
Cours
Introduction au data engineering
4 h
127.6K
Il existe plusieurs façons de traiter les dimensions qui changent lentement. Examinons trois des moyens les plus courants.
Avec le DSC de type 1, si un enregistrement d'un tableau de dimensions est modifié, l'enregistrement existant est mis à jour ou écrasé. Dans le cas contraire, le nouvel enregistrement est inséré dans le tableau de dimension. Cela signifie que les tableaux du tableau de dimension reflètent toujours l'état actuel et qu'aucune donnée historique n'est conservée.
Un tableau stockant des informations sur les articles vendus dans une épicerie peut traiter les enregistrements changeants à l'aide d'un SCD de type 1. Si un enregistrement existe déjà dans le tableau pour l'élément souhaité, il sera mis à jour avec les nouvelles informations. Dans le cas contraire, l'enregistrement sera inséré dans le tableau de dimension.
Dans le monde de l'ingénierie des données, cette pratique consistant à mettre à jour des données si elles existent ou à les insérer dans le cas contraire est connue sous le nom de "upserting". Le tableau ci-dessous contient des informations sur les articles vendus dans une épicerie.
|
item_id |
nom |
price |
aisle |
|
93201 |
Chips |
3.99 |
11 |
|
07879 |
Soda |
7.99 |
13 |
Si les chips sont déplacées dans l'allée 6, l'utilisation d'un SCD de type 1 pour saisir ce changement dans le tableau des dimensions produira le résultat ci-dessous :
|
item_id |
nom |
price |
aisle |
|
93201 |
Chips |
3.99 |
6 |
|
07879 |
Soda |
7.99 |
13 |
Le DSC de type 1 garantit qu'il n'y a pas d'enregistrements en double dans le tableau et que les données reflètent la dimension actuelle la plus récente. Ceci est particulièrement utile pour les tableaux de bord en temps réel et la modélisation prédictive, où seul l'état actuel est intéressant.
Toutefois, comme seules les informations les plus récentes sont stockées dans le tableau, les praticiens des données ne sont pas en mesure de comparer l'évolution des dimensions au fil du temps. Par exemple, un analyste de données aurait des difficultés à identifier l'augmentation du chiffre d'affaires des chips après qu'elles ont été déplacées dans l'allée 6 sans d'autres informations.
Le SCD de type 1 facilite l'établissement de rapports et d'analyses sur l'état actuel, mais présente des limites lorsqu'il s'agit d'effectuer des analyses historiques.
Bien qu'il soit utile d'avoir un tableau qui ne reflète que l'état actuel, il est parfois pratique, voire essentiel, de suivre l'évolution historique d'une dimension. Avec le SCD de type 2, les données historiques sont conservées en ajoutant une nouvelle ligne lorsqu'une dimension change et en désignant correctement cette nouvelle ligne comme actuelle tout en désignant l'enregistrement nouvellement historique en conséquence.
C'est facile à dire, mais il n'est pas toujours évident de savoir à quoi cela ressemble dans la pratique. Prenons un exemple.
Nous avons ici un tableau assez similaire à l'exemple que nous avons utilisé lors de l'exploration du DSC de type 1. Toutefois, une colonne supplémentaire a été ajoutée. Le site is_current stocke une valeur booléenne : true si l'enregistrement reflète la valeur la plus récente, false dans le cas contraire.
|
item_id |
nom |
price |
aisle |
is_current |
|
93201 |
Chips |
3.99 |
11 |
Vrai |
|
07879 |
Soda |
7.99 |
13 |
Vrai |
Si les chips sont placées dans l'allée 6, l'utilisation du type 2 du SCD pour documenter ce changement permettrait de créer un tableau qui ressemblerait à celui-ci :
|
item_id |
nom |
price |
aisle |
is_current |
|
93201 |
Chips |
3.99 |
11 |
Faux |
|
07879 |
Soda |
7.99 |
13 |
Vrai |
|
93201 |
Chips |
3.99 |
6 |
Vrai |
Une nouvelle ligne est ajoutée pour refléter le changement d'emplacement des chips, True étant stocké dans la colonne is_current. Pour conserver les données historiques et décrire avec précision l'état actuel, la colonne is_current de l'enregistrement précédent est fixée à False. Avec SCD type 1,
Mais qu'en est-il si vous souhaitez étudier la façon dont les ventes de chips ont réagi à un changement de lieu ? Cela s'avère assez difficile lorsqu'on n'utilise qu'une seule colonne et qu'il existe plusieurs enregistrements historiques pour un même article. Heureusement, il existe un moyen simple de le faire.
Consultez le tableau ci-dessous. Ce tableau de dimensions contient les mêmes informations que précédemment, mais au lieu d'une colonne is_current, il comporte une colonne start_date et une colonne end_date. Ces dates représentent la période pendant laquelle une dimension était la plus récente. Les données de ce tableau étant les plus récentes, le site end_date se situe bien dans le futur.
|
item_id |
nom |
price |
aisle |
start_date |
end_date |
|
93201 |
Chips |
3.99 |
11 |
2023-11-13 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
Si les chips sont déplacées dans l'allée 6 le 4 janvier 2024, le tableau mis à jour se présentera comme suit :
|
item_id |
nom |
price |
aisle |
start_date |
end_date |
|
93201 |
Chips |
3.99 |
6 |
2024-01-04 |
2099-12-31 |
|
07879 |
Soda |
7.99 |
13 |
2023-08-24 |
2099-12-31 |
|
93201 |
Chips |
3.99 |
11 |
2023-11-13 |
2024-01-03 |
Notez que le site end_date pour la première rangée a été mis à jour pour indiquer le dernier jour où des chips étaient disponibles dans l'allée 11. Un nouvel enregistrement est ajouté, les chips étant désormais rangées dans l'allée 6. Les adresses start_date et end_date permettent d'indiquer quand la modification a été effectuée et quel est l'enregistrement le plus récent.
L'utilisation de cette technique pour mettre en œuvre le DSC de type 1 permet non seulement de préserver les données historiques, mais aussi d'obtenir des informations sur le moment où les données ont été modifiées. Cela permet aux analystes et aux scientifiques des données d'explorer les changements opérationnels, d'effectuer des tests A/B et de prendre des décisions éclairées.
Lorsque vous travaillez avec des données qui ne devraient changer qu'une seule fois, ou que seul l'enregistrement historique le plus récent est intéressant, le SCD de type 3 est très utile. Plutôt que de "remonter" une dimension modifiée ou d'enregistrer la modification sous la forme d'une nouvelle ligne, le SCD de type 3 utilise une colonne pour représenter la modification. C'est un peu difficile à expliquer, alors prenons un exemple.
Le tableau ci-dessous contient des informations sur les sports pour les équipes à travers les États-Unis. Ici, le tableau contient deux colonnes pour stocker un nom de stade actuel et un nom de stade historique. Étant donné que chacune de ces équipes utilise le nom original du stade, la colonne previous_stadium_name est remplie par NULLs.
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Faucons de Lafayette |
Football |
Stade Triple X |
NULL |
|
930193 |
Écureuils du Fort Niagara |
Soccer |
Stade Musket |
NULL |
Si les Lafayette Hawks décident d'engager un nouveau sponsor pour une durée de vingt-cinq ans, le tableau actualisé ressemblera à ceci :
|
team_id |
team_name |
sport |
current_stadium_name |
previous_stadium_name |
|
562819 |
Faucons de Lafayette |
Football |
Champ Wabash |
Stade Triple X |
|
930193 |
Écureuils du Fort Niagara |
Soccer |
Stade Musket |
NULL |
Pour tenir compte du nouveau nom du stade, "Triple X Stadium" est déplacé sur le site previous_stadium_name column et "Wabash Field" prend sa place dans la colonne current_stadium_name. Le nouveau contrat de parrainage, d'une durée de vingt-cinq ans, survivra très probablement au modèle en cours de construction, ce qui signifie que le record ne changera probablement plus jamais.
L'utilisation du SCD de type 3 facilite la comparaison des données actuelles avec les données historiques. Il n'y a qu'une seule ligne pour chaque équipe, et les données actuelles et historiques sont placées côte à côte dans deux colonnes différentes. Toutefois, cela signifie qu'un seul enregistrement historique pour un attribut unidimensionnel peut être conservé, ce qui peut être limitatif, en particulier si les données changent plus fréquemment que prévu.
Outre les types 1, 2 et 3, il existe un certain nombre d'autres techniques permettant de mettre en œuvre des dimensions à variation lente. Le type 0 est utilisé lorsque les dimensions ne doivent jamais changer. Le type 4 stocke les données historiques dans un tableau distinct tout en conservant les données les plus récentes dans un tableau de dimensions. Le type 6 est un amalgame des types 1, 2 et 3 et est généralement mis en œuvre en combinant les meilleures caractéristiques de chacune de ces techniques.
Nous avons abordé les principes de base du changement lent de dimensions. Pour mieux comprendre comment mettre en œuvre chacune de ces techniques, prenons un exemple.
Dans cet exemple, nous utiliserons Snowflake pour mettre en œuvre les DSC de type 1, 2 et 3 pour les transactions de détail. Si vous avez besoin d'une remise à niveau sur Snowflake, consultez notre cours Introduction à Snowflake.
Il existe un tableau de faits, nommé sales, et trois tableaux de dimensions, nommés employees, items et discounts. Vous trouverez ci-dessous l'ERD de ce schéma en étoile.
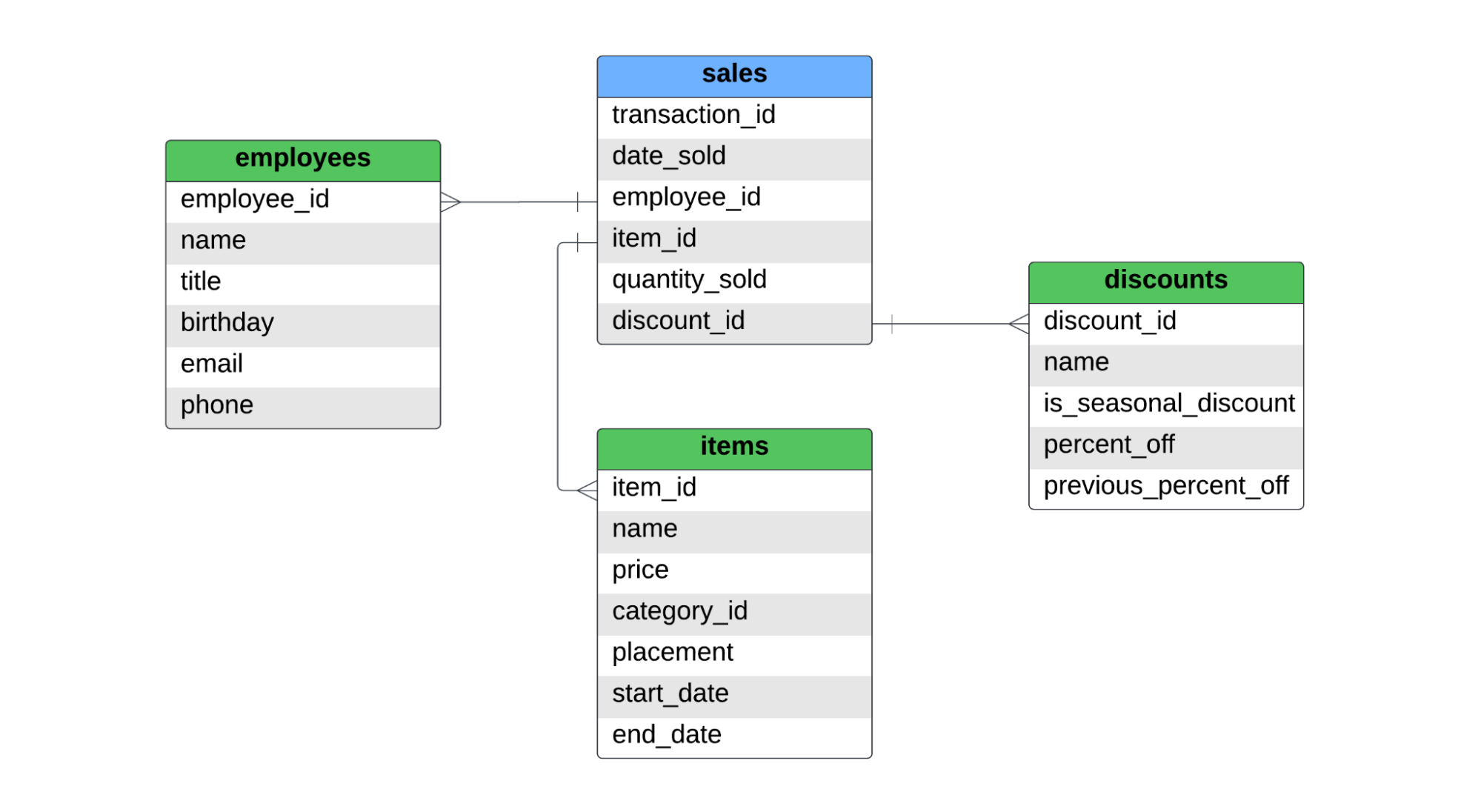
Le tableau sales permet de saisir les ventes au niveau des articles. Si un client a acheté deux tableaux et une paire de jeans, il y aura deux enregistrements dans le tableau des faits, puisque deux articles différents ont été vendus. Pour le SCD de type 1, de type 2 et de type 3, nous couvrirons les points suivants :
Nous ne nous pencherons pas sur la manière dont ces tableaux ont été alimentés à l'origine, mais en règle générale, un pipeline ETL ou ELT en amont de l'entrepôt de données a extrait les données brutes de la source, les a transformées dans le modèle souhaité et les a chargées dans leur destination finale.
Pour vous entraîner à mettre en œuvre le SCD de type 1, nous allons jeter un coup d'œil au tableau employee. Ce tableau contient des informations de base sur un employé, notamment son nom, son titre et ses coordonnées. Il peut contenir des enregistrements tels que ceux présentés ci-dessous.
|
employee_id |
nom |
title |
anniversaire |
|
phone |
|
477379 |
Emily Verplank |
Gestionnaire |
1989-07-28 |
everplank@gmail.com |
928-144-8201 |
|
392005 |
Josh Murray |
Caissier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
En utilisant le type 1 du SCD pour capturer cette dimension à évolution lente, l'enregistrement existant serait remplacé par l'enregistrement le plus récent. Si l'un de ces attributs dimensionnels change, le nouvel enregistrement doit être "inséré" dans le tableau existant. Par exemple, si le numéro de téléphone d'Emily devient 928-652-9704, le nouveau tableau se présentera comme suit :
|
employee_id |
nom |
title |
anniversaire |
|
phone |
|
477379 |
Emily Verplank |
Gestionnaire |
1989-07-28 |
everplank@gmail.com |
928-652-9704 |
|
392005 |
Josh Murray |
Caissier |
2002-12-11 |
jmurray@outlook.com |
717-304-5547 |
Pour ce faire avec Snowflake, nous utiliserons la commande MERGE INTO. MERGE INTO permet à un praticien des données de fournir une clé de correspondance et une condition. Si la clé de correspondance et la condition sont remplies, l'enregistrement peut être mis à jour avec le mot-clé UPDATE. Dans le cas contraire, un enregistrement peut être INSERT'ed, ou l'exécution peut être interrompue.
Avant de commencer à utiliser la commande MERGE INTO, nous allons d'abord créer et ajouter des enregistrements à un tableau nommé stage_employees. Ce tableau contient tous les enregistrements qui ont été mis à jour depuis la dernière actualisation du tableau employees. Nous pouvons le faire à l'aide des déclarations ci-dessous.
CREATE OR REPLACE TABLE stage_employees (
employee_id INT,
name VARCHAR,
title VARCHAR,
birthday DATE,
email VARCHAR,
phone VARCHAR
);
INSERT INTO stage_employees (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
477379,
'Emily Verplank',
'Manager',
'1989-07-28',
'everplank@gmail.com',
'928-652-9704'
);
Nous pouvons maintenant utiliser la fonctionnalité MERGE de Snowflake pour "réinsérer" l'enregistrement existant.
MERGE INTO employees USING stage_employees
ON employees.employee_id = stage_employees.employee_id
WHEN MATCHED THEN UPDATE SET
employees.name = stage_employees.name,
employees.title = stage_employees.title,
employees.email = stage_employees.email,
employees.phone = stage_employees.phone
WHEN NOT MATCHED THEN INSERT (
employee_id,
name,
title,
birthday,
email,
phone
) VALUES (
stage_employees.employee_id,
stage_employees.name,
stage_employees.title,
stage_employees.birthday,
stage_employees.email,
stage_employees.phone
);
Ci-dessus, la clé permettant de fusionner les données entre les tableaux employees et stage_employees était le champ employee_id. Une autre condition n'a pas été définie, ce qui signifie que si les employee_id correspondent, les attributs dimensionnels name, title, email et phone ont été mis à jour avec les valeurs du tableau stage_employees, pour l'ID de l'employé. Si les enregistrements du tableau stage_employees ne correspondent à aucun enregistrement du tableau employees, l'enregistrement est inséré dans le tableau employés.
La mise en œuvre du SCD de type 2 est un peu plus délicate que celle du SCD de type 1. Bien qu'il ne soit pas aussi simple d'écraser un enregistrement existant ou d'en insérer un autre, nous pouvons toujours utiliser la logique MERGE INTO de Snowflake pour résoudre ce problème. Jetez un coup d'œil à la dimension ci-dessous.
|
item_id |
nom |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Chaussettes |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Maillot de sport |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
NULL |
Ce tableau contient des informations sur des articles spécifiques vendus dans un magasin de détail. Les attributs dimensionnels comprennent le nom, le prix et l'emplacement de l'article, ainsi qu'une clé étrangère pour la catégorie à laquelle l'article appartient. Pour mettre en œuvre le SCD de type 2, nous devrons "réinsérer" les données, en utilisant cette fois start_date et end_date pour conserver les données historiques et actuelles.
Supposons qu'au début de la saison de la NFL (National Football League), les maillots de sport soient placés à l'avant du magasin pour une meilleure visibilité lorsqu'un client entre. Le prix de cet article a été réduit en même temps que son nouvel emplacement. Pour illustrer ce comportement opérationnel et conserver les données historiques, l'enregistrement existant est mis à jour avec une date de fin et un nouvel enregistrement est inséré. Consultez-le !
|
item_id |
nom |
price |
category_id |
placement |
start_date |
end_date |
|
667812 |
Chaussettes |
8.99 |
156 |
Aisle 11 |
2023-08-24 |
NULL |
|
747295 |
Maillot de sport |
59.99 |
743 |
Aisle 8 |
2023-02-17 |
2023-11-13 |
|
747295 |
Maillot de sport |
49.99 |
743 |
Affichage de l'entrée |
2023-11-13 |
NULL |
Comme précédemment, nous allons d'abord créer un tableau appelé stage_items. Ce tableau stockera les enregistrements qui seront utilisés pour mettre en œuvre le DSC de type 2 dans la dimension items correspondante, qui prend la forme indiquée ci-dessus. Une fois le tableau stage_items créé, nous allons insérer un enregistrement contenant à la fois le placement et le changement de prix des maillots de sport.
CREATE OR REPLACE TABLE stage_items (
item_id INT,
name VARCHAR,
price FLOAT,
category_id INT,
placement VARCHAR,
start_date DATE,
end_date DATE
);
INSERT INTO stage_items (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
747295,
'Sports Jersey',
49.99,
743,
'Entry Display',
'2023-11-13',
NULL
);
Il est maintenant temps d'utiliser la fonctionnalité MERGE INTO de Snowflake pour mettre en œuvre le DSC de type 2. Cet exemple est un peu plus délicat que le précédent et demande un peu de réflexion. Étant donné qu'un enregistrement ne peut être inséré que si la condition de correspondance n'est PAS remplie, nous devons procéder en deux étapes. Nous allons tout d'abord créer une condition de correspondance à l'aide des trois instructions suivantes :
item_id du tableau items et stage_items doivent correspondre.start_date dans le tableau stage_items doit être supérieure à celle du tableau items.end_date du tableau items doivent être au nombre de NULLSi ces trois conditions sont remplies, l'enregistrement original dans le tableau items doit être mis à jour. Notez que la colonne items.end_date ne sera plus NULL; elle prendra la valeur de start_date dans le tableau stage_items. Il n'y a pas de logique si l'enregistrement n'est pas apparié dans cette première déclaration.
Ensuite, nous utiliserons un appel distinct à MERGE INTO pour insérer le nouvel enregistrement. C'est un peu plus difficile. Pour qu'un nouvel enregistrement soit inséré, la condition de correspondance ne doit pas être remplie.
Dans cet exemple, nous pouvons le faire en vérifiant si les items_id des deux tableaux correspondent et si le end_date du tableau items est NULL. Voyons un peu plus en détail ce qu'il en est.
items_id correspondent et que le items.end_date est NULL, il existe déjà un enregistrement dans le tableau items qui est le plus récent. Cela signifie qu'un nouvel enregistrement ne doit pas être inséré.item_id des deux tableaux, la condition de correspondance n'est pas remplie et une nouvelle ligne est insérée. Il s'agira du premier enregistrement pour ce site item_id dans le tableau items.item_id du tableau stage_items correspond à l'adresse item_id du tableau items et que l'adresse end_date n'est pas NULL, une nouvelle valeur sera insérée. Cela permet de conserver les données historiques et de s'assurer qu'un enregistrement actuel est présent dans le tableau items.Vous trouverez ci-dessous la mise en œuvre, qui utilise deux instructions MERGE INTO pour mettre à jour l'enregistrement existant et insérer les données les plus récentes.
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.start_date < stage_items.start_date
AND items.end_date IS NULL
WHEN MATCHED
THEN UPDATE SET
-- Update the existing record
items.name = stage_items.name,
items.price = stage_items.price,
items.category_id = stage_items.category_id,
items.placement = stage_items.placement,
items.start_date = items.start_date,
items.end_date = stage_items.start_date
;
MERGE INTO items USING stage_items
ON items.item_id = stage_items.item_id
AND items.end_date IS NULL
WHEN NOT MATCHED THEN INSERT (
item_id,
name,
price,
category_id,
placement,
start_date,
end_date
) VALUES (
stage_items.item_id,
stage_items.name,
stage_items.price,
stage_items.category_id,
stage_items.placement,
stage_items.start_date,
NULL
);
Enfin, nous examinerons la mise en œuvre du SCD de type 3 avec une nouvelle dimension. Dans notre exemple, le tableau discounts stocke des informations sur certaines réductions que les clients peuvent utiliser lors de leur passage en caisse. Le tableau comprend l'identifiant de la réduction, ainsi que le nom, le pourcentage de réduction et la classification en tant que réduction saisonnière. Voici un exemple de deux enregistrements susceptibles d'être présents dans le tableau discounts.
|
discount_id |
nom |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Membre récompensé |
Faux |
10 |
NULL |
|
467782 |
Remise aux employés |
Faux |
50 |
NULL |
Étant donné que le détaillant ne s'attend pas à ce que les remises changent souvent, cette dimension est un excellent candidat pour la mise en œuvre d'une approche de type 3 afin de prendre en compte les dimensions qui changent lentement. Si le pourcentage de réduction offert par la remise change, le pourcentage de réduction précédent sera déplacé dans la colonne previous_percent_off , tandis que la nouvelle valeur prendra sa place dans la colonne percent_off.
Cela permet de conserver les données historiques tout en affichant la valeur la plus récente dans la colonne percent_off.
|
discount_id |
nom |
is_seasonal |
percent_off |
previous_percent_off |
|
994863 |
Membre récompensé |
Faux |
10 |
NULL |
|
467782 |
Remise aux employés |
Faux |
35 |
50 |
Pour mettre cela en œuvre avec Snowflake, nous allons créer un tableau stage_discounts et y insérer un seul enregistrement. Cet enregistrement comprendra le nouveau site percent_off.
CREATE TABLE stage_discounts (
discount_id INTEGER,
name VARCHAR,
is_seasonal BOOLEAN,
percent_off INTEGER
);
INSERT INTO stage_discounts (
discount_id,
name,
is_seasonal,
percent_off
) VALUES (
467782,
'Rewards Member',
FALSE,
35
);
Là encore, nous utiliserons MERGE INTO pour mettre en œuvre le SCD de type 3. La condition de correspondance est simple : si les valeurs de discount_id dans les tableaux discounts et stage_discounts correspondent et que les valeurs de percent_off diffèrent, l'enregistrement existant dans le tableau discounts sera mis à jour. La valeur existante percent_off sera déplacée dans le champ previous_percent_off, et si les discount_id des deux tableaux ne correspondent pas, un nouvel enregistrement sera inséré avec la valeur NULL. Notez que ces enregistrements ne sont pas limités dans le temps et qu'une seule valeur historique peut être conservée pour percent_off.
MERGE INTO discounts USING stage_discounts
ON discounts.discount_id = stage_discounts.discount_id
WHEN MATCHED
AND discounts.percent_off <> stage_discounts.percent_off
THEN UPDATE SET
discounts.previous_percent_off = discounts.percent_off,
discounts.percent_off = stage_discounts.percent_off
WHEN NOT MATCHED
THEN INSERT (
discount_id,
name,
is_seasonal,
percent_off,
previous_percent_off
) VALUES (
stage_discounts.discount_id,
stage_discounts.name,
stage_discounts.is_seasonal,
stage_discounts.percent_off,
NULL
);
Rappelez-vous que le DSC de type 3 est mieux mis en œuvre avec des données qui changent rarement, et que seule l'entrée historique la plus récente doit être conservée. Si de multiples changements de dimension sont prévus, il est probablement préférable d'utiliser le DSC de type 2.
Lorsque vous mettez en œuvre une technique permettant de modifier lentement les dimensions, il est important de garder à l'esprit la possibilité de duplication des données. Il y a deux types de doublons à surveiller : les doublons intra-lots et les doublons inter-lots. Voyons cela en détail.
Les doublons intra-lots sont des doublons qui existent entre différents lots de données. S'il existe un tableau de dimensions existant et que deux fichiers destinés à mettre à jour ce tableau peuvent contenir des enregistrements en double.
Pour ce faire, il est important d'ajouter des contraintes à votre logique d'insertion et/ou de chargement de données dans un tableau de dimension. Dans nos exemples ci-dessus, nous avons ajouté de la logique tout au long du processus pour nous assurer qu'il n'y avait pas de doublons. Il s'agit notamment de
employee_id n'existe pas.percent_off sont différentes dans le tableau des articles et de stage_items.Les doublons inter-lots sont des doublons qui se produisent dans le même lot de données. Par exemple, si un fichier contient deux entrées pour mettre à jour un seul enregistrement dans un tableau de dimensions, des précautions doivent être prises. Comme pour les doublons intra-lots, il est important d'ajouter des contraintes à la logique utilisée pour mettre en œuvre les DSC de type 1, 2 ou 3.
S'il y a des enregistrements contradictoires dans le même fichier, ces enregistrements devront être différenciés d'une manière ou d'une autre. Il peut s'agir de métadonnées sur l'enregistrement ou d'un horodatage fourni par la source. Quelle que soit la façon dont vous choisissez de traiter ces doublons, il est important de documenter vos hypothèses et de les revoir avec votre équipe afin de vous assurer que les dimensions qui en résultent reflètent correctement les valeurs opérationnelles.
Il arrive que des données soient modifiées alors qu'elles ne devraient pas l'être. Avec les trois techniques SCD que nous avons examinées jusqu'à présent, cela peut entraîner l'écrasement de données, l'ajout d'une nouvelle ligne ou l'ajout de données dans une nouvelle colonne.
Nous avons vu comment éviter que des données en double ne se retrouvent dans les tableaux de dimension. Outre les données dupliquées, les spécialistes des données qui mettent en œuvre des techniques pour gérer les dimensions à évolution lente devront faire attention aux éléments suivants :
Bien que tous les cas susmentionnés ne puissent pas être détectés directement dans le code utilisé pour gérer les tableaux de dimensions, le fait de disposer de règles et de processus de qualité des données solides pour contrôler les dimensions peut contribuer à garantir l'intégrité des données.
Dans l'exemple du commerce de détail ci-dessus, les ensembles de données avec lesquels nous avons travaillé ne comportaient que quelques lignes de données. Dans un environnement de production, ces tableaux de dimensions peuvent contenir des centaines, voire des milliers d'enregistrements. Cette situation est assez fréquente lors de la mise en œuvre du SCD de type 2, en particulier si les dimensions changent fréquemment.
Au fur et à mesure que le nombre de tableaux augmente, il est important pour un spécialiste des données de garder la performance au premier plan de ses plans de conception et de mise en œuvre. Voici quelques façons d'optimiser la mise en œuvre du DSC pour les grands ensembles de données à l'aide de Snowflake :
MERGE.UPDATE et INSERT, le cas échéant, plutôt que les déclarations MERGESi un ensemble de données dimensionnelles devient si important que les performances du système sont compromises, il peut être nécessaire de décider d'un compromis entre la précision historique et les performances du système. Comme indiqué plus haut, c'est généralement le cas lors de la mise en œuvre du DSC de type 2.
Si les enregistrements changent souvent, le nombre de tableaux peut rapidement grimper en flèche. Lorsque c'est le cas, il n'est peut-être plus prudent d'utiliser le SCD de type 2 pour gérer les données dimensionnelles.
Le passage à un SCD de type 1 ou de type 3 peut offrir des fonctionnalités similaires, avec des gains significatifs en termes de performances du système. La contrepartie est une représentation incomplète des données historiques. Travaillez avec votre équipe pour évaluer ce compromis avant de changer d'approche pour mettre en œuvre le SCD.
Il est assez facile d'exécuter une requête unique pour mettre en œuvre la DSC pour un tableau de dimensions. Cependant, l'exécution programmatique de ce processus pour maintenir cette dimension dans un environnement de production nécessite un peu de réflexion. Des outils tels qu'Apache Airflow sont parfaits pour orchestrer ces processus et fournissent une couche de surveillance et d'alerte pour garantir des performances nominales. En paramétrant la logique utilisée pour mettre à jour les tableaux de dimensions, Airflow peut être utilisé pour lancer des processus dans votre plateforme de données pour une période programmée, se substituant ainsi aux efforts manuels d'un praticien des données
Outre Airflow, des outils tels que Mage, Prefect ou Dagster peuvent être utilisés pour orchestrer la mise en œuvre de dimensions à évolution lente. Si de tels outils ne sont pas facilement disponibles, des outils d'orchestration maison peuvent également faire l'affaire.
La maîtrise des dimensions à changement lent (SCD) est une compétence fantastique à avoir dans sa ceinture d'outils, en particulier lors de la création de son propre modèle de données.
Dans cet article, nous avons abordé les bases des schémas en étoile, ainsi que les définitions et les bases du SCD. Nous avons étudié les types de DSC 1, 2 et 3 pour conserver les données historiques tout en capturant un instantané de l'état actuel.
Avec l'aide de Snowflake, nous avons mis en œuvre chacune des techniques de DSC définies ci-dessus à l'aide d'un exemple de commerce de détail. Ensuite, nous avons décrit certains des défis plus techniques que la mise en œuvre du DSC peut entraîner, ainsi que la manière de les relever.
Pour continuer à développer vos compétences en modélisation de données, suivez les cours Conception de base de données, Introduction à l'ingénierie de données et Introduction à l'entreposage de données disponibles via DataCamp. Bonne chance et bon codage !
Commencez votre voyage de données dès aujourd'hui !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Zoumana Keita
15 min
Tutoriel
Samuel Shaibu
Tutoriel

