programa
Fundamentos de la IA
10 h
Los modelos básicos y profundos de aprendizaje por refuerzo (RL) a menudo pueden parecerse más a la IA de ciencia ficción que a cualquier gran modelo lingüístico actual. Veamos cómo RL permite a este agente completar un nivel muy difícil en Super Mario:

Al principio, el agente no tiene ni idea de cómo jugar a este juego. No conoce los controles, ni cómo progresar, ni cuáles son los obstáculos, ni qué finaliza el juego. El agente debe aprender todas estas cosas sin ninguna intervención humana, todo mediante el poder de los algoritmos de aprendizaje por refuerzo.
Los agentes de RL pueden resolver problemas sin soluciones predefinidas ni acciones programadas explícitamente y, lo que es más importante, sin grandes cantidades de datos. Por eso la RL está teniendo un impacto significativo en muchos campos. Por ejemplo, se utiliza en
El aprendizaje por refuerzo es un campo en rápida evolución con un enorme potencial. A medida que avance la investigación, podemos esperar aplicaciones aún más revolucionarias en áreas como la gestión de recursos, la asistencia sanitaria y el aprendizaje personalizado.
Por eso ahora es un buen momento para aprender sobre este fascinante campo del aprendizaje automático. En este tutorial, te ayudaremos a comprender los fundamentos del aprendizaje por refuerzo y te explicaremos paso a paso conceptos como agente, entorno, acción, estado, recompensas y mucho más.
Supongamos que quieres enseñar a tu gato Bob a utilizar varios rascadores en una habitación en lugar de tus caros muebles. En términos de aprendizaje por refuerzo, Bob es el agente, el que aprende y el que toma las decisiones. Tiene que aprender qué cosas puede arañar (alfombras y postes) y cuáles no (sofás y cortinas).
La sala se denomina entorno con el que interactúa nuestro agente. Proporciona retos (muebles tentadores) y el objetivo deseado (un rascador satisfactorio).
Hay dos tipos principales de entornos en la VR:
Nuestra habitación también es un entorno estático. Los muebles no se mueven, y los postes rascadores permanecen en su sitio.
Pero si mueves aleatoriamente los muebles y los postes rascadores cada pocas horas (como los distintos niveles del juego Super Mario), la habitación se convertiría en un entorno dinámico, que es más difícil de aprender para un agente porque las cosas cambian constantemente.
Dos aspectos importantes de todos los problemas de aprendizaje por refuerzo son el espacio de estados y el espacio de acciones.
El espacio de estados representa todos los estados (situaciones) posibles en los que se encuentran el agente y el entorno en un momento dado. El tamaño del espacio de estados depende del tipo de entorno:
El espacio de acción son todas las cosas que Bob puede hacer en el entorno. En nuestro ejemplo del poste rascador, las acciones de Bob podrían ser rascar el poste, echarse la siesta en el sofá o incluso perseguirse la cola.
De forma similar al espacio de estados, el número de acciones que puede realizar Bob depende del entorno:
Cuando Bob comienza su aventura en el rascador, el entorno se encuentra en un estado por defecto, llamémoslo estado cero. En nuestro caso, podría ser la habitación con el poste rascador instalado. Cada acción que realiza mueve el entorno a nuevos estados posteriores.
Para que Bob alcance su objetivo general, necesita incentivos o recompensas.
La mayoría de los problemas de RL tienen recompensas predefinidas. Por ejemplo, en el ajedrez, capturar una pieza es una recompensa positiva, mientras que recibir un jaque es una recompensa negativa.
En nuestro caso, podemos darle golosinas a Bob si observamos una acción positiva, como no arañar los muebles durante algún tiempo o si realmente encuentra uno de los postes rascadores. También podríamos castigarlo con algunos chorros de agua en la cara si araña las cortinas.
Para medir el progreso del viaje de aprendizaje de Bob, podemos pensar en sus acciones en términos de pasos temporales. Por ejemplo, en el paso de tiempo t1, Bob realiza la acción a1, que da lugar a un nuevo estado s1 (s0 era el estado por defecto). También puede recibir una recompensa r1.
Un conjunto de pasos temporales se denomina episodio. Un episodio comienza siempre en un estado por defecto (los muebles y los postes están colocados) y termina cuando se alcanza el objetivo (se encuentra un poste) o el agente falla (raya los muebles). A veces, un episodio también puede terminar en función del tiempo transcurrido (como en el ajedrez).
Como un hábil jugador de ajedrez, Bob no debe buscar cualquier rascador. Bob debe querer el que le proporcione las recompensas más gratificantes. Esto pone de manifiesto un dilema clásico en el aprendizaje por refuerzo: exploración frente a explotación.
Mientras que un puesto tentador puede ofrecer una gratificación inmediata, una exploración más estratégica podría conducir a un premio gordo más adelante. Al igual que un jugador de ajedrez puede renunciar a una captura para obtener una posición superior, Bob puede rascar inicialmente un puesto subóptimo (exploración) para descubrir el refugio definitivo para rascar (explotación). Esta estrategia a largo plazo es crucial para que los agentes maximicen las recompensas en entornos complejos.
En otras palabras, Bob debe equilibrar la explotación (ceñirse a lo que funciona mejor) con la exploración (aventurarse de vez en cuando a buscar nuevos rascadores). Explorar demasiado puede hacerte perder tiempo, sobre todo en entornos continuos, mientras que explotar demasiado puede hacer que Bob se pierda algo aún mejor.
Por suerte, Bob puede adoptar algunas estrategias inteligentes:
Utilizando estas estrategias (u otras que quedan fuera del alcance de nuestro tutorial), Bob puede encontrar un equilibrio entre explorar lo desconocido y ceñirse a lo bueno.
Bob no puede averiguar por sí mismo cómo maximizar el número de golosinas. Necesita unos métodos y herramientas que guíen sus decisiones en cada estado del entorno. Aquí es donde los algoritmos de aprendizaje por refuerzo acuden al rescate de Bob.
Desde una perspectiva más amplia, los algoritmos de aprendizaje por refuerzo pueden clasificarse en función de cómo hacen que los agentes interactúen con el entorno y aprendan de la experiencia. Las dos categorías principales de algoritmos de aprendizaje por refuerzo son los basados en modelos y los libres de modelos.
En los algoritmos basados en modelos, el agente (como Bob) construye un modelo interno del entorno. Este modelo representa la dinámica del entorno, incluidas las transiciones de estado y las probabilidades de recompensa. A continuación, el agente puede utilizar este modelo para planificar y evaluar distintas acciones antes de emprenderlas en el entorno real.
Este enfoque tiene la ventaja de ser más eficiente en cuanto a las muestras, sobre todo en entornos complejos. Esto significa que Bob podría necesitar menos intentos de rascado para identificar el poste óptimo en comparación con los enfoques puramente de ensayo y error. Y eso es porque Bob puede planificar y evaluar antes de pasar a la acción.
La desventaja es que construir un modelo preciso puede ser un reto, especialmente para entornos complejos. El modelo puede no reflejar con exactitud el entorno real, lo que conduce a un comportamiento subóptimo.
Un algoritmo común de RL basado en modelos es Dyna-Q, que en realidad combina el aprendizaje basado en modelos y el aprendizaje sin modelos. Construye un modelo del entorno y lo utiliza para planificar la acción, a la vez que aprende directamente de la experiencia mediante el aprendizaje Q sin modelo (que explicaremos dentro de un rato).
Este enfoque se centra en aprender directamente de la interacción con el entorno, sin construir explícitamente un modelo interno. El agente (Bob) aprende el valor de los estados y las acciones o la estrategia óptima mediante ensayo y error.
La RL sin modelo ofrece un enfoque más sencillo en entornos en los que construir un modelo preciso es un reto. Para Bob, esto significa que no necesita crear un complejo mapa mental de la habitación: puede aprender rascando y experimentando las consecuencias.
La RL sin modelos destaca en entornos dinámicos en los que las reglas pueden cambiar. Si cambia la disposición de los muebles de la habitación, Bob puede adaptar su exploración y aprender los nuevos lugares óptimos para arañar.
Sin embargo, sólo el aprendizaje por ensayo y error puede ser menos eficiente desde el punto de vista muestral. Puede que Bob tenga que rascar muchos muebles antes de encontrar sistemáticamente el puesto más gratificante.
Algunos algoritmos comunes de RL sin modelo son:
Qué algoritmo debemos elegir depende de varios factores: la complejidad del entorno, la disponibilidad de recursos o el nivel de interpretabilidad deseado.
Los enfoques basados en modelos pueden ser preferibles para entornos más sencillos en los que sea factible construir un modelo preciso. Por otra parte, los enfoques sin modelos suelen ser más prácticos para escenarios complejos del mundo real.
Además, con el auge del aprendizaje profundo, las redes Q profundas (DQN) y otros algoritmos de RL profunda son cada vez más populares para abordar tareas complejas con espacios de estado de alta dimensión.
Centrémonos ahora en un único algoritmo y aprendamos más sobre el aprendizaje Q.
El aprendizaje Q es un algoritmo sin modelos que enseña a los agentes la estrategia ganadora óptima mediante interacciones inteligentes con el entorno.
Volvamos a nuestro ejemplo del gato e imaginemos que estamos resolviendo una versión arcade del problema con un entorno discreto y un conjunto finito de acciones.
Supongamos que le damos a Bob una mesa. Las columnas representan las acciones disponibles, mientras que cada fila asigna la acción a un estado concreto del espacio de estados.
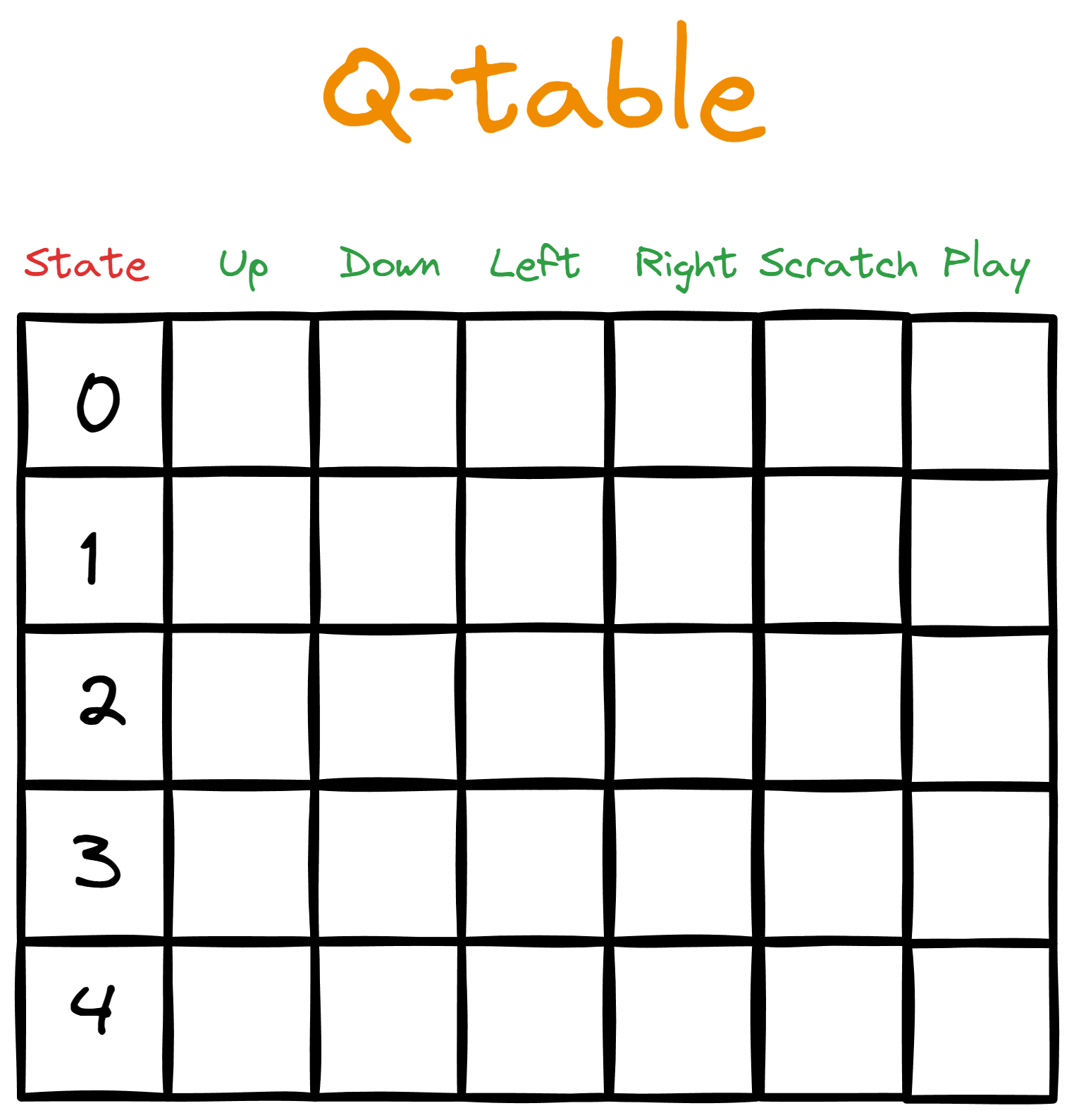
Al principio, llenamos la tabla con ceros, que representan los valores Qiniciales ;por eso la llamamos tabla Q.
A continuación, iniciamos un bucle de interacción desde el estado por defecto (el inicio de un episodio). En el bucle, Bob realiza la acción con el valor Q más alto para el estado dado. Sin embargo, en la primera pasada por el bucle, no habrá ningún valor Q más alto para guiar la acción de Bob, ya que todos los valores Q son inicialmente cero.
Aquí es donde entran en juego las estrategias de exploración (como la exploración aleatoria o la epsilon-greedy). Estas estrategias ayudan a Bob a reunir información cuando la tabla Q está vacía.
Una vez actualizada la tabla Q, Bob vuelve a iniciar un bucle de interacción. La acción que realiza da como resultado una recompensa y un nuevo estado. A continuación, calculamos nuevos valores Q para cada acción que Bob pueda realizar en el nuevo estado (dentro de un rato veremos cómo calcular los valores Q).
El episodio continúa hasta su finalización (Bob puede dar cualquier número de pasos en cada episodio), y entonces volvemos a empezar. Cada episodio posterior tendrá una tabla Q más rica, haciendo a Bob más inteligente.
Aquí tienes una visión general de los pasos que hay que dar:
Pasos como el uno y el dos pueden ser sencillos, pero el resto necesitan más explicación.
En el paso de tiempo 1, cuando Bob realice su primera acción, será aleatoria, ya que todos los valores Q son cero. En los siguientes pasos temporales, Bob tiene que considerar el equilibrio entre exploración y explotación.
Para ello, le damos a Bob un hiperparámetro llamado épsilon con un valor pequeño, normalmente 0,1. A continuación, le decimos a Bob que genere un número aleatorio entre 0 y 1 y, si el número es menor que épsilon, elegirá una acción aleatoria independientemente de su valor Q.
Si es mayor que épsilon, Bob elegirá la acción con el valor Q más alto. De este modo, Bob explorará épsilon (0,1 o 10%) del tiempo y explotará (1 - épsilon o 0,9 o 90%) del tiempo.
Lo que acabamos de describir se denomina política "epsilon-greedy". Las políticas definen cómo actúa el agente y cómo se calculan los valores Q.
Las reglas para calcular la recompensa las suele establecer la persona que crea el entorno. Por ejemplo, puedes decidir darle a Bob una sola golosina por usar una alfombra rascadora y cinco golosinas por saltar lo bastante alto para rascar la que está en la pared. También existe la posibilidad de que castigues a Bob por arañar objetos valiosos.
Pero la mayor parte del tiempo no habrá recompensa, ya que Bob dormirá, caminará o jugará.
La fórmula para calcular el valor Q puede resultar intimidatoria, así que veámosla primero en toda su extensión y luego la explicaremos paso a paso:

Consideremos el principio de la fórmula:
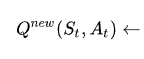
Esta parte dice: "Dado el estado y la acción anteriores, el nuevo valor Q se calcula como (...)".
La parte de abajo es el valor Q actual (pronto viejo) que el agente utilizó para realizar la acción.
![]()
Consideremos ahora la parte final:
![]()
St+1 es el nuevo estado resultante de realizar la acciónAt. Por tanto, esta parte consiste en encontrar el mayor valor Q de todas las acciones (a) en ese nuevo estado. Multiplicamos ese valor por un parámetro γ llamado gamma (factor de descuento) y sumamos el resultado a la recompensa recibida.
Si fijamos la gamma cerca de 1, damos más peso a las recompensas futuras. Si lo reducimos hacia cero, hacemos más hincapié en la recompensa actual Rt+1. Esto significa que gamma es otro parámetro que podemos utilizar para equilibrar la exploración y la explotación.
Por último, tenemos alfa (α), que controla la velocidad de entrenamiento y va de 0 a 1. Los valores cercanos a 1 hacen que las actualizaciones de los valores Q sean mayores, por lo que el agente aprende más rápido, haciendo que el lado derecho del signo más sea más pesado. Por el contrario, los valores próximos a 0 hacen más pesado el lado izquierdo, que contiene el valor Q actual.
Utilizar el ritmo de aprendizaje para controlar la velocidad de entrenamiento garantiza que el agente no progrese demasiado rápido y olvide la información antigua. También garantiza que no aprenda muy lentamente, con lo que posiblemente se pierda información importante.
Ésta es la parte más difícil de entender del aprendizaje Q, y espero que te hayas hecho una idea aproximada de cómo funciona.
Como en todo, Python tiene marcos para resolver problemas de aprendizaje por refuerzo. El más popular es Gymnasium, que viene preconstruido con más de 2000 entornos (todos ellos documentados exhaustivamente).
$ pip install "gymnasium[atari]"
$ pip install autorom[accept-rom-license]
$ AutoROM --accept-license
import gymnasium as gym
env = gym.make("ALE/Breakout-v5")El entorno que acabamos de cargar se llama Breakout. Esto es lo que parece:

El objetivo aquí es que el tablero (el agente) aprenda a eliminar todos los ladrillos mediante ensayo y error. Las reglas del juego dictan las penalizaciones y las recompensas.
Terminaremos el artículo mostrando cómo puedes ejecutar tus propios episodios de interacción y visualizar el progreso del agente con un GIF como el de arriba.
Aquí tienes el código del bucle de interacción:
epochs = 0
frames = [] # for animation
done = False
env = gym.make("ALE/Breakout-v5", render_mode="rgb_array")
observation, info = env.reset()
while not done:
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
# Put each rendered frame into dict for animation
frames.append(
{
"frame": env.render(),
"state": observation,
"action": action,
"reward": reward,
}
)
epochs += 1
if epochs == 1000:
breakAcabamos de ejecutar mil pasos temporales, o lo que es lo mismo, el agente ha realizado 1000 acciones. Sin embargo, todas estas acciones son puramente aleatorias: no se aprende de los errores del pasado. Para comprobarlo, podemos utilizar la variable fotogramas para crear un GIF:
from moviepy.editor import ImageSequenceClip
# !pip install moviepy - if you don’t have moviepy
def create_gif(frames: dict, filename, fps=100):
"""
Creates a GIF animation from a list of RGBA NumPy arrays.
Args:
frames: A list of RGBA NumPy arrays representing the animation frames.
filename: The output filename for the GIF animation.
fps: The frames per second of the animation (default: 10).
"""
rgba_frames = [frame["frame"] for frame in frames]
clip = ImageSequenceClip(rgba_frames, fps=fps)
clip.write_gif(filename, fps=fps)
# Example usage
create_gif(frames, "animation.gif") #saves the GIF locally
Nota: Si te encuentras con un "RuntimeError: No se ha podido encontrar el error "ffmpeg exe", prueba a añadir las dos líneas de código siguientes antes de importar moviepy:
from moviepy.config import change_settings
change_settings({"FFMPEG_BINARY": "/usr/bin/ffmpeg"})Nuestro primer fragmento devolvía el estado del entorno como matrices RGBA para cada paso temporal, y se almacenan en fotogramas. Juntando todos los fotogramas mediante la biblioteca moviepy, podemos crear el GIF que has visto antes:

Como nota al margen, puedes ajustar el parámetro fps para que el GIF sea más rápido si ejecutas muchos pasos de tiempo.
Ahora que vemos que el agente simplemente realiza acciones aleatorias, es hora de probar algunos algoritmos. Puedes hacerlo paso a paso en este curso sobre Aprendizaje por Refuerzo con Gimnasio en Python, donde explorarás muchos algoritmos, como Q-learning, SARSA y otros.
Asegúrate de utilizar la función que acabamos de crear para animar el progreso de tus agentes, ¡y diviértete!
El aprendizaje por refuerzo es una de las cosas más intrigantes de la informática y el aprendizaje automático. En este tutorial, hemos aprendido los conceptos fundamentales de la RL, desde agentes y entornos hasta algoritmos sin modelos como el aprendizaje Q.
Sin embargo, crear agentes de talla mundial capaces de resolver problemas complejos como el ajedrez o los videojuegos llevará tiempo y práctica. Por ello, aquí tienes algunos recursos que pueden ayudarte en el camino:
¡Gracias por leer!
Más información sobre la IA y el aprendizaje por refuerzo
programa
Curso
Curso
blog
Zoumana Keita
14 min
Tutorial
Abid Ali Awan
Tutorial
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Avinash Navlani

