programa
Fundamentos de la IA
10 h
Gemini 1.5 Pro representa un avance significativo en la familia Gemini. Introduce el razonamiento de contexto largo, que nos permite trabajar con conjuntos de datos masivos en varias modalidades (texto, vídeo y audio).
En este tutorial, aprenderemos a conectarnos a la API Gemini 1.5 Pro. Aprenderemos a ejecutar tareas como la recuperación, la respuesta a preguntas sobre documentos largos y vídeos, el reconocimiento automático del habla (ASR) en contexto largo y el aprendizaje en contexto.
Si quieres saber más sobre Géminis, consulta este artículo sobre Qué es Google Géminis.
Gemini AI engloba una serie de modelos generativos de IA desarrollados en colaboración por varios equipos de Google, incluidos Google Research y Google DeepMind.
Estos modelos, dotados de grandes capacidades para tareas multimodales de propósito general, están diseñados para evaluar a los desarrolladores en tareas de generación de contenidos y resolución de problemas. Cada variante del modelo está optimizada para casos de uso específicos, garantizando un rendimiento óptimo en diversos escenarios.
Gemini AI aborda el equilibrio entre recursos informáticos y funcionalidad ofreciendo tres tamaños de modelo:
|
Modelo |
Talla |
Capacidades |
Casos de uso ideales |
|
Gemini Ultra |
La más grande |
Más capaz, maneja tareas muy complejas |
Aplicaciones exigentes, proyectos a gran escala, resolución de problemas complejos |
|
Gemini Pro |
Medio |
Versátil, adecuado para una amplia gama de tareas, escalable |
Aplicaciones de uso general, adaptables a diversos escenarios, proyectos que requieren un equilibrio entre potencia y eficacia |
|
Gemini Nano |
El más pequeño |
Ligero y eficiente, optimizado para entornos en el dispositivo y con recursos limitados |
Aplicaciones móviles, sistemas embebidos, tareas con recursos computacionales limitados, procesamiento en tiempo real pen_spark |
Nos centraremos principalmente en Gemini 1.5 Pro, el primer modelo lanzado dentro de la serie Gemini 1.5.
Gemini 1.5 Pro, con su gran ventana de contexto de hasta al menos 10 millones de fichas, puede abordar el reto de comprender contextos largos en un amplio espectro de aplicaciones en escenarios del mundo real.
Se ha llevado a cabo una evaluación exhaustiva de las tareas de dependencia larga para evaluar a fondo las capacidades de contexto largo del modelo Gemini 1.5 Pro. El modelo Gemini 1.5 Pro abordó hábilmente la difícil tarea de la "aguja en un pajar", logrando un recuerdo casi perfecto (>99%) de la "aguja" incluso en medio de pajares que abarcaban varios millones de tokens en todas las modalidades, incluyendo texto, vídeo y audio.
Este rendimiento de recuerdo se mantuvo notablemente incluso con tamaños de pajar que alcanzaban los 10 millones de tokens dentro de la modalidad de texto.
El modelo Gemini 1.5 Pro superó a todos los modelos de la competencia, incluidos los aumentados con métodos de recuperación externos, sobre todo en tareas que requieren una comprensión de las interdependencias entre múltiples pruebas que abarcan ampliamente todo el contenido largo, como las instancias de Pregunta-Respuesta (QA) de larga dependencia.
Gemini 1.5 Pro también ha demostrado su notable capacidad, facilitada por textos muy largos, para aprender tareas en contexto, como traducir un nuevo idioma a partir de un único conjunto de documentación lingüística.
Este avance en el rendimiento de Gemini 1.5 Pro en contextos largos es digno de mención, ya que no compromete las capacidades multimodales fundamentales del modelo. Comparado con su predecesor (1.0 Pro), mejoró sustancialmente en varias áreas (+28,9% en Matemáticas, Ciencias y Razonamiento).
Incluso supera al modelo 1.0 Ultra de gama alta en más de la mitad de las pruebas de rendimiento, destacando especialmente en tareas de texto y visión (como se muestra en la tabla siguiente). Esto se consigue a pesar de requerir menos recursos y ser más eficiente desde el punto de vista computacional.
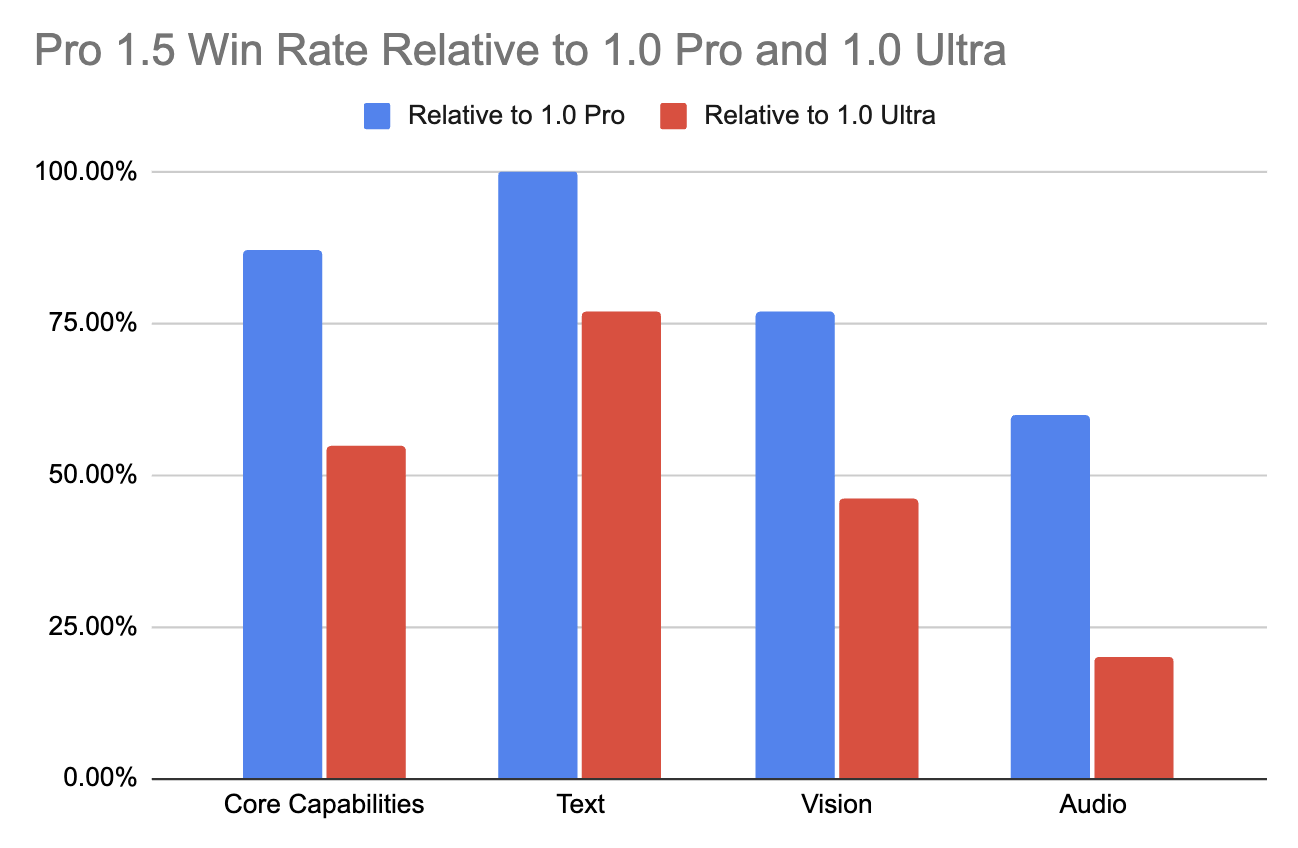 UltraFuente dealtdatosalt.
UltraFuente dealtdatosalt.
Para una visión más detallada, recomiendo consultar el informe técnico: "Géminis 1.5: Desbloqueando la comprensión multimodal a través de millones de tokens de contexto"para una visión más detallada".
Con la capacidad de procesar varios millones de fichas, surgen nuevas aplicaciones prácticas.
Gemini 1.5 Pro puede utilizarse ampliamente en ingeniería de software. Dada toda la base de código JAX de 746.152 tokens en contexto, Gemini 1.5 Pro puede identificar la ubicación específica de un método de diferenciación automática del núcleo.
Con acceso a un libro de gramática de referencia y a una lista bilingüe de palabras (total de ∼250k), Gemini 1.5 Pro puede traducir del inglés al kalamang con una calidad comparable a la de un humano que haya estudiado con los mismos recursos.
La limitada disponibilidad de datos en línea para el kalamang (menos de 200 hablantes) obliga a Gemini 1.5 Pro a basarse únicamente en el contexto proporcionado en cada pregunta para comprender y traducir la lengua. Este hallazgo sugiere oportunidades prometedoras para utilizar LLM con capacidades contextuales ampliadas para ayudar a preservar y revivir lenguas en peligro y fomentar la comunicación y la comprensión entre distintas comunidades lingüísticas.
Géminis 1.5 Pro también puede responder a una consulta de imágenes a partir del texto completo de Los Miserables (1382 páginas, 732k tokens). Al ser nativamente multimodal, el modelo puede identificar una escena famosa a partir de un boceto dibujado a mano.
Dada una película muda de 45 minutos "Sherlock Jr." (2.674 fotogramas a 1FPS, 684k tokens), Gemini 1.5 Pro recupera y extrae información textual de un fotograma concreto y proporciona la correspondiente marca de tiempo. El modelo también puede identificar una escena de la película a partir de un boceto dibujado a mano.
Ahora que conocemos las capacidades y aplicaciones de Gemini 1.5 Pro, vamos a aprender a conectarnos a su API.
En primer lugar, necesitamos obtener una clave API de la página de Google AI para Desarrolladores (asegúrate de haber iniciado sesión en tu cuenta de Google). Podemos hacerlo pulsando el botón Obtener una clave API:
A continuación, tenemos que establecer el proyecto y producir la clave API.
Primero instalemos el paquete API Python Gemini utilizando pip.
%pip install google-generativeaiA continuación, iniciaremos nuestro cuaderno Jupyter e importaremos las bibliotecas esenciales de Python necesarias para nuestro proyecto.
import google.generativeai as genai
from google.generativeai.types import ContentType
from PIL import Image
from IPython.display import Markdown
import time
import cv2Empecemos por introducir nuestra clave API en la variable GOOGLE_API_KEY y configurarla:
GOOGLE_API_KEY = ‘your-api-key-goes-here’
genai.configure(api_key=GOOGLE_API_KEY)Antes de llamar a la API, vamos a comprobar primero los modelos disponibles a través de la API libre.
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)models/gemini-1.0-pro
models/gemini-1.0-pro-001
models/gemini-1.0-pro-latest
models/gemini-1.0-pro-vision-latest
models/gemini-1.5-flash-latest
models/gemini-1.5-pro-latest
models/gemini-pro
models/gemini-pro-visionAccedamos al modelo gemini-1.5-pro-latest:
model = genai.GenerativeModel('gemini-1.5-pro-latest')¡Ahora vamos a hacer nuestra primera llamada a la API y a activar Gemini 1.5 Pro!
response = model.generate_content("Please provide a list of the most influential people in the world.")
print(response.text)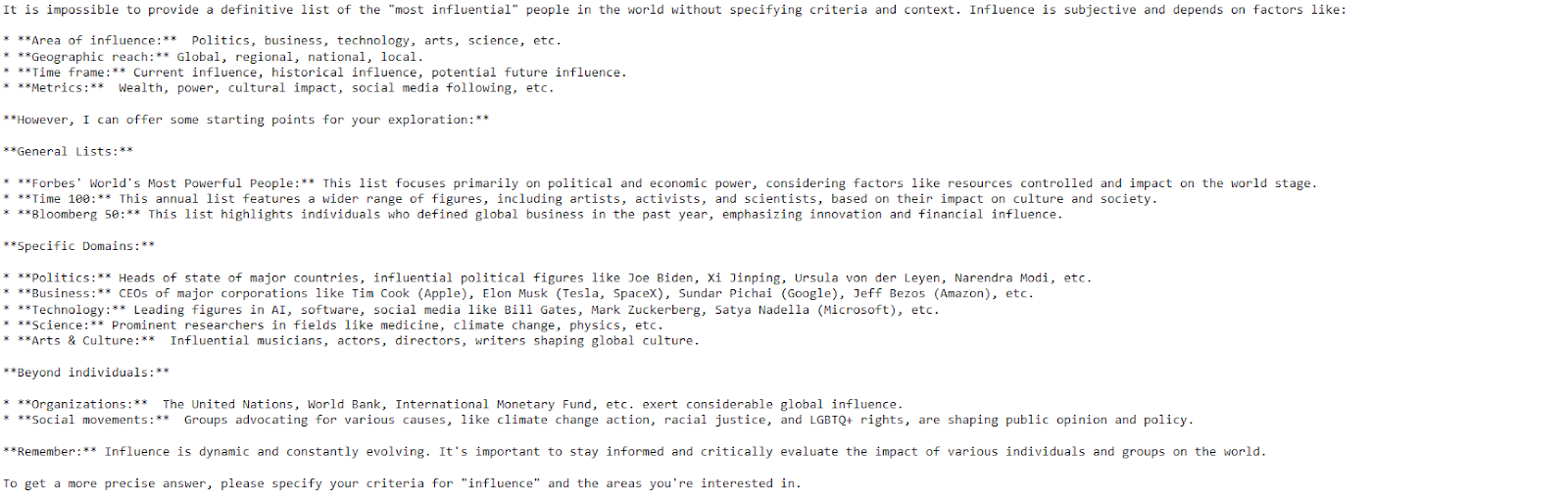
El modelo proporcionó una respuesta clara y detallada con sólo unas pocas líneas de código.
Gemini AI puede producir varias respuestas llamadas candidatas para una pregunta, permitiéndote seleccionar la más adecuada. 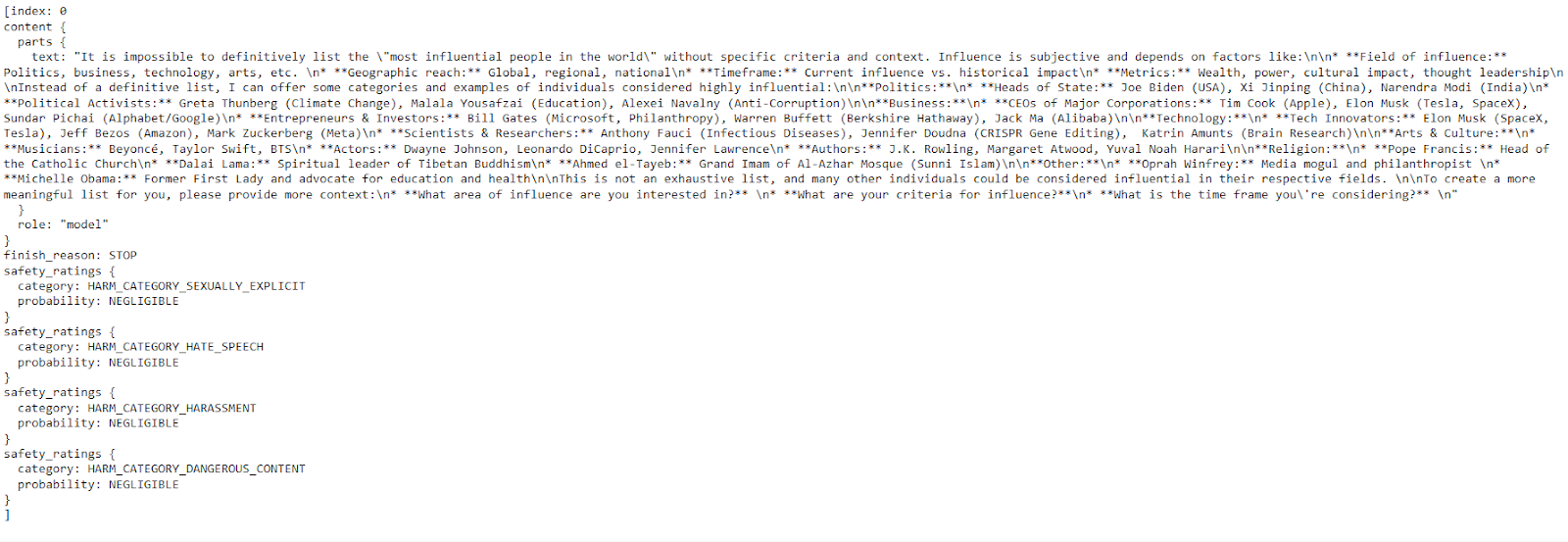
En esta sección, aprenderemos a aprovechar Gemini 1.5 Pro para automatizar la extracción de una lista de libros a partir de una imagen.
Consideremos primero esta imagen:

Imagen de una estantería con varios libros apilados.
Primero vamos a ordenar al modelo que identifique y enumere los títulos de los libros de la imagen siguiendo un orden determinado:
text_prompt = "List all the books and help me organize them into three categories."A continuación, abriremos nuestra imagen "estanteria.jpeg " utilizando la clase Image, preparándola para el análisis del modelo.
bookshelf_image = Image.open('bookshelf.jpeg')Pongamos text_prompt y bookshelf_image en una lista y preguntemos al modelo:
prompt = [text_prompt, bookshelf_image]
response = model.generate_content(prompt)Para evitar tener la salida en formato Markdown, vamos a utilizar la herramienta IPython Markdown.
Markdown(response.text)
El modelo ha conseguido clasificar con éxito todos los libros presentes en la imagen cargada en tres categorías diferentes .
En este tutorial hemos presentado Gemini 1.5 Pro, la primera versión de la familia Gemini 1.5. Además de sus capacidades multimodales y su eficacia, Gemini 1.5 Pro amplía la ventana de contenido en comparación con la serie Gemini 1.0, de 32.000 a varios millones de fichas.
Tanto si trabajas con texto, imágenes, vídeo o audio, la API Gemini 1.5 Pro ofrece la flexibilidad necesaria para abordar diversas aplicaciones, desde la recuperación de información y la respuesta a preguntas hasta la generación de contenidos y la traducción.
Si quieres aprender más sobre IA, echa un vistazo a este itinerario de seis cursos sobre Fundamentos de la IA.
Más información sobre los LLM
programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Richie Cotton
Tutorial
Matt Crabtree
Tutorial
Abid Ali Awan


