Curso
Introdução aos bancos de dados relacionais em SQL
4 h
192.8K
Se você está apenas começando com bancos de dados, talvez não tenha se deparado com o caos de dados confusos e redundantes ou com a frustração de consultas superlentas. Mas, acredite, depois de cinco anos trabalhando em várias startups e lidando com todos os tipos de estruturas de banco de dados, posso dizer que esses problemas aparecem com mais frequência do que você gostaria.
A normalização do banco de dados é uma das melhores maneiras de lidar com esses problemas, e tudo começa com a primeira forma normal (1NF). O 1NF é um conceito simples, mas poderoso, que ajuda a criar bancos de dados eficientes, confiáveis e de fácil manutenção, impondo a atomicidade em suas tabelas. Essa também é a etapa fundamental para outras formas de normalização, como 2NF e 3NF.
Neste artigo, mostrarei tudo o que você precisa saber sobre 1NF: o que é, como aplicá-lo na prática e por que ele é importante. Se você é novo no design de bancos de dados ou está apenas buscando aprimorar suas habilidades, este guia ajudará a atualizar suas tabelas e estabelecerá uma base sólida para futuras etapas de normalização.
Quando os bancos de dados foram desenvolvidos pela primeira vez, suas estruturas estavam longe do que consideramos "normalizado" hoje. Os primeiros sistemas de banco de dados geralmente dependiam de arquivos simples ou estruturas hierárquicas, o que tornava o gerenciamento e a recuperação de dados complicados. Esses projetos tinham limitações significativas, incluindo redundância de dados, inconsistência e inflexibilidade. A evolução da normalização do banco de dados, começando com a primeira forma normal, abordou esses desafios e revolucionou a maneira como armazenamos e gerenciamos os dados.
O conceito de primeira forma normal foi introduzido por Edgar F. Codd, amplamente considerado o pai dos bancos de dados relacionais. Na década de 1970, Codd propôs o modelo relacional como uma alternativa aos modelos hierárquicos e de rede que dominavam os primeiros sistemas de banco de dados. Sua motivação era clara: criar uma abordagem sistemática para organizar os dados que reduzisse a redundância, eliminasse anomalias e tornasse a manipulação de dados mais eficiente.
No centro desse modelo estava o 1NF, que definiu a regra fundamental de que cada célula em uma tabela de banco de dados deve conter um único valor atômico, e os grupos repetidos devem ser eliminados. Esse princípio abordou problemas comuns em sistemas anteriores, como atualizações inconsistentes e dificuldades na consulta de dados aninhados ou agrupados. O trabalho de Codd sobre normalização não apenas resolveu problemas imediatos, mas também abriu caminho para estruturas e operações de banco de dados mais avançadas.
A adoção do 1NF marcou um ponto de virada no desenvolvimento de bancos de dados. Ele formalizou o processo de organização de dados em tabelas com relacionamentos claros, estabelecendo as bases para os sistemas baseados em SQL que dominam o cenário atual de bancos de dados.
Antes da 1NF, sistemas como o Information Management System (IMS) da IBM dependiam de estruturas hierárquicas, que exigiam designs rígidos em forma de árvore. Esses sistemas tinham dificuldades para se adaptar às mudanças nos dados ou às necessidades comerciais. Com a introdução do 1NF e do modelo relacional, os bancos de dados se tornaram mais flexíveis, permitindo relações dinâmicas entre tabelas e maior escalabilidade.
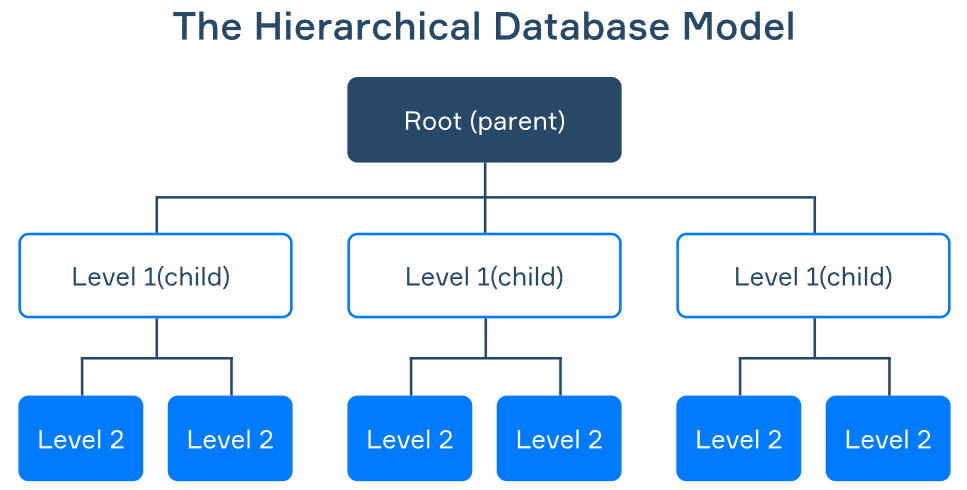
Fonte: Airbyte
Os modernos sistemas de gerenciamento de bancos de dados relacionais (RDBMS), como MySQL, PostgreSQL e Microsoft SQL Server, devem seus princípios de design aos conceitos fundamentais da 1NF. Esses sistemas permitem que os desenvolvedores trabalhem com dados bem estruturados, o que facilita muito a realização de consultas, atualizações e integrações complexas.
Os benefícios práticos do 1NF - e da normalização do banco de dados em geral - rapidamente ganharam força em todos os setores. No setor bancário, por exemplo, a 1NF ajudou a gerenciar registros de clientes e históricos de transações, garantindo que os dados fossem armazenados em um formato consistente e consultável. Os varejistas usavam o 1NF para controlar o estoque, as vendas e os pedidos dos clientes. Os sistemas de gerenciamento de estoque foram outra área em que a 1NF se mostrou inestimável. Ao estruturar os dados em formas atômicas e não repetitivas, os fabricantes puderam manter registros precisos de componentes, níveis de estoque e movimentos da cadeia de suprimentos.
Para atingir o 1NF, você precisa atender a quatro condições principais:
As duas primeiras condições são geralmente aplicadas por design na maioria dos bancos de dados modernos, portanto, neste artigo, vamos nos concentrar nas duas últimas: atomicidade e colunas exclusivas.
Você pode seguir etapas simples para decompor uma tabela que viola o 1NF.
A primeira etapa é localizar as colunas que armazenam vários valores em uma única célula ou que - em um esforço para evitar isso - são repetidas. Essas violações geralmente aparecem como:
Em seguida, precisamos reestruturar a tabela de modo que cada célula contenha apenas um valor e que cada coluna represente um tipo de dados. Isso geralmente envolve:
Após a reestruturação, verifique se sua tabela atende aos seguintes requisitos de 1NF. Se você não tiver certeza, pergunte a si mesmo: "Posso classificar, filtrar ou consultar os dados facilmente sem processamento adicional?". "Cada coluna representa um tipo de atributo e cada linha um registro exclusivo?" Se você respondeu sim a ambas as perguntas, então a tabela está em 1NF.
Agora que entendemos as etapas para transformar uma tabela e obter 1NF, vamos dar uma olhada em dois exemplos práticos da primeira forma normal.
Imagine um Pedidos de clientes com a seguinte aparência:
| CustomerID | Nome | Produto1 | Product2 | OrderDate |
|---|---|---|---|---|
| 1 | Alice | Apples | Bananas | 2025-01-10 |
| 2 | Bob | Laranjas | Uvas | 2025-01-11 |
Essa tabela viola o 1NF porque contém várias colunas, Product1 e Product2 que se referem ao mesmo tipo de dados (produtos)l.
Então, como podemos corrigir isso?Para obter 1NF, divida os dados em linhas separadas para que cada célula contenha apenas um valor:
| CustomerID | Nome | Produto | OrderDate |
|---|---|---|---|
| 1 | Alice | Apples | 2025-01-10 |
| 1 | Alice | Bananas | 2025-01-10 |
| 2 | Bob | Laranjas | 2025-01-11 |
| 2 | Bob | Uvas | 2025-01-11 |
Nesse primeiro exemplo de forma normal, eliminamos a ambiguidade e simplificamos a consulta e a análise dos dados. Agora é muito fácil encontrar todos os clientes que pediram bananas!
Vamos dar uma olhada em Notas dos alunos que tem a seguinte aparência:
| StudentID | Nome | Notas |
|---|---|---|
| 101 | Sarah | A, B, C |
| 102 | Michael | B, A, A |
As Notas viola 1NF porque armazena várias notas em uma única célula, em vez de usar valores atômicos.
Então, como podemos corrigir isso?Para estar em conformidade com o 1NF, precisamos criar linhas separadas para cada série:
| StudentID | Nome | Nota |
|---|---|---|
| 101 | Sarah | A |
| 101 | Sarah | B |
| 101 | Sarah | C |
| 102 | Michael | B |
| 102 | Michael | A |
| 102 | Michael | A |
A divisão das notas em valores atômicos melhora a organização dos dados e facilita o cálculo das médias, a identificação dos alunos com melhor desempenho ou a análise das distribuições de notas.
Se você quiser colocar a mão na massa e criar seus próprios bancos de dados, dê uma olhada no nosso curso PostgresQL. Se você for um pouco mais avançado, pode tentar esta Introdução à modelagem de dados no Snowflake, que aborda ideias como entidade-relacionamento e modelagem dimensional.
Vamos dar uma olhada nas vantagens e desvantagens:
A adoção da 1NF oferece alguns benefícios importantes que tornam o trabalho com bancos de dados muito mais fácil e eficiente.
Ao impor valores atômicos, ele elimina a possibilidade de dados confusos e concatenados, como "Apples, Bananas" em uma linha e "Apples;Bananas" em outra. Essa uniformidade torna os dados mais limpos e mais simples de ler, consultar e atualizar.
O 1NF também torna a manipulação de dados muito mais simples. Com valores atômicos, você pode facilmente pesquisar, filtrar e atualizar os dados sem ter problemas. Por exemplo, uma consulta que busca por "Maçãs" é muito mais rápida e precisa quando cada produto está em sua própria linha, em vez de estar agrupado em uma única coluna. Isso também reduziu o risco de inconsistências ao realizar atualizações, já que as alterações estão contidas em linhas específicas.
O 1NF não é uma solução perfeita. A conversão de colunas repetidas em linhas separadas ou a divisão de células com vários valores em linhas individuais pode aumentar o comprimento da tabela. Como mais linhas podem significar mais dados para classificar, isso pode afetar o desempenho da consulta.
É importante observar que o 1NF não é um fim em si mesmo, pois não aborda todas as formas de redundância. Questões como dependências parciais ou dependências transitivas são tratadas em formas normais superiores, como a segunda forma normal e a terceira forma normal. Portanto, embora o 1NF seja uma base sólida, ele é apenas a primeira etapa da normalização do banco de dados e não otimiza totalmente uma estrutura de banco de dados por si só.
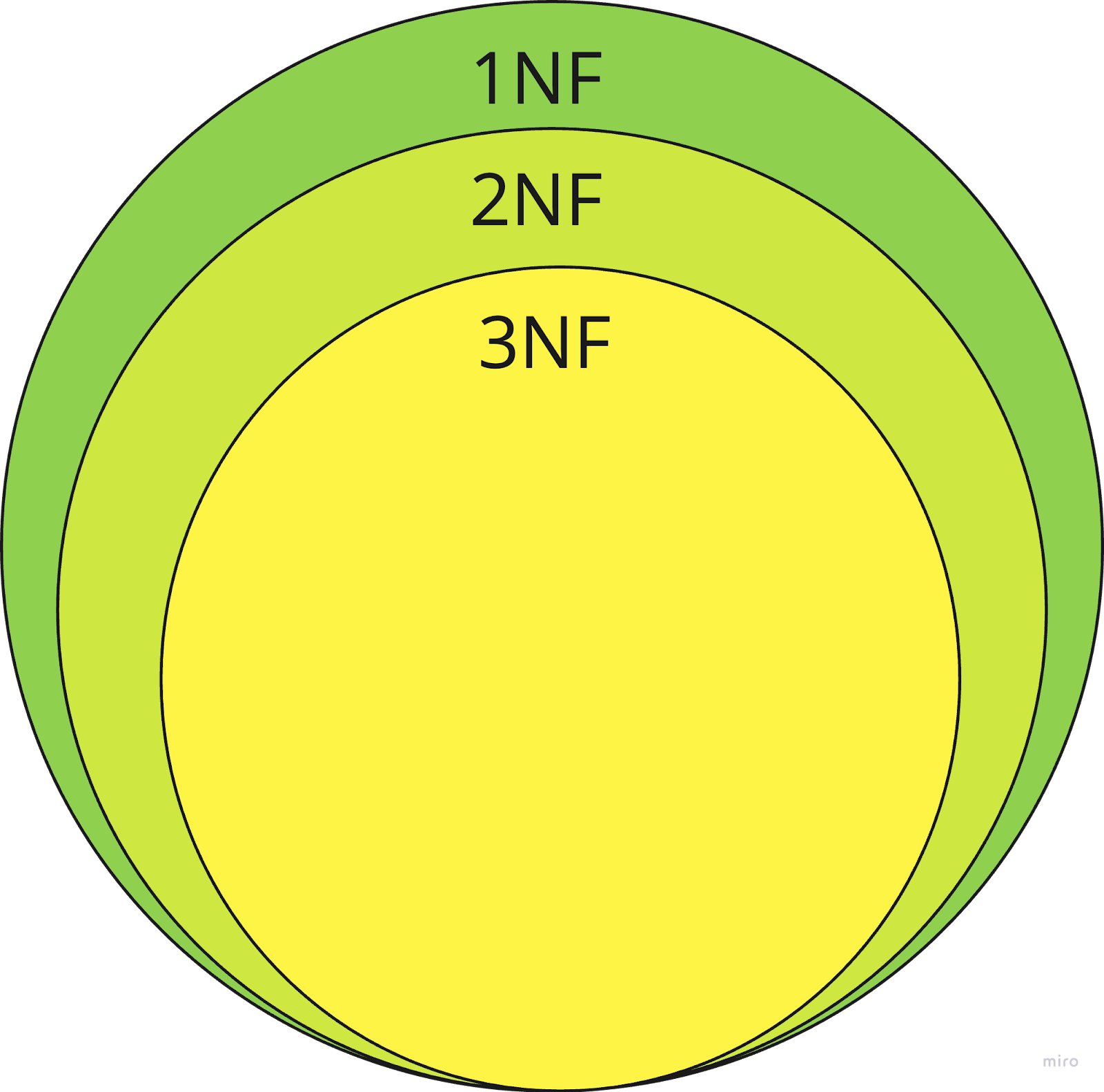
Os primeiros formulários de normalização de banco de dados. Fonte: Autor
Depois que você tiver estabelecido que seu banco de dados está na primeira forma formal, a próxima etapa lógica é passar para a segunda forma normal. O 2NF se baseia na fundação estabelecida pelo 1NF, abordando um problema importante: dependências parciais.
Em 2NF, o objetivo é eliminar dependências parciais, que ocorrem quando um atributo não-primário (um atributo que não faz parte da chave primária) é dependente de apenas uma parte de uma chave primária composta. Isso é particularmente importante em tabelas com chaves compostas - chaves formadas por várias colunas. Isso pode parecer um pouco abstrato, mas escrevi este guia sobre a segunda forma normal, que detalha o conceito e mostra exemplos práticos. Você terá uma boa compreensão do assunto em pouco tempo!
A primeira forma normal é a primeira etapa da normalização do banco de dados, garantindo que cada coluna contenha valores atômicos e eliminando colunas repetidas.
Como ele prepara o terreno para formas de normalização mais avançadas, como 2NF e 3NF, você provavelmente precisará adotar o 1NF se planeja criar bancos de dados eficientes, dimensionáveis e de fácil manutenção que possam lidar com consultas complexas e grandes conjuntos de dados com facilidade!
Se você estiver pronto para aprimorar suas habilidades, explore nosso curso de Design de banco de dados para aprofundar sua compreensão das técnicas de normalização e suas aplicações práticas. Você também pode validar suas habilidades de gerenciamento de banco de dados e SQL e demonstrar sua experiência para possíveis empregadores com a nossa Certificação SQL Associate!
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Summer Worsley
13 min
blog
Kurtis Pykes
11 min
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Oluseye Jeremiah
Tutorial
Allan Ouko

