
Curso
Modelos de IA escalables con PyTorch Lightning
3 h
1.1K
El equipo de Jan ha publicado recientemente Jan-v1, un modelo avanzado de razonamiento agencial que introduce sofisticadas capacidades de automatización de la investigación mediante una mejor utilización de las herramientas y la resolución de problemas en varios pasos.
En este tutorial me centraré en las capacidades únicas de razonamiento agencial de Jan-v1, demostrando cómo actúa como un complejo flujo de trabajo de investigación a través de una interfaz Streamlit implementada localmente y alimentada por llama.cpp.
En este tutorial, explicaré cómo:
Al final, tu aplicación tendrá este aspecto:
Jan-v1 es un modelo de 4B parámetros basado en los fundamentos de Lucy y Qwen3-4B-thinking, diseñado para flujos de trabajo agenticos como el uso de herramientas, el razonamiento en varios pasos y la investigación automatizada. A diferencia de los LLM convencionales, Jan-v1 destaca en la coordinación entre herramientas, fuentes de datos y pasos de razonamiento mediante un andamiaje estructurado y recompensas alineadas con el comportamiento.
Estas son algunas de las características principales de este modelo:
Para este proyecto, implementaremos Jan-v1 localmente utilizando Llama.cpp con la versión cuantificada GGUF para obtener un rendimiento óptimo y una eficiencia de recursos.
En primer lugar, asegúrate de que tienes los paquetes Python necesarios:
pip install llama-cpp-python==0.3.15
pip install streamlit aiohttp Este comando instala todas las dependencias básicas necesarias para la integración del modelo de IA, la creación de la interfaz web y las operaciones web asíncronas.
Antes de descargar el modelo, crea un nuevo directorio llamado « models/ » con el siguiente comando:
mkdir -p modelsA continuación, descarga el modelo utilizando el siguiente comando:
curl -L https://huggingface.co/janhq/Jan-v1-4B-GGUF/resolve/main/Jan-v1-4B-Q4_K_M.gguf -o Jan-v1-4B-Q4_K_M.ggufAl completar este paso, has descargado correctamente el modelo Jan-v1 4B en formato GGUF y lo has colocado en el directorio models/. Esta versión cuantificada ofrece un equilibrio entre rendimiento y eficiencia de memoria, lo que la hace ideal para la inferencia local en CPU o Colab.
Regístrate o inicia sesión en tu cuenta Serper: https://serper.dev/api-keys y selecciona la pestaña «Claves API». A continuación, copia la clave API predeterminada para esta demostración. Configuremos esta clave como variable de entorno de la siguiente manera:
export SERPER_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx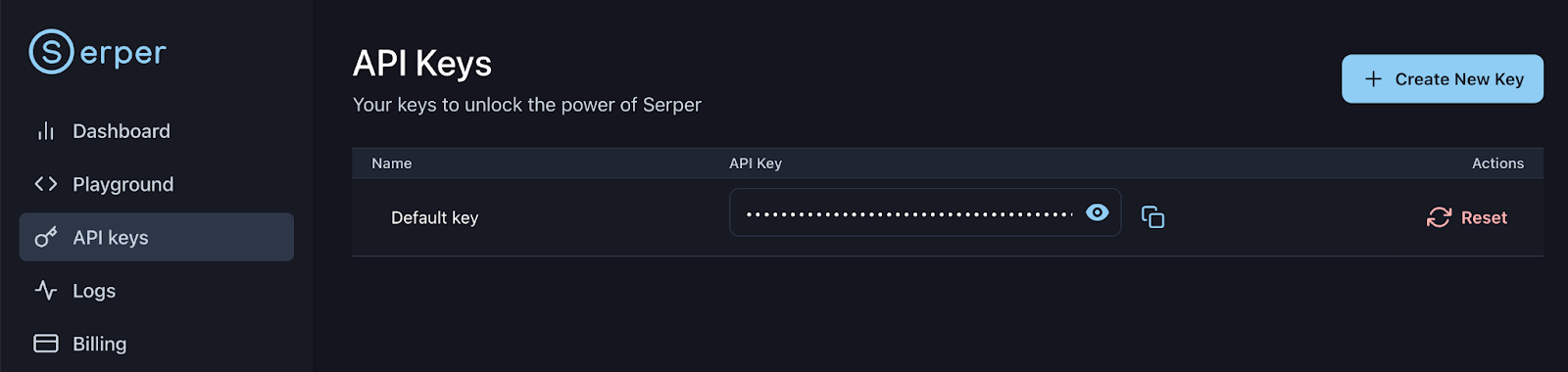
Ya estás listo para cargar e interactuar con el modelo en tu canalización de asistente de investigación.
Construyamos un aplicación Streamlit que demuestre las capacidades avanzadas de investigación de Jan-v1, con generación inteligente de consultas, búsqueda web automatizada (utilizando Serper) y síntesis de informes profesionales.
Comenzamos importando todas las bibliotecas necesarias para nuestro asistente de investigación. Estos soportan todo, desde la creación de interfaces web hasta la búsqueda web asíncrona y la integración de modelos de IA locales.
import streamlit as st
import json
import time
import re
from datetime import datetime
from typing import List, Dict, Optional
import asyncio
import aiohttp
from llama_cpp import Llama
import os
from dataclasses import dataclassImportamos todas las bibliotecas principales utilizadas en toda la aplicación. Entre ellos se incluyen componentes de la interfaz de usuario (Streamlit), herramientas de concurrencia (asyncio, aiohttp) y el backend LLM (llama_cpp). También incorporaremos utilidades para el análisis sintáctico, la tipificación y el manejo de fechas.
Ahora implementaremos algunas funciones auxiliares que se encargarán del formato de los informes y la extracción de contenido. Estas funciones garantizan que los informes generados mantengan una calidad profesional y una estructura coherente.
def sections_for_format(fmt: str) -> list[str]:
fmt = (fmt or "").strip().lower()
if fmt == "executive":
return ["EXECUTIVE SUMMARY"]
if fmt == "detailed":
return [
"INTRODUCTION",
"DETAILED ANALYSIS",
"CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS",
"CONCLUSION",
]
if fmt == "academic":
return [
"ABSTRACT",
"INTRODUCTION",
"METHODOLOGY",
"FINDINGS",
"DISCUSSION",
"CONCLUSION",
]
if fmt == "presentation":
return [
"OVERVIEW",
"KEY INSIGHTS",
"RECOMMENDATIONS",
"NEXT STEPS",
"CONCLUSION",
]
return ["INTRODUCTION", "DETAILED ANALYSIS", "CONCLUSION"]
def extract_final_block(text: str) -> str:
m = re.search(r"<final>([\s\S]*?)</final>", text, flags=re.IGNORECASE)
if m:
cleaned_text = m.group(1).strip()
else:
cleaned_text = text
preamble_patterns = [
r"^(?:note:|okay,|hmm,|internal|let me|i (?:will|’ll)|as an ai|thinking|plan:|here is your report|the following is|i have prepared|i am presenting|based on the provided information|below is the report|i hope this meets your requirements|this report outlines|this is the final report).*?$",
r"^(?:Here is the report|I have compiled the report|The report is provided below|This is the requested report).*?$", # More specific preambles
r"^(?:Please find the report below|Here's the report).*?$"
]
for pattern in preamble_patterns:
cleaned_text = re.sub(pattern, "", cleaned_text, flags=re.IGNORECASE | re.MULTILINE).strip()
cleaned_text = re.sub(r"(?m)^\s*[-*•]\s+", "", cleaned_text)
cleaned_text = re.sub(r"[#`*_]{1,3}", "", cleaned_text)
headers = [
"EXECUTIVE SUMMARY","INTRODUCTION","DETAILED ANALYSIS","CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS","CONCLUSION","ABSTRACT","METHODOLOGY","FINDINGS",
"DISCUSSION","OVERVIEW","KEY INSIGHTS","RECOMMENDATIONS","NEXT STEPS"
]
sorted_headers = sorted(headers, key=len, reverse=True)
first_pos = -1
for h in sorted_headers:
match = re.search(r'\b' + re.escape(h) + r'\b', cleaned_text, flags=re.IGNORECASE)
if match:
if first_pos == -1 or match.start() < first_pos:
first_pos = match.start()
if first_pos >= 0:
cleaned_text = cleaned_text[first_pos:].strip()
return cleaned_textA continuación se explica cómo encaja cada función en el proceso:
sections_for_format() función: Esta función genera encabezados de sección adaptados al formato de informe seleccionado (por ejemplo, ejecutivo, detallado, académico). Esto garantiza que cada informe cumpla con los estándares profesionales y satisfaga las expectativas de los usuarios.extract_final_block() función: Este paso de posprocesamiento aísla el contenido principal del informe. Extrae el texto entre las etiquetas « Estas funciones auxiliares son fundamentales para mantener una salida coherente y de alta calidad en diferentes formatos de informes y escenarios de investigación para un modelo de pensamiento como Jan-v1.
Establezcamos el sistema de configuración básico que gestiona los parámetros del modelo, los ajustes de la API y las preferencias de investigación. Este enfoque modular garantiza una fácil personalización y un rendimiento óptimo.
Este paso define un sistema de configuración y un cargador de modelos para una inferencia local eficiente con el modelo Jan-v1. El sistema está diseñado para admitir tareas de investigación reproducibles en entornos que solo utilizan CPU, como ordenadores portátiles o Colab Pro, al tiempo que mantiene la flexibilidad y la seguridad.
@dataclass
class ResearchConfig:
model_path: str = "models/Jan-v1-4B-Q4_K_M.gguf" #change as per your location
max_tokens: int = 2048
temperature: float = 0.6
top_p: float = 0.95
top_k: int = 20
context_length: int = 4096
search_api_key: str = os.getenv("SERPER_API_KEY", "")
search_engine: str = "serper" A continuación se ofrece una descripción general de la configuración del código anterior:
ResearchConfig es un panel de control ( @dataclass ) que centraliza todas las configuraciones de LLM y del motor de búsqueda, lo que permite un fácil ajuste para diferentes escenarios de investigación.temperature » (creatividad), « top_p » (conocimiento) y « top_k » (conocimiento) se establecen para equilibrar la creatividad con la base factual, lo cual es importante para los resultados orientados a la investigación.context_length ) está establecido en 4096 tokens, lo que está optimizado para las capacidades de razonamiento de formato largo de Jan-v1.search_api_key permite la integración con Serper para mejorar las búsquedas web en tiempo real.En este paso, definimos una clase Deep Research assistant que actúa como controlador central de todas las tareas de investigación, abstrayendo el modelo de bajo nivel y la gestión de la configuración, al tiempo que expone interfaces de alto nivel para la generación, la búsqueda y la síntesis.
class DeepResearchAssistant:
def __init__(self, config: ResearchConfig):
self.config = config
self.llm = None
self.demo_mode = False
def load_model(self):
try:
if not os.path.exists(self.config.model_path):
print(f"Model file not found: {self.config.model_path}")
return False
file_size_gb = os.path.getsize(self.config.model_path) / (1024**3)
if file_size_gb < 1.0:
print(f"Model file too small ({file_size_gb:.1f} GB).")
return False
self.llm = Llama(
model_path=self.config.model_path,
n_ctx=self.config.context_length,
verbose=False,
n_threads=max(1, min(4, os.cpu_count() // 2)),
n_gpu_layers=0,
use_mmap=True,
use_mlock=False,
n_batch=128,
f16_kv=True,
)
test = self.llm("Hi", max_tokens=3, temperature=0.1, echo=False)
ok = bool(test and 'choices' in test)
print("Model loaded " if ok else "Model loaded but test generation failed ")
return ok
except Exception as e:
print(f"Model loading failed: {e}")
return FalseLa clase DeepResearchAssistant es el principal coordinador que gestiona la carga de modelos, la validación de la configuración y proporciona una interfaz limpia para las operaciones de investigación. Este sistema de configuración proporciona gestión de errores y validación, lo que garantiza que el modelo se cargue correctamente y esté listo para las tareas de investigación. Estas son las características principales de esta clase:
load_model() » inicializa de forma segura el modelo Jan-v1 GGUF utilizando « llama-cpp-python », optimizado para la inferencia de la CPU local.use_mmap=True para habilitar una carga eficiente respaldada por disco sin consumir toda la RAM.f16_kv=True ) para reducir el uso de memoria. El parámetro « n_gpu_layers=0 » garantiza la ejecución solo en la CPU.Esta configuración garantiza una inferencia local rápida y ligera, ideal para ejecutar Jan-v1 en ordenadores portátiles o Colab sin GPU.
A continuación, implementaremos el sistema central de generación de respuestas junto con las capacidades de búsqueda web que impulsan nuestra automatización de la investigación. Para ello, utilizamos los servicios de la API de Serper, tal y como se muestra a continuación:
def generate_response(self, prompt: str, max_tokens: int = None, extra_stops: Optional[List[str]] = None) -> str:
if not self.llm:
return "Model not loaded."
stops = ["</s>", "<|im_end|>", "<|endoftext|>"]
if extra_stops:
stops.extend(extra_stops)
mt = max_tokens or self.config.max_tokens
try:
resp = self.llm(
prompt,
max_tokens=mt,
temperature=self.config.temperature,
top_p=self.config.top_p,
top_k=self.config.top_k,
stop=stops,
echo=False
)
return resp["choices"][0]["text"].strip()
except Exception as e:
return f"Error generating response: {str(e)}"
async def search_web(self, query: str, num_results: int = 10) -> List[Dict]:
if self.config.search_api_key:
return await self.search_serper(query, num_results)
return []
async def search_serper(self, query: str, num_results: int) -> List[Dict]:
url = "https://google.serper.dev/search"
payload = {"q": query, "num": num_results}
headers = {"X-API-KEY": self.config.search_api_key, "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload, headers=headers) as response:
data = await response.json()
results = []
for item in data.get('organic', []):
results.append({
'title': item.get('title', ''),
'url': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': 'web'
})
return results
def generate_search_queries(self, topic: str, focus_area: str, depth: str) -> List[str]:
counts = {'surface': 5, 'moderate': 8, 'deep': 15, 'comprehensive': 25}
n = counts.get(depth, 8)
base = [
f"{topic} overview",
f"{topic} recent developments",
f"{topic} academic studies",
f"{topic} case studies",
f"{topic} policy and regulation",
f"{topic} technical approaches",
f"{topic} market analysis",
f"{topic} statistics and data",
]
return base[:n]El código anterior desglosa la funcionalidad principal de la siguiente manera:
generate_response() función: Esta función gestiona todas las interacciones del modelo Jan-v1 con un manejo adecuado de los errores y secuencias de parada configurables. Esto garantiza una generación de texto coherente y de alta calidad para la síntesis de investigaciones.search_web() y las funciones search_serper(): Estas funciones implementan búsquedas web asíncronas mediante la API Serper, lo que permite realizar búsquedas rápidas y paralelas en varias consultas. El diseño asíncrono evita que la interfaz de usuario se bloquee durante las operaciones de investigación.generate_search_queries() función: Para crear consultas de búsqueda diversas basadas en la profundidad de la investigación y el tema central, implementamos la función « generate_search_queries() » (Búsqueda avanzada). Garantiza una cobertura exhaustiva del tema de investigación, desde descripciones generales y enfoques técnicos hasta casos prácticos, normativas y análisis de mercado. Permite al usuario escalar el número de consultas de 5 a 25 en función de la profundidad elegida (superficial, moderada, profunda o exhaustiva).Este sistema de generación de respuestas constituye el núcleo de nuestra automatización de la investigación, ya que combina las capacidades de razonamiento de Jan-v1 con la búsqueda web en tiempo real para crear informes de investigación.
A continuación, implementaremos un motor de síntesis de investigación que transforma los resultados de búsqueda sin procesar en informes pulidos y profesionales.
def synthesize_research(self, topic: str, search_results: List[Dict], focus_area: str, report_format: str) -> str:
context_lines = []
for i, result in enumerate(search_results[:20]):
title = result.get("title", "")
snippet = result.get("snippet", "")
context_lines.append(f"Source {i+1} Title: {title}\nSource {i+1} Summary: {snippet}")
context = "\n".join(context_lines)
sections = sections_for_format(report_format)
sections_text = "\n".join(sections)
synthesis_prompt = f"""
You are an expert research analyst. Write the final, polished report on: "{topic}" for a professional, real-world audience.
***CRITICAL INSTRUCTIONS:***
- Your entire response MUST be the final report, wrapped **EXACTLY** inside <final> and </final> tags.
- DO NOT output any text, thoughts, or commentary BEFORE the <final> tag or AFTER the </final> tag.
- DO NOT include any conversational filler, internal thoughts, or commentary about the generation process (e.g., "As an AI...", "I will now summarize...", "Here is your report:").
- DO NOT use markdown formatting (e.g., #, ##, *, -).
- DO NOT use bullet points or lists.
- Maintain a formal, academic/professional tone throughout.
- Ensure the report is complete and self-contained.
- Include the following section headers, in this order, and no others:
{sections_text}
Guidance:
- Base your writing strictly on the Research Notes provided below. If the notes lack specific data, write a careful, methodology-forward analysis without inventing facts or numbers.
Research Notes:
{context}
Now produce ONLY the final report:
<final>
...your report here...
</final>
"""
raw = self.generate_response(synthesis_prompt, max_tokens=1800, extra_stops=["</final>"])
final_report = extract_final_block(raw)
final_report = re.sub(r"(?m)^\s*[-*•]\s+", "", final_report)
final_report = re.sub(r"[#`*_]{1,3}", "", final_report)
first = next((h for h in sections if h in final_report), None)
if first:
final_report = final_report[final_report.find(first):].strip()
return final_reportEl código anterior aprovecha las capacidades avanzadas de razonamiento de Jan-v1 para transformar los resultados sin procesar de una búsqueda web en informes profesionales que normalmente requerirían horas de investigación y redacción manuales. Veamos en detalle las capacidades clave:
sections_for_format() », generamos encabezados de sección del informe adaptados al formato de salida seleccionado, que se insertan en el mensaje con reglas de generación estrictas para limitar el comportamiento del modelo.... y prohibir los andamios conversacionales, se evita que el modelo introduzca texto irrelevante, resúmenes especulativos o enmarcamientos redundantes.regex para eliminar artefactos de marcado, marcadores de lista y formateo erróneo. La función también garantiza que la salida comience desde el primer encabezado de sección válido para mejorar la coherencia estructural.Por último, crearemos la interfaz de usuario completa que reunirá todas nuestras capacidades de investigación en una aplicación interactiva.
def main():
st.set_page_config(page_title="Deep Research Assistant", page_icon="", layout="wide")
st.markdown("""
<div style="background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 1.25rem; border-radius: 10px; color: white; text-align: center; margin-bottom: 1rem;">
<h1 style="margin:0;"> Deep Research Assistant</h1>
</div>
""", unsafe_allow_html=True)
if 'research_assistant' not in st.session_state:
config = ResearchConfig()
st.session_state.research_assistant = DeepResearchAssistant(config)
st.session_state.model_loaded = st.session_state.research_assistant.load_model()
st.session_state.research_results = None
if not st.session_state.research_assistant.config.search_api_key:
st.warning("SERPER_API_KEY not found in environment. Using fallback demo results.")
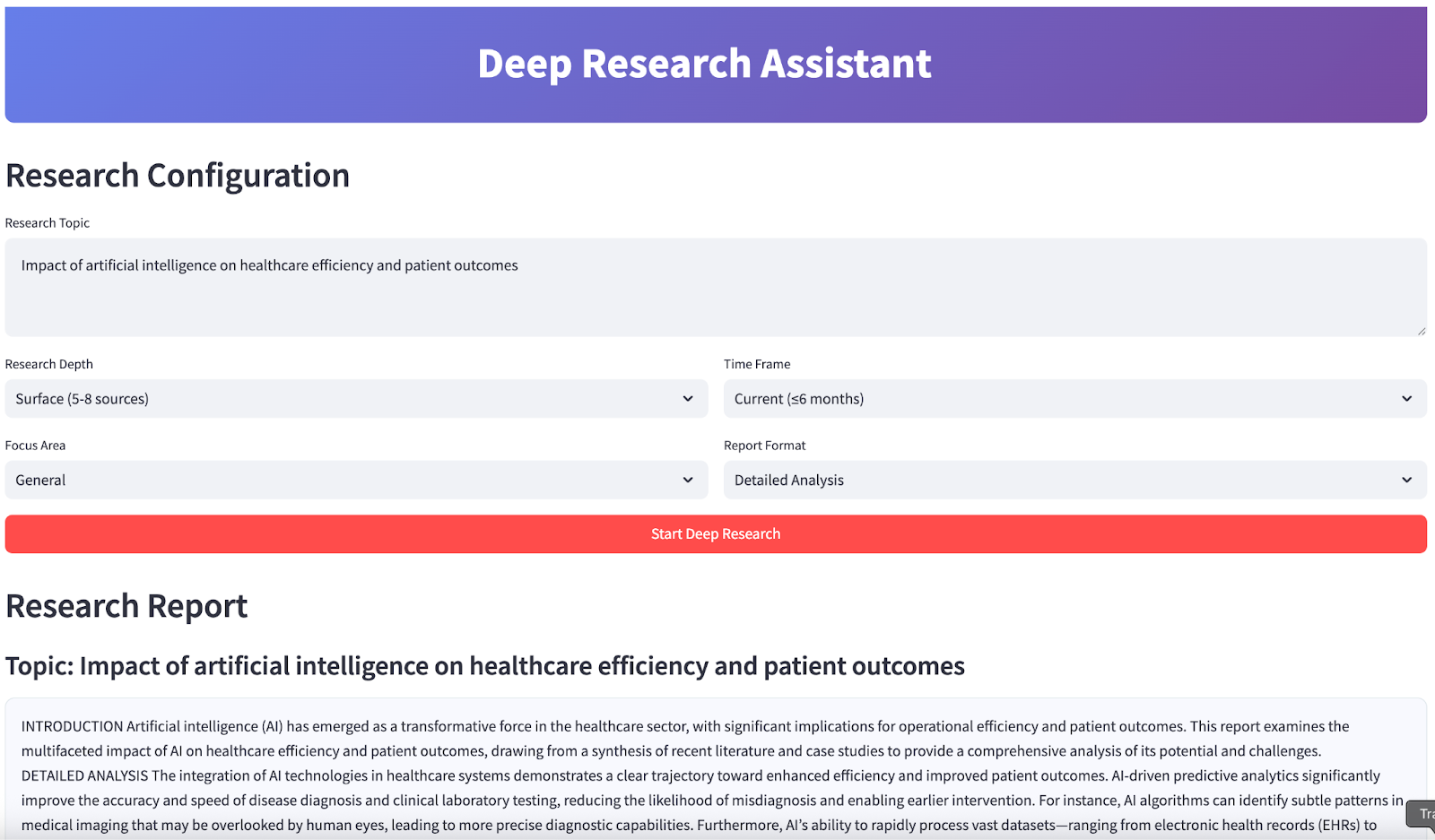
st.header("Research Configuration")
research_topic = st.text_area(
"Research Topic",
placeholder="e.g., Impact of artificial intelligence on healthcare efficiency and patient outcomes",
height=100
)
col1a, col1b = st.columns(2)
with col1a:
research_depth = st.selectbox(
"Research Depth",
["surface", "moderate", "deep", "comprehensive"],
index=1,
format_func=lambda x: {
"surface": "Surface (5-8 sources)",
"moderate": "Moderate (10-15)",
"deep": "Deep Dive (20-30)",
"comprehensive": "Comprehensive (40+)"
}[x]
)
focus_area = st.selectbox("Focus Area", ["general", "academic", "business", "technical", "policy"], index=0, format_func=str.title)
with col1b:
time_frame = st.selectbox(
"Time Frame",
["current", "recent", "comprehensive"],
index=1,
format_func=lambda x: {"current":"Current (≤6 months)","recent":"Recent (≤2 years)","comprehensive":"All time"}[x]
)
report_format = st.selectbox(
"Report Format",
["executive", "detailed", "academic", "presentation"],
index=1,
format_func=lambda x: {
"executive":"Executive Summary",
"detailed":"Detailed Analysis",
"academic":"Academic Style",
"presentation":"Presentation Format"
}[x]
)
if st.button("Start Deep Research", type="primary", use_container_width=True):
if not st.session_state.model_loaded:
st.error("Model not loaded. See terminal logs for details.")
elif not research_topic.strip():
st.error("Please enter a research topic.")
else:
start_research(research_topic, research_depth, focus_area, time_frame, report_format)
if st.session_state.research_results:
display_research_results(st.session_state.research_results)
def start_research(topic: str, depth: str, focus: str, timeframe: str, format_type: str):
assistant = st.session_state.research_assistant
progress_bar = st.progress(0)
status_text = st.empty()
try:
status_text.text("Generating search queries...")
progress_bar.progress(15)
queries = assistant.generate_search_queries(topic, focus, depth)
status_text.text("Searching sources...")
progress_bar.progress(40)
all_results = []
for i, query in enumerate(queries):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
results = loop.run_until_complete(assistant.search_web(query, 5))
all_results.extend(results)
loop.close()
progress_bar.progress(40 + int(((i + 1) / max(1, len(queries))) * 30))
time.sleep(0.05)
status_text.text("Synthesizing report...")
progress_bar.progress(80)
research_report = assistant.synthesize_research(topic, all_results, focus, format_type)
status_text.text("Done.")
progress_bar.progress(100)
st.session_state.research_results = {
'topic': topic,
'report': research_report,
'sources': all_results,
'queries': queries,
'config': {'depth': depth, 'focus': focus, 'timeframe': timeframe, 'format': format_type},
'timestamp': datetime.now()
}
time.sleep(0.3)
status_text.empty()
progress_bar.empty()
except Exception as e:
st.error(f"Research failed: {str(e)}")
status_text.empty()
progress_bar.empty()
def display_research_results(results: Dict):
st.header("Research Report")
st.subheader(f"Topic: {results['topic']}")
st.markdown(
f'<div style="background:#f8f9ff;padding:1rem;border-radius:10px;border:1px solid #e1e8ed;">{results["report"]}</div>',
unsafe_allow_html=True,
)
with st.expander("Sources", expanded=False):
for i, source in enumerate(results['sources'][:12]):
st.markdown(f"""
<div style="background:#fff;padding:0.75rem;border-radius:8px;border:1px solid #e1e8ed;margin:0.4rem 0;">
<h4 style="margin:0 0 .25rem 0;">{source['title']}</h4>
<p style="margin:0 0 .25rem 0;">{source['snippet']}</p>
<small><a href="{source['url']}" target="_blank">{source['url']}</a></small>
</div>
""", unsafe_allow_html=True)
st.markdown("### Export")
c1, c2, c3 = st.columns(3)
with c1:
report_text = f"Research Report: {results['topic']}\n\n{results['report']}"
st.download_button("Download Text", data=report_text, file_name=f"research_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt", mime="text/plain")
with c2:
json_data = json.dumps(results, default=str, indent=2)
st.download_button("Download JSON", data=json_data, file_name=f"research_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json", mime="application/json")
with c3:
if st.button("Start New Research"):
st.session_state.research_results = None
st.experimental_rerun()
if __name__ == "__main__":
main()
El código anterior se divide en capas, desde la carga del modelo y la recopilación de datos del usuario hasta la generación de consultas, la búsqueda web y la síntesis del informe final. Analicemos estas capas en detalle:
DeepResearchAssistant ) se inicializa una vez por sesión mediante st.session_state, lo que conserva el estado del modelo y evita que se cargue repetidamente. asyncio, lo que garantiza la ejecución paralela de las consultas sin bloquear la capacidad de respuesta de la interfaz de usuario.TXT o JSON, o volver a ejecutar el flujo de trabajo con un solo clic.Para probarlo tú mismo, guarda el código como app.py y ejecútalo:
streamlit run app.py¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali
Tutorial
Kurtis Pykes



