
Curso
Modelos de IA escaláveis com PyTorch Lightning
3 h
1.1K
A equipe da Jan lançou recentemente Jan-v1, um modelo avançado de raciocínio agênico que traz recursos sofisticados de automação de pesquisa por meio de uma melhor utilização das ferramentas e resolução de problemas em várias etapas.
Neste tutorial, vou focar nas capacidades únicas de raciocínio agênico do Jan-v1, mostrando como ele funciona como um fluxo de trabalho de pesquisa complexo por meio de uma interface Streamlit implantada localmente e alimentada por llama.cpp.
Neste tutorial, vou explicar como:
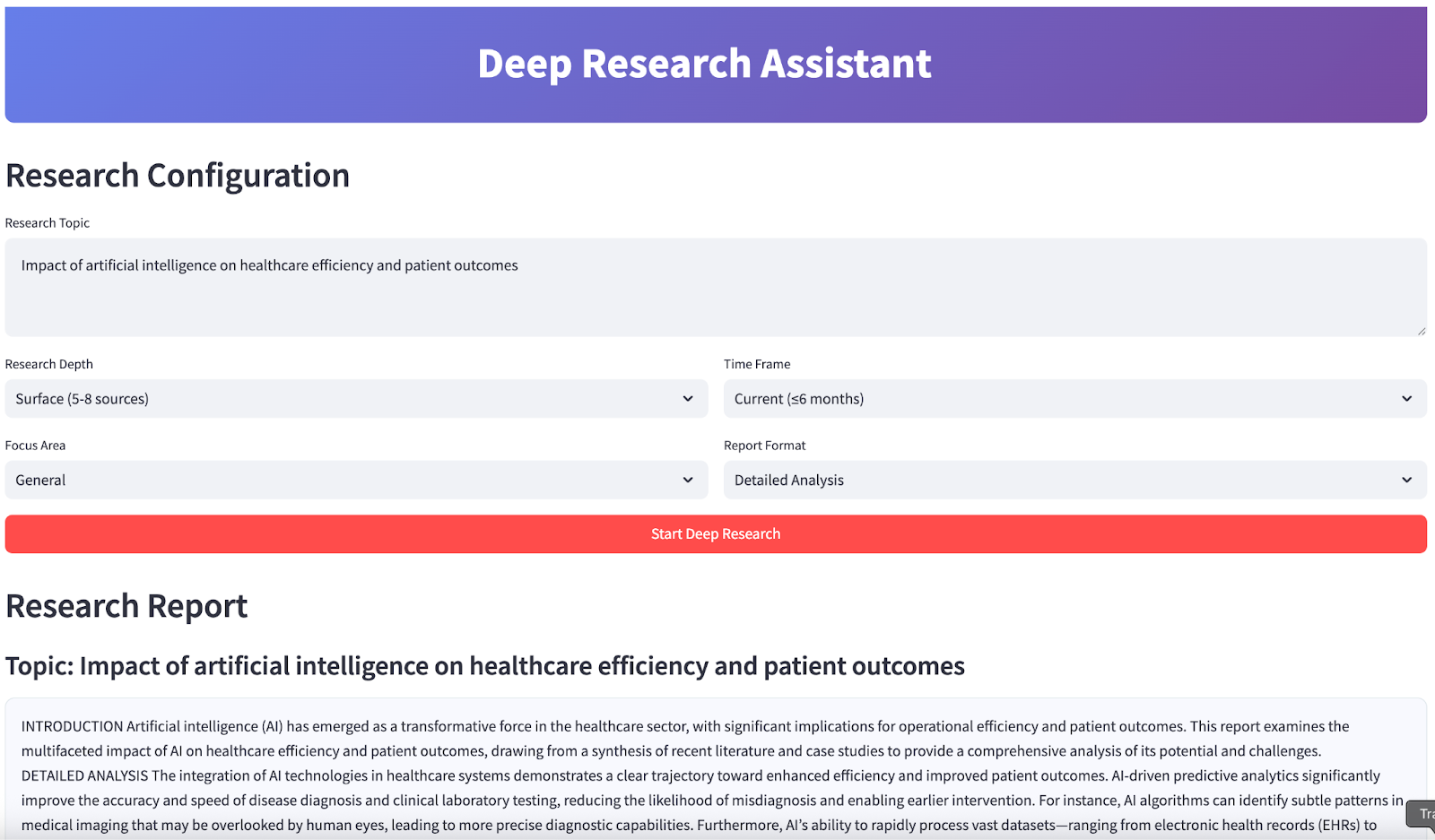
No final, seu aplicativo vai ficar assim:
Jan-v1 é um modelo de 4B parâmetros construído com base no pensamento Lucy e Qwen3-4B, feito para fluxos de trabalho com agentes, como uso de ferramentas, raciocínio em várias etapas e pesquisa automatizada. Diferente dos LLMs tradicionais, o Jan-v1 é ótimo em coordenar ferramentas, fontes de dados e etapas de raciocínio por meio de uma estrutura organizada e recompensas que seguem o comportamento.
Aqui estão algumas das principais características deste modelo:
Para esse projeto, vamos instalar o Jan-v1 localmente usando Llama.cpp com a versão quantizada GGUF para um desempenho ideal e eficiência de recursos.
Primeiro, certifique-se de que você tem os pacotes Python necessários:
pip install llama-cpp-python==0.3.15
pip install streamlit aiohttp Esse comando instala todas as dependências principais necessárias para a integração do modelo de IA, a criação da interface web e as operações web assíncronas.
Antes de baixar o modelo, crie um novo diretório chamado “ models/ ” usando o seguinte comando:
mkdir -p modelsDepois, baixa o modelo usando o seguinte comando:
curl -L https://huggingface.co/janhq/Jan-v1-4B-GGUF/resolve/main/Jan-v1-4B-Q4_K_M.gguf -o Jan-v1-4B-Q4_K_M.ggufAo concluir esta etapa, você baixou com sucesso o modelo Jan-v1 4B no formato GGUF e o colocou no diretório models/. Essa versão quantizada oferece um equilíbrio entre desempenho e eficiência de memória, tornando-a ideal para inferência local em CPUs ou Colab.
Cadastre-se ou entre na sua conta Serper: https://serper.dev/api-keys e selecione a guia Chaves API, depois copie a chave API padrão para esta demonstração. Vamos configurar essa chave como uma variável de ambiente assim:
export SERPER_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx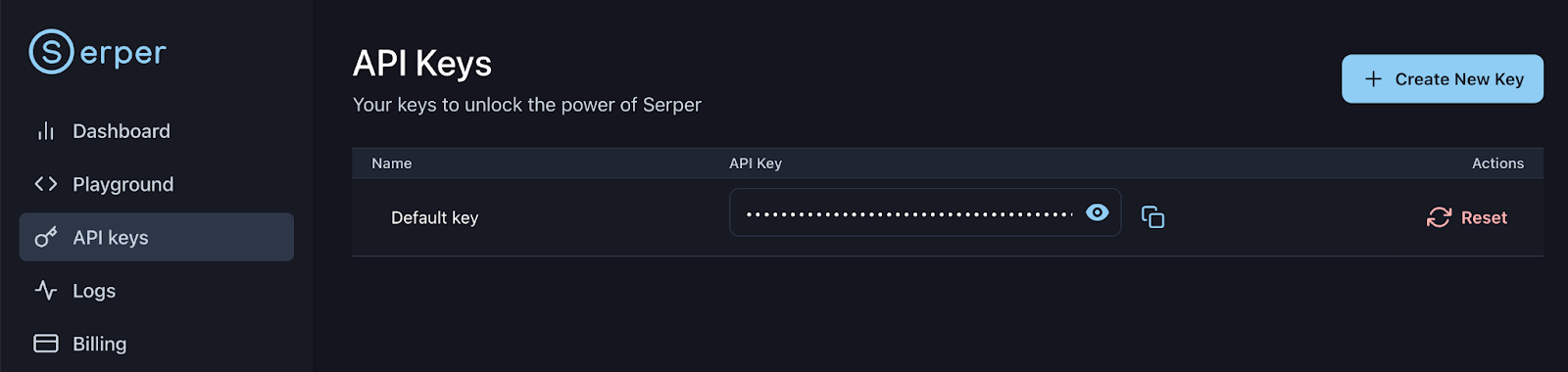
Agora você está pronto para carregar e interagir com o modelo no seu pipeline do assistente de pesquisa.
Vamos criar um aplicativo Streamlit que mostre os recursos avançados de pesquisa do Jan-v1, com geração inteligente de consultas, pesquisa automatizada na web (usando Serper) e síntese profissional de relatórios.
Começamos importando todas as bibliotecas necessárias para o nosso assistente de pesquisa. Eles dão suporte a tudo, desde a criação de interfaces web até pesquisas web assíncronas e integração de modelos de IA locais.
import streamlit as st
import json
import time
import re
from datetime import datetime
from typing import List, Dict, Optional
import asyncio
import aiohttp
from llama_cpp import Llama
import os
from dataclasses import dataclassImportamos todas as bibliotecas principais usadas em todo o aplicativo. Isso inclui componentes da interface do usuário (Streamlit), ferramentas de concorrência (asyncio, aiohttp) e o backend LLM (llama_cpp). Também vamos trazer utilitários para análise, digitação e tratamento de datas.
Agora, vamos implementar algumas funções auxiliares que cuidam da formatação do relatório e da extração do conteúdo. Essas funções garantem que os relatórios que a gente gera tenham qualidade profissional e uma estrutura consistente.
def sections_for_format(fmt: str) -> list[str]:
fmt = (fmt or "").strip().lower()
if fmt == "executive":
return ["EXECUTIVE SUMMARY"]
if fmt == "detailed":
return [
"INTRODUCTION",
"DETAILED ANALYSIS",
"CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS",
"CONCLUSION",
]
if fmt == "academic":
return [
"ABSTRACT",
"INTRODUCTION",
"METHODOLOGY",
"FINDINGS",
"DISCUSSION",
"CONCLUSION",
]
if fmt == "presentation":
return [
"OVERVIEW",
"KEY INSIGHTS",
"RECOMMENDATIONS",
"NEXT STEPS",
"CONCLUSION",
]
return ["INTRODUCTION", "DETAILED ANALYSIS", "CONCLUSION"]
def extract_final_block(text: str) -> str:
m = re.search(r"<final>([\s\S]*?)</final>", text, flags=re.IGNORECASE)
if m:
cleaned_text = m.group(1).strip()
else:
cleaned_text = text
preamble_patterns = [
r"^(?:note:|okay,|hmm,|internal|let me|i (?:will|’ll)|as an ai|thinking|plan:|here is your report|the following is|i have prepared|i am presenting|based on the provided information|below is the report|i hope this meets your requirements|this report outlines|this is the final report).*?$",
r"^(?:Here is the report|I have compiled the report|The report is provided below|This is the requested report).*?$", # More specific preambles
r"^(?:Please find the report below|Here's the report).*?$"
]
for pattern in preamble_patterns:
cleaned_text = re.sub(pattern, "", cleaned_text, flags=re.IGNORECASE | re.MULTILINE).strip()
cleaned_text = re.sub(r"(?m)^\s*[-*•]\s+", "", cleaned_text)
cleaned_text = re.sub(r"[#`*_]{1,3}", "", cleaned_text)
headers = [
"EXECUTIVE SUMMARY","INTRODUCTION","DETAILED ANALYSIS","CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS","CONCLUSION","ABSTRACT","METHODOLOGY","FINDINGS",
"DISCUSSION","OVERVIEW","KEY INSIGHTS","RECOMMENDATIONS","NEXT STEPS"
]
sorted_headers = sorted(headers, key=len, reverse=True)
first_pos = -1
for h in sorted_headers:
match = re.search(r'\b' + re.escape(h) + r'\b', cleaned_text, flags=re.IGNORECASE)
if match:
if first_pos == -1 or match.start() < first_pos:
first_pos = match.start()
if first_pos >= 0:
cleaned_text = cleaned_text[first_pos:].strip()
return cleaned_textVeja como cada função se encaixa no pipeline:
sections_for_format() função: Essa função cria cabeçalhos de seção personalizados para o formato de relatório escolhido (por exemplo, executivo, detalhado, acadêmico). Isso garante que cada relatório siga os padrões profissionais e atenda às expectativas dos usuários.extract_final_block() função: Esta etapa de pós-processamento isola o conteúdo principal do relatório. Ele pega o texto entre as tags Essas funções auxiliares são essenciais para manter uma saída consistente e de alta qualidade em diferentes formatos de relatório e cenários de pesquisa para um modelo de pensamento como o Jan-v1.
Vamos definir o sistema de configuração principal que controla os parâmetros do modelo, as configurações da API e as preferências de pesquisa. Essa abordagem modular garante fácil personalização e ótimo desempenho.
Essa etapa define um sistema de configuração e um carregador de modelo para uma inferência local eficiente com o modelo Jan-v1. O sistema foi feito pra dar suporte a tarefas de pesquisa que podem ser reproduzidas em ambientes só com CPU, tipo laptops ou Colab Pro, sem perder a flexibilidade e a segurança.
@dataclass
class ResearchConfig:
model_path: str = "models/Jan-v1-4B-Q4_K_M.gguf" #change as per your location
max_tokens: int = 2048
temperature: float = 0.6
top_p: float = 0.95
top_k: int = 20
context_length: int = 4096
search_api_key: str = os.getenv("SERPER_API_KEY", "")
search_engine: str = "serper" Aqui está uma visão geral da configuração do código acima:
ResearchConfig é um @dataclass que junta todas as configurações do LLM e do mecanismo de pesquisa, facilitando o ajuste para diferentes cenários de pesquisa.temperature, top_p e top_k são definidos para equilibrar a criatividade com a base factual, o que é importante para resultados orientados para a pesquisa.context_length ) está definido para 4096 tokens, o que é ideal para as capacidades de raciocínio de longo prazo do Jan-v1.search_api_key permite a integração com o Serper para aumentar as pesquisas na web em tempo real.Nesta etapa, a gente define uma classe assistente de Pesquisa Profunda que funciona como o controlador principal de todas as tarefas de pesquisa, abstraindo o modelo de baixo nível e o gerenciamento de configurações, enquanto expõe interfaces de alto nível para geração, pesquisa e síntese.
class DeepResearchAssistant:
def __init__(self, config: ResearchConfig):
self.config = config
self.llm = None
self.demo_mode = False
def load_model(self):
try:
if not os.path.exists(self.config.model_path):
print(f"Model file not found: {self.config.model_path}")
return False
file_size_gb = os.path.getsize(self.config.model_path) / (1024**3)
if file_size_gb < 1.0:
print(f"Model file too small ({file_size_gb:.1f} GB).")
return False
self.llm = Llama(
model_path=self.config.model_path,
n_ctx=self.config.context_length,
verbose=False,
n_threads=max(1, min(4, os.cpu_count() // 2)),
n_gpu_layers=0,
use_mmap=True,
use_mlock=False,
n_batch=128,
f16_kv=True,
)
test = self.llm("Hi", max_tokens=3, temperature=0.1, echo=False)
ok = bool(test and 'choices' in test)
print("Model loaded " if ok else "Model loaded but test generation failed ")
return ok
except Exception as e:
print(f"Model loading failed: {e}")
return FalseA classe ` DeepResearchAssistant ` é o principal orquestrador que gerencia o carregamento do modelo, a validação da configuração e fornece uma interface limpa para operações de pesquisa. Esse sistema de configuração oferece suporte a erros e validação, garantindo que o modelo carregue corretamente e esteja pronto para tarefas de pesquisa. Aqui estão as principais características desta aula:
load_model() inicializa com segurança o modelo Jan-v1 GGUF usando llama-cpp-python, otimizado para inferência local da CPU.use_mmap=True pra permitir um carregamento eficiente com suporte em disco sem usar toda a RAM.f16_kv=True ” para usar menos memória. O parâmetro “ n_gpu_layers=0 ” garante que a execução seja feita só pela CPU.Essa configuração garante uma inferência local rápida e leve, ideal para rodar o Jan-v1 em laptops ou Colab sem GPUs.
Depois, vamos implementar o sistema principal de geração de respostas junto com os recursos de pesquisa na web que fazem nossa automação de pesquisa funcionar. Pra isso, a gente usa os serviços da API Serper, como mostra a imagem abaixo:
def generate_response(self, prompt: str, max_tokens: int = None, extra_stops: Optional[List[str]] = None) -> str:
if not self.llm:
return "Model not loaded."
stops = ["</s>", "<|im_end|>", "<|endoftext|>"]
if extra_stops:
stops.extend(extra_stops)
mt = max_tokens or self.config.max_tokens
try:
resp = self.llm(
prompt,
max_tokens=mt,
temperature=self.config.temperature,
top_p=self.config.top_p,
top_k=self.config.top_k,
stop=stops,
echo=False
)
return resp["choices"][0]["text"].strip()
except Exception as e:
return f"Error generating response: {str(e)}"
async def search_web(self, query: str, num_results: int = 10) -> List[Dict]:
if self.config.search_api_key:
return await self.search_serper(query, num_results)
return []
async def search_serper(self, query: str, num_results: int) -> List[Dict]:
url = "https://google.serper.dev/search"
payload = {"q": query, "num": num_results}
headers = {"X-API-KEY": self.config.search_api_key, "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload, headers=headers) as response:
data = await response.json()
results = []
for item in data.get('organic', []):
results.append({
'title': item.get('title', ''),
'url': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': 'web'
})
return results
def generate_search_queries(self, topic: str, focus_area: str, depth: str) -> List[str]:
counts = {'surface': 5, 'moderate': 8, 'deep': 15, 'comprehensive': 25}
n = counts.get(depth, 8)
base = [
f"{topic} overview",
f"{topic} recent developments",
f"{topic} academic studies",
f"{topic} case studies",
f"{topic} policy and regulation",
f"{topic} technical approaches",
f"{topic} market analysis",
f"{topic} statistics and data",
]
return base[:n]O código acima divide a funcionalidade principal da seguinte forma:
generate_response() função: Essa função cuida de todas as interações do modelo Jan-v1 com um tratamento de erros legal e sequências de parada que você pode configurar. Isso garante uma geração de texto consistente e de alta qualidade para a síntese da pesquisa.search_web() e as funçõ search_serper(): Essas funções fazem uma busca na web de forma assíncrona usando a API Serper, permitindo buscas rápidas e paralelas em várias consultas. O design assíncrono evita que a interface do usuário fique travada durante as operações de pesquisa.generate_search_queries() função: Para criar consultas de pesquisa variadas com base na profundidade da pesquisa e no tema em foco, usamos a função “ generate_search_queries() ”. Garantimos uma cobertura completa do assunto da pesquisa, desde visões gerais e abordagens técnicas até estudos de caso, regulamentações e análises de mercado. Permite ao usuário escalar o número de consultas de 5 a 25, dependendo da profundidade escolhida (superficial, moderada, profunda ou abrangente).Esse sistema de geração de respostas é o ponto principal da nossa automação de pesquisa, juntando as capacidades de raciocínio do Jan-v1 com a pesquisa na web em tempo real para criar relatórios de pesquisa.
Depois, vamos implementar um mecanismo de síntese de pesquisa que transforma resultados brutos de pesquisa em relatórios profissionais e bem elaborados.
def synthesize_research(self, topic: str, search_results: List[Dict], focus_area: str, report_format: str) -> str:
context_lines = []
for i, result in enumerate(search_results[:20]):
title = result.get("title", "")
snippet = result.get("snippet", "")
context_lines.append(f"Source {i+1} Title: {title}\nSource {i+1} Summary: {snippet}")
context = "\n".join(context_lines)
sections = sections_for_format(report_format)
sections_text = "\n".join(sections)
synthesis_prompt = f"""
You are an expert research analyst. Write the final, polished report on: "{topic}" for a professional, real-world audience.
***CRITICAL INSTRUCTIONS:***
- Your entire response MUST be the final report, wrapped **EXACTLY** inside <final> and </final> tags.
- DO NOT output any text, thoughts, or commentary BEFORE the <final> tag or AFTER the </final> tag.
- DO NOT include any conversational filler, internal thoughts, or commentary about the generation process (e.g., "As an AI...", "I will now summarize...", "Here is your report:").
- DO NOT use markdown formatting (e.g., #, ##, *, -).
- DO NOT use bullet points or lists.
- Maintain a formal, academic/professional tone throughout.
- Ensure the report is complete and self-contained.
- Include the following section headers, in this order, and no others:
{sections_text}
Guidance:
- Base your writing strictly on the Research Notes provided below. If the notes lack specific data, write a careful, methodology-forward analysis without inventing facts or numbers.
Research Notes:
{context}
Now produce ONLY the final report:
<final>
...your report here...
</final>
"""
raw = self.generate_response(synthesis_prompt, max_tokens=1800, extra_stops=["</final>"])
final_report = extract_final_block(raw)
final_report = re.sub(r"(?m)^\s*[-*•]\s+", "", final_report)
final_report = re.sub(r"[#`*_]{1,3}", "", final_report)
first = next((h for h in sections if h in final_report), None)
if first:
final_report = final_report[final_report.find(first):].strip()
return final_reportO código acima usa as funcionalidades avançadas de raciocínio do Jan-v1 para transformar resultados brutos de pesquisa na web em relatórios profissionais que normalmente levariam horas de pesquisa e redação manual. Vamos entender melhor as principais funcionalidades:
sections_for_format() ”, a gente gera cabeçalhos de seção de relatório personalizados para o formato de saída escolhido, que são colocados no prompt com regras de geração bem rígidas para controlar o comportamento do modelo.... e banir estruturas de conversação, o modelo não coloca texto que não tem nada a ver, resumos que são só suposições ou enquadramentos que são repetitivos.regex para tirar artefatos de marcação, marcadores de lista e formatação extra. A função também garante que a saída comece a partir do primeiro cabeçalho de seção válido para melhorar a consistência estrutural.Por fim, vamos criar a interface de usuário completa que junta todas as nossas capacidades de pesquisa em um aplicativo interativo.
def main():
st.set_page_config(page_title="Deep Research Assistant", page_icon="", layout="wide")
st.markdown("""
<div style="background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 1.25rem; border-radius: 10px; color: white; text-align: center; margin-bottom: 1rem;">
<h1 style="margin:0;"> Deep Research Assistant</h1>
</div>
""", unsafe_allow_html=True)
if 'research_assistant' not in st.session_state:
config = ResearchConfig()
st.session_state.research_assistant = DeepResearchAssistant(config)
st.session_state.model_loaded = st.session_state.research_assistant.load_model()
st.session_state.research_results = None
if not st.session_state.research_assistant.config.search_api_key:
st.warning("SERPER_API_KEY not found in environment. Using fallback demo results.")
st.header("Research Configuration")
research_topic = st.text_area(
"Research Topic",
placeholder="e.g., Impact of artificial intelligence on healthcare efficiency and patient outcomes",
height=100
)
col1a, col1b = st.columns(2)
with col1a:
research_depth = st.selectbox(
"Research Depth",
["surface", "moderate", "deep", "comprehensive"],
index=1,
format_func=lambda x: {
"surface": "Surface (5-8 sources)",
"moderate": "Moderate (10-15)",
"deep": "Deep Dive (20-30)",
"comprehensive": "Comprehensive (40+)"
}[x]
)
focus_area = st.selectbox("Focus Area", ["general", "academic", "business", "technical", "policy"], index=0, format_func=str.title)
with col1b:
time_frame = st.selectbox(
"Time Frame",
["current", "recent", "comprehensive"],
index=1,
format_func=lambda x: {"current":"Current (≤6 months)","recent":"Recent (≤2 years)","comprehensive":"All time"}[x]
)
report_format = st.selectbox(
"Report Format",
["executive", "detailed", "academic", "presentation"],
index=1,
format_func=lambda x: {
"executive":"Executive Summary",
"detailed":"Detailed Analysis",
"academic":"Academic Style",
"presentation":"Presentation Format"
}[x]
)
if st.button("Start Deep Research", type="primary", use_container_width=True):
if not st.session_state.model_loaded:
st.error("Model not loaded. See terminal logs for details.")
elif not research_topic.strip():
st.error("Please enter a research topic.")
else:
start_research(research_topic, research_depth, focus_area, time_frame, report_format)
if st.session_state.research_results:
display_research_results(st.session_state.research_results)
def start_research(topic: str, depth: str, focus: str, timeframe: str, format_type: str):
assistant = st.session_state.research_assistant
progress_bar = st.progress(0)
status_text = st.empty()
try:
status_text.text("Generating search queries...")
progress_bar.progress(15)
queries = assistant.generate_search_queries(topic, focus, depth)
status_text.text("Searching sources...")
progress_bar.progress(40)
all_results = []
for i, query in enumerate(queries):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
results = loop.run_until_complete(assistant.search_web(query, 5))
all_results.extend(results)
loop.close()
progress_bar.progress(40 + int(((i + 1) / max(1, len(queries))) * 30))
time.sleep(0.05)
status_text.text("Synthesizing report...")
progress_bar.progress(80)
research_report = assistant.synthesize_research(topic, all_results, focus, format_type)
status_text.text("Done.")
progress_bar.progress(100)
st.session_state.research_results = {
'topic': topic,
'report': research_report,
'sources': all_results,
'queries': queries,
'config': {'depth': depth, 'focus': focus, 'timeframe': timeframe, 'format': format_type},
'timestamp': datetime.now()
}
time.sleep(0.3)
status_text.empty()
progress_bar.empty()
except Exception as e:
st.error(f"Research failed: {str(e)}")
status_text.empty()
progress_bar.empty()
def display_research_results(results: Dict):
st.header("Research Report")
st.subheader(f"Topic: {results['topic']}")
st.markdown(
f'<div style="background:#f8f9ff;padding:1rem;border-radius:10px;border:1px solid #e1e8ed;">{results["report"]}</div>',
unsafe_allow_html=True,
)
with st.expander("Sources", expanded=False):
for i, source in enumerate(results['sources'][:12]):
st.markdown(f"""
<div style="background:#fff;padding:0.75rem;border-radius:8px;border:1px solid #e1e8ed;margin:0.4rem 0;">
<h4 style="margin:0 0 .25rem 0;">{source['title']}</h4>
<p style="margin:0 0 .25rem 0;">{source['snippet']}</p>
<small><a href="{source['url']}" target="_blank">{source['url']}</a></small>
</div>
""", unsafe_allow_html=True)
st.markdown("### Export")
c1, c2, c3 = st.columns(3)
with c1:
report_text = f"Research Report: {results['topic']}\n\n{results['report']}"
st.download_button("Download Text", data=report_text, file_name=f"research_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt", mime="text/plain")
with c2:
json_data = json.dumps(results, default=str, indent=2)
st.download_button("Download JSON", data=json_data, file_name=f"research_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json", mime="application/json")
with c3:
if st.button("Start New Research"):
st.session_state.research_results = None
st.experimental_rerun()
if __name__ == "__main__":
main()
O código acima está dividido em camadas, desde o carregamento do modelo e a coleta de entradas do usuário até a geração da consulta, a pesquisa na web e a síntese do relatório final. Vamos falar sobre essas camadas em detalhes:
DeepResearchAssistant " é inicializado uma vez por sessão usando " st.session_state", preservando o estado do modelo e evitando carregamentos repetidos. asyncio, garantindo que as consultas sejam feitas ao mesmo tempo sem atrapalhar a resposta da interface do usuário.TXT ou JSON ou executar novamente o fluxo de trabalho com um único clique.Para experimentar, salva o código como app.py e abre:
streamlit run app.pyAprenda IA com esses cursos!
Curso
Curso
Curso
blog
DataCamp Team
4 min
Tutorial
Zoumana Keita
Tutorial
Tutorial
Moez Ali



