
Curso
Introdução à Engenharia de Dados
4 h
127.6K
Há várias maneiras de lidar com dimensões que mudam lentamente. Vamos dar uma olhada em três das formas mais comuns.
Usando o SCD tipo 1, se um registro em uma tabela de dimensão for alterado, o registro existente será atualizado ou substituído. Caso contrário, o novo registro é inserido na tabela de dimensão. Isso significa que os registros na tabela de dimensão sempre refletem o estado atual e nenhum dado histórico é mantido.
Uma tabela que armazena informações sobre os itens vendidos em uma mercearia pode lidar com a alteração de registros usando o SCD tipo 1. Se já existir um registro na tabela para o item desejado, ele será atualizado com as novas informações. Caso contrário, o registro será inserido na tabela de dimensão.
No mundo da engenharia de dados, essa prática de atualizar os dados, caso eles existam, ou inseri-los, caso contrário, é conhecida como "upserting". A tabela abaixo contém informações sobre itens vendidos em uma mercearia.
|
item_id |
nome |
preço |
corredor |
|
93201 |
Batatas fritas |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Se as batatas fritas forem movidas para o corredor 6, o uso do SCD tipo 1 para capturar essa alteração na tabela de dimensões produzirá o resultado abaixo:
|
item_id |
nome |
preço |
corredor |
|
93201 |
Batatas fritas |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
O SCD tipo 1 garante que não haja registros duplicados na tabela e que os dados reflitam a dimensão atual mais recente. Isso é especialmente útil para painéis de controle em tempo real e modelagem preditiva, em que apenas o estado atual é de interesse.
No entanto, como apenas as informações mais recentes são armazenadas na tabela, os profissionais de dados não conseguem comparar as alterações nas dimensões ao longo do tempo. Por exemplo, um analista de dados teria dificuldade em identificar o aumento na receita de batatas fritas depois que elas foram transferidas para o corredor 6 sem outras informações.
O SCD tipo 1 facilita o relatório e a análise do estado atual, mas tem limitações ao realizar análises históricas.
Embora seja útil ter uma tabela que reflita apenas o estado atual, há ocasiões em que é conveniente, e até mesmo essencial, rastrear as alterações históricas em uma dimensão. Com o SCD tipo 2, os dados históricos são mantidos adicionando uma nova linha quando uma dimensão é alterada e denotando adequadamente essa nova linha como atual, ao mesmo tempo em que denota o novo registro histórico de acordo.
É fácil falar, mas talvez você não tenha certeza de como isso funciona na prática. Vamos dar uma olhada em um exemplo.
Aqui, temos uma tabela bastante semelhante ao exemplo que usamos ao explorar a SCD tipo 1. No entanto, uma coluna adicional foi adicionada. O is_current armazena um valor booleano; verdadeiro se o registro refletir o valor mais atual e falso caso contrário.
|
item_id |
nome |
preço |
corredor |
is_current |
|
93201 |
Batatas fritas |
3.99 |
11 |
Verdadeiro |
|
07879 |
Soda |
7.99 |
13 |
Verdadeiro |
Se as batatas fritas forem transferidas para o corredor 6, o uso do SCD tipo 2 para documentar essa alteração criaria uma tabela semelhante a esta:
|
item_id |
nome |
preço |
corredor |
is_current |
|
93201 |
Batatas fritas |
3.99 |
11 |
Falso |
|
07879 |
Soda |
7.99 |
13 |
Verdadeiro |
|
93201 |
Batatas fritas |
3.99 |
6 |
Verdadeiro |
Uma nova linha é adicionada para refletir a mudança no local das batatas fritas, com True armazenado na coluna is_current. Para manter os dados históricos e representar com precisão o estado atual, a coluna is_current do registro anterior é definida como False. Com SCD tipo 1,
Mas e se você quiser explorar como as vendas de batatas fritas reagiram a uma mudança de local? Isso é bastante difícil quando se usa apenas uma única coluna se houver vários registros históricos para um único item. Felizmente, há uma maneira fácil de fazer isso.
Dê uma olhada na tabela abaixo. Essa tabela de dimensão contém as mesmas informações que a anterior, mas, em vez de uma coluna is_current, ela tem as colunas start_date e end_date. Essas datas representam o período de tempo em que uma dimensão era a mais atual. Como os dados dessa tabela são os mais recentes, o site end_date está bem definido para o futuro.
|
item_id |
nome |
preço |
corredor |
start_date |
end_date |
|
93201 |
Batatas fritas |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Se as batatas fritas fossem transferidas para o corredor 6 em 4 de janeiro de 2024, a tabela atualizada ficaria assim:
|
item_id |
nome |
preço |
corredor |
start_date |
end_date |
|
93201 |
Batatas fritas |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Batatas fritas |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Observe que o site end_date para a primeira fileira foi atualizado para o último dia em que as batatas fritas estavam disponíveis no corredor 11. Um novo registro é adicionado, com as batatas fritas agora sendo armazenadas no corredor 6. Os endereços start_date e end_date ajudam a mostrar quando a alteração foi feita e indicam qual registro é o atual.
O uso dessa técnica para implementar o SCD tipo 1 não apenas preserva os dados históricos, mas também oferece informações sobre quando os dados foram alterados. Isso permite que os analistas e cientistas de dados explorem as mudanças operacionais, realizem testes A/B e possibilitem a tomada de decisões informadas.
Ao trabalhar com dados que devem ser alterados apenas uma vez, ou quando apenas o registro histórico mais recente é de interesse, o SCD tipo 3 é bastante útil. Em vez de "inserir" uma dimensão alterada ou armazenar a alteração como uma nova linha, o SCD tipo 3 usa uma coluna para representar a alteração. Isso é um pouco complicado de explicar, então vamos direto para um exemplo.
A tabela abaixo contém informações sobre esportes para equipes nos Estados Unidos. Aqui, a tabela contém duas colunas para armazenar o nome atual e histórico do estádio. Como cada uma dessas equipes está usando o nome original do estádio, a coluna previous_stadium_name é preenchida com NULLs.
|
team_id |
team_name |
esporte |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Futebol |
Estádio Triple X |
NULL |
|
930193 |
Esquilos de Fort Niagara |
Futebol |
Estádio Musket |
NULL |
Se os Lafayette Hawks decidirem contratar um novo patrocinador para um contrato de vinte e cinco anos, a tabela atualizada será mais ou menos assim:
|
team_id |
team_name |
esporte |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Hawks |
Futebol |
Campo de Wabash |
Estádio Triple X |
|
930193 |
Esquilos de Fort Niagara |
Futebol |
Estádio Musket |
NULL |
Para levar em conta o novo nome do estádio, "Triple X Stadium" foi movido para previous_stadium_name column, e "Wabash Field" tomou seu lugar na coluna current_stadium_name. O novo contrato de patrocínio, que tem duração de vinte e cinco anos, provavelmente sobreviverá ao modelo que está sendo construído, o que significa que é improvável que o recorde mude novamente.
O uso do SCD tipo 3 torna a comparação dos dados do estado atual com os dados históricos bastante simples. Há apenas uma única linha para cada equipe, e os dados atuais e históricos ficam lado a lado em duas colunas diferentes. No entanto, isso significa que apenas um único registro histórico para um atributo unidimensional pode ser mantido, o que pode ser limitante, especialmente se os dados mudarem com mais frequência do que o esperado.
Além dos tipos 1, 2 e 3, há várias outras técnicas para implementar dimensões que mudam lentamente. O tipo 0 é usado quando as dimensões nunca devem mudar. O tipo 4 armazena dados históricos em uma tabela separada e mantém os dados mais atuais em uma tabela de dimensão. O tipo 6 é um amálgama dos tipos 1, 2 e 3 e, normalmente, é implementado combinando os melhores recursos de cada uma dessas técnicas.
Abordamos os conceitos básicos das dimensões que mudam lentamente. Para que você entenda melhor como implementar cada uma dessas técnicas, vamos dar uma olhada em um exemplo.
Neste exemplo, usaremos o Snowflake para implementar o SCD tipo 1, 2 e 3 para transações de varejo. Se você precisar de uma atualização sobre o Snowflake, confira nosso curso de Introdução ao Snowflake.
Há uma tabela de fatos, chamada sales, e três tabelas de dimensões, com os nomes employees, items, e discounts. Abaixo você encontra o ERD para esse esquema em estrela.
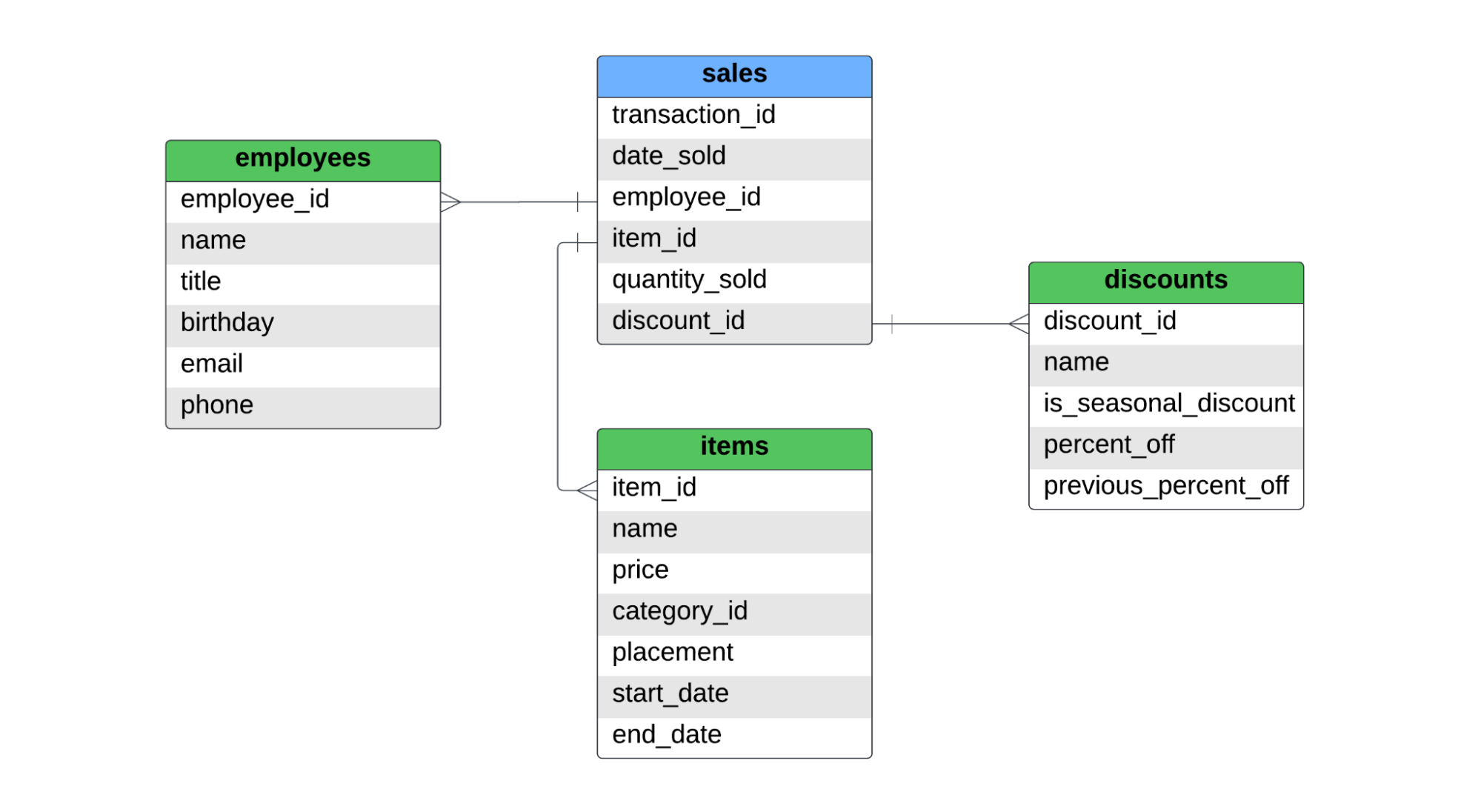
A tabela sales captura as vendas no nível do item. Se um cliente comprasse duas camisas e um par de jeans, haveria dois registros na tabela de fatos, pois dois itens diferentes foram vendidos. Para a SCD tipo 1, tipo 2 e tipo 3, abordaremos o seguinte:
Não exploraremos como essas tabelas foram originalmente preenchidas, mas, normalmente, um pipeline de ETL ou ELT a montante do data warehouse extraiu dados brutos da fonte, transformou-os no modelo desejado e os carregou em seu destino final.
Para praticar a implementação do SCD tipo 1, vamos dar uma olhada na tabela employee. Essa tabela contém informações básicas sobre um funcionário, incluindo seu nome, cargo e informações de contato. Ele pode conter registros como os abaixo.
|
ID do funcionário |
nome |
título |
aniversário |
|
telefone |
|
477379 |
Emily Verplank |
Gerente |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Caixa |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Usando o SCD tipo 1 para capturar essa dimensão que muda lentamente, o registro existente seria substituído pelo registro mais recente. Se um desses atributos dimensionais for alterado, o novo registro deverá ser "inserido" na tabela existente. Por exemplo, se o número de telefone de Emily mudar para 928-652-9704, a nova tabela terá a seguinte aparência:
|
ID do funcionário |
nome |
título |
aniversário |
|
telefone |
|
477379 |
Emily Verplank |
Gerente |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Caixa |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Para fazer isso com o Snowflake, usaremos o comando MERGE INTO. MERGE INTO permite que um praticante de dados forneça uma chave de correspondência e uma condição. Se a chave de correspondência e a condição forem atendidas, o registro poderá ser atualizado com a palavra-chave UPDATE. Caso contrário, um registro pode ser INSERT'ed, ou a execução pode ser interrompida.
Antes de começar a usar o comando MERGE INTO, primeiro criaremos e adicionaremos registros a uma tabela chamada stage_employees. Isso conterá todos os registros que foram atualizados desde que a tabela employees foi atualizada pela última vez. Você pode fazer isso com as declarações abaixo.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Agora, podemos usar a funcionalidade MERGE do Snowflake para "inserir" o registro existente.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Acima, a chave para mesclar dados entre as tabelas employees e stage_employees foi o campo employee_id. Outra condição não foi definida, o que significa que, se os employee_id corresponderem, os atributos dimensionais name, title, email e phone serão atualizados com os valores da tabela stage_employees para esse ID de funcionário. Se os registros da tabela stage_employees não corresponderem a nenhum registro da tabela employees, o registro será inserido na tabela employees.
A implementação do SCD tipo 2 é um pouco mais complicada do que a do SCD tipo 1. Embora não seja tão simples quanto substituir um registro existente ou inserir outro, ainda podemos usar a lógica MERGE INTO do Snowflake para resolver esse problema. Dê uma olhada na dimensão abaixo.
|
item_id |
nome |
preço |
category_id |
colocação |
start_date |
end_date |
|
667812 |
Meias |
8.99 |
156 |
Corredor 11 |
2023-08-24 |
NULL |
|
747295 |
Camiseta esportiva |
59.99 |
743 |
Corredor 8 |
2023-02-17 |
NULL |
Essa tabela contém informações sobre itens específicos vendidos em uma loja de varejo. Os atributos dimensionais incluem o nome, o preço e a localização do item, além de uma chave externa para a categoria à qual o item pertence. Para implementar o SCD tipo 2, precisaremos "atualizar" os dados, desta vez usando start_date e end_date para manter os dados históricos e atuais.
Digamos que, no início da temporada da NFL (Liga Nacional de Futebol Americano), as camisas esportivas sejam movidas para a frente da loja para melhor visibilidade quando um cliente entra. Juntamente com um novo local, o preço desse item foi reduzido. Para ilustrar esse comportamento operacional, bem como manter dados históricos, o registro existente é atualizado com uma data final e um novo é inserido. Dê uma olhada!
|
item_id |
nome |
preço |
category_id |
colocação |
start_date |
end_date |
|
667812 |
Meias |
8.99 |
156 |
Corredor 11 |
2023-08-24 |
NULL |
|
747295 |
Camiseta esportiva |
59.99 |
743 |
Corredor 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Camiseta esportiva |
49.99 |
743 |
Exibição de entrada |
2023-11-13 |
NULL |
Da mesma forma que antes, primeiro criaremos uma tabela chamada stage_items. Essa tabela armazenará registros que serão usados para implementar o SCD tipo 2 na dimensão items correspondente, que tem o formato mostrado acima. Depois que a tabela stage_items for criada, inseriremos um registro que contém a colocação e a alteração de preço das camisetas esportivas.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Agora, é hora de usar a funcionalidade MERGE INTO do Snowflake para implementar o SCD tipo 2. Isso é um pouco mais complicado do que o exemplo anterior e requer um pouco de raciocínio. Como um registro só pode ser inserido se a condição de correspondência NÃO for atendida, teremos que fazer isso em duas etapas. Primeiro, criaremos uma condição de correspondência com os três comandos a seguir:
item_id's na tabela items e stage_items devem corresponder a você.start_date na tabela stage_items deve ser maior do que na tabela items.end_date na tabela items deve ser NULLSe essas três condições forem atendidas, o registro original na tabela items deverá ser atualizado. Observe que a coluna items.end_date não será mais NULL; ela assumirá o valor de start_date na tabela stage_items. Não há lógica se o registro for incomparável nessa primeira declaração.
Em seguida, usaremos uma chamada separada para MERGE INTO para inserir o novo registro. Isso é um pouco mais difícil. Para que um novo registro seja inserido, a condição de correspondência não deve ser atendida.
Neste exemplo, podemos fazer isso verificando se os items_id's nas duas tabelas coincidem e se o end_date na tabela items é NULL. Vamos detalhar um pouco mais.
items_id coincidirem e o items.end_date for NULL, já haverá um registro na tabela items que é o mais atual. Isso significa que um novo registro não deve ser inserido.item_id's nas duas tabelas, a condição de correspondência não será atendida e uma nova linha será inserida. Esse será o primeiro registro para esse item_id na tabela items.item_id na tabela stage_items corresponder a registros com o mesmo item_id na tabela items, e o end_date não for NULL, um novo valor será inserido. Isso mantém os dados históricos e garante que um registro atual esteja presente na tabela items.Abaixo está a implementação, usando dois comandos MERGE INTO para primeiro atualizar o registro existente e depois inserir os dados mais atuais.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Por fim, daremos uma olhada na implementação do SCD tipo 3 com uma nova dimensão. Em nosso exemplo, a tabela discounts armazena informações sobre determinados descontos que os clientes podem resgatar no checkout. A tabela inclui o ID do desconto, bem como o nome, a porcentagem de desconto e a classificação como um desconto sazonal. Aqui está um exemplo de dois registros que podem estar presentes na tabela discounts.
|
discount_id |
nome |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Membro do programa de recompensas |
Falso |
10 |
NULL |
|
467782 |
Desconto para funcionários |
Falso |
50 |
NULL |
Como o varejista não espera que os descontos sejam alterados com frequência, essa dimensão é uma ótima candidata para a implementação de uma abordagem do tipo 3 para obter dimensões que mudam lentamente. Se a porcentagem de desconto oferecida pelo desconto for alterada, a porcentagem de desconto anterior será movida para a coluna previous_percent_off , enquanto o novo valor ocupará seu lugar na coluna percent_off.
Isso permite que os dados históricos sejam mantidos enquanto você expõe o valor mais recente na coluna percent_off.
|
discount_id |
nome |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Membro do programa de recompensas |
Falso |
10 |
NULL |
|
467782 |
Desconto para funcionários |
Falso |
35 |
50 |
Para implementar isso com o Snowflake, criaremos uma tabela stage_discounts e inseriremos um único registro. Esse registro incluirá o novo percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Novamente, usaremos o site MERGE INTO para implementar o SCD tipo 3. A condição de correspondência é simples: se os valores de discount_id nas tabelas discounts e stage_discounts forem iguais e os valores de percent_off forem diferentes, o registro existente na tabela discounts será atualizado. O valor existente em percent_off será movido para o campo previous_percent_off e, em seguida, se os discount_id's nas duas tabelas não corresponderem, um novo registro será inserido com o valor NULL. Observe que esses registros não são limitados no tempo, e somente um único valor histórico para percent_off pode ser mantido.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Lembre-se de que o SCD tipo 3 é melhor implementado com dados que raramente mudam, e somente o registro histórico mais recente deve ser mantido. Se forem esperadas várias alterações na dimensão, provavelmente será melhor usar o SCD tipo 2.
Ao implementar qualquer técnica para alterar lentamente as dimensões, é importante que você tenha em mente a possibilidade de dados duplicados. Você deve ficar atento a dois tipos de duplicatas: duplicatas intra-lote e inter-lote. Vamos detalhar isso.
As duplicatas intra-lote são duplicatas que existem entre diferentes lotes de dados. Se houver uma tabela de dimensão existente, e dois arquivos destinados a atualizar essa tabela podem conter registros duplicados.
Para lidar com isso, é importante adicionar restrições à lógica que está "upserting" e/ou carregando dados em uma tabela de dimensão. Em nossos exemplos acima, adicionamos lógica para garantir que não houvesse duplicatas. Isso inclui:
employee_id percent_off eram diferentes na tabela de itens e stage_items antes de atualizar um registro existenteAs duplicatas entre lotes são duplicatas que ocorrem no mesmo lote de dados. Por exemplo, se um arquivo contiver duas entradas para atualizar um único registro em uma tabela de dimensão, é necessário tomar precauções. Assim como no caso das duplicatas dentro do lote, é importante adicionar restrições à lógica usada para implementar o SCD tipo 1, 2 ou 3.
Se houver registros conflitantes no mesmo arquivo, esses registros terão que ser diferenciados de alguma forma. Podem ser metadados sobre o registro ou um carimbo de data e hora fornecido pela fonte. Seja qual for a maneira que você escolher para lidar com essas duplicatas, é importante documentar suas suposições e revisá-las com sua equipe para garantir que as dimensões resultantes capturem com precisão os valores operacionais.
Às vezes, os dados mudam quando não deveriam. Com as três técnicas de SCD que discutimos até agora, isso pode fazer com que os dados sejam substituídos, que uma nova linha seja adicionada ou que os dados sejam preenchidos em uma nova coluna.
Discutimos maneiras de garantir que dados duplicados não entrem nas tabelas de dimensão. Além dos dados duplicados, os profissionais de dados que implementam técnicas para lidar com dimensões que mudam lentamente devem ficar atentos ao seguinte:
Embora nem todos os casos acima possam ser detectados diretamente no código usado para manter as tabelas de dimensões, ter regras e processos sólidos de qualidade de dados para monitorar as dimensões pode ajudar a garantir que a integridade dos dados seja mantida.
No exemplo de varejo acima, os conjuntos de dados com os quais trabalhamos eram compostos de apenas algumas linhas de dados. Em uma configuração de produção, essas tabelas de dimensão podem conter centenas ou até milhares de registros. Isso é bastante comum ao implementar o SCD tipo 2, especialmente se as dimensões mudarem com frequência.
À medida que o número de linhas em uma tabela de dimensão aumenta, é importante que um profissional de dados mantenha o desempenho na vanguarda de seus planos de design e implementação. Aqui estão algumas maneiras de otimizar a implementação do SCD para grandes conjuntos de dados usando o Snowflake:
MERGE.UPDATE e INSERT quando apropriado, em vez de MERGESe um conjunto de dados de dimensão se tornar tão grande que o desempenho do sistema seja comprometido, talvez seja necessário tomar uma decisão sobre uma compensação entre a precisão histórica e o desempenho do sistema. Conforme mencionado acima, esse é o caso típico da implementação do SCD tipo 2.
Se os registros forem alterados com frequência, o número de linhas na tabela poderá aumentar rapidamente. Quando esse for o caso, talvez não seja mais prudente usar o SCD tipo 2 para manter os dados dimensionais.
A mudança para a alavancagem do SCD tipo 1 ou tipo 3 pode oferecer funcionalidade semelhante, com ganhos significativos no desempenho do sistema. A desvantagem é uma representação incompleta dos dados históricos. Trabalhe com sua equipe para avaliar essa troca antes de mudar uma abordagem para implementar o SCD.
É bastante fácil executar uma consulta única para implementar o SCD em uma tabela de dimensão. No entanto, a execução programática desse processo para manter essa dimensão em um ambiente de produção requer um pouco de reflexão. Ferramentas como o Apache Airflow são ótimas para orquestrar esses processos e fornecer uma camada de monitoramento e alerta para garantir o desempenho nominal. Ao parametrizar a lógica usada para atualizar as tabelas de dimensão, o Airflow pode ser usado para iniciar processos em sua plataforma de dados por um período programado, substituindo os esforços manuais de um profissional de dados
Além do Airflow, ferramentas como Mage, Prefect ou Dagster podem ser usadas para orquestrar a implementação de dimensões que mudam lentamente. Se ferramentas como essas não estiverem prontamente disponíveis, as ferramentas de orquestração desenvolvidas internamente também podem ser úteis.
Dominar as dimensões que mudam lentamente (SCD) é uma habilidade fantástica que você deve ter em seu conjunto de ferramentas, especialmente ao criar seu próprio modelo de dados.
Neste artigo, abordamos os conceitos básicos dos esquemas em estrela, bem como as definições e os conceitos básicos do SCD. Exploramos os tipos 1, 2 e 3 de SCD para manter os dados históricos e, ao mesmo tempo, capturar um instantâneo do estado atual.
Com a ajuda do Snowflake, implementamos cada uma das técnicas de SCD definidas acima com a ajuda de um exemplo de varejo. Em seguida, descrevemos alguns dos desafios mais técnicos que a implementação do SCD pode trazer e como lidar com eles.
Para continuar aprimorando suas habilidades de modelagem de dados, faça os cursos Database Design, Introduction to Data Engineering e Introduction to Data Warehousing disponíveis no DataCamp. Boa sorte e boa codificação!
Comece sua jornada de dados hoje mesmo!
Curso
Curso
Curso
blog
Abid Ali Awan
7 min
blog
Matt Crabtree
11 min
blog
Nisha Arya Ahmed
15 min
blog
Mark Graus
15 min
blog
Joyce Chiu
8 min
Tutorial
Abid Ali Awan
