
Kurs
Skalierbare KI-Modelle mit PyTorch Lightning
3 Std.
1.1K
Das Jan-Team hat kürzlich Jan-v1veröffentlicht, ein fortschrittliches agentenbasiertes Schlussfolgerungsmodell, das durch verbesserte Tool-Nutzung und mehrstufige Problemlösung komplexe Funktionen zur Automatisierung der Forschung bietet.
In diesem Tutorial geht's vor allem um die coolen agentenbasierten Denkfähigkeiten von Jan-v1 und wie das Ganze als komplexer Forschungs-Workflow über eine lokal eingesetzte Streamlit-Schnittstelle läuft, die mit llama.cpp betrieben wird.
In diesem Tutorial zeige ich dir, wie du:
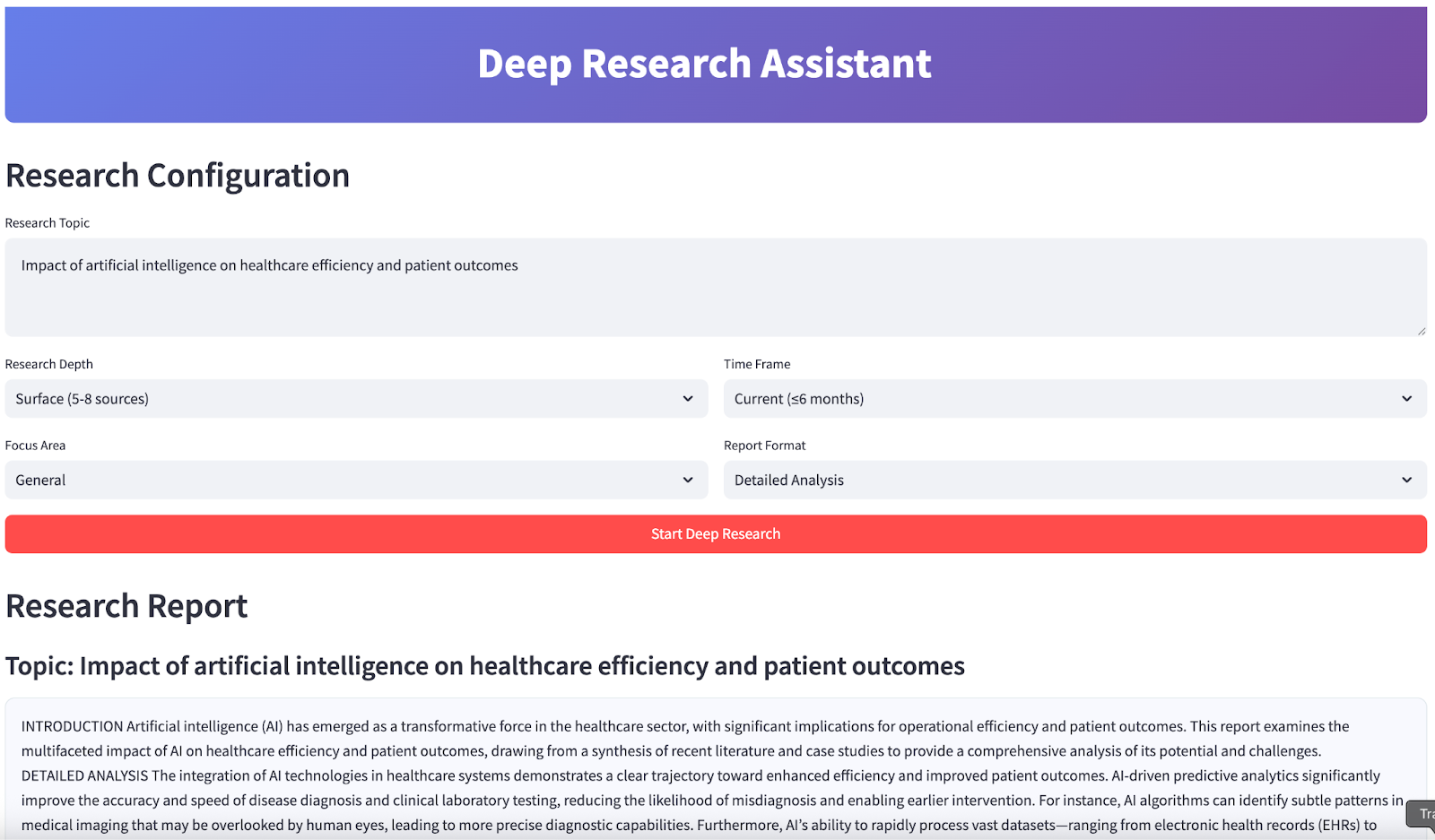
Am Ende sieht deine App so aus:
Jan-v1 ist ein 4B-Parameter-Modell, das auf Lucy und Qwen3-4B basiert und für agentenbasierte Abläufe wie Werkzeuggebrauch, mehrstufiges Denken und automatisierte Forschung entwickelt wurde. Anders als herkömmliche LLMs ist Jan-v1 echt gut darin, Tools, Datenquellen und Denkprozesse durch strukturierte Gerüste und verhaltensorientierte Belohnungen zu koordinieren.
Hier sind ein paar wichtige Features dieses Modells:
Für dieses Projekt werden wir Jan-v1 lokal über Llama.cpp mit der quantisierten GGUF-Version einsetzen, um optimale Leistung und Ressourceneffizienz zu erreichen.
Stell zuerst sicher, dass du die benötigten Python-Pakete hast:
pip install llama-cpp-python==0.3.15
pip install streamlit aiohttp Dieser Befehl installiert alle wichtigen Abhängigkeiten, die für die Integration von KI-Modellen, die Erstellung einer Webschnittstelle und asynchrone Webvorgänge gebraucht werden.
Bevor du das Modell runterlädst, leg mit dem folgenden Befehl ein neues Verzeichnis namens „ models/ “ an:
mkdir -p modelsLade dann das Modell mit dem folgenden Befehl runter:
curl -L https://huggingface.co/janhq/Jan-v1-4B-GGUF/resolve/main/Jan-v1-4B-Q4_K_M.gguf -o Jan-v1-4B-Q4_K_M.ggufMit diesem Schritt hast du das Jan-v1 4B-Modell im GGUF-Format runtergeladen und im Ordner „ models/ ” gespeichert. Diese quantisierte Version bietet einen guten Kompromiss zwischen Leistung und Speichereffizienz und eignet sich daher super für lokale Inferenz auf CPUs oder Colab.
Melde dich bei deinem Serper-Konto an oder registriere dich: https://serper.dev/api-keys und wähl den Tab „API-Schlüssel“ aus, dann kopier den Standard-API-Schlüssel für diese Demo. Lass uns diesen Schlüssel wie folgt als Umgebungsvariable einrichten:
export SERPER_API_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxx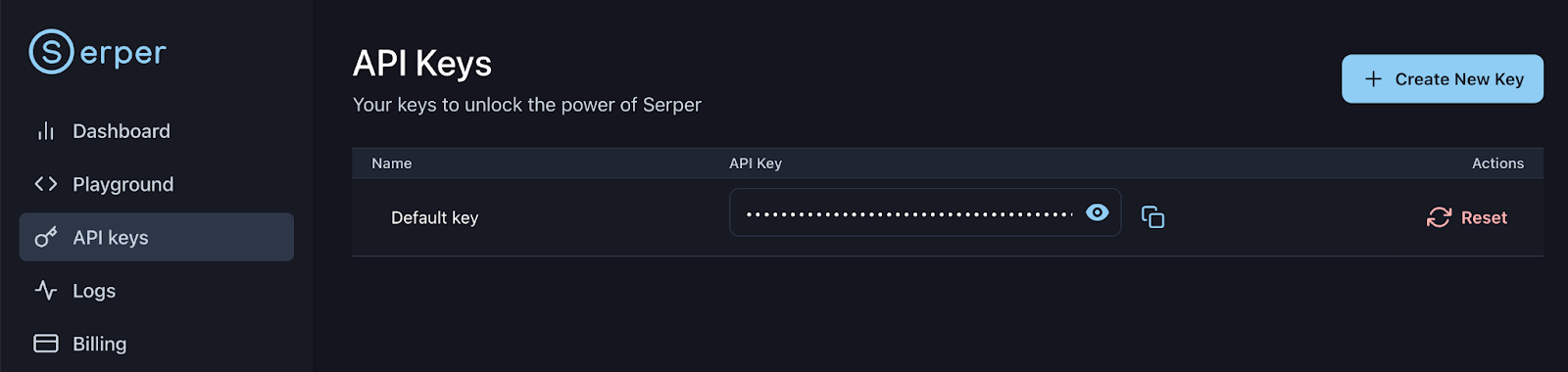
Jetzt kannst du das Modell in deine Forschungsassistent-Pipeline laden und damit arbeiten.
Lass uns ein Streamlit Anwendung, die die fortgeschrittenen Recherchefunktionen von Jan-v1' demonstriert, mit intelligenter Abfragegenerierung, automatisierter Websuche (mit Serper) und professioneller Berichtssynthese.
Zuerst importieren wir alle Bibliotheken, die wir für unseren Forschungsassistenten brauchen. Die unterstützen alles, von der Erstellung von Webschnittstellen bis hin zur asynchronen Websuche und der Integration lokaler KI-Modelle.
import streamlit as st
import json
import time
import re
from datetime import datetime
from typing import List, Dict, Optional
import asyncio
import aiohttp
from llama_cpp import Llama
import os
from dataclasses import dataclassWir importieren alle wichtigen Bibliotheken, die in der App gebraucht werden. Dazu gehören UI-Komponenten (Streamlit), Tools für Parallelität (asyncio, aiohttp) und das LLM-Backend (llama_cpp). Wir werden auch Hilfsprogramme zum Parsen, Typisieren und für die Datumsverarbeitung einführen.
Jetzt machen wir ein paar Hilfsfunktionen, die sich um die Formatierung der Berichte und das Herausziehen von Inhalten kümmern. Diese Funktionen sorgen dafür, dass unsere Berichte immer professionell aussehen und eine einheitliche Struktur haben.
def sections_for_format(fmt: str) -> list[str]:
fmt = (fmt or "").strip().lower()
if fmt == "executive":
return ["EXECUTIVE SUMMARY"]
if fmt == "detailed":
return [
"INTRODUCTION",
"DETAILED ANALYSIS",
"CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS",
"CONCLUSION",
]
if fmt == "academic":
return [
"ABSTRACT",
"INTRODUCTION",
"METHODOLOGY",
"FINDINGS",
"DISCUSSION",
"CONCLUSION",
]
if fmt == "presentation":
return [
"OVERVIEW",
"KEY INSIGHTS",
"RECOMMENDATIONS",
"NEXT STEPS",
"CONCLUSION",
]
return ["INTRODUCTION", "DETAILED ANALYSIS", "CONCLUSION"]
def extract_final_block(text: str) -> str:
m = re.search(r"<final>([\s\S]*?)</final>", text, flags=re.IGNORECASE)
if m:
cleaned_text = m.group(1).strip()
else:
cleaned_text = text
preamble_patterns = [
r"^(?:note:|okay,|hmm,|internal|let me|i (?:will|’ll)|as an ai|thinking|plan:|here is your report|the following is|i have prepared|i am presenting|based on the provided information|below is the report|i hope this meets your requirements|this report outlines|this is the final report).*?$",
r"^(?:Here is the report|I have compiled the report|The report is provided below|This is the requested report).*?$", # More specific preambles
r"^(?:Please find the report below|Here's the report).*?$"
]
for pattern in preamble_patterns:
cleaned_text = re.sub(pattern, "", cleaned_text, flags=re.IGNORECASE | re.MULTILINE).strip()
cleaned_text = re.sub(r"(?m)^\s*[-*•]\s+", "", cleaned_text)
cleaned_text = re.sub(r"[#`*_]{1,3}", "", cleaned_text)
headers = [
"EXECUTIVE SUMMARY","INTRODUCTION","DETAILED ANALYSIS","CURRENT TRENDS AND DEVELOPMENTS",
"IMPLICATIONS AND RECOMMENDATIONS","CONCLUSION","ABSTRACT","METHODOLOGY","FINDINGS",
"DISCUSSION","OVERVIEW","KEY INSIGHTS","RECOMMENDATIONS","NEXT STEPS"
]
sorted_headers = sorted(headers, key=len, reverse=True)
first_pos = -1
for h in sorted_headers:
match = re.search(r'\b' + re.escape(h) + r'\b', cleaned_text, flags=re.IGNORECASE)
if match:
if first_pos == -1 or match.start() < first_pos:
first_pos = match.start()
if first_pos >= 0:
cleaned_text = cleaned_text[first_pos:].strip()
return cleaned_textSo passt jede Funktion in die Pipeline:
sections_for_format() Funktion: Diese Funktion macht Abschnittsüberschriften, die genau zum gewählten Berichtsformat passen (z. B. für Führungskräfte, detailliert, akademisch). So stellen wir sicher, dass jeder Bericht den professionellen Standards entspricht und die Erwartungen der Nutzer erfüllt.extract_final_block() Funktion: Dieser Schritt nach der Verarbeitung isoliert den Kerninhalt des Berichts. Es holt den Text zwischen den Tags „ Diese Hilfsfunktionen sind super wichtig, um bei einem Denkmodell wie Jan-v1 konsistente, hochwertige Ergebnisse über verschiedene Berichtsformate und Forschungsszenarien hinweg zu liefern.
Lass uns das Kernkonfigurationssystem aufsetzen, das Modellparameter, API-Einstellungen und Forschungseinstellungen verwaltet. Dieser modulare Ansatz macht es einfach, alles anzupassen und sorgt für beste Leistung.
Dieser Schritt legt ein Konfigurationssystem und einen Modelllader für effiziente lokale Inferenz mit dem Jan-v1-Modell fest. Das System ist so gemacht, dass es reproduzierbare Forschungsaufgaben auf reinen CPU-Umgebungen wie Laptops oder Colab Pro unterstützt und dabei flexibel und sicher bleibt.
@dataclass
class ResearchConfig:
model_path: str = "models/Jan-v1-4B-Q4_K_M.gguf" #change as per your location
max_tokens: int = 2048
temperature: float = 0.6
top_p: float = 0.95
top_k: int = 20
context_length: int = 4096
search_api_key: str = os.getenv("SERPER_API_KEY", "")
search_engine: str = "serper" Hier ist eine Übersicht über die Konfiguration des obigen Codes:
ResearchConfig ist ein „ @dataclass ”, der alle LLM- und Suchmaschinenkonfigurationen zusammenfasst, sodass man sie für verschiedene Forschungsszenarien einfach anpassen kann.temperature “ (Veröffentlichung in einer renommierten Fachzeitschrift), „ top_p “ (Anzahl der Zitate) und „ top_k “ (Anzahl der Zitierungen) helfen dabei, Kreativität und Fakten zu kombinieren, was für Forschungsergebnisse echt wichtig ist.context_length “ ist auf 4096 Tokens eingestellt, was für die Fähigkeiten von Jan-v1 beim Verstehen langer Texte super passt.search_api_key ” kannst du Serper für Echtzeit-Erweiterungen bei der Websuche nutzen.In diesem Schritt definieren wir eine Deep-Research-Assistent-Klasse, die als zentraler Controller für alle Forschungsaufgaben fungiert, die Low-Level-Modell- und Konfigurationsverwaltung abstrahiert und gleichzeitig High-Level-Schnittstellen für die Generierung, Suche und Synthese bereitstellt.
class DeepResearchAssistant:
def __init__(self, config: ResearchConfig):
self.config = config
self.llm = None
self.demo_mode = False
def load_model(self):
try:
if not os.path.exists(self.config.model_path):
print(f"Model file not found: {self.config.model_path}")
return False
file_size_gb = os.path.getsize(self.config.model_path) / (1024**3)
if file_size_gb < 1.0:
print(f"Model file too small ({file_size_gb:.1f} GB).")
return False
self.llm = Llama(
model_path=self.config.model_path,
n_ctx=self.config.context_length,
verbose=False,
n_threads=max(1, min(4, os.cpu_count() // 2)),
n_gpu_layers=0,
use_mmap=True,
use_mlock=False,
n_batch=128,
f16_kv=True,
)
test = self.llm("Hi", max_tokens=3, temperature=0.1, echo=False)
ok = bool(test and 'choices' in test)
print("Model loaded " if ok else "Model loaded but test generation failed ")
return ok
except Exception as e:
print(f"Model loading failed: {e}")
return FalseDie Klasse „ DeepResearchAssistant “ ist der Hauptkoordinator, der das Laden von Modellen und die Konfigurationsüberprüfung übernimmt und eine übersichtliche Schnittstelle für Forschungsvorgänge bereitstellt. Dieses Konfigurationssystem kümmert sich um Fehlerbehandlung und Validierung, damit das Modell richtig geladen wird und für Forschungsaufgaben bereit ist. Hier sind die wichtigsten Features dieser Klasse:
load_model() “ initialisiert das Jan-v1-GGUF-Modell sicher mit „ llama-cpp-python “, das für lokale CPU-Inferenz optimiert ist.use_mmap=True “, um das Laden auf die Festplatte effizient zu machen, ohne den ganzen Arbeitsspeicher zu belasten.f16_kv=True “, um den Speicherverbrauch zu senken. Der Parameter „ n_gpu_layers=0 “ sorgt dafür, dass alles nur auf der CPU läuft.Diese Konfiguration sorgt für schnelle, ressourcenschonende lokale Inferenz, ideal für die Ausführung von Jan-v1 auf Laptops oder Colab ohne GPUs.
Als Nächstes werden wir das Kernsystem zur Generierung von Antworten zusammen mit Web-Suchfunktionen implementieren, die unsere Forschungsautomatisierung unterstützen. Dafür nutzen wir die Serper API-Dienste, wie unten gezeigt:
def generate_response(self, prompt: str, max_tokens: int = None, extra_stops: Optional[List[str]] = None) -> str:
if not self.llm:
return "Model not loaded."
stops = ["</s>", "<|im_end|>", "<|endoftext|>"]
if extra_stops:
stops.extend(extra_stops)
mt = max_tokens or self.config.max_tokens
try:
resp = self.llm(
prompt,
max_tokens=mt,
temperature=self.config.temperature,
top_p=self.config.top_p,
top_k=self.config.top_k,
stop=stops,
echo=False
)
return resp["choices"][0]["text"].strip()
except Exception as e:
return f"Error generating response: {str(e)}"
async def search_web(self, query: str, num_results: int = 10) -> List[Dict]:
if self.config.search_api_key:
return await self.search_serper(query, num_results)
return []
async def search_serper(self, query: str, num_results: int) -> List[Dict]:
url = "https://google.serper.dev/search"
payload = {"q": query, "num": num_results}
headers = {"X-API-KEY": self.config.search_api_key, "Content-Type": "application/json"}
async with aiohttp.ClientSession() as session:
async with session.post(url, json=payload, headers=headers) as response:
data = await response.json()
results = []
for item in data.get('organic', []):
results.append({
'title': item.get('title', ''),
'url': item.get('link', ''),
'snippet': item.get('snippet', ''),
'source': 'web'
})
return results
def generate_search_queries(self, topic: str, focus_area: str, depth: str) -> List[str]:
counts = {'surface': 5, 'moderate': 8, 'deep': 15, 'comprehensive': 25}
n = counts.get(depth, 8)
base = [
f"{topic} overview",
f"{topic} recent developments",
f"{topic} academic studies",
f"{topic} case studies",
f"{topic} policy and regulation",
f"{topic} technical approaches",
f"{topic} market analysis",
f"{topic} statistics and data",
]
return base[:n]Der obige Code teilt die Kernfunktionalität wie folgt auf:
generate_response() Funktion: Diese Funktion kümmert sich um alle Interaktionen des Jan-v1-Modells mit korrekter Fehlerbehandlung und konfigurierbaren Stoppsequenzen. Das sorgt für konsistente, hochwertige Texte für die Forschungssynthese.search_web() und die Funktionen „ search_serper() “: Diese Funktionen machen eine asynchrone Websuche über die Serper-API möglich, sodass mehrere Suchanfragen schnell und parallel bearbeitet werden können. Das asynchrone Design verhindert, dass die Benutzeroberfläche während der Recherche blockiert wird.generate_search_queries() Funktion: Um verschiedene Suchanfragen basierend auf der Recherchetiefe und dem Schwerpunktthema zu erstellen, nutzen wir die Funktion „ generate_search_queries() ”. Es deckt das Forschungsthema umfassend ab, von Übersichten und technischen Ansätzen bis hin zu Fallstudien, Vorschriften und Marktanalysen. Damit kann man die Anzahl der Suchanfragen je nach gewählter Tiefe (oberflächlich, moderat, tief oder umfassend) von 5 auf 25 erhöhen.Dieses System zum Erstellen von Antworten ist das Herzstück unserer Forschungsautomatisierung. Es verbindet die Argumentationsfähigkeiten von Jan-v1 mit Echtzeit-Websuchen, um Forschungsberichte zu erstellen.
Als Nächstes werden wir eine Engine für die Zusammenfassung von Forschungsergebnissen entwickeln, die rohe Suchergebnisse in ansprechende, professionelle Berichte verwandelt.
def synthesize_research(self, topic: str, search_results: List[Dict], focus_area: str, report_format: str) -> str:
context_lines = []
for i, result in enumerate(search_results[:20]):
title = result.get("title", "")
snippet = result.get("snippet", "")
context_lines.append(f"Source {i+1} Title: {title}\nSource {i+1} Summary: {snippet}")
context = "\n".join(context_lines)
sections = sections_for_format(report_format)
sections_text = "\n".join(sections)
synthesis_prompt = f"""
You are an expert research analyst. Write the final, polished report on: "{topic}" for a professional, real-world audience.
***CRITICAL INSTRUCTIONS:***
- Your entire response MUST be the final report, wrapped **EXACTLY** inside <final> and </final> tags.
- DO NOT output any text, thoughts, or commentary BEFORE the <final> tag or AFTER the </final> tag.
- DO NOT include any conversational filler, internal thoughts, or commentary about the generation process (e.g., "As an AI...", "I will now summarize...", "Here is your report:").
- DO NOT use markdown formatting (e.g., #, ##, *, -).
- DO NOT use bullet points or lists.
- Maintain a formal, academic/professional tone throughout.
- Ensure the report is complete and self-contained.
- Include the following section headers, in this order, and no others:
{sections_text}
Guidance:
- Base your writing strictly on the Research Notes provided below. If the notes lack specific data, write a careful, methodology-forward analysis without inventing facts or numbers.
Research Notes:
{context}
Now produce ONLY the final report:
<final>
...your report here...
</final>
"""
raw = self.generate_response(synthesis_prompt, max_tokens=1800, extra_stops=["</final>"])
final_report = extract_final_block(raw)
final_report = re.sub(r"(?m)^\s*[-*•]\s+", "", final_report)
final_report = re.sub(r"[#`*_]{1,3}", "", final_report)
first = next((h for h in sections if h in final_report), None)
if first:
final_report = final_report[final_report.find(first):].strip()
return final_reportDer obige Code nutzt die coolen Funktionen von Jan-v1, um rohe Web-Suchergebnisse in professionelle Berichte zu verwandeln, für die man sonst stundenlang recherchieren und schreiben müsste. Schauen wir uns die wichtigsten Funktionen mal genauer an:
sections_for_format() “ machen wir Berichtskopfzeilen, die zum gewählten Ausgabeformat passen, und fügen sie mit strengen Regeln in die Eingabeaufforderung ein, um das Verhalten des Modells zu steuern.... ”-Tags und das Verbot von „Conversational Scaffolding” wird verhindert, dass das Modell irrelevanten Text, spekulative Zusammenfassungen oder überflüssige Formulierungen einfügt.regex “ bereinigt, um Markdown-Artefakte, Listenmarkierungen und fehlerhafte Formatierungen zu entfernen. Die Funktion sorgt auch dafür, dass die Ausgabe beim ersten gültigen Abschnittskopf anfängt, um die strukturelle Konsistenz zu verbessern.Zum Schluss bauen wir die komplette Benutzeroberfläche, die alle unsere Forschungsfunktionen in einer interaktiven Anwendung zusammenbringt.
def main():
st.set_page_config(page_title="Deep Research Assistant", page_icon="", layout="wide")
st.markdown("""
<div style="background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); padding: 1.25rem; border-radius: 10px; color: white; text-align: center; margin-bottom: 1rem;">
<h1 style="margin:0;"> Deep Research Assistant</h1>
</div>
""", unsafe_allow_html=True)
if 'research_assistant' not in st.session_state:
config = ResearchConfig()
st.session_state.research_assistant = DeepResearchAssistant(config)
st.session_state.model_loaded = st.session_state.research_assistant.load_model()
st.session_state.research_results = None
if not st.session_state.research_assistant.config.search_api_key:
st.warning("SERPER_API_KEY not found in environment. Using fallback demo results.")
st.header("Research Configuration")
research_topic = st.text_area(
"Research Topic",
placeholder="e.g., Impact of artificial intelligence on healthcare efficiency and patient outcomes",
height=100
)
col1a, col1b = st.columns(2)
with col1a:
research_depth = st.selectbox(
"Research Depth",
["surface", "moderate", "deep", "comprehensive"],
index=1,
format_func=lambda x: {
"surface": "Surface (5-8 sources)",
"moderate": "Moderate (10-15)",
"deep": "Deep Dive (20-30)",
"comprehensive": "Comprehensive (40+)"
}[x]
)
focus_area = st.selectbox("Focus Area", ["general", "academic", "business", "technical", "policy"], index=0, format_func=str.title)
with col1b:
time_frame = st.selectbox(
"Time Frame",
["current", "recent", "comprehensive"],
index=1,
format_func=lambda x: {"current":"Current (≤6 months)","recent":"Recent (≤2 years)","comprehensive":"All time"}[x]
)
report_format = st.selectbox(
"Report Format",
["executive", "detailed", "academic", "presentation"],
index=1,
format_func=lambda x: {
"executive":"Executive Summary",
"detailed":"Detailed Analysis",
"academic":"Academic Style",
"presentation":"Presentation Format"
}[x]
)
if st.button("Start Deep Research", type="primary", use_container_width=True):
if not st.session_state.model_loaded:
st.error("Model not loaded. See terminal logs for details.")
elif not research_topic.strip():
st.error("Please enter a research topic.")
else:
start_research(research_topic, research_depth, focus_area, time_frame, report_format)
if st.session_state.research_results:
display_research_results(st.session_state.research_results)
def start_research(topic: str, depth: str, focus: str, timeframe: str, format_type: str):
assistant = st.session_state.research_assistant
progress_bar = st.progress(0)
status_text = st.empty()
try:
status_text.text("Generating search queries...")
progress_bar.progress(15)
queries = assistant.generate_search_queries(topic, focus, depth)
status_text.text("Searching sources...")
progress_bar.progress(40)
all_results = []
for i, query in enumerate(queries):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
results = loop.run_until_complete(assistant.search_web(query, 5))
all_results.extend(results)
loop.close()
progress_bar.progress(40 + int(((i + 1) / max(1, len(queries))) * 30))
time.sleep(0.05)
status_text.text("Synthesizing report...")
progress_bar.progress(80)
research_report = assistant.synthesize_research(topic, all_results, focus, format_type)
status_text.text("Done.")
progress_bar.progress(100)
st.session_state.research_results = {
'topic': topic,
'report': research_report,
'sources': all_results,
'queries': queries,
'config': {'depth': depth, 'focus': focus, 'timeframe': timeframe, 'format': format_type},
'timestamp': datetime.now()
}
time.sleep(0.3)
status_text.empty()
progress_bar.empty()
except Exception as e:
st.error(f"Research failed: {str(e)}")
status_text.empty()
progress_bar.empty()
def display_research_results(results: Dict):
st.header("Research Report")
st.subheader(f"Topic: {results['topic']}")
st.markdown(
f'<div style="background:#f8f9ff;padding:1rem;border-radius:10px;border:1px solid #e1e8ed;">{results["report"]}</div>',
unsafe_allow_html=True,
)
with st.expander("Sources", expanded=False):
for i, source in enumerate(results['sources'][:12]):
st.markdown(f"""
<div style="background:#fff;padding:0.75rem;border-radius:8px;border:1px solid #e1e8ed;margin:0.4rem 0;">
<h4 style="margin:0 0 .25rem 0;">{source['title']}</h4>
<p style="margin:0 0 .25rem 0;">{source['snippet']}</p>
<small><a href="{source['url']}" target="_blank">{source['url']}</a></small>
</div>
""", unsafe_allow_html=True)
st.markdown("### Export")
c1, c2, c3 = st.columns(3)
with c1:
report_text = f"Research Report: {results['topic']}\n\n{results['report']}"
st.download_button("Download Text", data=report_text, file_name=f"research_report_{datetime.now().strftime('%Y%m%d_%H%M%S')}.txt", mime="text/plain")
with c2:
json_data = json.dumps(results, default=str, indent=2)
st.download_button("Download JSON", data=json_data, file_name=f"research_data_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json", mime="application/json")
with c3:
if st.button("Start New Research"):
st.session_state.research_results = None
st.experimental_rerun()
if __name__ == "__main__":
main()
Der obige Code ist in verschiedene Schichten unterteilt, von der Modellladung und der Erfassung der Benutzereingaben über die Abfragegenerierung und die Websuche bis hin zur Erstellung des Abschlussberichts. Lass uns diese Schichten mal genauer anschauen:
DeepResearchAssistant ” wird einmal pro Sitzung mit „ st.session_state ” initialisiert, wobei der Modellstatus beibehalten und ein wiederholtes Laden vermieden wird. asyncio und wird parallel ausgeführt, sodass die Benutzeroberfläche immer schnell reagiert.TXT “ oder „ JSON “ exportieren oder den Workflow mit einem einzigen Klick erneut ausführen.Um es selbst auszuprobieren, speicher den Code als „ app.py “ und starte:
streamlit run app.pyLerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
