Curso
Fundamentos de PySpark
4 h
157.5K
Apache Spark es un sistema de procesamiento distribuido que se utiliza para realizar tareas de big data y machine learning en grandes conjuntos de datos.
Como entusiasta de la ciencia de datos, probablemente estés familiarizado con el almacenamiento de archivos en tu dispositivo local y su procesamiento mediante lenguajes como R y Python. Sin embargo, las estaciones de trabajo locales tienen sus limitaciones y no pueden manejar conjuntos de datos extremadamente grandes.
Aquí es donde entra en juego un sistema de procesamiento distribuido como Apache Spark. El procesamiento distribuido es una configuración en la que se utilizan varios procesadores para ejecutar una aplicación. En lugar de intentar procesar grandes conjuntos de datos en un solo ordenador, la tarea puede dividirse entre varios dispositivos que se comunican entre sí.
Con Apache Spark, los usuarios pueden ejecutar consultas y flujos de trabajo de machine learning en petabytes de datos, algo imposible de hacer en tu dispositivo local.
Este marco es incluso más rápido que motores de procesamiento de datos anteriores como Hadoop, y su popularidad ha aumentado en los últimos ocho años. Empresas como IBM, Amazon y Yahoo utilizan Apache Spark como marco computacional.
La capacidad de analizar datos y entrenar modelos de machine learning con conjuntos de datos a gran escala es una habilidad valiosa si quieres convertirte en científico de datos. Tener los conocimientos necesarios para trabajar con marcos de big data como Apache Spark te diferenciará de los demás en este campo.
Practica el uso de Pyspark con ejercicios prácticos en nuestro curso Introducción a PySpark.
PySpark es una interfaz para Apache Spark en Python. Con PySpark, puedes escribir comandos tipo Python y SQL para manipular y analizar datos en un entorno de procesamiento distribuido. Para aprender los fundamentos del lenguaje, puedes hacer el curso Introducción a PySpark de DataCamp. Este es un programa para principiantes que te llevará a través de la manipulación de datos, la creación de pipelines de machine learning y el ajuste de modelos con PySpark.
La mayoría de los científicos y analistas de datos están familiarizados con Python y lo utilizan para implementar flujos de trabajo de machine learning. PySpark les permite trabajar con un lenguaje familiar en conjuntos de datos distribuidos a gran escala.
Apache Spark también se puede utilizar con otros lenguajes de programación de ciencia de datos como R. Si te interesa aprender esto, el curso Introducción a Spark con sparklyr en R es un buen punto de partida.
Las empresas que recopilan terabytes de datos dispondrán de un marco de big data como Apache Spark. Para trabajar con estos conjuntos de datos a gran escala, no basta con conocer los marcos Python y R.
Debes aprender un marco que te permita manipular conjuntos de datos sobre un sistema de procesamiento distribuido, ya que la mayoría de las organizaciones basadas en datos te lo exigirán. PySpark es un buen lugar para empezar, ya que su sintaxis es sencilla y se puede aprender fácilmente si ya estás familiarizado con Python.
La razón por la que las empresas deciden utilizar un marco como PySpark es la rapidez con la que puede procesar el big data. Es más rápido que bibliotecas como Pandas y Dask, y puede manejar mayores cantidades de datos que estos marcos. Si tuvieras que procesar cifras de datos por encima de los petabytes, por ejemplo, Pandas y Dask fallarían, pero PySpark podría manejarlo sin problemas.
Aunque también es posible escribir código Python sobre un sistema distribuido como Hadoop, muchas organizaciones optan por usar Spark y utilizan la API PySpark, ya que es más rápida y puede manejar datos en tiempo real. Con PySpark, puedes escribir código para recopilar datos de una fuente que se actualiza continuamente, mientras que los datos solo pueden procesarse en modo lote con Hadoop.
Apache Flink es un sistema de procesamiento distribuido que tiene una API Python llamada PyFlink y es realmente más rápido que Spark en cuanto a rendimiento. Sin embargo, Apache Spark existe desde hace más tiempo y cuenta con un mejor apoyo de la comunidad, lo que significa que es más fiable.
Además, PySpark proporciona tolerancia a fallos, lo que significa que tiene capacidad para recuperar pérdidas después de que se produzca un fallo. El marco también tiene computación en memoria y se almacena en memoria de acceso aleatorio (RAM). Puede ejecutarse en un equipo que no tenga instalado un disco duro o SSD.
Requisitos previos:
Antes de instalar Apache Spark y PySpark, debes tener configurado el siguiente software en tu dispositivo:
Si aún no tienes instalado Python, sigue nuestra guía de configuración para desarrolladores de Python para configurarlo antes de pasar al siguiente paso.
A continuación, sigue este tutorial para instalar Java en tu ordenador si utilizas Windows. Aquí hay una guía de instalación para MacOs, y aquí hay una para Linux.
Jupyter Notebook es una aplicación web que puedes utilizar para escribir código y mostrar ecuaciones, visualizaciones y texto. Es uno de los editores de programación más utilizados por los científicos de datos. Utilizaremos Jupyter Notebook para escribir todo el código PySpark en este tutorial, así que asegúrate de tenerlo instalado.
Puedes seguir nuestro tutorial para poner en marcha Jupyter en tu dispositivo local.
Utilizaremos el conjunto de datos de comercio electrónico de DataCamp para todos los análisis de este tutorial, así que asegúrate de tenerlo descargado. Hemos cambiado el nombre del archivo por "datacamp_ecommerce.csv" y lo hemos guardado en el directorio principal, y tú puedes hacer lo mismo para que te resulte más fácil programar.
Ahora que ya tienes configurados todos los requisitos previos, puedes proceder a instalar Apache Spark y PySpark.
Para configurar Apache Spark, ve a la página de descargas y descarga el archivo .tgz que aparece en la página:
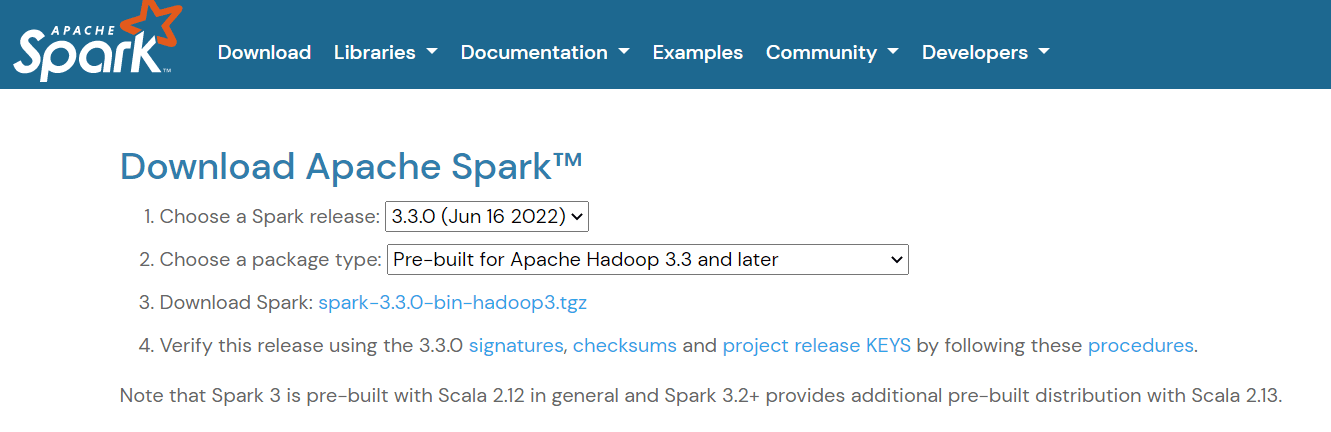
A continuación, si utilizas Windows, crea una carpeta en tu directorio C llamada "spark". Si utilizas Linux o Mac, puedes pegar esto en una nueva carpeta de tu carpeta de usuario.
A continuación, extrae el archivo que acabas de descargar y pega su contenido en esta carpeta "spark". Este es el aspecto que debe tener la ruta de la carpeta:

Ahora, tienes que configurar tus variables de entorno. Hay dos formas de hacerlo:
Método 1: Cambiar las variables de entorno con Powershell
Si utilizas un equipo Windows, la primera forma de cambiar tus variables de entorno es utilizando Powershell:
Paso 1: Haz clic en Start -> Windows Powershell -> Run as administrator
Paso 2: Escribe la siguiente línea en Windows Powershell para establecer SPARK_HOME:
setx SPARK_HOME "C:\spark\spark-3.3.0-bin-hadoop3" # change this to your pathPaso 3: A continuación, establece tu directorio de ejecutables Spark como variable de ruta:
setx PATH "C:\spark\spark-3.3.0-bin-hadoop3\bin"Método 2: Cambiar manualmente las variables de entorno
Paso 1: Ve a Start -> System -> Settings -> Advanced Settings
Paso 2: Haz clic en Environment Variables
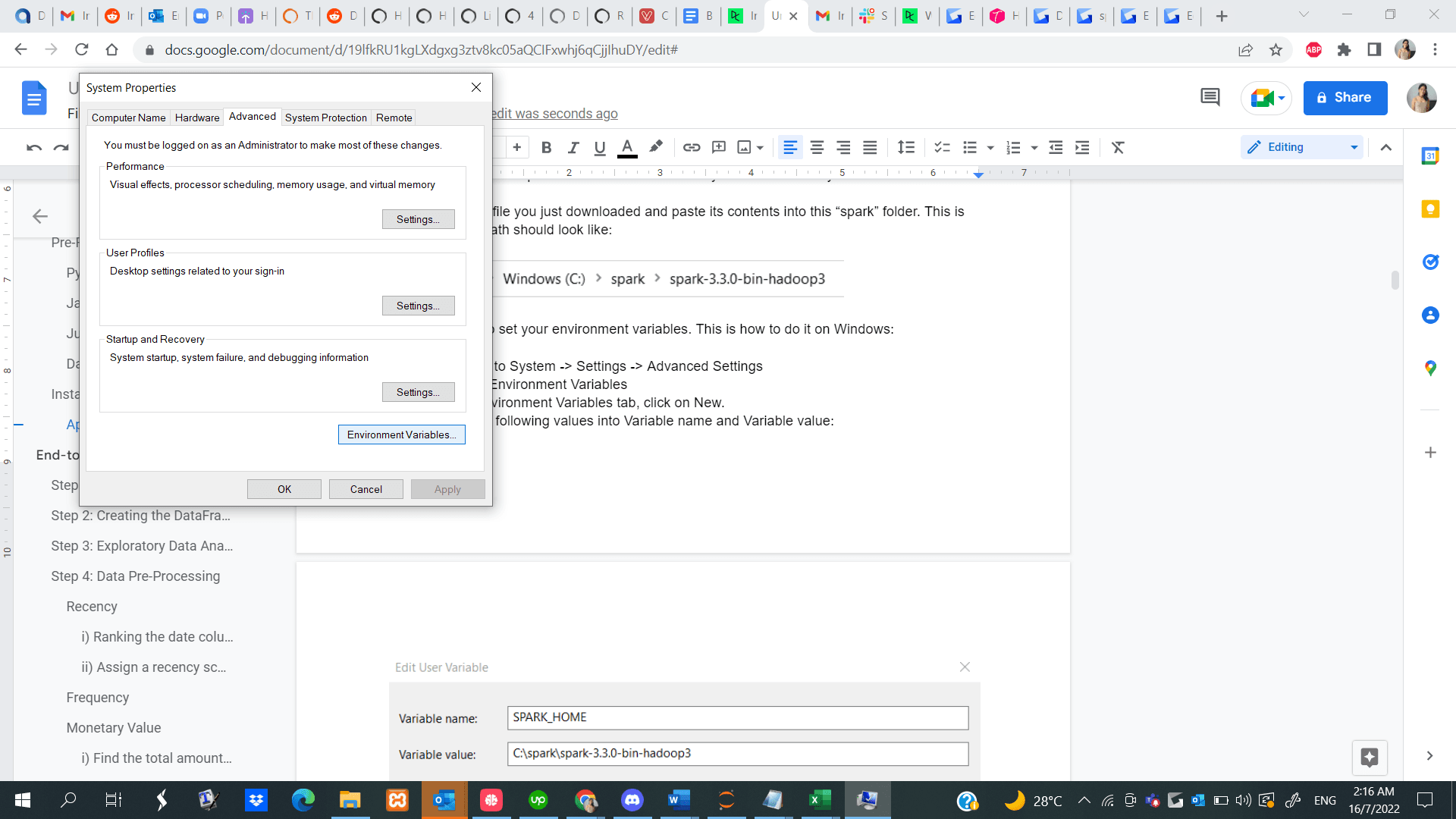
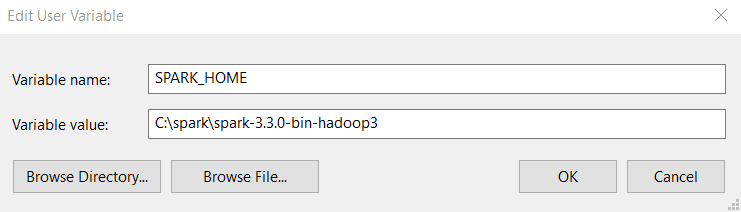
Paso 3: En la pestaña Environment Variables, haz clic en New.
Paso 4: Introduce los siguientes valores en Variable name y Variable value. Ten en cuenta que la versión que instales puede ser diferente de la que se muestra a continuación, así que copia la ruta y pégala en tu directorio Spark.
Paso 5: A continuación, en la pestaña Environment Variables, haz clic en Path y selecciona Edit.
Paso 6: Haz clic en New y pega la ruta a tu directorio de ejecutables Spark. Aquí tienes un ejemplo del aspecto del directorio de ejecutables:
C:\spark\spark-3.3.0-bin-hadoop3\binAquí tienes una guía para configurar tus variables de entorno si utilizas un dispositivo Linux, y aquí tienes una para MacOS.
Ahora que has instalado correctamente Apache Spark y todos los demás requisitos previos necesarios, abre un archivo Python en tu Jupyter Notebook y ejecuta las siguientes líneas de código en la primera celda:
!pip install pysparkTambién puedes seguir esta completa guía de instalación de PySpark para instalar el software en tu dispositivo.
Ahora que ya tienes PySpark en funcionamiento, te mostraremos cómo ejecutar un proyecto de segmentación de clientes de principio a fin utilizando la biblioteca.
La segmentación de clientes es una técnica de marketing que utilizan las empresas para identificar y agrupar a los usuarios que presentan características similares. Por ejemplo, si visitas Starbucks solo en verano para comprar bebidas frías, se te puede segmentar como "comprador de temporada" y pueden seducirte con promociones especiales diseñadas para la época estival.
Los científicos de datos suelen crear algoritmos de machine learning no supervisado como K-medias o agrupamiento jerárquico para realizar la segmentación de clientes. Estos modelos son excelentes para identificar patrones similares entre grupos de usuarios que a menudo pasan desapercibidos al ojo humano.
En este tutorial, utilizaremos K-medias para realizar la segmentación de clientes en el conjunto de datos de comercio electrónico que descargamos anteriormente.
Al final de este tutorial, estarás familiarizado con los siguientes conceptos:
Una SparkSession es un punto de entrada a toda la funcionalidad de Spark, y es necesaria si quieres crear un marco de datos en PySpark. Ejecuta las siguientes líneas de código para inicializar una SparkSession:
spark = SparkSession.builder.appName("Datacamp Pyspark Tutorial").config("spark.memory.offHeap.enabled","true").config("spark.memory.offHeap.size","10g").getOrCreate()Utilizando los códigos anteriores, creamos una spark session y establecemos un nombre para la aplicación. A continuación, los datos se almacenaban en caché en la memoria off-heap para evitar almacenarlos directamente en el disco, y se especificaba manualmente la cantidad de memoria.
Ahora podemos leer el conjunto de datos que acabamos de descargar:
df = spark.read.csv('datacamp_ecommerce.csv',header=True,escape="\"")Ten en cuenta que hemos definido un carácter de escape para evitar comas en el archivo .csv al analizarlo.
Echemos un vistazo a la cabecera del dataframe utilizando la función show():
df.show(5,0)
El dataframe consta de 8 variables:
Ahora que hemos visto las variables presentes en este conjunto de datos, vamos a realizar algunos análisis exploratorios de datos para comprender mejor estos puntos de datos:
df.count() # Answer: 2,500df.select('CustomerID').distinct().count() # Answer: 95Para buscar el país desde el que se realizan la mayoría de las compras, tenemos que utilizar la cláusula groupBy() de PySpark:
from pyspark.sql.functions import *
from pyspark.sql.types import *
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).show()Tras ejecutar los códigos anteriores, aparecerá la siguiente tabla:

Casi todas las compras de la plataforma se hicieron desde el Reino Unido, y solo unas pocas se hicieron desde países como Alemania, Australia y Francia.
Observa que los datos de la tabla anterior no se presentan por orden de compra. Para ordenar esta tabla, podemos incluir la cláusula orderBy():
df.groupBy('Country').agg(countDistinct('CustomerID').alias('country_count')).orderBy(desc('country_count')).show()La salida mostrada se ordena ahora en orden descendente:

Para averiguar cuándo se realizó la última compra en la plataforma, tenemos que convertir la columna "InvoiceDate" a un formato de marca de tiempo y utilizar la función max() de Pyspark:
spark.sql("set spark.sql.legacy.timeParserPolicy=LEGACY")
df = df.withColumn('date',to_timestamp("InvoiceDate", 'yy/MM/dd HH:mm'))
df.select(max("date")).show()Deberías ver la siguiente tabla después de ejecutar el código anterior:
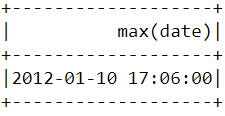
De forma similar a lo que hicimos antes, se puede utilizar la función min() para buscar la fecha y hora de compra más tempranas:
df.select(min("date")).show()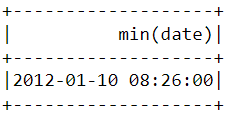
Observa que las compras más recientes y las más tempranas se hicieron el mismo día, con solo unas horas de diferencia. Esto significa que el conjunto de datos que descargamos solo contiene información de las compras realizadas en un solo día.
Ahora que hemos analizado el conjunto de datos y tenemos una mejor comprensión de cada punto de datos, tenemos que preparar los datos para introducirlos en el algoritmo de machine learning.
Echemos un vistazo a la cabecera del dataframe una vez más para entender cómo se realizará el preprocesamiento:
df.show(5,0)
A partir del conjunto de datos anterior, tenemos que crear varios segmentos de clientes en función del comportamiento de compra de cada usuario.
Las variables de este conjunto de datos están en un formato que no se puede ingerir fácilmente en el modelo de segmentación de clientes. Estas características por separado no nos dicen mucho sobre el comportamiento de compra del cliente.
Por ello, utilizaremos las variables existentes para derivar tres nuevas características informativas: reciente, frecuencia y valor monetario (RFM).
El RFM se utiliza habitualmente en marketing para evaluar el valor de un cliente en función de su:
Ahora preprocesaremos el dataframe para crear las variables anteriores.
En primer lugar, calculemos el valor de reciente: la última fecha y hora en que se realizó una compra en la plataforma. Esto puede conseguirse en dos pasos:
Restaremos todas las fechas del dataframe a la fecha más antigua. Esto nos dirá lo recientemente que se ha visto a un cliente en el dataframe. Un valor 0 indica lo menos reciente, ya que se asignará a la persona que hizo una compra en la fecha más temprana.
df = df.withColumn("from_date", lit("12/1/10 08:26"))
df = df.withColumn('from_date',to_timestamp("from_date", 'yy/MM/dd HH:mm'))
df2=df.withColumn('from_date',to_timestamp(col('from_date'))).withColumn('recency',col("date").cast("long") - col('from_date').cast("long"))Un cliente puede hacer varias compras en distintos momentos. Tenemos que seleccionar solo la última vez que compró un producto, ya que esto es indicativo de cuándo se hizo la compra más reciente:
df2 = df2.join(df2.groupBy('CustomerID').agg(max('recency').alias('recency')),on='recency',how='leftsemi')Veamos la cabecera del nuevo dataframe. Ahora tiene añadida una variable llamada "recency":
df2.show(5,0)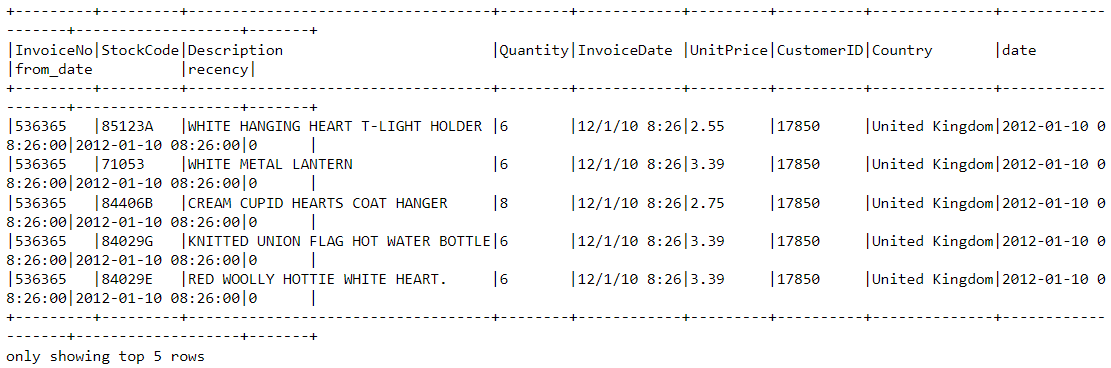
Una forma más sencilla de ver todas las variables presentes en un dataframe PySpark es utilizar su función printSchema(). Es el equivalente de la función info() en Pandas:
df2.printSchema()El resultado obtenido debería tener este aspecto:

Calculemos ahora el valor de la frecuencia: la frecuencia con la que un cliente compró algo en la plataforma. Para ello, solo tenemos que agrupar por cada ID de cliente y contar el número de artículos que ha comprado:
df_freq = df2.groupBy('CustomerID').agg(count('InvoiceDate').alias('frequency'))Mira la cabecera de este nuevo dataframe que acabamos de crear:
df_freq.show(5,0)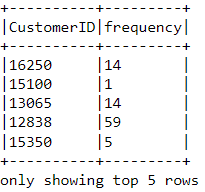
A cada cliente del dataframe se le añade un valor de frecuencia. Este nuevo dataframe solo tiene dos columnas, y tenemos que unirlo con el anterior:
df3 = df2.join(df_freq,on='CustomerID',how='inner')Vamos a imprimir el esquema de este dataframe:
df3.printSchema()
Por último, calculemos el valor monetario: el importe total gastado por cada cliente en el dataframe. Hay dos pasos para conseguirlo:
Cada ID de cliente tiene variables llamadas "Quantity" y "UnitPrice" para una sola compra:

Para obtener el importe total gastado por cada cliente en una compra, tenemos que multiplicar "Quantity" por "UnitPrice":
m_val = df3.withColumn('TotalAmount',col("Quantity") * col("UnitPrice"))Para hallar el importe total gastado por cada cliente en conjunto, solo tenemos que agrupar por la columna CustomerID y sumar el importe total gastado:
m_val = m_val.groupBy('CustomerID').agg(sum('TotalAmount').alias('monetary_value'))Fusiona este dataframe con el resto de variables:
finaldf = m_val.join(df3,on='CustomerID',how='inner')Ahora que hemos creado todas las variables necesarias para crear el modelo, ejecuta las siguientes líneas de código para seleccionar solo las columnas necesarias y eliminar las filas duplicadas del dataframe:
finaldf = finaldf.select(['recency','frequency','monetary_value','CustomerID']).distinct()Mira la cabecera del dataframe final para asegurarte de que el preprocesamiento se haya realizado correctamente:

Antes de crear el modelo de segmentación de clientes, estandaricemos el dataframe para asegurarnos de que todas las variables estén en torno a la misma escala:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.feature import StandardScaler
assemble=VectorAssembler(inputCols=[
'recency','frequency','monetary_value'
], outputCol='features')
assembled_data=assemble.transform(finaldf)
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)Ejecuta las siguientes líneas de código para ver qué aspecto tiene el vector de características estandarizado:
data_scale_output.select('standardized').show(2,truncate=False)
Estas son las características escaladas que se introducirán en el algoritmo de clustering.
Si quieres aprender más sobre la preparación de datos con PySpark, haz este curso de ingeniería de características en DataCamp.
Ahora que hemos completado todo el análisis y la preparación de los datos, vamos a construir el modelo K-medias.
El algoritmo se creará utilizando la API de machine learning de PySpark.
Al crear un modelo K-medias, primero tenemos que determinar el número de clústeres o grupos que queremos que devuelva el algoritmo. Si nos decidimos por tres grupos, por ejemplo, tendremos tres segmentos de clientes.
La técnica más utilizada para decidir cuántos clústeres utilizar en K-medias se denomina "método del codo".
Esto se hace simplemente ejecutando el algoritmo K-medias para una amplia gama de clústeres y visualizando los resultados del modelo para cada clúster. El gráfico tendrá un punto de inflexión parecido a un codo, y solo tenemos que elegir el número de clústeres de este punto.
Lee este tutorial de K-medias de DataCamp para saber más sobre el funcionamiento del algoritmo.
Vamos a ejecutar las siguientes líneas de código para crear un algoritmo de K-medias de 2 a 10 clústeres:
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
import numpy as np
cost = np.zeros(10)
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized',metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
cost[i] = KMeans_fit.summary.trainingCostCon los códigos anteriores, hemos creado y evaluado correctamente un modelo K-medias con 2-10 clústeres. Los resultados se han colocado en una matriz, y ahora se pueden visualizar en un gráfico de líneas:
import pandas as pd
import pylab as pl
df_cost = pd.DataFrame(cost[2:])
df_cost.columns = ["cost"]
new_col = range(2,10)
df_cost.insert(0, 'cluster', new_col)
pl.plot(df_cost.cluster, df_cost.cost)
pl.xlabel('Number of Clusters')
pl.ylabel('Score')
pl.title('Elbow Curve')
pl.show()Los códigos anteriores mostrarán el siguiente gráfico:
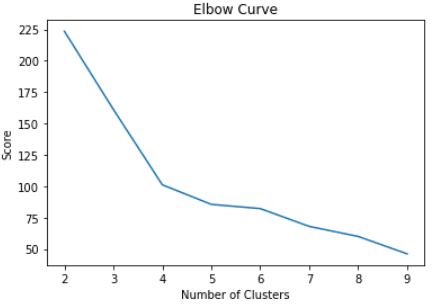
En el gráfico anterior, podemos ver que hay un punto de inflexión que parece un codo en el cuatro. Por ello, procederemos a crear el algoritmo K-medias con cuatro clústeres:
KMeans_algo=KMeans(featuresCol='standardized', k=4)
KMeans_fit=KMeans_algo.fit(data_scale_output)Utilicemos el modelo que hemos creado para asignar clústeres a cada cliente del conjunto de datos:
preds=KMeans_fit.transform(data_scale_output)
preds.show(5,0)Observa que en este dataframe tenemos la columna "prediction", que nos dice a qué clúster pertenece cada CustomerID:

El último paso de todo este tutorial es analizar los segmentos de clientes que acabamos de crear.
Ejecuta las siguientes líneas de código para visualizar Reciente, Frecuencia y Valor monetario en cada customerID en el dataframe:
import matplotlib.pyplot as plt
import seaborn as sns
df_viz = preds.select('recency','frequency','monetary_value','prediction')
df_viz = df_viz.toPandas()
avg_df = df_viz.groupby(['prediction'], as_index=False).mean()
list1 = ['recency','frequency','monetary_value']
for i in list1:
sns.barplot(x='prediction',y=str(i),data=avg_df)
plt.show()Los códigos anteriores mostrarán los siguientes gráficos:
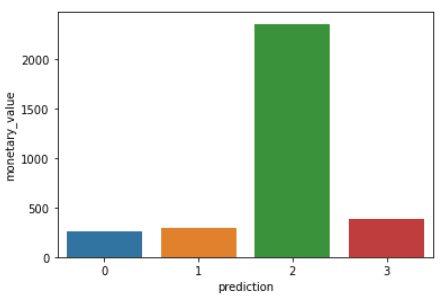
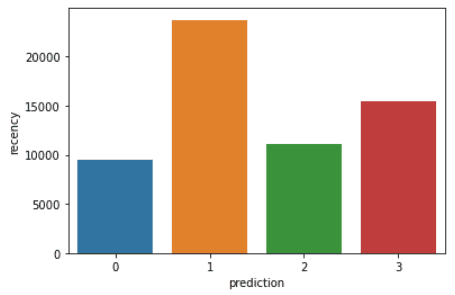
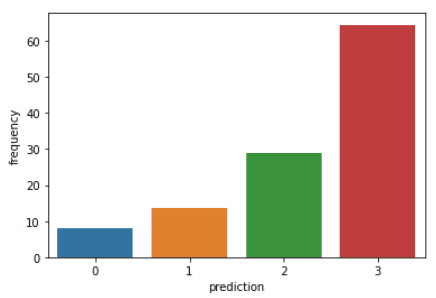
Aquí tienes un resumen de las características que muestran los clientes de cada clúster:
Para ir más allá de los conceptos de modelado predictivo cubiertos en este curso, puedes realizar el curso Machine Learning con PySpark en DataCamp.
Si has conseguido seguir todo este tutorial de PySpark, ¡enhorabuena! Ya has instalado correctamente PySpark en tu dispositivo local, has analizado un conjunto de datos de comercio electrónico y has creado un algoritmo de machine learning utilizando el marco.
Una advertencia sobre el análisis anterior es que se realizó con 2500 filas de datos de comercio electrónico recogidos en un solo día. El resultado de este análisis puede solidificarse si tenemos una mayor cantidad de datos con los que trabajar, ya que técnicas como el modelado RFM suelen aplicarse sobre meses de datos históricos.
Sin embargo, puedes tomar los principios aprendidos en este artículo y aplicarlos a una amplia variedad de conjuntos de datos mayores en el espacio del machine learning no supervisado.
Consulta esta hoja de trucos de DataCamp para saber más sobre la sintaxis de PySpark y sus módulos.
Por último, si quieres ir más allá de los conceptos tratados en este tutorial y aprender los fundamentos de la programación con PySpark, puedes seguir el programa de aprendizaje Big data con PySpark en DataCamp. Este programa contiene una serie de cursos que te enseñarán a hacer lo siguiente con PySpark:
Cursos de visualización de datos
Curso
Curso
Curso
Tutorial
Olivia Smith
Tutorial
Vidhi Chugh
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Javier Canales Luna
