Programa
Fundamentos da IA
10 h
O Gemini 1.5 Pro representa um avanço significativo na família Gemini. Ele apresenta o raciocínio de contexto longo, que nos permite trabalhar com conjuntos de dados maciços em várias modalidades (texto, vídeo e áudio).
Neste tutorial, você aprenderá a se conectar à API Gemini 1.5 Pro. Aprenderemos a executar tarefas como recuperação, resposta a perguntas de documentos longos e vídeos, reconhecimento automático de fala (ASR) de contexto longo e aprendizado no contexto.
Se você quiser saber mais sobre o Gemini, confira este artigo sobre O que é o Google Gemini.
O Gemini AI engloba uma série de modelos de IA generativa desenvolvidos em colaboração por várias equipes do Google, incluindo o Google Research e o Google DeepMind.
Esses modelos, equipados com recursos avançados para tarefas multimodais de uso geral, foram projetados para avaliar os desenvolvedores em tarefas de geração de conteúdo e resolução de problemas. Cada variante de modelo é otimizada para casos de uso específicos, garantindo o desempenho ideal em diversos cenários.
O Gemini AI aborda o equilíbrio entre recursos computacionais e funcionalidade, oferecendo três tamanhos de modelo:
|
Modelo |
Tamanho |
Recursos |
Casos de uso ideais |
|
Gemini Ultra |
Maior |
Mais capaz, lida com tarefas altamente complexas |
Aplicativos exigentes, projetos de grande escala, solução de problemas complexos |
|
Gemini Pro |
Médio |
Versátil, adequado para uma ampla gama de tarefas, escalável |
Aplicativos de uso geral, adaptáveis a diversos cenários, projetos que exigem um equilíbrio entre potência e eficiência |
|
Gemini Nano |
Menor |
Leve e eficiente, otimizado para ambientes no dispositivo e com recursos limitados |
Aplicativos móveis, sistemas incorporados, tarefas com recursos computacionais limitados, processamento em tempo real pen_spark |
Nosso foco principal será o Gemini 1.5 Pro, o primeiro modelo lançado da série Gemini 1.5.
O Gemini 1.5 Pro, com sua grande janela de contexto de até pelo menos 10 milhões de tokens, pode enfrentar o desafio de compreender contextos longos em um amplo espectro de aplicativos em cenários do mundo real.
Uma avaliação abrangente das tarefas de dependência longa foi realizada para avaliar completamente os recursos de contexto longo do modelo Gemini 1.5 Pro. O modelo Gemini 1.5 Pro lidou habilmente com a desafiadora tarefa "agulha em um palheiro", alcançando uma recuperação quase perfeita (>99%) da "agulha", mesmo em meio a palheiros com vários milhões de tokens em todas as modalidades, incluindo texto, vídeo e áudio.
Esse desempenho de recuperação foi mantido de forma notável, mesmo com tamanhos de palheiro chegando a 10 milhões de tokens na modalidade de texto.
O modelo Gemini 1.5 Pro superou todos os modelos concorrentes, inclusive os que foram ampliados com métodos de recuperação externos, especialmente em tarefas que exigem uma compreensão das interdependências entre várias evidências que abrangem todo o conteúdo longo, como instâncias de perguntas e respostas (QA) de longa dependência.
O Gemini 1.5 Pro também demonstrou sua notável capacidade, possibilitada por textos muito longos, de aprender tarefas no contexto, como a tradução de um novo idioma a partir de um único conjunto de documentação linguística.
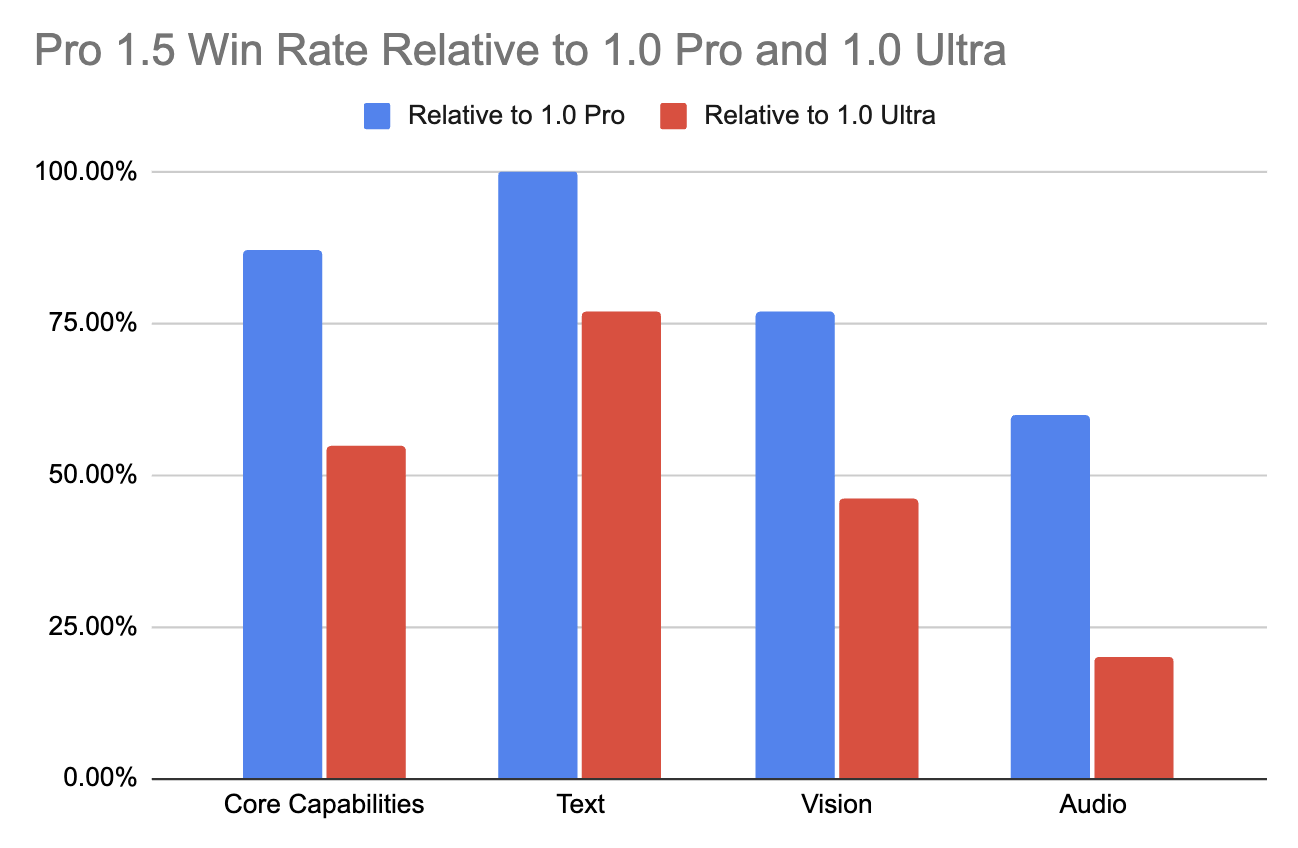
Esse avanço no desempenho do Gemini 1.5 Pro em contextos longos é digno de nota, pois não compromete os recursos multimodais fundamentais do modelo. Em comparação com seu antecessor (1.0 Pro), ele melhorou substancialmente em várias áreas (+28,9% em matemática, ciências e raciocínio).
Ele supera até mesmo o modelo topo de linha 1.0 Ultra em mais da metade dos benchmarks, destacando-se especialmente em tarefas de texto e visão (conforme mostrado na tabela abaixo). Isso é alcançado apesar de exigir menos recursos e ser mais eficiente em termos de computação.
Para obter informações mais detalhadas, recomendo que você consulte o relatório técnico: “Gemini 1.5: Desbloqueio do entendimento multimodal em milhões de tokens de contexto"para obter insights mais detalhados.
Com a capacidade de processar vários milhões de tokens, surgem novos aplicativos práticos.
O Gemini 1.5 Pro pode ser amplamente utilizado na engenharia de software. Com o contexto de toda a base de código JAX de 746.152 tokens, o Gemini 1.5 Pro pode identificar o local específico de um método de diferenciação automática principal.
Com acesso a um livro de gramática de referência e a uma lista de palavras bilíngue (total de ∼250k), o Gemini 1.5 Pro pode traduzir do inglês para o Kalamang com uma qualidade comparável à de um ser humano que estudou usando os mesmos recursos.
A disponibilidade limitada de dados on-line para o Kalamang (menos de 200 falantes) força o Gemini 1.5 Pro a depender exclusivamente do contexto fornecido em cada prompt para entender e traduzir o idioma. Essa descoberta sugere oportunidades promissoras para a utilização de LLMs com habilidades contextuais ampliadas para ajudar a preservar e reviver idiomas ameaçados de extinção e promover a comunicação e a compreensão entre diferentes comunidades linguísticas.
O Gemini 1.5 Pro também pode responder a uma consulta de imagem com o texto completo de Les Misérables (1382 páginas, 732 mil tokens). Por ser nativamente multimodal, o modelo pode identificar uma cena famosa a partir de um esboço desenhado à mão.
Dado um filme mudo de 45 minutos "Sherlock Jr." (2.674 quadros a 1FPS, 684 mil tokens), o Gemini 1.5 Pro recupera e extrai informações textuais de um quadro específico e fornece o registro de data e hora correspondente. O modelo também pode identificar uma cena do filme a partir de um esboço desenhado à mão.
Agora que você já conhece os recursos e os aplicativos do Gemini 1.5 Pro, vamos aprender como se conectar à sua API.
Primeiro, precisamos obter uma chave de API na página Google AI for Developers (certifique-se de que você esteja conectado à sua conta do Google). Você pode fazer isso clicando no botão Obter uma chave de API:
Em seguida, precisamos estabelecer o projeto e produzir a chave de API.
Primeiro, vamos instalar o pacote Gemini Python API usando pip.
%pip install google-generativeaiEm seguida, iniciaremos nosso notebook Jupyter e importaremos as bibliotecas Python essenciais necessárias para nosso projeto.
import google.generativeai as genai
from google.generativeai.types import ContentType
from PIL import Image
from IPython.display import Markdown
import time
import cv2Vamos começar preenchendo nossa chave de API na variável GOOGLE_API_KEY e configurá-la:
GOOGLE_API_KEY = ‘your-api-key-goes-here’
genai.configure(api_key=GOOGLE_API_KEY)Antes de chamar a API, vamos primeiro verificar os modelos disponíveis por meio da API gratuita.
for m in genai.list_models():
if 'generateContent' in m.supported_generation_methods:
print(m.name)models/gemini-1.0-pro
models/gemini-1.0-pro-001
models/gemini-1.0-pro-latest
models/gemini-1.0-pro-vision-latest
models/gemini-1.5-flash-latest
models/gemini-1.5-pro-latest
models/gemini-pro
models/gemini-pro-visionVamos acessar o modelo gemini-1.5-pro-latest:
model = genai.GenerativeModel('gemini-1.5-pro-latest')Agora, vamos fazer nossa primeira chamada à API e ativar o Gemini 1.5 Pro!
response = model.generate_content("Please provide a list of the most influential people in the world.")
print(response.text)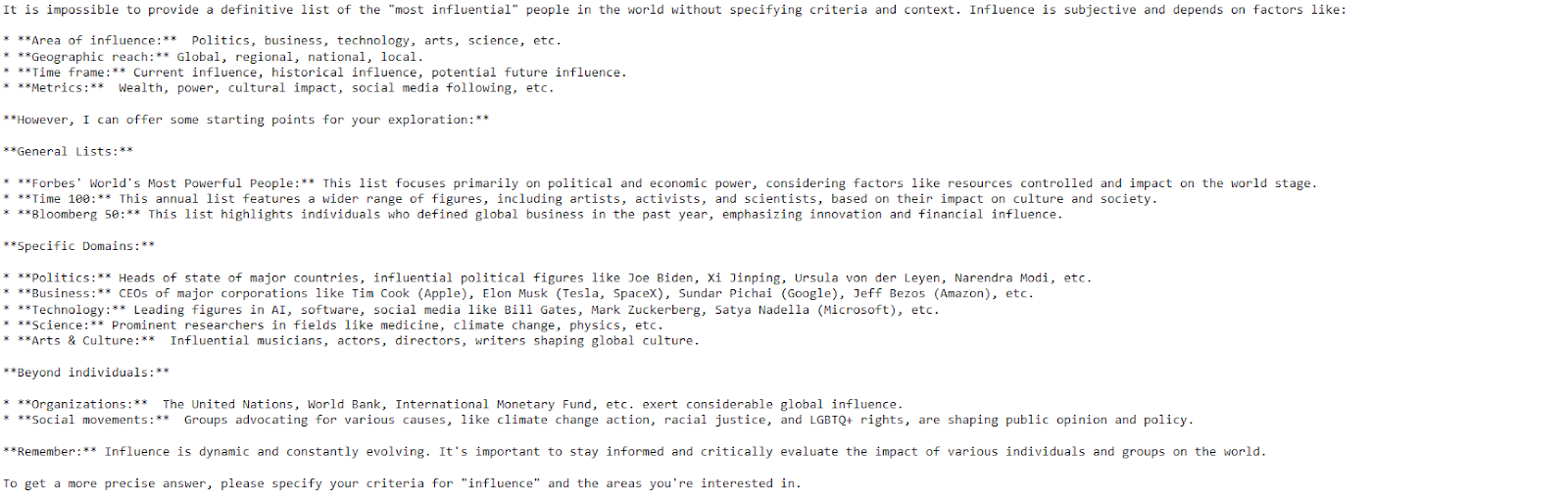
O modelo forneceu uma resposta clara e detalhada com apenas algumas linhas de código.
O Gemini AI pode produzir várias respostas chamadas de candidatas para um prompt, permitindo que você selecione a mais adequada. 
Nesta seção, aprenderemos como aproveitar o Gemini 1.5 Pro para automatizar a extração de uma lista de livros de uma imagem!
Primeiro, vamos considerar esta imagem:

Uma imagem de uma estante com vários livros empilhados sobre ela.
Primeiro, vamos instruir o modelo a identificar e listar os títulos dos livros na imagem seguindo uma ordem específica:
text_prompt = "List all the books and help me organize them into three categories."Em seguida, abriremos nossa imagem "bookshelf.jpeg" usando a classe Image, preparando-a para a análise do modelo.
bookshelf_image = Image.open('bookshelf.jpeg')Vamos colocar text_prompt e bookshelf_image em uma lista e solicitar ao modelo:
prompt = [text_prompt, bookshelf_image]
response = model.generate_content(prompt)Para evitar que você tenha a saída no formato Markdown, vamos usar a ferramenta IPython Markdown.
Markdown(response.text)
O modelo conseguiu categorizar com sucesso todos os livros presentes na imagem carregada em três categorias diferentes.
Neste tutorial, apresentamos o Gemini 1.5 Pro, a primeira versão da família Gemini 1.5. Além de seus recursos multimodais e de sua eficiência, o Gemini 1.5 Pro expande a janela de conteúdo em comparação com a série Gemini 1.0 de 32 mil para vários milhões de tokens.
Seja trabalhando com texto, imagens, vídeo ou áudio, a API Gemini 1.5 Pro oferece a flexibilidade necessária para lidar com vários aplicativos, desde a recuperação de informações e resposta a perguntas até a geração de conteúdo e tradução.
Se você quiser saber mais sobre IA, confira este programa de seis cursos de habilidades AI Fundamentals.
Saiba mais sobre os LLMs!
Programa
Curso
Curso
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev



