
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Es gibt eine Reihe von Möglichkeiten, mit langsam wechselnden Dimensionen umzugehen. Werfen wir einen Blick auf drei der häufigsten Wege.
Wenn sich ein Datensatz in einer Dimensionstabelle ändert, wird der bestehende Datensatz mit SCD Typ 1 aktualisiert oder überschrieben. Andernfalls wird der neue Datensatz in die Dimensionstabelle eingefügt. Das bedeutet, dass die Datensätze in der Dimensionstabelle immer den aktuellen Stand widerspiegeln und keine historischen Daten gepflegt werden.
Eine Tabelle, in der Informationen über die in einem Lebensmittelgeschäft verkauften Artikel gespeichert sind, könnte mit dem SCD-Typ 1 veränderte Datensätze verarbeiten. Wenn in der Tabelle bereits ein Datensatz für den gewünschten Artikel existiert, wird er mit den neuen Informationen aktualisiert. Andernfalls wird der Datensatz in die Dimensionstabelle eingefügt.
In der Welt der Datentechnik wird diese Praxis, Daten zu aktualisieren, wenn sie bereits existieren, oder sie anderweitig einzufügen, als "Upserting" bezeichnet. Die folgende Tabelle enthält Informationen über Artikel, die in einem Lebensmittelladen verkauft werden.
|
item_id |
Name |
Preis |
Gang |
|
93201 |
Kartoffelchips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Wenn Kartoffelchips in Gang 6 verschoben werden, führt die Verwendung des SCD-Typs 1 zur Erfassung dieser Änderung in der Tabelle mit den Abmessungen zu folgendem Ergebnis:
|
item_id |
Name |
Preis |
Gang |
|
93201 |
Kartoffelchips |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
SCD Typ 1 stellt sicher, dass es keine doppelten Datensätze in der Tabelle gibt und dass die Daten die letzte aktuelle Dimension widerspiegeln. Dies ist besonders nützlich für Echtzeit-Dashboarding und prädiktive Modellierung, wo nur der aktuelle Zustand von Interesse ist.
Da jedoch nur die aktuellsten Informationen in der Tabelle gespeichert werden, können Datenpraktiker/innen die Veränderungen der Dimensionen im Laufe der Zeit nicht vergleichen. Ein Datenanalyst hätte z. B. Schwierigkeiten, den Umsatzanstieg bei Kartoffelchips zu erkennen, nachdem diese in Gang 6 verlegt wurden, ohne weitere Informationen.
SCD Typ 1 erleichtert die Berichterstattung und Analyse des aktuellen Zustands, hat aber Einschränkungen bei der Durchführung historischer Analysen.
Eine Tabelle, die nur den aktuellen Stand widerspiegelt, kann zwar nützlich sein, aber manchmal ist es sinnvoll oder sogar notwendig, historische Änderungen an einer Dimension zu verfolgen. Beim SCD-Typ 2 werden historische Daten beibehalten, indem eine neue Zeile hinzugefügt wird, wenn sich eine Dimension ändert, und diese neue Zeile ordnungsgemäß als aktuell bezeichnet wird, während der neue historische Datensatz entsprechend gekennzeichnet wird.
Das sagt sich leicht, aber es ist vielleicht nicht ganz klar, wie das in der Praxis aussieht. Werfen wir einen Blick auf ein Beispiel.
Hier haben wir eine Tabelle, die dem Beispiel, das wir bei der Untersuchung von SCD Typ 1 verwendet haben, sehr ähnlich ist. Es wurde jedoch eine zusätzliche Spalte hinzugefügt. Auf is_current wird ein boolescher Wert gespeichert: true, wenn der Datensatz den aktuellsten Wert widerspiegelt, und false, wenn nicht.
|
item_id |
Name |
Preis |
Gang |
is_current |
|
93201 |
Kartoffelchips |
3.99 |
11 |
Wahr |
|
07879 |
Soda |
7.99 |
13 |
Wahr |
Wenn Kartoffelchips in Gang 6 verlegt werden, würde eine Tabelle mit SCD-Typ 2, die diese Änderung dokumentiert, wie folgt aussehen:
|
item_id |
Name |
Preis |
Gang |
is_current |
|
93201 |
Kartoffelchips |
3.99 |
11 |
Falsch |
|
07879 |
Soda |
7.99 |
13 |
Wahr |
|
93201 |
Kartoffelchips |
3.99 |
6 |
Wahr |
Es wird eine neue Zeile hinzugefügt, um die Änderung des Standorts für Kartoffelchips widerzuspiegeln, wobei True in der Spalte is_current gespeichert wird. Um historische Daten zu erhalten und den aktuellen Zustand genau darzustellen, wird die Spalte is_current für den vorherigen Datensatz auf False gesetzt. Mit SCD Typ 1,
Aber was ist, wenn du herausfinden möchtest, wie die Verkäufe von Kartoffelchips auf eine Veränderung des Standorts reagiert haben? Das ist ziemlich schwierig, wenn nur eine einzige Spalte verwendet wird und es mehrere historische Datensätze für einen einzelnen Artikel gibt. Zum Glück gibt es einen einfachen Weg, das zu tun.
Wirf einen Blick auf die Tabelle unten. Diese Dimensionstabelle enthält dieselben Informationen wie zuvor, aber statt einer is_current Spalte hat sie sowohl eine start_date als auch eine end_date Spalte. Diese Daten stellen den Zeitraum dar, in dem eine Dimension am aktuellsten war. Da die Daten in dieser Tabelle die neuesten sind, liegt die end_date weit in der Zukunft.
|
item_id |
Name |
Preis |
Gang |
start_date |
end_date |
|
93201 |
Kartoffelchips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Wenn die Kartoffelchips am 4. Januar 2024 in Gang 6 umziehen würden, sähe die aktualisierte Tabelle wie folgt aus:
|
item_id |
Name |
Preis |
Gang |
start_date |
end_date |
|
93201 |
Kartoffelchips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Kartoffelchips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Beachte, dass die end_date für die erste Reihe auf den letzten Tag aktualisiert wurde, an dem Kartoffelchips in Gang 11 erhältlich waren. Es gibt einen neuen Rekord: Die Kartoffelchips stehen jetzt in Gang 6. Auf start_date und end_date kannst du sehen, wann die Änderung vorgenommen wurde und welcher Datensatz aktuell ist.
Wenn du diese Technik zur Umsetzung von SCD Typ 1 verwendest, bleiben nicht nur historische Daten erhalten, sondern du erhältst auch Informationen darüber, wann sich die Daten geändert haben. So können Datenanalysten und Datenwissenschaftler betriebliche Veränderungen untersuchen, A/B-Tests durchführen und fundierte Entscheidungen treffen.
Wenn du mit Daten arbeitest, die sich voraussichtlich nur einmal ändern werden, oder wenn nur der jüngste historische Datensatz von Interesse ist, ist SCD Typ 3 sehr nützlich. Anstatt eine geänderte Dimension "einzufügen" oder die Änderung als neue Zeile zu speichern, verwendet SCD Typ 3 eine Spalte, um die Änderung darzustellen. Das ist ein bisschen kompliziert zu erklären, also lass uns gleich mit einem Beispiel anfangen.
Die folgende Tabelle enthält Informationen über Sportarten für Teams in den Vereinigten Staaten. Hier enthält die Tabelle zwei Spalten, in denen der aktuelle und der historische Stadionname gespeichert werden. Da jedes dieser Teams den ursprünglichen Stadionnamen verwendet, ist die Spalte previous_stadium_name mit NULLgefüllt.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Falken |
Fußball |
Triple X Stadion |
NULL |
|
930193 |
Fort Niagara Eichhörnchen |
Fußball |
Musketenstadion |
NULL |
Wenn sich die Lafayette Hawks entscheiden, einen neuen Sponsor für einen Fünfundzwanzigjahresvertrag zu engagieren, wird die aktualisierte Tabelle etwa so aussehen:
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Lafayette Falken |
Fußball |
Wabash Feld |
Triple X Stadion |
|
930193 |
Fort Niagara Eichhörnchen |
Fußball |
Musketenstadion |
NULL |
Um dem neuen Stadionnamen Rechnung zu tragen, wird "Triple X Stadium '' auf die previous_stadium_name column verschoben, und "Wabash Field '' nimmt seinen Platz in der current_stadium_name Spalte ein. Der neue Sponsoringvertrag hat eine Laufzeit von fünfundzwanzig Jahren und wird höchstwahrscheinlich das gebaute Modell überdauern, was bedeutet, dass sich der Rekord wahrscheinlich nicht mehr ändern wird.
Mit SCD Typ 3 ist es ganz einfach, aktuelle Daten mit historischen Daten zu vergleichen. Es gibt nur eine Zeile für jedes Team, und die aktuellen und historischen Daten stehen in zwei verschiedenen Spalten nebeneinander. Das bedeutet jedoch, dass nur ein einziger historischer Datensatz für ein eindimensionales Attribut gepflegt werden kann, was vor allem dann einschränkend sein kann, wenn sich die Daten häufiger als erwartet ändern.
Neben den Typen 1, 2 und 3 gibt es eine Reihe weiterer Techniken, um langsam wechselnde Dimensionen zu realisieren. Typ 0 wird verwendet, wenn sich die Abmessungen nie ändern sollen. Typ 4 speichert historische Daten in einer separaten Tabelle, während die aktuellsten Daten in einer Dimensionstabelle aufbewahrt werden. Typ 6 ist eine Verschmelzung der Typen 1, 2 und 3 und wird in der Regel durch die Kombination der besten Eigenschaften jeder dieser Techniken umgesetzt.
Wir haben die Grundlagen des langsamen Dimensionswechsels behandelt. Um ein besseres Verständnis dafür zu bekommen, wie jede dieser Techniken umgesetzt wird, schauen wir uns ein Beispiel an.
In diesem Beispiel verwenden wir Snowflake, um SCD Typ 1, 2 und 3 für Einzelhandelstransaktionen zu implementieren. Wenn du einen Auffrischungskurs zu Snowflake brauchst, schau dir unseren Kurs Einführung in Snowflake an.
Es gibt eine Faktentabelle mit dem Namen sales und drei Dimensionstabellen mit den Namen employees, items und discounts. Unten findest du das ERD für dieses Sternschema.
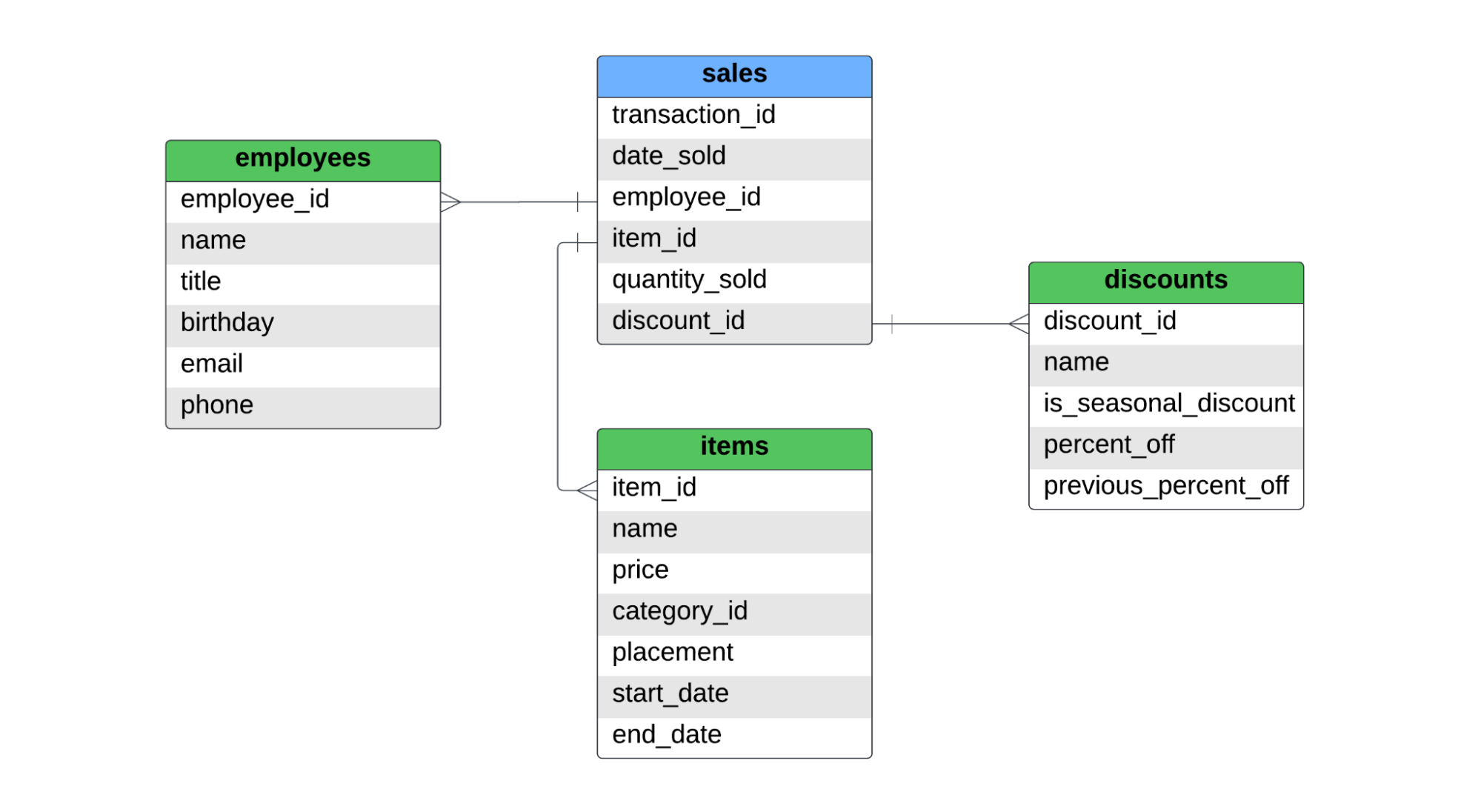
In der Tabelle sales werden die Verkäufe auf Artikelebene erfasst. Wenn ein Kunde zwei Hemden und eine Jeans gekauft hat, gibt es zwei Datensätze in der Faktentabelle, da zwei verschiedene Artikel verkauft wurden. Für SCD Typ 1, Typ 2 und Typ 3 werden wir die folgenden Themen behandeln:
Wir werden nicht näher darauf eingehen, wie diese Tabellen ursprünglich gefüllt wurden, aber in der Regel hat eine dem Data Warehouse vorgeschaltete ETL- oder ELT-Pipeline die Rohdaten aus der Quelle gezogen, sie in das gewünschte Modell umgewandelt und in das endgültige Ziel geladen.
Um die Umsetzung von SCD Typ 1 zu üben, werfen wir einen Blick auf die Tabelle employee. Diese Tabelle enthält grundlegende Informationen über einen Mitarbeiter, darunter Name, Titel und Kontaktinformationen. Sie kann Datensätze wie die folgenden enthalten.
|
employee_id |
Name |
title |
Geburtstag |
|
Telefon |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Kassierer |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Wenn du den SCD-Typ 1 verwendest, um diese sich langsam verändernde Dimension zu erfassen, würde der bestehende Datensatz durch den neuesten Datensatz überschrieben werden. Wenn sich eines dieser Dimensionsattribute ändert, sollte der neue Datensatz in die bestehende Tabelle "hochgesetzt" werden. Wenn sich zum Beispiel Emilys Telefonnummer in 928-652-9704 ändert, würde die neue Tabelle wie folgt aussehen:
|
employee_id |
Name |
title |
Geburtstag |
|
Telefon |
|
477379 |
Emily Verplank |
Manager |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Kassierer |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Um dies mit Snowflake zu tun, verwenden wir den Befehl MERGE INTO. MERGE INTO ermöglicht es einem Datenpraktiker, einen Übereinstimmungsschlüssel und eine Bedingung anzugeben. Wenn der Übereinstimmungsschlüssel und die Bedingung erfüllt sind, kann der Datensatz mit dem Schlüsselwort UPDATEaktualisiert werden. Andernfalls kann ein Datensatz INSERT'ed werden, oder die Ausführung kann abgebrochen werden.
Bevor wir mit dem Befehl MERGE INTO beginnen, erstellen wir zunächst eine Tabelle namens stage_employees und fügen ihr Datensätze hinzu. Diese enthält alle Datensätze, die seit der letzten Aktualisierung der Tabelle employees aktualisiert wurden. Das können wir mit den folgenden Aussagen tun.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Jetzt können wir die Funktion MERGE von Snowflake nutzen, um den bestehenden Datensatz "hochzuladen".
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Der Schlüssel zum Zusammenführen von Daten zwischen den Tabellen employees und stage_employees war das Feld employee_id. Eine weitere Bedingung wurde nicht gesetzt, d.h. wenn die employee_id übereinstimmten, wurden die Dimensionsattribute name, title, email und phone mit den Werten aus der Tabelle stage_employees für diese Mitarbeiter-ID aktualisiert. Wenn die Datensätze in stage_employees nicht mit denen in der Tabelle employees übereinstimmen, wird der Datensatz in die Tabelle "Mitarbeiter" eingefügt.
Die Umsetzung von SCD Typ 2 ist etwas schwieriger als SCD Typ 1. Es ist zwar nicht ganz so einfach, einen bestehenden Datensatz zu überschreiben oder einen neuen einzufügen, aber wir können die MERGE INTO Logik von Snowflake nutzen, um dieses Problem zu lösen. Sieh dir die Dimensionen unten an.
|
item_id |
Name |
Preis |
category_id |
Platzierung |
start_date |
end_date |
|
667812 |
Socken |
8.99 |
156 |
Gang 11 |
2023-08-24 |
NULL |
|
747295 |
Sport Trikot |
59.99 |
743 |
Gang 8 |
2023-02-17 |
NULL |
Diese Tabelle enthält Informationen über bestimmte Artikel, die in einem Einzelhandelsgeschäft verkauft werden. Die Dimensionsattribute umfassen den Namen, den Preis und die Platzierung des Artikels sowie einen Fremdschlüssel für die Kategorie, zu der der Artikel gehört. Um SCD Typ 2 zu implementieren, müssen wir Daten "hochladen", diesmal mit start_date und end_date, um sowohl historische als auch aktuelle Daten zu erhalten.
Angenommen, zu Beginn der NFL-Saison (National Football League) werden die Trikots in den vorderen Teil des Ladens verlegt, damit sie besser sichtbar sind, wenn ein Kunde den Laden betritt. Zusammen mit einem neuen Standort wird der Preis dieses Artikels reduziert. Um dieses betriebliche Verhalten zu veranschaulichen und um historische Daten zu erhalten, wird der bestehende Datensatz mit einem Enddatum aktualisiert und ein neuer Datensatz eingefügt. Schau es dir an!
|
item_id |
Name |
Preis |
category_id |
Platzierung |
start_date |
end_date |
|
667812 |
Socken |
8.99 |
156 |
Gang 11 |
2023-08-24 |
NULL |
|
747295 |
Sport Trikot |
59.99 |
743 |
Gang 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Sport Trikot |
49.99 |
743 |
Eintrag Display |
2023-11-13 |
NULL |
Ähnlich wie zuvor erstellen wir zunächst eine Tabelle namens stage_items. In dieser Tabelle werden Datensätze gespeichert, die für die Umsetzung des SCD-Typs 2 in der entsprechenden Dimension items verwendet werden, die die oben dargestellte Form hat. Sobald die Tabelle stage_items erstellt ist, fügen wir einen Datensatz ein, der sowohl die Platzierung als auch die Preisänderung für Sporttrikots enthält.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Jetzt ist es an der Zeit, Snowflakes MERGE INTO -Funktionalität zu nutzen, um SCD Typ 2 zu implementieren. Das ist ein bisschen kniffliger als das vorherige Beispiel und erfordert ein bisschen Nachdenken. Da ein Datensatz nur eingefügt werden kann, wenn die Übereinstimmungsbedingung NICHT erfüllt ist, müssen wir dies in zwei Schritten tun. Zuerst erstellen wir eine Übereinstimmungsbedingung mit den folgenden drei Anweisungen:
item_id's in den Tabellen items und stage_items müssen übereinstimmen.start_date in der Tabelle stage_items muss größer sein als in der Tabelle items end_date in der Tabelle items muss von NULLWenn diese drei Bedingungen erfüllt sind, muss der ursprüngliche Datensatz in der Tabelle items aktualisiert werden. Beachte, dass die Spalte items.end_date nicht mehr NULL heißt, sondern den Wert der Spalte start_date in der Tabelle stage_items annimmt. Es gibt keine Logik, wenn der Datensatz in dieser ersten Anweisung nicht übereinstimmt.
Als Nächstes verwenden wir einen separaten Aufruf von MERGE INTO, um den neuen Datensatz einzufügen. Das ist ein bisschen schwieriger. Damit ein neuer Datensatz eingefügt werden kann, darf die Übereinstimmungsbedingung nicht erfüllt sein.
In diesem Beispiel können wir dies tun, indem wir prüfen, ob die items_id's in den beiden Tabellen übereinstimmen und die end_date in der Tabelle items NULL ist. Lass uns das noch ein bisschen weiter aufschlüsseln.
items_id's übereinstimmen und die items.end_date NULL ist, gibt es bereits einen Datensatz in der items Tabelle, der der aktuellste ist. Das bedeutet, dass ein neuer Datensatz nicht eingefügt werden sollte.item_id's in den beiden Tabellen gibt, wird die Übereinstimmungsbedingung nicht erfüllt und eine neue Zeile wird eingefügt. Dies ist der erste Datensatz für diese item_id in der Tabelle items.item_id in der Tabelle stage_items mit den Datensätzen des item_id in der Tabelle items übereinstimmt und der end_date nicht NULL ist, wird ein neuer Wert eingefügt. Dadurch werden historische Daten beibehalten und sichergestellt, dass ein aktueller Datensatz in der Tabelle items vorhanden ist.Im Folgenden siehst du die Implementierung, die zwei MERGE INTO Anweisungen verwendet, um zuerst den bestehenden Datensatz zu aktualisieren und dann die aktuellsten Daten einzufügen.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Zum Schluss werfen wir einen Blick auf die Umsetzung von SCD Typ 3 mit einer neuen Dimension. In unserem Beispiel speichert die Tabelle discounts Informationen über bestimmte Rabatte, die Kunden an der Kasse einlösen können. Die Tabelle enthält die ID des Rabatts sowie den Namen, den prozentualen Nachlass und die Einstufung als saisonaler Rabatt. Hier ist ein Beispiel für zwei Datensätze, die in der Tabelle discounts vorhanden sein könnten.
|
discount_id |
Name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Belohnungsmitglied |
Falsch |
10 |
NULL |
|
467782 |
Mitarbeiterrabatt |
Falsch |
50 |
NULL |
Da der Einzelhändler nicht erwartet, dass sich die Rabatte oft ändern, ist diese Dimension ein guter Kandidat für die Umsetzung eines Typ-3-Ansatzes, um langsam wechselnde Dimensionen zu erfassen. Wenn sich der prozentuale Nachlass, der über den Rabatt angeboten wird, ändert, wird der bisherige Nachlass in die Spalte previous_percent_off verschoben, während der neue Wert seinen Platz in der Spalte percent_off einnimmt.
So können historische Daten beibehalten werden, während der aktuellste Wert in der Spalte percent_off angezeigt wird.
|
discount_id |
Name |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Belohnungsmitglied |
Falsch |
10 |
NULL |
|
467782 |
Mitarbeiterrabatt |
Falsch |
35 |
50 |
Um dies mit Snowflake umzusetzen, erstellen wir eine Tabelle stage_discounts und fügen einen einzelnen Datensatz ein. Dieser Datensatz wird die neue percent_off enthalten.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Auch hier verwenden wir MERGE INTO, um SCD Typ 3 umzusetzen. Die Abgleichsbedingung ist einfach: Wenn die discount_id in den Tabellen discounts und stage_discounts übereinstimmen und die percent_off Werte unterschiedlich sind, wird der bestehende Datensatz in der Tabelle discounts aktualisiert. Der bestehende Wert percent_off wird in das Feld previous_percent_off verschoben, und wenn die Werte discount_id in den beiden Tabellen nicht übereinstimmen, wird ein neuer Datensatz mit dem Wert NULL eingefügt. Beachte, dass diese Aufzeichnungen nicht zeitgebunden sind und nur ein einziger historischer Wert für percent_off gepflegt werden kann.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Denke daran, dass SCD Typ 3 am besten mit Daten umgesetzt wird, die sich selten ändern, und dass nur der letzte historische Eintrag beibehalten werden soll. Wenn mehrere Änderungen an der Dimension zu erwarten sind, ist es wahrscheinlich am besten, SCD Typ 2 zu verwenden.
Wenn du eine Technik zur langsamen Veränderung von Dimensionen anwendest, musst du die Möglichkeit von doppelten Daten im Auge behalten. Es gibt zwei Arten von Duplikaten, auf die du achten musst: Intra-Batch- und Inter-Batch-Duplikate. Lass uns das mal aufschlüsseln.
Intra-Batch-Duplikate sind Duplikate, die zwischen verschiedenen Chargen von Daten bestehen. Wenn es eine bestehende Dimensionstabelle gibt und zwei Dateien, die diese Tabelle aktualisieren sollen, können doppelte Datensätze enthalten.
Deshalb ist es wichtig, dass du deine Logik beim Einfügen und/oder Laden von Daten in eine Dimensionstabelle mit Beschränkungen versiehst. In unseren obigen Beispielen haben wir durchgehend Logik hinzugefügt, um sicherzustellen, dass es keine Duplikate gibt. Dazu gehören:
employee_id existiertpercent_off in den Tabellen items und stage_items unterschiedlich sind, bevor ein bestehender Datensatz aktualisiert wirdBatchübergreifende Duplikate sind Duplikate, die im selben Datenstapel auftreten. Wenn eine Datei zum Beispiel zwei Einträge enthält, um einen einzigen Datensatz in einer Dimensionstabelle zu aktualisieren, müssen Vorsichtsmaßnahmen getroffen werden. Wie bei den Intra-Batch-Duplikaten ist es wichtig, die Logik für die Implementierung von SCD Typ 1, 2 oder 3 mit Einschränkungen zu versehen.
Wenn es in derselben Datei widersprüchliche Datensätze gibt, müssen diese auf irgendeine Weise unterschieden werden. Dies können Metadaten über den Datensatz oder ein von der Quelle bereitgestellter Zeitstempel sein. Unabhängig davon, wie du mit diesen Duplikaten umgehst, ist es wichtig, dass du deine Annahmen dokumentierst und sie mit deinem Team überprüfst, um sicherzustellen, dass die resultierenden Dimensionen die betrieblichen Werte genau erfassen.
Manchmal ändern sich Daten, wenn sie sich nicht ändern sollten. Bei den drei SCD-Techniken, die wir bisher besprochen haben, kann dies dazu führen, dass Daten überschrieben werden, eine neue Zeile hinzugefügt wird oder Daten in eine neue Spalte eingefügt werden.
Wir haben besprochen, wie du sicherstellen kannst, dass keine doppelten Daten in Dimensionstabellen auftauchen. Zusätzlich zu doppelten Daten sollten Datenpraktiker, die Techniken zur Handhabung sich langsam ändernder Dimensionen einsetzen, auf Folgendes achten:
Auch wenn nicht alle der oben genannten Fälle direkt im Code zur Pflege der Tabellen erfasst werden können, können strenge Datenqualitätsregeln und Prozesse zur Überwachung der Tabellen dazu beitragen, dass die Datenintegrität gewahrt bleibt.
Im obigen Beispiel aus dem Einzelhandel bestanden die Datensätze, mit denen wir gearbeitet haben, nur aus einigen wenigen Datenzeilen. In einer Produktionsumgebung können diese Tabellen Hunderte oder sogar Tausende von Datensätzen enthalten. Das kommt bei der Umsetzung von SCD Typ 2 häufig vor, vor allem wenn sich die Maße häufig ändern.
Wenn die Anzahl der Zeilen in einer Dimensionstabelle wächst, ist es für Datenexperten wichtig, die Leistung in den Vordergrund ihrer Design- und Implementierungspläne zu stellen. Hier sind einige Möglichkeiten, wie du die SCD-Implementierung für große Datensätze mit Snowflake optimieren kannst:
MERGE Anweisung(en) zu verarbeitenden Daten zu reduzieren.UPDATE und INSERT, wo es angebracht ist, anstatt MERGEWenn ein Dimensionsdatensatz so groß wird, dass die Systemleistung beeinträchtigt wird, muss unter Umständen eine Entscheidung über einen Kompromiss zwischen historischer Genauigkeit und Systemleistung getroffen werden. Wie bereits erwähnt, ist dies typischerweise bei der Umsetzung von SCD Typ 2 der Fall.
Wenn sich die Datensätze häufig ändern, kann die Anzahl der Zeilen in der Tabelle schnell ansteigen. Wenn dies der Fall ist, ist es möglicherweise nicht mehr ratsam, den SCD-Typ 2 zur Pflege von Maßdaten zu verwenden.
Die Umstellung auf Leverage SCD Typ 1 oder Typ 3 kann ähnliche Funktionen bieten und die Systemleistung erheblich steigern. Der Kompromiss ist eine unvollständige Darstellung der historischen Daten. Arbeite mit deinem Team zusammen, um diesen Kompromiss abzuwägen, bevor du einen Ansatz zur Umsetzung von SCD änderst.
Es ist ganz einfach, eine einmalige Abfrage durchzuführen, um SCD für eine Dimensionstabelle zu implementieren. Um diese Dimension in einer Produktionsumgebung aufrechtzuerhalten, muss man jedoch ein wenig programmieren. Tools wie Apache Airflow eignen sich hervorragend für die Orchestrierung dieser Prozesse und bieten eine Überwachungs- und Alarmierungsebene, um die Nennleistung sicherzustellen. Durch die Parametrisierung der Logik für die Aktualisierung von Tabellen kann Airflow Prozesse in deiner Datenplattform für einen geplanten Zeitraum anstoßen und so die manuellen Bemühungen eines Datenexperten ersetzen.
Zusätzlich zu Airflow können Tools wie Mage, Prefect oder Dagster verwendet werden, um die Umsetzung von sich langsam verändernden Dimensionen zu orchestrieren. Wenn solche Tools nicht ohne Weiteres verfügbar sind, können auch selbst entwickelte Orchestrierungstools den Zweck erfüllen.
Die Beherrschung von sich langsam verändernden Dimensionen (SCD) ist eine fantastische Fähigkeit, die du in deinem Werkzeuggürtel haben solltest, besonders wenn du dein eigenes Datenmodell erstellst.
In diesem Artikel haben wir die Grundlagen von Sternschemata sowie die Definitionen und Grundlagen von SCD behandelt. Wir haben die SCD-Typen 1, 2 und 3 untersucht, um historische Daten zu erhalten und gleichzeitig eine Momentaufnahme des aktuellen Zustands zu erfassen.
Mit Hilfe von Snowflake haben wir jede der oben beschriebenen SCD-Techniken anhand eines Beispiels aus dem Einzelhandel umgesetzt. Danach haben wir einige der eher technischen Herausforderungen beschrieben, die die Umsetzung von SCD mit sich bringen kann, und wie man diese bewältigen kann.
Um deine Kenntnisse in der Datenmodellierung weiter auszubauen, kannst du die Kurse Database Design, Introduction to Data Engineering und Introduction to Data Warehousing bei DataCamp besuchen. Viel Glück und viel Spaß beim Codieren!
Beginne deine Datenreise noch heute!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Zoumana Keita
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
