
Course
Scalable AI Models with PyTorch Lightning
3 hr
1.1K
The Jan team recently released Jan-v1, an advanced agentic reasoning model that introduces sophisticated research automation capabilities through enhanced tool utilization and multi-step problem solving.
My focus in this tutorial will be on Jan-v1's unique agentic reasoning capabilities, demonstrating how it acts as a complex research workflow through a locally-deployed Streamlit interface powered by llama.cpp.
In this tutorial, I'll explain how to:
At the end, your app will look like this:
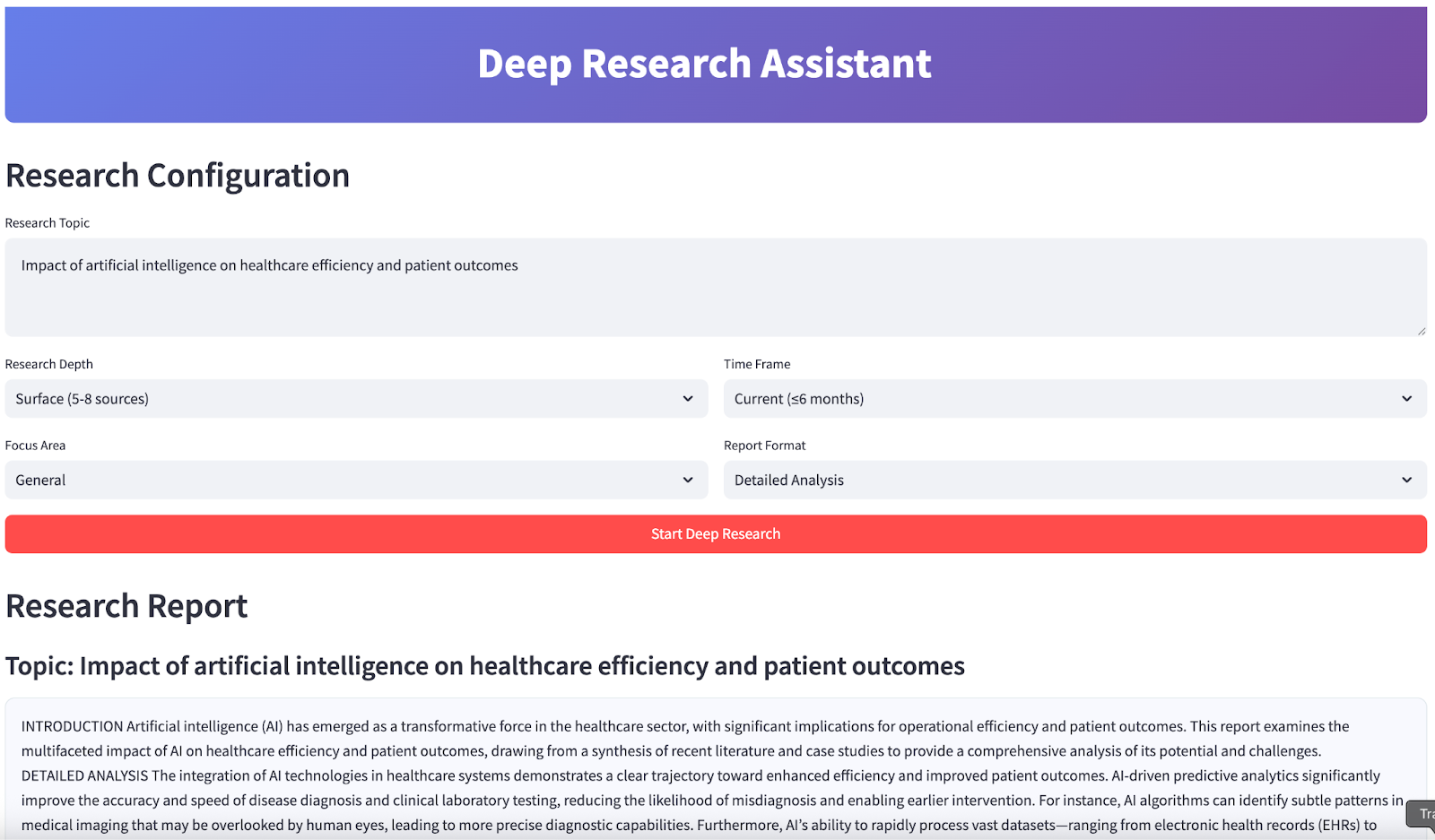
Jan-v1 is a 4B-parameter model built on the Lucy and Qwen3-4B-thinking foundation, designed for agentic workflows like tool use, multi-step reasoning, and automated research. Unlike conventional LLMs, Jan-v1 excels at coordinating between tools, data sources, and reasoning steps through structured scaffolding and behavior-aligned rewards.
Here are a few key features of this model:
For this project, we'll deploy Jan-v1 locally using Llama.cpp with the GGUF quantized version for optimal performance and resource efficiency.
First, ensure you have the required Python packages:
pip install llama-cpp-python==0.3.15
pip install streamlit aiohttp This command installs all core dependencies needed for AI model integration, web interface creation, and asynchronous web operations.
Before downloading the model, create a new directory named models/ using the following command:
mkdir -p modelsThen, download the model using the following command:
curl -L https://huggingface.co/janhq/Jan-v1-4B-GGUF/resolve/main/Jan-v1-4B-Q4_K_M.gguf -o Jan-v1-4B-Q4_K_M.ggufBy completing this step, you've successfully downloaded the Jan-v1 4B model in GGUF format and placed it in the models/ directory. This quantized version offers a balanced trade-off between performance and memory efficiency, making it ideal for local inference on CPUs or Colab.
Sign up or log in to your Serper account: https://serper.dev/api-keys and select the API Keys tab, then copy the default API key for this demo. Let’s set up this key as an environment variable as follows:
export SERPER_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx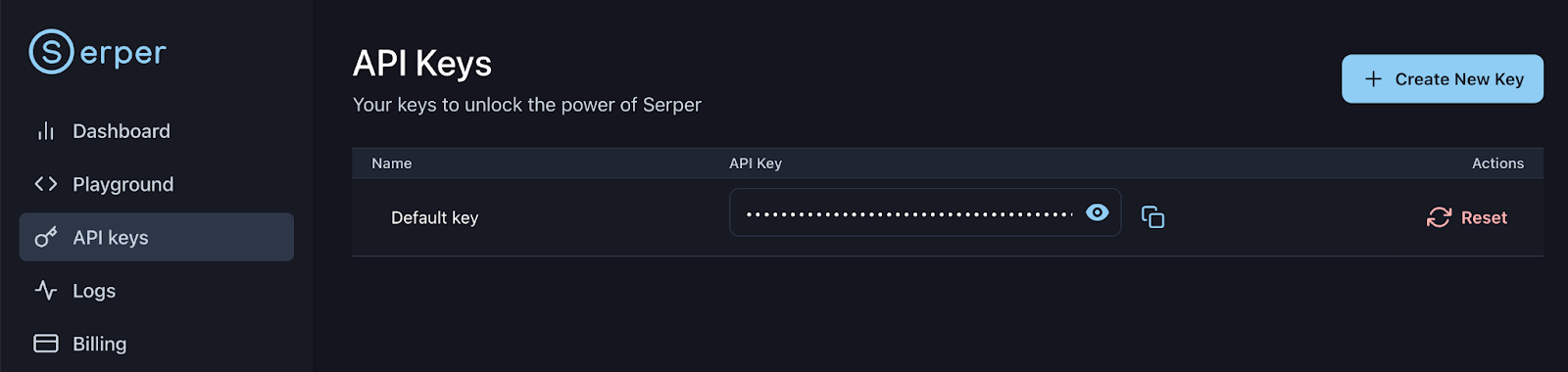
You're now ready to load and interact with the model in your research assistant pipeline.
Let’s build a Streamlit application that demonstrates Jan-v1's advanced research capabilities, with intelligent query generation, automated web search(using Serper), and professional report synthesis.
We begin by importing all the necessary libraries required for our research assistant. These support everything from web interface creation to asynchronous web searching and local AI model integration.
import streamlit as st
import json
import time
import re
from datetime import datetime
from typing import List, Dict, Optional
import asyncio
import aiohttp
from llama_cpp import Llama
import os
from dataclasses import dataclassWe import all the core libraries used throughout the app. These include UI components (Streamlit), concurrency tools (asyncio, aiohttp), and the LLM backend (llama_cpp). We'll also bring in utilities for parsing, typing, and date handling.
Now, we'll implement a few helper functions that handle report formatting and content extraction. These functions ensure that our generated reports maintain professional quality and a consistent structure.
def sections_for_format(fmt: str) -> list[str]:
fmt = (fmt or "").strip().lower()
if fmt == "executive":
return ["EXECUTIVE SUMMARY"]
if fmt == "detailed":
return [
"INTRODUCTION",
"DETAILED ANALYSIS",
"CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS",
"CONCLUSION",
]
if fmt == "academic":
return [
"ABSTRACT",
"INTRODUCTION",
"METHODOLOGY",
"FINDINGS",
"DISCUSSION",
"CONCLUSION",
]
if fmt == "presentation":
return [
"OVERVIEW",
"KEY INSIGHTS",
"RECOMMENDATIONS",
"NEXT STEPS",
"CONCLUSION",
]
return ["INTRODUCTION", "DETAILED ANALYSIS", "CONCLUSION"]
def extract_final_block(text: str) -> str:
m = re.search(r"<final>([\s\S]*?)</final>", text, flags=re.IGNORECASE)
if m:
cleaned_text = m.group(1).strip()
else:
cleaned_text = text
preamble_patterns = [
r"^(?:note:|okay,|hmm,|internal|let me|i (?:will|’ll)|as an ai|thinking|plan:|here is your report|the following is|i have prepared|i am presenting|based on the provided information|below is the report|i hope this meets your requirements|this report outlines|this is the final report).*?$",
r"^(?:Here is the report|I have compiled the report|The report is provided below|This is the requested report).*?$", # More specific preambles
r"^(?:Please find the report below|Here's the report).*?$"
]
for pattern in preamble_patterns:
cleaned_text = re.sub(pattern, "", cleaned_text, flags=re.IGNORECASE | re.MULTILINE).strip()
cleaned_text = re.sub(r"(?m)^\s*[-*•]\s+", "", cleaned_text)
cleaned_text = re.sub(r"[#`*_]{1,3}", "", cleaned_text)
headers = [
"EXECUTIVE SUMMARY","INTRODUCTION","DETAILED ANALYSIS","CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS","CONCLUSION","ABSTRACT","METHODOLOGY","FINDINGS",
"DISCUSSION","OVERVIEW","KEY INSIGHTS","RECOMMENDATIONS","NEXT STEPS"
]
sorted_headers = sorted(headers, key=len, reverse=True)
first_pos = -1
for h in sorted_headers:
match = re.search(r'\b' + re.escape(h) + r'\b', cleaned_text, flags=re.IGNORECASE)
if match:
if first_pos == -1 or match.start() < first_pos:
first_pos = match.start()
if first_pos >= 0:
cleaned_text = cleaned_text[first_pos:].strip()
return cleaned_textHere's how each function fits into the pipeline:
sections_for_format() function: This function generates section headers tailored to the selected report format (e.g., executive, detailed, academic). This ensures each report adheres to professional standards and meets user expectations.extract_final_block() function: This post-processing step isolates the core report content. It extracts text between <final> tags and removes preambles, filler phrases, and markdown artifacts. It also detects the earliest standard header (e.g., "INTRODUCTION", "SUMMARY") to remove irrelevant lead-in text, ensuring the final output is clean, structured, and ready for use.These helper functions are crucial for maintaining consistent, high-quality output across different report formats and research scenarios for a thinking model like Jan-v1.
Let's establish the core configuration system that manages model parameters, API settings, and research preferences. This modular approach ensures easy customization and optimal performance.
This step defines a configuration system and model loader for efficient local inference with the Jan-v1 model. The system is designed to support reproducible research tasks on CPU-only environments, such as laptops or Colab Pro, while maintaining flexibility and safety.
@dataclass
class ResearchConfig:
model_path: str = "models/Jan-v1-4B-Q4_K_M.gguf" #change as per your location
max_tokens: int = 2048
temperature: float = 0.6
top_p: float = 0.95
top_k: int = 20
context_length: int = 4096
search_api_key: str = os.getenv("SERPER_API_KEY", "")
search_engine: str = "serper" Here is a configuration overview of the above code:
ResearchConfig is a @dataclass that centralizes all LLM and search engine configurations, enabling easy tuning for different research scenarios.temperature, top_p, and top_k are set to balance creativity with factual grounding, which is important for research-oriented outputs.context_length is set to 4096 tokens, which is optimized for Jan-v1's long-form reasoning capabilities.search_api_key enables integration with Serper for real-time web search augmentation.In this step, we define a Deep Research assistant class that acts as the core controller for all research tasks, abstracting low-level model and config handling while exposing high-level interfaces for generation, search, and synthesis.
class DeepResearchAssistant:
def __init__(self, config: ResearchConfig):
self.config = config
self.llm = None
self.demo_mode = False
def load_model(self):
try:
if not os.path.exists(self.config.model_path):
print(f"Model file not found: {self.config.model_path}")
return False
file_size_gb = os.path.getsize(self.config.model_path) / (1024**3)
if file_size_gb < 1.0:
print(f"Model file too small ({file_size_gb:.1f} GB).")
return False
self.llm = Llama(
model_path=self.config.model_path,
n_ctx=self.config.context_length,
verbose=False,
n_threads=max(1, min(4, os.cpu_count() // 2)),
n_gpu_layers=0,
use_mmap=True,
use_mlock=False,
n_batch=128,
f16_kv=True,
)
test = self.llm("Hi", max_tokens=3, temperature=0.1, echo=False)
ok = bool(test and 'choices' in test)
print("Model loaded " if ok else "Model loaded but test generation failed ")
return ok
except Exception as e:
print(f"Model loading failed: {e}")
return FalseThe DeepResearchAssistant class is the main orchestrator that manages model loading, configuration validation, and provides a clean interface for research operations. This configuration system provides error handling and validation, ensuring the model loads correctly and is ready for research tasks. Here are the key features of this class:
load_model() method safely initializes the Jan-v1 GGUF model using llama-cpp-python, optimized for local CPU inference.use_mmap=True to enable efficient disk-backed loading without consuming full RAM.f16_kv=True for reduced memory usage. The n_gpu_layers=0 parameter ensures CPU-only execution.This setup ensures fast, lightweight local inference ideal for running Jan-v1 on laptops or Colab without GPUs.
Next, we'll implement the core response generation system along with web search capabilities that power our research automation. For this, we use Serper API services as shown below:
def generate_response(self, prompt: str, max_tokens: int = None, extra_stops: Optional[List[str]] = None) -> str:
if not self.llm:
return "Model not loaded."
stops = ["</s>", "<|im_end|>", "<|endoftext|>"]
if extra_stops:
stops.extend(extra_stops)
mt = max_tokens or self.config.max_tokens
try:
resp = self.llm(
prompt,
max_tokens=mt,
temperature=self.config.temperature,
top_p=self.config.top_p,
top_k=self.config.top_k,
stop=stops,
echo=False
)
return resp["choices"][0]["text"].strip()
except Exception as e:
return f"Error generating response: {str(e)}"
async def search_web(self, query: str, num_results: int = 10) -> List[Dict]:
if self.config.search_api_key:
return await self.search_serper(query, num_results)
return []
async def search_serper(self, query: str, num_results: int) -> List[Dict]:
url = "https://google.serper.dev/search"
payload = {"q": query, "num": num_results}
headers = {"X-API-KEY": self.config.search_api_key, "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload, headers=headers) as response:
data = await response.json()
results = []
for item in data.get('organic', []):
results.append({
'title': item.get('title', ''),
'url': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': 'web'
})
return results
def generate_search_queries(self, topic: str, focus_area: str, depth: str) -> List[str]:
counts = {'surface': 5, 'moderate': 8, 'deep': 15, 'comprehensive': 25}
n = counts.get(depth, 8)
base = [
f"{topic} overview",
f"{topic} recent developments",
f"{topic} academic studies",
f"{topic} case studies",
f"{topic} policy and regulation",
f"{topic} technical approaches",
f"{topic} market analysis",
f"{topic} statistics and data",
]
return base[:n]The above code breaks down the core functionality as follows:
generate_response() function: This function handles all Jan-v1 model interactions with proper error handling and configurable stop sequences. This ensures consistent, high-quality text generation for research synthesis.search_web() and search_serper() functions: These functions implement asynchronous web search using the Serper API, enabling fast, parallel searches across multiple queries. The async design prevents UI blocking during research operations.generate_search_queries() function: To create diverse search queries based on research depth and focus topic, we implement the generate_search_queries() function. It ensures comprehensive coverage of the research subject, ranging from overviews and technical approaches to case studies, regulations, and market analysis. It allows the user to scale the number of queries from 5 to 25 depending on the chosen depth (surface, moderate, deep, or comprehensive).This response generation system forms the core of our research automation, combining Jan-v1's reasoning capabilities with real-time web search to create research reports.
Next, we'll implement a research synthesis engine that transforms raw search results into polished, professional reports.
def synthesize_research(self, topic: str, search_results: List[Dict], focus_area: str, report_format: str) -> str:
context_lines = []
for i, result in enumerate(search_results[:20]):
title = result.get("title", "")
snippet = result.get("snippet", "")
context_lines.append(f"Source {i+1} Title: {title}\nSource {i+1} Summary: {snippet}")
context = "\n".join(context_lines)
sections = sections_for_format(report_format)
sections_text = "\n".join(sections)
synthesis_prompt = f"""
You are an expert research analyst. Write the final, polished report on: "{topic}" for a professional, real-world audience.
***CRITICAL INSTRUCTIONS:***
- Your entire response MUST be the final report, wrapped **EXACTLY** inside <final> and </final> tags.
- DO NOT output any text, thoughts, or commentary BEFORE the <final> tag or AFTER the </final> tag.
- DO NOT include any conversational filler, internal thoughts, or commentary about the generation process (e.g., "As an AI...", "I will now summarize...", "Here is your report:").
- DO NOT use markdown formatting (e.g., #, ##, *, -).
- DO NOT use bullet points or lists.
- Maintain a formal, academic/professional tone throughout.
- Ensure the report is complete and self-contained.
- Include the following section headers, in this order, and no others:
{sections_text}
Guidance:
- Base your writing strictly on the Research Notes provided below. If the notes lack specific data, write a careful, methodology-forward analysis without inventing facts or numbers.
Research Notes:
{context}
Now produce ONLY the final report:
<final>
...your report here...
</final>
"""
raw = self.generate_response(synthesis_prompt, max_tokens=1800, extra_stops=["</final>"])
final_report = extract_final_block(raw)
final_report = re.sub(r"(?m)^\s*[-*•]\s+", "", final_report)
final_report = re.sub(r"[#`*_]{1,3}", "", final_report)
first = next((h for h in sections if h in final_report), None)
if first:
final_report = final_report[final_report.find(first):].strip()
return final_reportThe above code takes advantage of Jan-v1's advanced reasoning capabilities to transform raw web search results into professional reports that would typically require hours of manual research and writing. Let’s understand the key capabilities in detail:
sections_for_format() function, we generate report section headers tailored to the selected output format, which are injected into the prompt with strict generation rules to constrain the model's behavior.<final>...</final> tags and banning conversational scaffolding, the model is prevented from introducing irrelevant text, speculative summaries, or redundant framing..regex filters to strip markdown artifacts, list markers, and stray formatting. The function also ensures the output begins from the first valid section header to improve structural consistency.Finally, we'll build the complete user interface that brings together all our research capabilities into an interactive application.
def main():
st.set_page_config(page_title="Deep Research Assistant", page_icon="", layout="wide")
st.markdown("""
<div style="background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 1.25rem; border-radius: 10px; color: white; text-align: center; margin-bottom: 1rem;">
<h1 style="margin:0;"> Deep Research Assistant</h1>
</div>
""", unsafe_allow_html=True)
if 'research_assistant' not in st.session_state:
config = ResearchConfig()
st.session_state.research_assistant = DeepResearchAssistant(config)
st.session_state.model_loaded = st.session_state.research_assistant.load_model()
st.session_state.research_results = None
if not st.session_state.research_assistant.config.search_api_key:
st.warning("SERPER_API_KEY not found in environment. Using fallback demo results.")
st.header("Research Configuration")
research_topic = st.text_area(
"Research Topic",
placeholder="e.g., Impact of artificial intelligence on healthcare efficiency and patient outcomes",
height=100
)
col1a, col1b = st.columns(2)
with col1a:
research_depth = st.selectbox(
"Research Depth",
["surface", "moderate", "deep", "comprehensive"],
index=1,
format_func=lambda x: {
"surface": "Surface (5-8 sources)",
"moderate": "Moderate (10-15)",
"deep": "Deep Dive (20-30)",
"comprehensive": "Comprehensive (40+)"
}[x]
)
focus_area = st.selectbox("Focus Area", ["general", "academic", "business", "technical", "policy"], index=0, format_func=str.title)
with col1b:
time_frame = st.selectbox(
"Time Frame",
["current", "recent", "comprehensive"],
index=1,
format_func=lambda x: {"current":"Current (≤6 months)","recent":"Recent (≤2 years)","comprehensive":"All time"}[x]
)
report_format = st.selectbox(
"Report Format",
["executive", "detailed", "academic", "presentation"],
index=1,
format_func=lambda x: {
"executive":"Executive Summary",
"detailed":"Detailed Analysis",
"academic":"Academic Style",
"presentation":"Presentation Format"
}[x]
)
if st.button("Start Deep Research", type="primary", use_container_width=True):
if not st.session_state.model_loaded:
st.error("Model not loaded. See terminal logs for details.")
elif not research_topic.strip():
st.error("Please enter a research topic.")
else:
start_research(research_topic, research_depth, focus_area, time_frame, report_format)
if st.session_state.research_results:
display_research_results(st.session_state.research_results)
def start_research(topic: str, depth: str, focus: str, timeframe: str, format_type: str):
assistant = st.session_state.research_assistant
progress_bar = st.progress(0)
status_text = st.empty()
try:
status_text.text("Generating search queries...")
progress_bar.progress(15)
queries = assistant.generate_search_queries(topic, focus, depth)
status_text.text("Searching sources...")
progress_bar.progress(40)
all_results = []
for i, query in enumerate(queries):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
results = loop.run_until_complete(assistant.search_web(query, 5))
all_results.extend(results)
loop.close()
progress_bar.progress(40 + int(((i + 1) / max(1, len(queries))) * 30))
time.sleep(0.05)
status_text.text("Synthesizing report...")
progress_bar.progress(80)
research_report = assistant.synthesize_research(topic, all_results, focus, format_type)
status_text.text("Done.")
progress_bar.progress(100)
st.session_state.research_results = {
'topic': topic,
'report': research_report,
'sources': all_results,
'queries': queries,
'config': {'depth': depth, 'focus': focus, 'timeframe': timeframe, 'format': format_type},
'timestamp': datetime.now()
}
time.sleep(0.3)
status_text.empty()
progress_bar.empty()
except Exception as e:
st.error(f"Research failed: {str(e)}")
status_text.empty()
progress_bar.empty()
def display_research_results(results: Dict):
st.header("Research Report")
st.subheader(f"Topic: {results['topic']}")
st.markdown(
f'<div style="background:#f8f9ff;padding:1rem;border-radius:10px;border:1px solid #e1e8ed;">{results["report"]}</div>',
unsafe_allow_html=True,
)
with st.expander("Sources", expanded=False):
for i, source in enumerate(results['sources'][:12]):
st.markdown(f"""
<div style="background:#fff;padding:0.75rem;border-radius:8px;border:1px solid #e1e8ed;margin:0.4rem 0;">
<h4 style="margin:0 0 .25rem 0;">{source['title']}</h4>
<p style="margin:0 0 .25rem 0;">{source['snippet']}</p>
<small><a href="{source['url']}" target="_blank">{source['url']}</a></small>
</div>
""", unsafe_allow_html=True)
st.markdown("### Export")
c1, c2, c3 = st.columns(3)
with c1:
report_text = f"Research Report: {results['topic']}\n\n{results['report']}"
st.download_button("Download Text", data=report_text, file_name=f"research_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt", mime="text/plain")
with c2:
json_data = json.dumps(results, default=str, indent=2)
st.download_button("Download JSON", data=json_data, file_name=f"research_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json", mime="application/json")
with c3:
if st.button("Start New Research"):
st.session_state.research_results = None
st.experimental_rerun()
if __name__ == "__main__":
main()
The above code is divided into layers from model loading and user input collection to query generation, web search, and final report synthesis. Let’s discuss these layers in detail:
DeepResearchAssistant is initialized once per session using st.session_state, preserving model state and avoiding repeated loading. asyncio, ensuring parallel query execution without blocking UI responsiveness.TXT or JSON format or re-run the workflow with a single click.To try it yourself, save the code as app.py and launch:
streamlit run app.pyLearn AI with these courses!
Course
Course
Course
Tutorial
Bhavishya Pandit
Tutorial
Aashi Dutt
Tutorial
Marie Fayard
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt
Tutorial
Aashi Dutt