
Course
Retrieval Augmented Generation (RAG) with LangChain
3 hr
18K
To better demonstrate what RAG is and how the technique works, let’s consider a scenario that many businesses today face.
Imagine you are an executive for an electronics company that sells devices like smartphones and laptops. You want to create a customer support chatbot for your company to answer user queries related to product specifications, troubleshooting, warranty information, and more.
You’d like to use an LLM to power your chatbot. However, as I already hinted at, large language models have some important limitations, leading to an inefficient customer experience:
Language models are limited to providing generic answers based on their training data. If users were to ask questions specific to the software you sell, or if they have queries on how to perform in-depth troubleshooting, a traditional LLM may not be able to provide accurate answers.
This is because they haven’t been trained on data specific to your organization. Furthermore, the training data of these models have a cutoff date, limiting their ability to provide up-to-date responses.
LLMs can “hallucinate,” which means that they tend to confidently generate false responses based on imagined facts. These algorithms can also provide responses that are off-topic if they don’t have an accurate answer to the user’s query, leading to a bad customer experience.
Language models often provide generic responses that aren’t tailored to specific contexts. This can be a major drawback in a customer support scenario since individual user preferences are usually required to facilitate a personalized customer experience.
RAG effectively bridges these gaps by providing you with a way to integrate the general knowledge base of LLMs with the ability to access specific information, such as the data present in your product database and user manuals. This methodology allows for highly accurate and reliable responses that are tailored to your organization’s needs.
A typical RAG pipeline has two phases: an offline indexing phase (preparing your data) and a real-time inference phase (answering queries). Here are the key steps.
You must first gather all the data that is needed for your application. In the case of a customer support chatbot for an electronics company, this can include user manuals, a product database, and a list of FAQs.
Data chunking is the process of breaking your data down into smaller, more manageable pieces. For instance, if you have a lengthy 100-page user manual, you might break it down into different sections, each potentially answering different customer questions.
This way, each chunk of data is focused on a specific topic. When a piece of information is retrieved from the source dataset, it is more likely to be directly applicable to the user’s query, since we avoid including irrelevant information from entire documents.
This also improves efficiency, since the system can quickly obtain the most relevant pieces of information instead of processing entire documents.
Now that the source data has been broken down into smaller parts, it needs to be converted into a vector representation. This involves transforming text data into embeddings, which are numeric representations that capture the semantic meaning behind text.
Document embeddings let the system match user queries to relevant information based on meaning rather than exact keyword overlap. A query about “fix my laptop screen” will match a chunk about “display troubleshooting” even though the words differ.
If you’d like to learn more about how text data is converted into vector representations, check out our tutorial on text embeddings with the OpenAI API.
When a user query enters the system, it must also be converted into an embedding or vector representation. The same model must be used for both the document and query embedding to ensure uniformity between the two.
Once the query is converted into an embedding, the system compares the query embedding with the document embeddings. It identifies and retrieves chunks whose embeddings are most similar to the query embedding, using measures such as cosine similarity and Euclidean distance.
These chunks are considered to be the most relevant to the user’s query.
The retrieved text chunks, along with the initial user query, are fed into a language model. The algorithm will use this information to generate a coherent response to the user’s questions through a chat interface.
Here is a simplified flowchart summarizing how RAG works:
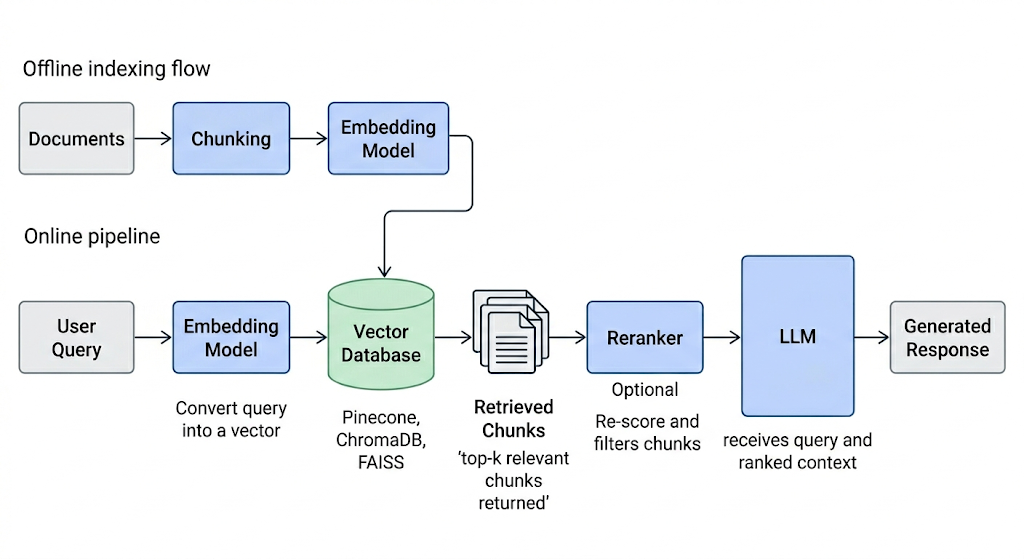
To build this pipeline in practice, you can use a framework like LlamaIndex or LangChain.
Both frameworks handle the orchestration of chunking, embedding, retrieval, and prompt construction, so you can focus on your data and use case rather than plumbing.
Beyond the customer support chatbot example above, RAG has several other practical applications:
RAG can use content from external sources to produce accurate summaries, resulting in considerable time savings. For instance, managers and high-level executives are busy people who don’t have the time to sift through extensive reports.
With an RAG-powered application, they can quickly tap into the most critical findings from text data and make decisions more efficiently instead of having to read through lengthy documents.
RAG systems can be used to analyze customer data, such as past purchases and reviews, to generate product recommendations. This will increase the user’s overall experience and ultimately generate more revenue for the organization.
For example, RAG applications can be used to recommend better movies on streaming platforms based on the user’s viewing history and ratings. They can also be used to analyze written reviews on e-commerce platforms.
Since LLMs excel at understanding the semantics behind text data, RAG systems can provide users with personalized suggestions that are more nuanced than those of a traditional recommendation system.
Organizations make business decisions by tracking competitor behavior and market trends across reports, financial statements, and research documents.
An RAG application can surface relevant findings from these documents on demand, cutting the time analysts spend reading through hundreds of pages.
The basic retrieve-and-generate pattern works well for simple use cases, but production deployments introduce engineering challenges at every stage of the pipeline.
It can be difficult to integrate a retrieval system with an LLM. This complexity increases when there are multiple sources of external data in varying formats. Data that is fed into an RAG system must be consistent, and the embeddings generated need to be uniform across all data sources.
To overcome this challenge, separate modules can be designed to handle different data sources independently. The data within each module can then be preprocessed for uniformity, and a standardized model can be used to ensure that the embeddings have a consistent format.
As the amount of data increases, it gets more challenging to maintain the efficiency of the RAG system. Many complex operations need to be performed - such as generating embeddings, comparing the meaning between different pieces of text, and retrieving data in real-time.
These tasks are computationally intensive and can slow down the system as the size of the source data increases.
To address this challenge, you can distribute computational load across different servers and invest in robust hardware infrastructure. To improve response time, it might also be beneficial to cache queries that are frequently asked.
Vector databases like Pinecone, ChromaDB, FAISS, and Weaviate are purpose-built for this problem. They store embeddings and perform fast approximate nearest-neighbor (ANN) search, returning the most relevant chunks in milliseconds even across millions of documents.
For a hands-on walkthrough, see our tutorial on vector databases with Pinecone, or learn how to build a complete RAG system with LangChain and FastAPI.
The effectiveness of an RAG system depends heavily on the quality of data being fed into it. If the source content accessed by the application is poor, the responses generated will be inaccurate.
Organizations must invest in a diligent content curation and fine-tuning process. It is necessary to refine data sources to enhance their quality. For commercial applications, it can be beneficial to involve a subject matter expert to review and fill in any information gaps before using the dataset in an RAG system.
The basic RAG pipeline works, but it has known failure modes: irrelevant retrieval, lost context in long documents, and inability to reason across multiple sources. Several techniques have emerged to address these gaps.
For a broader overview of optimization strategies, see our guide on how to improve RAG performance.
A common question is whether to use RAG or fine-tuning to customize an LLM. The short answer: they solve different problems, and many production systems use both. For a detailed comparison, see our guide on RAG vs. fine-tuning.
| Criteria | RAG | Fine-Tuning |
|---|---|---|
| Knowledge updates | Swap documents without retraining | Requires retraining on new data |
| Cost | Lower (no GPU training needed) | Higher (GPU hours + data prep) |
| Hallucination control | Strong (answers grounded in retrieved docs) | Moderate (depends on training data) |
| Domain adaptation | Good for factual recall | Better for style, tone, and reasoning patterns |
| Latency | Higher (retrieval step adds time) | Lower (no retrieval overhead) |
| Best for | Dynamic knowledge, FAQ bots, document Q&A | Specialized tasks, consistent output format |
RAG remains the most widely adopted technique for grounding LLM outputs in external knowledge. It directly addresses the core limitations of language models—stale training data, hallucinations, and lack of domain specificity—without the cost and complexity of fine-tuning.
That said, RAG is only as good as the data you feed it. Poor-quality or outdated source documents will produce poor answers, regardless of how capable the LLM is. Human oversight remains necessary, especially for high-stakes applications.
Good data curation, combined with domain expertise, is what separates a useful RAG system from one that confidently returns wrong answers.
To get hands-on with RAG, I recommend our RAG with LangChain course, which walks through building a complete retrieval pipeline from scratch. For a deeper dive into LLM fundamentals, check out the LLMs Concepts course.
Learn RAG with DataCamp!
Course
Course
Course
blog
Stanislav Karzhev
12 min
blog
Oluseye Jeremiah
10 min
Tutorial
Iván Palomares Carrascosa
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Ryan Ong