
programa
Fundamentos del negocio de la IA
12 h
El uso de modelos de lenguaje grandes (LLM) en sistemas locales es cada vez más popular gracias a la mejora de la privacidad, el control y la fiabilidad que ofrecen. A veces, estos modelos pueden ser incluso más precisos y rápidos que chatGPT.
Mostraremos siete formas de ejecutar LLM localmente con aceleración GPU en Windows 11, pero los métodos que describimos también funcionan en macOS y Linux.
Si quieres aprender sobre los LLM desde cero, un buen punto de partida es este curso sobre modelos de aprendizaje grandes (LLM).
Comencemos por explorar nuestro primer marco LLM.
Ollama es el ecosistema dominante para ejecutar LLM como Llama 4, Mistral 3y Gemma 3 a nivel local.
Además, múltiples aplicaciones aceptan una integración con Ollama, lo que la convierte en una herramienta excelente para acceder de forma más rápida y sencilla a los modelos lingüísticos en tu equipo local.
Ollama ahora ofrece compatibilidad total con la API de OpenAI, lo que lo convierte en un sustituto directo del servicio en la nube de OpenAI. Las características recientes incluyen llamadas a funciones, salida JSON estructurada, Flash Attention para modelos de visión y una inferencia un 30 % más rápida en Apple Silicon y GPU AMD.
Podéis descargar Ollama desde la página de descargas.
Una vez que lo instalemos (utilizando la configuración predeterminada), el logotipo de Ollama aparecerá en la bandeja del sistema.
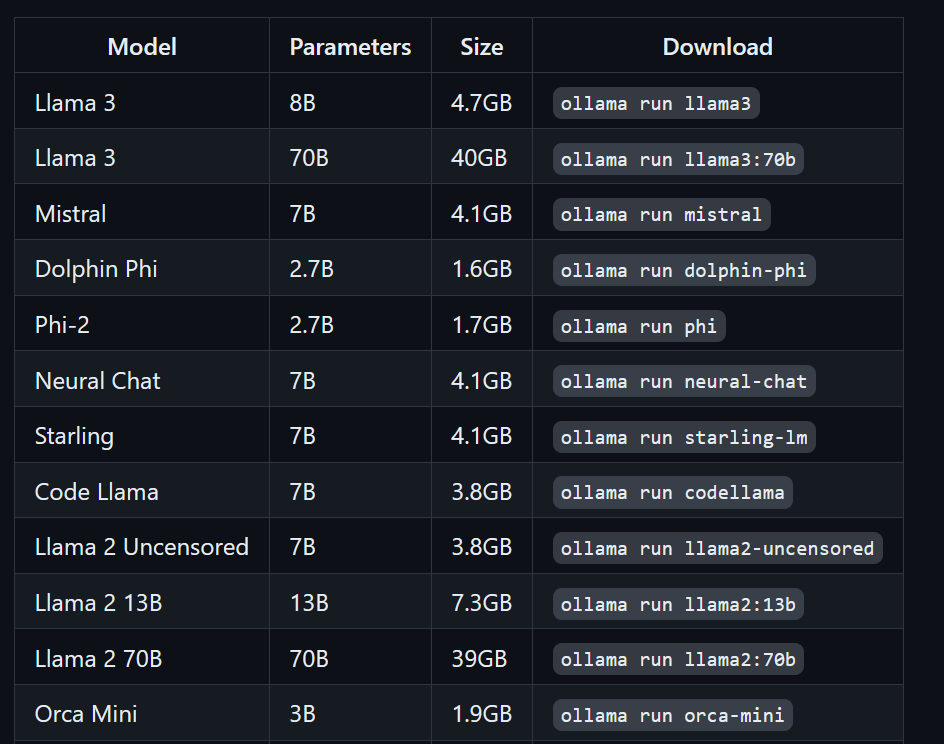
Podemos descargar el modelo Llama 3 escribiendo el siguiente comando en la terminal:
$ ollama run llama3¡Llama 3 ya está listo para usar! A continuación, vemos una lista de comandos que debéis usar si queréis utilizar otros LLM:
Para acceder a los modelos que ya se han descargado y están disponibles en la carpeta llama.cpp, hay que hacer lo siguiente:
cd ».$ cd C:/Repository/GitHub/llama.cppModelfile y añade la línea "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf".$ echo "FROM ./Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf" > Modelfile$ ollama create NHM-7b -f Modelfile
$ ollama run NHM-7bCon este método, podemos descargar cualquier LLM de Hugging Face con la extensión .gguf y utilizarlo en la terminal. Si deseas obtener más información, consulta este curso sobre cómo trabajar con Hugging Face.
LM Studio es un banco de trabajo todo en uno para ejecutar LLM localmente y ofrece ajuste fino de forma nativa. Además, admite múltiples modelos simultáneos, decodificación especulativa (tokens entre 1,5 y 3 veces más rápidos) e integración de RAG de documentos.
Podemos descargar el instalador desde la página de inicio de LM Studio.
Una vez completada la descarga, instalamos la aplicación con las opciones predeterminadas.
¡Por fin lanzamos LM Studio!
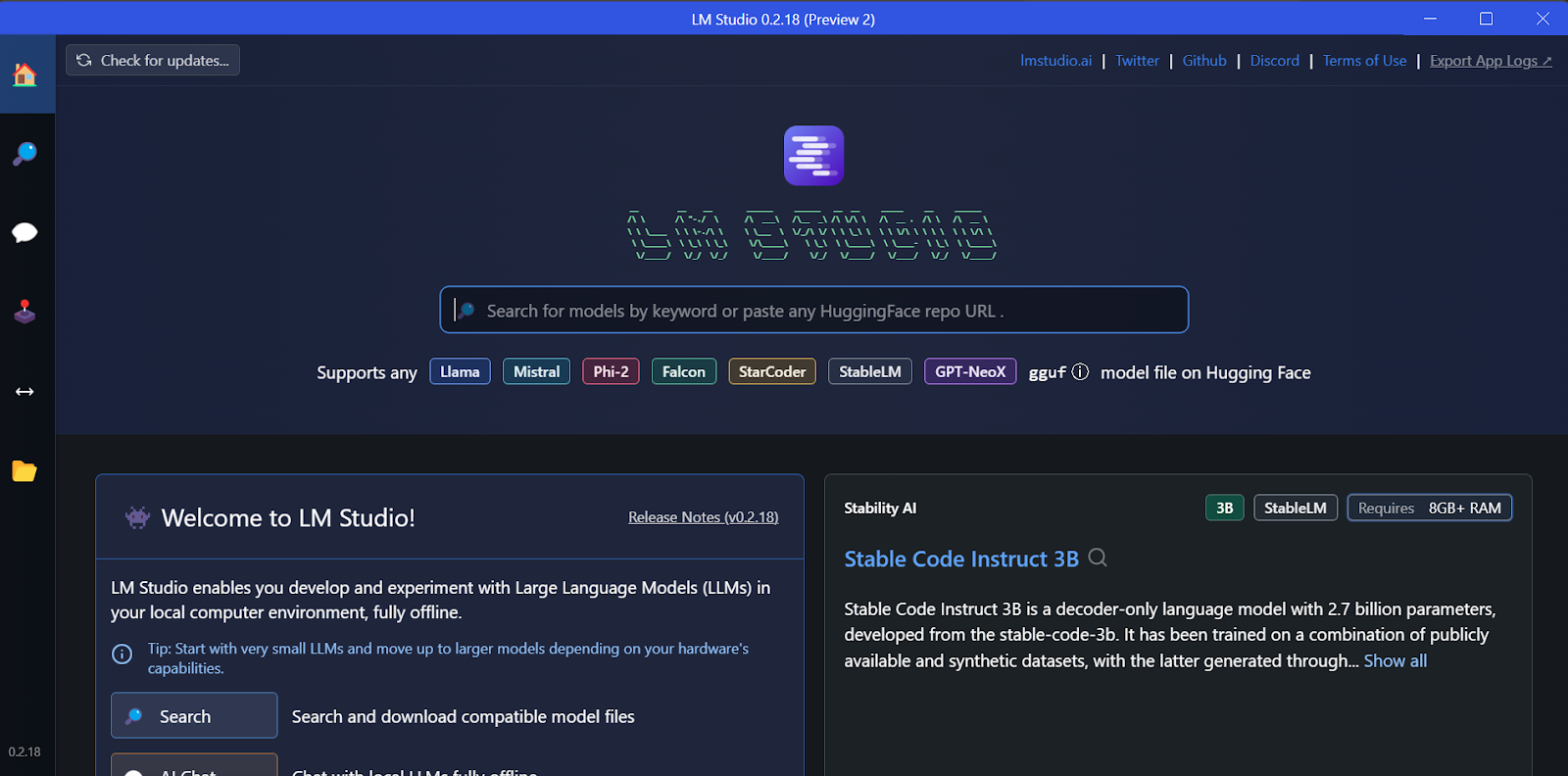
Podemos descargar cualquier modelo de Hugging Face utilizando la función de búsqueda.
En nuestro caso, descargaremos el modelo más pequeño, Gemma 2B Instruct de Google.
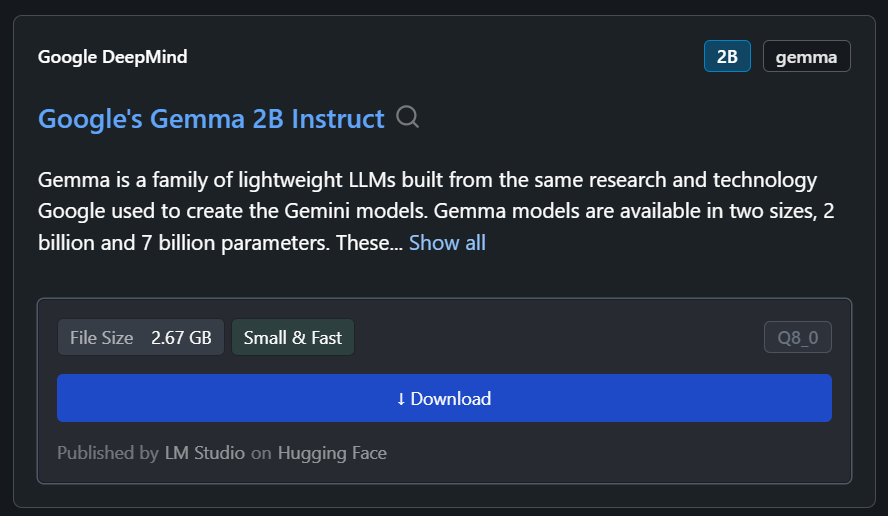
Podemos seleccionar el modelo descargado en el menú desplegable de la parte superior y chatear con él como de costumbre. LM Studio ofrece más opciones de personalización que GPT4All.
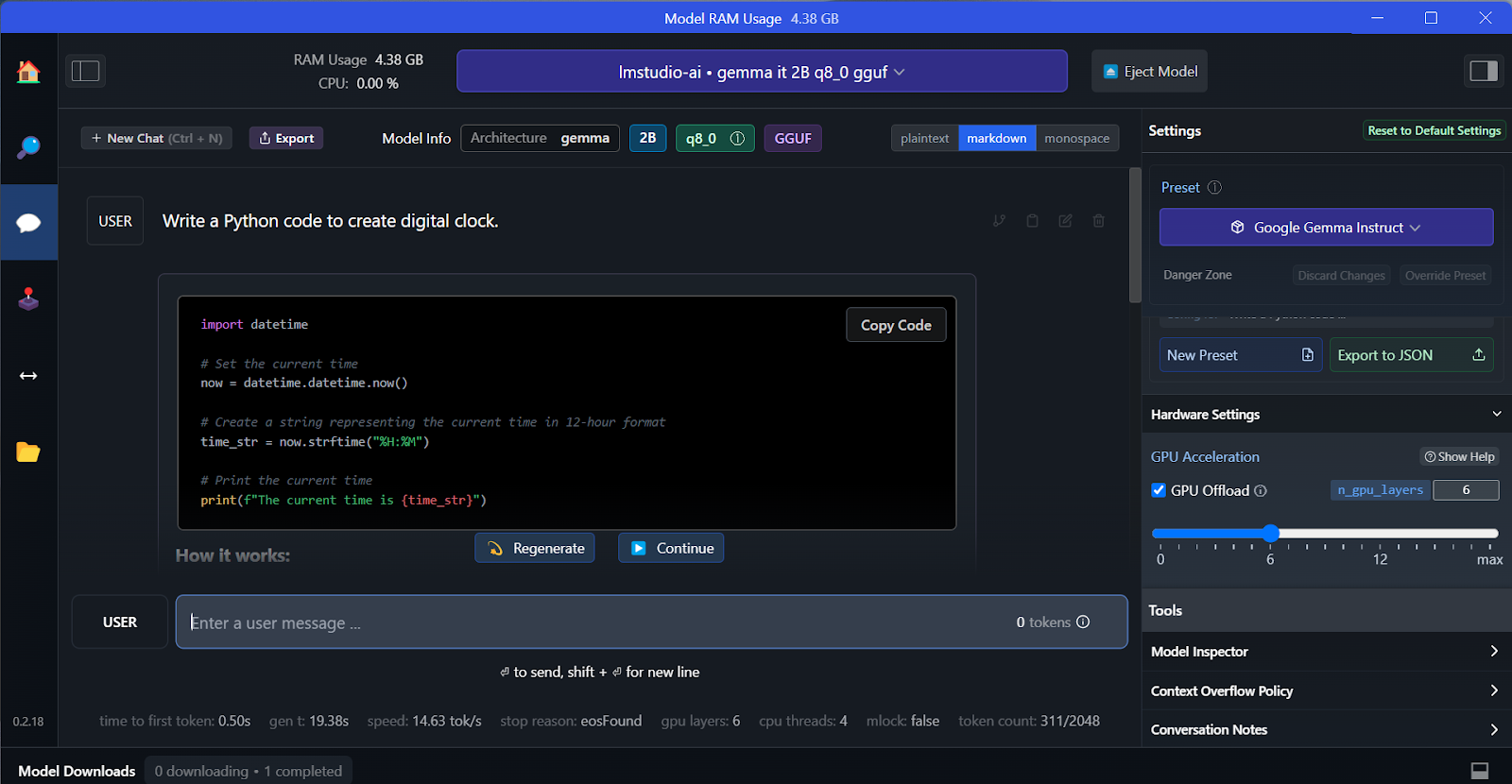
Al igual que GPT4All, podemos personalizar el modelo y lanzar el servidor API con un solo clic. Para acceder al modelo, podemos utilizar el paquete Python de la API de OpenAI, CURL, o integrarlo directamente con cualquier aplicación.
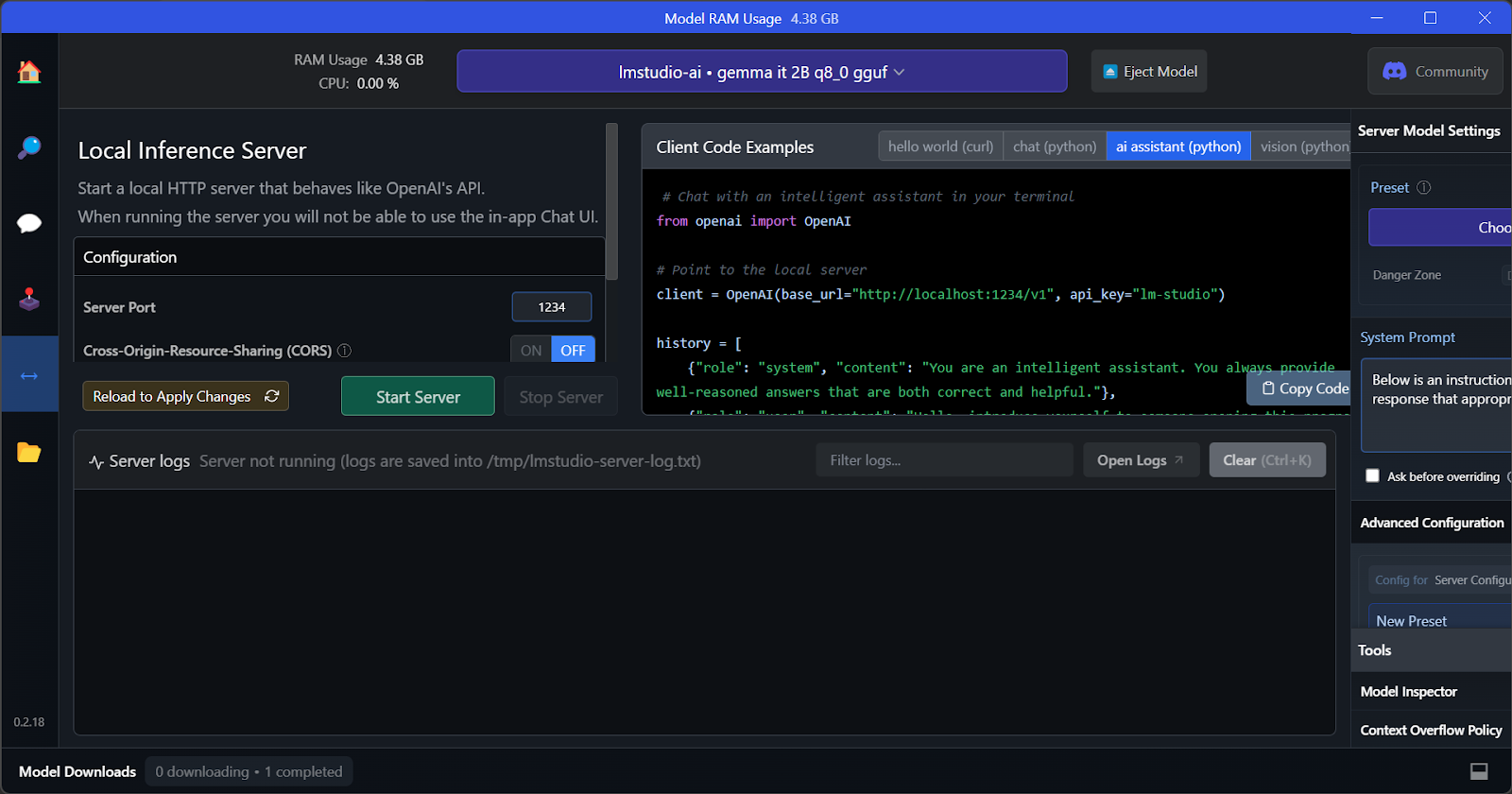
La característica clave de LM Studio es que ofrece la opción de ejecutar y servir varios modelos a la vez. Esto permite a los usuarios comparar los resultados de diferentes modelos y utilizarlos para múltiples aplicaciones. Para ejecutar varias sesiones de modelos, necesitamos una GPU con mucha memoria VRAM.
El ajuste fino es otra forma de generar respuestas personalizadas y sensibles al contexto. Puedes aprender a ajustar tu modelo Google Gemma siguiendo el tutorial « » (Ajustar Google Gemma): Mejora de los modelos de lenguaje grande (LLM) con instrucciones personalizadas. Aprenderás a ejecutar inferencias en GPU/TPU y a ajustar el último modelo Gemma 7b-it en un conjunto de datos de juegos de rol.
vLLM es un motor de inferencia de código abierto para ejecutar LLM a escala de producción. A diferencia de Ollama o LM Studio, vLLM prioriza el rendimiento y la latencia para escenarios multiusuario.
Su innovación principal es PagedAttention, que gestiona la memoria de la GPU como si fuera memoria virtual, reutilizando páginas pequeñas en lugar de reservar bloques masivos, combinado con el procesamiento por lotes continuo. Las pruebas de rendimiento reales muestran que vLLM ofrece 793 tokens por segundo en Llama 70B, frente a los 41 tokens por segundo de Ollama bajo carga simultánea.
vLLM también admite el paralelismo tensorial entre GPU, el almacenamiento en caché de prefijos y el procesamiento por lotes multi-LoRA para servir variantes ajustadas simultáneamente.
En Mac y Linux, vLLM se puede instalar fácilmente utilizando pip.
En Linux con CUDA 11.8+:
pip install vllmEn macOS con Apple Silicon:
python3.11 -m venv vllm_env
source vllm_env/bin/activate
pip install vllmPor el momento no hay soporte oficial para Windows. Sin embargo, existen soluciones alternativas a través de WSL2 o Docker.
Inicia el servidor compatible con OpenAI:
vllm serve meta-llama/Llama-2-7b-hf --port 8000 --gpu-memory-utilization 0.9Para modelos 70B con múltiples GPU:
vllm serve meta-llama/Llama-2-70b-hf --tensor-parallel-size 2 --port 8000Para el procesamiento por lotes en Python:
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-hf", dtype="bfloat16")
sampling_params = SamplingParams(temperature=0.8, max_tokens=256)
outputs = llm.generate(["Write hello world", "Explain AI"], sampling_params)Para realizar consultas, utiliza el SDK de OpenAI:
from openai import OpenAI
client = OpenAI(base_url='http://localhost:8000/v1', api_key='any')
response = client.chat.completions.create(
model='meta-llama/Llama-2-7b-hf',
messages=[{'role': 'user', 'content': 'What is ML?'}],
max_tokens=200
)
print(response.choices[0].message.content)Otra opción es ejecutarlo mediante cURL:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "meta-llama/Llama-2-7b-hf", "messages": [{"role": "user", "content": "Hello"}]}'Elige vLLM para las API de producción que prestan servicio a cientos de usuarios simultáneos; utiliza Ollama para el desarrollo local.
Una de las aplicaciones LLM locales más populares y atractivas es Jan. Es una alternativa a chatGPT que prioriza la privacidad.
Podemos descargar el instalador desde Jan.ai.
Una vez que instalamos la aplicación Jan con la configuración predeterminada, estamos listos para ejecutar la aplicación.
Cuando hablamos de GPT4All y LM Studio, ya descargamos dos modelos. En lugar de descargar otro, importaremos los que ya tenemos yendo a la página del modelo y haciendo clic en el botón Importar modelo.
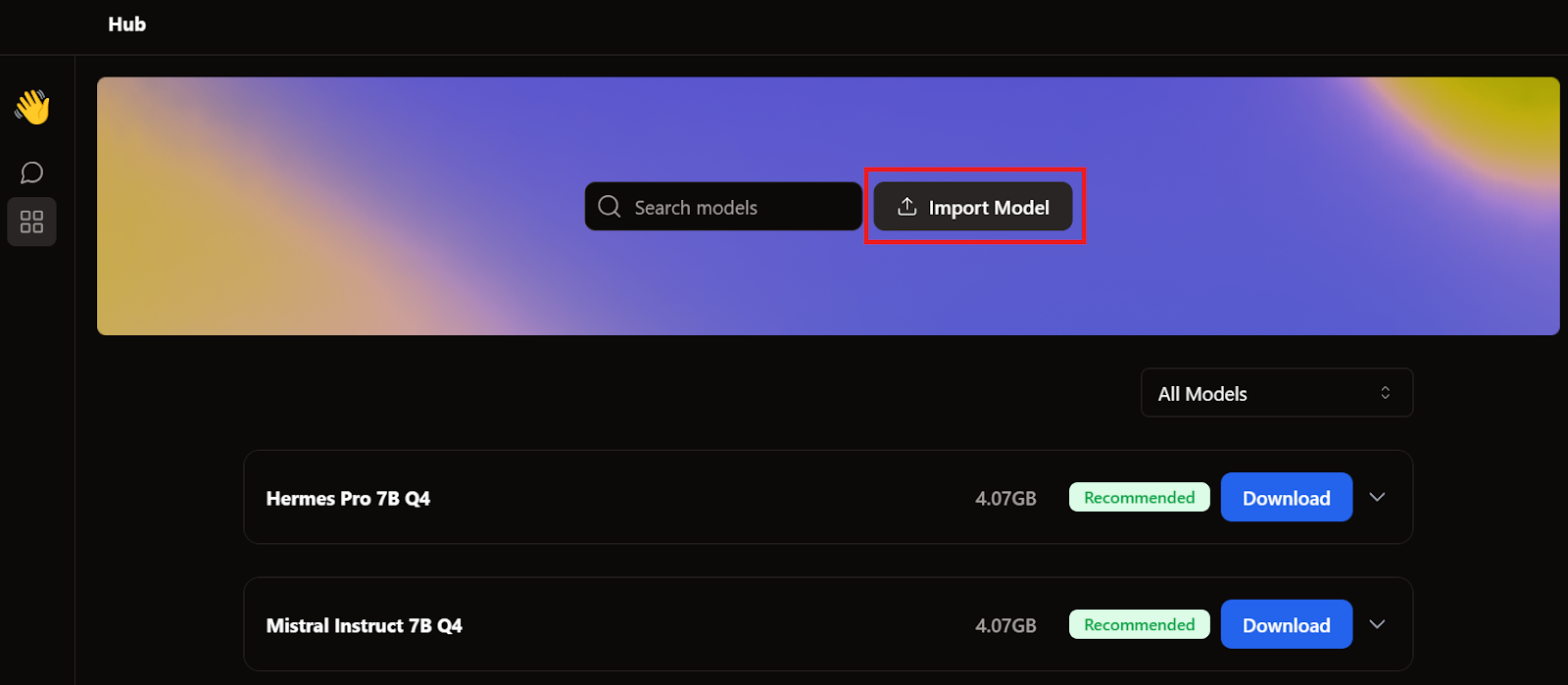
A continuación, vamos al directorio de aplicaciones, seleccionamos los modelos GPT4All y LM Studio, y los importamos.
Para acceder a los modelos locales, vamos a la interfaz de usuario del chat y abrimos la sección de modelos en el panel derecho.
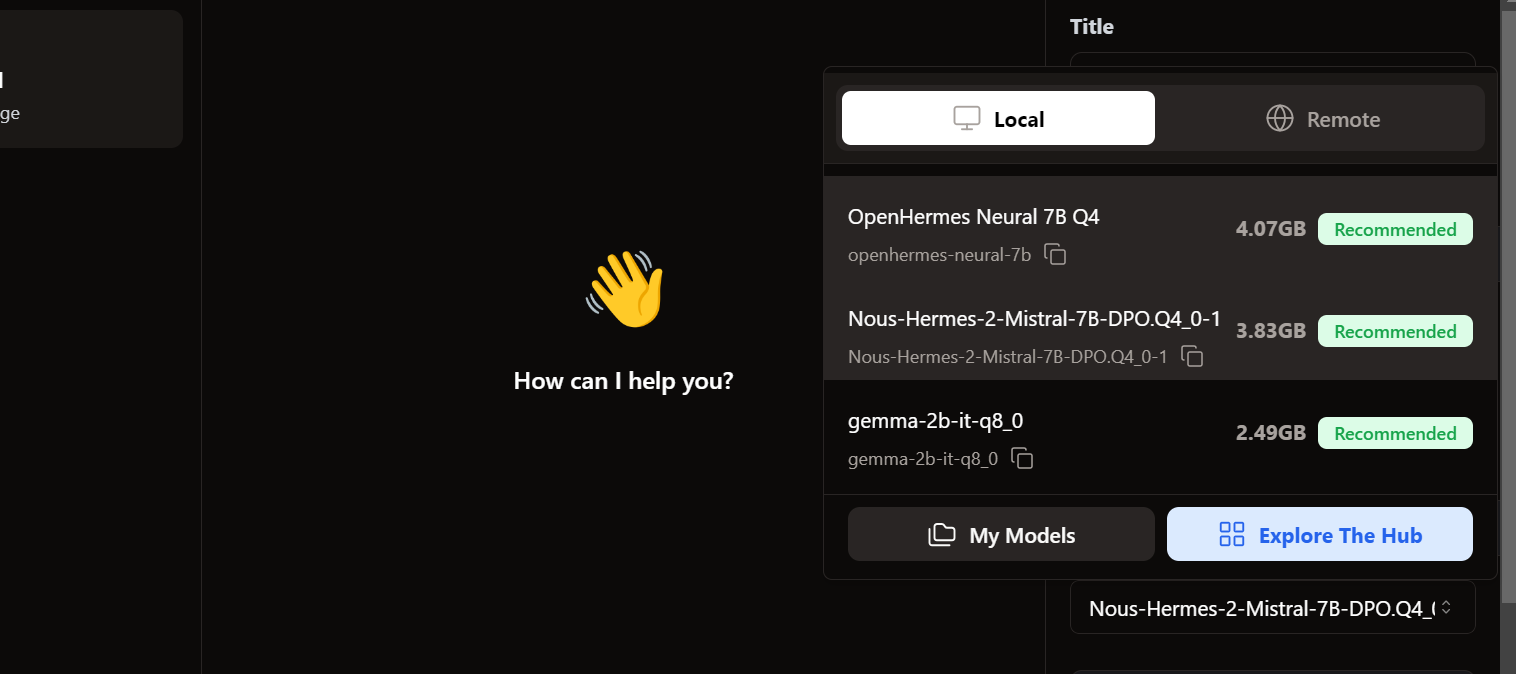
Vemos que vuestros modelos importados ya están ahí. ¡Podemos seleccionar el que queramos y empezar a utilizarlo inmediatamente!
La generación de respuestas es muy rápida. La interfaz de usuario resulta natural, similar a chatGPT, y no ralentiza tu ordenador portátil o PC.
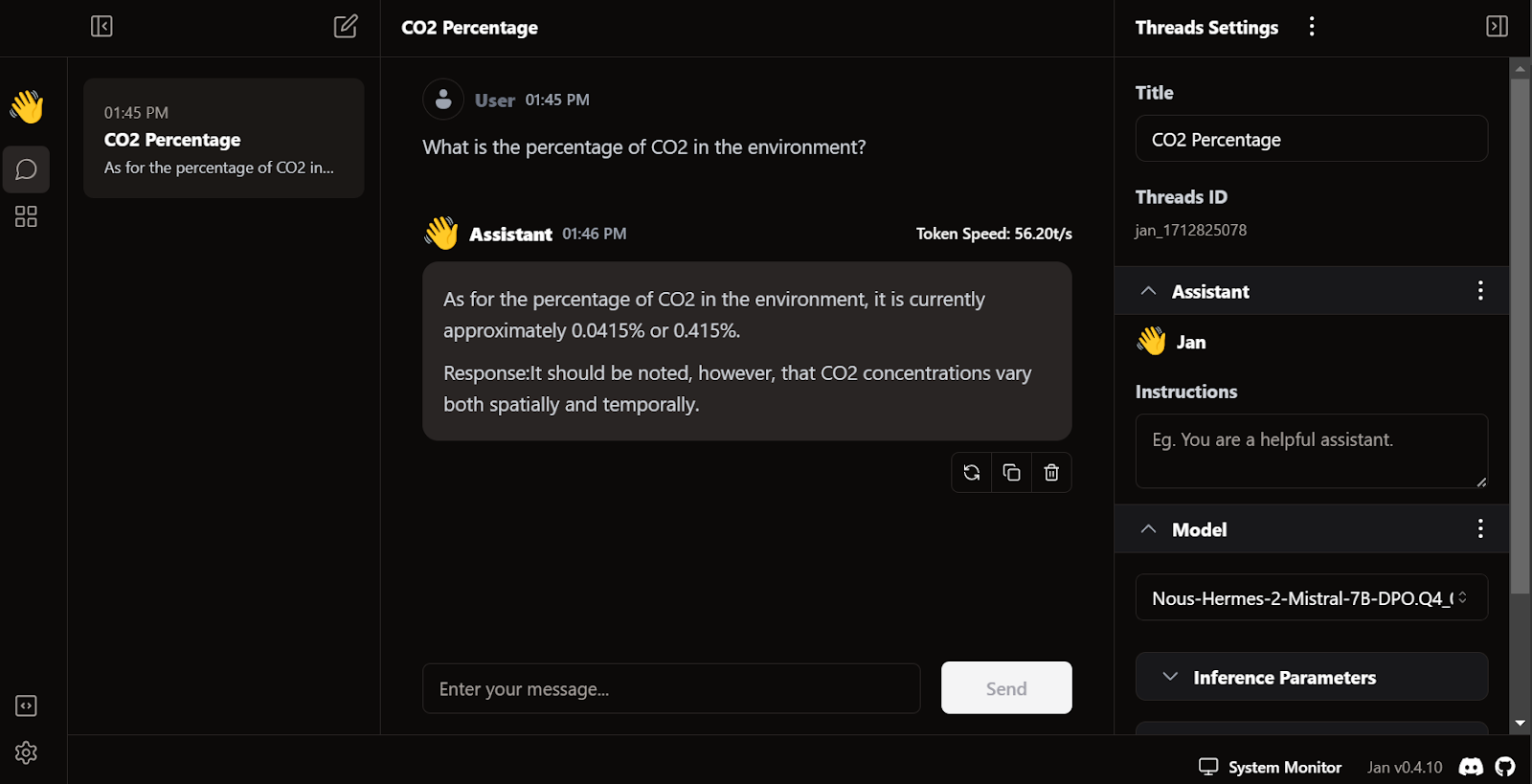
La característica única de Jan es que nos permite instalar extensiones y utilizar modelos propietarios de OpenAI, MistralAI, Groq, TensorRT y Triton RT.
Al igual que LM Studio, también podemos utilizar Jan como servidor API local. Ofrece más capacidades de registro y control sobre la respuesta del LLM, e integra OpenAI, Mistral AI, Groq, Claude y DeepSeek mediante una sencilla configuración de la clave API en los ajustes.
Otro marco LLM de código abierto muy popular es llama.cpp. Está escrito íntegramente en C/C++, lo que lo hace rápido y eficiente.
Muchas aplicaciones locales y basadas en la web de inteligencia artificial se basan en llama.cpp. Por lo tanto, aprender a utilizarlo localmente te dará una ventaja a la hora de comprender cómo funcionan otras aplicaciones LLM entre bastidores.
Primero, debemos ir al directorio de nuestro proyecto utilizando el comando « cd » en el terminal. Puedes obtener más información sobre el terminal en este curso Introducción al terminal.
A continuación, clonamos todos los archivos del servidor GitHub utilizando el siguiente comando:
$ git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitLa herramienta de línea de comandos make está disponible de forma predeterminada en Linux y MacOS. Sin embargo, en Windows, hay que seguir los siguientes pasos:
$ cd C:/Repository/GitHub/llama.cpp » para acceder a la carpeta llama.cpp.$ make y pulsa Intro para instalar llama.cpp.
Una vez completada la instalación, ejecutamos el servidor de interfaz de usuario web llama.cpp escribiendo el siguiente comando. (Nota: Hemos copiado el archivo del modelo de la carpeta GPT4All a la carpeta llama.cpp para poder acceder fácilmente al modelo.
$ ./server -m Nous-Hermes-2-Mistral-7B-DPO.Q4_0.gguf -ngl 27 -c 2048 --port 6589
El servidor web está funcionando en http://127.0.0.1:6589/. Puedes copiar esta URL y pegarla en tu navegador para acceder a la interfaz web llama.cpp.
Antes de interactuar con el chatbot, debemos modificar la configuración y los parámetros del modelo.
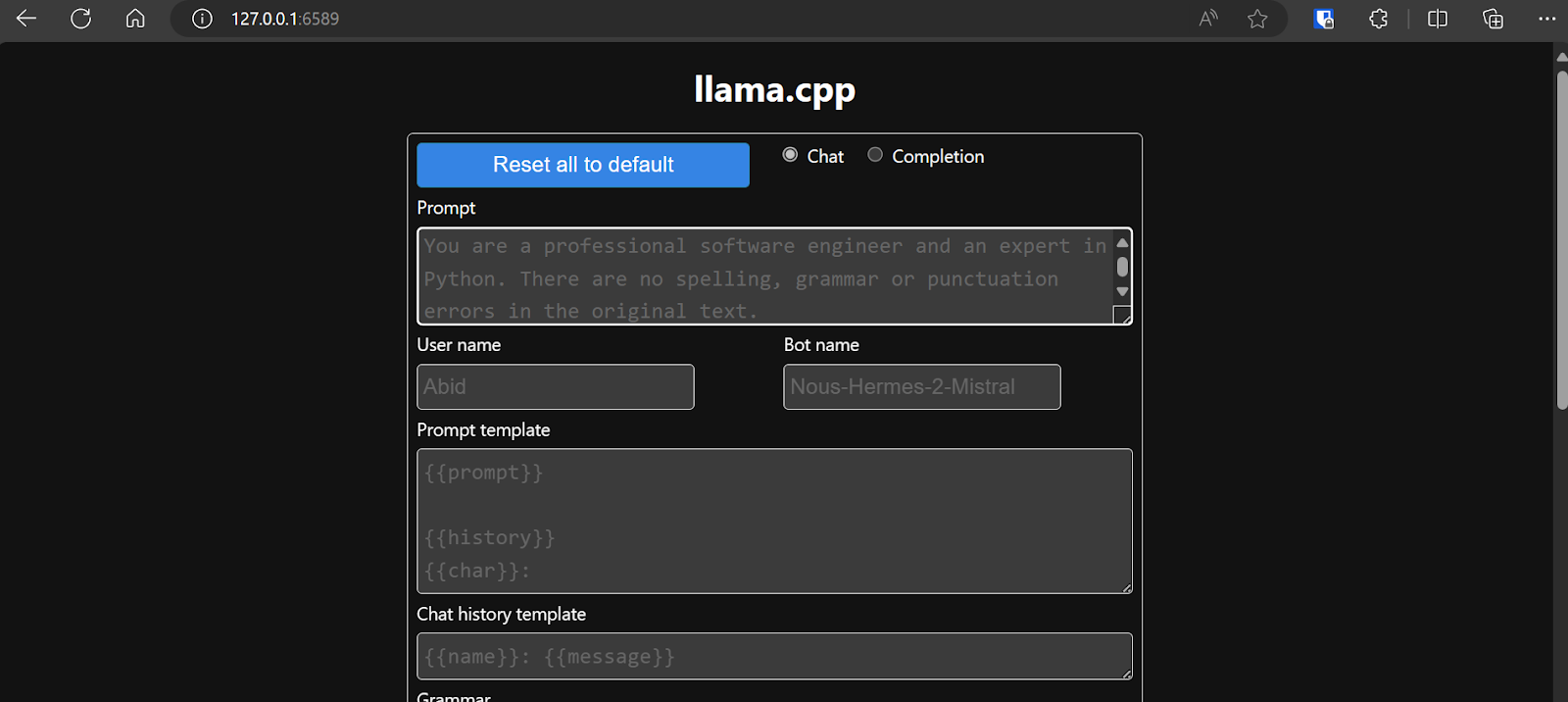 ¡Echa un vistazo a este tutorial de llama.cpp si deseas obtener más información!
¡Echa un vistazo a este tutorial de llama.cpp si deseas obtener más información!
La generación de respuestas es lenta porque la ejecutamos en la CPU, no en la GPU. Debemos instalar una versión diferente de llama.cpp para ejecutarlo en la GPU.
$ make LLAMA_CUDA=1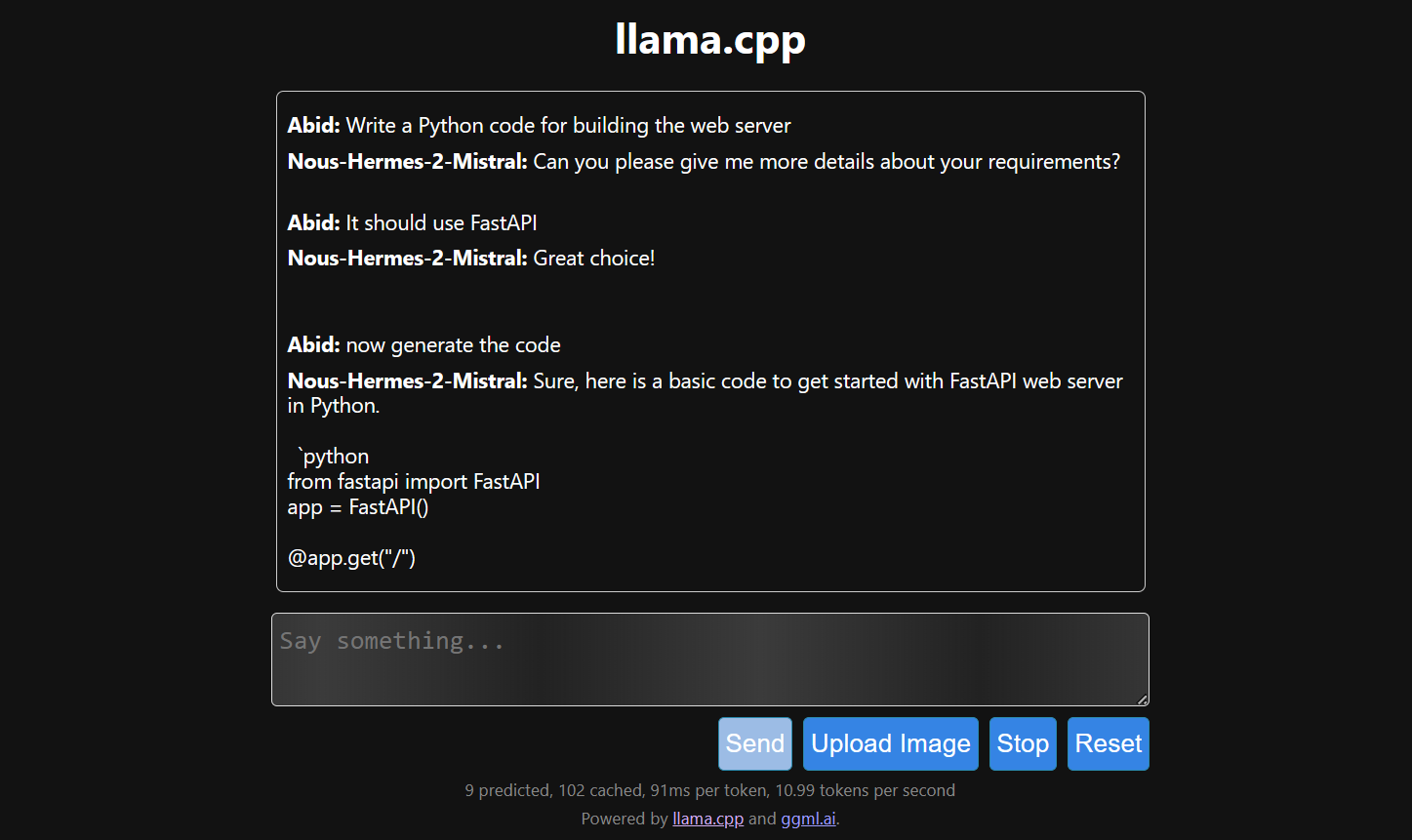
Si te parece que llama.cpp es demasiado complejo, prueba con llamafile. Este marco simplifica los LLM tanto para los programadores como para los usuarios finales al combinar llama.cpp con Cosmopolitan Libc en un único archivo ejecutable. Elimina todas las complejidades asociadas a los LLM, haciéndolos más accesibles.
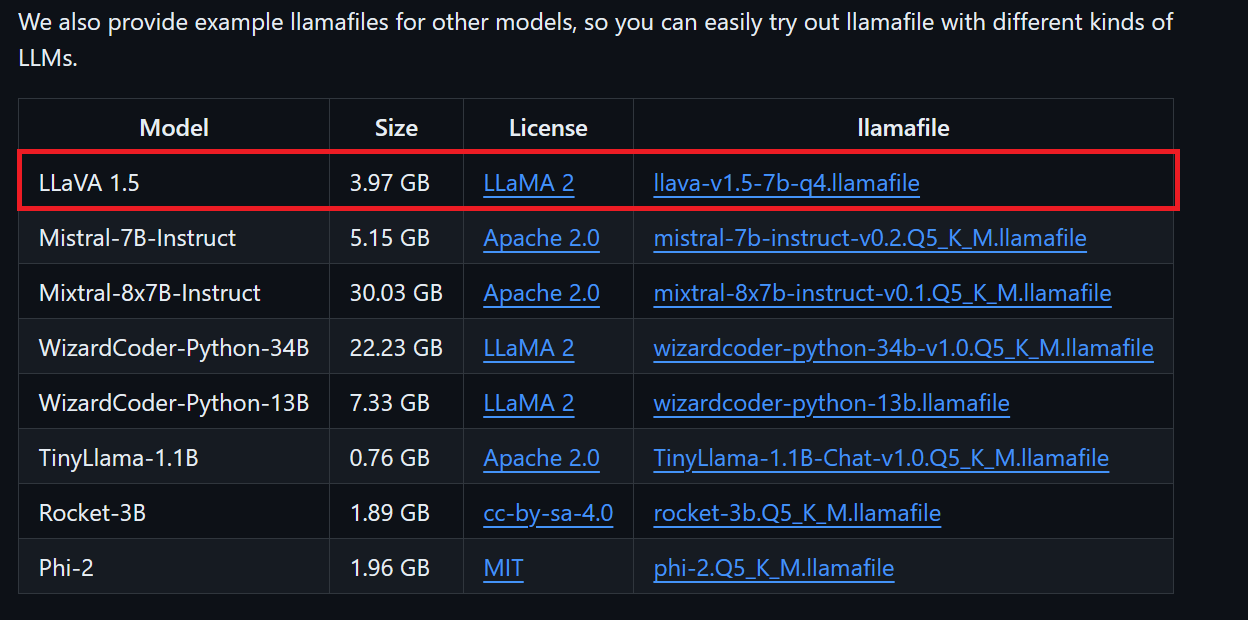
Podemos descargar el archivo del modelo que queramos desde el repositorio GitHub de llamafile.
Descargaremos LLaVA 1.5 porque también puede entender imágenes.
Los usuarios de Windows deben añadir .exe a los nombres de los archivos en el terminal. Para ello, haz clic con el botón derecho del ratón en el archivo descargado y selecciona Renombrar.

Primero vamos al directorio llamafile utilizando el comando « cd » en la terminal. A continuación, ejecutamos el siguiente comando para iniciar el servidor web llama.cpp.
$ ./llava-v1.5-7b-q4.llamafile -ngl 9999El servidor web utiliza la GPU sin necesidad de instalar ni configurar nada.
También se iniciará automáticamente el navegador web predeterminado con la aplicación web llama.cpp en ejecución. Si no es así, podemos utilizar la URL http://127.0.0.1:8080/ para acceder directamente.
Una vez que hayamos decidido la configuración del modelo, podremos empezar a utilizar la aplicación web.
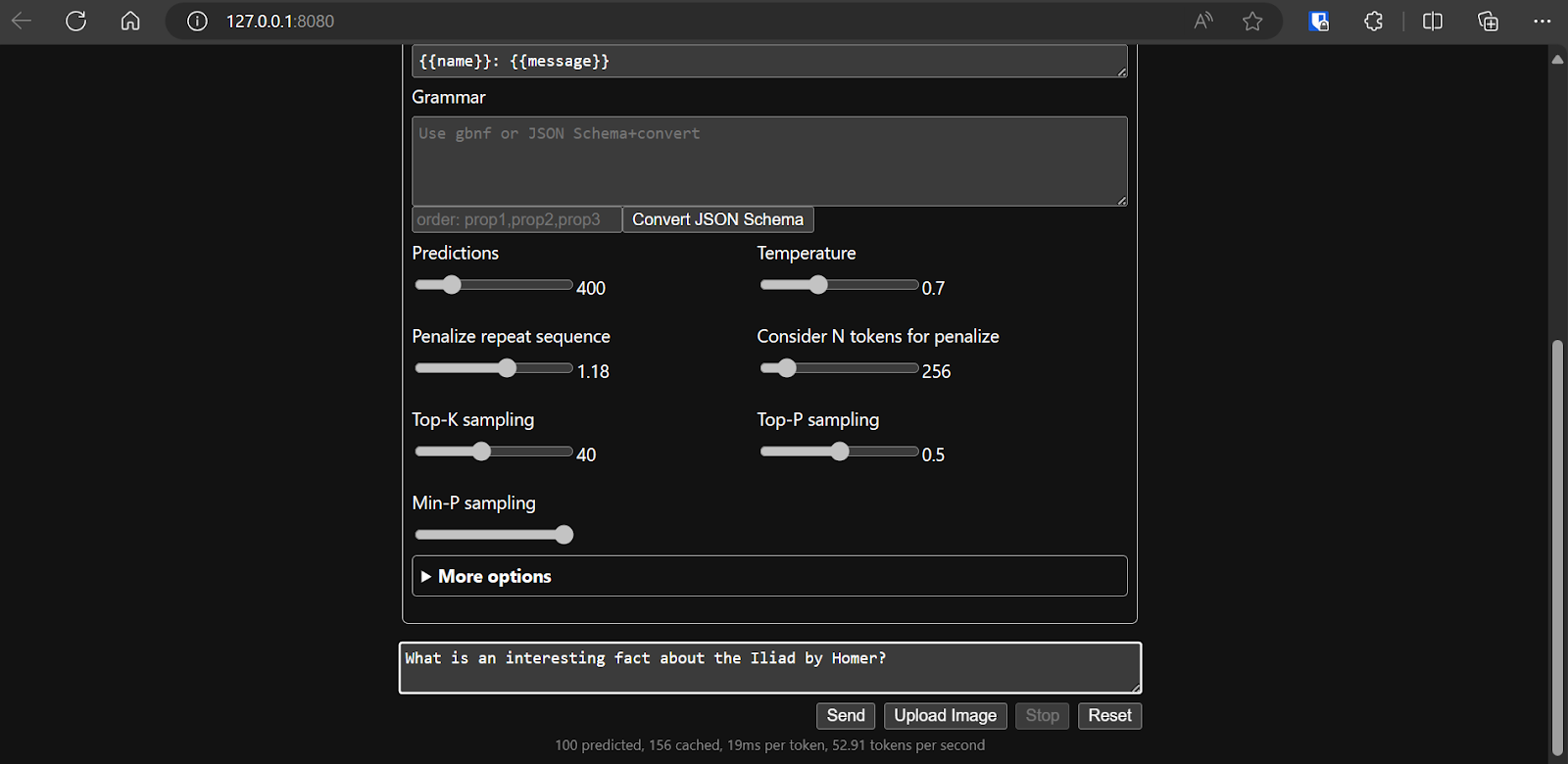
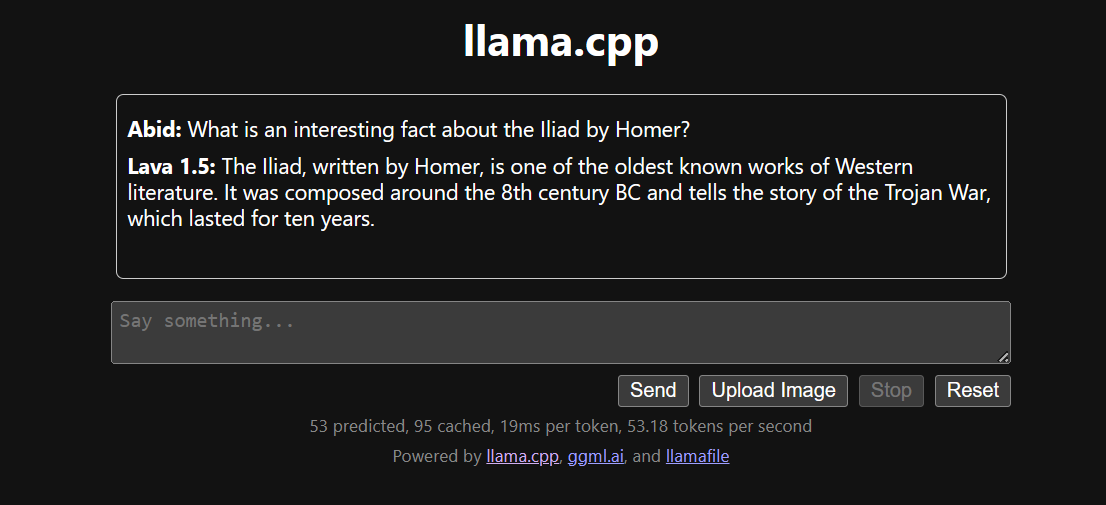
Ejecutar llama.cpp utilizando llamafile es más fácil y eficiente. Generamos la respuesta con 53,18 tokens/segundo (sin llamafile, la velocidad era de 10,99 tokens/segundo).
Instalar y utilizar los LLM de forma local puede ser una experiencia divertida y emocionante. Podemos experimentar con los últimos modelos de código abierto por nuestra cuenta, disfrutar de privacidad, control y una experiencia de chat mejorada.
El uso local de los LLM también tiene aplicaciones prácticas, como su integración con otras aplicaciones mediante servidores API y la conexión de carpetas locales para proporcionar respuestas contextuales. En algunos casos, es esencial utilizar los LLM de forma local, especialmente cuando la privacidad y la seguridad son factores críticos.
Puedes obtener más información sobre los LLM y la creación de aplicaciones de IA consultando los siguientes recursos:
¡Desarrolla tu carrera en IA con DataCamp!
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Ryan Ong
Tutorial
Abid Ali Awan


