
Curso
Fundamentos de PySpark
4 h
157.5K
Imagina que gestionas una plataforma de comercio electrónico que procesa miles de transacciones diarias. Quieres analizar las tendencias de ventas, realizar un seguimiento del crecimiento de los ingresos y pronosticar los ingresos futuros. Las consultas de bases de datos tradicionales no pueden manejar esta escala o velocidad. Por lo tanto, necesitas una forma más rápida de procesar grandes conjuntos de datos y obtener información en tiempo real.
Apache Spark lte permite analizar grandes volúmenes de datos de manera eficiente. En este tutorial, te mostraré cómo conectar Django, MongoDB y Apache Spark para analizar datos de transacciones de comercio electrónico.
Configurarás un proyecto Django con MongoDB como base de datos y almacenarás datos de transacciones en él. A continuación, utilizarás PySpark, la API de Python para Apache Spark, para leer y filtrar los datos. También realizarás cálculos básicos y guardarás los datos procesados en MongoDB. Por último, mostrarás los datos procesados en tu aplicación Django.
Para sacar el máximo partido a este tutorial, debes tener conocimientos básicos de Python y del marco web Django.
Ahora, vamos a profundizar en el tema.
Comienza creando un entorno virtual para tu proyecto Django:
python -m venv venv
source venv/bin/activateAsegúrate de tener Python 3.10 o una versión posterior instalada en tu entorno virtual. A continuación, instala el backend MongoDB de Django:
pip install django-mongodb-backendEl comando anterior también instala las últimas versiones de PyMongo 4.x y Django 5.2.x.
Una vez que hayas descargado Django MongoDB Backend, crea un nuevo proyecto Django:
django-admin startproject pyspark_tutorialAhora, ve a la carpeta del proyecto y ejecuta el servidor de desarrollo para confirmar que tu proyecto está correctamente configurado:
cd pyspark_tutorial
python manage.py runserverVisita http://127.0.0.1:8000/ para comprobar que tu proyecto Django se está ejecutando correctamente.
Por defecto, Django utiliza identificadores enteros de tipo `AutoField ` como claves primarias, lo que funciona bien con bases de datos SQL. Sin embargo, MongoDB utiliza ObjectId para los ID de los documentos. Para que tus modelos sean compatibles, necesitas que Django genere claves primarias como ObjectId en lugar de enteros.
Abrir pyspark_tutorial/settings.py y actualiza la DEFAULT_AUTO_FIELD configuración:
DEFAULT_AUTO_FIELD = 'django_mongodb_backend.fields.ObjectIdAutoField'Incluso con esta configuración global, las aplicaciones integradas de Django, como admin, auth y contenttypes, seguirán utilizando por defecto AutoField. Para garantizar la coherencia en todas las aplicaciones, crea configuraciones de aplicaciones personalizadas para que utilicen ObjectId.
Crea un pyspark_tutorial/apps.py archivo y añade lo siguiente:
from django.contrib.admin.apps import AdminConfig
from django.contrib.auth.apps import AuthConfig
from django.contrib.contenttypes.apps import ContentTypesConfig
class MongoAdminConfig(AdminConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoAuthConfig(AuthConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoContentTypesConfig(ContentTypesConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'Ahora, en pyspark_tutorial/settings.py, actualiza la configuración de INSTALLED_APPS:
INSTALLED_APPS = [
'pyspark_tutorial.apps.MongoAdminConfig',
'pyspark_tutorial.apps.MongoAuthConfig',
'pyspark_tutorial.apps.MongoContentTypesConfig',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]Dado que todos los modelos deben utilizar ObjectIdAutoField, cada aplicación de terceros y contrib que utilices debe tener sus propias migraciones específicas para MongoDB. Añade lo siguiente al archivo pyspark_tutorial/setting.py:
MIGRATION_MODULES = {
'admin': 'mongo_migrations.admin',
'auth': 'mongo_migrations.auth',
'contenttypes': 'mongo_migrations.contenttypes',
}Crea una carpeta mongo_migrations en la carpeta de tu proyecto, al mismo nivel que tu archivomanage.py. En este punto, la estructura de carpetas debería ser similar a esta:
pyspark_tutorial/
├── pyspark_tutorial/
├── mongo_migrations/
└── manage.pyDetén el servidor con **Ctrl + C** y, a continuación, genera tus migraciones:
python manage.py makemigrations admin auth contenttypesSi revisas la carpeta « mongo_migrations », verás una carpeta para cada aplicación integrada. Cada carpeta contiene sus migraciones.
Para obtener una plantilla de proyecto Django que tenga todas las configuraciones anteriores de MongoDB, ejecuta:
django-admin startproject pyspark_tutorial --template https://github.com/mongodb-labs/django-mongodb-project/archive/refs/heads/5.2.x.zipNota: Si utilizas una versión de Django distinta a la 5.2.x, sustituye los dos números por los dos primeros números de tu versión.
El siguiente paso es crear una aplicación Django para almacenar tus registros de transacciones sin procesar y procesados.
python manage.py startapp salesPara configurar tu nueva aplicación para que utilice ObjectId, abre sales/apps.py y sustituye la línea default_auto_field = 'django.db.models.BigAutoField':
from django.apps import AppConfig
class SalesConfig(AppConfig):
# Use ObjectId as the default primary key field type for MongoDB:
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
name = 'sales'Como alternativa, puedes utilizar la siguiente plantilla startapp, que incluye el cambio anterior:
python manage.py startapp sales --template https://github.com/mongodb-labs/django-mongodb-app/archive/refs/heads/5.2.x.zipAhora, en pyspark_tutorial/settings.py, añade tu aplicación sales a la listaINSTALLED_APPS:
INSTALLED_APPS = [
# Add your sales app:
'sales.apps.SalesConfig',
...
]Dado que almacenarás tus datos en MongoDB, te explicaré cómo crear una implementación de nivel gratuito en MongoDB Atlas para almacenar y gestionar tus datos en la nube.
Regístrate para obtener una cuenta de Atlas utilizando tu cuenta de Google o una dirección de correo electrónico.
Haz clic en Crear para crear un clúster de Free:
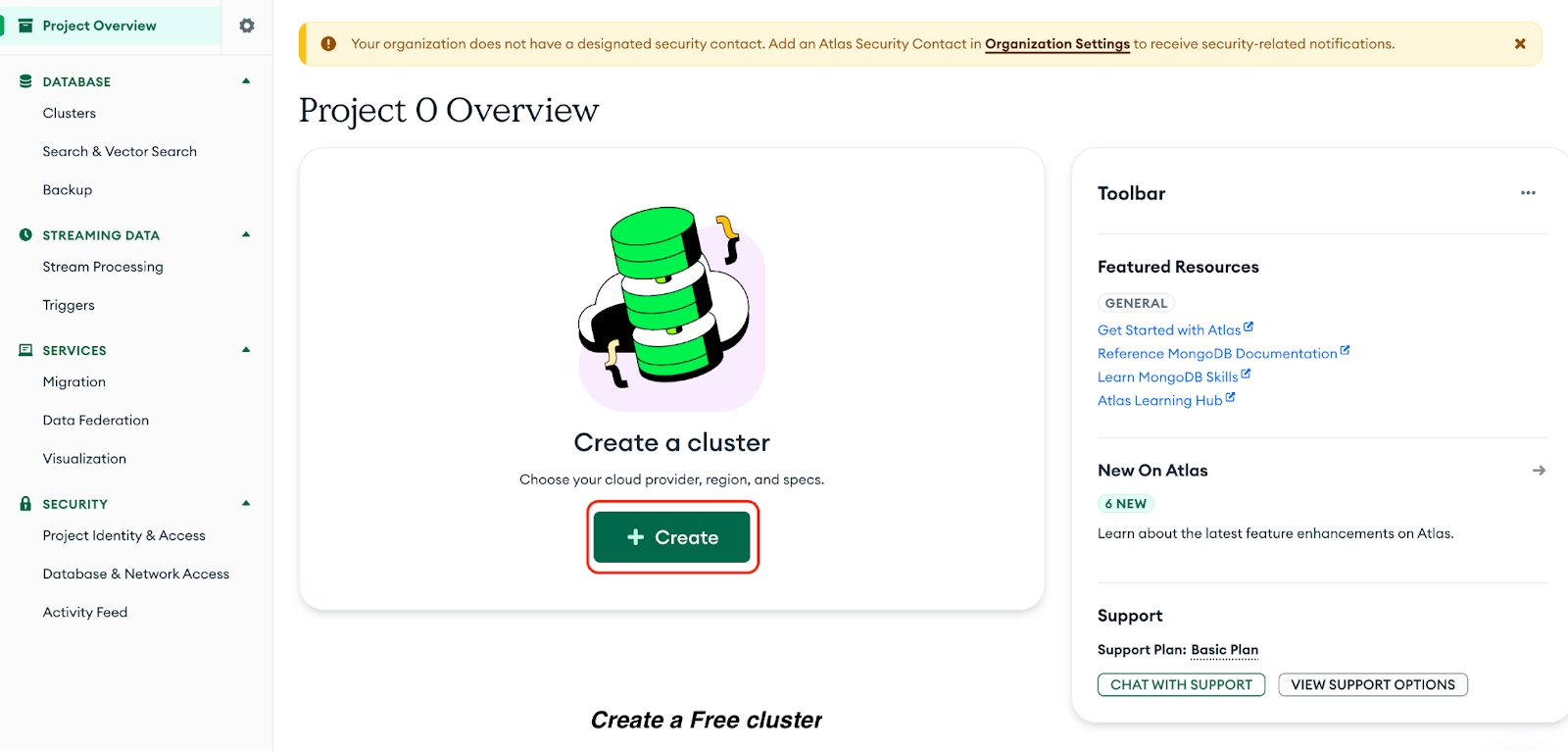
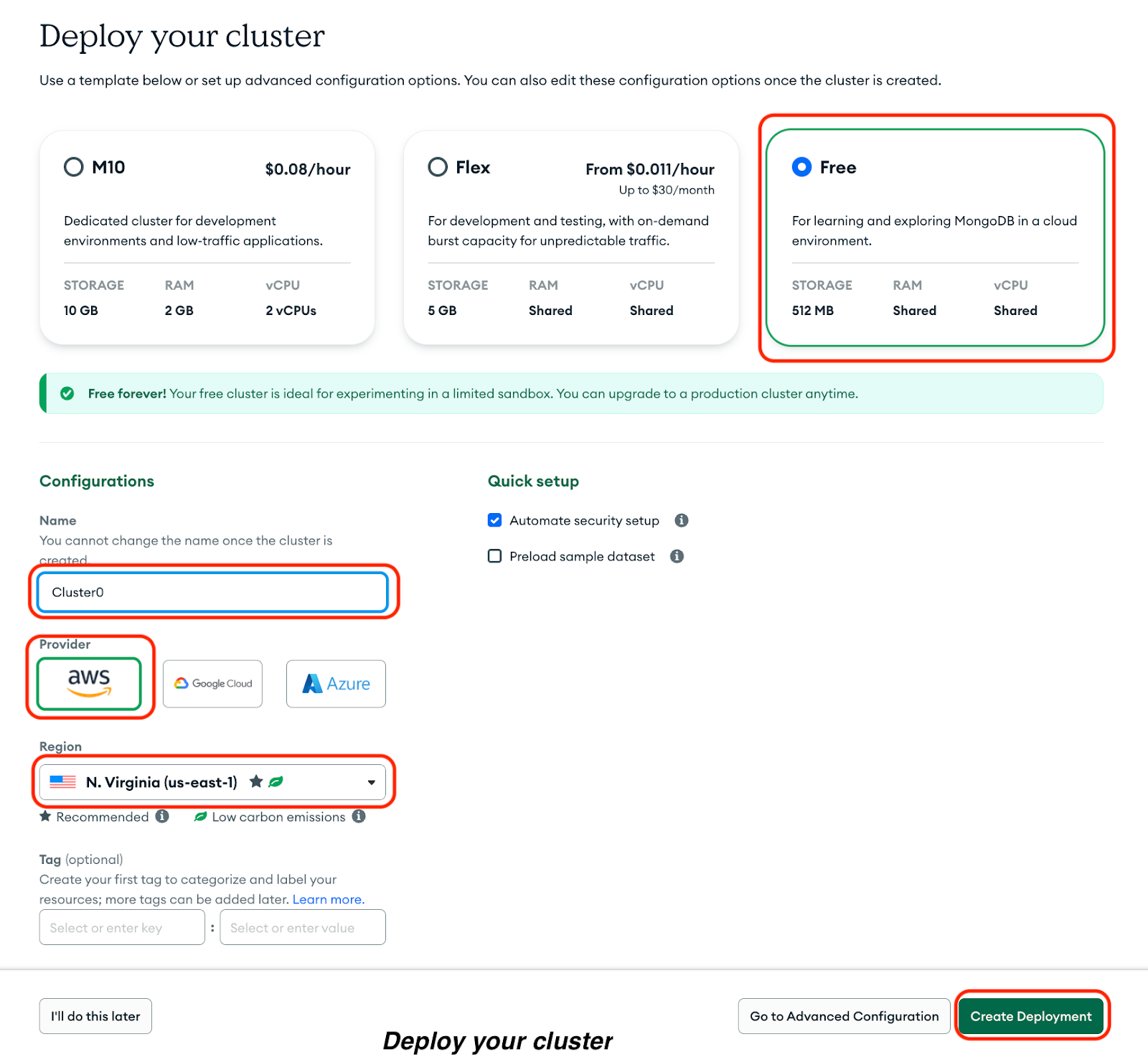
Ahora, selecciona las siguientes opciones en la página resultante:
Haz clic en Crear implementación:
Verás tu nombre de usuario y contraseña. Haz lo siguiente:
1. Copia tu nombre de usuario y contraseña en un documento seguro.
2. Haz clic en« » (Crear usuario de base de datos).
3. Haz clic en« » (Configuración de red). Elige un método de conexión para establecer una dirección IP de conexión.
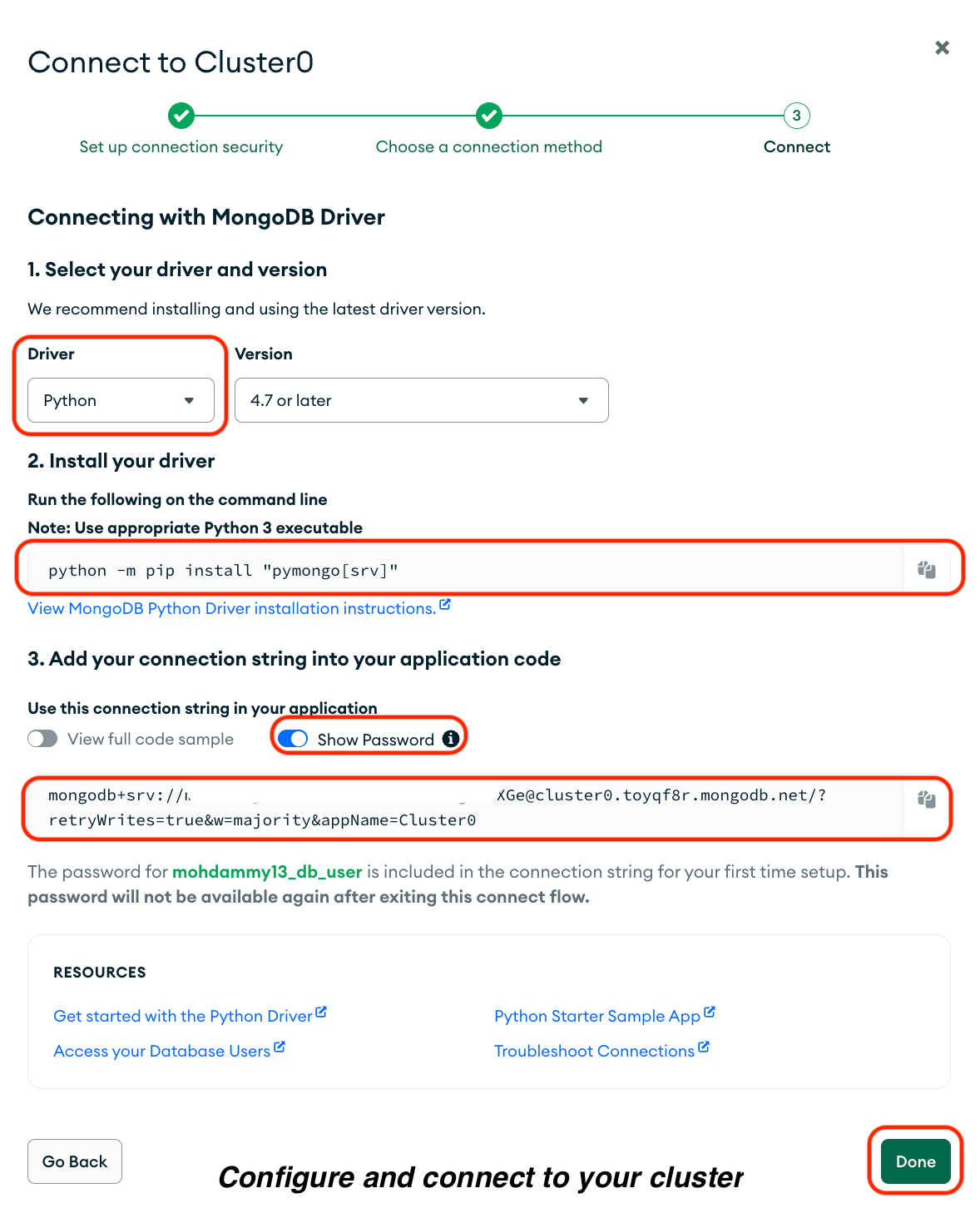
En la página resultante, haz lo siguiente:
1. Selecciona« » (Controladores).

2. Selecciona« Python» como controlador.
3. Copia el comando de la opción«Install your driver» (Instala tu controlador) y ejecútalo en tu terminal.
4. Copia tu connection string, incluida tu contraseña, en Añade tu cadena de conexión al código de tu aplicación, y guárdala en un documento seguro.
5. Haz clic en« » (Aceptar). Listo.
Abre pyspark_tutorial/settings.py y actualiza la configuración DATABASES para utilizar el backend MongoDB de Django con tu connection string guardado . Establece también un nombre para la base de datos:
DATABASES = {
'default': {
# Change to use Django MongoDB Backend:
'ENGINE': 'django_mongodb_backend',
# Use your saved connection string:
'HOST': '<connection string>',
# Set a database name:
'NAME': 'pyspark_tutorial',
},
}En el código anterior, asegúrate de sustituir por la cadena de conexión que hayas guardado.
Esta configuración conecta Django a tu clúster MongoDB Atlas. ENGINE apunta al backend de MongoDB, HOST almacena tu cadena de conexión y NAME define el nombre de la base de datos que utilizará Django.
Ahora que tu aplicación está configurada, crearás los modelos, vistas, URL y plantillas necesarios para mostrar los datos de las transacciones en tu navegador.
Los modelos describen la estructura de tus datos. Crea un modelo para representar los registros de transacciones. Abre sales/models.py y sustituye el código:
from django.db import models
# Define a model to represent each transaction record:
class Transaction(models.Model):
order_id = models.CharField(max_length=50, unique=True)
user_id = models.CharField(max_length=50)
product = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
quantity = models.PositiveIntegerField()
timestamp = models.DateTimeField()
country = models.CharField(max_length=50)
class Meta:
# Sort transactions by order ID:
ordering = ['order_id']
# Add indexes to improve query performance for common lookup fields
indexes = [
models.Index(fields=['timestamp']),
models.Index(fields=['country']),
models.Index(fields=['product']),
]
def __str__(self):
return f'{self.order_id} - {self.product}'
@property
def total_amount(self):
# Calculate and return the total transaction amount:
return self.price * self.quantityEste modelo define cada transacción con campos para los detalles del producto, el precio, la cantidad y el país. Ordena las transacciones por order_id. También incluye un índice en campos clave para mejorar el rendimiento de las consultas y una propiedad que calcula el importe total de la transacción.
Las vistas controlan cómo aparecen esos registros en el navegador. Crea una vista para mostrar los registros de transacciones. Abre sales/views.py y sustituye el código:
from django.shortcuts import render
from .models import Transaction
# Define a view to display all transactions and total revenue:
def transaction_list_view(request):
# Retrieve all transaction records from the database:
transactions = Transaction.objects.all()
# Calculate the total revenue from all transactions:
total_revenue = sum(t.total_amount for t in transactions)
# Render the transaction list template with context data
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})La vista anterior recupera todos los registros de transacciones de MongoDB utilizando el modelo Transaction. Calcula los ingresos totales sumando el campo « total_amount » (Ingresos totales) de cada transacción. A continuación, envía dos valores a una plantilla transaction_list.html , que crearemos más adelante:
* transactions: una lista de todos los registros de transacciones que se mostrarán en una tabla.
* total_revenue: el importe total generado por todas las transacciones.
La plantilla utilizará estos valores para mostrar cada transacción y los ingresos totales.
Debes crear rutas para que Django sepa qué vista cargar cuando los usuarios visiten una URL. Crea un archivo sales/urls.py y añade lo siguiente:
from django.urls import path
from . import views
# Define URL patterns for the sales app:
urlpatterns = [
# Route the root URL to the transaction list view:
path('', views.transaction_list_view, name='transaction_list'),
]Incluye las URL de tu aplicación en la configuración de URL de tu proyecto. Abre pyspark_tutorial/urls.py y actualízalo así:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# Include your app’s URLs:
path("", include('sales.urls')),
]Las plantillas definen cómo se muestran tus datos en el navegador. Crea una carpeta llamada « sales/templates/sales » y añade un archivo llamado «transaction_list.html » dentro de ella.
Tu sales estructura de la aplicación debería ser similar a esta:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
└── templates/
└── sales/
└── transaction_list.htmlAñade lo siguiente al archivo transaction_list.html:
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
</head>
<body>
<h1>E-commerce Transactions</h1>
<h3>Total Revenue: ${{ total_revenue }}</h3>
<table>
<thead>
<tr>
<th>Order ID</th>
<th>User ID</th>
<th>Product</th>
<th>Price</th>
<th>Quantity</th>
<th>Country</th>
<th>Timestamp</th>
</tr>
</thead>
<tbody>
{% for t in transactions %}
<tr>
<td>{{ t.order_id }}</td>
<td>{{ t.user_id }}</td>
<td>{{ t.product }}</td>
<td>${{ t.price }}</td>
<td>{{ t.quantity }}</td>
<td>{{ t.country }}</td>
<td>{{ t.timestamp }}</td>
</tr>
{% empty %}
<tr><td colspan="7">No transactions available.</td></tr>
{% endfor %}
</tbody>
</table>
</body>
</html>La plantilla anterior utiliza el lenguaje de plantillas de Django para mostrar dinámicamente los datos pasados desde la vista.
En la parte superior, se muestra el ingreso total utilizando {{ total_revenue }}. A continuación, la plantilla recorre todos los registros de transacciones utilizando la etiqueta « {% for t in transactions %} » y muestra cada registro como una fila en la tabla. Cada columna muestra un atributo específico de una transacción, como order_id, product, price, quantity y country. Si no hay registros, la etiqueta ` {% empty %} ` garantiza que aparezca el mensaje «No hay transacciones disponibles» en lugar de una tabla vacía.
Para que tu página de transacciones resulte más atractiva visualmente y más fácil de leer, añadirás estilos CSS personalizados. Django sirve archivos estáticos, como CSS, JavaScript e imágenes, a través de un directorio especial llamado static. Esto mantiene los archivos de diseño separados de tu código.
Ahora, crea una carpeta llamada « sales/static/sales » y añade un archivo llamado « styles.css » dentro de ella. La estructura de tu carpeta sales debería tener este aspecto:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
├── templates/
│ └── sales/
│ └── transaction_list.html
└── static/
└── sales/
└── styles.cssEn pyspark_tutorial/settings.py, asegúrate de queSTATIC_URL esté definido:
STATIC_URL = 'static/'Añade esto al archivo sales/static/sales/styles.css:
table {
width: 100%;
border-collapse: collapse;
margin-top: 20px;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f5f5f5;
}
body {
background-color:transparent;font-weight:400;font-style:normal;font-variant:normal;text-decoration:none;vertical-align:baseline;white-space:pre;white-space:pre-wrap;">: Arial, sans-serif;
margin: 20px;
}
h1 {
color: #333;
}
a {
text-decoration: none;
color: #007bff;
}
a:hover {
text-decoration: underline;
}Por último, indica a Django que cargue los archivos estáticos e incluya el archivo CSS en tu plantilla HTML.
En la parte superior de sales/templates/sales/transaction_list.html , añade {% load static %} y, a continuación, actualiza el elemento para que enlace con el archivostyles.css:
<!-- Load static files:-->
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
<!-- Link the CSS file for styling the template:-->
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>Genera y aplica tus migraciones para que Django pueda crear las colecciones necesarias en MongoDB:
python manage.py makemigrations
python manage.py migrateAhora, utilicemos los modelos de tu aplicación para añadir registros de transacciones a tu base de datos pyspark_tutorial utilizando el terminal interactivo de Django:
python manage.py shellA continuación, importa el modelo Transaction desde tu aplicación de ventas y timezone desde las utilidades de Django:
from sales.models import Transaction
from django.utils import timezoneAhora, inserta los registros de transacciones utilizando bulk_create():
Transaction.objects.bulk_create([
Transaction(order_id='T1001', user_id='U001', product='Laptop', price=1000.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1002', user_id='U002', product='Smartphone', price=800.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1003', user_id='U003', product='Headphones', price=150.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1004', user_id='U004', product='Laptop', price=1200.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1005', user_id='U005', product='Keyboard', price=45.00, quantity=3, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1006', user_id='U006', product='Monitor', price=300.00, quantity=2, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1007', user_id='U007', product='Smartwatch', price=199.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1008', user_id='U008', product='Speaker', price=150.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1009', user_id='U009', product='Camera', price=800.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1010', user_id='U010', product='Tablet', price=350.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1011', user_id='U011', product='Headphones', price=75.00, quantity=2, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1012', user_id='U012', product='Laptop', price=1300.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1013', user_id='U013', product='Mouse', price=30.00, quantity=3, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1014', user_id='U014', product='Smartphone', price=950.00, quantity=1, timestamp=timezone.now(), country='KE'),
Transaction(order_id='T1015', user_id='U015', product='Keyboard', price=55.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1016', user_id='U016', product='Smartwatch', price=250.00, quantity=1, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1017', user_id='U017', product='Speaker', price=180.00, quantity=1, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1018', user_id='U018', product='Monitor', price=400.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1019', user_id='U019', product='Laptop', price=1250.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1020', user_id='U020', product='Camera', price=780.00, quantity=1, timestamp=timezone.now(), country='US'),
])Comprueba que los registros se hayan añadido correctamente:
Transaction.objects.count()Si el recuento devuelve 20, tus registros se han guardado correctamente.
Ahora, sal de la terminal ejecutando exit() y inicia tu servidor Django para ver tus transacciones en el navegador:
python manage.py runserverVisita http://127.0.0.1:8000/ para confirmar que tus datos aparecen correctamente.
Ahora que tus registros están almacenados en tu base de datos MongoDB, utilizarás Apache Spark para procesar tus datos. Apache Spark incluye una API de Python, PySpark, que puedes utilizar en tu proyecto Django para procesar grandes conjuntos de datos.
Crearás un script de Python que utiliza PySpark para conectarse a MongoDB y leer tus registros de transacciones. Realizarás operaciones básicas con estos datos, como filtrarlos. A continuación, los agruparás por país y calcularás los ingresos totales de cada uno. Por último, escribirás los datos procesados en una nueva colección MongoDB en tu base de datos.
Detén tu servidor e instala la versión PySpark que sea compatible con la última versión de conector MongoDB Spark:
pip install pyspark==3.5.0Verifica que la instalación se haya realizado correctamente:
pyspark --versionDeberías recibir una respuesta dándote la bienvenida a Spark.
A continuación, crea un archivo transactions.py en la carpeta de tu proyecto, al mismo nivel que manage.py. Tu estructura de carpetas debería tener ahora este aspecto:
pyspark_tutorial/
├── mongo_migrations/
├── pyspark_tutorial/
├── sales/
├── manage.py
└── transactions.pyPara conectar PySpark a MongoDB, debes crear una cadena de conexión que incluya el nombre de tu base de datos y el nombre de la colección. Una colección en MongoDB es similar a una tabla en bases de datos relacionales y almacena documentos relacionados. El nombre de tu colección está compuesto por el nombre de tu aplicación y el nombre del modelo, separados por un guión bajo (_).
Utiliza la cadena de conexión integrada en tu archivo transactions.py . El formato correcto es:
mongodb+srv://<mongodb username>:<mongodb password>@<cluster address>/<database name>.<app name>_<model name>?retryWrites=true&w=majority&appName=Cluster0A continuación se explica el significado de los valores de los marcadores de posición:
cluster0.2rvn82q.mongodb.net.settings.py._ es el nombre de la colección generada a partir de tu aplicación y modelo Django, por ejemplo, sales_transaction.En esta sección, la cadena de conexión que utilizarás en tu código PySpark tendrá el siguiente aspecto:
mongodb+srv://db_user:password@cluster.mongodb.net/pyspark_tutorial.sales_transaction?retryWrites=true&w=majority&appName=Cluster0Añade el siguiente código al archivo transactions.py:
from pyspark.sql import SparkSession
# Initialize SparkSession with MongoDB connector:
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
# Add the MongoDB Spark connector package:
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
# Read data from MongoDB into a Spark DataFrame:
df = spark.read.format('mongodb').load()
# Show result:
df.show()
# Stop the Spark session:
spark.stop()from pyspark.sql import SparkSession es el punto de entrada para utilizar PySpark. Te permite interactuar con Spark y realizar operaciones con datos.
spark = SparkSession.builder inicializa una nueva sesión de Spark y le asigna un nombre, ReadTransactions. Las dos opciones .config() definen cómo Spark debe conectarse a MongoDB:
spark.mongodb.read.connection.urila cadena de conexión MongoDB que indica a Spark dónde se encuentra tu base de datos.spark.jars.packages: descarga el paquete del conector MongoDB Spark para que Spark pueda comunicarse con MongoDB.df = spark.read.format('mongodb').load() Carga todos los documentos de la colección definida en tu cadena de conexión en un DataFrame de PySpark, lo que facilita la consulta y transformación de tus datos..show() imprime una vista previa de tus datos de MongoDB en formato tabular directamente en la terminal.spark.stop() Cierra la aplicación Spark y libera los recursos del sistema una vez finalizado el trabajo.Por último, sustituye por tu cadena de conexión MongoDB creada. Además, asegúrate de que tu dirección IP actual esté incluida en la lista blanca de [la lista de acceso a la red de MongoDB Atlas](https://cloud.mongodb.com/) antes de conectarte.
Ahora, ejecuta python transactions.pyy obtendrás los registros de transacciones almacenados en tu base de datos en tu terminal.
También puedes filtrar tus registros utilizando funciones SQL de PySpark, por ejemplo, para mostrar solo las transacciones de Nigeria (NG). Modifica el código en tu archivo transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame column names:
from pyspark.sql.functions import col
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Filter transactions from Nigeria:
ng_df = df.filter(col('country') == 'NG')
# Show filtered results:
ng_df.show()
# Stop the Spark session:
spark.stop()Ejecuta python transactions.py de nuevo y verás las transacciones de NG.
También puedes agrupar tus registros de transacciones por país y calcular los ingresos totales de cada uno. Modifica el código en tu archivo transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame columns and import sum as _sum to avoid naming conflicts:
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country:
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Show total revenue per country:
revenue_per_country.show()
# Stop the Spark session:
spark.stop()Ejecuta python transactions.py. Verás una tabla que muestra los ingresos totales por país.
Ahora que ya sabes cómo utilizar PySpark para leer y procesar tus datos, te mostraré cómo escribir los datos procesados en una colección de MongoDB.
Aquí, escribirás el DataFrame que contiene los ingresos totales por país en una nueva colección.
Modifica el código en tu transactions.py archivo:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Write aggregated records into a new MongoDB collection:
revenue_per_country.write \
.format('mongodb') \
.mode('overwrite') \
.option(
'spark.mongodb.write.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.option(
# Specify the target database name:
'spark.mongodb.write.database',
'pyspark_tutorial'
) \
.option(
# Specify the target collection name:
'spark.mongodb.write.collection',
'revenue_per_country'
) \
.save()
# Stop the Spark session:
spark.stop()En el código anterior, Spark escribe el DataFrame agregado, revenue_per_country, en una nueva colección denominada revenue_per_country en tu base de datospyspark_tutorial en MongoDB.
Por último, asegúrate de sustituir '' en ambas configuraciones de conexión por tu cadena de conexión MongoDB creada con. A continuación, ejecuta python transactions.py.
Ahora, mostremos tus ingresos totales por país en una página de Django.
En primer lugar, creemos un nuevo modelo para los ingresos por país. Añade esto al final del archivo sales/models.py:
class RevenuePerCountry(models.Model):
country = models.CharField(max_length=50)
total_revenue = models.DecimalField(max_digits=15, decimal_places=2)
class Meta:
# Define the collection (table) name in MongoDB:
db_table = 'revenue_per_country'
# Order results by total_revenue when querying:
ordering = ['total_revenue']
def __str__(self):
# Return a readable string representation of the record:
return f'{self.country}: ${self.total_revenue}'A continuación, modifica tu archivo sales/views.py para recuperar y mostrar la colecciónrevenue_per_country:
from django.shortcuts import render
from .models import Transaction
# Import the RevenuePerCountry model:
from .models import RevenuePerCountry
def transaction_list_view(request):
transactions = Transaction.objects.all()
total_revenue = sum(t.total_amount for t in transactions)
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})
# Add a new view to fetch and display your revenue per country:
def revenue_per_country_view(request):
revenue_per_country = RevenuePerCountry.objects.all()
return render(request, 'sales/revenue_per_country.html', {'revenue_per_country': revenue_per_country})Incluye una ruta a la nueva vista en sales/urls.py:
from django.urls import path
from . import views
urlpatterns = [
path('', views.transaction_list_view, name='transaction_list'),
# Add new URL route:
path('revenue_per_country/', views.revenue_per_country_view, name='revenue_per_country'),
]A continuación, crea una nueva plantilla para mostrar los ingresos totales por país.
En la carpeta sales/templates/sales, crea un archivorevenue_per_country.html y añade lo siguiente:
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transactions</title>
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>
<body>
<h1>Total Revenue by Country</h1>
<a href="{% url 'transaction_list' %}">← Back to Transactions</a>
<table>
<tr>
<th>Country</th>
<th>Total Revenue (USD)</th>
</tr>
{% for r in revenue_per_country %}
<tr>
<td>{{ r.country }}</td>
<td>${{ r.total_revenue|floatformat:2 }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>También debes modificar la plantilla sales/templates/sales/transaction_list.html para incluir un enlace a la página de ingresos por país. Añade el siguiente código después de
:<a href="{% url 'revenue_per_country' %}">View Total Revenue by Country</a>
Ejecuta el servidor Django:
python manage.py runserver
Visita http://127.0.0.1:8000/revenue_per_country/ para confirmar que la nueva página se muestra correctamente.
¡Enhorabuena! Has utilizado Apache Spark correctamente para procesar tus datos, los has almacenado en MongoDB y has mostrado los datos procesados en una página web utilizando Django.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Nic Raboy
Tutorial
Natassha Selvaraj
Tutorial
Olivia Smith
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan

