Kurs
Einführung in relationale Datenbanken in SQL
4 Std.
192.8K
Wenn du gerade erst mit Datenbanken anfängst, kennst du vielleicht noch nicht das Chaos unordentlicher, redundanter Daten oder die Frustration über superlangsame Abfragen. Aber glaub mir, nach fünf Jahren Arbeit in verschiedenen Startups und dem Umgang mit allen möglichen Datenbankstrukturen, kann ich dir sagen, dass diese Probleme öfter auftauchen, als dir lieb ist.
Die Normalisierung von Datenbanken ist eine der besten Möglichkeiten, diese Probleme zu lösen, und alles beginnt mit der ersten Normalform (1NF). 1NF ist ein einfaches, aber mächtiges Konzept, das dabei hilft, effiziente, zuverlässige und wartbare Datenbanken zu erstellen, indem es die Atomarität in deinen Tabellen erzwingt. Sie ist auch der Grundstein für andere Normalisierungsformen, wie 2NF und 3NF.
In diesem Artikel erkläre ich dir alles, was du über 1NF wissen musst: was es ist, wie du es in der Praxis anwendest und warum es wichtig ist. Egal, ob du neu in der Datenbankentwicklung bist oder deine Kenntnisse auffrischen willst, dieser Leitfaden wird dir helfen, deine Tabellen zu aktualisieren und eine solide Grundlage für zukünftige Normalisierungsschritte zu schaffen.
Als die ersten Datenbanken entwickelt wurden, waren ihre Strukturen noch weit von dem entfernt, was wir heute als "normalisiert" ansehen. Frühe Datenbanksysteme basierten oft auf flachen Dateien oder hierarchischen Strukturen, was die Verwaltung und Abfrage von Daten umständlich machte. Diese Entwürfe hatten erhebliche Einschränkungen, darunter Datenredundanz, Inkonsistenz und Inflexibilität. Die Entwicklung der Datenbanknormalisierung, beginnend mit der ersten Normalform, hat diese Herausforderungen angenommen und die Art und Weise, wie wir Daten speichern und verwalten, revolutioniert.
Das Konzept der ersten Normalform wurde von Edgar F. Codd eingeführt, der als Vater der relationalen Datenbanken gilt. In den 1970er Jahren schlug Codd das relationale Modell als Alternative zu den hierarchischen und Netzwerkmodellen vor, die die frühen Datenbanksysteme dominierten. Seine Motivation war klar: Er wollte einen systematischen Ansatz zur Organisation von Daten entwickeln, der Redundanzen reduziert, Anomalien beseitigt und die Datenbearbeitung effizienter macht.
Das Herzstück dieses Modells war 1NF, das die Grundregel aufstellte, dass jede Zelle in einer Tabelle einen einzelnen, atomaren Wert enthalten muss und sich wiederholende Gruppen eliminiert werden sollten. Mit diesem Prinzip wurden häufige Probleme früherer Systeme gelöst, wie z. B. inkonsistente Aktualisierungen und Schwierigkeiten bei der Abfrage verschachtelter oder gruppierter Daten. Codds Arbeit an der Normalisierung löste nicht nur unmittelbare Probleme, sondern ebnete auch den Weg für fortschrittlichere Datenbankstrukturen und -operationen.
Die Einführung von 1NF markierte einen Wendepunkt in der Datenbankentwicklung. Sie formalisierte den Prozess der Organisation von Daten in Tabellen mit klaren Beziehungen und legte damit den Grundstein für SQL-basierte Systeme, die heute die Datenbanklandschaft dominieren.
Vor 1NF basierten Systeme wie das Information Management System (IMS) von IBM auf hierarchischen Strukturen, die ein starres baumartiges Design erforderten. Diese Systeme konnten sich nur schwer an Änderungen der Daten oder der Geschäftsanforderungen anpassen. Mit der Einführung von 1NF und dem relationalen Modell wurden Datenbanken flexibler und ermöglichten dynamische Beziehungen zwischen Tabellen und eine bessere Skalierbarkeit.
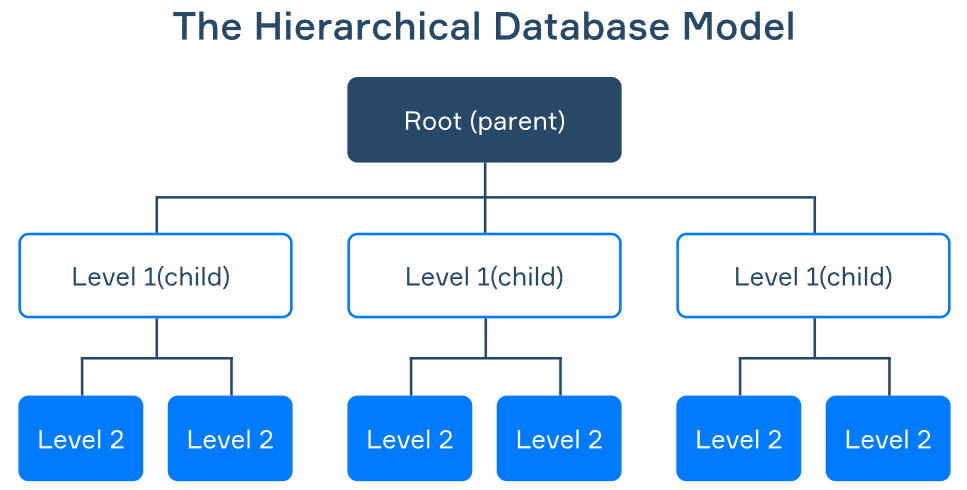
Quelle: Airbyte
Moderne relationale Datenbankmanagementsysteme (RDBMS) wie MySQL, PostgreSQL und Microsoft SQL Server verdanken ihre Designprinzipien den grundlegenden Konzepten der 1NF. Diese Systeme ermöglichen es Entwicklern, mit gut strukturierten Daten zu arbeiten, was die Durchführung komplexer Abfragen, Aktualisierungen und Integrationen erheblich erleichtert.
Die praktischen Vorteile der 1NF - und der Datenbanknormalisierung im Allgemeinen - haben sich schnell in allen Branchen durchgesetzt. Im Bankwesen zum Beispiel half 1NF bei der Verwaltung von Kundendatensätzen und Transaktionshistorien, indem es dafür sorgte, dass die Daten in einem einheitlichen und abfragbaren Format gespeichert wurden. Einzelhändler nutzten 1NF, um den Bestand, die Verkäufe und die Kundenbestellungen zu verfolgen. Bestandsverwaltungssysteme waren ein weiterer Bereich, in dem sich 1NF als unschätzbar wertvoll erwies. Durch die Strukturierung von Daten in atomaren, sich nicht wiederholenden Formen konnten die Hersteller genaue Aufzeichnungen über Komponenten, Lagerbestände und Bewegungen in der Lieferkette führen.
Um 1NF zu erreichen, müssen 4 wichtige Bedingungen erfüllt werden:
Die ersten beiden Bedingungen werden in den meisten modernen Datenbanken bereits durch das Design erzwungen, daher werden wir uns in diesem Artikel auf die letzten beiden konzentrieren: Atomarität und eindeutige Spalten.
Um eine Tabelle zu zerlegen, die gegen 1NF verstößt, gibt es einfache Schritte, die du befolgen kannst.
Der erste Schritt besteht darin, Spalten ausfindig zu machen, die mehrere Werte in einer einzigen Zelle speichern oder - um genau das zu vermeiden - wiederholt werden. Diese Verstöße zeigen sich oft als:
Als Nächstes müssen wir die Tabelle so umstrukturieren, dass jede Zelle nur einen Wert enthält und dass jede Spalte einen Datentyp darstellt. Das beinhaltet oft:
Prüfe nach der Umstrukturierung, ob deine Tabelle die folgenden 1NF-Anforderungen erfüllt. Wenn du dir unsicher bist, frage dich: "Kann ich die Daten einfach sortieren, filtern oder abfragen, ohne sie zusätzlich zu bearbeiten?". "Steht jede Spalte für eine Art von Attribut und jede Zeile für einen eindeutigen Datensatz?" Wenn du beide Fragen mit Ja beantwortet hast, dann ist die Tabelle in 1NF.
Nachdem wir nun wissen, wie man eine Tabelle umwandelt und 1NF erreicht, wollen wir uns zwei praktische Beispiele für die erste Normalform ansehen.
Stell dir eine Kundenbestellungen Tabelle, die wie folgt aussieht:
| CustomerID | Name | Produkt1 | Produkt2 | BestellDatum |
|---|---|---|---|---|
| 1 | Alice | Äpfel | Bananas | 2025-01-10 |
| 2 | Bob | Orangen | Weintrauben | 2025-01-11 |
Diese Tabelle verstößt gegen 1NF, weil sie mehrere Spalten enthält, Produkt1 und Produkt2 die sich auf denselben Datentyp beziehen (Produkte)l.
Wie also lösen wir das Problem?Um 1NF zu erreichen, teilst du die Daten in einzelne Zeilen auf, so dass jede Zelle nur einen Wert enthält:
| CustomerID | Name | Produkt | BestellDatum |
|---|---|---|---|
| 1 | Alice | Äpfel | 2025-01-10 |
| 1 | Alice | Bananas | 2025-01-10 |
| 2 | Bob | Orangen | 2025-01-11 |
| 2 | Bob | Weintrauben | 2025-01-11 |
In diesem ersten Normalform-Beispiel haben wir Mehrdeutigkeiten beseitigt und die Abfrage und Analyse der Daten vereinfacht. Alle Kunden zu finden, die Bananen bestellt haben, ist jetzt super einfach!
Nehmen wir eine Schüler-Noten Tabelle, die wie folgt aussieht:
| StudentID | Name | Klassen |
|---|---|---|
| 101 | Sarah | A, B, C |
| 102 | Michael | B, A, A |
Die Noten Spalte verstößt gegen 1NF, weil sie mehrere Noten in einer einzigen Zelle speichert, anstatt atomare Werte zu verwenden.
Wie können wir das also ändern?Um die 1NF zu erfüllen, müssen wir für jede Klasse eine eigene Zeile erstellen:
| StudentID | Name | Klasse |
|---|---|---|
| 101 | Sarah | A |
| 101 | Sarah | B |
| 101 | Sarah | C |
| 102 | Michael | B |
| 102 | Michael | A |
| 102 | Michael | A |
Die Aufteilung der Noten in atomare Werte verbessert die Datenorganisation und erleichtert die Berechnung von Durchschnittswerten, die Identifizierung leistungsstärkerer Schüler/innen oder die Analyse der Notenverteilung.
Wenn du selbst Hand anlegen und deine eigene Datenbank erstellen willst, schau dir unseren PostgresQL-Kurs an. Wenn du schon etwas fortgeschrittener bist, könntest du diese Einführung in die Datenmodellierung in Snowflake ausprobieren, in der Ideen wie Entity-Relationship und Dimensionsmodellierung behandelt werden.
Schauen wir uns die Vor- und Nachteile an:
Die Einführung von 1NF bietet einige wichtige Vorteile, die die Arbeit mit Datenbanken viel einfacher und effizienter machen.
Indem sie atomare Werte erzwingt, verhindert sie, dass unordentliche, verkettete Daten wie "Äpfel, Bananen" in einer Zeile und "Äpfel;Bananen" in einer anderen entstehen. Diese Einheitlichkeit macht die Daten sauberer und einfacher zu lesen, abzufragen und zu aktualisieren.
1NF macht auch die Datenmanipulation viel einfacher. Mit atomaren Werten kannst du die Daten einfach suchen, filtern und aktualisieren, ohne dass es zu Problemen kommt. Eine Abfrage nach "Äpfeln" ist zum Beispiel viel schneller und präziser, wenn jedes Produkt in einer eigenen Zeile steht, anstatt in einer einzigen Spalte zusammengefasst zu werden. Außerdem wurde das Risiko von Inkonsistenzen bei Aktualisierungen verringert, da die Änderungen in bestimmten Zeilen enthalten sind.
1NF ist keine perfekte Lösung. Das Umwandeln von sich wiederholenden Spalten in einzelne Zeilen oder das Aufteilen von mehrwertigen Zellen in einzelne Zeilen kann dazu führen, dass die Länge der Tabelle zunimmt. Da mehr Zeilen mehr Daten bedeuten, die sortiert werden müssen, kann sich dies auf die Abfrageleistung auswirken.
Es ist wichtig zu beachten, dass 1NF kein Selbstzweck ist, da es nicht alle Formen von Redundanz bekämpft. Probleme wie partielle Abhängigkeiten oder transitive Abhängigkeiten werden in höheren Normalformen wie der zweiten Normalform und der dritten Normalform behandelt. 1NF ist zwar eine solide Grundlage, aber nur der erste Schritt in der Datenbanknormalisierung und reicht nicht aus, um eine Datenbankstruktur allein zu optimieren.
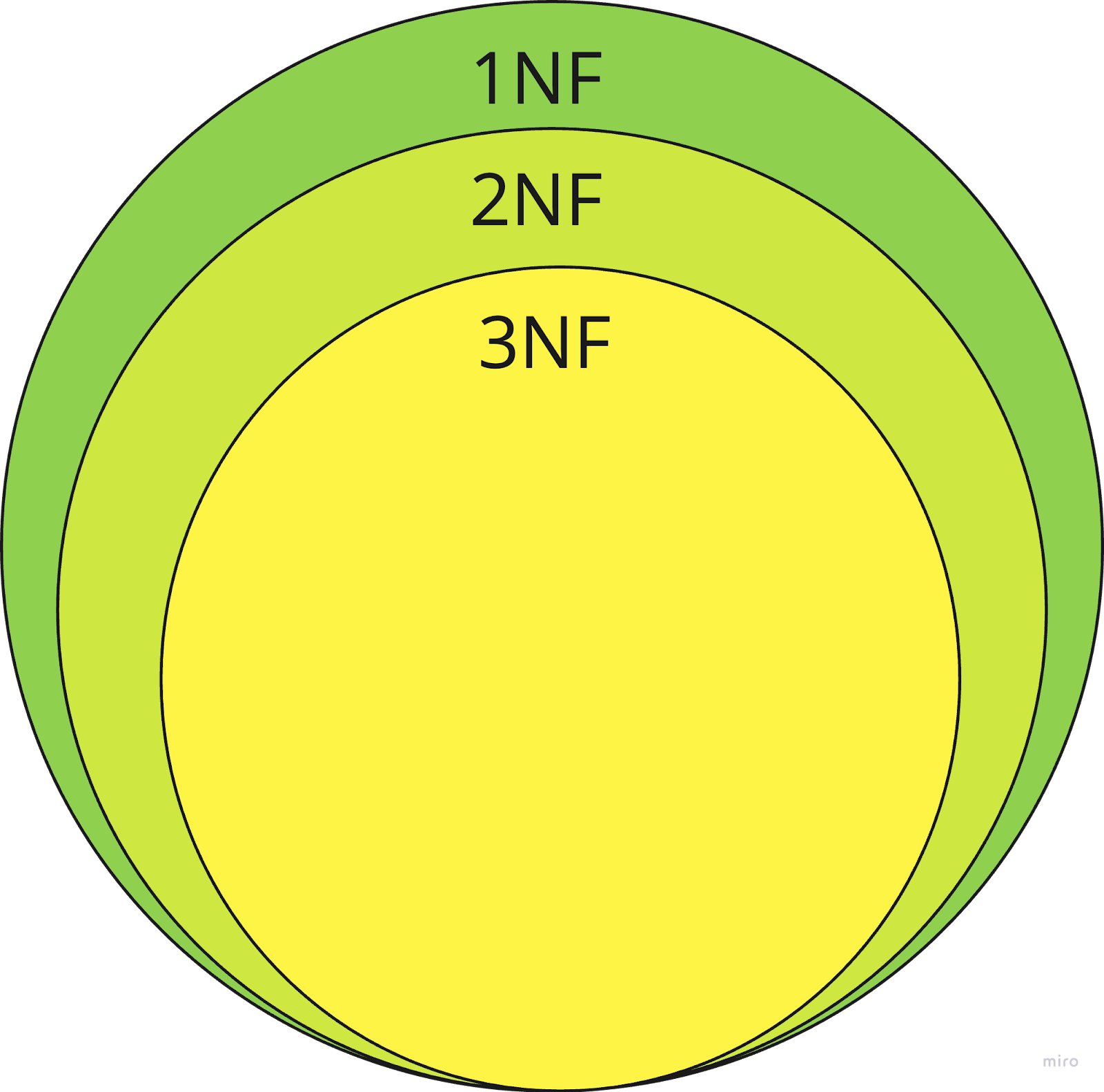
Die ersten Formen der Datenbanknormalisierung. Quelle: Autor
Wenn du festgestellt hast, dass sich deine Datenbank in der ersten Normalform befindet, ist der nächste logische Schritt der Übergang zur zweiten Normalform. Die 2NF baut auf der Grundlage der 1NF auf, indem sie ein zentrales Problem angeht: partielle Abhängigkeiten.
Bei der 2NF geht es darum, partielle Abhängigkeiten zu beseitigen, die auftreten, wenn ein Nicht-Primär-Attribut (ein Attribut, das nicht Teil des Primärschlüssels ist) nur von einem Teil eines zusammengesetzten Primärschlüssels abhängig ist. Dies ist besonders wichtig bei Tabellen mit zusammengesetzten Schlüsseln - also Schlüsseln, die aus mehreren Spalten bestehen. Das klingt vielleicht ein bisschen abstrakt, aber ich habe diesen Leitfaden zur zweiten Normalform geschrieben , der das Konzept aufschlüsselt und praktische Beispiele zeigt. Du wirst es im Handumdrehen beherrschen!
Die erste Normalform ist der erste Schritt der Datenbanknormalisierung, der sicherstellt, dass jede Spalte atomare Werte enthält und sich wiederholende Spalten eliminiert.
Da sie die Grundlage für fortgeschrittenere Normalisierungsformen wie 2NF und 3NF bildet, wirst du höchstwahrscheinlich 1NF übernehmen müssen, wenn du effiziente, skalierbare und wartbare Datenbanken aufbauen willst, die komplexe Abfragen und große Datenmengen problemlos verarbeiten können!
Wenn du bereit bist, deine Kenntnisse zu vertiefen, solltest du unseren Kurs Datenbankdesign besuchen, um dein Verständnis von Normalisierungstechniken und ihren praktischen Anwendungen zu vertiefen. Mit unserer SQL Associate-Zertifizierung kannst du außerdem deine SQL- und Datenbankmanagement-Kenntnisse unter Beweis stellen und potenziellen Arbeitgebern dein Fachwissen zeigen!
Lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
