
Curso
Introducción a la ingeniería de datos
4 h
127.6K
Hay varias formas de tratar las dimensiones que cambian lentamente. Veamos tres de las formas más comunes.
Con el SCD tipo 1, si cambia un registro de una tabla de dimensiones, el registro existente se actualiza o se sobrescribe. En caso contrario, el nuevo registro se inserta en la tabla de dimensiones. Esto significa que los registros de la tabla de dimensiones siempre reflejan el estado actual y no se mantiene ningún dato histórico.
Una tabla que almacene información sobre los artículos que se venden en una tienda de comestibles podría gestionar los registros cambiantes utilizando SCD tipo 1. Si ya existe un registro en la tabla para el artículo deseado, se actualizará con la nueva información. En caso contrario, el registro se insertará en la tabla de dimensiones.
En el mundo de la ingeniería de datos, esta práctica de actualizar los datos si existen o insertarlos en caso contrario se conoce como "upserting". La siguiente tabla contiene información sobre los artículos que se venden en una tienda de comestibles.
|
item_id |
nombre |
precio |
pasillo |
|
93201 |
Patatas fritas |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Si las Patatas fritas se trasladan al pasillo 6, al utilizar SCD tipo 1 para capturar este cambio en la tabla de dimensiones se obtendrá el resultado que se indica a continuación:
|
item_id |
nombre |
precio |
pasillo |
|
93201 |
Patatas fritas |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
El SCD tipo 1 garantiza que no haya registros duplicados en la tabla y que los datos reflejen la dimensión actual más reciente. Esto es especialmente útil para los cuadros de mando en tiempo real y los modelos predictivos, en los que sólo interesa el estado actual.
Sin embargo, como en la tabla sólo se almacena la información más reciente, los profesionales de los datos no pueden comparar los cambios en las dimensiones a lo largo del tiempo. Por ejemplo, un analista de datos tendría problemas para identificar el aumento de los ingresos de las Patatas Fritas después de que se trasladaran al pasillo 6 sin alguna otra información.
El SCD tipo 1 facilita la elaboración de informes y análisis del estado actual, pero tiene limitaciones a la hora de realizar análisis históricos.
Aunque tener una tabla que refleje sólo el estado actual puede ser útil, hay veces en que es conveniente, e incluso esencial, hacer un seguimiento de los cambios históricos de una dimensión. Con el SCD tipo 2, los datos históricos se mantienen añadiendo una nueva fila cuando cambia una dimensión y denotando adecuadamente esta nueva fila como actual, al tiempo que se denota en consecuencia el nuevo registro histórico.
Es fácil decirlo, pero puede que no esté muy claro cómo es en la práctica. Veamos un ejemplo.
Aquí tenemos una tabla bastante similar al ejemplo que utilizamos al explorar la ECF tipo 1. Sin embargo, se ha añadido una columna adicional. La dirección is_current almacena un valor booleano; verdadero si el registro refleja el valor más actual, y falso en caso contrario.
|
item_id |
nombre |
precio |
pasillo |
is_current |
|
93201 |
Patatas fritas |
3.99 |
11 |
Verdadero |
|
07879 |
Soda |
7.99 |
13 |
Verdadero |
Si las Patatas fritas se trasladan al pasillo 6, utilizando SCD tipo 2 para documentar este cambio se crearía una tabla con el siguiente aspecto:
|
item_id |
nombre |
precio |
pasillo |
is_current |
|
93201 |
Patatas fritas |
3.99 |
11 |
Falso |
|
07879 |
Soda |
7.99 |
13 |
Verdadero |
|
93201 |
Patatas fritas |
3.99 |
6 |
Verdadero |
Se añade una nueva fila para reflejar el cambio de ubicación de las Patatas Fritas, con True almacenada en la columna is_current. Para mantener los datos históricos y representar con precisión el estado actual, la columna is_current del registro anterior se establece en False. Con SCD tipo 1,
Pero, ¿y si quisieras explorar cómo respondieron las ventas de patatas fritas a un cambio de ubicación? Esto es bastante difícil cuando se utiliza una sola columna si hay varios registros históricos para un mismo artículo. Por suerte, hay una forma fácil de hacerlo.
Echa un vistazo a la siguiente tabla. Esta tabla de dimensiones contiene la misma información que antes, pero en lugar de una columna is_current, tiene las columnas start_date y end_date. Estas fechas representan el periodo de tiempo en que una dimensión fue la más actual. Dado que los datos de esta tabla son los más recientes, la end_date se sitúa bastante en el futuro.
|
item_id |
nombre |
precio |
pasillo |
start_date |
end_date |
|
93201 |
Patatas fritas |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Si las Patatas Fritas se trasladaran al pasillo 6 el 4 de enero de 2024, la tabla actualizada tendría este aspecto:
|
item_id |
nombre |
precio |
pasillo |
start_date |
end_date |
|
93201 |
Patatas fritas |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Patatas fritas |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Ten en cuenta que el end_date de la primera fila se ha actualizado al último día en que había Patatas Fritas en el pasillo 11. Se añade un nuevo récord: ahora las Patatas Fritas están en la estantería del pasillo 6. start_date y end_date ayudan a mostrar cuándo se hizo el cambio y denotan qué registro es el actual.
Utilizar esta técnica para aplicar el SCD tipo 1 no sólo conserva los datos históricos, sino que también ofrece información sobre cuándo han cambiado los datos. Esto permite a los analistas y científicos de datos explorar los cambios operativos, realizar pruebas A/B y potenciar la toma de decisiones informadas.
Cuando se trabaja con datos que sólo se espera que cambien una vez, o sólo interesa el registro histórico más reciente, el SCD tipo 3 es bastante útil. En lugar de "insertar" una dimensión alterada o almacenar el cambio como una nueva fila, el SCD tipo 3 utiliza una columna para representar el cambio. Esto es un poco difícil de explicar, así que pasemos directamente a un ejemplo.
La siguiente tabla contiene información sobre deportes para equipos de todo Estados Unidos. Aquí, la tabla contiene dos columnas para almacenar un nombre de estadio actual y otro histórico. Como cada uno de estos equipos utiliza el nombre original del estadio, la columna previous_stadium_name se rellena con NULLs.
|
team_id |
team_name |
deporte |
current_stadium_name |
previous_stadium_name |
|
562819 |
Halcones de Lafayette |
Fútbol |
Estadio Triple X |
NULL |
|
930193 |
Ardillas de Fort Niagara |
Fútbol |
Estadio Musket |
NULL |
Si los Lafayette Hawks deciden contratar a un nuevo patrocinador para un acuerdo de veinticinco años, la tabla actualizada tendrá este aspecto:
|
team_id |
team_name |
deporte |
current_stadium_name |
previous_stadium_name |
|
562819 |
Halcones de Lafayette |
Fútbol |
Campo Wabash |
Estadio Triple X |
|
930193 |
Ardillas de Fort Niagara |
Fútbol |
Estadio Musket |
NULL |
Para tener en cuenta el nuevo nombre del estadio, "Triple X Stadium '' se traslada a previous_stadium_name column, y "Wabash Field '' ocupa su lugar en la columna current_stadium_name. El nuevo acuerdo de patrocinio, que tiene una duración de veinticinco años, muy probablemente sobrevivirá al modelo que se está construyendo, lo que significa que es poco probable que el récord vuelva a cambiar.
Utilizar el SCD tipo 3 hace que comparar los datos del estado actual con los datos históricos sea bastante sencillo. Sólo hay una fila para cada equipo, y los datos actuales e históricos están uno al lado del otro en dos columnas diferentes. Sin embargo, esto significa que sólo se puede mantener un único registro histórico para un atributo unidimensional, lo que puede ser limitante, sobre todo si los datos cambian con más frecuencia de lo esperado.
Además de los tipos 1, 2 y 3, existen otras técnicas para aplicar dimensiones que cambian lentamente. El tipo 0 se utiliza cuando las dimensiones no deben cambiar nunca. El tipo 4 almacena los datos históricos en una tabla separada mientras persiste los datos más actuales en una tabla de dimensiones. El tipo 6 es una amalgama de los tipos 1, 2 y 3, y suele aplicarse combinando las mejores características de cada una de estas técnicas.
Hemos cubierto los aspectos básicos del cambio lento de dimensiones. Para comprender mejor cómo aplicar cada una de estas técnicas, veamos un ejemplo.
En este ejemplo, utilizaremos Snowflake para implementar SCD de tipo 1, 2 y 3 para transacciones minoristas. Si necesitas un repaso sobre Snowflake, consulta nuestro curso Introducción a Snowflake.
Hay una tabla de hechos, denominada sales, y tres tablas de dimensiones, con los nombres de employees, items, y discounts. A continuación se muestra el ERD de este esquema estrella.
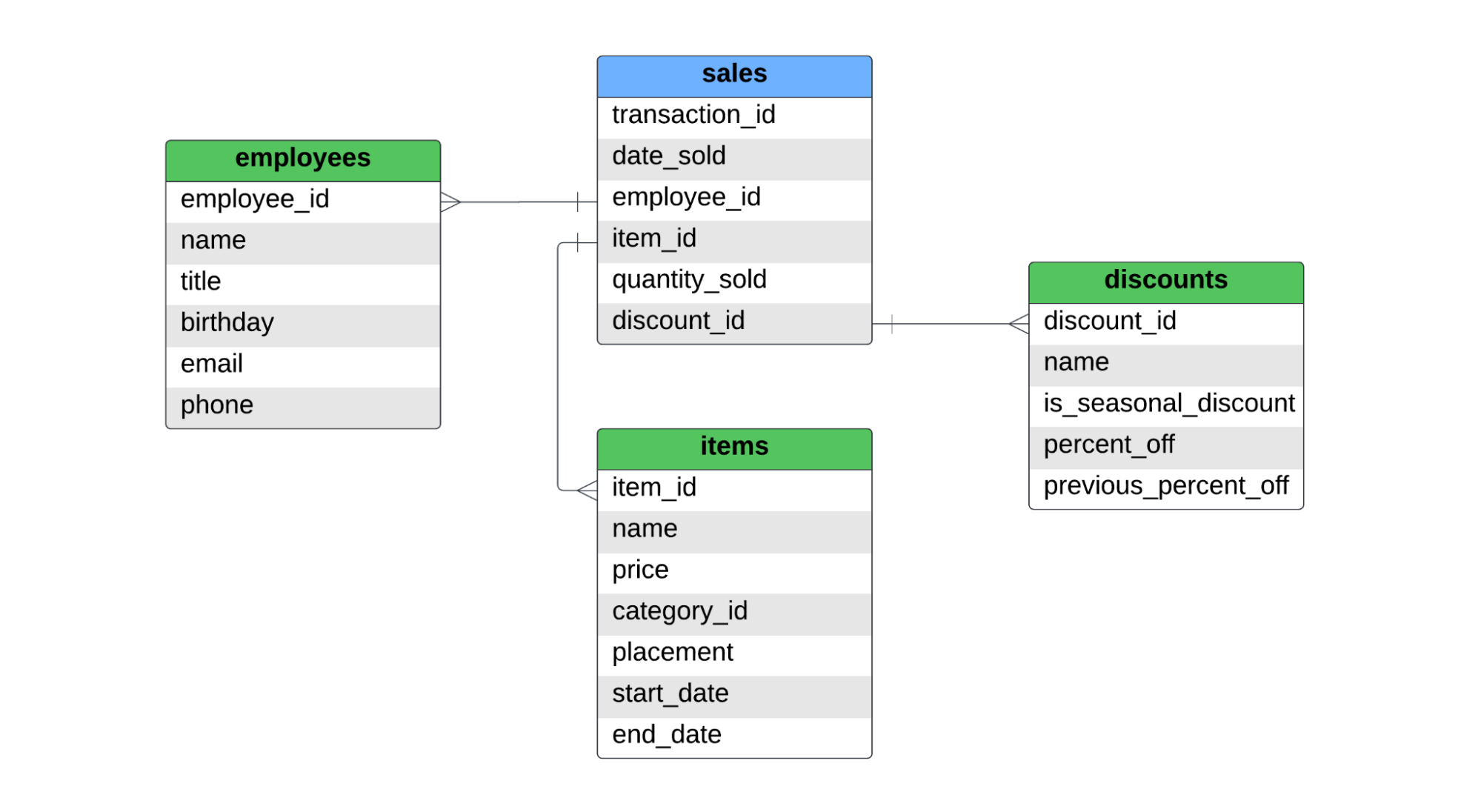
La tabla sales recoge las ventas a nivel de artículo. Si un cliente compró dos camisas y un par de vaqueros, habría dos registros en la tabla de hechos, ya que se vendieron dos artículos diferentes. Para la SCD tipo 1, tipo 2 y tipo 3, cubriremos lo siguiente:
No vamos a explorar cómo se rellenaron originalmente estas tablas, pero normalmente, una canalización ETL o ELT previa al almacén de datos extrajo los datos brutos de la fuente, los transformó en el modelo deseado y los cargó en su destino final.
Para practicar la aplicación de la SCD tipo 1, echaremos un vistazo a la tabla employee. Esta tabla contiene información básica sobre un empleado, incluyendo su nombre, cargo e información de contacto. Puede contener registros como los siguientes.
|
employee_id |
nombre |
title |
cumpleaños |
|
teléfono |
|
477379 |
Emily Verplank |
Director |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cajero |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Utilizando el SCD tipo 1 para captar esta dimensión que cambia lentamente, el registro existente se sobrescribiría con el registro más reciente. Si cambia uno de estos atributos dimensionales, el nuevo registro debe "insertarse" en la tabla existente. Por ejemplo, si el número de teléfono de Emily cambia a 928-652-9704, la nueva tabla tendría el siguiente aspecto:
|
employee_id |
nombre |
title |
cumpleaños |
|
teléfono |
|
477379 |
Emily Verplank |
Director |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cajero |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Para hacerlo con Snowflake, utilizaremos el comando MERGE INTO. MERGE INTO permite que un profesional de los datos proporcione una clave de coincidencia y una condición. Si se cumplen la clave de coincidencia y la condición, el registro puede actualizarse con la palabra clave UPDATE. De lo contrario, un registro puede ser INSERT'ed, o la ejecución puede cesar.
Antes de empezar con el comando MERGE INTO, primero crearemos y añadiremos registros a una tabla llamada stage_employees. Contendrá todos los registros que se hayan actualizado desde la última actualización de la tabla employees. Podemos hacerlo con las afirmaciones siguientes.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Ahora, podemos utilizar la funcionalidad MERGE de Snowflake para "subir" el registro existente.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Arriba, la clave para fusionar datos entre la tabla employees y stage_employees era el campo employee_id. No se estableció otra condición, lo que significa que si los employee_id's coincidían, los atributos dimensionales name, title, email, y phone se actualizaban con los valores de la tabla stage_employees, para ese ID de empleado. Si los registros de la stage_employees no coincidían con ninguno de la tabla employees, el registro se insertaría en la tabla de empleados.
Poner en práctica la SCD tipo 2 es un poco más complicado que la SCD tipo 1. Aunque no es tan sencillo como sobrescribir un registro existente o insertar uno de otro modo, podemos utilizar la lógica MERGE INTO de Snowflake para afrontar este problema. Echa un vistazo a la dimensión de abajo.
|
item_id |
nombre |
precio |
category_id |
colocación |
start_date |
end_date |
|
667812 |
Calcetines |
8.99 |
156 |
Pasillo 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Pasillo 8 |
2023-02-17 |
NULL |
Esta tabla contiene información sobre artículos concretos que se venden en un comercio. Los atributos dimensionales incluyen el nombre, el precio y la ubicación del artículo, así como una clave ajena a la categoría a la que pertenece el artículo. Para implantar el SCD tipo 2, tendremos que "subir" los datos, esta vez utilizando start_date y end_date para mantener tanto los datos históricos como los actuales.
Digamos que al principio de la temporada de la NFL (Liga Nacional de Fútbol Americano), las camisetas deportivas se trasladan a la parte delantera de la tienda para que sean más visibles cuando entre un cliente. Junto con una nueva ubicación, se reduce el precio de este artículo. Para ilustrar este comportamiento operativo, así como para mantener los datos históricos, se actualiza el registro existente con una fecha de finalización y se inserta uno nuevo. ¡Compruébalo!
|
item_id |
nombre |
precio |
category_id |
colocación |
start_date |
end_date |
|
667812 |
Calcetines |
8.99 |
156 |
Pasillo 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Pasillo 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sports Jersey |
49.99 |
743 |
Pantalla de entrada |
2023-11-13 |
NULL |
Como antes, crearemos primero una tabla llamada stage_items. Esta tabla almacenará los registros que se utilizarán para implementar el SCD tipo 2 en la dimensión items correspondiente, que adopta la forma mostrada anteriormente. Una vez creada la tabla stage_items, insertaremos un registro que contenga tanto la colocación como el cambio de precio de las camisetas deportivas.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Ahora, es el momento de utilizar la funcionalidad MERGE INTO de Snowflake para implementar el SCD tipo 2. Esto es un poco más complicado que el ejemplo anterior, y requiere pensar un poco. Como sólo se puede insertar un registro si NO se cumple la condición de coincidencia, tendremos que hacerlo en dos pasos. Primero crearemos una condición de coincidencia con las tres sentencias siguientes:
item_id's de la tabla items y stage_items deben coincidirstart_date de la tabla stage_items debe ser mayor que el de la tabla items end_date de la tabla items debe por NULLSi se cumplen estas tres condiciones, hay que actualizar el registro original de la tabla items. Ten en cuenta que la columna items.end_date ya no será NULL; tomará el valor de start_date en la tabla stage_items. No hay lógica si el registro no está emparejado en esta primera declaración.
A continuación, utilizaremos otra llamada a MERGE INTO para insertar el nuevo registro. Esto es un poco más difícil. Para que se inserte un nuevo registro, no debe cumplirse la condición de coincidencia.
En este ejemplo, podemos hacerlo comprobando si los items_id's de las dos tablas coinciden, y el end_date de la tabla items es NULL. Vamos a desglosarlo un poco más.
items_id's coinciden, y el items.end_date es NULL, ya existe un registro en la tabla items que es el más actual. Esto significa que no se debe insertar un nuevo registro.item_id's de las dos tablas, no se cumplirá la condición de coincidencia y se insertará una nueva fila. Éste será el primer registro de ese item_id en la tabla items.item_id de la tabla stage_items coincide con registros de ese mismo item_id en la tabla items, y el end_date no es NULL, se insertará un nuevo valor. Esto mantiene los datos históricos y garantiza la presencia de un registro actual en la tabla items.A continuación se muestra la implementación, utilizando dos sentencias MERGE INTO para actualizar primero el registro existente y luego insertar los datos más actuales.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Por último, echaremos un vistazo a la aplicación de la SCD tipo 3 con una nueva dimensión. En nuestro ejemplo, la tabla discounts almacena información sobre determinados descuentos que los clientes pueden canjear en la caja. La tabla incluye el ID del descuento, así como el nombre, el porcentaje de descuento y la clasificación como descuento de temporada. He aquí un ejemplo de dos registros que podrían estar presentes en la tabla discounts.
|
discount_id |
nombre |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Miembro de Recompensas |
Falso |
10 |
NULL |
|
467782 |
Descuento para empleados |
Falso |
50 |
NULL |
Dado que el minorista no espera que los descuentos cambien a menudo, esta dimensión es una candidata ideal para aplicar un enfoque de tipo 3 para tomar dimensiones que cambien lentamente. Si el porcentaje de descuento que se ofrece mediante el descuento cambia, el porcentaje de descuento anterior pasará a la columna previous_percent_off , mientras que el nuevo valor ocupará su lugar en la columna percent_off.
Esto permite mantener los datos históricos a la vez que se expone el valor más reciente en la columna percent_off.
|
discount_id |
nombre |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Miembro de Recompensas |
Falso |
10 |
NULL |
|
467782 |
Descuento para empleados |
Falso |
35 |
50 |
Para ponerlo en práctica con Snowflake, crearemos una tabla stage_discounts, e insertaremos un único registro. Este registro incluirá el nuevo percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
De nuevo, utilizaremos MERGE INTO para poner en práctica el SCD tipo 3. La condición de coincidencia es sencilla; si los discount_id de las tablas discounts y stage_discounts coinciden, y los valores de percent_off difieren, se actualizará el registro existente en la tabla discounts. El valor percent_off existente se trasladará al campo previous_percent_off y, a continuación, si los discount_id's de las dos tablas no coinciden, se insertará un nuevo registro con el valor NULL. Ten en cuenta que estos registros no están limitados en el tiempo, y que sólo se puede mantener un único valor histórico para percent_off.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Recuerda que el SCD tipo 3 se aplica mejor con datos que raramente cambian, y que sólo debe mantenerse la entrada histórica más reciente. Si se prevén múltiples cambios en la dimensión, probablemente sea mejor utilizar el SCD tipo 2.
Al aplicar cualquier técnica para cambiar lentamente las dimensiones, es importante tener en cuenta la posibilidad de que haya datos duplicados. Hay dos tipos de duplicados a los que hay que prestar atención: los duplicados dentro de un lote y los duplicados entre lotes. Vamos a desglosarlo.
Los duplicados intralote son duplicados que existen entre diferentes lotes de datos. Si existe una tabla de dimensiones, y dos ficheros destinados a actualizar esta tabla pueden contener registros duplicados.
Para manejar esto, es importante añadir restricciones a tu lógica que está "upserting" y/o cargando datos en una tabla de dimensión. En nuestros ejemplos anteriores, añadimos lógica en todo el proceso para asegurarnos de que no había duplicados. Esto incluía:
employee_id coincidentepercent_off eran diferentes en la tabla de artículos y stage_items antes de actualizar un registro existenteLos duplicados entre lotes son duplicados que se producen en el mismo lote de datos. Por ejemplo, si un fichero contiene dos entradas para actualizar un único registro de una tabla de dimensiones, hay que tomar precauciones. Al igual que con los duplicados intralote, es importante añadir restricciones a la lógica utilizada para implementar los SCD de tipo 1, 2 ó 3.
Si hay registros contradictorios en el mismo archivo, habrá que diferenciarlos de alguna manera. Pueden ser metadatos sobre el registro o una marca de tiempo proporcionada por la fuente. Sea cual sea la forma que elijas para gestionar estos duplicados, es importante documentar tus suposiciones y revisarlas con tu equipo para asegurarte de que las dimensiones resultantes capturan con precisión los valores operativos.
A veces, los datos cambian cuando no deberían. Con las tres técnicas SCD que hemos analizado hasta ahora, esto puede provocar que se sobrescriban datos, que se añada una nueva fila o que se rellenen datos en una nueva columna.
Ya hemos hablado de formas de garantizar que los datos duplicados no lleguen a las tablas de dimensiones. Además de los datos duplicados, los profesionales de los datos que apliquen técnicas para manejar dimensiones que cambian lentamente deberán tener cuidado con lo siguiente:
Aunque no todos los casos anteriores pueden detectarse directamente en el código utilizado para mantener las tablas de dimensiones, disponer de reglas y procesos sólidos de calidad de datos para supervisar las dimensiones puede ayudar a garantizar que se mantiene la integridad de los datos.
En el ejemplo del comercio anterior, los conjuntos de datos con los que trabajamos estaban formados por unas pocas filas de datos. En un entorno de producción, estas tablas de dimensiones podrían contener cientos o incluso miles de registros. Esto es bastante habitual cuando se aplica la SCD tipo 2, sobre todo si las dimensiones cambian con frecuencia.
A medida que aumenta el número de filas de una tabla de dimensiones, es importante que un profesional de los datos mantenga el rendimiento en el primer plano de sus planes de diseño e implementación. He aquí algunas formas de optimizar la implementación de SCD para grandes conjuntos de datos utilizando Snowflake:
MERGE UPDATE y INSERT declaraciones cuando proceda, en lugar de MERGESi un conjunto de datos de dimensiones llega a ser tan grande que el rendimiento del sistema se ve comprometido, puede ser necesario tomar una decisión sobre un compromiso entre la precisión histórica y el rendimiento del sistema. Como ya se ha dicho, éste suele ser el caso cuando se aplica el SCD tipo 2.
Si los registros cambian a menudo, el número de filas de la tabla puede aumentar rápidamente. Cuando éste sea el caso, puede que ya no sea prudente utilizar el SCD tipo 2 para mantener los datos dimensionales.
Pasar a aprovechar el SCD tipo 1 o tipo 3 puede ofrecer una funcionalidad similar, con ganancias significativas en el rendimiento del sistema. La contrapartida es una representación incompleta de los datos históricos. Trabaja con tu equipo para sopesar esta compensación antes de cambiar un enfoque para implantar la SCD.
Es bastante fácil ejecutar una consulta única para implementar SCD para una tabla de dimensión. Sin embargo, ejecutar programáticamente este proceso para mantener esta dimensión en un entorno de producción requiere un poco de reflexión. Herramientas como Apache Airflow son estupendas para orquestar estos procesos y proporcionan una capa de supervisión y alerta para garantizar un rendimiento nominal. Al parametrizar la lógica utilizada para actualizar las tablas de dimensiones, Airflow puede utilizarse para poner en marcha procesos en tu plataforma de datos durante un periodo programado, ocupando el lugar de los esfuerzos manuales de un profesional de los datos.
Además de Airflow, pueden utilizarse herramientas como Mage, Prefect o Dagster para orquestar la aplicación de dimensiones que cambian lentamente. Si este tipo de herramientas no están disponibles, las herramientas de orquestación caseras también pueden servir.
Dominar las dimensiones que cambian lentamente (SCD) es una habilidad fantástica que debes tener en tu cinturón de herramientas, sobre todo al crear tu propio modelo de datos.
En este artículo hemos tratado los fundamentos de los esquemas en estrella, así como las definiciones y conceptos básicos de SCD. Exploramos los tipos de SCD 1, 2 y 3 para mantener los datos históricos a la vez que se captura una instantánea del estado actual.
Con la ayuda de Snowflake, implementamos cada una de las técnicas SCD definidas anteriormente con la ayuda de un ejemplo de venta al por menor. Después, esbozamos algunos de los retos más técnicos que puede plantear la implantación de la SCD, y cómo afrontarlos.
Para seguir desarrollando tus habilidades de modelado de datos, sigue los cursos de Diseño de Bases de Datos, Introducción a la Ingeniería de Datos e Introducción al Almacenamiento de Datos, disponibles a través de DataCamp. Mucha suerte y ¡feliz codificación!
¡Comienza hoy tu viaje de datos!
Curso
Curso
Curso
blog
Abid Ali Awan
7 min
blog
Mike Shakhomirov
11 min
blog
Nisha Arya Ahmed
15 min
blog
Moez Ali
14 min
Tutorial
Dimitri Didmanidze
Tutorial
Joleen Bothma

