La mayoría de los proveedores de LLM, como OpenAI y Anthropic, ofrecen API fáciles de usar para integrar sus modelos en aplicaciones de IA personalizadas. Pero esta facilidad de uso tiene un coste: ya no podrás utilizar interfaces web familiares como ChatGPT o Claude. Tu aplicación será independiente y estará escrita en un montón de scripts.
Por esta razón, es crucial aprender a envolver el código de tu aplicación con una interfaz de usuario amigable para que los usuarios externos y las partes interesadas sin conocimientos técnicos puedan interactuar con ella.
En este tutorial, aprenderás a construir UIs Streamlit para aplicaciones basadas en LLM construidas con LangChain. El tutorial será práctico: utilizaremos una base de datos real de la historia del fútbol internacional para construir un chatbot que pueda responder a preguntas sobre partidos históricos y detalles de competiciones internacionales. Puedes jugar con la aplicación o verla en acción a continuación:
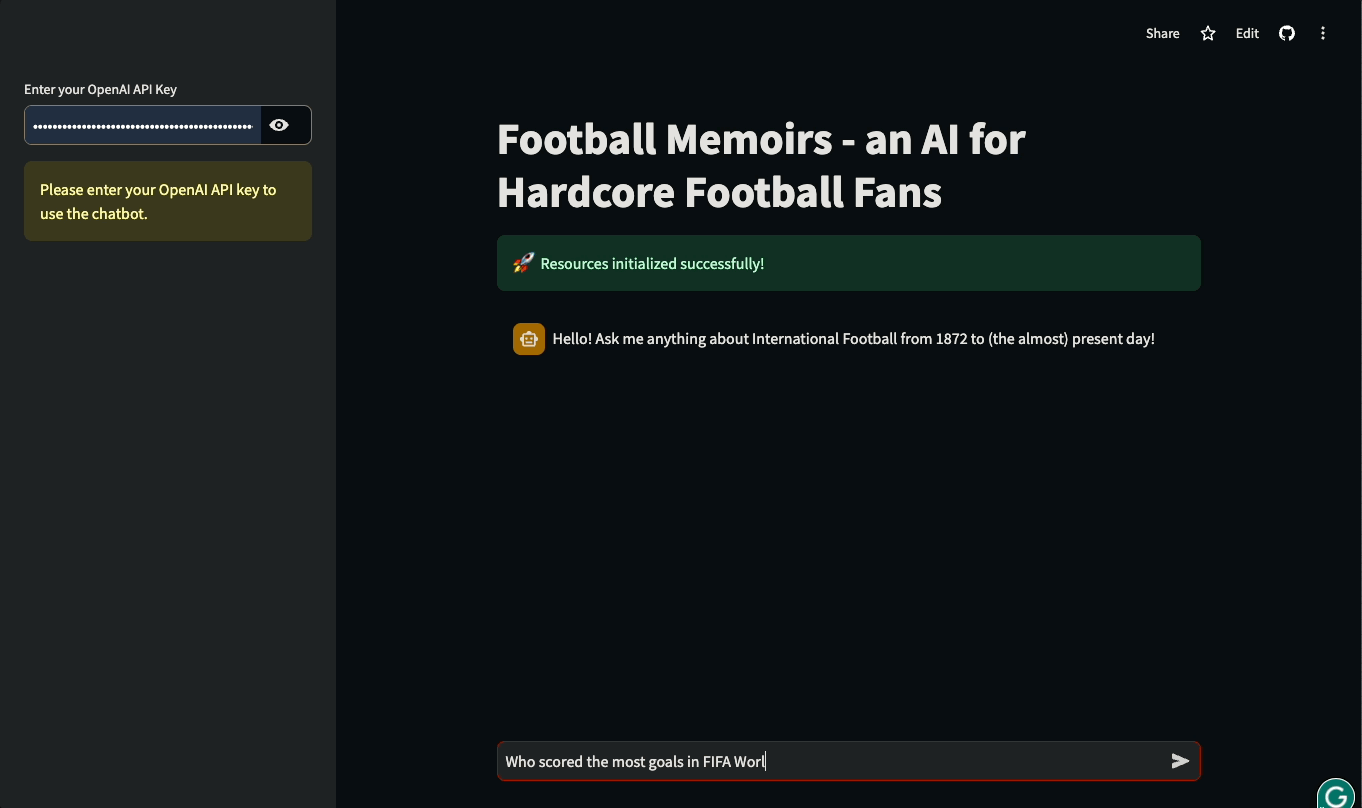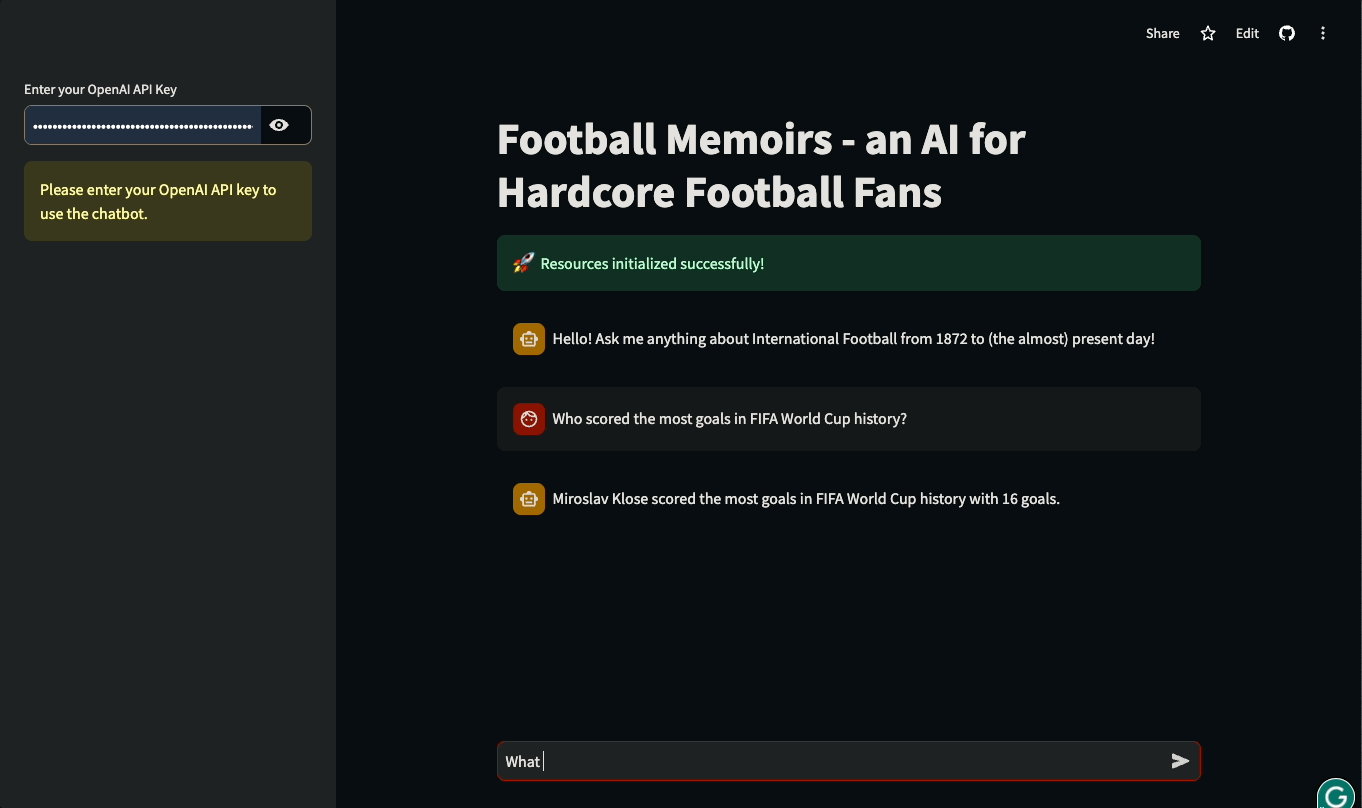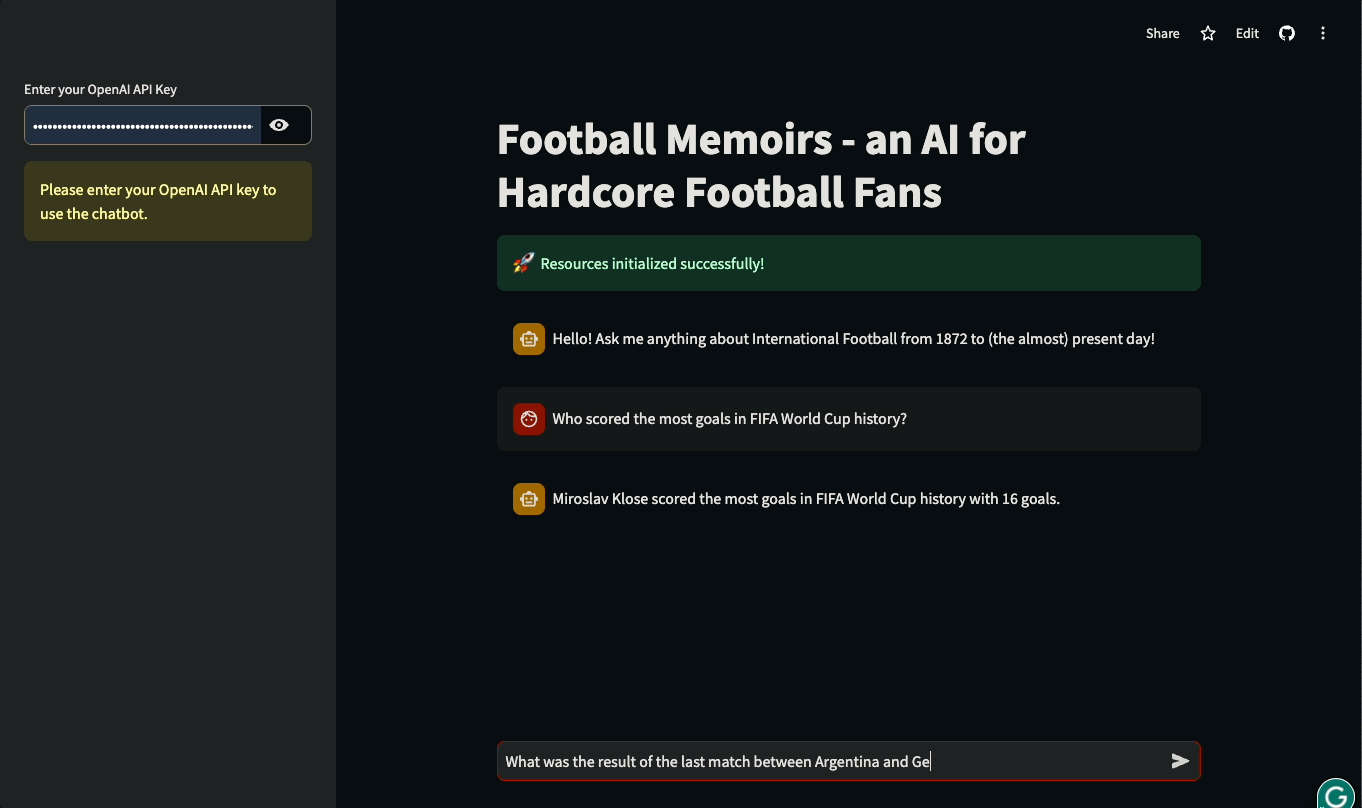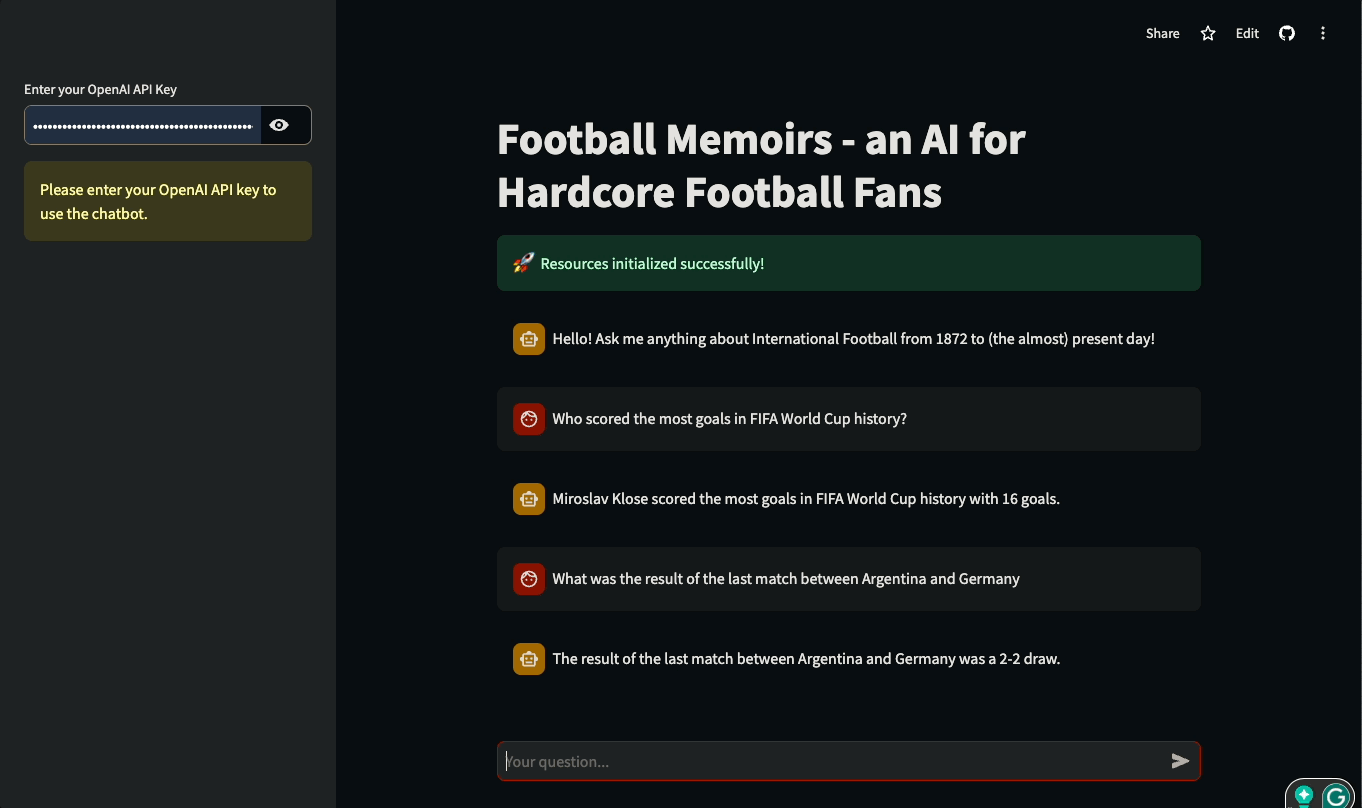
¡Sumerjámonos y empecemos a construir!
Repaso de Conceptos Prerrequisito
Utilizaremos una combinación de diferentes herramientas para construir el chatbot que has visto antes, así que repasemos brevemente los propósitos de cada una.
Streamlit
La primera herramienta es Streamlitque es, con diferencia, el marco más popular para crear aplicaciones web utilizando sólo Python. Tiene más de 35.000 estrellas y lo utilizan la mayoría de las empresas de Fortune 50.
Streamlit ofrece un rico conjunto de componentes web incorporados para mostrar datos y medios, así como elementos para recibir entradas del usuario. Con el auge de los LLM, ahora tienen componentes para mostrar los mensajes de chat producidos tanto por los usuarios como por los LLM y un campo de entrada de texto para escribir indicaciones, parecido a la interfaz de ChatGPT.
Si eres completamente nuevo en Streamlit, lee nuestro artículo introductorio sobre el framework.
LangChain
Aunque los proveedores de LLM tienen APIs fáciles de usar para los desarrolladores, su funcionalidad no lo abarca todo. Integrarlas con las herramientas de código abierto existentes requiere mucho tiempo y esfuerzo.
Por eso el marco LangChain nació. Reúne casi todos los principales LLM bajo una sintaxis unificada y proporciona utilidades para simplificar el proceso de construcción de aplicaciones complejas de IA. LangChain ofrece una amplia gama de herramientas y componentes que permiten a los desarrolladores crear potentes sistemas de IA con menos código y mayor flexibilidad.
Algunas características clave de LangChain son
- Integración perfecta con varios proveedores de LLM
- Soporte integrado para ingeniería y gestión rápidas
- Herramientas para la gestión de memoria y estados en la IA conversacional
- Utilidades para la carga, transformación y vectorización de datos
- Componentes para construir cadenas y agentes para la automatización de tareas complejas
En el tutorial, utilizaremos LangChain para integrarnos con los modelos GPT de OpenAI, gestionar nuestro historial de conversaciones y construir nuestro pipeline de recuperación para acceder a la base de datos del fútbol.
Lee nuestra guía para principiantes sobre LangChain para lo básico.
Bases de datos gráficas, Neo4j y AuraDB
La segunda estructura de base de datos más popular (después de la tabular) es la gráfica. Las bases de datos gráficas su adopción es cada vez mayor por su capacidad innata de almacenar información interconectada. Nuestra base de datos de Fútbol Internacional es un ejemplo perfecto.
Las bases de datos de grafos están formadas por nodos y las relaciones entre ellos. Por ejemplo, si consideramos los términos clave del fútbol como nodos de un gráfico, la forma en que se relacionan entre sí representa las relaciones entre nodos. En ese caso, los nodos son jugadores, partidos, equipos, competiciones, etc. Las relaciones serían:
- El jugador JUEGA EN un partido
- Los equipos PARTICIPAN en un partido
- El partido es PARTE de una competición
Entonces, los nodos y las relaciones podrían tener propiedades como
- Jugador: edad, posición, nacionalidad
- Partido: equipo local, equipo visitante, resultado, lugar
- JUEGOS EN (relación): número de goles marcados, número de minutos jugados
etc.
Neo4j es el sistema de gestión más popular para este tipo de bases de datos gráficas. Su lenguaje de consulta, Cypheres muy similar a SQL, pero está diseñado específicamente para recorrer estructuras gráficas complejas. LangChain utilizará el cliente Python oficial de Neo4j para generar y ejecutar consultas Cypher en nuestra base de datos gráfica. Consulta nuestro tutorial de Neo4j para obtener más información.
Hablando de eso, nuestra base de datos está alojada en una instancia en la nube de Aura DB. Aura DB forma parte de Neo4j y proporciona una plataforma segura para gestionar bases de datos gráficas en la nube.
Recuperación Generación Aumentada
Los LLM reciben formación sobre grandes cantidades de datos, pero no tienen acceso a bases de datos privadas propiedad de empresas. Por eso, el caso de uso más popular de los LLM en la empresa es Generación Aumentada de Recuperación (GRA).
En el GAR, el LLM se aumenta con información relevante recuperada de una base de conocimientos o base de datos antes de generar una respuesta. Este proceso suele implicar los siguientes pasos:
- Comprensión de la consulta: El sistema analiza la consulta del usuario para comprender su intención y sus elementos clave.
- Recuperación de información: En función del análisis de la consulta, se recupera la información relevante de la base de datos conectada o de la base de conocimientos.
- Aumento del contexto: La información recuperada se añade al aviso enviado al LLM, proporcionándole un contexto específico, actualizado y relevante.
- Generación de respuestas: El LLM genera una respuesta basada tanto en su conocimiento preentrenado como en el contexto adicional proporcionado.
- Refinamiento de la salida: La respuesta generada puede seguir procesándose o filtrándose para garantizar su precisión y pertinencia.
La RAG permite a los LLM acceder a información específica, actual y propia, y utilizarla, lo que los hace más útiles para aplicaciones especializadas, al tiempo que mantienen sus capacidades generales de comprensión lingüística.
En nuestro caso, utilizaremos la RAG para aumentar nuestro LLM con información de nuestra base de datos de fútbol, lo que le permitirá responder a preguntas específicas sobre jugadores, partidos y competiciones a las que, de otro modo, no tendría acceso.
Puedes adquirir experiencia práctica en la aplicación de RAG utilizando nuestro proyecto guiado sobre la construcción de un chatbot RAG para documentación técnica.
Comprender los datos
Echemos un vistazo a nuestra base de datos gráfica antes de empezar a construirla. A continuación se visualiza el esquema del gráfico:

El gráfico tiene seis tipos de nodos: jugador, equipo, partido, torneo, ciudad y país. Estos nodos están conectados por varias relaciones, como Equipo_JUGÓ_EN_CASA en un partido o Jugador_PUNTUÓ_POR_un_equipo. Este esquema se basa en los datos disponibles en el siguiente conjunto de datos de Kaggle:
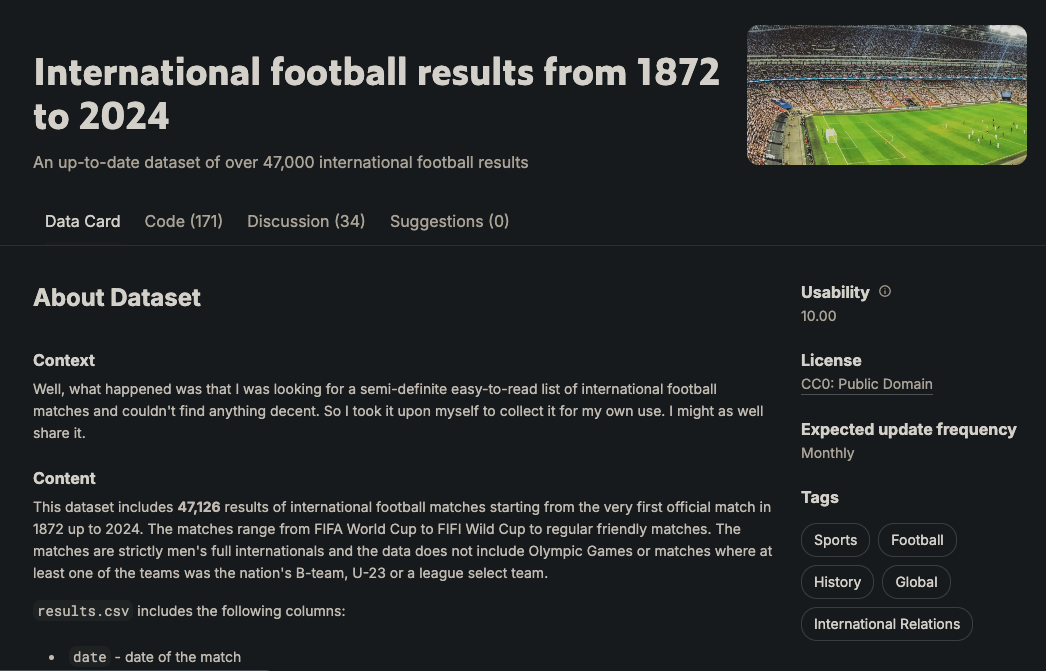
Contiene más de 47.000 partidos, sus resultados, los goles marcados en cada partido, quién los marcó y algunas propiedades adicionales como minutos de gol, goles en propia puerta y sedes de los partidos.
Los datos están originalmente en formato CSV, pero he podido ingerirlos en una instancia de Aura DB utilizando el controlador Python de Neo4j y consultas Cypher (consulta el código en nuestro tutorial de Neo4j).
El objetivo de nuestra aplicación es generar consultas Cypher a partir de los datos introducidos por el usuario, ejecutar las consultas en nuestra base de datos gráfica y presentar los resultados en un formato legible para el ser humano.
Así que, por fin, vamos a construirlo.
Construir un Chatbot RAG Gráfico en LangChain
Abordaremos este problema paso a paso, desde la creación de un entorno de trabajo hasta el despliegue de la aplicación mediante Streamlit Cloud.
1. Configurar el entorno
Empecemos creando un nuevo entorno Conda con Python 3.9 y activémoslo:
$ conda create -n football_chatbot python=3.9 -y
$ conda activate football_chatbotNecesitaremos instalar las siguientes bibliotecas:
$ pip install streamlit langchain langchain-openai langchain_community neo4jAhora, vamos a crear nuestro directorio de trabajo y a rellenar su estructura:
$ mkdir football_chatbot; cd football_chatbot
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,app.py}Escribiremos nuestra aplicación dentro de app.py mientras que secrets.toml dentro del directorio.streamlit servirá como nuestro archivo de credenciales. Ábrelo y pega los tres secretos siguientes:
NEO4J_URI = "neo4j+s://eed9dd8f.databases.neo4j.io"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "ivbSF02UWzHeHuzBIePyOH5cQ4LdyRxLeNbWvdpPA4k"Estas credenciales te dan acceso a la instancia de Aura DB que almacena la base de datos del fútbol. Si deseas crear tu propia instancia con los mismos datos, consulta nuestro tutorial sobre Neo4jque cubre exactamente ese paso.
2. Importar bibliotecas y cargar los secretos
Ahora, vamos a trabajar en el archivoapp.py. En la parte superior, importa los módulos y paquetes necesarios y carga los secretos utilizando st.secrets:
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
# Load secrets
neo4j_uri = st.secrets["NEO4J_URI"]
neo4j_user = st.secrets["NEO4J_USER"]
neo4j_password = st.secrets["NEO4J_PASSWORD"]Esto es lo que hace cada clase:
Neo4jGraph: Una clase abreviada para conectarse a bases de datos Neo4j existentes y consultarlas con Cypher.GraphCypherQAChain: una clase global para realizar RAG de grafos en bases de datos de grafos. Pasando nuestro grafo cargado con Neo4jGraph, podemos generar consultas Cypher con lenguaje natural utilizando esta clase.ChatOpenAI: Da acceso a la API de Finalizaciones de Chat de OpenAI.
3. Añadir autenticación
Para evitar usos malintencionados y costes elevados, deberíamos añadir una autenticación que pida el token de la API OpenAI del usuario. Esto se puede conseguir añadiendo un formulario de contraseña a la barra lateral izquierda utilizando el elemento st.sidebar:
# Set the app title
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")En cuanto el usuario cargue nuestra aplicación, se le presentará el campo de entrada y no se mostrará nada más (excepto el título de la aplicación) hasta que proporcione su clave.
4. Conéctate a la base de datos Neo4j e inicializa una cadena de control de calidad
Después de recuperar la clave de la API OpenAI del usuario, podemos inicializar nuestros recursos: el grafo Neo4j y la clase de cadena QA:
# Initialize connections and models
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password,
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chainLa funcióninit_resources() acepta la clave API como argumento y establece una conexión con la base de datos gráfica. A continuación, actualiza el esquema (estructura) del grafo para que el LLM pueda disponer de información actualizada sobre la estructura de la base de datos cuando formule consultas Cypher. Por último, inicializa el GraphCypherQAChain con el grafo y el modelo OpenAI, devolviendo tanto el grafo como los objetos de la cadena para su uso posterior en la aplicación.
Cabe destacar el uso del decoradorst.cache_resource(). Este decorador almacena en caché las instancias del grafo y de la cadena, lo que mejora el rendimiento. No necesitamos crear nuevas instancias cada vez que un usuario carga la aplicación, por lo que almacenarlas en caché es un enfoque eficiente.
Vamos a ejecutar el inicializador con una comprobación de clave API:
# Initialize resources only if API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")5. Añadir historial de mensajes a Streamlit
En cuanto los recursos estén disponibles, tenemos que activar el historial de mensajes utilizando el estado de sesión de Streamlit. También queremos mostrar un mensaje inicial de IA que informe al usuario sobre lo que hace el bot.
Para ello, creamos una nueva clave messages en st.session_state y establecemos su valor en una lista con un solo elemento. El elemento es un diccionario con dos claves:
role: A quién pertenece el mensajecontent: El contenido del mensaje
# Initialize message history
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]En caso de que ya exista un historial de mensajes dentro st.session_state.messageslos mostramos con st.chat_message y st.markdown componentes:
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])6. Mostrar componentes del chat
Ahora, definimos una función, query_graph, que ejecutará la cadena utilizando un indicador proporcionado por el usuario. El método .invoke() de la cadena acepta un diccionario con un par de clave-valor de consulta y devuelve otro diccionario como salida. Queremos su clave result:
def query_graph(query):
try:
result = chain.invoke({"query": query})["result"]
return result
except Exception as e:
st.error(f"An error occurred: {str(e)}")
return "I'm sorry, I encountered an error while processing your request."Ahora, vamos a mostrar un campo de entrada en la parte inferior de la página utilizando el componente st.chat_input componente:
# Accept user input
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)En cuanto se proporciona el aviso, lo almacenamos como mensaje de usuario en el historial de mensajes y lo mostramos en la pantalla. A continuación, con otra comprobación de la clave API, ejecutamos la función query_graph, pasando la consulta:
if prompt := st.chat_input("Your question..."):
...
# Generate answer if API key is provided
if openai_api_key:
with st.spinner("Thinking..."):
response = query_graph(prompt)
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error("Please enter your OpenAI API key in the sidebar to use the chatbot.")Añadimos un widget spinner mientras se genera la consulta Cypher y la respuesta final. A continuación, mostramos el mensaje y lo añadimos al historial de mensajes.
Eso es. La aplicación ya está lista:
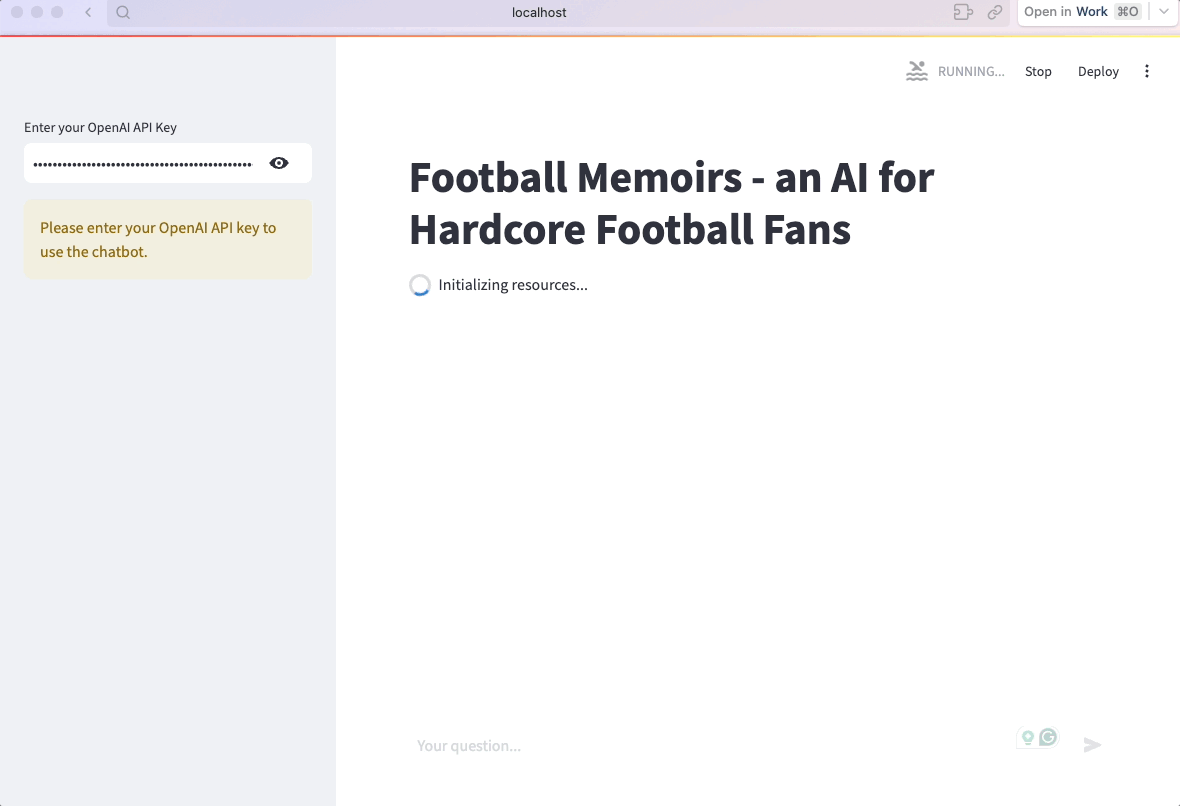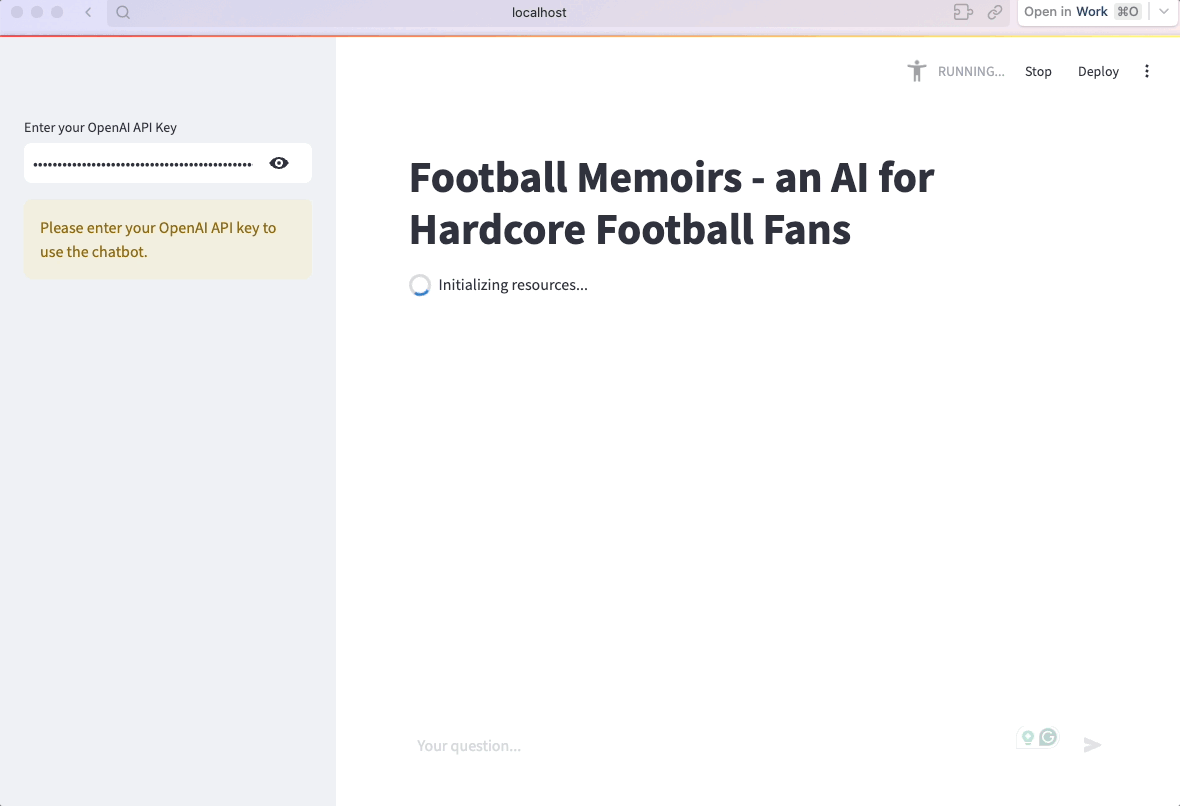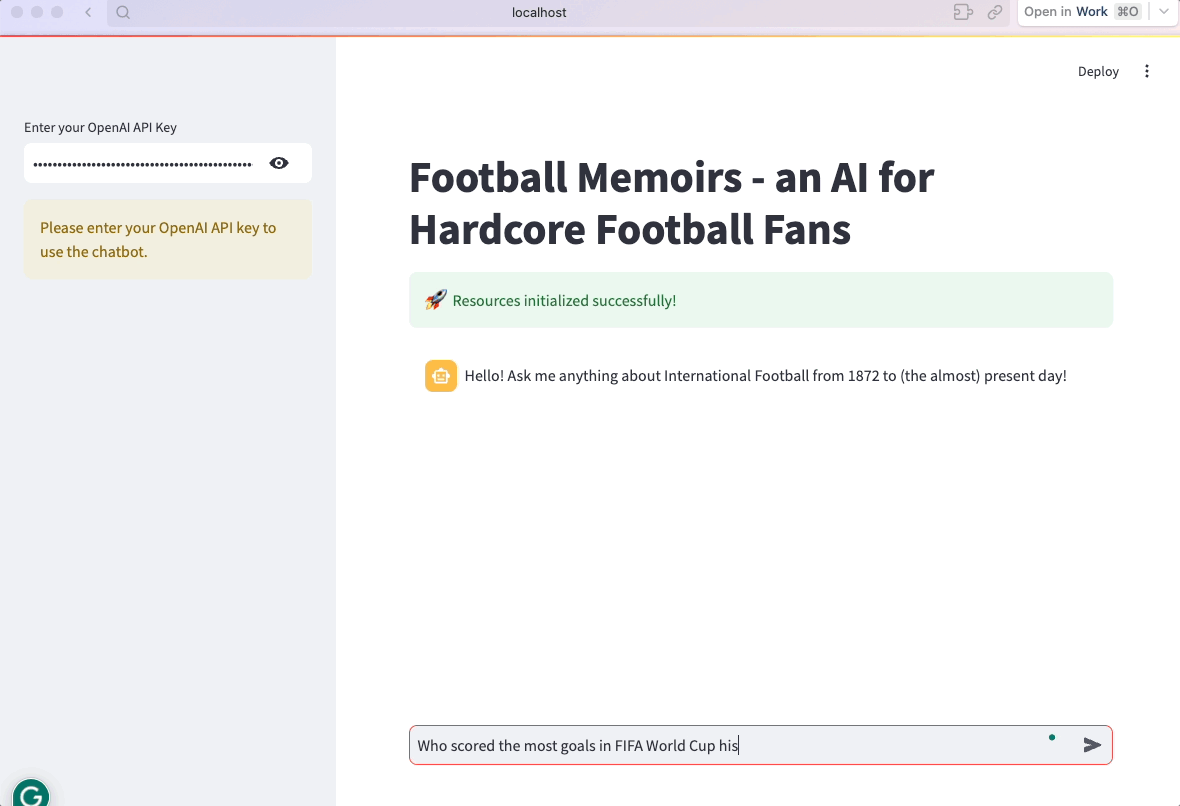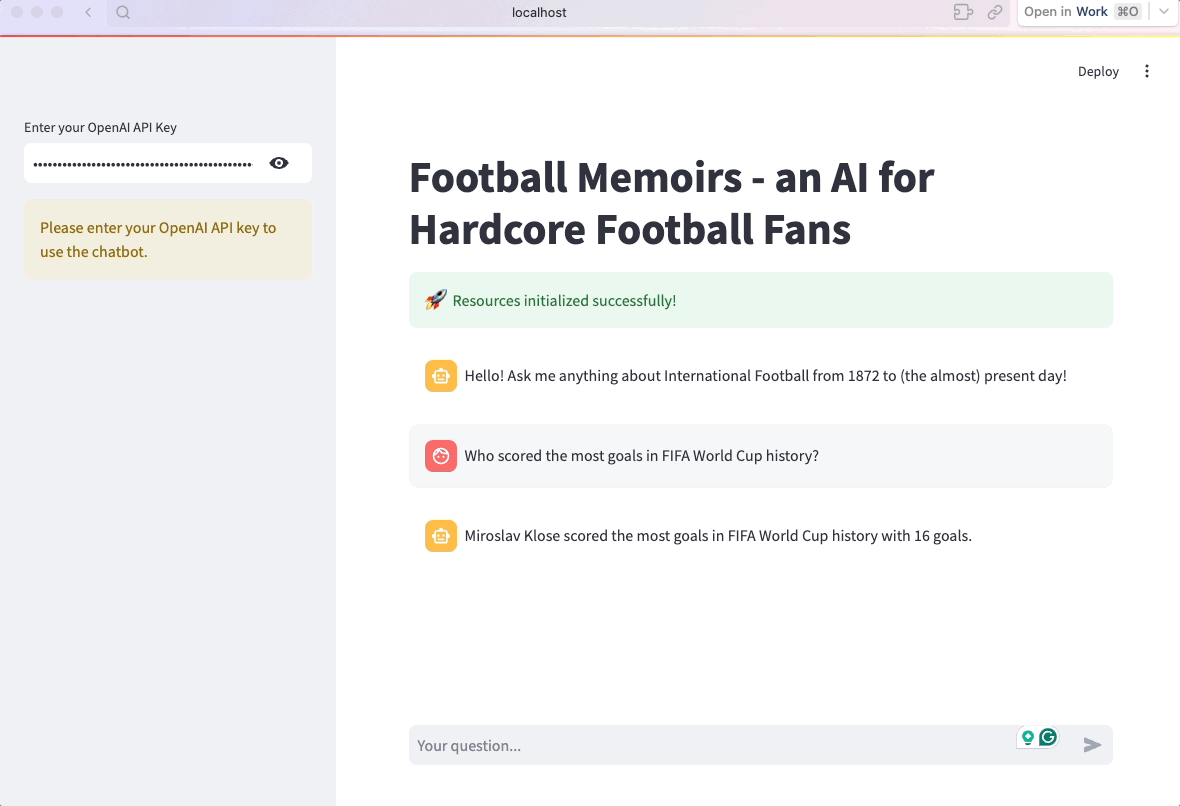
7. Optimizar y organizar el código
La aplicación está lista, pero está escrita en un único archivo sin ninguna estructura optimizada. Renovémoslo y hagámoslo modular:
$ cd football_chatbot
$ rm -rf . # Start from scratch
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,.gitignore,app.py,chat_utils.py,graph_utils.py,README.MD,requirements.txt}Esta vez, nuestra estructura de directorios contiene algunos archivos más:
.
├── .git
├── .gitignore
├── .streamlit
├── README.md
├── app.py
├── chat_utils.py
├── graph_utils.py
├── requirements.txtAhora, dentro de graph_utils.pypega el siguiente código organizado:
# graph_utils.py
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=st.secrets["NEO4J_URI"],
username=st.secrets["NEO4J_USER"],
password=st.secrets["NEO4J_PASSWORD"],
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chain
def query_graph(chain, query):
result = chain.invoke({"query": query})["result"]
return resultAquí, la diferencia está en la funciónquery_graph. Concretamente, no tiene tratamiento de errores ni visualización mediante la función st.error. Trasladaremos esa parte al archivo principal app.py.
Ahora, vamos a trabajar en el chat_utils.py archivo:
# chat_utils.py
import streamlit as st
def initialize_chat_history():
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]
def display_chat_history():
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])En primer lugar, creamos dos funciones:
initialize_chat_history: Habilita el historial de mensajes con un mensaje por defecto si no está ya disponible.display_chat_history: Mostrar todos los mensajes del historial de mensajes.
Creamos otra función para gestionar las preguntas y la generación de respuestas:
# chat_utils.py
def handle_user_input(openai_api_key, query_graph_func, chain):
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
if openai_api_key:
with st.spinner("Thinking..."):
try:
response = query_graph_func(chain=chain, query=prompt)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
response = "I'm sorry, I encountered an error while processing your request."
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error(
"Please enter your OpenAI API key in the sidebar to use the chatbot."
)La diferencia aquí es el uso de un bloque try-except alrededor de query_graph_func para atrapar y mostrar los errores. El resto de la funcionalidad es la misma.
Finalmente, dentro app.pylo juntamos todo:
import streamlit as st
from graph_utils import init_resources, query_graph
from chat_utils import initialize_chat_history, display_chat_history, handle_user_input
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Importamos las funciones de otros archivos, establecemos el título de la aplicación y añadimos el campo de entrada de la clave API a la barra lateral izquierda. A continuación, bajo una comprobación de clave API, inicializamos los recursos y mostramos el historial de mensajes de chat y los componentes:
# Initialize resources only if the API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")
# Initialize and display chat history
initialize_chat_history()
display_chat_history()
# Handle user input
handle_user_input(
openai_api_key=openai_api_key, query_graph_func=query_graph, chain=chain
)Ahora, ¡la aplicación está lista para su despliegue!
8. Despliega la aplicación en Streamlit Cloud
El método más sencillo y sin complicaciones para desplegar aplicaciones Streamlit es utilizar Streamlit Cloud. Todas las aplicaciones alojadas en Streamlit Cloud son gratuitas siempre que utilices el hardware predeterminado.
Pero primero, añadamos estas dos líneas a nuestro archivo .gitignore para que los secretos de nuestra aplicación no aparezcan en GitHub:
*.toml
__pycache__Además, todo (buen) repositorio necesita un archivo README. Así que escribamos la nuestra:
# Football Memoirs - AI for Hardcore Football Fans
This Streamlit app uses a Neo4j graph database and OpenAI's GPT-4o model to answer questions about international football history from 1872 to the present day.
## Setup
1. Clone this repository
2. Install dependencies: pip install -r requirements.txt
3. Set up your .streamlit/secrets.toml file with the following keys:
- NEO4J_URI
- NEO4J_USER
- NEO4J_PASSWORD
4. Run the app: streamlit run app.py
## Deployment
To deploy this app on Streamlit Cloud:
1. Push your code to a GitHub repository
2. Connect your GitHub account to Streamlit Cloud
3. Create a new app in Streamlit Cloud and select your repository
4. Add your secrets in the Streamlit Cloud dashboard under the "Secrets" section
5. Deploy your appLas aplicaciones de Streamlit Cloud necesitan un archivorequirements.txt para poblar los entornos con dependencias. Añádelos a los tuyos:
streamlit
langchain
langchain-community
langchain-openai
neo4jAhora, inicializamos git, hacemos nuestro primer commit, y lo empujamos al repositorio remoto que deberías haber creado para el proyecto:
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin https://github.com/Username/repository.git
$ git push --set-upstream origin mainA continuación, regístrate en Streamlit Cloud, visita tu panel de control y haz clic en "Crear app":
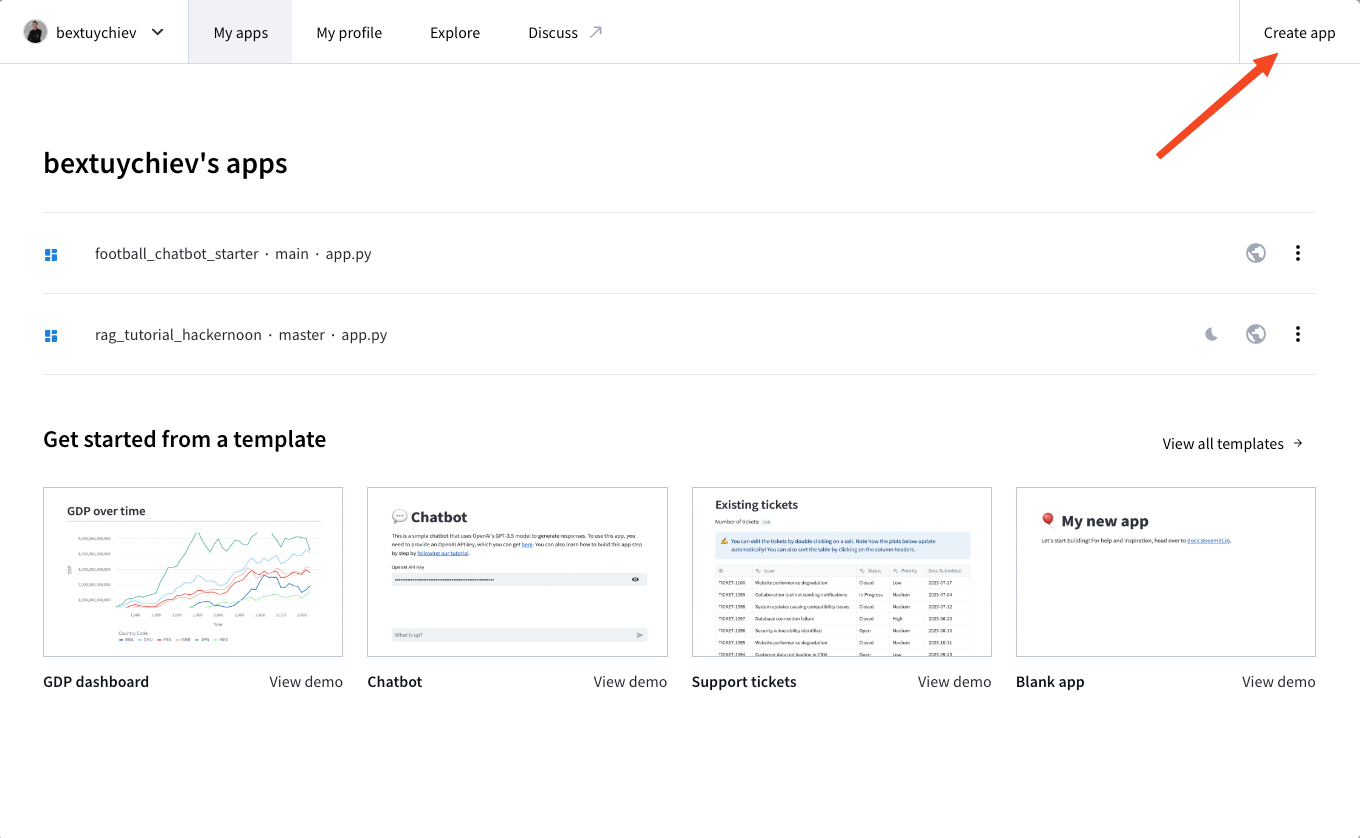
Se te presentarán las siguientes opciones:
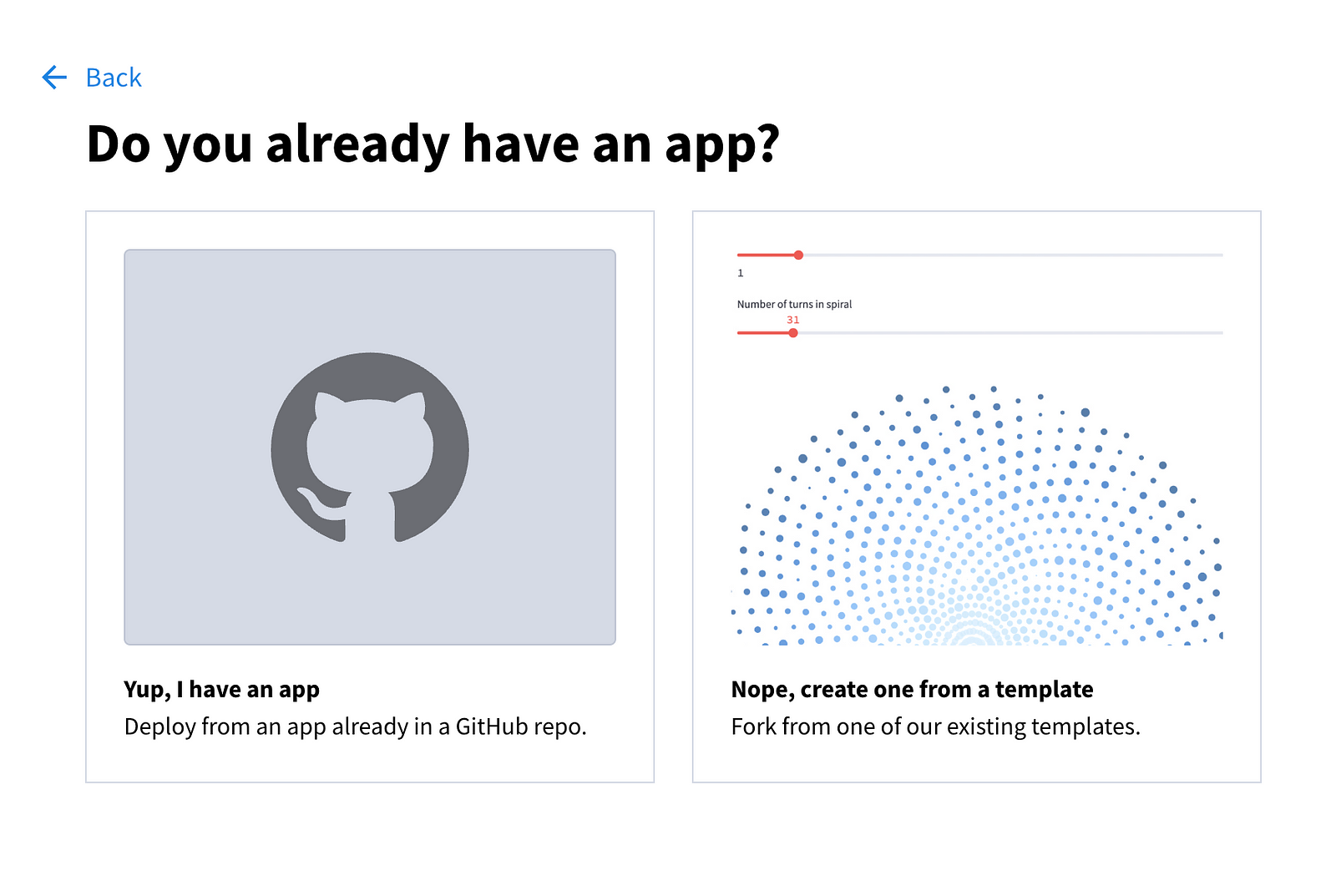
Elige la primera opción y rellena los campos de la página siguiente.
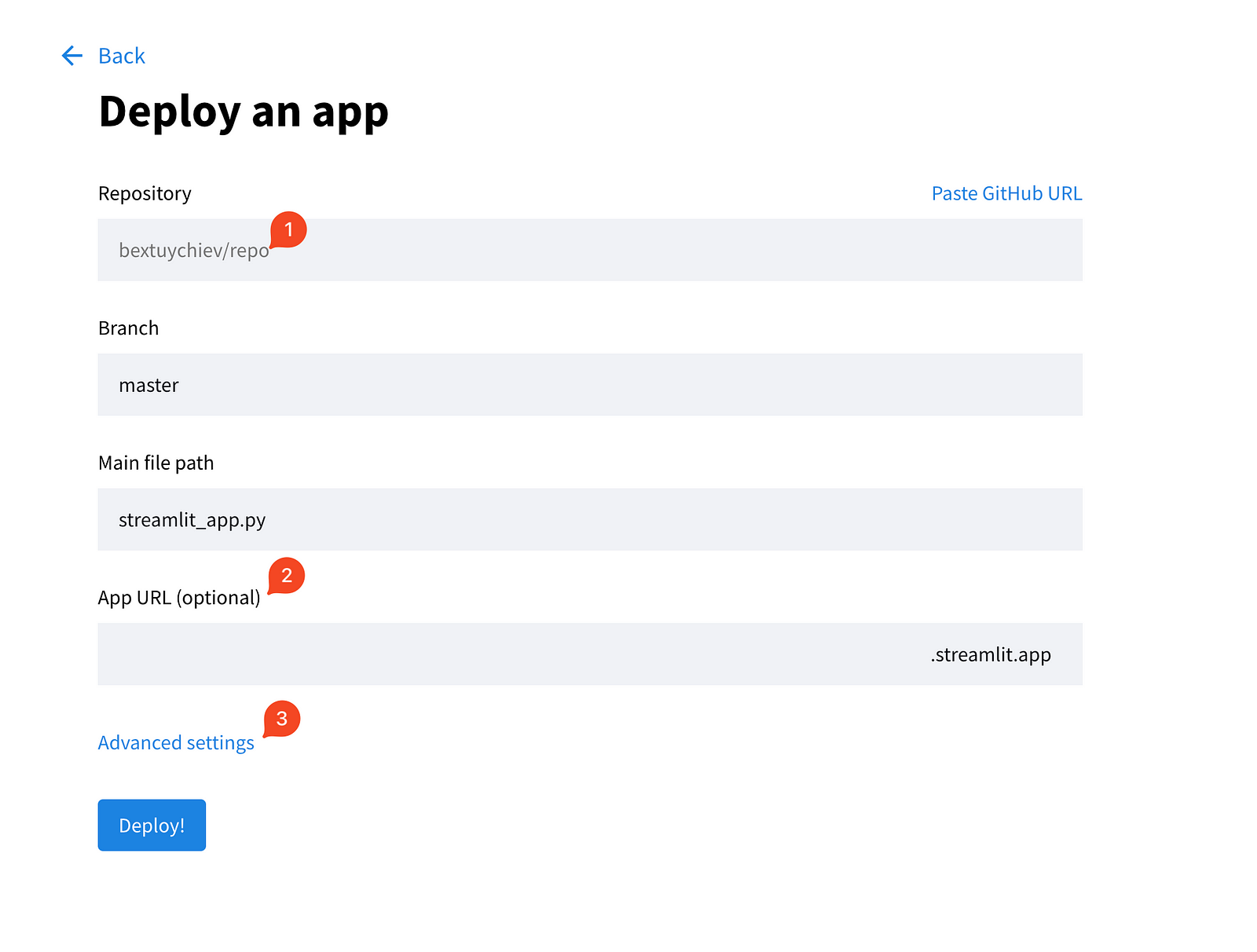
Además, amplía la configuración avanzada, que te ofrece dos campos para elegir la versión de Python y pegar las credenciales que necesite tu aplicación. Aquí es donde copias/pegas el contenido del archivo local secrets.toml:
Guarda los secretos y haz clic en "¡Desplegar!". La aplicación debería estar operativa en un par de minutos.
Conclusión
En este tutorial, hemos construido un chatbot de IA que responde a preguntas sobre la historia del fútbol internacional utilizando Streamlit, LangChain y una base de datos de grafos Neo4j. Lo hemos cubierto:
- Crear una interfaz web fácil de usar con Streamlit
- Integración de los modelos GPT de OpenAI con una base de datos de grafos mediante LangChain
- Implantación de la Generación Aumentada de Recuperación (RAG)
- Construir una base de código modular
- Despliegue en Streamlit Cloud
Este proyecto sirve de plantilla para crear interfaces de usuario de IA de chat. Aunque la lógica de la aplicación es diferente en cada proyecto, los componentes de interfaz de usuario que hemos utilizado hoy se emplearán en la mayoría de ellos de alguna manera.
Además, ten en cuenta que la construcción de la interfaz de usuario es la parte más fácil de construir aplicaciones de IA. La mayor parte de tu tiempo se dedicará a perfeccionar el rendimiento de la aplicación. Por ejemplo, nuestro proceso de generación de Cypher aún necesita mucho trabajo. Debido a la falta de ejemplos, la vaga estructura del grafo y las limitaciones de los LLM, la precisión de nuestra aplicación no es aceptable para la producción. Ten en cuenta estos aspectos al crear tus aplicaciones.
Si te interesa saber más sobre desarrollo de grandes modelos lingüísticosecha un vistazo a nuestra pista de habilidades, que cubre cómo construir LLM con PyTorch y Hugging Face, utilizando las últimas técnicas de aprendizaje profundo y PNL.



