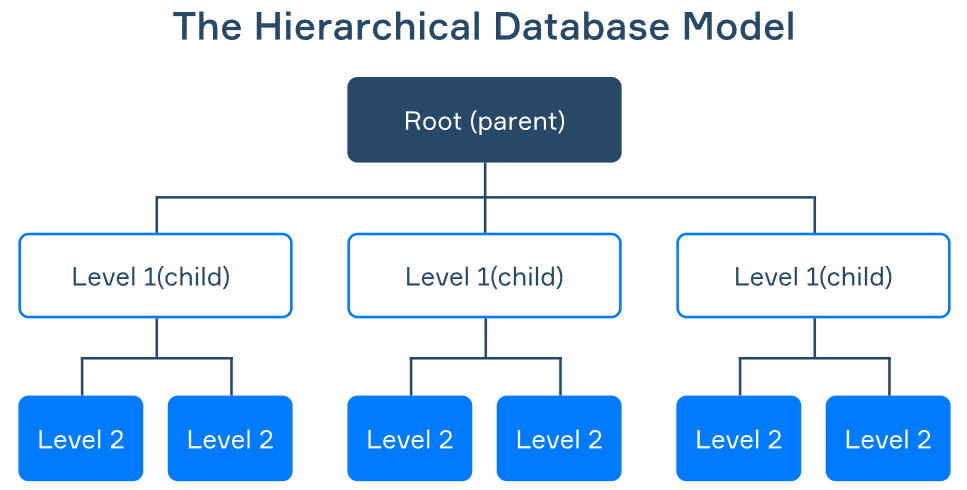
Fuente: Airbyte
Los modernos sistemas de gestión de bases de datos relacionales (RDBMS) como MySQL, PostgreSQL y Microsoft SQL Server deben sus principios de diseño a los conceptos fundacionales de 1NF. Estos sistemas permiten a los desarrolladores trabajar con datos bien estructurados, lo que facilita enormemente la realización de consultas, actualizaciones e integraciones complejas.
Las ventajas prácticas de 1NF -y de la normalización de bases de datos en general- se extendieron rápidamente por todos los sectores. En la banca, por ejemplo, 1NF ayudó a gestionar los registros de clientes y los historiales de transacciones, garantizando que los datos se almacenaban en un formato coherente y consultable. Los minoristas utilizaban 1NF para hacer un seguimiento del inventario, las ventas y los pedidos de los clientes. Los sistemas de gestión de inventarios fueron otra área en la que 1NF demostró ser inestimable. Al estructurar los datos en formas atómicas y no repetitivas, los fabricantes podían mantener registros precisos de los componentes, los niveles de existencias y los movimientos de la cadena de suministro.
Conseguir 1NF requiere cumplir 4 condiciones clave:
Las dos primeras condiciones suelen cumplirse por diseño en la mayoría de las bases de datos modernas, así que en este artículo nos centraremos en las dos últimas: atomicidad y columnas únicas.
Hay unos sencillos pasos a seguir para descomponer una tabla que viola 1NF.
El primer paso es localizar las columnas que almacenan varios valores en una sola celda, o que -para evitar hacer precisamente eso- están repetidas. Estas infracciones suelen aparecer como:
A continuación, tenemos que reestructurar la tabla para que cada celda contenga un solo valor, y para que cada columna represente un tipo de datos. Esto suele implicar:
Tras la reestructuración, comprueba que tu tabla cumple los siguientes requisitos 1NF. Si no estás seguro, pregúntate "¿Puedo ordenar, filtrar o consultar los datos fácilmente sin procesamiento adicional?". "¿Cada columna representa un tipo de atributo, y cada fila un registro único?" Si has respondido afirmativamente a ambas preguntas, entonces la tabla está en 1NF.
Ahora que ya conocemos los pasos para transformar una tabla y conseguir 1NF, veamos dos ejemplos prácticos de primera forma normal.
Imagina una Pedidos de clientes con el siguiente aspecto:
| CustomerID | Nombre | Producto1 | Producto2 | FechaPedido |
|---|---|---|---|---|
| 1 | Alice | Manzanas | Bananas | 2025-01-10 |
| 2 | Bob | Naranjas | Uvas | 2025-01-11 |
Esta tabla viola 1NF porque contiene varias columnas, Producto1 y Producto2 que se refieren al mismo tipo de datos (productos)l.
Entonces, ¿cómo lo arreglamos?Para conseguir 1NF, divide los datos en filas separadas, de modo que cada celda contenga un solo valor:
| CustomerID | Nombre | Producto | FechaPedido |
|---|---|---|---|
| 1 | Alice | Manzanas | 2025-01-10 |
| 1 | Alice | Plátanos | 2025-01-10 |
| 2 | Bob | Naranjas | 2025-01-11 |
| 2 | Bob | Uvas | 2025-01-11 |
En este primer ejemplo de forma normal, eliminamos la ambigüedad y simplificamos la consulta y el análisis de los datos. ¡Encontrar a todos los clientes que pidieron plátanos es ahora superfácil!
Tomemos una Calificaciones del alumno con el siguiente aspecto:
| StudentID | Nombre | Grados |
|---|---|---|
| 101 | Sarah | A, B, C |
| 102 | Michael | B, A, A |
El Calificaciones viola 1NF porque almacena varias calificaciones en una sola celda, en lugar de utilizar valores atómicos.
Entonces, ¿cómo lo arreglamos?Para cumplir con 1NF, tenemos que crear filas separadas para cada grado:
| StudentID | Nombre | Grado |
|---|---|---|
| 101 | Sarah | A |
| 101 | Sarah | B |
| 101 | Sarah | C |
| 102 | Michael | B |
| 102 | Michael | A |
| 102 | Michael | A |
Dividir las calificaciones en valores atómicos mejora la organización de los datos y facilita el cálculo de medias, la identificación de los alumnos con mejores resultados o el análisis de la distribución de las calificaciones.
Si quieres ponerte manos a la obra y crear tus propias bases de datos, echa un vistazo a nuestro curso PostgresQL. Si eres un poco más avanzado, podrías probar esta Introducción al modelado de datos en Snowflake, que abarca ideas como el modelado entidad-relación y el modelado dimensional.
Veamos los pros y los contras:
Adoptar 1NF ofrece algunas ventajas clave que hacen que trabajar con bases de datos sea mucho más fácil y eficaz.
Al imponer valores atómicos, elimina la posibilidad de que aparezcan datos desordenados y concatenados como "Manzanas, Plátanos" en una fila y "Manzanas;Plátanos" en otra. Esta uniformidad hace que los datos sean más limpios y sencillos de leer, consultar y actualizar.
1NF también hace que la manipulación de datos sea mucho más sencilla. Con los valores atómicos, puedes buscar, filtrar y actualizar fácilmente los datos sin encontrarte con problemas. Por ejemplo, una consulta que busque "Manzanas" es mucho más rápida y precisa cuando cada producto está en su propia fila, en lugar de agrupado en una sola columna. También redujo el riesgo de incoherencias al realizar actualizaciones, ya que los cambios están contenidos en filas concretas.
1NF no es una solución perfecta. Convertir las columnas repetidas en filas separadas o dividir las celdas multivalor en filas individuales puede hacer que aumente la longitud de la tabla. Puesto que más filas pueden significar más datos que ordenar, esto puede repercutir en el rendimiento de la consulta.
Es importante señalar que 1NF no es un fin en sí mismo, ya que no aborda todas las formas de redundancia. Cuestiones como las dependencias parciales o las dependencias transitivas se tratan en formas normales superiores, como la segunda forma normal y la tercera forma normal. Así que, aunque 1NF es una base sólida, es sólo el primer paso en la normalización de una base de datos y no optimiza completamente una estructura de base de datos por sí sola.
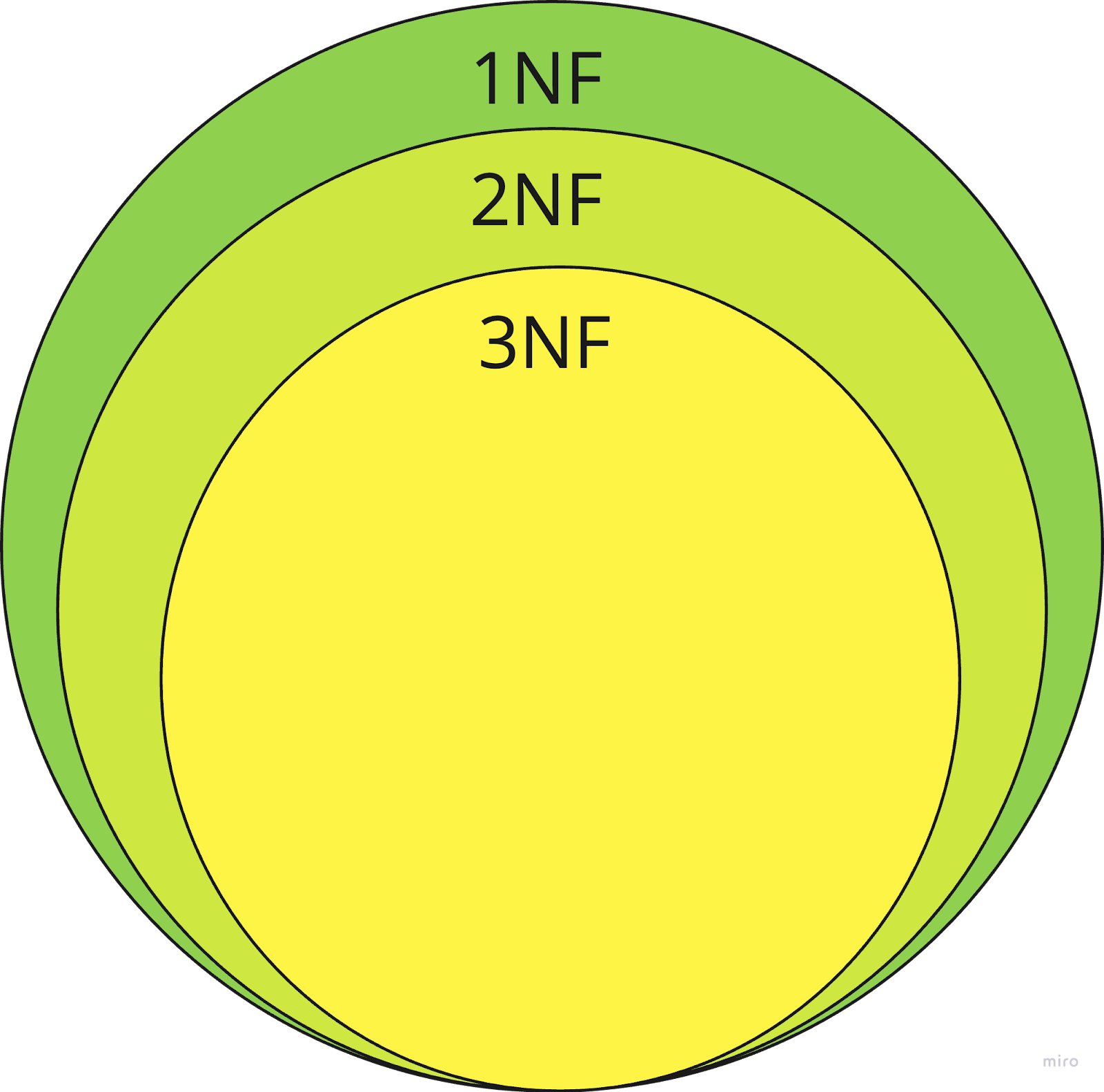
Los primeros formularios de normalización de bases de datos. Fuente: Autor
Una vez que hayas establecido que tu base de datos está en primera forma formal, el siguiente paso lógico es avanzar hacia la segunda forma normal. 2NF se basa en los cimientos establecidos por 1NF abordando un problema clave: las dependencias parciales.
En 2NF, el objetivo es eliminar las dependencias parciales, que se producen cuando un atributo no primo (un atributo que no forma parte de la clave primaria) depende sólo de una parte de una clave primaria compuesta. Esto es especialmente importante en tablas con claves compuestas, es decir, claves formadas por varias columnas. Esto puede sonar un poco abstracto, pero he escrito esta guía sobre la segunda forma normal que desglosa el concepto y muestra ejemplos prácticos. ¡Te harás con él enseguida!
La primera forma normal es el primer paso en la normalización de una base de datos, ya que garantiza que cada columna contenga valores atómicos y elimina las columnas repetidas.
Puesto que sienta las bases para formas de normalización más avanzadas como 2NF y 3NF, lo más probable es que tengas que adoptar 1NF si quieres crear bases de datos eficientes, escalables y fáciles de mantener que puedan gestionar consultas complejas y grandes conjuntos de datos con facilidad.
Si estás preparado para llevar tus habilidades más allá, explora nuestro curso de Diseño de Bases de Datos para profundizar en las técnicas de normalización y sus aplicaciones prácticas. También puedes validar tus conocimientos de SQL y de gestión de bases de datos y demostrar tu experiencia a posibles empleadores con nuestra Certificación de Asociado SQL.
Aprende con DataCamp
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Abid Ali Awan
