Programa
Engenheiro de dados Em Python
40 h
Como cientistas de dados, normalmente não nos envolvemos com a implantação e a manutenção - criamos os modelos estatísticos e os engenheiros fazem o resto.
No entanto, as coisas estão começando a mudar!
Com a crescente demanda por cientistas de dados que possam preencher a lacuna entre a criação e a produção de modelos, familiarizar-se com as ferramentas de automação e CI/CD (integração contínua/implantação contínua) pode ser uma vantagem estratégica.
Neste tutorial, você aprenderá sobre duas ferramentas de automação populares: Make (automação local) e GitHub Actions (automação baseada na nuvem). Nosso foco principal será a incorporação dessas ferramentas em nossos projetos de dados.

GitHub Action e Make. Imagem de Abid Ali Awan.
Se você quiser saber mais sobre automação no contexto da ciência de dados, confira este curso sobre MLOps totalmente automatizados.
Um Makefile é um plano para criar e gerenciar projetos de software. É um arquivo que contém instruções para automatizar tarefas, simplificar processos de compilação complexos e garantir a consistência.
Para executar os comandos no Makefile, usamos a ferramenta de linha de comando make. Essa ferramenta pode ser executada como um programa Python, se você fornecer os argumentos ou simplesmente executá-la por conta própria.
Um Makefile geralmente consiste em uma lista de alvos, dependências, ações e variáveis:
python test.py.python test.py $variable_1 $variable_2.Em resumo, é assim que o modelo de um MakeFile poderia ser:
Variable = some_value
Target: Dependencies
Actions (commands to build the target) $VariableUsando nossos exemplos acima, o MakeFile poderia ter a seguinte aparência:
# Define variables
variable_1 = 5
variable_2 = 10
# Target to run a test with variables
test: test_data.txt # Dependency on test data file
python test.py $variable_1 $variable_2Podemos instalar a ferramenta Make CLI em todos os sistemas operacionais.
No Linux, precisamos usar o seguinte comando no terminal:
$ sudo apt install makeNo macOS, podemos usar o homebrew para instalar o make:
$ brew install makeO Windows é um pouco diferente. A ferramenta Make pode ser usada de várias maneiras. As opções mais populares são WSL (Ubuntu Linxus), w64devkit e GnuWin32.
Vamos baixar e instalar o GnuWin32 da página do SourceForge.
Para usá-lo como uma ferramenta de linha de comando no terminal, precisamos adicionar o local da pasta à variável de ambiente do Windows. Essas são as medidas que podemos tomar:
Para testar se o Make foi instalado com êxito, você pode digitar make -h no PowerShell.
Nesta seção, aprenderemos a usar as ferramentas Makefile e Make CLI em um projeto de ciência de dados.
Usaremos o conjunto de dados do World Happiness Report 2023 para cobrir o processamento de dados, a análise e o salvamento de resumos e visualizações de dados.
Para começar, você deve acessar o diretório do projeto e criar uma pasta chamada Makefile-Action. Em seguida, criamos o arquivo data_processing.py dentro dessa pasta e iniciamos o editor VSCode.
$ cd GitHub
$ mkdir Makefile-Action
$ cd .\Makefile-Action\
$ code data_processing.pyComeçamos com o processamento de nossos dados usando Python. No bloco de código abaixo, executamos as seguintes etapas (observação: este é um código de exemplo - em um cenário real, provavelmente teríamos que executar mais etapas):
Arquivo: data_processing.py
import sys
import pandas as pd
# Check if the data location argument is provided
if len(sys.argv) != 2:
print("Usage: python data_processing.py <data_location>")
sys.exit(1)
# Load the raw dataset (step 1)
df = pd.read_csv(sys.argv[1])
# Rename columns to more descriptive names (step 2)
df.columns = [
"Country",
"Happiness Score",
"Happiness Score Error",
"Upper Whisker",
"Lower Whisker",
"GDP per Capita",
"Social Support",
"Healthy Life Expectancy",
"Freedom to Make Life Choices",
"Generosity",
"Perceptions of Corruption",
"Dystopia Happiness Score",
"GDP per Capita",
"Social Support",
"Healthy Life Expectancy",
"Freedom to Make Life Choices",
"Generosity",
"Perceptions of Corruption",
"Dystopia Residual",
]
# Handle missing values by replacing them with the mean (step 3)
df.fillna(df.mean(numeric_only=True), inplace=True)
# Check for missing values after cleaning
print("Missing values after cleaning:")
print(df.isnull().sum())
print(df.head())
# Save the cleaned and normalized dataset to a new CSV file (step 4)
df.to_csv("processed_data\WHR2023_cleaned.csv", index=False)Agora, continuamos com a análise dos dados e salvamos todo o nosso código em um arquivo chamado data_analysis.py. Você pode criar esse arquivo com o seguinte comando no terminal:
$ code data_analysis.pyTambém podemos usar o comando echo para criar o arquivo Python e abri-lo em um editor de código diferente.
$ echo "" > data_analysis.pyNo bloco de código a seguir, você pode
Arquivo: data_analysis.py
import io
import sys
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
# Check if the data location argument is provided
if len(sys.argv) != 2:
print("Usage: python data_analysis.py <data_location>")
sys.exit(1)
# Load the clean dataset (step 1)
df = pd.read_csv(sys.argv[1])
# Data summary (step 2)
print("Data Summary:")
summary = df.describe()
data_head = df.head()
print(summary)
print(data_head)
# Collecting data information
buffer = io.StringIO()
df.info(buf=buffer)
info = buffer.getvalue()
## Write metrics to file
with open("processed_data/summary.txt", "w") as outfile:
f"\n## Data Summary\n\n{summary}\n\n## Data Info\n\n{info}\n\n## Dataframe\n\n{data_head}"
print("Data summary saved in processed_data folder!")
# Distribution of Happiness Score (step 3)
plt.figure(figsize=(10, 6))
sns.displot(df["Happiness Score"])
plt.title("Distribution of Happiness Score")
plt.xlabel("Happiness Score")
plt.ylabel("Frequency")
plt.savefig("figures/happiness_score_distribution.png")
# Top 20 countries by Happiness Score
top_20_countries = df.nlargest(20, "Happiness Score")
plt.figure(figsize=(10, 6))
sns.barplot(x="Country", y="Happiness Score", data=top_20_countries)
plt.title("Top 20 Countries by Happiness Score")
plt.xlabel("Country")
plt.ylabel("Happiness Score")
plt.xticks(rotation=90)
plt.savefig("figures/top_20_countries_by_happiness_score.png")
# Scatter plot of Happiness Score vs GDP per Capita
plt.figure(figsize=(10, 6))
sns.scatterplot(x="GDP per Capita", y="Happiness Score", data=df)
plt.title("Happiness Score vs GDP per Capita")
plt.xlabel("GDP per Capita")
plt.ylabel("Happiness Score")
plt.savefig("figures/happiness_score_vs_gdp_per_capita.png")
# Visualize the relationship between Happiness Score and Social Support
plt.figure(figsize=(10, 6))
plt.scatter(x="Social Support", y="Happiness Score", data=df)
plt.xlabel("Social Support")
plt.ylabel("Happiness Score")
plt.title("Relationship between Social Support and Happiness Score")
plt.savefig("figures/social_support_happiness_relationship.png")
# Heatmap of correlations between variables
corr_matrix = df.drop("Country", axis=1).corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm", square=True)
plt.title("Correlation Heatmap")
plt.savefig("figures/correlation_heatmap.png")
print("Visualizations saved to figures folder!")Antes de criarmos um Makefile, precisamos configurar um arquivo requirements.txt para instalar todos os pacotes Python necessários em uma nova máquina. É assim que o arquivo requirements.txt se parecerá:
pandas
numpy
seaborn
matplotlib
blackNosso Makefile consiste em variáveis, dependências, alvos e ações - aprenderemos todos os blocos de construção. Criamos um arquivo chamado Makefile e começamos a adicionar as ações para os alvos:
Arquivo: Arquivo de criação
RAW_DATA_PATH = "raw_data/WHR2023.csv"
PROCESSED_DATA = "processed_data/WHR2023_cleaned.csv"
install:
pip install --upgrade pip &&\
pip install -r requirements.txt
format:
black *.py --line-length 88
process: ./raw_data/WHR2023.csv
python data_processing.py $(RAW_DATA_PATH)
analyze: ./processed_data/WHR2023_cleaned.csv
python data_analysis.py $(PROCESSED_DATA)
clean:
rm -f processed_data/* **/*.png
all: install format process analyzePara executar o alvo, usaremos a ferramenta make e forneceremos o nome do alvo no terminal.
$ make formatO script Black foi executado com êxito.

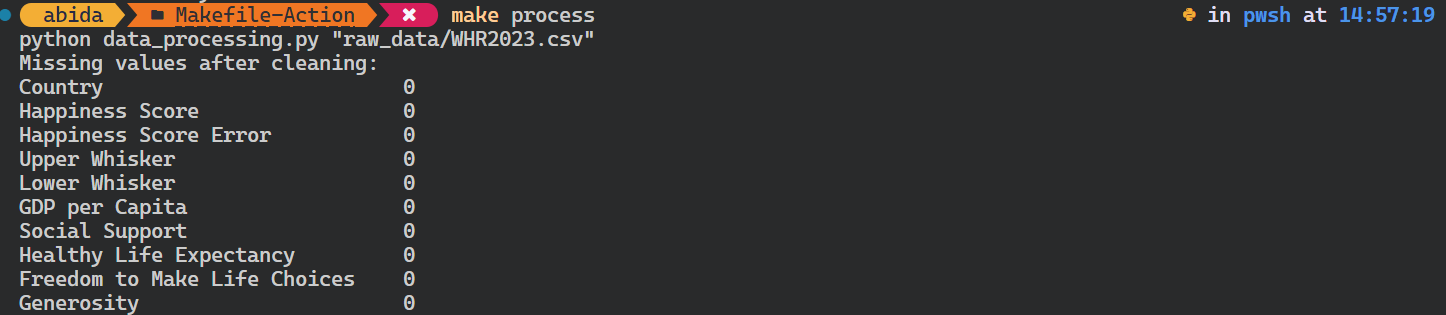
Vamos tentar executar o script Python para processamento de dados.
É importante observar que ele verifica as dependências do alvo antes de executar o alvo process. No nosso caso, ele verifica se o arquivo de dados brutos existe. Se isso não acontecer, o comando não será iniciado.
$ make processComo você pode ver, é muito simples.
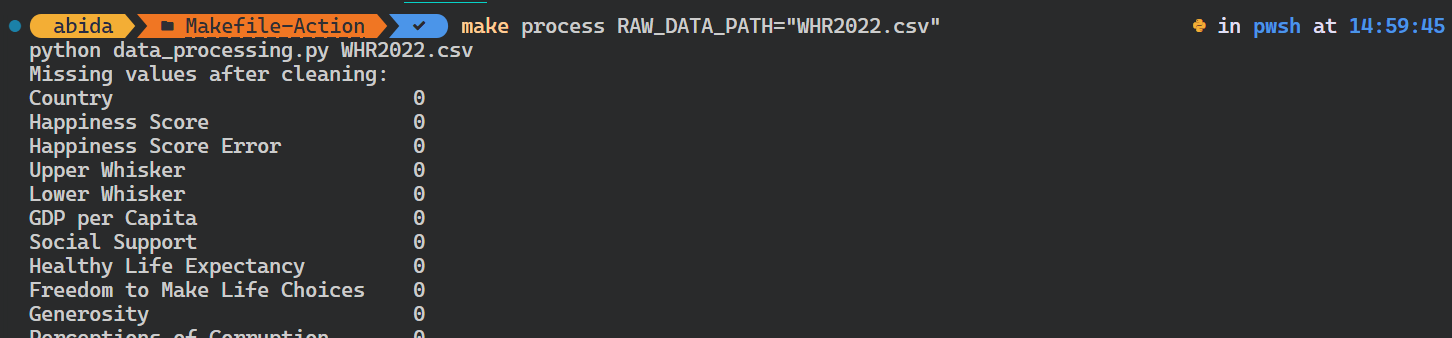
Você pode até mesmo substituir a variável existente fornecendo um argumento adicional ao comando make.
Em nosso caso, alteramos o caminho dos dados brutos.
$ make process RAW_DATA_PATH="WHR2022.csv"O script Python foi executado com o argumento de entrada diferente.
Para automatizar todo o fluxo de trabalho, usaremos o site all como alvo, que aprenderá, instalará, formatará, processará e analisará os alvos um a um.
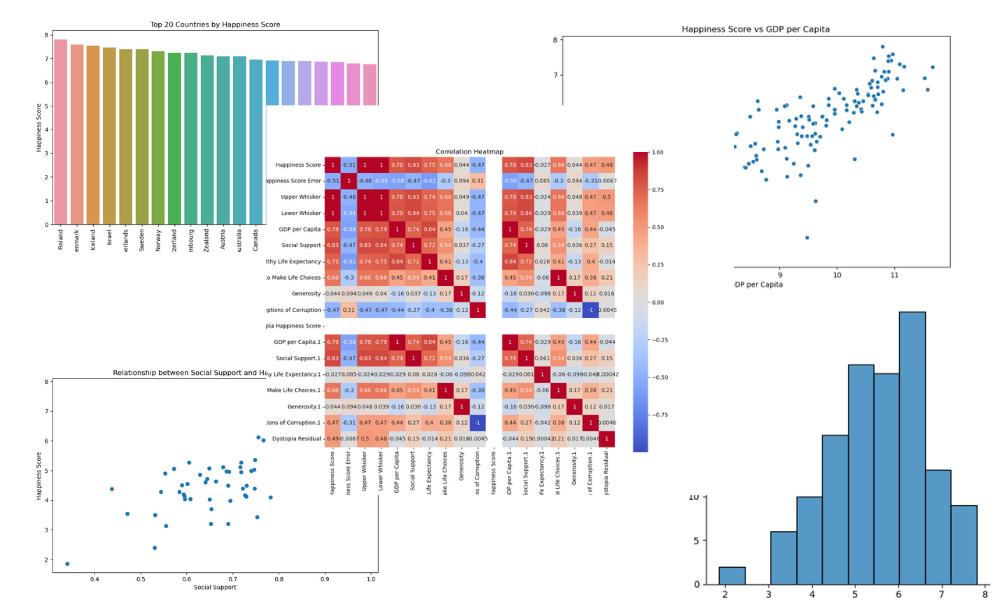
$ make allO comando make instalou os pacotes Python, formatou o código, processou os dados e salvou o resumo e as visualizações.
É assim que o diretório do projeto deve ficar depois que você executar o comando make all:
Embora o Make seja excelente para a automação local em nosso ambiente de desenvolvimento, o GitHub Actions oferece uma alternativa baseada na nuvem.
O GitHub Actions é geralmente usado para CI/CD, o que permite que os desenvolvedores compilem, criem, testem e implantem o aplicativo na produção diretamente do GitHub.
Por exemplo, podemos criar um fluxo de trabalho personalizado que será acionado com base em eventos específicos, como solicitações push ou pull. Esse fluxo de trabalho executará scripts de shell e scripts Python, ou podemos até mesmo usar ações pré-construídas. O fluxo de trabalho personalizado é um arquivo YML e, em geral, é bastante simples de entender e começar a escrever execuções e ações personalizadas.
Vamos explorar os principais componentes do GitHub Actions:
Nesta seção, aprenderemos a usar o GitHub Actions e tentaremos replicar os comandos que usamos anteriormente no Makefile.
Para transferir nosso código para o GitHub, temos que converter nossa pasta de projeto em um repositório Git usando:
$ git initEm seguida, criamos um novo repositório no GitHub e copiamos a URL.
No terminal, digitamos os comandos abaixo para você:
master para a filial remota main.$ git remote add github https://github.com/kingabzpro/Makefile-Actions.git
$ git pull github main
$ git add .
$ git commit -m "adding all the files"
$ git push github master:mainComo observação lateral, se você precisar de uma breve recapitulação sobre o GitHub ou o Git, confira este tutorial para iniciantes sobre o GitHub e o Git. Ele ajudará você a versionar seu projeto de ciência de dados e compartilhá-lo com a equipe usando a ferramenta Git CLI.
Continuando nossa lição, vemos que todos os arquivos foram transferidos com sucesso para o repositório remoto.
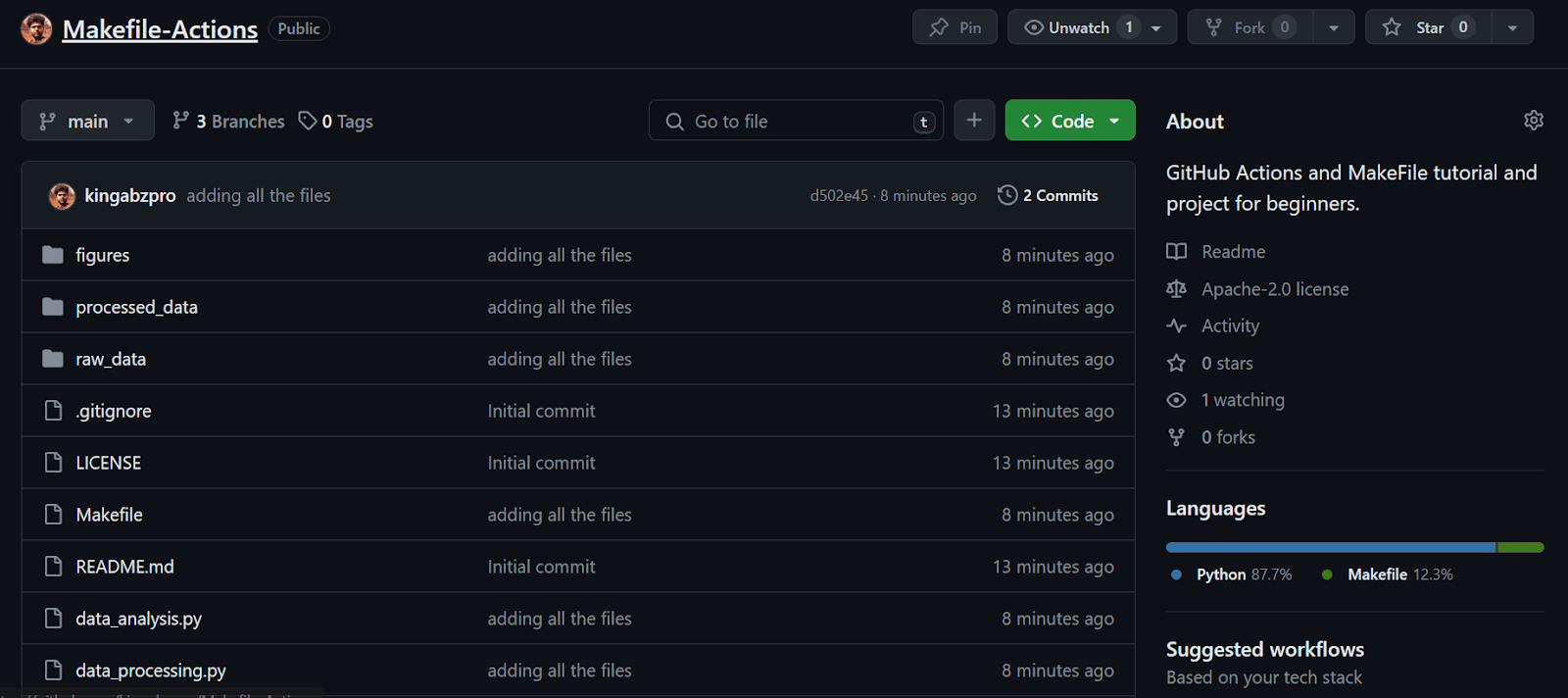
Em seguida, criaremos um fluxo de trabalho do GitHub Action. Primeiro, precisamos ir para a guia Actions (Ações ) em nosso repositório kingabzpro/Makefile-Actions. Em seguida, clicamos no texto azul "configure um fluxo de trabalho você mesmo".
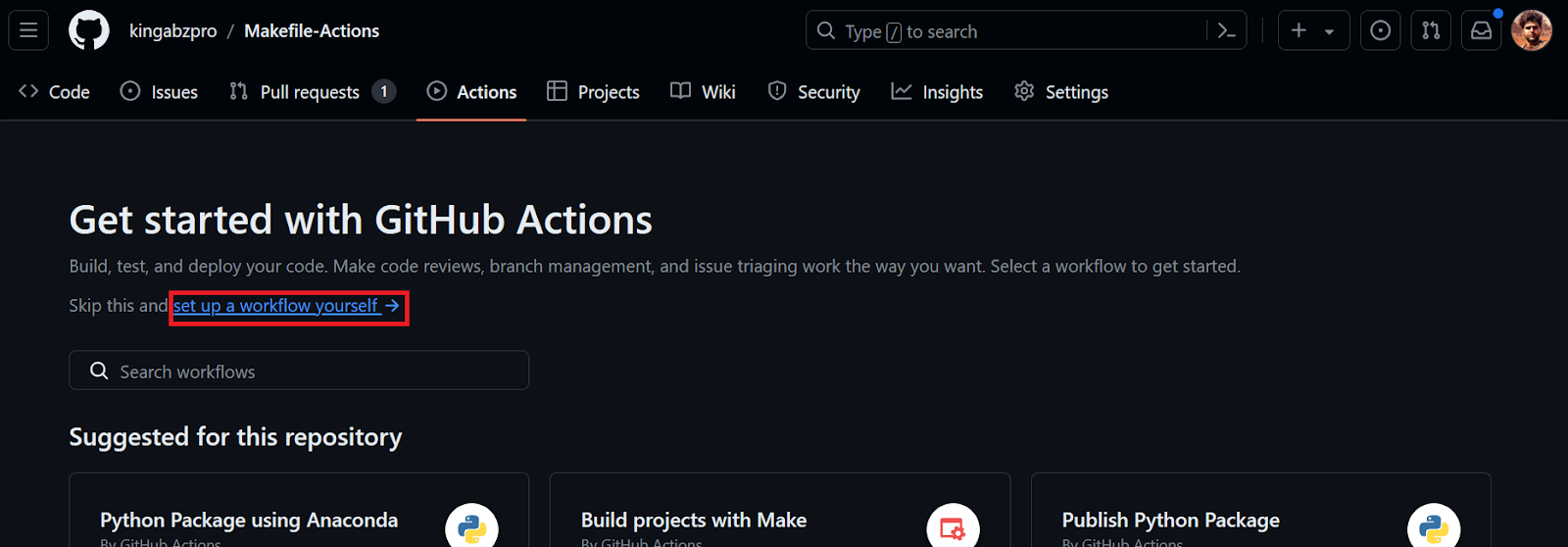
Seremos redirecionados para o arquivo YML, onde escreveremos todo o código para configurar o ambiente e executar os comandos. Nós o faremos:
main ou quando houver uma solicitação pull na ramificação main.name: Data Processing and Analysis
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install Packages
run: |
pip install --upgrade pip
pip install -r requirements.txt
- name: Format
run: black *.py --line-length 88
- name: Data Processing
env:
RAW_DATA_DIR: "./raw_data/WHR2023.csv"
run: python data_processing.py $RAW_DATA_DIR
- name: Data Analysis
env:
CLEAN_DATA_DIR: "./processed_data/WHR2023_cleaned.csv"
run: python data_analysis.py $CLEAN_DATA_DIRDepois de confirmar o arquivo de fluxo de trabalho com a mensagem, você começará a executar o fluxo de trabalho automaticamente.
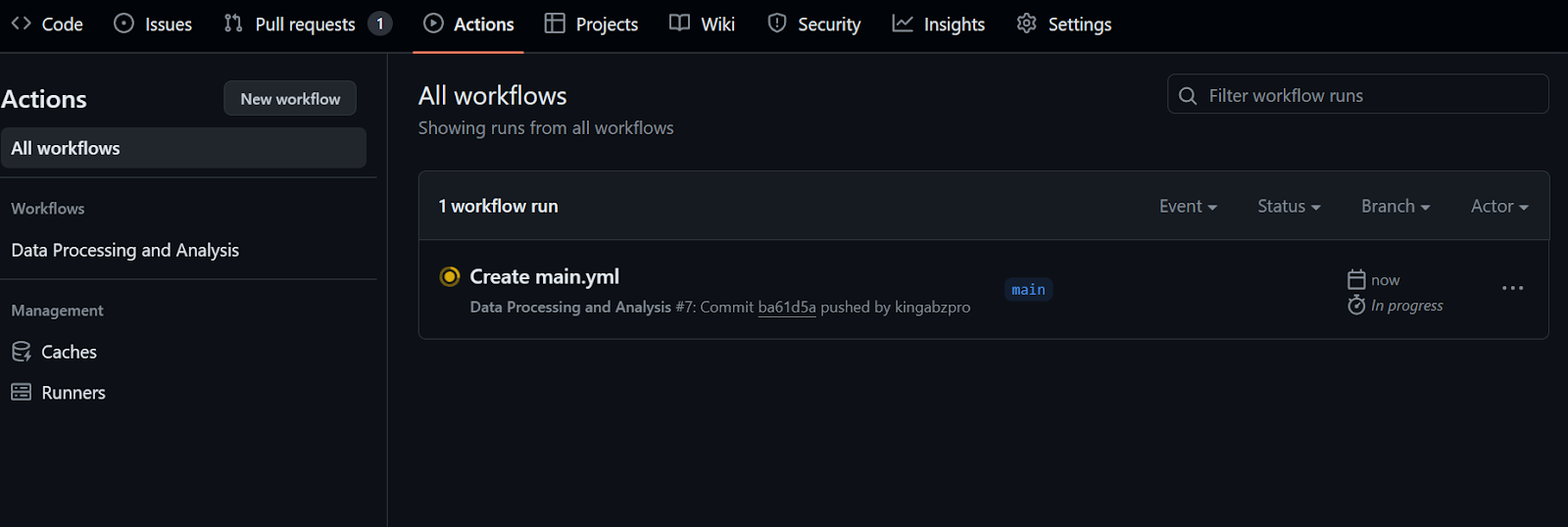
Você levará pelo menos 20 segundos para concluir todas as etapas.
Para verificar os logs, primeiro clicamos na execução do fluxo de trabalho, depois no botão Build e, em seguida, clicamos em cada trabalho para acessar os logs.
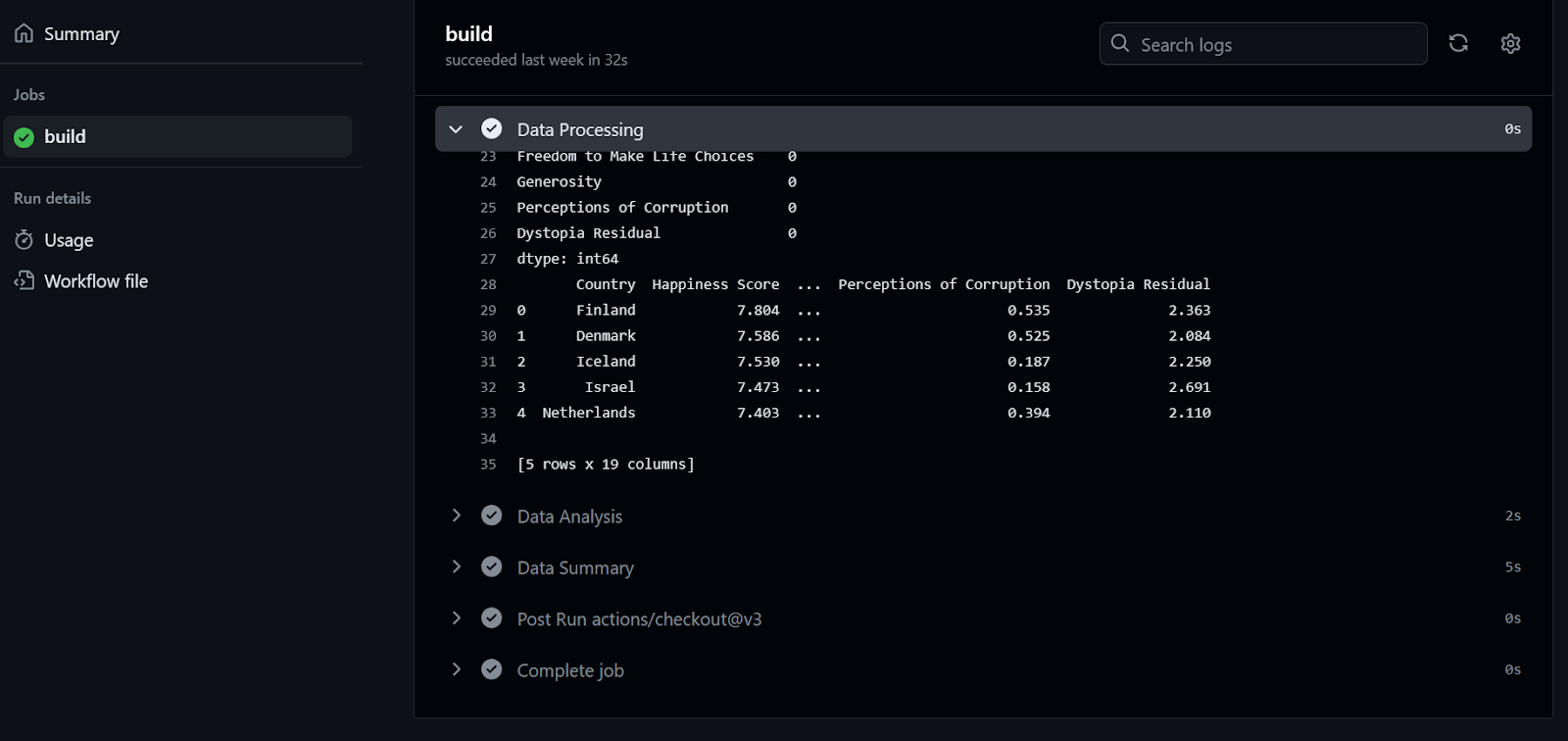
Se isso foi divertido para você, certamente gostará deste Guia para iniciantes em CI/CD para machine learning, que aborda os conceitos básicos de criação e automação de um fluxo de trabalho de machine learning.
Para simplificar e padronizar os fluxos de trabalho do GitHub Action, os desenvolvedores usam os comandos Make no arquivo de fluxo de trabalho. Nesta seção, aprenderemos a simplificar nosso código de fluxo de trabalho usando o comando Make e aprenderemos a usar a ação de machine learning contínuo (CML).
Antes de começarmos, precisamos extrair o arquivo de fluxo de trabalho do repositório remoto.
$ git pullO Continuous Machine Learning (CML) é uma biblioteca de código aberto da iterative.ai que nos permite implementar a integração contínua em nosso projeto de ciência de dados.
Neste projeto, usaremos o iterative/setup-cml GitHub Action que usa funções CML no fluxo de trabalho para gerar o relatório de análise usando figuras e estatísticas de dados.
O relatório será criado e anexado ao nosso commit no GitHub para que nossa equipe o revise e aprove antes de fazer o merge.
Modificaremos o Makefile e adicionaremos outro alvo "summary". Observe que:
cml para criar um relatório analítico de dados e exibi-lo nos comentários do commit.Imagine adicionar tantas linhas ao arquivo de fluxo de trabalho do GitHub - seria difícil para você ler e modificar. Em vez disso, usaremos make summary.
Arquivo: Arquivo de criação
summary: ./processed_data/summary.txt
echo "# Data Summary" > report.md
cat ./processed_data/summary.txt >> report.md
echo '\n# Data Analysis' >> report.md
echo '\n## Correlation Heatmap' >> report.md
echo '' >> report.md
echo '\n## Happiness Score Distribution' >> report.md
echo '' >> report.md
echo '\n## Happiness Score vs GDP per Capita' >> report.md
echo '' >> report.md
echo '\n## Social Support vs Happiness Relationship' >> report.md
echo '' >> report.md
echo '\n## Top 20 Countries by Happiness Score' >> report.md
echo '' >> report.md
cml comment create report.md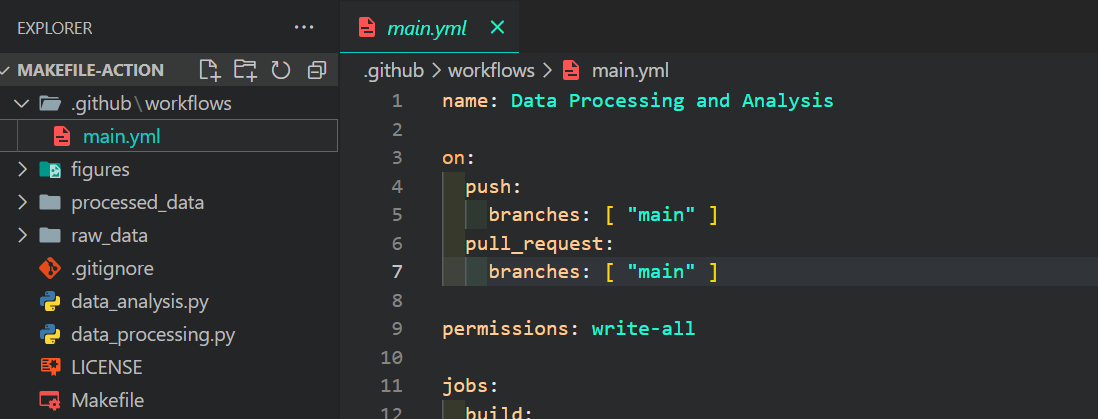
Agora, editaremos nosso arquivo main.yml, que pode ser encontrado no diretório .github/workflows.
Alteramos todos os comandos e scripts Python com o comando make e fornecemos permissão para que a ação CML crie o relatório de dados no comentário de confirmação. Além disso, vamos nos certificar de que não nos esquecemos de adicionar a ação iterative/setup-cml@v3 à nossa execução.
name: Data Processing and Analysis
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
permissions: write-all
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: iterative/setup-cml@v3
- name: Install Packages
run: make install
- name: Format
run: make format
- name: Data Processing
env:
RAW_DATA_DIR: "./raw_data/WHR2023.csv"
run: make process RAW_DATA_PATH=$RAW_DATA_DIR
- name: Data Analysis
env:
CLEAN_DATA_DIR: "./processed_data/WHR2023_cleaned.csv"
run: make analyze PROCESSED_DATA=$CLEAN_DATA_DIR
- name: Data Summary
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: make summaryPara executar o fluxo de trabalho, precisamos apenas confirmar todas as alterações e sincronizá-las com a ramificação remota do main.
$ git commit -am "makefile and github action combo"
$ git push github master:main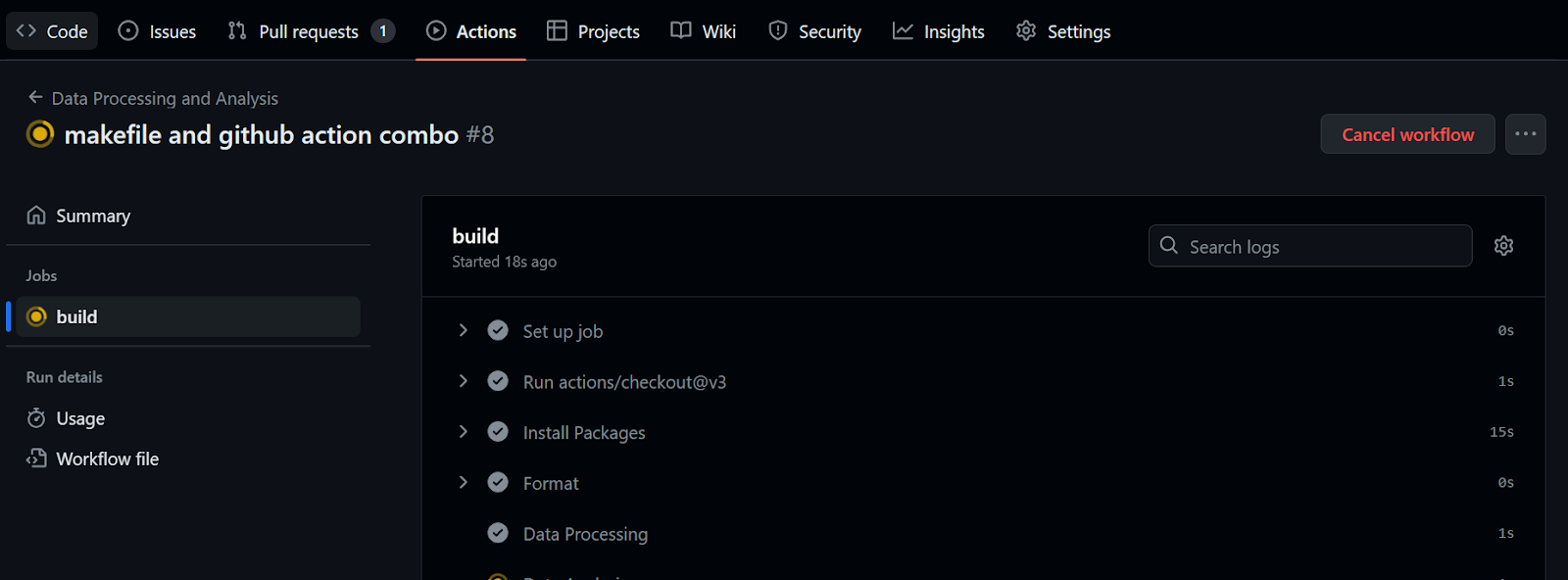
Foram necessários 32 segundos para executar o fluxo de trabalho - nosso relatório está pronto para ser revisado. Para fazer isso, vamos para o resumo da compilação, rolamos para baixo para clicar na guia Resumo de dados e, em seguida, clicamos no link de comentário (o link que você vê na linha 20 na figura abaixo):
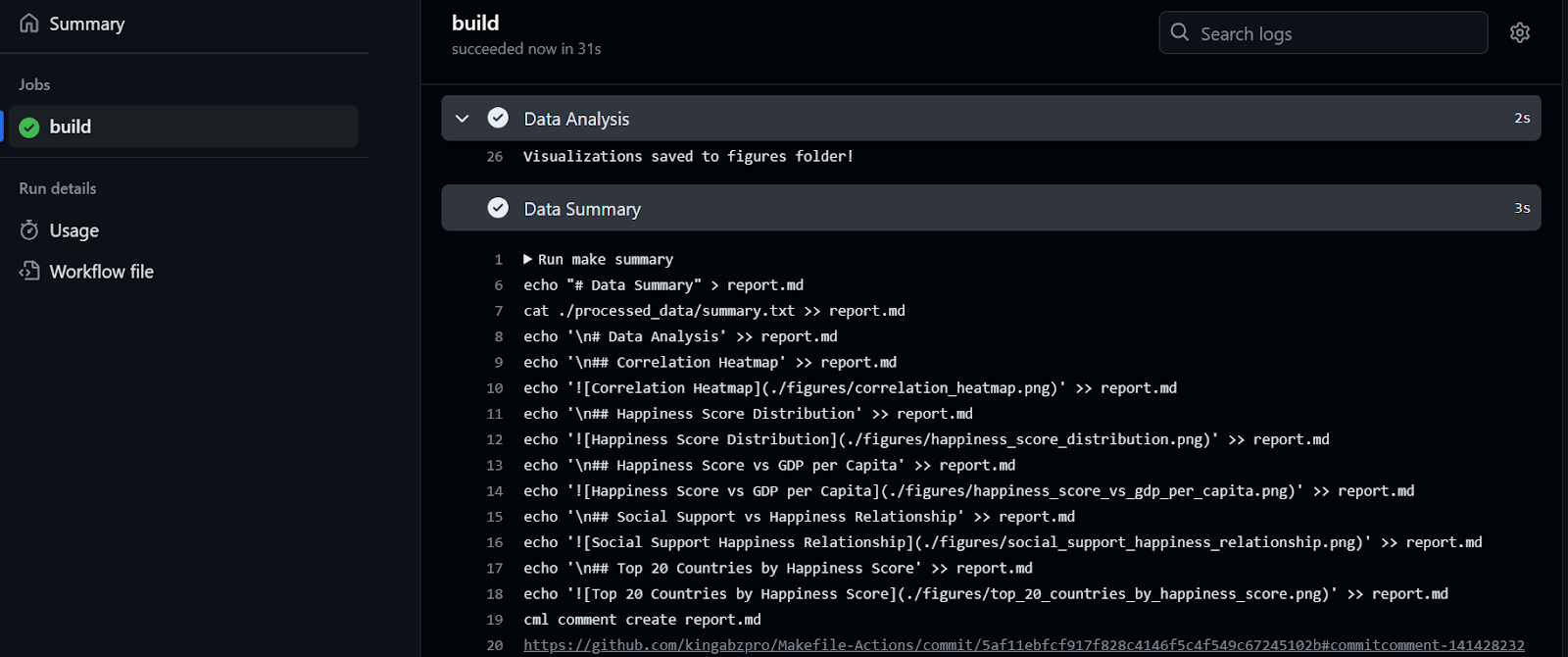
Como você pode ver, o resumo e as visualizações dos dados estão anexados ao nosso commit.
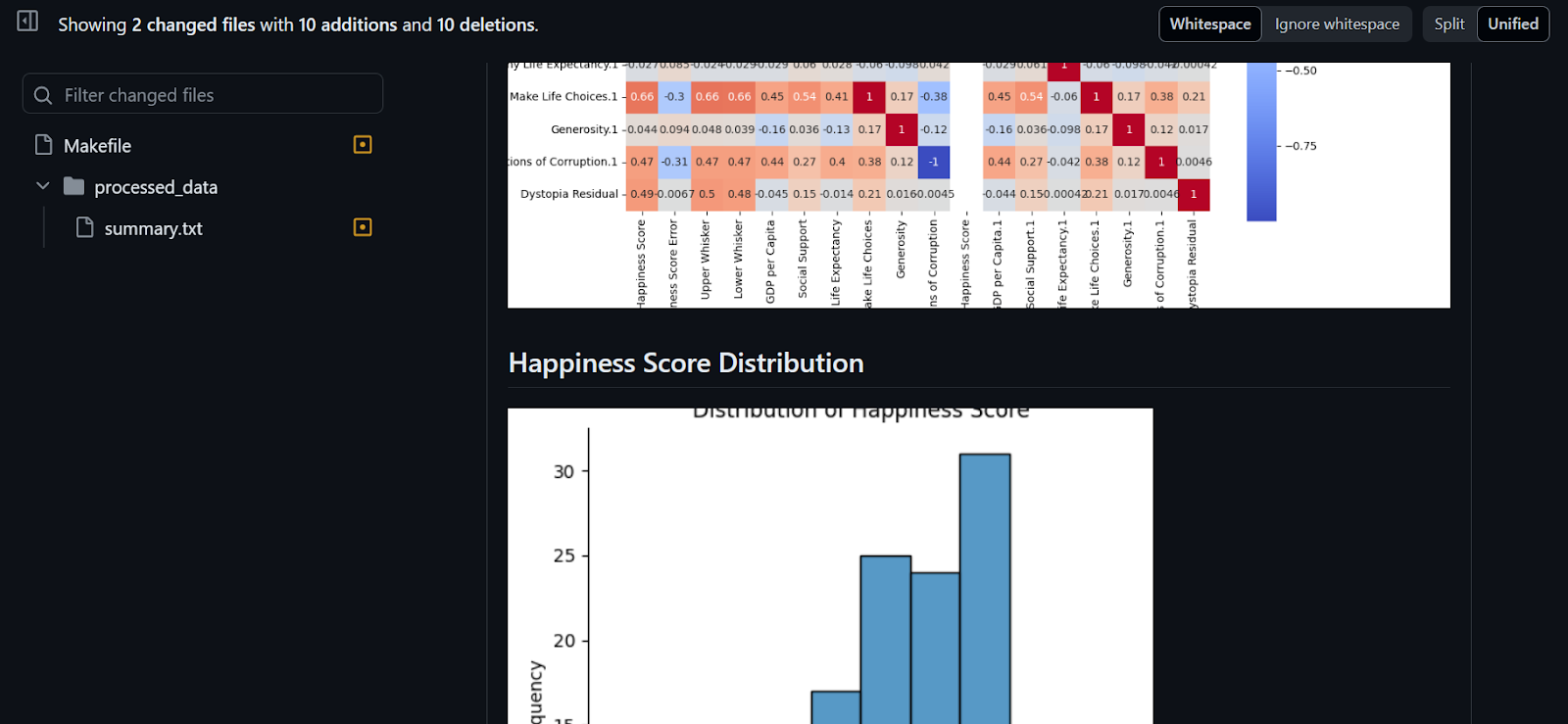
O projeto está disponível em kingabzpro/Makefile-Actions, e você pode usá-lo como um guia quando tiver dúvidas. O repositório é público, portanto, faça uma bifurcação e experimente a mágica você mesmo!
Neste tutorial, nos concentramos no Makefile e no GitHub Actions para automatizar a geração de relatórios analíticos de dados.
Também aprendemos a criar e executar o fluxo de trabalho e a usar a ferramenta Make no fluxo de trabalho do GitHub para otimizar e simplificar o processo de automação. Em vez de escrever várias linhas de código, podemos usar o make summary para gerar um relatório de análise de dados que será anexado ao nosso commit.
Se você quiser dominar a arte de CI/CD para ciência de dados, experimente este curso sobre CI/CD para machine learning. Ele abrange os fundamentos de CI/CD, ações do GitHub, versão de dados e automatização da otimização e avaliação de hiperparâmetros de modelos.
Torne-se um engenheiro de machine learning!
Programa
Programa
Curso
blog
Summer Worsley
14 min
blog
Karlijn Willems
15 min
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Oluseye Jeremiah
Tutorial
Abid Ali Awan
