Course
Introduction to Data Engineering
4 hr
127.6K
There are a number of ways to handle slowly changing dimensions. Let’s take a look at three of the most common ways.
Using SCD type 1, if a record in a dimension table changes, the existing record is updated or overwritten. Otherwise, the new record is inserted into the dimension table. This means records in the dimension table always reflect the current state and no historical data is maintained.
A table storing information about the items sold in a grocery store might handle changing records using SCD type 1. If a record already exists in the table for the desired item, it will be updated with the new information. Otherwise, the record will be inserted into the dimension table.
In the data engineering world, this practice of updating data if it exists or inserting it otherwise is known as “upserting.” The table below contains information about items sold in a grocery store.
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
If Potato Chips are moved to aisle 6, using SCD type 1 to capture this change in the dimension table will produce the result below:
|
item_id |
name |
price |
aisle |
|
93201 |
Potato Chips |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
SCD type 1 ensures that there are no duplicate records in the table and that the data reflects the most recent current dimension. This is especially useful for real-time dashboarding and predictive modeling, where only the current state is of interest.
However, since only the most recent information is stored in the table, data practitioners are not able to compare changes in dimensions over time. For example, a data analyst would have trouble identifying the lift in revenue for Potato Chips after they were moved to aisle 6 without some other information.
SCD type 1 makes current state reporting and analytics easy but has limitations when performing historic analyses.
While having a table that reflects only the current state may be useful, there are times when it’s convenient, and even essential, to track historical changes to a dimension. With SCD type 2, historical data is maintained by adding a new row when a dimension changes and properly denoting this new row as current while denoting the newly historical record accordingly.
Easy to say, but it may not be quite clear what this looks like in practice. Let’s take a peek at an example.
Here, we have a table quite similar to the example we used when exploring SCD type 1. However, an additional column has been added. The is_current stores a boolean value; true if the record reflects the most current value, and false otherwise.
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
True |
|
07879 |
Soda |
7.99 |
13 |
True |
If Potato Chips move to aisle 6, using SCD type 2 to document this change would create a table that looks like this:
|
item_id |
name |
price |
aisle |
is_current |
|
93201 |
Potato Chips |
3.99 |
11 |
False |
|
07879 |
Soda |
7.99 |
13 |
True |
|
93201 |
Potato Chips |
3.99 |
6 |
True |
A new row is added to reflect the change in location for Potato Chips, with True stored in the is_current column. To maintain historical data and accurately depict current state, the is_current column for the previous record is set to False. With SCD type 1,
But what if you’d like to explore how Potato Chip sales responded to a change in location? This is quite difficult when using only a single column if there are multiple historical records for a single item. Luckily, there’s an easy way to do this.
Take a look at the table below. This dimension table contains the same information as before, but rather than an is_current column, it has both a start_date and end_date column. These dates represent the period of time that a dimension was the most current. Since the data in this table is the most recent, the end_date is set well in the future.
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
If the Potato Chips moved to aisle 6 on January 4, 2024, the updated table would look like this:
|
item_id |
name |
price |
aisle |
start_date |
end_date |
|
93201 |
Potato Chips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Potato Chips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Note that the end_date for the first row has been updated to the last day Potato Chips were available in aisle 11. A new record is added, with Potato Chips now being shelved in aisle 6. The start_date and end_date help to show when the change was made and denote which record is current.
Using this technique to implement SCD type 1 not only preserves historic data, it also offers information about when data has changed. This enables data analysts and data scientists to explore operational changes, perform A/B testing, and empower informed decision-making.
When working with data that is only expected to change once, or only the most recent historical record is of interest, SCD type 3 is quite useful. Rather than “upserting” an altered dimension or storing the change as a new row, SCD type 3 uses a column to represent the change. This is a little bit tricky to explain, so let’s jump right into an example.
The table below contains information about sports for teams across the United States. Here, the table contains two columns to store a current and historic stadium name. Since each of these teams is using the original stadium name, the previous_stadium_name column is populated with NULLs.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Triple X Stadium |
NULL |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
If the Lafayette Hawks decide to take on a new sponsor for a twenty-five-year deal, the updated table will look something like this:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Football |
Wabash Field |
Triple X Stadium |
|
930193 |
Fort Niagara Squirrels |
Soccer |
Musket Stadium |
NULL |
To account for the new stadium name, “Triple X Stadium '' is moved to the previous_stadium_name column, and “Wabash Field '' takes its place in the current_stadium_name column. The new sponsorship deal, which is for twenty-five years, will most likely outlive the model being built, meaning the record is unlikely to change again.
Using SCD type 3 makes comparing current state data to historical data quite simple. There is only a single row for each team, and the current and historical data sit side-by-side in two different columns. However, this means that only a single historical record for a single-dimensional attribute can be maintained, which may be limiting, especially if data changes more frequently than expected.
In addition to types 1, 2, and 3, there are a number of other techniques to implement slowly changing dimensions. Type 0 is used when dimensions should never change. Type 4 stores historic data in a separate table while persisting the most current data in a dimension table. Type 6 is an amalgamation of types 1, 2, and 3 and is typically implemented by combining the best features of each of these techniques.
We’ve covered the basics of slowly changing dimensions. To get a better understanding of how to implement each of these techniques, let’s take a look at an example.
In this example, we’ll use Snowflake to implement SCD type 1, 2, and 3 for retail transactions. If you need a refresher on Snowflake, check out our Introduction to Snowflake course.
There is one fact table, named sales, and three dimension tables, with names of employees, items, and discounts. Below is the ERD for this star-schema.
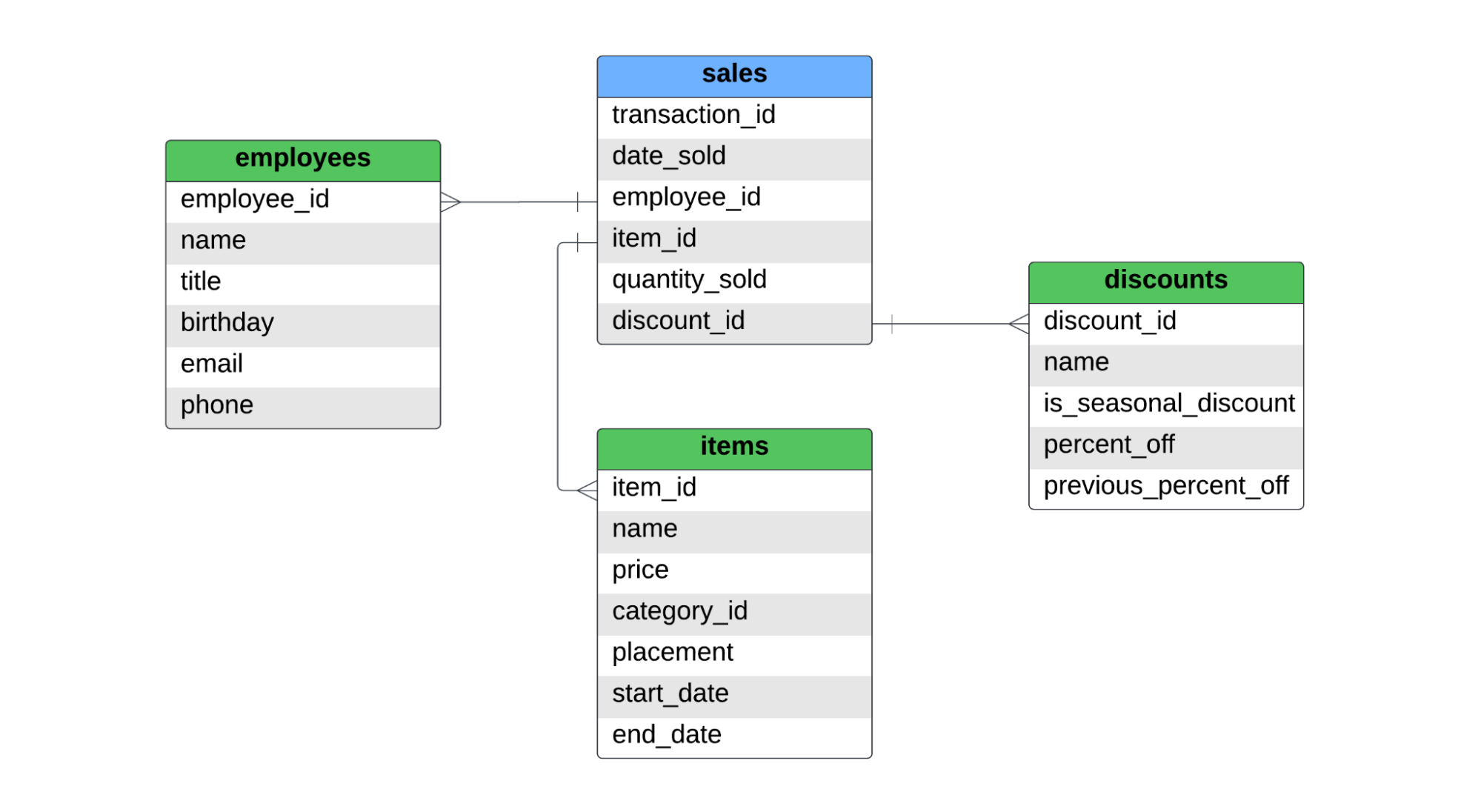
The sales table captures item-level sales. If a customer bought two shirts, and a pair of jeans, there would be two records in the fact table, since two different items were sold. For SCD type 1, type 2, and type 3, we’ll cover the following:
We won’t explore how these tables were originally populated, but typically, an ETL or ELT pipeline upstream of the data warehouse pulled raw data from source, transformed it into the desired model, and loaded it into its final destination.
To practice implementing SCD type 1, we’ll take a look at the employee table. This table contains basic information about an employee, including their name, title, and contact information. It may contain records like the ones below.
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Using SCD type 1 to capture this slowly changing dimension, the existing record would be overwritten by the most recent record. If one of these dimensional attributes changes, the new record should be “upserted” into the existing table. For example, if Emily’s phone number changes to 928-652-9704, the new table would look like this:
|
employee_id |
name |
title |
birthday |
|
phone |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Cashier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
To do this with Snowflake, we’ll use the MERGE INTO command. MERGE INTO allows for a data practitioner to provide a match key, and an condition. If the match key and the condition are met, the record can be updated with the UPDATEkeyword. Otherwise, a record can be INSERT'ed, or execution can cease.
Before getting started with the MERGE INTO command, we’ll first create and add records to a table named stage_employees. This will contain all records that have been updated since the employees table was last refreshed. We can do this with the statements below.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Now, we can use Snowflake’s MERGE functionality to “upsert” the existing record.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Above, the key to merge data between the employees and stage_employees table was the employee_id field. Another condition was not set, meaning if the employee_id's matched, the name, title, email, and phone dimensional attributes were updated with the values from the stage_employees table, for that employee ID. If records from the stage_employees did not match any from the employees table, the record would be inserted into the employees table.
Implementing SCD type 2 is a little trickier than SCD type 1. While it’s not quite as simple as overwriting an existing record or inserting one otherwise, we can still use Snowflake’s MERGE INTO logic to take on this problem. Take a look at the dimension below.
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
NULL |
This table contains information about specific items sold at a retail store. The dimensional attributes include the name, price, and placement of the item, as well as a foreign key to the category the item belongs to. To implement SCD type 2, we’ll need to “upsert” data, this time using start_date and end_date to maintain both historical and current data.
Let’s say at the beginning of the NFL (National Football League) season, sports jerseys are moved to the front of the store for better visibility when a customer walks in. Along with a new location, the price of this item is reduced. To illustrate this operational behavior, as well as maintain historical data, the existing record is updated with an end date, and a new one is inserted. Check it out!
|
item_id |
name |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Socks |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Sports Jersey |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sports Jersey |
49.99 |
743 |
Entry Display |
2023-11-13 |
NULL |
Similar to before, we’ll first create a table called stage_items. This table will store records that will be used to implement SCD type 2 in the corresponding items dimension, which takes the form shown above. Once the stage_items table is created, we’ll insert a record that contains both the placement and price change for sports jerseys.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Now, it’s time to use Snowflake’s MERGE INTO functionality to implement SCD type 2. This is a little trickier than the previous example, and takes a little bit of thinking. Since a record can only be inserted if the match condition is NOT met, we’ll have to do this in two steps. First we’ll create a match condition with the following three statements:
item_id's in the items and stage_items table must matchstart_date in the stage_items table must be greater than in the items tableend_date in the items table must by NULLIf these three conditions are met, then the original record in the items table must be updated. Note that the items.end_date column will not be NULL anymore; it will take the value of the start_date in the stage_items table. There’s no logic if the record is unmatched in this first statement.
Next, we’ll use a separate call to MERGE INTO to insert the new record. This is a little more difficult. For a new record to be inserted, the match condition must not be met.
In this example, we can do this by checking to see if the items_id's in the two tables match, and the end_date in the items table is NULL. Let’s break it down a little further.
items_id's match, and the items.end_date is NULL, there is already a record in the items table that is the most current. This means that a new record should not be inserted.item_id's in the two tables, the match condition will not be met, and a new row will be inserted. This will be the first record for that item_id in the items table.item_id in the stage_items table matches records with that same item_id in the items table, and the end_date is not NULL, a new value will be inserted. This maintains historical data and ensures that a current record is present in the items table.Below is the implementation, using two MERGE INTO statements to first update the existing record and then insert the most current data.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Finally, we’ll take a look at implementing SCD type 3 with a new dimension. In our example, the discounts table stores information about certain discounts that customers may redeem at checkout. The table includes the ID of the discount, as well as the name, percent off, and classification as a seasonal discount. Here’s an example of two records that might be present in the discounts table.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
50 |
NULL |
Since the retailer doesn’t expect the discounts to change often, this dimension is a great candidate for implementing a type 3 approach to take slowly changing dimensions. If the percent off that is offered via the discount changes, the previous percent off will move to the previous_percent_off column, while the new value will take its spot in the percent_off column.
This allows historical data to be maintained while exposing the most recent value in the percent_off column.
|
discount_id |
name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Rewards Member |
False |
10 |
NULL |
|
467782 |
Employee Discount |
False |
35 |
50 |
To implement this with Snowflake, we’ll create a stage_discounts table, and insert a single record. This record will include the new percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Again, we’ll use MERGE INTO to implement SCD type 3. The match condition is simple; if the discount_id in the discounts and stage_discounts table match, and the percent_off values differ, the existing record in the discounts table will be updated. The existing percent_off value will be moved to the previous_percent_off field, and then if the discount_id's in the two tables do not match, a new record will be inserted with the value NULL. Note that these records are not time-bound, and only a single historical value for percent_off can be maintained.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Remember, SCD type 3 is best implemented with data that rarely changes, and only the most recent historical entry is to be maintained. If multiple changes to the dimension are expected, it’s probably best to use SCD type 2.
When implementing any technique for slowly changing dimensions, it’s important to keep the possibility of duplicate data in mind. There are two types of duplicates to watch out for: intra-batch and inter-batch duplicates. Let’s break it down.
Intra-batch duplicates are duplicates that exist between different batches of data. If there is an existing dimension table, and two files meant to update this table may contain duplicate records.
To handle this, it’s important to add constraints to your logic that is “upserting” and/or loading data to a dimension table. In our examples above, we added logic throughout to ensure there were no duplicates. This included:
employee_id did not existpercent_off values were different in the items and stage_items table before updating an existing recordInter-batch duplicates are duplicates that occur in the same batch of data. For example, if a file contains two entries to update a single record in a dimension table, precautions must be taken. Like with intra-batch duplicates, it’s important to add constraints to the logic used to implement SCD type 1, 2, or 3.
If there are conflicting records in the same file, these records will have to be differentiated in some way. This could be metadata about the record or a source-provided timestamp. Whichever way you choose to handle these duplicates, it’s important to document your assumptions and review them with your team to ensure the resulting dimensions accurately capture operational values.
Sometimes, data changes when it shouldn’t. With the three SCD techniques we’ve discussed so far, this can lead to data being overwritten, a new row being added, or data being populated in a new column.
We’ve discussed ways to ensure duplicate data does not make its way into dimension tables. In addition to duplicate data, data practitioners implementing techniques to handle slowly changing dimensions will want to watch out for the following:
While not all of the cases above can be caught directly in the code used to maintain dimension tables, having strong data quality rules and processes to monitor dimensions can help to ensure data integrity is upheld.
In the retail example above, the datasets we worked with were made up of just a few rows of data. In a production setting, these dimension tables could contain hundreds or even thousands of records. This is quite common when implementing SCD type 2, especially if dimensions change frequently.
As the number of rows in a dimension table grows, it’s important for a data practitioner to keep performance at the forefront of their design and implementation plans. Here are a few ways to optimize SCD implementation for large datasets using Snowflake:
MERGE statement(s)UPDATE and INSERT statements where appropriate, rather than MERGEIf a dimension dataset becomes so large that system performance is compromised, a decision may need to be made about a tradeoff between historical accuracy and system performance. As mentioned above, this is typically the case when implementing SCD type 2.
If records change often, the number of rows in the table can balloon quickly. When this is the case, it may no longer be prudent to use SCD type 2 to maintain dimensional data.
Switching to leverage SCD type 1 or type 3 may offer similar functionality, with significant gains in system performance. The tradeoff is an incomplete representation of historical data. Work with your team to weigh this tradeoff before changing an approach to implement SCD.
It’s easy enough to run a one-time query to implement SCD for a dimension table. However, programmatically running this process to maintain this dimension in a production environment requires a little thought. Tools such as Apache Airflow are great for orchestrating these processes and provide a layer of monitoring and alerting to ensure nominal performance. By parameterizing the logic used to update dimension tables, Airflow can be used to kick off processes in your data platform for a scheduled period, taking the place of a data practitioner’s manual efforts
In addition to Airflow, tools such as Mage, Prefect, or Dagster can be used to orchestrate the implementation of slowly changing dimensions. If tools such as these are not readily available, homegrown orchestration tools can also do the trick.
Mastering slowly changing dimensions (SCD) is a fantastic skill to have in your tool belt, especially when creating your own data model.
In this article, we covered the basics of star schemas, as well as the definitions and basics of SCD. We explored SCD types 1, 2, and 3 for maintaining historical data while capturing a snapshot of the current state.
With the help of Snowflake, we implemented each of the SCD techniques defined above with the help of a retail example. After, we outlined some of the more technical challenges that implementing SCD may bring, and how to tackle these.
To keep growing your data modeling skills, take the Database Design, Introduction to Data Engineering, and Introduction to Data Warehousing courses available via DataCamp. Best of luck, and happy coding!
Start Your Data Journey Today!
Course
Course
Course
blog
John Marquez
12 min
blog
Bex Tuychiev
14 min
blog
Alena Guzharina
3 min
Tutorial
Bex Tuychiev
Tutorial
Tim Lu
Tutorial
Bex Tuychiev