
Cours
Modèles d'IA évolutifs avec PyTorch Lightning
3 h
1.1K
L'équipe Jan a récemment publié Jan-v1, un modèle avancé de raisonnement agentique qui introduit des capacités sophistiquées d'automatisation de la recherche grâce à une utilisation améliorée des outils et à la résolution de problèmes en plusieurs étapes.
Dans ce tutoriel, je me concentrerai sur les capacités uniques de raisonnement agentique de Jan-v1, en démontrant comment il agit comme un workflow de recherche complexe via une interface Streamlit déployée localement et alimentée par llama.cpp.
Dans ce tutoriel, je vais vous expliquer comment :
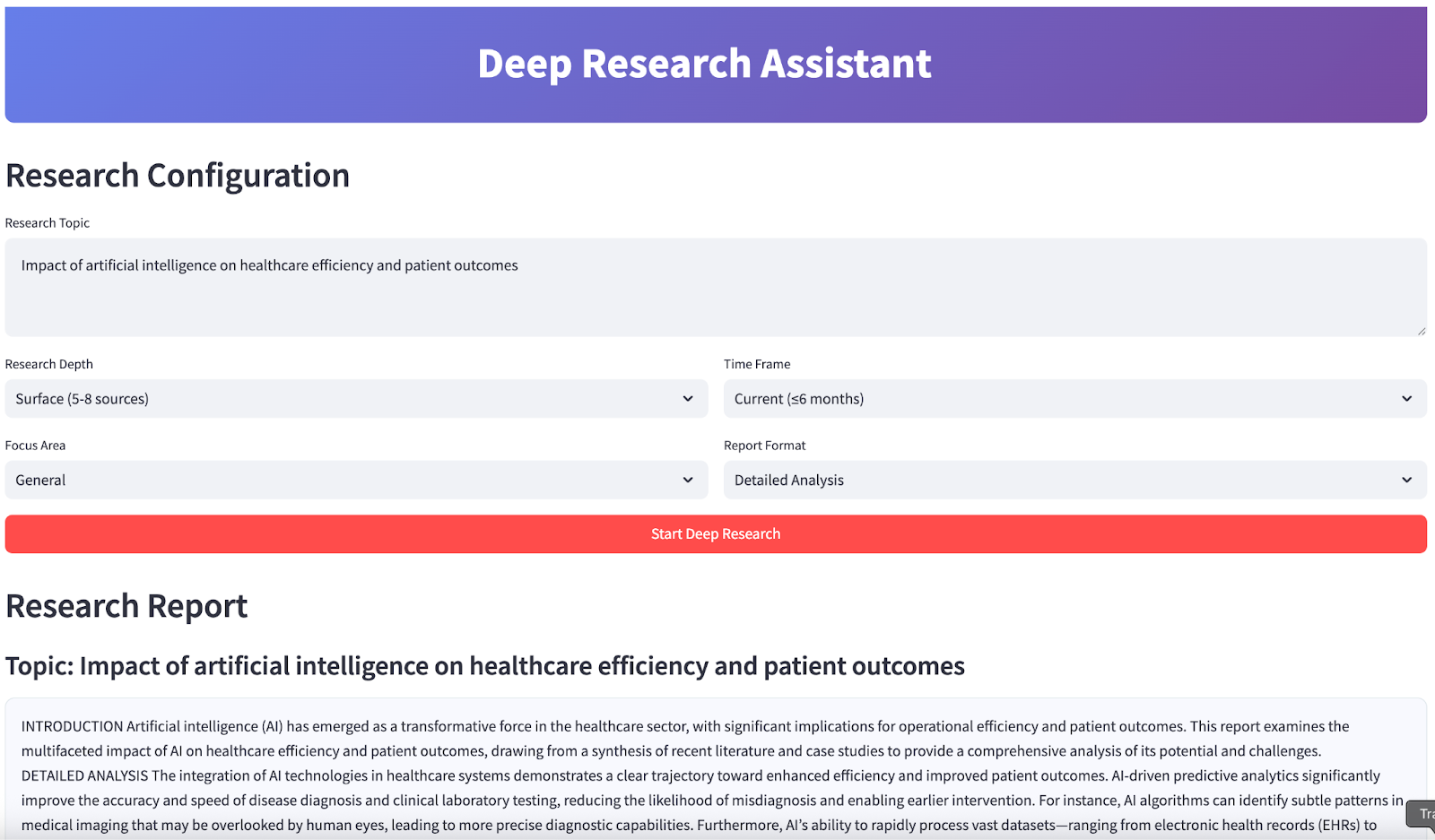
À la fin, votre application ressemblera à ceci :
Jan-v1 est un modèle à 4 paramètres B basé sur les principes de Lucy et Qwen3-4B, conçu pour les flux de travail agentés tels que l'utilisation d'outils, le raisonnement en plusieurs étapes et la recherche automatisée. Contrairement aux LLM traditionnels, Jan-v1 excelle dans la coordination entre les outils, les sources de données et les étapes de raisonnement grâce à une structure structurée et à des récompenses alignées sur le comportement.
Voici quelques caractéristiques clés de ce modèle :
Pour ce projet, nous déploierons Jan-v1 localement à l'aide de Llama.cpp avec la version quantifiée GGUF pour des performances optimales et une utilisation efficace des ressources.
Tout d'abord, assurez-vous que vous disposez des paquets Python requis :
pip install llama-cpp-python==0.3.15
pip install streamlit aiohttp Cette commande installe toutes les dépendances essentielles nécessaires à l'intégration du modèle d'IA, à la création d'une interface Web et aux opérations Web asynchrones.
Avant de télécharger le modèle, veuillez créer un nouveau répertoire nommé « models/ » à l'aide de la commande suivante :
mkdir -p modelsEnsuite, veuillez télécharger le modèle à l'aide de la commande suivante :
curl -L https://huggingface.co/janhq/Jan-v1-4B-GGUF/resolve/main/Jan-v1-4B-Q4_K_M.gguf -o Jan-v1-4B-Q4_K_M.ggufEn suivant cette étape, vous avez téléchargé avec succès le modèle Jan-v1 4B au format GGUF et l'avez placé dans le répertoire models/. Cette version quantifiée offre un compromis équilibré entre performances et efficacité mémoire, ce qui la rend idéale pour l'inférence locale sur les processeurs ou Colab.
Veuillez vous inscrire ou vous connecter à votre compte Serper : https://serper.dev/api-keys et sélectionnez l'onglet « API Keys » (Clés API), puis copiez la clé API par défaut pour cette démonstration. Configurons cette clé en tant que variable d'environnement comme suit :
export SERPER_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx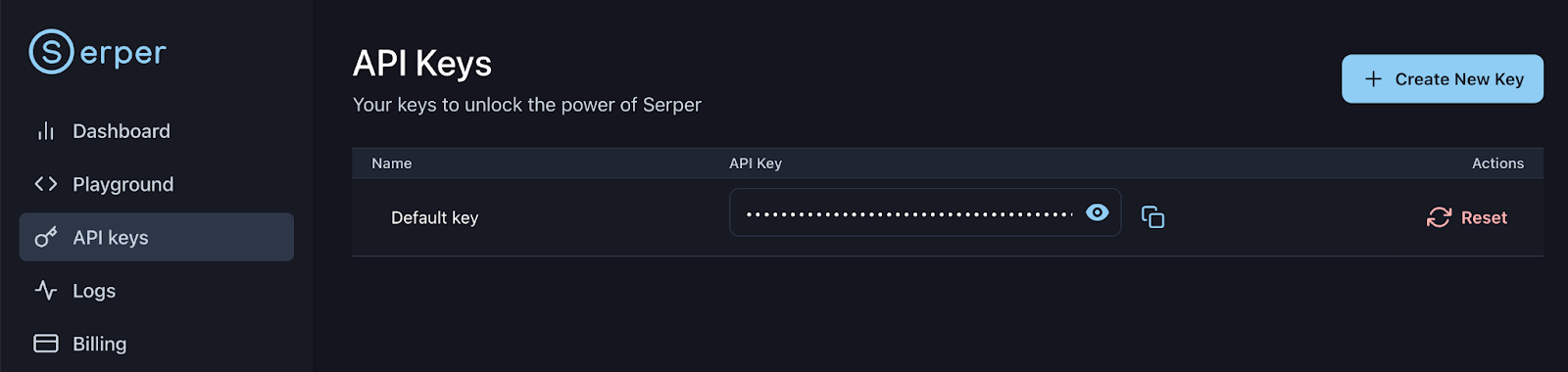
Vous êtes désormais prêt à charger le modèle et à interagir avec celui-ci dans votre pipeline d'assistant de recherche.
Construisons un application Streamlit qui démontre les capacités avancées de recherche de Jan-v1, avec la génération intelligente de requêtes, la recherche Web automatisée (à l'aide de Serper) et la synthèse de rapports professionnels.
Nous commençons par importer toutes les bibliothèques nécessaires à notre assistant de recherche. Ils prennent en charge toutes les fonctionnalités, de la création d'interfaces Web à la recherche Web asynchrone, en passant par l'intégration de modèles d'IA locaux.
import streamlit as st
import json
import time
import re
from datetime import datetime
from typing import List, Dict, Optional
import asyncio
import aiohttp
from llama_cpp import Llama
import os
from dataclasses import dataclassNous importons toutes les bibliothèques principales utilisées dans l'application. Il s'agit notamment des composants de l'interface utilisateur (Streamlit), des outils de concurrence (asyncio, aiohttp) et du backend LLM (llama_cpp). Nous intégrerons également des utilitaires pour l'analyse syntaxique, la saisie et la gestion des dates.
Maintenant, nous allons implémenter quelques fonctions d'aide qui gèrent le formatage des rapports et l'extraction du contenu. Ces fonctions garantissent que les rapports que nous générons conservent une qualité professionnelle et une structure cohérente.
def sections_for_format(fmt: str) -> list[str]:
fmt = (fmt or "").strip().lower()
if fmt == "executive":
return ["EXECUTIVE SUMMARY"]
if fmt == "detailed":
return [
"INTRODUCTION",
"DETAILED ANALYSIS",
"CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS",
"CONCLUSION",
]
if fmt == "academic":
return [
"ABSTRACT",
"INTRODUCTION",
"METHODOLOGY",
"FINDINGS",
"DISCUSSION",
"CONCLUSION",
]
if fmt == "presentation":
return [
"OVERVIEW",
"KEY INSIGHTS",
"RECOMMENDATIONS",
"NEXT STEPS",
"CONCLUSION",
]
return ["INTRODUCTION", "DETAILED ANALYSIS", "CONCLUSION"]
def extract_final_block(text: str) -> str:
m = re.search(r"<final>([\s\S]*?)</final>", text, flags=re.IGNORECASE)
if m:
cleaned_text = m.group(1).strip()
else:
cleaned_text = text
preamble_patterns = [
r"^(?:note:|okay,|hmm,|internal|let me|i (?:will|’ll)|as an ai|thinking|plan:|here is your report|the following is|i have prepared|i am presenting|based on the provided information|below is the report|i hope this meets your requirements|this report outlines|this is the final report).*?$",
r"^(?:Here is the report|I have compiled the report|The report is provided below|This is the requested report).*?$", # More specific preambles
r"^(?:Please find the report below|Here's the report).*?$"
]
for pattern in preamble_patterns:
cleaned_text = re.sub(pattern, "", cleaned_text, flags=re.IGNORECASE | re.MULTILINE).strip()
cleaned_text = re.sub(r"(?m)^\s*[-*•]\s+", "", cleaned_text)
cleaned_text = re.sub(r"[#`*_]{1,3}", "", cleaned_text)
headers = [
"EXECUTIVE SUMMARY","INTRODUCTION","DETAILED ANALYSIS","CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS","CONCLUSION","ABSTRACT","METHODOLOGY","FINDINGS",
"DISCUSSION","OVERVIEW","KEY INSIGHTS","RECOMMENDATIONS","NEXT STEPS"
]
sorted_headers = sorted(headers, key=len, reverse=True)
first_pos = -1
for h in sorted_headers:
match = re.search(r'\b' + re.escape(h) + r'\b', cleaned_text, flags=re.IGNORECASE)
if match:
if first_pos == -1 or match.start() < first_pos:
first_pos = match.start()
if first_pos >= 0:
cleaned_text = cleaned_text[first_pos:].strip()
return cleaned_textVoici comment chaque fonction s'intègre dans le pipeline :
sections_for_format() fonction : Cette fonction génère des en-têtes de section adaptés au format de rapport sélectionné (par exemple, exécutif, détaillé, académique). Cela garantit que chaque rapport respecte les normes professionnelles et répond aux attentes des utilisateurs.extract_final_block() fonction : Cette étape de post-traitement permet d'isoler le contenu principal du rapport. Il extrait le texte entre les balises d'Ces fonctions d'aide sont essentielles pour garantir la cohérence et la qualité des résultats dans différents formats de rapport et scénarios de recherche pour un modèle de réflexion tel que Jan-v1.
Mettons en place le système de configuration de base qui gère les paramètres du modèle, les paramètres API et les préférences de recherche. Cette approche modulaire garantit une personnalisation aisée et des performances optimales.
Cette étape définit un système de configuration et un chargeur de modèle pour une inférence locale efficace avec le modèle Jan-v1. Le système est conçu pour prendre en charge des tâches de recherche reproductibles dans des environnements exclusivement équipés d'un processeur, tels que les ordinateurs portables ou Colab Pro, tout en garantissant flexibilité et sécurité.
@dataclass
class ResearchConfig:
model_path: str = "models/Jan-v1-4B-Q4_K_M.gguf" #change as per your location
max_tokens: int = 2048
temperature: float = 0.6
top_p: float = 0.95
top_k: int = 20
context_length: int = 4096
search_api_key: str = os.getenv("SERPER_API_KEY", "")
search_engine: str = "serper" Voici un aperçu de la configuration du code ci-dessus :
ResearchConfig est une interface utilisateur ( @dataclass ) qui centralise toutes les configurations LLM et du moteur de recherche, permettant ainsi un réglage facile pour différents scénarios de recherche.temperature, l'top_p et l'top_k sont définis afin d'équilibrer la créativité et le fondement factuel, ce qui est important pour les résultats axés sur la recherche.context_length ) est fixée à 4 096 jetons, ce qui est optimisé pour les capacités de raisonnement à long terme de Jan-v1.search_api_key permet l'intégration avec Serper pour une amélioration en temps réel des recherches sur le Web.Dans cette étape, nous définissons une classe d'assistant de recherche approfondie qui agit comme contrôleur central pour toutes les tâches de recherche, en abstraisant la gestion des modèles et des configurations de bas niveau tout en exposant des interfaces de haut niveau pour la génération, la recherche et la synthèse.
class DeepResearchAssistant:
def __init__(self, config: ResearchConfig):
self.config = config
self.llm = None
self.demo_mode = False
def load_model(self):
try:
if not os.path.exists(self.config.model_path):
print(f"Model file not found: {self.config.model_path}")
return False
file_size_gb = os.path.getsize(self.config.model_path) / (1024**3)
if file_size_gb < 1.0:
print(f"Model file too small ({file_size_gb:.1f} GB).")
return False
self.llm = Llama(
model_path=self.config.model_path,
n_ctx=self.config.context_length,
verbose=False,
n_threads=max(1, min(4, os.cpu_count() // 2)),
n_gpu_layers=0,
use_mmap=True,
use_mlock=False,
n_batch=128,
f16_kv=True,
)
test = self.llm("Hi", max_tokens=3, temperature=0.1, echo=False)
ok = bool(test and 'choices' in test)
print("Model loaded " if ok else "Model loaded but test generation failed ")
return ok
except Exception as e:
print(f"Model loading failed: {e}")
return FalseLa classe DeepResearchAssistant est le principal orchestrateur qui gère le chargement des modèles, la validation de la configuration et fournit une interface claire pour les opérations de recherche. Ce système de configuration assure la gestion des erreurs et la validation, garantissant ainsi que le modèle se charge correctement et est prêt pour les tâches de recherche. Voici les principales caractéristiques de ce cours :
load_model() La méthode « initialise_Jan-v1_GGUF » initialise en toute sécurité le modèle Jan-v1 GGUF à l'aide de l'llama-cpp-python, optimisé pour l'inférence CPU locale.use_mmap=True pour permettre un chargement efficace sur disque sans utiliser toute la mémoire vive.f16_kv=True e pour réduire l'utilisation de la mémoire. Le paramètre « n_gpu_layers=0 » garantit une exécution uniquement sur le processeur.Cette configuration garantit une inférence locale rapide et légère, idéale pour exécuter Jan-v1 sur des ordinateurs portables ou Colab sans GPU.
Ensuite, nous implémenterons le système central de génération de réponses ainsi que les fonctionnalités de recherche Web qui alimentent notre automatisation de la recherche. Pour ce faire, nous utilisons les services API Serper comme indiqué ci-dessous :
def generate_response(self, prompt: str, max_tokens: int = None, extra_stops: Optional[List[str]] = None) -> str:
if not self.llm:
return "Model not loaded."
stops = ["</s>", "<|im_end|>", "<|endoftext|>"]
if extra_stops:
stops.extend(extra_stops)
mt = max_tokens or self.config.max_tokens
try:
resp = self.llm(
prompt,
max_tokens=mt,
temperature=self.config.temperature,
top_p=self.config.top_p,
top_k=self.config.top_k,
stop=stops,
echo=False
)
return resp["choices"][0]["text"].strip()
except Exception as e:
return f"Error generating response: {str(e)}"
async def search_web(self, query: str, num_results: int = 10) -> List[Dict]:
if self.config.search_api_key:
return await self.search_serper(query, num_results)
return []
async def search_serper(self, query: str, num_results: int) -> List[Dict]:
url = "https://google.serper.dev/search"
payload = {"q": query, "num": num_results}
headers = {"X-API-KEY": self.config.search_api_key, "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload, headers=headers) as response:
data = await response.json()
results = []
for item in data.get('organic', []):
results.append({
'title': item.get('title', ''),
'url': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': 'web'
})
return results
def generate_search_queries(self, topic: str, focus_area: str, depth: str) -> List[str]:
counts = {'surface': 5, 'moderate': 8, 'deep': 15, 'comprehensive': 25}
n = counts.get(depth, 8)
base = [
f"{topic} overview",
f"{topic} recent developments",
f"{topic} academic studies",
f"{topic} case studies",
f"{topic} policy and regulation",
f"{topic} technical approaches",
f"{topic} market analysis",
f"{topic} statistics and data",
]
return base[:n]Le code ci-dessus décompose les fonctionnalités principales comme suit :
generate_response() fonction : Cette fonction gère toutes les interactions du modèle Jan-v1 avec une gestion des erreurs appropriée et des séquences d'arrêt configurables. Cela garantit une génération de texte cohérente et de haute qualité pour la synthèse de recherche.search_web() et les fonctions d'search_serper(): Ces fonctions implémentent la recherche Web asynchrone à l'aide de l'API Serper, permettant des recherches rapides et parallèles sur plusieurs requêtes. La conception asynchrone empêche le blocage de l'interface utilisateur pendant les opérations de recherche.generate_search_queries() fonction : Afin de créer des requêtes de recherche variées en fonction de la profondeur de la recherche et du sujet principal, nous mettons en œuvre la fonction « generate_search_queries() » (Recherche avancée). Il assure une couverture complète du sujet de recherche, allant des aperçus généraux et des approches techniques aux études de cas, en passant par la réglementation et l'analyse de marché. Il permet à l'utilisateur de faire varier le nombre de requêtes de 5 à 25 en fonction de la profondeur choisie (superficielle, modérée, approfondie ou exhaustive).Ce système de génération de réponses constitue le cœur de notre automatisation de la recherche, combinant les capacités de raisonnement de Jan-v1 avec la recherche Web en temps réel pour créer des rapports de recherche.
Ensuite, nous mettrons en œuvre un moteur de synthèse de recherche qui transforme les résultats de recherche bruts en rapports professionnels et soignés.
def synthesize_research(self, topic: str, search_results: List[Dict], focus_area: str, report_format: str) -> str:
context_lines = []
for i, result in enumerate(search_results[:20]):
title = result.get("title", "")
snippet = result.get("snippet", "")
context_lines.append(f"Source {i+1} Title: {title}\nSource {i+1} Summary: {snippet}")
context = "\n".join(context_lines)
sections = sections_for_format(report_format)
sections_text = "\n".join(sections)
synthesis_prompt = f"""
You are an expert research analyst. Write the final, polished report on: "{topic}" for a professional, real-world audience.
***CRITICAL INSTRUCTIONS:***
- Your entire response MUST be the final report, wrapped **EXACTLY** inside <final> and </final> tags.
- DO NOT output any text, thoughts, or commentary BEFORE the <final> tag or AFTER the </final> tag.
- DO NOT include any conversational filler, internal thoughts, or commentary about the generation process (e.g., "As an AI...", "I will now summarize...", "Here is your report:").
- DO NOT use markdown formatting (e.g., #, ##, *, -).
- DO NOT use bullet points or lists.
- Maintain a formal, academic/professional tone throughout.
- Ensure the report is complete and self-contained.
- Include the following section headers, in this order, and no others:
{sections_text}
Guidance:
- Base your writing strictly on the Research Notes provided below. If the notes lack specific data, write a careful, methodology-forward analysis without inventing facts or numbers.
Research Notes:
{context}
Now produce ONLY the final report:
<final>
...your report here...
</final>
"""
raw = self.generate_response(synthesis_prompt, max_tokens=1800, extra_stops=["</final>"])
final_report = extract_final_block(raw)
final_report = re.sub(r"(?m)^\s*[-*•]\s+", "", final_report)
final_report = re.sub(r"[#`*_]{1,3}", "", final_report)
first = next((h for h in sections if h in final_report), None)
if first:
final_report = final_report[final_report.find(first):].strip()
return final_reportLe code ci-dessus tire parti des capacités avancées de raisonnement de Jan-v1 pour transformer des résultats de recherche Web bruts en rapports professionnels qui nécessiteraient normalement des heures de recherche et de rédaction manuelles. Examinons en détail les principales fonctionnalités :
sections_for_format() », nous générons des en-têtes de section de rapport adaptés au format de sortie sélectionné, qui sont insérés dans l'invite avec des règles de génération strictes afin de limiter le comportement du modèle.... et en interdisant les structures conversationnelles, le modèle est empêché d'introduire du texte non pertinent, des résumés spéculatifs ou des encadrements redondants.regex pour supprimer les artefacts de balisage, les marqueurs de liste et les formats indésirables. La fonction garantit également que la sortie commence à partir du premier en-tête de section valide afin d'améliorer la cohérence structurelle.Enfin, nous construirons l'interface utilisateur complète qui réunira toutes nos capacités de recherche dans une application interactive.
def main():
st.set_page_config(page_title="Deep Research Assistant", page_icon="", layout="wide")
st.markdown("""
<div style="background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 1.25rem; border-radius: 10px; color: white; text-align: center; margin-bottom: 1rem;">
<h1 style="margin:0;"> Deep Research Assistant</h1>
</div>
""", unsafe_allow_html=True)
if 'research_assistant' not in st.session_state:
config = ResearchConfig()
st.session_state.research_assistant = DeepResearchAssistant(config)
st.session_state.model_loaded = st.session_state.research_assistant.load_model()
st.session_state.research_results = None
if not st.session_state.research_assistant.config.search_api_key:
st.warning("SERPER_API_KEY not found in environment. Using fallback demo results.")
st.header("Research Configuration")
research_topic = st.text_area(
"Research Topic",
placeholder="e.g., Impact of artificial intelligence on healthcare efficiency and patient outcomes",
height=100
)
col1a, col1b = st.columns(2)
with col1a:
research_depth = st.selectbox(
"Research Depth",
["surface", "moderate", "deep", "comprehensive"],
index=1,
format_func=lambda x: {
"surface": "Surface (5-8 sources)",
"moderate": "Moderate (10-15)",
"deep": "Deep Dive (20-30)",
"comprehensive": "Comprehensive (40+)"
}[x]
)
focus_area = st.selectbox("Focus Area", ["general", "academic", "business", "technical", "policy"], index=0, format_func=str.title)
with col1b:
time_frame = st.selectbox(
"Time Frame",
["current", "recent", "comprehensive"],
index=1,
format_func=lambda x: {"current":"Current (≤6 months)","recent":"Recent (≤2 years)","comprehensive":"All time"}[x]
)
report_format = st.selectbox(
"Report Format",
["executive", "detailed", "academic", "presentation"],
index=1,
format_func=lambda x: {
"executive":"Executive Summary",
"detailed":"Detailed Analysis",
"academic":"Academic Style",
"presentation":"Presentation Format"
}[x]
)
if st.button("Start Deep Research", type="primary", use_container_width=True):
if not st.session_state.model_loaded:
st.error("Model not loaded. See terminal logs for details.")
elif not research_topic.strip():
st.error("Please enter a research topic.")
else:
start_research(research_topic, research_depth, focus_area, time_frame, report_format)
if st.session_state.research_results:
display_research_results(st.session_state.research_results)
def start_research(topic: str, depth: str, focus: str, timeframe: str, format_type: str):
assistant = st.session_state.research_assistant
progress_bar = st.progress(0)
status_text = st.empty()
try:
status_text.text("Generating search queries...")
progress_bar.progress(15)
queries = assistant.generate_search_queries(topic, focus, depth)
status_text.text("Searching sources...")
progress_bar.progress(40)
all_results = []
for i, query in enumerate(queries):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
results = loop.run_until_complete(assistant.search_web(query, 5))
all_results.extend(results)
loop.close()
progress_bar.progress(40 + int(((i + 1) / max(1, len(queries))) * 30))
time.sleep(0.05)
status_text.text("Synthesizing report...")
progress_bar.progress(80)
research_report = assistant.synthesize_research(topic, all_results, focus, format_type)
status_text.text("Done.")
progress_bar.progress(100)
st.session_state.research_results = {
'topic': topic,
'report': research_report,
'sources': all_results,
'queries': queries,
'config': {'depth': depth, 'focus': focus, 'timeframe': timeframe, 'format': format_type},
'timestamp': datetime.now()
}
time.sleep(0.3)
status_text.empty()
progress_bar.empty()
except Exception as e:
st.error(f"Research failed: {str(e)}")
status_text.empty()
progress_bar.empty()
def display_research_results(results: Dict):
st.header("Research Report")
st.subheader(f"Topic: {results['topic']}")
st.markdown(
f'<div style="background:#f8f9ff;padding:1rem;border-radius:10px;border:1px solid #e1e8ed;">{results["report"]}</div>',
unsafe_allow_html=True,
)
with st.expander("Sources", expanded=False):
for i, source in enumerate(results['sources'][:12]):
st.markdown(f"""
<div style="background:#fff;padding:0.75rem;border-radius:8px;border:1px solid #e1e8ed;margin:0.4rem 0;">
<h4 style="margin:0 0 .25rem 0;">{source['title']}</h4>
<p style="margin:0 0 .25rem 0;">{source['snippet']}</p>
<small><a href="{source['url']}" target="_blank">{source['url']}</a></small>
</div>
""", unsafe_allow_html=True)
st.markdown("### Export")
c1, c2, c3 = st.columns(3)
with c1:
report_text = f"Research Report: {results['topic']}\n\n{results['report']}"
st.download_button("Download Text", data=report_text, file_name=f"research_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt", mime="text/plain")
with c2:
json_data = json.dumps(results, default=str, indent=2)
st.download_button("Download JSON", data=json_data, file_name=f"research_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json", mime="application/json")
with c3:
if st.button("Start New Research"):
st.session_state.research_results = None
st.experimental_rerun()
if __name__ == "__main__":
main()
Le code ci-dessus est divisé en couches, depuis le chargement du modèle et la collecte des données saisies par l'utilisateur jusqu'à la génération de la requête, la recherche sur le Web et la synthèse du rapport final. Examinons ces couches en détail :
DeepResearchAssistant est initialisé une fois par session à l'aide de l'st.session_state, ce qui permet de conserver l'état du modèle et d'éviter les chargements répétés. asyncio, ce qui garantit l'exécution parallèle des requêtes sans bloquer la réactivité de l'interface utilisateur.TXT ou JSON ou relancer le workflow d'un simple clic.Pour l'essayer vous-même, enregistrez le code sous le nom app.py et lancez :
streamlit run app.pyApprenez l'IA grâce à ces cours !
Cours
Cours
Cours