
Cours
Introduction à PySpark
4 h
157.5K
Imaginez que vous soyez responsable d'une plateforme de commerce électronique qui traite des milliers de transactions quotidiennement. Vous souhaitez analyser les tendances des ventes, suivre la croissance du chiffre d'affaires et prévoir les revenus futurs. Les requêtes traditionnelles dans les bases de données ne peuvent pas gérer une telle échelle ou une telle vitesse. Vous avez donc besoin d'un moyen plus rapide pour traiter de grands ensembles de données et obtenir des informations en temps réel.
Apache Spark, l', vous permet d'analyser efficacement de très grands volumes de données. Dans ce tutoriel, je vais vous expliquer comment connecter Django, MongoDB et Apache Spark afin d'analyser les données de transactions e-commerce. afin d'analyser les données de transactions e-commerce.
Vous allez configurer un projet Django avec MongoDB comme base de données et y stocker les données transactionnelles. Ensuite, vous utiliserez PySpark, l'API Python pour Apache Spark, afin de lire et de filtrer les données. Vous effectuerez également des calculs de base et enregistrerez les données traitées dans MongoDB. Enfin, vous afficherez les données traitées dans votre application Django.
Pour tirer le meilleur parti de ce tutoriel, il est recommandé d'avoir une connaissance de base de Python et du framework web Django.
Maintenant, passons aux choses sérieuses.
Commencez par créer un environnement virtuel pour votre projet Django :
python -m venv venv
source venv/bin/activateVeuillez vous assurer que Python 3.10 ou une version ultérieure est installé dans votre environnement virtuel. Ensuite, veuillez installer le backend Django MongoDB:
pip install django-mongodb-backendLa commande précédente installe également les dernières versions de PyMongo 4.x et Django 5.2.x.
Une fois que vous avez téléchargé Django MongoDB Backend, veuillez créer un nouveau projet Django :
django-admin startproject pyspark_tutorialVeuillez maintenant accéder au dossier du projet et exécuter le serveur de développement afin de vérifier que votre projet est correctement configuré :
cd pyspark_tutorial
python manage.py runserverVeuillez consulter http://127.0.0.1:8000/ pour vérifier que votre projet Django fonctionne correctement.
Par défaut, Django utilise des identifiants entiers d'AutoField s pour les clés primaires, ce qui fonctionne efficacement avec les bases de données SQL. Cependant, MongoDB utilise l'ObjectId e pour les identifiants de documents. Pour que vos modèles soient compatibles, il est nécessaire que Django génère des clés primaires sous forme d' ObjectId s plutôt que d'entiers.
Veuillez ouvrir pyspark_tutorial/settings.py et mettez à jour le DEFAULT_AUTO_FIELD paramètres :
DEFAULT_AUTO_FIELD = 'django_mongodb_backend.fields.ObjectIdAutoField'Même avec ce paramètre global, les applications intégrées de Django telles que admin, auth et contenttypes continueront à utiliser par défaut AutoField. Afin de garantir la cohérence entre toutes les applications, veuillez créer des configurations d'application personnalisées pour qu'elles utilisent ObjectId.
Veuillez créer un fichier pyspark_tutorial/apps.py et ajoutez-y les éléments suivants :
from django.contrib.admin.apps import AdminConfig
from django.contrib.auth.apps import AuthConfig
from django.contrib.contenttypes.apps import ContentTypesConfig
class MongoAdminConfig(AdminConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoAuthConfig(AuthConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoContentTypesConfig(ContentTypesConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'Veuillez maintenant mettre à jour votre paramètreINSTALLED_APPS dans le fichier pyspark_tutorial/settings.py:
INSTALLED_APPS = [
'pyspark_tutorial.apps.MongoAdminConfig',
'pyspark_tutorial.apps.MongoAuthConfig',
'pyspark_tutorial.apps.MongoContentTypesConfig',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]Étant donné que tous les modèles doivent utiliser ObjectIdAutoField, chaque application tierce et contrib que vous utilisez doit disposer de ses propres migrations spécifiques à MongoDB. Veuillez ajouter les éléments suivants à votre fichier pyspark_tutorial/setting.py:
MIGRATION_MODULES = {
'admin': 'mongo_migrations.admin',
'auth': 'mongo_migrations.auth',
'contenttypes': 'mongo_migrations.contenttypes',
}Veuillez créer un dossier intitulé « mongo_migrations » dans le dossier de votre projet, au même niveau que votre fichier «manage.py ». À ce stade, votre structure de dossiers devrait ressembler à ceci :
pyspark_tutorial/
├── pyspark_tutorial/
├── mongo_migrations/
└── manage.pyVeuillez arrêter le serveur à l'aide de **Ctrl + C**, puis générez vos migrations :
python manage.py makemigrations admin auth contenttypesSi vous consultez votre dossier mongo_migrations, vous constaterez qu'il existe un dossier pour chaque application intégrée. Chaque dossier contient ses migrations.
Pour un modèle de projet Django disposant de toutes les configurations MongoDB précédentes, veuillez exécuter :
django-admin startproject pyspark_tutorial --template https://github.com/mongodb-labs/django-mongodb-project/archive/refs/heads/5.2.x.zipRemarque: Si vous utilisez une version de Django autre que 5.2.x, veuillez remplacer les deux chiffres par les deux premiers chiffres de votre version.
La prochaine étape consiste à créer une application Django pour stocker vos enregistrements de transactions bruts et traités.
python manage.py startapp salesPour configurer votre nouvelle application afin qu'elle utilise ObjectId, veuillez ouvrir sales/apps.py et remplacer la ligne default_auto_field = 'django.db.models.BigAutoField':
from django.apps import AppConfig
class SalesConfig(AppConfig):
# Use ObjectId as the default primary key field type for MongoDB:
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
name = 'sales'Vous pouvez également utiliser le modèle suivant startapp, qui inclut la modification précédente :
python manage.py startapp sales --template https://github.com/mongodb-labs/django-mongodb-app/archive/refs/heads/5.2.x.zipMaintenant, dans pyspark_tutorial/settings.py, veuillez ajouter votre application sales à la listeINSTALLED_APPS:
INSTALLED_APPS = [
# Add your sales app:
'sales.apps.SalesConfig',
...
]Étant donné que vous allez stocker vos données dans MongoDB, je vais vous expliquer comment créer un déploiement gratuit sur MongoDB Atlas afin de stocker et de gérer vos données dans le cloud.
Veuillez créer un compte Atlas en utilisant votre compte Google ou une adresse e-mail.
Veuillez cliquer sur Créer pour créer un cluster d' Free s :
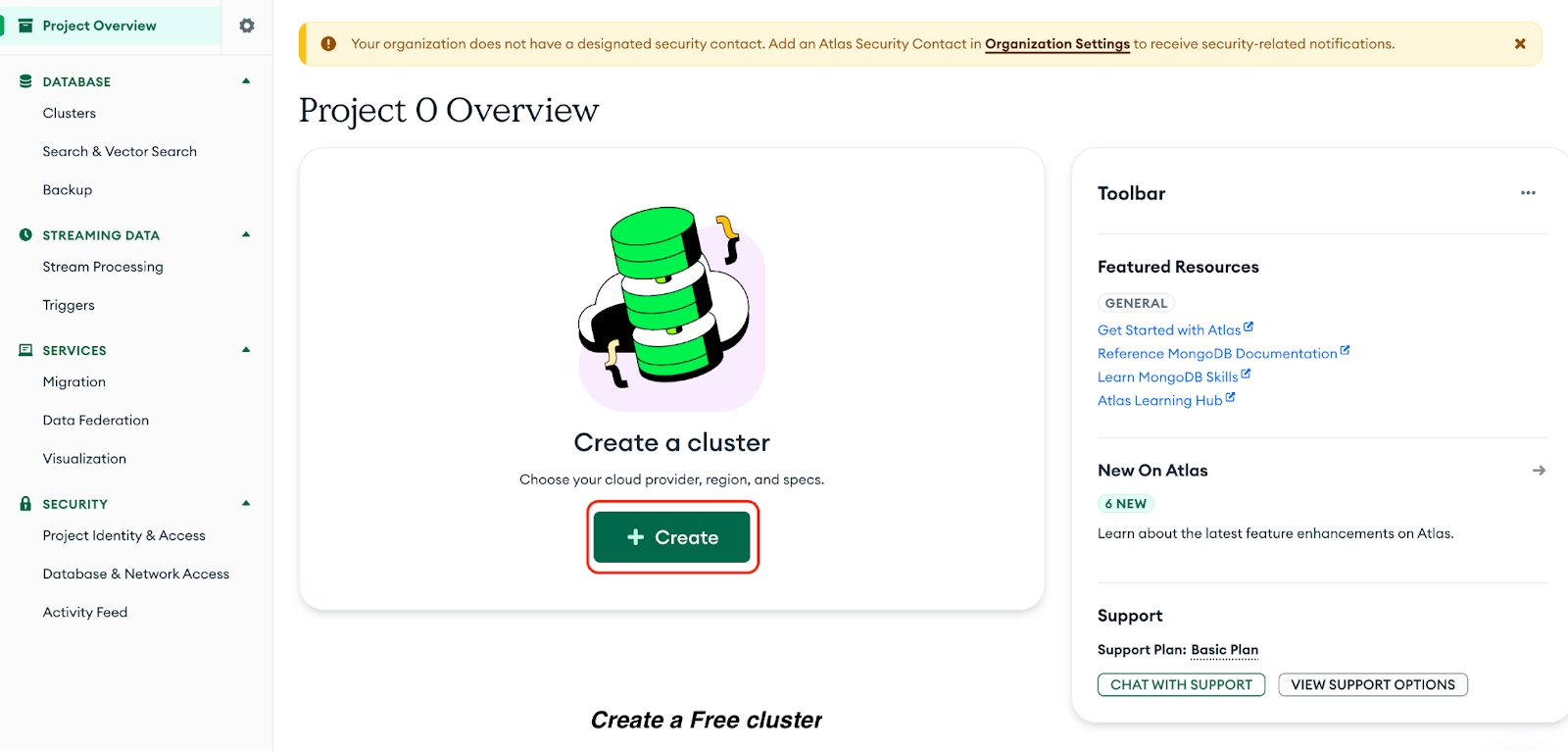
Veuillez maintenant sélectionner les options suivantes dans la page qui s'affiche :
Cliquez sur Créer un déploiement:
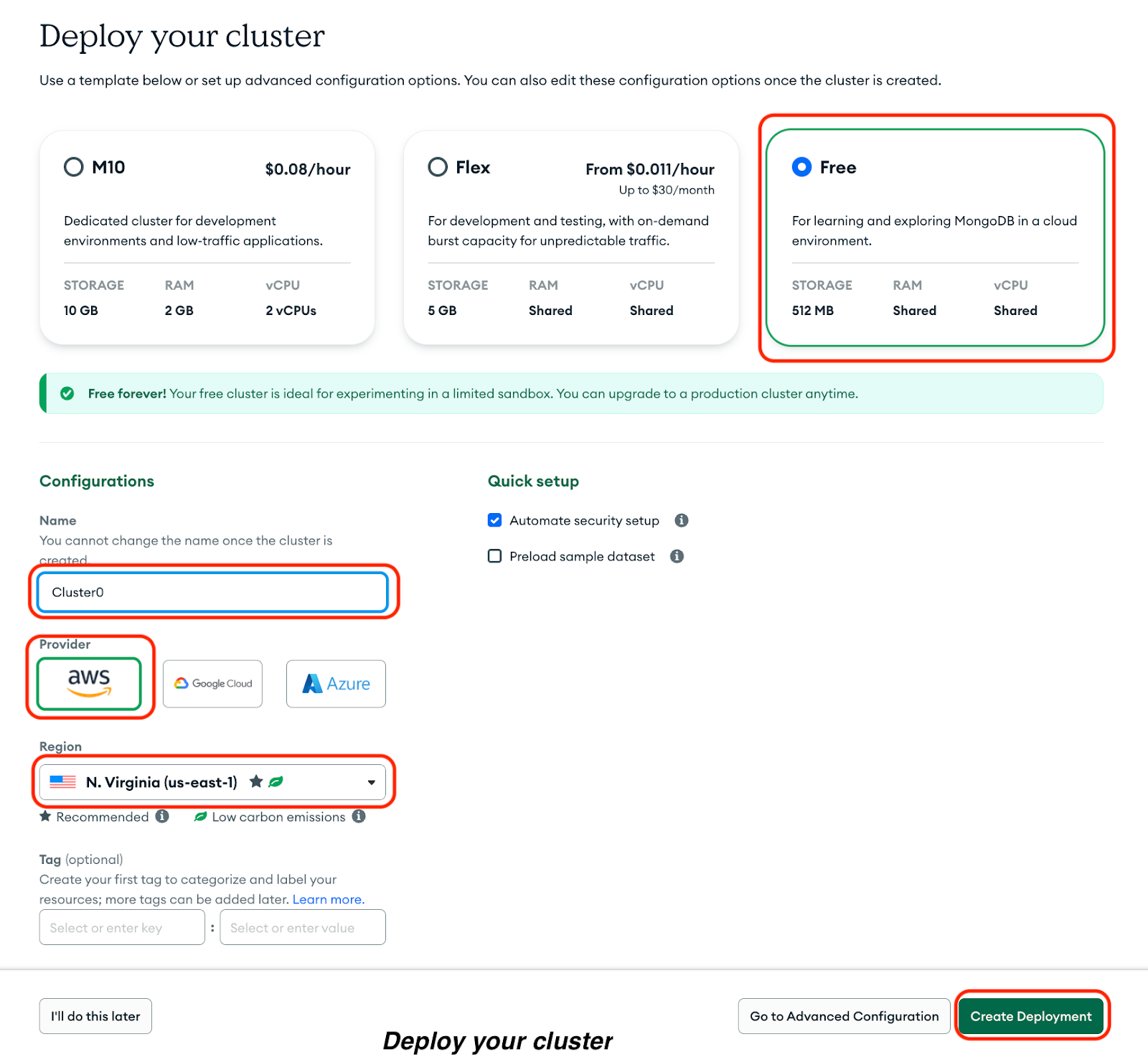
Vous verrez votre nom d'utilisateur et votre mot de passe. Veuillez procéder comme suit :
1. Veuillez copier votre nom d'utilisateur et votre mot de passe dans un document sécurisé.
2. Veuillez cliquer sur « » (Créer un utilisateur de base de données).
3. Veuillez cliquer sur . Sélectionnez une méthode de connexion pour définir une adresse IP de connexion.
Veuillez procéder comme suit sur la page qui s'affiche :
1. Veuillez sélectionnerles pilotes d' .

2. Veuillez sélectionnerPython d' comme pilote.
3. Veuillez copier la commande dans l'option «Install your driver » (Installer votre pilote) et l'exécuter dans votre terminal.
4. Veuillez copier votre clé d' connection string, y compris votre mot de passe, sous Ajouter votre chaîne de connexion dans le code de votre application, et la sauvegarder dans un document sécurisé.
5. Veuillez cliquer sur « » (Terminé).
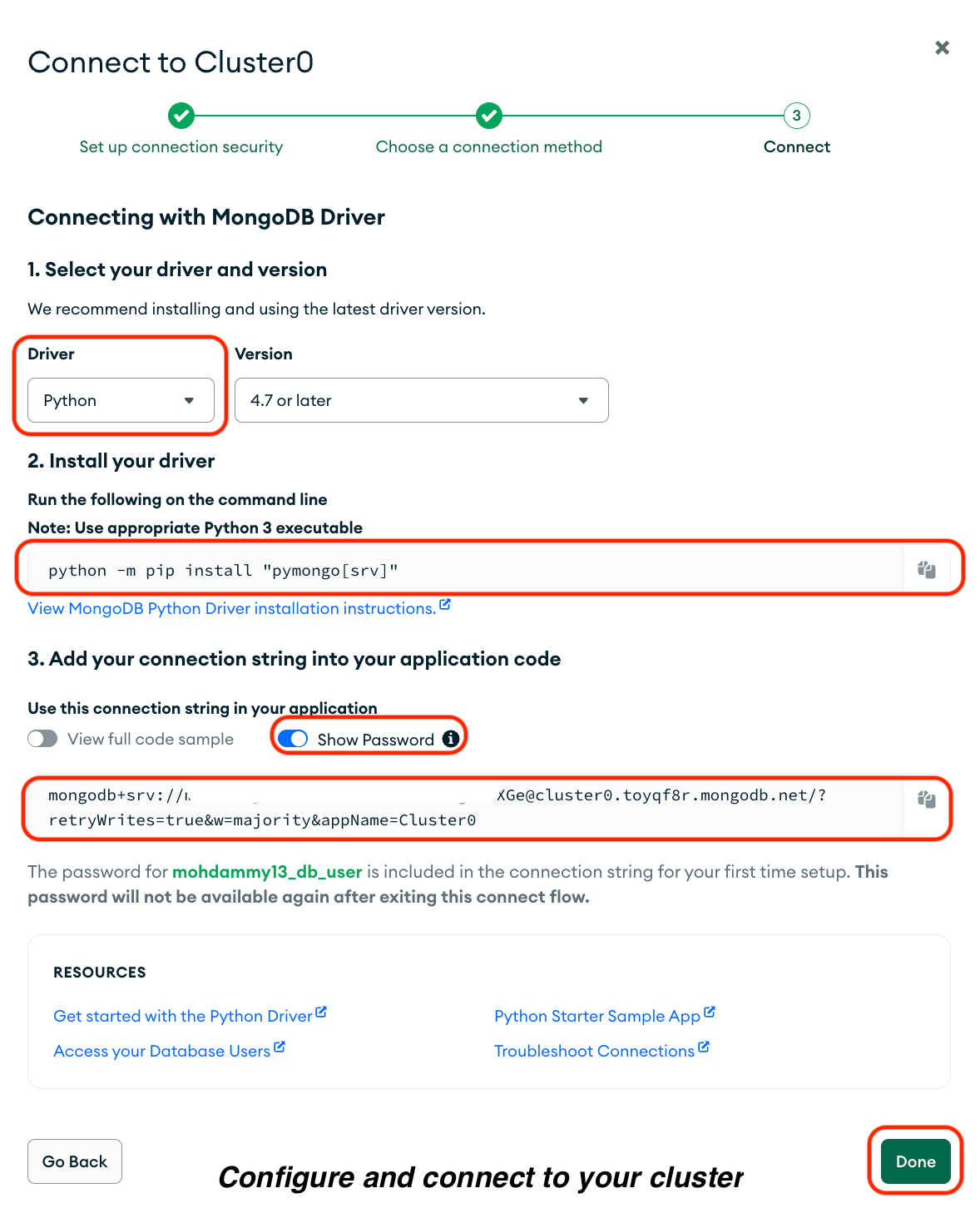
Veuillez ouvrir le fichier pyspark_tutorial/settings.py et mettre à jour le paramètre DATABASES afin d'utiliser le backend Django MongoDB avec votre base de données MongoDB enregistrée connection string. Veuillez également définir un nom de base de données :
DATABASES = {
'default': {
# Change to use Django MongoDB Backend:
'ENGINE': 'django_mongodb_backend',
# Use your saved connection string:
'HOST': '<connection string>',
# Set a database name:
'NAME': 'pyspark_tutorial',
},
}Dans le code ci-dessus, veuillez remplacer par votre chaîne de connexion enregistrée.
Cette configuration permet de connecter Django à votre cluster MongoDB Atlas. ENGINE pointe vers le backend MongoDB, HOST stocke votre chaîne de connexion et NAME définit le nom de la base de données que Django utilisera.
Maintenant que votre application est configurée, vous allez créer les modèles, les vues, les URL et les modèles nécessaires pour afficher les données de transaction dans votre navigateur.
Les modèles décrivent la structure de vos données. Veuillez créer un modèle pour représenter les enregistrements de transactions. Veuillez ouvrir le fichier sales/models.py et remplacer le code :
from django.db import models
# Define a model to represent each transaction record:
class Transaction(models.Model):
order_id = models.CharField(max_length=50, unique=True)
user_id = models.CharField(max_length=50)
product = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
quantity = models.PositiveIntegerField()
timestamp = models.DateTimeField()
country = models.CharField(max_length=50)
class Meta:
# Sort transactions by order ID:
ordering = ['order_id']
# Add indexes to improve query performance for common lookup fields
indexes = [
models.Index(fields=['timestamp']),
models.Index(fields=['country']),
models.Index(fields=['product']),
]
def __str__(self):
return f'{self.order_id} - {self.product}'
@property
def total_amount(self):
# Calculate and return the total transaction amount:
return self.price * self.quantityCe modèle définit chaque transaction à l'aide de champs pour les détails du produit, le prix, la quantité et le pays. Il classe les transactions par order_id. Il comprend également un index sur les champs clés afin d'améliorer les performances des requêtes, ainsi qu'une propriété qui calcule le montant total des transactions.
Les vues déterminent la manière dont ces enregistrements s'affichent dans le navigateur. Veuillez créer une vue pour afficher les enregistrements de transaction. Veuillez ouvrir le fichier sales/views.py et remplacer le code :
from django.shortcuts import render
from .models import Transaction
# Define a view to display all transactions and total revenue:
def transaction_list_view(request):
# Retrieve all transaction records from the database:
transactions = Transaction.objects.all()
# Calculate the total revenue from all transactions:
total_revenue = sum(t.total_amount for t in transactions)
# Render the transaction list template with context data
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})La vue précédente récupère tous les enregistrements de transaction depuis MongoDB à l'aide du modèle Transaction. Il calcule le revenu total en additionnant le champ « total_amount » (Montant de la transaction) pour chaque transaction. Ensuite, il transmet deux valeurs à un modèle d'transaction_list.html , que nous créerons ultérieurement :
* transactions: une liste de tous les enregistrements de transactions à afficher dans un tableau
* total_revenue: le montant total généré par l'ensemble des transactions
Le modèle utilisera ces valeurs pour afficher chaque transaction et le revenu total.
Il est nécessaire de créer des routes afin que Django sache quelle vue charger lorsque les utilisateurs visitent une URL. Veuillez créer un fichier sales/urls.py et y ajouter les éléments suivants :
from django.urls import path
from . import views
# Define URL patterns for the sales app:
urlpatterns = [
# Route the root URL to the transaction list view:
path('', views.transaction_list_view, name='transaction_list'),
]Veuillez inclure les URL de votre application dans la configuration des URL de votre projet. Veuillez ouvrir le fichier pyspark_tutorial/urls.py et le mettre à jour comme suit :
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# Include your app’s URLs:
path("", include('sales.urls')),
]Les modèles déterminent la manière dont vos données s'affichent dans le navigateur. Veuillez créer un dossier intitulé « sales/templates/sales » et y ajouter un fichier nommé «transaction_list.html ».
Votre sales application devrait avoir la structure suivante :
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
└── templates/
└── sales/
└── transaction_list.htmlVeuillez ajouter les éléments suivants à votre fichier transaction_list.html:
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
</head>
<body>
<h1>E-commerce Transactions</h1>
<h3>Total Revenue: ${{ total_revenue }}</h3>
<table>
<thead>
<tr>
<th>Order ID</th>
<th>User ID</th>
<th>Product</th>
<th>Price</th>
<th>Quantity</th>
<th>Country</th>
<th>Timestamp</th>
</tr>
</thead>
<tbody>
{% for t in transactions %}
<tr>
<td>{{ t.order_id }}</td>
<td>{{ t.user_id }}</td>
<td>{{ t.product }}</td>
<td>${{ t.price }}</td>
<td>{{ t.quantity }}</td>
<td>{{ t.country }}</td>
<td>{{ t.timestamp }}</td>
</tr>
{% empty %}
<tr><td colspan="7">No transactions available.</td></tr>
{% endfor %}
</tbody>
</table>
</body>
</html>Le modèle précédent utilise le langage de modélisation de Django pour afficher de manière dynamique les données transmises depuis la vue.
En haut, le revenu total est affiché à l'aide de {{ total_revenue }}. Ensuite, le modèle parcourt tous les enregistrements de transaction dans transactions à l'aide de la balise ` {% for t in transactions %} ` et affiche chaque enregistrement sous forme de ligne dans le tableau. Chaque colonne présente un attribut spécifique d'une transaction, tel que order_id, product, price, quantity et country. S'il n'y a pas d'enregistrements, la balise d' {% empty %} garantit qu'un message « Aucune transaction disponible » s'affiche à la place d'un tableau vide.
Afin de rendre votre page de transaction plus attrayante visuellement et plus facile à lire, vous ajouterez un style CSS personnalisé. Django fournit des fichiers statiques, tels que CSS, JavaScript et des images, via un répertoire spécial appelé static. Cela permet de séparer les fichiers de conception de votre code.
Veuillez maintenant créer un dossier intitulé «sales/static/sales » et y ajouter un fichier nommé « styles.css ». La structure de votre dossier sales devrait se présenter comme suit :
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
├── templates/
│ └── sales/
│ └── transaction_list.html
└── static/
└── sales/
└── styles.cssDans pyspark_tutorial/settings.py, veuillez vous assurer que STATIC_URL est défini :
STATIC_URL = 'static/'Veuillez ajouter ceci à votre fichier sales/static/sales/styles.css:
table {
width: 100%;
border-collapse: collapse;
margin-top: 20px;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f5f5f5;
}
body {
background-color:transparent;font-weight:400;font-style:normal;font-variant:normal;text-decoration:none;vertical-align:baseline;white-space:pre;white-space:pre-wrap;">: Arial, sans-serif;
margin: 20px;
}
h1 {
color: #333;
}
a {
text-decoration: none;
color: #007bff;
}
a:hover {
text-decoration: underline;
}Enfin, veuillez indiquer à Django de charger les fichiers statiques et d'inclure le fichier CSS dans votre modèle HTML.
En haut de sales/templates/sales/transaction_list.html , veuillez ajouter {% load static %}, puis mettez à jour l'élément pour qu'il pointe vers le fichierstyles.css:
<!-- Load static files:-->
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
<!-- Link the CSS file for styling the template:-->
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>Veuillez générer et appliquer vos migrations afin que Django puisse créer les collections nécessaires dans MongoDB :
python manage.py makemigrations
python manage.py migrateÀ présent, utilisons les modèles de votre application pour ajouter des enregistrements de transaction à votre base de données pyspark_tutorial à l'aide du shell interactif Django :
python manage.py shellEnsuite, importez le modèle Transaction depuis votre application de vente et timezone depuis les utilitaires Django :
from sales.models import Transaction
from django.utils import timezoneVeuillez maintenant insérer les enregistrements de transaction à l'aide de l' bulk_create():
Transaction.objects.bulk_create([
Transaction(order_id='T1001', user_id='U001', product='Laptop', price=1000.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1002', user_id='U002', product='Smartphone', price=800.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1003', user_id='U003', product='Headphones', price=150.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1004', user_id='U004', product='Laptop', price=1200.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1005', user_id='U005', product='Keyboard', price=45.00, quantity=3, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1006', user_id='U006', product='Monitor', price=300.00, quantity=2, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1007', user_id='U007', product='Smartwatch', price=199.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1008', user_id='U008', product='Speaker', price=150.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1009', user_id='U009', product='Camera', price=800.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1010', user_id='U010', product='Tablet', price=350.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1011', user_id='U011', product='Headphones', price=75.00, quantity=2, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1012', user_id='U012', product='Laptop', price=1300.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1013', user_id='U013', product='Mouse', price=30.00, quantity=3, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1014', user_id='U014', product='Smartphone', price=950.00, quantity=1, timestamp=timezone.now(), country='KE'),
Transaction(order_id='T1015', user_id='U015', product='Keyboard', price=55.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1016', user_id='U016', product='Smartwatch', price=250.00, quantity=1, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1017', user_id='U017', product='Speaker', price=180.00, quantity=1, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1018', user_id='U018', product='Monitor', price=400.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1019', user_id='U019', product='Laptop', price=1250.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1020', user_id='U020', product='Camera', price=780.00, quantity=1, timestamp=timezone.now(), country='US'),
])Veuillez vérifier que les enregistrements ont bien été ajoutés :
Transaction.objects.count()Si le compteur renvoie 20, vos enregistrements ont été sauvegardés avec succès.
Veuillez maintenant quitter le shell en exécutant « exit() » et démarrer votre serveur Django pour visualiser vos transactions dans le navigateur :
python manage.py runserverVeuillez consulter le site http://127.0.0.1:8000/ pour vérifier que vos données sont bien affichées.
Maintenant que vos enregistrements sont stockés dans votre base de données MongoDB, vous utiliserez Apache Spark pour traiter vos données. Apache Spark est fourni avec une API Python, PySpark, que vous pouvez utiliser dans votre projet Django pour traiter de grands ensembles de données.
Vous allez créer un script Python qui utilise PySpark pour se connecter à MongoDB et lire vos enregistrements de transactions. Vous effectuerez des opérations de base sur ces données, telles que le filtrage. Vous les regrouperez ensuite par pays et calculerez le chiffre d'affaires total pour chacun d'entre eux. Enfin, vous enregistrerez les données traitées dans une nouvelle collection MongoDB de votre base de données.
Veuillez arrêter votre serveur et installer la version PySpark qui est compatible avec la dernière version du connecteur MongoDB Spark:
pip install pyspark==3.5.0Vérifiez que l'installation s'est déroulée avec succès :
pyspark --versionVous devriez recevoir une réponse vous souhaitant la bienvenue chez Spark.
Ensuite, veuillez créer un fichier transactions.py dans le dossier de votre projet, au même niveau que manage.py. Votre structure de dossiers devrait maintenant ressembler à ceci :
pyspark_tutorial/
├── mongo_migrations/
├── pyspark_tutorial/
├── sales/
├── manage.py
└── transactions.pyPour connecter PySpark à MongoDB, il est nécessaire de créer une chaîne de connexion qui inclut le nom de votre base de données et le nom de la collection. Une collection dans MongoDB est similaire à une table dans les bases de données relationnelles et stocke des documents connexes. Le nom de votre collection est composé du nom de votre application et du nom du modèle, séparés par un trait de soulignement (_).
Veuillez utiliser la chaîne de connexion intégrée dans votre fichier transactions.py . Le format correct est le suivant :
mongodb+srv://<mongodb username>:<mongodb password>@<cluster address>/<database name>.<app name>_<model name>?retryWrites=true&w=majority&appName=Cluster0Voici l'explication des valeurs des espaces réservés :
cluster0.2rvn82q.mongodb.net.settings.py._ est le nom de la collection générée à partir de votre application et de votre modèle Django, par exemple sales_transaction.Dans cette section, la chaîne de connexion que vous utiliserez dans votre code PySpark ressemblera à ceci :
mongodb+srv://db_user:password@cluster.mongodb.net/pyspark_tutorial.sales_transaction?retryWrites=true&w=majority&appName=Cluster0Veuillez ajouter le code suivant à votre fichier transactions.py:
from pyspark.sql import SparkSession
# Initialize SparkSession with MongoDB connector:
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
# Add the MongoDB Spark connector package:
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
# Read data from MongoDB into a Spark DataFrame:
df = spark.read.format('mongodb').load()
# Show result:
df.show()
# Stop the Spark session:
spark.stop()from pyspark.sql import SparkSession est le point d'entrée pour l'utilisation de PySpark. Il vous permet d'interagir avec Spark et d'effectuer des opérations sur les données.
spark = SparkSession.builder initialise une nouvelle session Spark et lui attribue le nom ReadTransactions. Les deux options d' .config() s définissent la manière dont Spark doit se connecter à MongoDB :
spark.mongodb.read.connection.urila chaîne de connexion MongoDB qui indique à Spark où se trouve votre base de données.spark.jars.packagestélécharge le package du connecteur MongoDB Spark afin que Spark puisse communiquer avec MongoDB.df = spark.read.format('mongodb').load() charge tous les documents de la collection définie dans votre chaîne de connexion dans un DataFrame PySpark, ce qui facilite la consultation et la transformation de vos données..show() affiche un aperçu de vos données MongoDB sous forme de tableau directement dans le terminal.spark.stop() ferme l'application Spark et libère les ressources système une fois la tâche terminée.Enfin, veuillez remplacer par votre chaîne de connexion MongoDB personnalisée. Veuillez également vous assurer que votre adresse IP actuelle figure sur la liste blanche de votre [liste d'accès au réseau MongoDB Atlas](https://cloud.mongodb.com/) avant de vous connecter.
Maintenant, exécutez python transactions.py, et vous obtiendrez les enregistrements de transactions stockés dans votre base de données dans votre terminal.
Vous pouvez également filtrer vos enregistrements à l'aide des fonctions SQL PySpark, par exemple pour n'afficher que les transactions provenant du Nigeria (NG). Veuillez modifier le code dans votre fichier transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame column names:
from pyspark.sql.functions import col
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Filter transactions from Nigeria:
ng_df = df.filter(col('country') == 'NG')
# Show filtered results:
ng_df.show()
# Stop the Spark session:
spark.stop() Veuillez relancer python transactions.py et vous observerez les transactions provenant de NG.
Vous pouvez également regrouper vos enregistrements de transactions par pays et calculer le revenu total pour chacun d'entre eux. Veuillez modifier le code dans votre fichier transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame columns and import sum as _sum to avoid naming conflicts:
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country:
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Show total revenue per country:
revenue_per_country.show()
# Stop the Spark session:
spark.stop()Veuillez exécuter python transactions.py. Vous observerez un tableau présentant le revenu total par pays.
Maintenant que vous comprenez comment utiliser PySpark pour lire et traiter vos données, je vais vous montrer comment enregistrer les données traitées dans une collection MongoDB.
Ici, vous allez créer le DataFrame contenant le revenu total par pays dans une nouvelle collection.
Veuillez modifier le code dans votre fichier transactions.py :
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Write aggregated records into a new MongoDB collection:
revenue_per_country.write \
.format('mongodb') \
.mode('overwrite') \
.option(
'spark.mongodb.write.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.option(
# Specify the target database name:
'spark.mongodb.write.database',
'pyspark_tutorial'
) \
.option(
# Specify the target collection name:
'spark.mongodb.write.collection',
'revenue_per_country'
) \
.save()
# Stop the Spark session:
spark.stop()Dans le code précédent, Spark enregistre le DataFrame agrégé, revenue_per_country, dans une nouvelle collection nommée revenue_per_country dans votre base de donnéespyspark_tutorial sur MongoDB.
Enfin, veuillez vous assurer de remplacer '' dans les deux configurations de connexion par votre chaîne de connexion MongoDB construite. Veuillez ensuite exécuter python transactions.py.
Maintenant, affichons votre chiffre d'affaires total par pays sur une page Django.
Tout d'abord, nous allons créer un nouveau modèle pour le chiffre d'affaires par pays. Veuillez ajouter ceci à la fin de votre fichier sales/models.py:
class RevenuePerCountry(models.Model):
country = models.CharField(max_length=50)
total_revenue = models.DecimalField(max_digits=15, decimal_places=2)
class Meta:
# Define the collection (table) name in MongoDB:
db_table = 'revenue_per_country'
# Order results by total_revenue when querying:
ordering = ['total_revenue']
def __str__(self):
# Return a readable string representation of the record:
return f'{self.country}: ${self.total_revenue}'Ensuite, veuillez modifier votre fichier sales/views.py afin de récupérer et d'afficher la collectionrevenue_per_country:
from django.shortcuts import render
from .models import Transaction
# Import the RevenuePerCountry model:
from .models import RevenuePerCountry
def transaction_list_view(request):
transactions = Transaction.objects.all()
total_revenue = sum(t.total_amount for t in transactions)
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})
# Add a new view to fetch and display your revenue per country:
def revenue_per_country_view(request):
revenue_per_country = RevenuePerCountry.objects.all()
return render(request, 'sales/revenue_per_country.html', {'revenue_per_country': revenue_per_country})Veuillez inclure un itinéraire vers la nouvelle vue dans sales/urls.py:
from django.urls import path
from . import views
urlpatterns = [
path('', views.transaction_list_view, name='transaction_list'),
# Add new URL route:
path('revenue_per_country/', views.revenue_per_country_view, name='revenue_per_country'),
]Ensuite, veuillez créer un nouveau modèle pour afficher le chiffre d'affaires total par pays.
Dans le dossier sales/templates/sales, veuillez créer un fichierrevenue_per_country.html et y ajouter les éléments suivants :
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transactions</title>
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>
<body>
<h1>Total Revenue by Country</h1>
<a href="{% url 'transaction_list' %}">← Back to Transactions</a>
<table>
<tr>
<th>Country</th>
<th>Total Revenue (USD)</th>
</tr>
{% for r in revenue_per_country %}
<tr>
<td>{{ r.country }}</td>
<td>${{ r.total_revenue|floatformat:2 }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>Il est également nécessaire de modifier le modèle sales/templates/sales/transaction_list.html afin d'y inclure un lien vers la page des revenus par pays. Veuillez ajouter le code suivant après
:<a href="{% url 'revenue_per_country' %}">View Total Revenue by Country</a>
Veuillez lancer le serveur Django :
python manage.py runserver
Veuillez consulter http://127.0.0.1:8000/revenue_per_country/ pour vérifier que la nouvelle page s'affiche correctement.
Félicitations. Vous avez utilisé Apache Spark avec succès pour traiter vos données, les avez stockées dans MongoDB et avez affiché les données traitées sur une page Web à l'aide de Django.
Meilleurs cours DataCamp
Cours
Cours
Cours