
Kurs
Einführung in PySpark
4 Std.
157.5K
Stell dir vor, du leitest eine E-Commerce-Plattform, die jeden Tag Tausende von Transaktionen abwickelt. Du willst Verkaufstrends analysieren, das Umsatzwachstum verfolgen und zukünftige Einnahmen prognostizieren. Herkömmliche Datenbankabfragen können mit dieser Größe und Geschwindigkeit nicht umgehen. Du brauchst also eine schnellere Möglichkeit, große Datensätze zu verarbeiten und Echtzeit-Erkenntnisse zu gewinnen.
Mit Apache Spark lkannst du riesige Datenmengen effizient analysieren. In diesem Tutorial zeige ich dir, wie du Django, MongoDB und Apache Spark verbinden kannst, um , um E-Commerce-Transaktionsdaten zu analysieren.
Du richtest ein Django-Projekt mit MongoDB als Datenbank ein und speicherst Transaktionsdaten darin. Dann nimmst du PySpark, die Python-API für Apache Spark, um die Daten zu lesen und zu filtern. Du wirst auch einfache Berechnungen durchführen und die verarbeiteten Daten in MongoDB speichern. Zum Schluss zeigst du die verarbeiteten Daten in deiner Django-App an.
Um das Beste aus diesem Tutorial rauszuholen, solltest du Python und das Django-Webframework schon ein bisschen kennen.
Also, los geht's.
Mach zuerst mal eine virtuelle Umgebung für dein Django-Projekt:
python -m venv venv
source venv/bin/activateStell sicher, dass du Python 3.10 oder höher in deiner virtuellen Umgebung installiert hast. Dann installierst du das Django MongoDB-Backend:
pip install django-mongodb-backendDer vorhergehende Befehl installiert auch die neuesten Versionen von PyMongo 4.x und Django 5.2.x.
Nachdem du Django MongoDB Backend runtergeladen hast, leg einfach ein neues Django-Projekt an:
django-admin startproject pyspark_tutorialGeh jetzt zum Projektordner und starte den Entwicklungsserver, um zu checken, ob dein Projekt richtig eingerichtet ist:
cd pyspark_tutorial
python manage.py runserverGeh auf http://127.0.0.1:8000/, um zu checken, ob dein Django-Projekt richtig läuft.
Standardmäßig nutzt Django ganzzahlige IDs vom Typ „ AutoField “ als Primärschlüssel, was bei SQL-Datenbanken gut funktioniert. MongoDB nutzt aber „ ObjectId “ für Dokument-IDs. Damit deine Modelle kompatibel sind, musst du Django dazu bringen, Primärschlüssel als „ ObjectId ” statt als Ganzzahlen zu generieren.
Öffnen pyspark_tutorial/settings.py und aktualisieren Sie die DEFAULT_AUTO_FIELD Einstellung:
DEFAULT_AUTO_FIELD = 'django_mongodb_backend.fields.ObjectIdAutoField'Auch mit dieser globalen Einstellung werden die integrierten Apps von Django wie admin, auth und contenttypes weiterhin standardmäßig auf AutoField gesetzt . Damit alles in allen Apps gleich läuft, kannst du eigene App-Einstellungen machen, damit sie ObjectId nutzen.
Mach eine pyspark_tutorial/apps.py Datei und füge Folgendes hinzu:
from django.contrib.admin.apps import AdminConfig
from django.contrib.auth.apps import AuthConfig
from django.contrib.contenttypes.apps import ContentTypesConfig
class MongoAdminConfig(AdminConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoAuthConfig(AuthConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
class MongoContentTypesConfig(ContentTypesConfig):
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'Jetzt musst du in der Datei „ pyspark_tutorial/settings.py “ die Einstellung „INSTALLED_APPS “ ändern :
INSTALLED_APPS = [
'pyspark_tutorial.apps.MongoAdminConfig',
'pyspark_tutorial.apps.MongoAuthConfig',
'pyspark_tutorial.apps.MongoContentTypesConfig',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]Da alle Modelle ObjectIdAutoField verwenden müssen, braucht jede Drittanbieter- und contrib -App, die du benutzt, ihre eigenen, für MongoDB spezifischen Migrationen. Füge also Folgendes zu deiner Datei „ pyspark_tutorial/setting.py “ hinzu:
MIGRATION_MODULES = {
'admin': 'mongo_migrations.admin',
'auth': 'mongo_migrations.auth',
'contenttypes': 'mongo_migrations.contenttypes',
}Mach einen Ordner namens „ mongo_migrations ” in deinem Projektordner, auf derselben Ebene wie deine Datei „ manage.py ”. Deine Ordnerstruktur sollte jetzt ungefähr so aussehen:
pyspark_tutorial/
├── pyspark_tutorial/
├── mongo_migrations/
└── manage.pyHalt den Server mit **Strg + C** an und mach dann deine Migrationen:
python manage.py makemigrations admin auth contenttypesWenn du deinen Ordner „ mongo_migrations “ anschaust, findest du dort einen Ordner für jede integrierte App. Jeder Ordner hat seine eigenen Migrationen.
Für eine Django-Projektvorlage, die alle oben genannten MongoDB-Konfigurationen enthält, machst du Folgendes:
django-admin startproject pyspark_tutorial --template https://github.com/mongodb-labs/django-mongodb-project/archive/refs/heads/5.2.x.zipAnmerkung: Wenn du eine andere Django-Version als 5.2.x benutzt, tausche die beiden Zahlen gegen die ersten beiden Zahlen deiner Version aus.
Der nächste Schritt ist, eine Django-App zu erstellen, um deine rohen und verarbeiteten Transaktionsdatensätze zu speichern.
python manage.py startapp salesUm deine neue App für die Nutzung von ObjectId einzurichten, öffne sales/apps.py und ersetze die Zeile default_auto_field = 'django.db.models.BigAutoField':
from django.apps import AppConfig
class SalesConfig(AppConfig):
# Use ObjectId as the default primary key field type for MongoDB:
default_auto_field = 'django_mongodb_backend.fields.ObjectIdAutoField'
name = 'sales'Du kannst auch die folgende Vorlage „ startapp “ verwenden, die die oben genannte Änderung enthält:
python manage.py startapp sales --template https://github.com/mongodb-labs/django-mongodb-app/archive/refs/heads/5.2.x.zipJetzt fügst du in der Datei „ pyspark_tutorial/settings.py “ deine App „ sales “ zur Liste „INSTALLED_APPS “ hinzu :
INSTALLED_APPS = [
# Add your sales app:
'sales.apps.SalesConfig',
...
]Da du deine Daten in MongoDB speichern wirst, zeige ich dir, wie du eine kostenlose Bereitstellung auf MongoDB Atlas erstellst, um deine Daten in der Cloud zu speichern und zu verwalten.
Melde dich mit deinem Google-Konto oder einer E-Mail-Adresse für ein Atlas-Konto an.
Klick auf „Erstellen“, um einen „ Free “-Cluster zu machen:
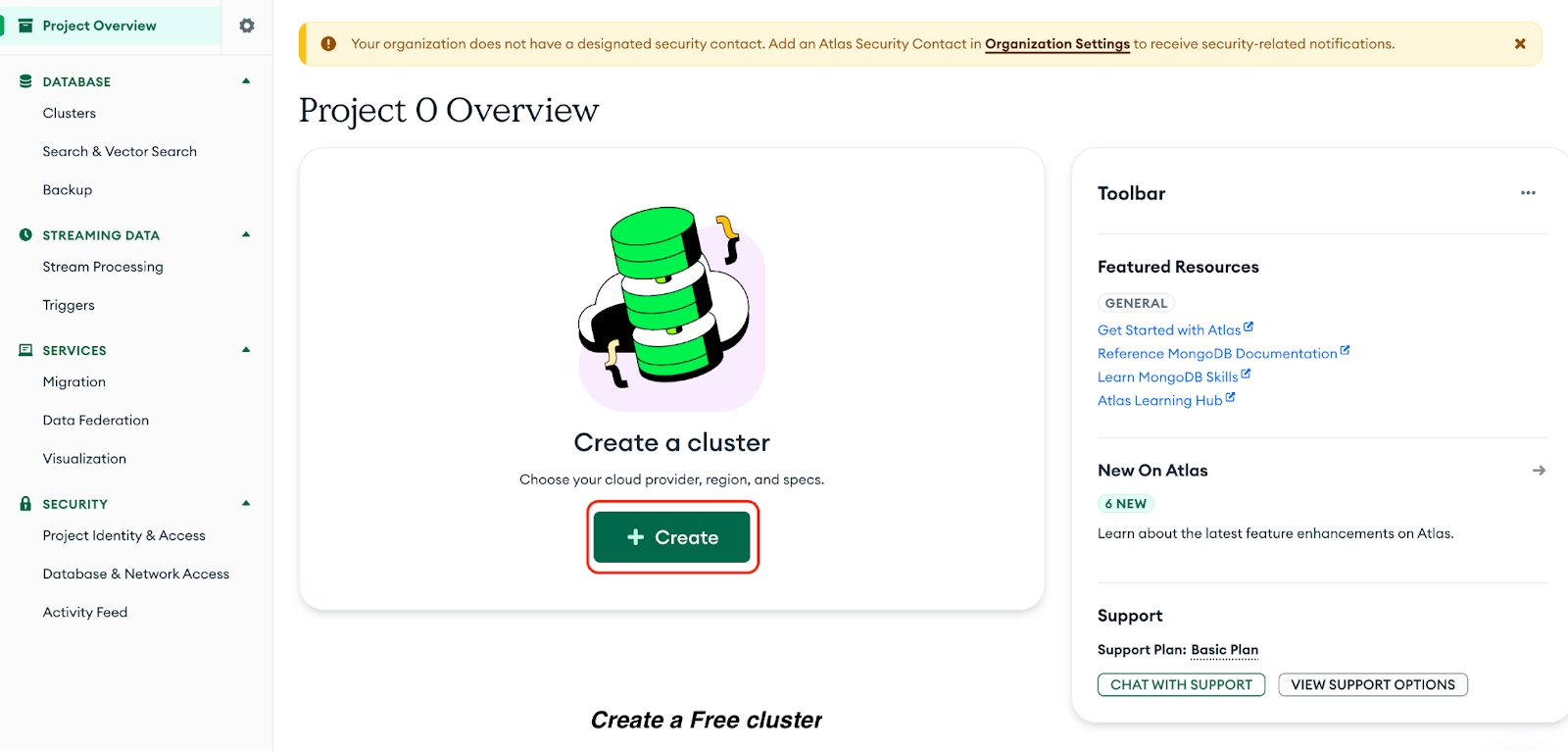
Jetzt wählst du auf der angezeigten Seite die folgenden Optionen aus:
Klick Bereitstellung erstellen:
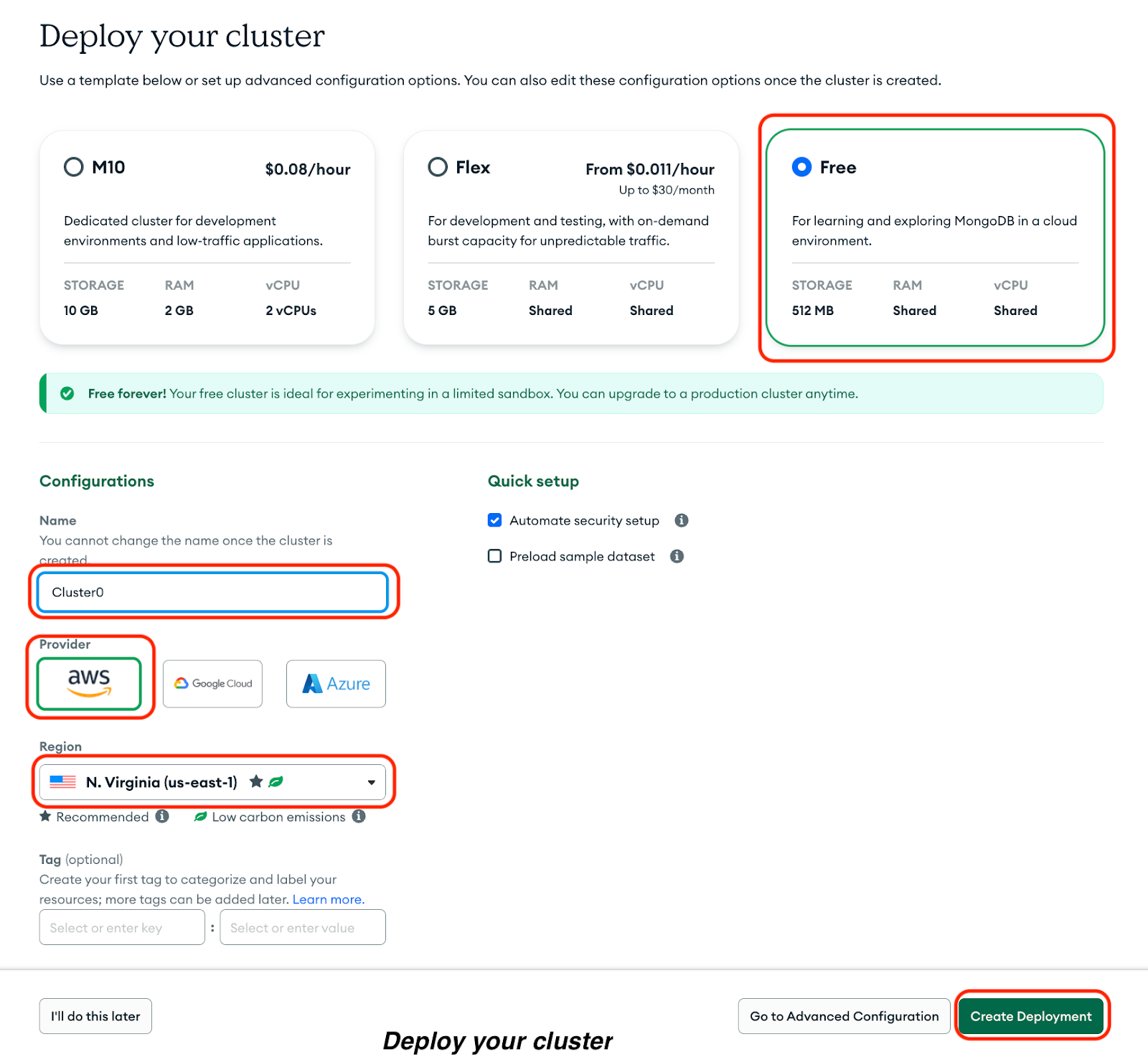
Du siehst deinen Benutzernamen und dein Passwort. Mach Folgendes:
1. Schreib deinen Benutzernamen und dein Passwort in ein sicheres Dokument.
2. Klick auf„ “ (Datenbankbenutzer erstellen).
3. Klick auf„ “ ( Verbindungs-IP-Adresse festlegen).Wähle eine Verbindungsmethode aus, um eine Verbindungs-IP-Adresse festzulegen.
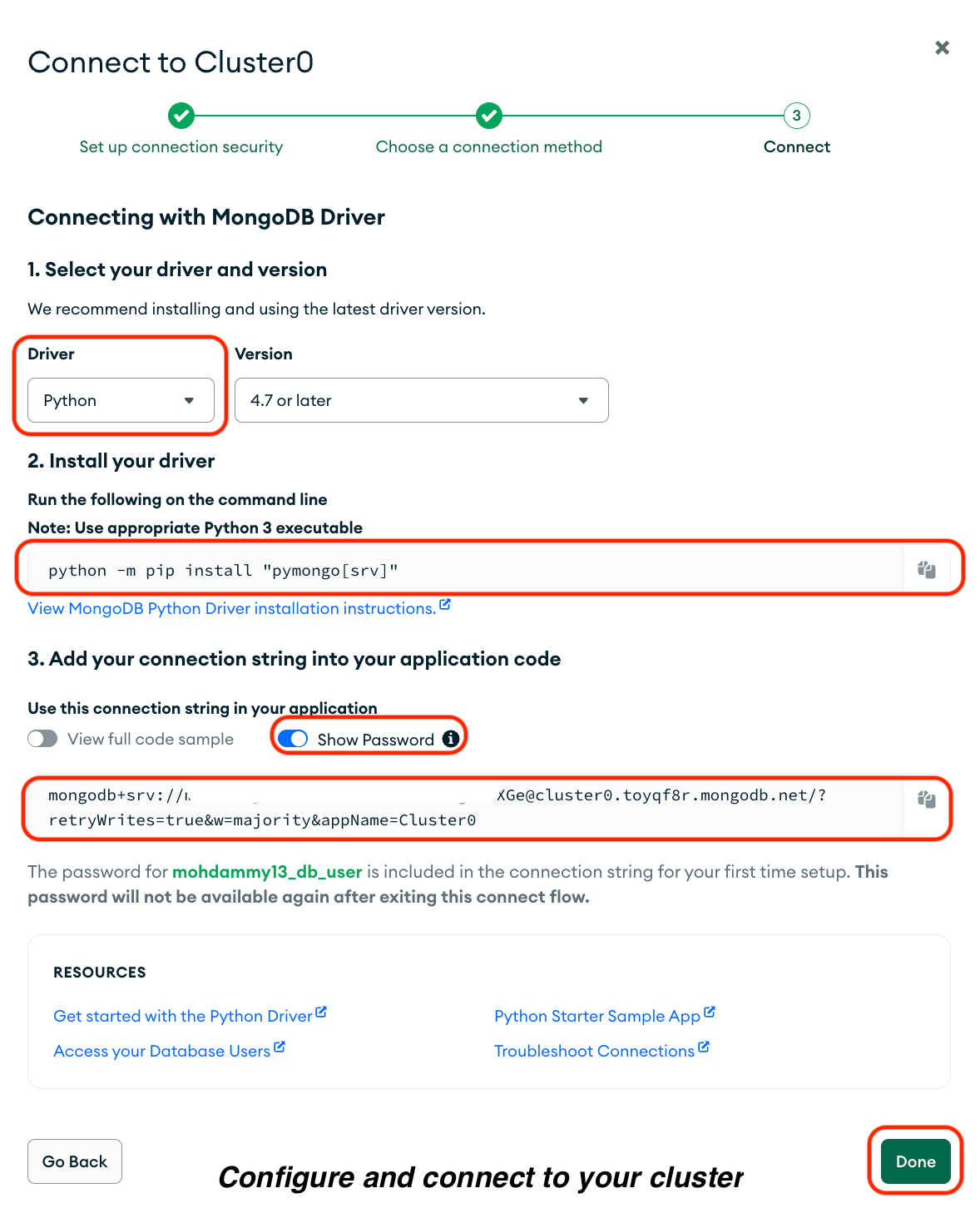
Mach auf der angezeigten Seite Folgendes:
1. Wähl„ -Treiber“ aus.

2. Wähl„ Python” als Treiber aus.
3. Kopier den Befehl aus der Option„Treiber istallieren“ und führ ihn in deinem Terminal aus.
4. Kopiere deine Verbindungszeichenfolge „ connection string “ zusammen mit deinem Passwort unter „Add your connection string“ in deinen Anwendungscode und speichere sie in einem sicheren Dokument.
5. Klick auf„ “ Fertig.
Öffne pyspark_tutorial/settings.py und ändere die Einstellung „ DATABASES “ , um das Django MongoDB-Backend mit deiner gespeicherten Datenbank „ connection string “ zu nutzen . Leg auch einen Datenbanknamen fest:
DATABASES = {
'default': {
# Change to use Django MongoDB Backend:
'ENGINE': 'django_mongodb_backend',
# Use your saved connection string:
'HOST': '<connection string>',
# Set a database name:
'NAME': 'pyspark_tutorial',
},
}Stell im obigen Code sicher, dass du durch deine gespeicherte Verbindungszeichenfolge ersetzt.
Diese Konfiguration verbindet Django mit deinem MongoDB Atlas-Cluster. Die Datei „ ENGINE ” zeigt auf das MongoDB-Backend, „ HOST ” speichert deine Verbindungszeichenfolge und „NAME ” legt den Datenbanknamen fest, den Django verwenden wird.
Jetzt, wo deine App fertig ist, kannst du die Modelle, Ansichten, URLs und Vorlagen erstellen, die du brauchst, um die Transaktionsdaten in deinem Browser anzuzeigen.
Modelle zeigen, wie deine Daten aufgebaut sind. Mach ein Modell, um Transaktionsdatensätze darzustellen. Öffne „ sales/models.py “ und ersetze den Code:
from django.db import models
# Define a model to represent each transaction record:
class Transaction(models.Model):
order_id = models.CharField(max_length=50, unique=True)
user_id = models.CharField(max_length=50)
product = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
quantity = models.PositiveIntegerField()
timestamp = models.DateTimeField()
country = models.CharField(max_length=50)
class Meta:
# Sort transactions by order ID:
ordering = ['order_id']
# Add indexes to improve query performance for common lookup fields
indexes = [
models.Index(fields=['timestamp']),
models.Index(fields=['country']),
models.Index(fields=['product']),
]
def __str__(self):
return f'{self.order_id} - {self.product}'
@property
def total_amount(self):
# Calculate and return the total transaction amount:
return self.price * self.quantityDieses Modell definiert jede Transaktion mit Feldern für Produktdetails, Preis, Menge und Land. Es sortiert die Transaktionen nach „ order_id “. Es hat auch einen Index für wichtige Felder, um die Abfrage-Performance zu verbessern, und eine Eigenschaft, die den Gesamtbetrag der Transaktion berechnet.
Ansichten bestimmen, wie diese Datensätze im Browser angezeigt werden. Mach dir eine Ansicht, um die Transaktionsdatensätze anzuzeigen. Öffne „ sales/views.py “ und ersetze den Code:
from django.shortcuts import render
from .models import Transaction
# Define a view to display all transactions and total revenue:
def transaction_list_view(request):
# Retrieve all transaction records from the database:
transactions = Transaction.objects.all()
# Calculate the total revenue from all transactions:
total_revenue = sum(t.total_amount for t in transactions)
# Render the transaction list template with context data
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})Die vorherige Ansicht ruft alle Transaktionsdatensätze aus MongoDB mit dem Modell „ Transaction “ ab. Es berechnet den Gesamtumsatz, indem es das Feld „ total_amount “ für jede Transaktion zusammenzählt. Dann schickt es zwei Werte an eine Vorlage namens „ transaction_list.html “ , die wir später erstellen werden:
* transactionsEine Liste aller Transaktionsdatensätze, die in einer Tabelle angezeigt werden sollen.
* total_revenue: der Gesamtbetrag, der durch alle Transaktionen zusammen gemacht wird
Die Vorlage nutzt diese Werte, um jede Transaktion und den Gesamtumsatz anzuzeigen.
Du musst Routen erstellen, damit Django weiß, welche Ansicht geladen werden soll, wenn Nutzer eine URL aufrufen. Mach eine Datei namens „ sales/urls.py “ und füge Folgendes hinzu:
from django.urls import path
from . import views
# Define URL patterns for the sales app:
urlpatterns = [
# Route the root URL to the transaction list view:
path('', views.transaction_list_view, name='transaction_list'),
]Füge die URLs deiner App in die URL-Konfiguration deines Projekts ein. Öffne die Datei „ pyspark_tutorial/urls.py “ und ändere sie so:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
# Include your app’s URLs:
path("", include('sales.urls')),
]Vorlagen bestimmen, wie deine Daten im Browser angezeigt werden. Mach einen Ordner namens „ sales/templates/sales “ und leg eine Datei namens „transaction_list.html “ rein.
Deine sales App-Struktur sollte ungefähr so aussehen:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
└── templates/
└── sales/
└── transaction_list.htmlFüge Folgendes zu deiner Datei „ transaction_list.html “ hinzu:
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
</head>
<body>
<h1>E-commerce Transactions</h1>
<h3>Total Revenue: ${{ total_revenue }}</h3>
<table>
<thead>
<tr>
<th>Order ID</th>
<th>User ID</th>
<th>Product</th>
<th>Price</th>
<th>Quantity</th>
<th>Country</th>
<th>Timestamp</th>
</tr>
</thead>
<tbody>
{% for t in transactions %}
<tr>
<td>{{ t.order_id }}</td>
<td>{{ t.user_id }}</td>
<td>{{ t.product }}</td>
<td>${{ t.price }}</td>
<td>{{ t.quantity }}</td>
<td>{{ t.country }}</td>
<td>{{ t.timestamp }}</td>
</tr>
{% empty %}
<tr><td colspan="7">No transactions available.</td></tr>
{% endfor %}
</tbody>
</table>
</body>
</html>Die obige Vorlage nutzt die Vorlagensprache von Django, um Daten, die von der Ansicht übergeben werden, dynamisch anzuzeigen.
Oben wird der Gesamtumsatz mit „ {{ total_revenue }} “ angezeigt. Dann geht die Vorlage mit dem Tag „ {% for t in transactions %} “ alle Transaktionsdatensätze in den Transaktionen durch und zeigt jeden Datensatz als Zeile in der Tabelle an. Jede Spalte zeigt ein bestimmtes Merkmal einer Transaktion, wie zum Beispiel „ order_id “, „ product “, „ price “, „ quantity “ und „ country “. Wenn es keine Datensätze gibt, sorgt das Tag „ {% empty %} “ dafür, dass statt einer leeren Tabelle die Meldung „Keine Transaktionen verfügbar“ angezeigt wird.
Damit deine Transaktionsseite optisch ansprechender und übersichtlicher wird, fügst du ein individuelles CSS-Styling hinzu. Django stellt statische Dateien wie CSS, JavaScript und Bilder über ein spezielles Verzeichnis namens „ static “ bereit. So bleiben die Designdateien von deinem Code getrennt.
Erstell jetzt einen Ordner namens „ sales/static/sales “ und leg darin eine Datei mit dem Namen „ styles.css “ ab . Deine Ordnerstruktur im Ordner „ sales “ sollte so aussehen:
sales/
├── __init__.py
├── admin.py
├── apps.py
├── migrations/
├── models.py
├── views.py
├── tests.py
├── urls.py
├── templates/
│ └── sales/
│ └── transaction_list.html
└── static/
└── sales/
└── styles.cssStell sicher, dass in ` pyspark_tutorial/settings.py ` die Variable `STATIC_URL ` definiert ist:
STATIC_URL = 'static/'Füge das hier in deine Datei „ sales/static/sales/styles.css “ ein:
table {
width: 100%;
border-collapse: collapse;
margin-top: 20px;
}
th, td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
th {
background-color: #f5f5f5;
}
body {
background-color:transparent;font-weight:400;font-style:normal;font-variant:normal;text-decoration:none;vertical-align:baseline;white-space:pre;white-space:pre-wrap;">: Arial, sans-serif;
margin: 20px;
}
h1 {
color: #333;
}
a {
text-decoration: none;
color: #007bff;
}
a:hover {
text-decoration: underline;
}Sag Django zum Schluss, dass es die statischen Dateien laden und die CSS-Datei in deine HTML-Vorlage einbinden soll.
Füge oben auf der Seite „ sales/templates/sales/transaction_list.html “ den folgenden Code ein : {% load static %}. Aktualisiere dann das Element „ “ , damit es auf die Datei „styles.css “ verweist :
<!-- Load static files:-->
{% load static %}
<!DOCTYPE html>
<html>
<head>
<title>Transactions</title>
<!-- Link the CSS file for styling the template:-->
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>Erstell und wende deine Migrationen an, damit Django die nötigen Sammlungen in MongoDB erstellen kann:
python manage.py makemigrations
python manage.py migrateJetzt fügen wir mit den Modellen deiner Anwendung Transaktionsdatensätze zur Datenbank „ pyspark_tutorial ” hinzu. Dazu benutzen wir die interaktive Shell von Django:
python manage.py shellDann importier das Modell „ Transaction ” aus deiner Vertriebs-App und „timezone ” aus den Django-Utilities:
from sales.models import Transaction
from django.utils import timezoneJetzt füge die Transaktionsdatensätze mit „ bulk_create() “ ein:
Transaction.objects.bulk_create([
Transaction(order_id='T1001', user_id='U001', product='Laptop', price=1000.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1002', user_id='U002', product='Smartphone', price=800.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1003', user_id='U003', product='Headphones', price=150.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1004', user_id='U004', product='Laptop', price=1200.00, quantity=1, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1005', user_id='U005', product='Keyboard', price=45.00, quantity=3, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1006', user_id='U006', product='Monitor', price=300.00, quantity=2, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1007', user_id='U007', product='Smartwatch', price=199.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1008', user_id='U008', product='Speaker', price=150.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1009', user_id='U009', product='Camera', price=800.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1010', user_id='U010', product='Tablet', price=350.00, quantity=1, timestamp=timezone.now(), country='UK'),
Transaction(order_id='T1011', user_id='U011', product='Headphones', price=75.00, quantity=2, timestamp=timezone.now(), country='US'),
Transaction(order_id='T1012', user_id='U012', product='Laptop', price=1300.00, quantity=1, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1013', user_id='U013', product='Mouse', price=30.00, quantity=3, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1014', user_id='U014', product='Smartphone', price=950.00, quantity=1, timestamp=timezone.now(), country='KE'),
Transaction(order_id='T1015', user_id='U015', product='Keyboard', price=55.00, quantity=2, timestamp=timezone.now(), country='CA'),
Transaction(order_id='T1016', user_id='U016', product='Smartwatch', price=250.00, quantity=1, timestamp=timezone.now(), country='DE'),
Transaction(order_id='T1017', user_id='U017', product='Speaker', price=180.00, quantity=1, timestamp=timezone.now(), country='FR'),
Transaction(order_id='T1018', user_id='U018', product='Monitor', price=400.00, quantity=2, timestamp=timezone.now(), country='NG'),
Transaction(order_id='T1019', user_id='U019', product='Laptop', price=1250.00, quantity=1, timestamp=timezone.now(), country='IN'),
Transaction(order_id='T1020', user_id='U020', product='Camera', price=780.00, quantity=1, timestamp=timezone.now(), country='US'),
])Schau mal, ob die Datensätze erfolgreich hinzugefügt wurden:
Transaction.objects.count()Wenn die Zählung 20 ergibt, wurden deine Datensätze erfolgreich gespeichert.
Jetzt verlass die shell, indem du „ exit() “ ausführst, und starte deinen Django-Server, um deine Transaktionen im Browser anzuzeigen:
python manage.py runserverSchau mal auf http://127.0.0.1:8000/ vorbei, um zu checken, ob deine Daten da sind.
Jetzt, wo deine Datensätze in deiner MongoDB-Datenbank gespeichert sind, wirst du Apache Spark nutzen, um deine Daten zu verarbeiten. Apache Spark hat eine Python-API namens PySpark, die du in deinem Django-Projekt nutzen kannst, um große Datensätze zu verarbeiten.
Du wirst ein Python-Skript erstellen, das PySpark nutzt, um eine Verbindung zu MongoDB herzustellen und deine Transaktionsdatensätze zu lesen. Du wirst grundlegende Operationen mit diesen Daten durchführen, wie zum Beispiel das Filtern. Dann gruppierst du sie nach Ländern und rechnest den Gesamtumsatz für jedes Land aus. Zum Schluss speicherst du die bearbeiteten Daten in einer neuen MongoDB-Sammlung in deiner Datenbank.
Schalte deinen Server aus und installiere die Version, PySpark die mit dem neuesten MongoDB Spark-Konnektor:
pip install pyspark==3.5.0Schau mal, ob die Installation geklappt hat:
pyspark --versionDu solltest eine Antwort bekommen, in der du bei Spark willkommen geheißen wirst.
Als Nächstes legst du eine Datei namens „ transactions.py “ in deinem Projektordner an, auf derselben Ebene wie „ manage.py “. Deine Ordnerstruktur sollte jetzt so aussehen:
pyspark_tutorial/
├── mongo_migrations/
├── pyspark_tutorial/
├── sales/
├── manage.py
└── transactions.pyUm PySpark mit MongoDB zu verbinden, musst du eine Verbindungszeichenfolge erstellen, die deinen Datenbanknamen und deinen Sammlungsnamen enthält. Eine Sammlung in MongoDB ist wie eine Tabelle in relationalen Datenbanken und speichert zusammengehörige Dokumente. Der Name deiner Sammlung setzt sich aus dem Namen deiner App und dem Modellnamen zusammen, die durch einen Unterstrich (_) getrennt sind.
Benutz die eingebaute Verbindungszeichenfolge in deiner Datei „ transactions.py “. Das richtige Format ist:
mongodb+srv://<mongodb username>:<mongodb password>@<cluster address>/<database name>.<app name>_<model name>?retryWrites=true&w=majority&appName=Cluster0Hier ist die Erklärung der Platzhalterwerte:
cluster0.2rvn82q.mongodb.net.settings.py._ ist der Name der Sammlung, die aus deiner Django-App und deinem Modell generiert wird – zum Beispiel sales_transaction.In diesem Abschnitt sieht die Verbindungszeichenfolge, die du in deinem PySpark-Code verwenden wirst, so aus:
mongodb+srv://db_user:password@cluster.mongodb.net/pyspark_tutorial.sales_transaction?retryWrites=true&w=majority&appName=Cluster0Füge den folgenden Code zu deiner Datei „ transactions.py “ hinzu:
from pyspark.sql import SparkSession
# Initialize SparkSession with MongoDB connector:
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
# Add the MongoDB Spark connector package:
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
# Read data from MongoDB into a Spark DataFrame:
df = spark.read.format('mongodb').load()
# Show result:
df.show()
# Stop the Spark session:
spark.stop()from pyspark.sql import SparkSession ist der Einstiegspunkt für die Nutzung von PySpark. Damit kannst du mit Spark interagieren und Datenoperationen durchführen.
Der „ spark = SparkSession.builder ” startet eine neue Spark-Sitzung und gibt ihr den Namen „ ReadTransactions ”. Die beiden Optionen „ .config() “ legen fest, wie Spark sich mit MongoDB verbinden soll:
spark.mongodb.read.connection.uriDie MongoDB-Verbindungszeichenfolge, die Spark sagt, wo deine Datenbank ist.spark.jars.packagesLädt das MongoDB Spark-Konnektorpaket runter, damit Spark mit MongoDB reden kann.df = spark.read.format('mongodb').load() lädt alle Dokumente aus der in deiner Verbindungszeichenfolge definierten Sammlung in ein PySpark-DataFrame, wodurch du deine Daten ganz einfach abfragen und umwandeln kannst..show() Zeigt eine Vorschau deiner MongoDB-Daten in Tabellenform direkt im Terminal an.spark.stop() beendet die Spark-Anwendung und gibt die Systemressourcen frei, sobald der Job erledigt ist.Zum Schluss ersetze durch deine erstellte MongoDB-Verbindungszeichenfolge. Stell außerdem sicher, dass deine aktuelle IP-Adresse in deiner [MongoDB Atlas-Netzwerkzugriffsliste](https://cloud.mongodb.com/) auf der Whitelist steht, bevor du eine Verbindung herstellst.
Jetzt mach mal python transactions.pyaus, und du bekommst die gespeicherten Transaktionsdatensätze aus deiner Datenbank in deinem Terminal angezeigt.
Du kannst deine Datensätze auch mit PySpark-SQL-Funktionen filtern, zum Beispiel um nur Transaktionen aus Nigeria (NG) anzuzeigen. Ändere den Code in deiner Datei „ transactions.py “:
from pyspark.sql import SparkSession
# Import col to reference DataFrame column names:
from pyspark.sql.functions import col
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<built connection string>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Filter transactions from Nigeria:
ng_df = df.filter(col('country') == 'NG')
# Show filtered results:
ng_df.show()
# Stop the Spark session:
spark.stop()Mach nochmal „ python transactions.py “ und du siehst die Transaktionen von „NG “.
Du kannst deine Transaktionsdaten auch nach Ländern gruppieren und den Gesamtumsatz für jedes Land berechnen. Ändere den Code in deiner Datei „ transactions.py “:
from pyspark.sql import SparkSession
# Import col to reference DataFrame columns and import sum as _sum to avoid naming conflicts:
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country:
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Show total revenue per country:
revenue_per_country.show()
# Stop the Spark session:
spark.stop()Mach mal ' python transactions.py'. Du siehst eine Tabelle mit den Gesamteinnahmen pro Land.
Jetzt, wo du weißt, wie du mit PySpark deine Daten lesen und bearbeiten kannst, zeige ich dir, wie du die bearbeiteten Daten in eine MongoDB-Sammlung schreiben kannst.
Hier schreibst du den DataFrame mit den Gesamteinnahmen pro Land in eine neue Sammlung.
Ändere den Code in deiner transactions.py Datei:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum as _sum
spark = SparkSession.builder \
.appName('ReadTransactions') \
.config(
'spark.mongodb.read.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.config(
'spark.jars.packages',
'org.mongodb.spark:mongo-spark-connector_2.12:10.4.0'
) \
.getOrCreate()
df = spark.read.format('mongodb').load()
# Calculate total revenue per country
revenue_per_country = df.groupBy('country').agg(
_sum(col('price') * col('quantity')).alias('total_revenue')
)
# Write aggregated records into a new MongoDB collection:
revenue_per_country.write \
.format('mongodb') \
.mode('overwrite') \
.option(
'spark.mongodb.write.connection.uri',
# Replace with your built MongoDB connection string:
'<Built Connection String>'
) \
.option(
# Specify the target database name:
'spark.mongodb.write.database',
'pyspark_tutorial'
) \
.option(
# Specify the target collection name:
'spark.mongodb.write.collection',
'revenue_per_country'
) \
.save()
# Stop the Spark session:
spark.stop()Im obigen Code schreibt Spark das aggregierte DataFrame „ revenue_per_country “ in eine neue Sammlung namens „ revenue_per_country “ in deiner Datenbank „pyspark_tutorial “ auf MongoDB.
Stell zum Schluss sicher, dass du in beiden Verbindungskonfigurationen „ '' “ durch deine selbst erstellte MongoDB-Verbindungszeichenfolge„ “ ersetzt . Dann machst du Folgendes: python transactions.py.
Jetzt zeigen wir deinen Gesamtumsatz nach Ländern auf einer Django-Seite an.
Zuerst erstellen wir ein neues Modell für den Umsatz pro Land. Füge das hier am Ende deiner Datei „ sales/models.py “ hinzu:
class RevenuePerCountry(models.Model):
country = models.CharField(max_length=50)
total_revenue = models.DecimalField(max_digits=15, decimal_places=2)
class Meta:
# Define the collection (table) name in MongoDB:
db_table = 'revenue_per_country'
# Order results by total_revenue when querying:
ordering = ['total_revenue']
def __str__(self):
# Return a readable string representation of the record:
return f'{self.country}: ${self.total_revenue}'Als Nächstes musst du deine Datei „ sales/views.py “ ändern, um die Sammlung „revenue_per_country “ abzurufen und anzuzeigen :
from django.shortcuts import render
from .models import Transaction
# Import the RevenuePerCountry model:
from .models import RevenuePerCountry
def transaction_list_view(request):
transactions = Transaction.objects.all()
total_revenue = sum(t.total_amount for t in transactions)
return render(request, 'sales/transaction_list.html', {
'transactions': transactions,
'total_revenue': total_revenue,
})
# Add a new view to fetch and display your revenue per country:
def revenue_per_country_view(request):
revenue_per_country = RevenuePerCountry.objects.all()
return render(request, 'sales/revenue_per_country.html', {'revenue_per_country': revenue_per_country})Füge eine Route zur neuen Ansicht in „ sales/urls.py “ ein:
from django.urls import path
from . import views
urlpatterns = [
path('', views.transaction_list_view, name='transaction_list'),
# Add new URL route:
path('revenue_per_country/', views.revenue_per_country_view, name='revenue_per_country'),
]Als Nächstes machst du eine neue Vorlage, um die Gesamteinnahmen pro Land anzuzeigen.
Mach im Ordner „ sales/templates/sales “ eine Datei namens „revenue_per_country.html “ und füge Folgendes hinzu:
{% load static %}
<!DOCTYPE html>
<html lang="en">
<head>
<title>Transactions</title>
<link rel="stylesheet" href="{% static 'sales/styles.css' %}">
</head>
<body>
<h1>Total Revenue by Country</h1>
<a href="{% url 'transaction_list' %}">← Back to Transactions</a>
<table>
<tr>
<th>Country</th>
<th>Total Revenue (USD)</th>
</tr>
{% for r in revenue_per_country %}
<tr>
<td>{{ r.country }}</td>
<td>${{ r.total_revenue|floatformat:2 }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>Du musst auch die Vorlage „ sales/templates/sales/transaction_list.html “ ändern, um einen Link zur Seite „Umsatz pro Land“ hinzuzufügen. Füge den folgenden Code nach „
”:<a href="{% url 'revenue_per_country' %}">View Total Revenue by Country</a>
Starte den Django-Server:
python manage.py runserver
Schau mal auf http://127.0.0.1:8000/revenue_per_country/ vorbei, um zu checken, ob die neue Seite richtig angezeigt wird.
Herzlichen Glückwunsch! Du hast Apache Spark erfolgreich benutzt, um deine Daten zu verarbeiten, sie in MongoDB gespeichert und die verarbeiteten Daten mit Django auf einer Webseite angezeigt.
einDie besten DataCamp-Kurse
Kurs
Kurs
Kurs
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Javier Canales Luna
