
programa
Científico especializado en machine learning en Python
85 h
To fully appreciate the content of this article on Falcon 40B, readers should have a foundational understanding of machine learning and natural language processing concepts. Familiarity with transformer models and their components, such as attention mechanisms and positional embeddings, is valuable.
If you're new to AI and looking to learn the fundamentals, take our AI Fundamentals skill track. You'll gain knowledge about ChatGPT, Machine Learning, LLMs, Generative AI, and AI ethics.
The Falcon 40B is part of the Falcon family of large language models (LLMs) developed by Technology Innovation Institute (TII), which also includes the Falcon 7B and Falcon 180B. As a causal decoder-only model, Falcon 40B is designed for various natural language generation tasks.
The multilingual capabilities of Falcon 40B encompass English, German, Spanish, and French, with limited proficiency in several other languages, including Italian, Portuguese, Polish, Dutch, Romanian, Czech, and Swedish.
Falcon 40B's architecture is adapted from GPT-3 but with key modifications for enhanced performance. It employs rotary positional embeddings for better sequence understanding. Attention mechanisms are enriched with multi-query attention and FlashAttention. The decoder block features parallel attention and Multi-Layer Perceptron (MLP) structures with a two-layer normalization scheme, balancing computational efficiency.
Falcon 40B was trained on 1 trillion tokens from RefinedWeb, an internet corpus filtered for quality, as well as additional curated datasets. Instead of gathering scattered curated sources, TII enhanced the quality of web data by employing large-scale deduplication and strict filtering, thus achieving a high-quality training dataset that contributes to the high performance of Falcon models.
Falcon 40B was trained on AWS SageMaker 384 A100 40GB GPUs, utilizing a 3D parallelism strategy (TP=8, PP=4, DP=12) in conjunction with ZeRO. The training commenced in December 2022 and took two months to finish.
Learn how to train large language models using PyTorch, from initial setup to final implementation, by following the How to Train a Large Language Model with PyTorch tutorial.
Unlike the traditional multihead attention scheme, Falcon 40B employs Multi-Query Attention where one key and value are shared across all attention heads. This innovative attention mechanism does not significantly impact pretraining but vastly improves inference scalability.
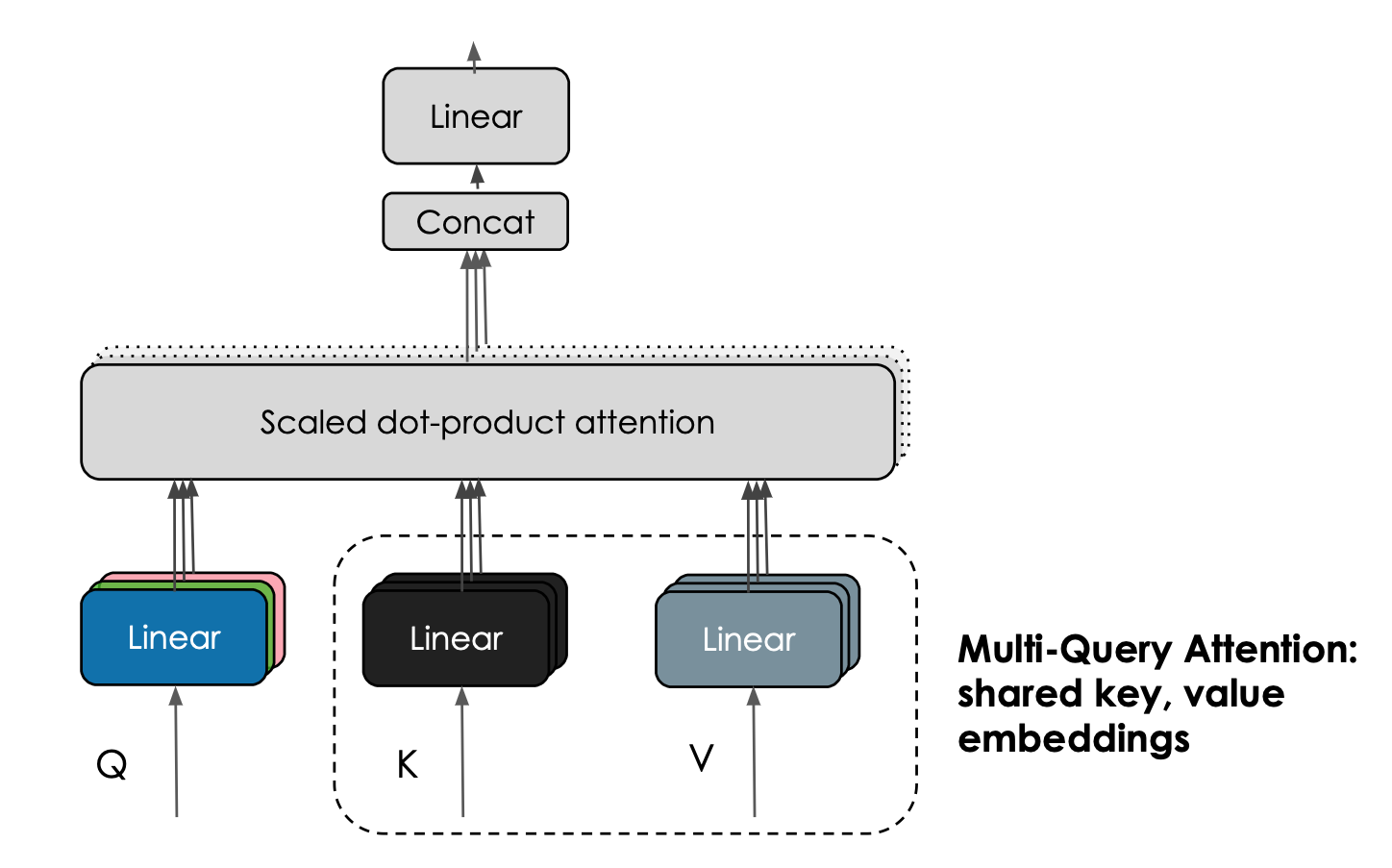
Image from Falcon blog
TII has also introduced instruct versions of the models, Falcon-7B-Instruct and Falcon 40B-Instruct, which are fine-tuned on instructions and conversational data for better performance on assistant-style tasks.
Though Falcon 40B requires substantial GPU memory, you can always use quantization to make this model accessible on cheaper GPUs or even run a smaller version of the model Falcon-7B on Google Colab.
Falcon 40B outclasses other open-source models like LLaMA, StableLM, RedPajama, and MPT, as evidenced on the OpenLLM Leaderboard. Its superior performance makes it a leading choice among available open-source models.
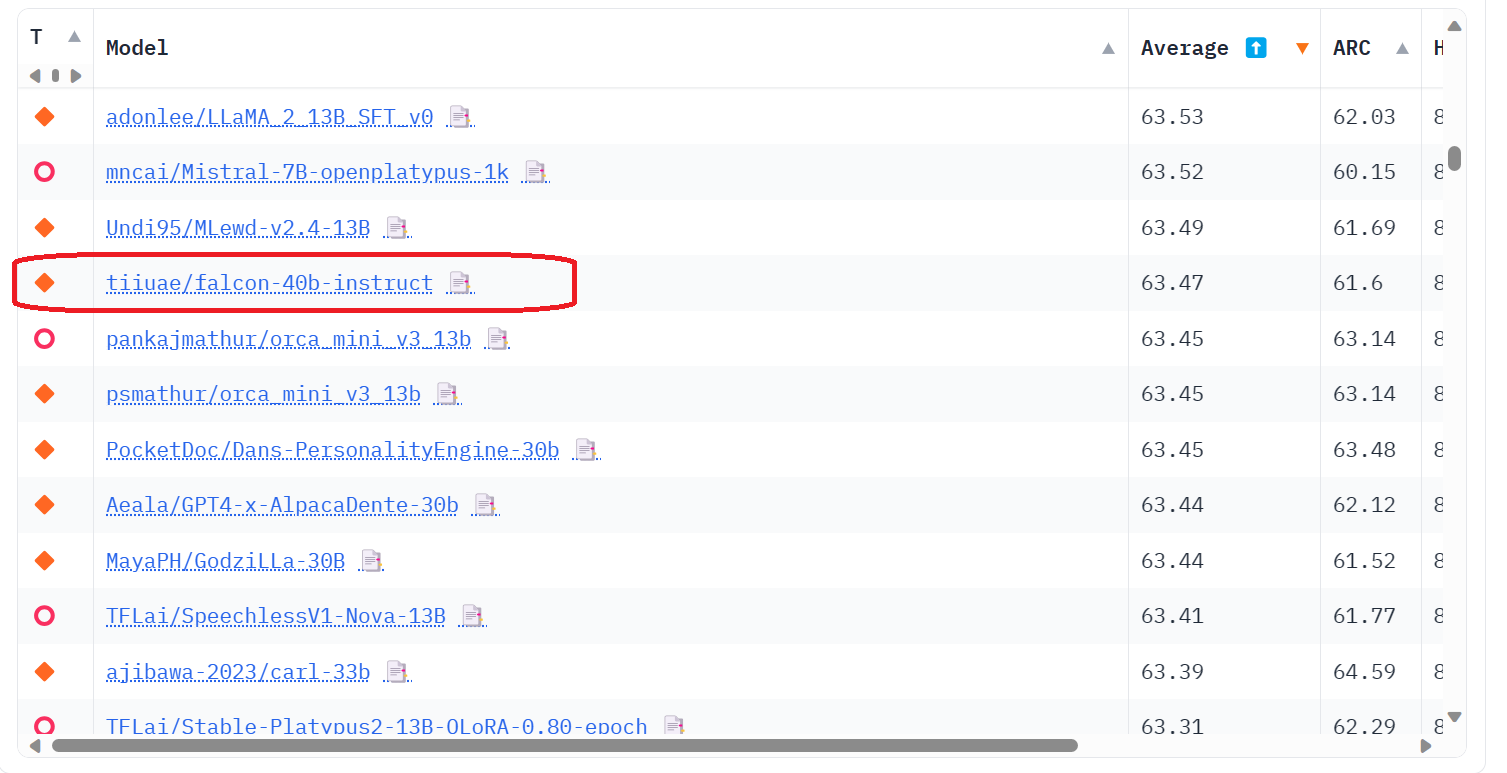
Image from Open LLM Leaderboard
The Falcon 40B architecture is optimized for efficient inference using features such as FlashAttention and multi-query attention, resulting in higher inference speed and scalability. It is a raw pre-trained language model that requires further fine-tuning to be used for most cases.
Falcon 40B comes with an Apache 2.0 license, which lets you use the model and dataset for commercial usage without any royalty obligations or restrictions.
In this section, we will cover the process of loading the Falcon 40B model and running the inference. Additionally, we will explore how to run the inference for the smaller Falcon 7B version on Google Colab using 4bit Quantization. Finally, we will learn to use QLoRA and SFT Trainer to fine-tune our model on a new dataset.
Running the 40 billion parameter Falcon 40B model poses memory challenges. The model exceeds the memory capacity of a single NVIDIA A100 GPU with 80 GB RAM, even when using reduced precision 8-bit mode, which requires approximately 45 GB RAM.
By using 4-bit precision loading with the latest versions of bitsandbytes, transformers, and accelerate libraries, the memory footprint can be reduced to around 27 GB RAM. This allows Falcon-40B to be loaded into the 40 GB A100 GPUs.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-40b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
trust_remote_code=True,
device_map="auto",
)
prompt = "What are the main benefits of enrolling in a DataCamp career track?"
sequences = pipeline(
prompt,
max_length=100,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")Loading Falcon 40B and running inference with 4-bit quantization is not possible on consumer GPUs. Therefore, we will use the smaller version of the Falcon 7B model, which can be easily run on the free version of Google Colab.
We will install all of the necessary Python libraries.
%pip install transformers bitsandbytes accelerate -qAnd then load the necessary modules for loading the model and running the inference.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import transformers
import torchWe use BitsAndBytes to create a 4-bit quantization with NF4 type configuration. This reduces memory footprint, allowing us to load the model in Colab GPU. Read about 4-bit quantization and QLoRA.
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)We will load the Falcon 7B model and tokenizer and create a text generation pipeline using the Transformers library to run inference.
model_name = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
quantization_config=bnb_config,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)By providing the prompt to the pipeline, we can generate the response.
prompt = "What are the main benefits of enrolling in a DataCamp career track?"
sequences = pipeline(
prompt,
max_length=100,
do_sample=True,
top_k=20,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")Our result is impressive. You can experiment with different parameters in the pipeline to further improve the model's response.
Result: What are the main benefits of enrolling in a DataCamp career track? A: When you enroll in a DataCamp career track you have the opportunity to: - Build a solid foundation in one specific topic. - Learn new data science skills. - Gain valuable job search and interview prep tools. - Build a project portfolio that you can easily showcase to potential employers. - Network with thousands of like-minded people from diverse backgrounds.If you are facing difficulty running the Falcon 7B on Colab, you can use the Colab Notebook as a guide.
Using the TRL library with QLoRA, we can fine-tune the model. The following code is a part of the fine-tuning process and enables running the SFTTrainer without PEFT.
from datasets import load_dataset
from trl import SFTTrainer
dataset = load_dataset("timdettmers/openassistant-guanaco
", split="train")
trainer = SFTTrainer(
model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()You can check out the Falcon-Guanaco.ipynb notebook for the code to fine-tune Falcon-7B on Guanaco dataset. To train the model on the Guanaco dataset - a high-quality subset of the Open Assistant dataset containing approximately 10,000 dialogues - we can use the PEFT library along with the recent QLoRA approach to fine-tune adapters, which are placed on top of the frozen 4-bit model.
When using Low Rank Adapters (LoRA), only a tiny fraction of the model is trainable, resulting in a significant reduction in the number of learned parameters and the size of the trained artifact. This allows for faster fine-tuning of the model while conserving memory resources.
You can also skip the fine-tuning part and use Retrieval Augmented Generation (RAG) to personalize the response by providing access to your private documents. You can do that by following the LlamaIndex: A Data Framework for the Large Language Models (LLMs) based applications tutorial.
You can also Build LLM Applications with LangChain using your recently fine-tuned model similar to LlamaIndex.
Falcon-180B was trained on 3,500B tokens of the RefinedWeb dataset. It is a 180 billion parameters causal decoder-only model licensed under the Falcon-180B TII that outperforms LLaMA-2, StableLM, RedPajama, MPT, and other top models on OpenLLM Leaderboard.
The downside of the Falcon 180B model is that running inference requires at least 400GB of memory. In short, you need approximately 8xA100 80GB.
The positive aspect of this release is that TII has also launched Falcon-180B-Chat, which has been fine-tuned on a combination of Ultrachat, Platypus, and Airoboros datasets. It has gained significant popularity among the AI community. You can also try out the demo on Hugging Face Spaces and experience the high-quality response.
Image from Falcon-180B Demo
The Falcon 40B from TII demonstrates impressive performance as an open-source generative language model. With 40 billion parameters and trained on high-quality filtered web data, it achieves state-of-the-art results on OpenLLM Leaderboard.
While the full Falcon 40B model requires substantial compute resources, the smaller 7B version can run on free Colab GPUs using 4-bit quantization. Fine-tuning is possible through QLoRA, PEFT, and SFT Trainer. The new 180B Falcon version pushes performance even further, but it requires 400GB just to run the inference.
If you're interested in pursuing a career in machine learning and wish to build your own large language model, consider taking the Machine Learning Scientist with Python career track.
Start Your Machine Learning Journey Today!
programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev



