
Curso
Fundamentos do PySpark
4 h
157.5K
Imagina que você gerencia uma plataforma de comércio eletrônico que processa milhares de transações por dia. Você quer analisar as tendências de vendas, acompanhar o crescimento da receita e prever a renda futura. As consultas tradicionais a bancos de dados não conseguem lidar com essa escala ou velocidade. Então você precisa de uma maneira mais rápida de processar grandes conjuntos de dados e obter insights em tempo real.
O Apache Spark lpermite que você analise grandes volumes de dados de forma eficiente. Neste tutorial, vou mostrar como conectar o Django, o MongoDB e o Apache Spark para analisar dados de transações de comércio eletrônico.
Você vai configurar um projeto Django com o MongoDB como banco de dados e guardar os dados das transações nele. Depois, você vai usar o PySpark, a API Python para o Apache Spark, para ler e filtrar os dados. Você também vai fazer cálculos básicos e salvar os dados processados no MongoDB. Por fim, você vai mostrar os dados processados no seu aplicativo Django.
Pra aproveitar ao máximo esse tutorial, é bom você ter um conhecimento básico de Python e da estrutura web Django.
Agora, vamos começar.
Comece criando um ambiente virtual para o seu projeto Django:
python -m venv venv
source venv/bin/activateCertifique-se de que você tem o Python 3.10 ou mais recente instalado no seu ambiente virtual. Depois, instale o Django MongoDB Backend:
pip install django-mongodb-backendO comando anterior também instala as versões mais recentes do PyMongo 4.x e doDjango 5.2.x.
Depois de baixar o Django MongoDB Backend, crie um novo projeto Django:
django-admin startproject pyspark_tutorialAgora, vá até a pasta do projeto e execute o servidor de desenvolvimento para ver se o seu projeto está configurado corretamente:
cd pyspark_tutorial
python manage.py runserverAcesse http://127.0.0.1:8000/ para ver se o seu projeto Django está funcionando direitinho.
Por padrão, o Django usa IDs inteiros d AutoField o como chaves primárias, o que funciona bem com bancos de dados SQL. Mas, o MongoDB usa o algoritmo de hash SHA-1 ( ObjectId ) para os IDs dos documentos. Para deixar seus modelos compatíveis, você precisa que o Django gere chaves primárias como ObjectId em vez de inteiros.
Abrir pyspark_tutorial/settings.py e atualize a DEFAULT_AUTO_FIELD configuração:
DEFAULT_AUTO_FIELD = 'django_mongodb_backend.fields.ObjectIdAutoField'Mesmo com essa configuração global, os aplicativos integrados do Django, como admin, auth e contenttypes, ainda usarão AutoField como padrão . Para garantir a consistência em todos os aplicativos, crie configurações personalizadas para que eles usem ObjectId.
Crie um arquivo pyspark_tutorial/apps.py arquivo e adicione o seguinte:
from django.contrib.admin.apps import AdminConfig
from django.contrib.auth.apps import AuthConfig
from django.contrib.contenttypes.apps import ContentTypesConfig
class MongoAdminConfig(AdminConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoAuthConfig(AuthConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoContentTypesConfig(ContentTypesConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'Agora, em pyspark_tutorial/settings.py, atualize sua configuraçãoINSTALLED_APPS:
INSTALLED_APPS = [
'pyspark_tutorial.apps.MongoAdminConfig',
'pyspark_tutorial.apps.MongoAuthConfig',
'pyspark_tutorial.apps.MongoContentTypesConfig',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]Como todos os modelos precisam usar ObjectIdAutoField, cada aplicativo de terceiros e contrib que você usa precisa ter suas próprias migrações específicas para o MongoDB. Então, adicione o seguinte ao seu arquivo pyspark_tutorial/setting.py:
MIGRATION_MODULES = {
'admin': 'mongo_migrations.admin',
'auth': 'mongo_migrations.auth',
'contenttypes': 'mongo_migrations.contenttypes',
}Crie uma pasta chamada “ mongo_migrations ” na pasta do seu projeto, no mesmo nível do arquivo “ manage.py ”. A estrutura da sua pasta nesta fase deve ficar assim:
pyspark_tutorial/
├── pyspark_tutorial/
├── mongo_migrations/
└── manage.pyPare o servidor com **Ctrl + C** e, em seguida, gere suas migrações:
python manage.py makemigrations admin auth contenttypesSe você der uma olhada na pasta “ mongo_migrations ”, vai ver uma pasta para cada aplicativo integrado. Cada pasta tem suas migrações.
Para um modelo de projeto Django que tenha todas as configurações anteriores do MongoDB, execute:
django-admin startproject pyspark_tutorial --template https://github.com/mongodb-labs/django-mongodb-project/archive/refs/heads/5.2.x.zipObservação: Se você estiver usando uma versão do Django diferente da 5.2.x, troque os dois números para combinar com os dois primeiros números da sua versão.
O próximo passo é criar um aplicativo Django para guardar seus registros de transações brutos e processados.
python manage.py startapp salesPara configurar seu novo aplicativo para usar ObjectId, abra sales/apps.py e troque a linha default_auto_field = 'django.db.models.BigAutoField':
from django.apps import AppConfig
class SalesConfig(AppConfig):
# Use ObjectId as the default primary key field type for MongoDB:
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
name = 'sales'Como alternativa, você pode usar o seguinte modelo startapp, que inclui a alteração anterior:
python manage.py startapp sales --template https://github.com/mongodb-labs/django-mongodb-app/archive/refs/heads/5.2.x.zipAgora, em pyspark_tutorial/settings.py, adicione seu aplicativo sales à listaINSTALLED_APPS:
INSTALLED_APPS = [
# Add your sales app:
'sales.apps.SalesConfig',
...
]Como você vai guardar seus dados no MongoDB, vou te mostrar como criar uma implantação gratuita no MongoDB Atlas pra guardar e gerenciar seus dados na nuvem.
Cadastre-se para uma conta Atlas usando sua conta Google ou um endereço de e-mail.
Clique em Criar para criar um cluster do Free:
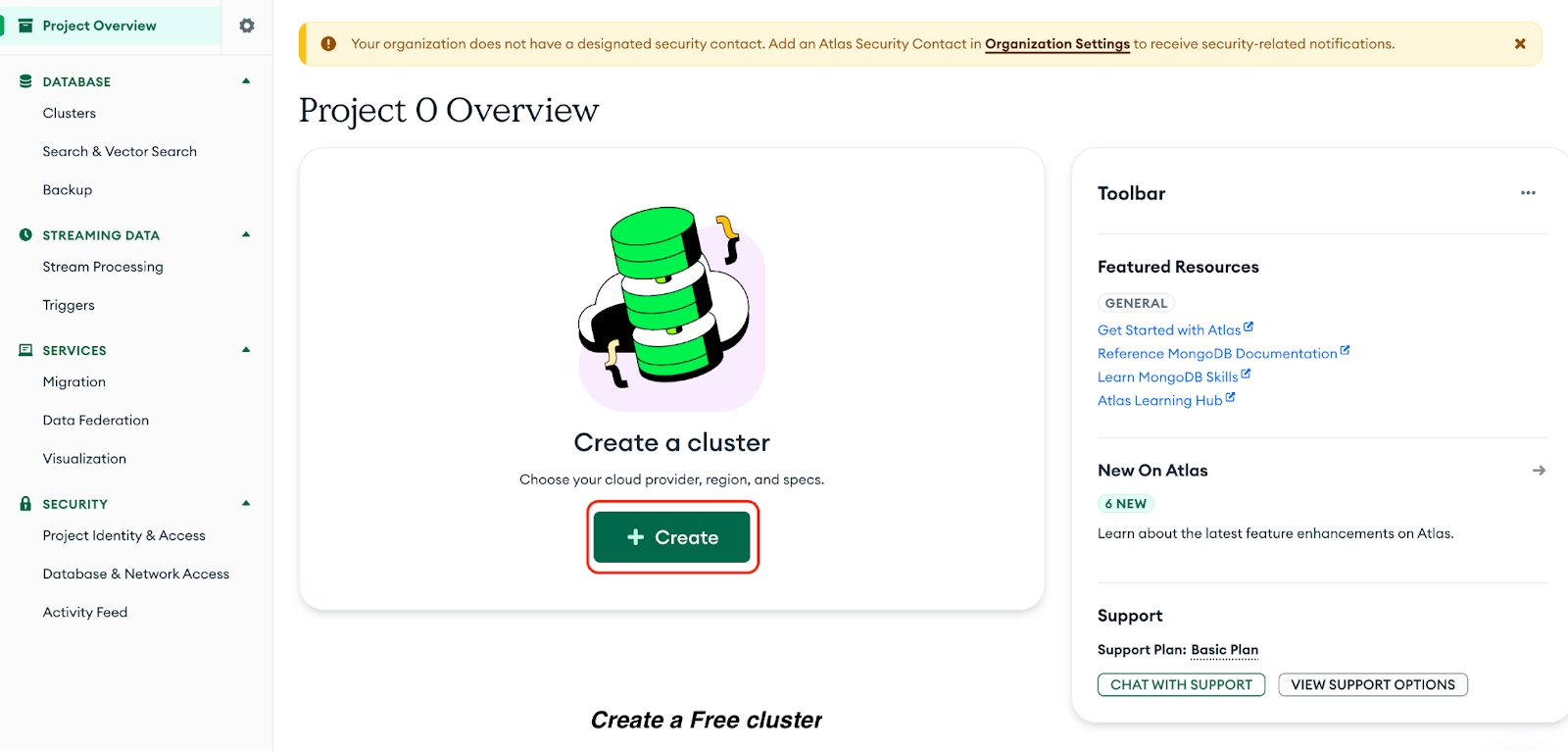
Agora, selecione as seguintes opções na página resultante:
Clique em Criar implantação:
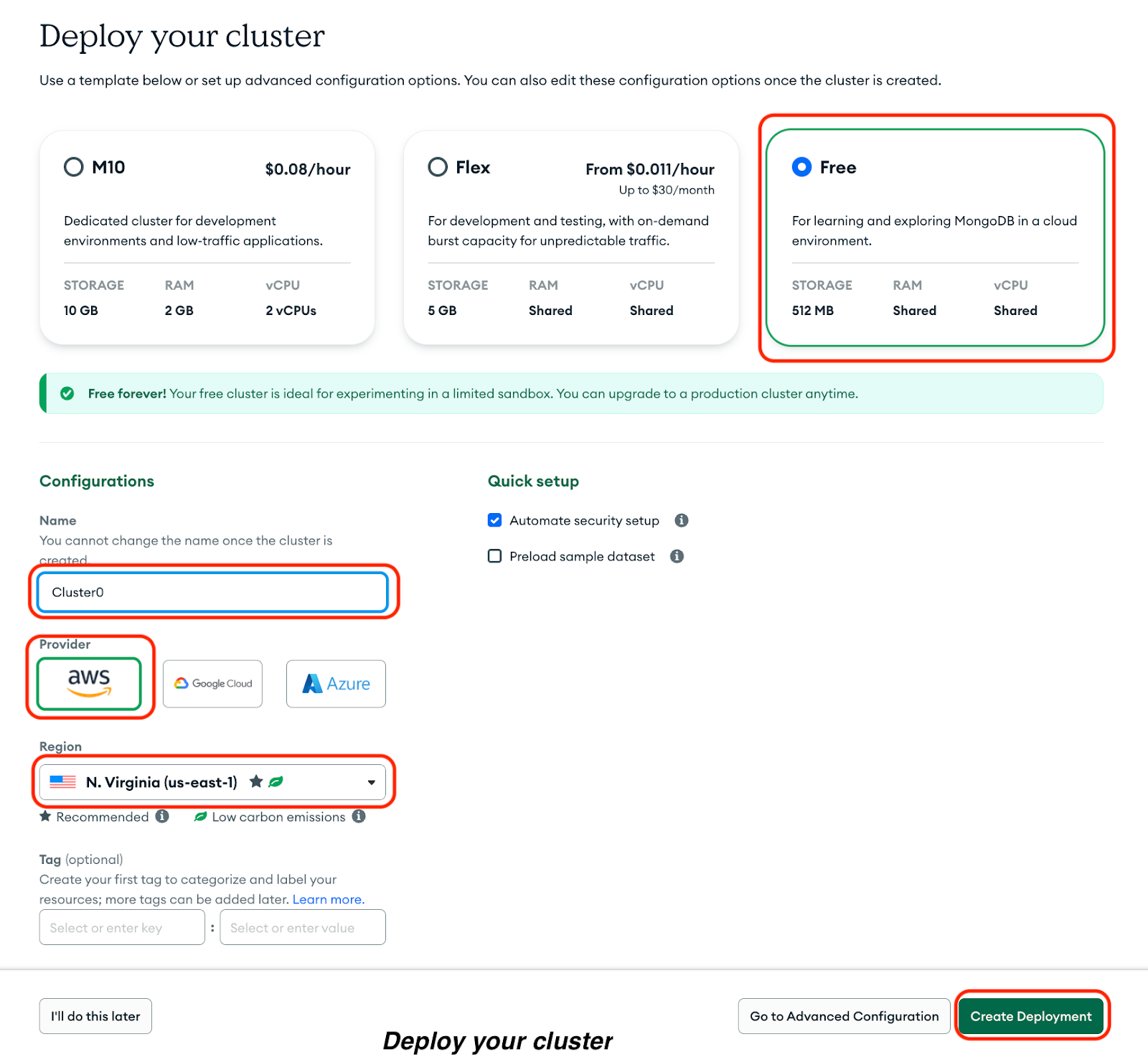
Você vai ver seu nome de usuário e senha. Faça o seguinte:
1. Copia seu nome de usuário e senha em um documento seguro.
2. Clique em“ ” (Criar usuário do banco de dados).
3. Clique em“ ” (Conexão de rede) Escolha um método de conexão para definir um endereço IP de conexão.
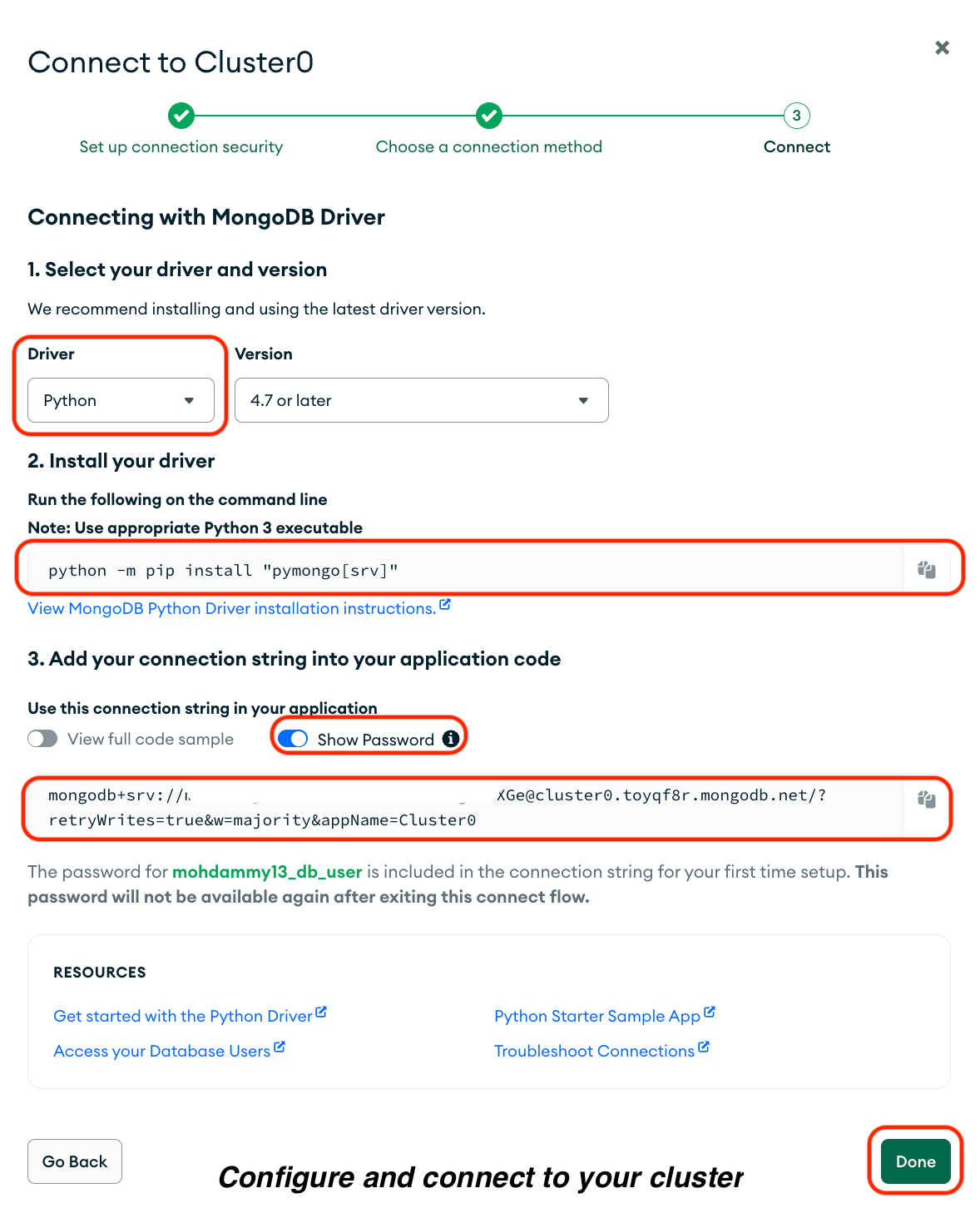
Faça o seguinte na página que aparecer:
1. Selecioneos drivers .

2. Escolhao Python como seu driver.
3. Copie o comando na opção“Instalar seu driver” e execute-o no seu terminal.
4. Copie sua connection string, incluindo sua senha, em Adicione sua string de conexão ao código do aplicativo e salve-a em um documento seguro.
5. Clique em“ ” (Concluir). Pronto.
Abra pyspark_tutorial/settings.py e atualize a configuração DATABASES para usar o Django MongoDB Backend com seu connection string salvo . Defina também um nome para o banco de dados:
DATABASES = {
'default': {
# Change to use Django MongoDB Backend:
'ENGINE': 'django_mongodb_backend',
# Use your saved connection string:
'HOST': '<connection string>',
# Set a database name:
'NAME': 'pyspark_tutorial',
},
}No código anterior, certifique-se de substituir pela sua string de conexão salva.
Essa configuração conecta o Django ao seu cluster MongoDB Atlas. O arquivo ` ENGINE ` aponta para o backend MongoDB, `HOST ` guarda sua string de conexão e `NAME ` define o nome do banco de dados que o Django vai usar.
Agora que seu aplicativo está configurado, você vai criar os modelos, visualizações, URLs e modelos necessários para mostrar os dados da transação no seu navegador.
Os modelos mostram como seus dados estão organizados. Crie um modelo para representar registros de transações. Abra sales/models.py e troque o código:
from django.db import models
# Define a model to represent each transaction record:
class Transaction(models.Model):
order_id = models.CharField(max_length=50, unique=True)
user_id = models.CharField(max_length=50)
product = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
quantity = models.PositiveIntegerField()
timestamp = models.DateTimeField()
country = models.CharField(max_length=50)
class Meta:
# Sort transactions by order ID:
ordering = ['order_id']
# Add indexes to improve query performance for common lookup fields
indexes = [
models.Index(fields=['timestamp']),
models.Index(fields=['country']),
models.Index(fields=['product']),
]
def __str__(self):
return f'{self.order_id} - {self.product}'
@property
def total_amount(self):
# Calculate and return the total transaction amount:
return self.price * self.quantityEsse modelo define cada transação com campos para detalhes do produto, preço, quantidade e país. Ele organiza as transações por order_id. Também inclui um índice nos campos principais para melhorar o desempenho das consultas e uma propriedade que calcula o valor total da transação.
As visualizações controlam como esses registros aparecem no navegador. Crie uma visualização para mostrar os registros das transações. Abra sales/views.py e troque o código:
from django.shortcuts import render
from .models import Transaction
# Define a view to display all transactions and total revenue:
def transaction_list_view(request):
# Retrieve all transaction records from the database:
transactions = Transaction.objects.all()
# Calculate the total revenue from all transactions:
total_revenue = sum(t.total_amount for t in transactions)
# Render the transaction list template with context data
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})A visualização anterior busca todos os registros de transações do MongoDB usando o modelo ` Transaction `. Ele calcula a receita total somando o campo “ total_amount ” (Receita total) de cada transação. Depois, ele manda dois valores para um modelo transaction_list.html , que vamos criar mais tarde:
* transactions: uma lista de todos os registros de transações para mostrar numa tabela
* total_revenue: o valor total gerado por todas as transações
O modelo vai usar esses valores para mostrar cada transação e a receita total.
Você precisa criar rotas para que o Django saiba qual visualização carregar quando os usuários acessarem uma URL. Crie um arquivo chamado ` sales/urls.py ` e adicione o seguinte:
from django.urls import path
from . import views
# Define URL patterns for the sales app:
urlpatterns = [
# Route the root URL to the transaction list view:
path('', views.transaction_list_view, name='transaction_list'),
]Inclua as URLs do seu aplicativo na configuração de URL do seu projeto. Abra o arquivo ` pyspark_tutorial/urls.py ` e atualize-o assim:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# Include your app’s URLs:
path("", include('sales.urls')),
]Os modelos definem como seus dados aparecem no navegador. Crie uma pasta chamada “ sales/templates/sales ” e coloque um arquivo chamado “transaction_list.html ” dentro dela.
A estrutura do seu aplicativo sales A estrutura do seu aplicativo deve ficar assim:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
└── templates/
└── sales/
└── transaction_list.htmlAdicione o seguinte ao seu arquivo transaction_list.html:
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
</head>
<body>
<h1>E-commerce Transactions</h1>
<h3>Total Revenue: ${{ total_revenue }}</h3>
<table>
<thead>
<tr>
<th>Order ID</th>
<th>User ID</th>
<th>Product</th>
<th>Price</th>
<th>Quantity</th>
<th>Country</th>
<th>Timestamp</th>
</tr>
</thead>
<tbody>
{% for t in transactions %}
<tr>
<td>{{ t.order_id }}</td>
<td>{{ t.user_id }}</td>
<td>{{ t.product }}</td>
<td>${{ t.price }}</td>
<td>{{ t.quantity }}</td>
<td>{{ t.country }}</td>
<td>{{ t.timestamp }}</td>
</tr>
{% empty %}
<tr><td colspan="7">No transactions available.</td></tr>
{% endfor %}
</tbody>
</table>
</body>
</html>O modelo anterior usa a linguagem de modelagem do Django para mostrar dinamicamente os dados passados da visualização.
No topo, a receita total é mostrada usando {{ total_revenue }}. Então, o modelo percorre todos os registros de transações usando a tag ` {% for t in transactions %} ` e mostra cada registro como uma linha na tabela. Cada coluna mostra um atributo específico de uma transação, como order_id, product, price, quantity e country. Se não tiver registros, a tag ` {% empty %} ` faz com que apareça a mensagem “Nenhuma transação disponível” em vez de uma tabela vazia.
Para deixar sua página de transações mais bonita e fácil de ler, você vai adicionar um estilo CSS personalizado. O Django serve arquivos estáticos, como CSS, JavaScript e imagens, por meio de um diretório especial chamado static. Isso mantém os arquivos de design separados do seu código.
Agora, crie uma pasta chamada “ sales/static/sales ” e coloque um arquivo chamado “ styles.css ” dentro dela. A estrutura da sua pasta sales deve ficar assim:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
├── templates/
│ └── sales/
│ └── transaction_list.html
└── static/
└── sales/
└── styles.cssEm pyspark_tutorial/settings.py, certifique-se de que STATIC_URL esteja definido:
STATIC_URL = 'static/'Adicione isso ao seu arquivo sales/static/sales/styles.css:
table {
width: 100%;
border-collapse: collapse;
margin-top: 20px;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f5f5f5;
}
body {
background-color:transparent;font-weight:400;font-style:normal;font-variant:normal;text-decoration:none;vertical-align:baseline;white-space:pre;white-space:pre-wrap;">: Arial, sans-serif;
margin: 20px;
}
h1 {
color: #333;
}
a {
text-decoration: none;
color: #007bff;
}
a:hover {
text-decoration: underline;
}Por fim, diga ao Django para carregar os arquivos estáticos e incluir o arquivo CSS no seu modelo HTML.
No topo de sales/templates/sales/transaction_list.html, adicione {% load static %} e, em seguida, atualize o elemento para vincular ao arquivostyles.css:
<!-- Load static files:-->
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
<!-- Link the CSS file for styling the template:-->
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>Gere e aplique suas migrações para que o Django possa criar as coleções necessárias no MongoDB:
python manage.py makemigrations
python manage.py migrateAgora, vamos usar os modelos do seu aplicativo para adicionar registros de transações ao seu banco de dados pyspark_tutorial usando o shell interativo do Django:
python manage.py shellDepois, importa o modelo Transaction do teu aplicativo de vendas e otimezone dos utilitários do Django:
from sales.models import Transaction
from django.utils import timezoneAgora, insira os registros de transação usando o comando ` bulk_create()`:
Transaction.objects.bulk_create([
Transaction(order_id='T1001', user_id='U001', product='Laptop', price=1000.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1002', user_id='U002', product='Smartphone', price=800.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1003', user_id='U003', product='Headphones', price=150.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1004', user_id='U004', product='Laptop', price=1200.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1005', user_id='U005', product='Keyboard', price=45.00, quantity=3, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1006', user_id='U006', product='Monitor', price=300.00, quantity=2, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1007', user_id='U007', product='Smartwatch', price=199.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1008', user_id='U008', product='Speaker', price=150.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1009', user_id='U009', product='Camera', price=800.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1010', user_id='U010', product='Tablet', price=350.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1011', user_id='U011', product='Headphones', price=75.00, quantity=2, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1012', user_id='U012', product='Laptop', price=1300.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1013', user_id='U013', product='Mouse', price=30.00, quantity=3, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1014', user_id='U014', product='Smartphone', price=950.00, quantity=1, timestamp=timezone.now(), country='KE'),
Transaction(order_id='T1015', user_id='U015', product='Keyboard', price=55.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1016', user_id='U016', product='Smartwatch', price=250.00, quantity=1, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1017', user_id='U017', product='Speaker', price=180.00, quantity=1, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1018', user_id='U018', product='Monitor', price=400.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1019', user_id='U019', product='Laptop', price=1250.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1020', user_id='U020', product='Camera', price=780.00, quantity=1, timestamp=timezone.now(), country='US'),
])Confira se os registros foram adicionados com sucesso:
Transaction.objects.count()Se a contagem retornar 20, seus registros foram salvos com sucesso.
Agora, saia do shell executando` exit()` e inicie seu servidor Django para visualizar suas transações no navegador:
python manage.py runserverVisite http://127.0.0.1:8000/ para ver se seus dados estão aparecendo.
Agora que seus registros estão guardados no banco de dados MongoDB, você vai usar o Apache Spark pra processar seus dados. O Apache Spark vem com uma API Python, PySpark, que você pode usar no seu projeto Django para processar grandes conjuntos de dados.
Você vai criar um script Python que usa o PySpark para se conectar ao MongoDB e ler seus registros de transações. Você vai fazer operações básicas com esses dados, tipo filtrá-los. Depois, você vai agrupá-los por país e calcular a receita total de cada um. Por fim, você vai gravar os dados processados em uma nova coleção MongoDB no seu banco de dados.
Desligue o servidor e instale a versão PySpark que é compatível com o mais recente conector MongoDB Spark:
pip install pyspark==3.5.0Confira se a instalação deu certo:
pyspark --versionVocê deve receber uma resposta dando as boas-vindas a Spark.
Depois, crie um arquivo transactions.py na pasta do seu projeto, no mesmo nível que manage.py. A estrutura da sua pasta agora deve ficar assim:
pyspark_tutorial/
├── mongo_migrations/
├── pyspark_tutorial/
├── sales/
├── manage.py
└── transactions.pyPara conectar o PySpark ao MongoDB, você precisa criar uma string de conexão que inclua o nome do seu banco de dados e o nome da coleção. Uma coleção no MongoDB é parecida com uma tabela em bancos de dados relacionais e guarda documentos relacionados. O nome da sua coleção é composto pelo nome do seu aplicativo e pelo nome do modelo, separados por um sublinhado (_).
Use a string de conexão criada no seu arquivo ` transactions.py `. O formato certo é:
mongodb+srv://<mongodb username>:<mongodb password>@<cluster address>/<database name>.<app name>_<model name>?retryWrites=true&w=majority&appName=Cluster0Aqui está a explicação dos valores dos placeholders:
cluster0.2rvn82q.mongodb.net.settings.py._ é o nome da coleção gerada a partir do seu aplicativo e modelo Django — por exemplo, sales_transaction.Nesta seção, a string de conexão que você vai usar no seu código PySpark vai ficar assim:
mongodb+srv://db_user:password@cluster.mongodb.net/pyspark_tutorial.sales_transaction?retryWrites=true&w=majority&appName=Cluster0Adicione o seguinte código ao seu arquivo transactions.py:
from pyspark.sql import SparkSession
# Initialize SparkSession with MongoDB connector:
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
# Add the MongoDB Spark connector package:
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
# Read data from MongoDB into a Spark DataFrame:
df = spark.read.format('mongodb').load()
# Show result:
df.show()
# Stop the Spark session:
spark.stop()from pyspark.sql import SparkSession é o ponto de partida para usar o PySpark. Permite que você interaja com o Spark e faça operações com dados.
O `spark = SparkSession.builder ` inicia uma nova sessão Spark e dá a ela um nome, ` ReadTransactions`. As duas opções ` .config() ` definem como o Spark deve se conectar ao MongoDB:
spark.mongodb.read.connection.uria string de conexão do MongoDB que diz ao Spark onde seu banco de dados está localizadospark.jars.packagesbaixa o pacote do conector MongoDB Spark para que o Spark possa se comunicar com o MongoDB.df = spark.read.format('mongodb').load() carrega todos os documentos da coleção definida na sua string de conexão em um DataFrame do PySpark, facilitando a consulta e a transformação dos seus dados..show() imprime uma pré-visualização dos seus dados MongoDB em formato tabular diretamente no terminal.spark.stop() encerra o aplicativo Spark e libera os recursos do sistema assim que o trabalho estiver concluído.Por fim, troque pela sua string de conexão MongoDB criada. Além disso, certifique-se de que seu endereço IP atual esteja na lista de permissões da sua [lista de acesso à rede do MongoDB Atlas](https://cloud.mongodb.com/) antes de se conectar.
Agora, execute python transactions.pye você vai ver os registros de transações salvos no seu banco de dados no seu terminal.
Você também pode filtrar seus registros usando funções PySpark SQL — por exemplo, para mostrar só transações da Nigéria (NG). Muda o código no seu arquivo transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame column names:
from pyspark.sql.functions import col
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Filter transactions from Nigeria:
ng_df = df.filter(col('country') == 'NG')
# Show filtered results:
ng_df.show()
# Stop the Spark session:
spark.stop()Execute python transactions.py de novo e você vai ver as transações de NG.
Você também pode agrupar seus registros de transações por país e calcular a receita total para cada um. Muda o código no teu arquivo transactions.py:
from pyspark.sql import SparkSession
# Import col to reference DataFrame columns and import sum as _sum to avoid naming conflicts:
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country:
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Show total revenue per country:
revenue_per_country.show()
# Stop the Spark session:
spark.stop()Execute python transactions.py. Você vai ver uma tabela mostrando a receita total por país.
Agora que você já sabe como usar o PySpark pra ler e processar seus dados, vou mostrar como gravar os dados processados numa coleção MongoDB.
Aqui, você vai escrever o DataFrame com a receita total por país em uma nova coleção.
Muda o código no teu transactions.py arquivo:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Write aggregated records into a new MongoDB collection:
revenue_per_country.write \
.format('mongodb') \
.mode('overwrite') \
.option(
'spark.mongodb.write.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.option(
# Specify the target database name:
'spark.mongodb.write.database',
'pyspark_tutorial'
) \
.option(
# Specify the target collection name:
'spark.mongodb.write.collection',
'revenue_per_country'
) \
.save()
# Stop the Spark session:
spark.stop()No código anterior, o Spark grava o DataFrame agregado, revenue_per_country, em uma nova coleção chamada revenue_per_country no seu banco de dadospyspark_tutorial no MongoDB.
Por fim, certifique-se de substituir '' em ambas as configurações de conexão pela sua string de conexão MongoDB criada em. Depois, execute python transactions.py.
Agora, vamos mostrar sua receita total por país em uma página Django.
Primeiro, vamos criar um novo modelo para a receita por país. Adicione isso ao final do seu arquivo sales/models.py:
class RevenuePerCountry(models.Model):
country = models.CharField(max_length=50)
total_revenue = models.DecimalField(max_digits=15, decimal_places=2)
class Meta:
# Define the collection (table) name in MongoDB:
db_table = 'revenue_per_country'
# Order results by total_revenue when querying:
ordering = ['total_revenue']
def __str__(self):
# Return a readable string representation of the record:
return f'{self.country}: ${self.total_revenue}'Depois, mexe no seu arquivo sales/views.py pra pegar e mostrar a coleçãorevenue_per_country:
from django.shortcuts import render
from .models import Transaction
# Import the RevenuePerCountry model:
from .models import RevenuePerCountry
def transaction_list_view(request):
transactions = Transaction.objects.all()
total_revenue = sum(t.total_amount for t in transactions)
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})
# Add a new view to fetch and display your revenue per country:
def revenue_per_country_view(request):
revenue_per_country = RevenuePerCountry.objects.all()
return render(request, 'sales/revenue_per_country.html', {'revenue_per_country': revenue_per_country})Inclua uma rota para a nova visualização em sales/urls.py:
from django.urls import path
from . import views
urlpatterns = [
path('', views.transaction_list_view, name='transaction_list'),
# Add new URL route:
path('revenue_per_country/', views.revenue_per_country_view, name='revenue_per_country'),
]Depois, crie um novo modelo pra mostrar a receita total por país.
Na pasta sales/templates/sales, crie um arquivorevenue_per_country.html e adicione o seguinte:
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transactions</title>
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>
<body>
<h1>Total Revenue by Country</h1>
<a href="{% url 'transaction_list' %}">← Back to Transactions</a>
<table>
<tr>
<th>Country</th>
<th>Total Revenue (USD)</th>
</tr>
{% for r in revenue_per_country %}
<tr>
<td>{{ r.country }}</td>
<td>${{ r.total_revenue|floatformat:2 }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>Você também precisa modificar o modelo sales/templates/sales/transaction_list.html para incluir um link para a página de receita por país. Adicione o seguinte código depois de
:<a href="{% url 'revenue_per_country' %}">View Total Revenue by Country</a>
Execute o servidor Django:
python manage.py runserver
Acesse http://127.0.0.1:8000/revenue_per_country/ para ver se a nova página tá aparecendo direitinho.
Parabéns! Você usou o Apache Spark com sucesso para processar seus dados, armazenou-os no MongoDB e exibiu os dados processados em uma página da web usando o Django.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Bekhruz Tuychiev
15 min
Tutorial
Natassha Selvaraj
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Javier Canales Luna
Tutorial
Abid Ali Awan

