
Curso
Ingesta de datos eficiente con pandas
4 h
62.7K
El marco de Airflow, así como su arquitectura, tienen varias características clave que lo hacen único. En primer lugar, profundicemos un poco más en las características más importantes del marco de Airflow.
La unidad más simple del marco Airflow son las tareas. Las tareas pueden considerarse operaciones o, para la mayoría de los equipos de datos, operaciones en una canalización de datos.
Un flujo de trabajo ETL tradicional tiene tres tareas: extraer, transformar y cargar datos. Las dependencias definen las relaciones entre las tareas. Volviendo a nuestro ejemplo de ETL, la tarea "cargar" depende de la tarea "transformar", que, a su vez, depende de la tarea "extraer". La combinación de tareas y dependencias crea DAGs, o grafos acíclicos dirigidos. Los DAG representan canalizaciones de datos en Airflow, y son un poco enrevesados de definir. En su lugar, veamos un diagrama de una canalización ETL básica:
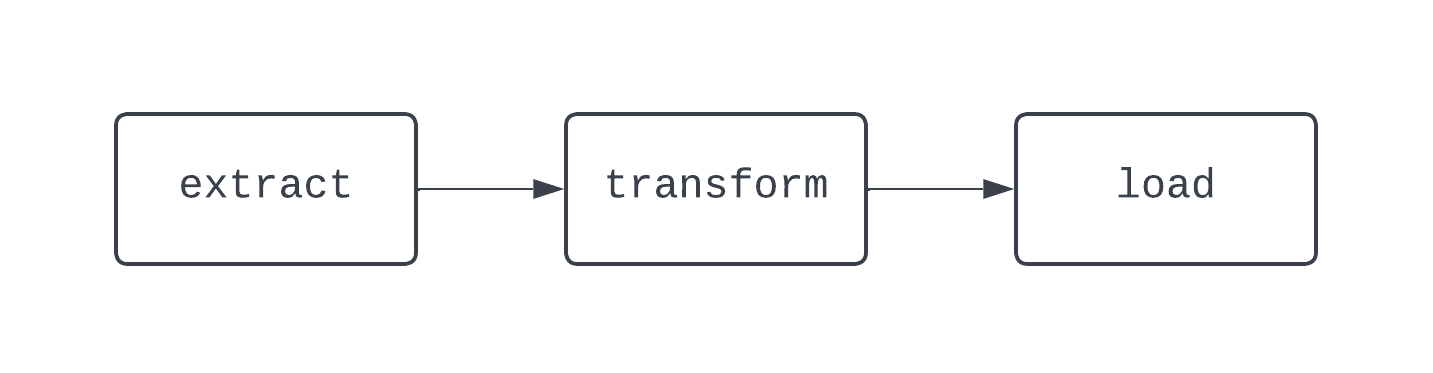
El DAG anterior tiene tres tareas, con dos dependencias. Se considera un DAG porque no hay bucles (o ciclos) entre tareas. Aquí, las flechas muestran la naturaleza dirigida del proceso; primero se ejecuta la tarea extract, seguida de las tareas transform y load. Con los DAG, es fácil ver un comienzo y un final distintos en el proceso, aunque la lógica sea compleja, como el DAG que se muestra a continuación:
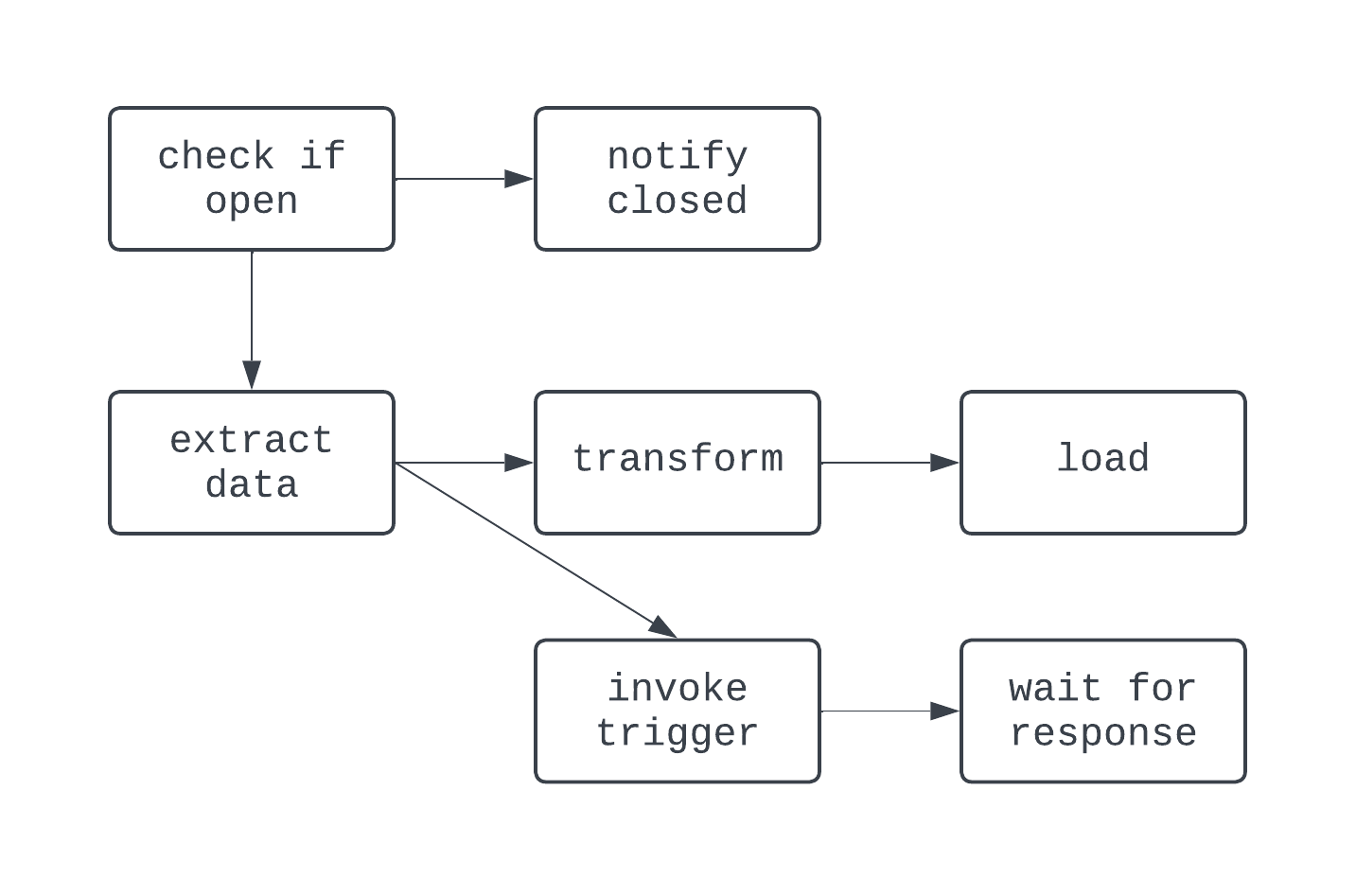
En este DAG, la lógica es un poco más loca. Hay bifurcaciones basadas en una condición, y algunas tareas se ejecutan en paralelo. Sin embargo, el grafo es dirigido, y no hay dependencias cíclicas entre tareas. Veamos ahora un proceso que no es un DAG:
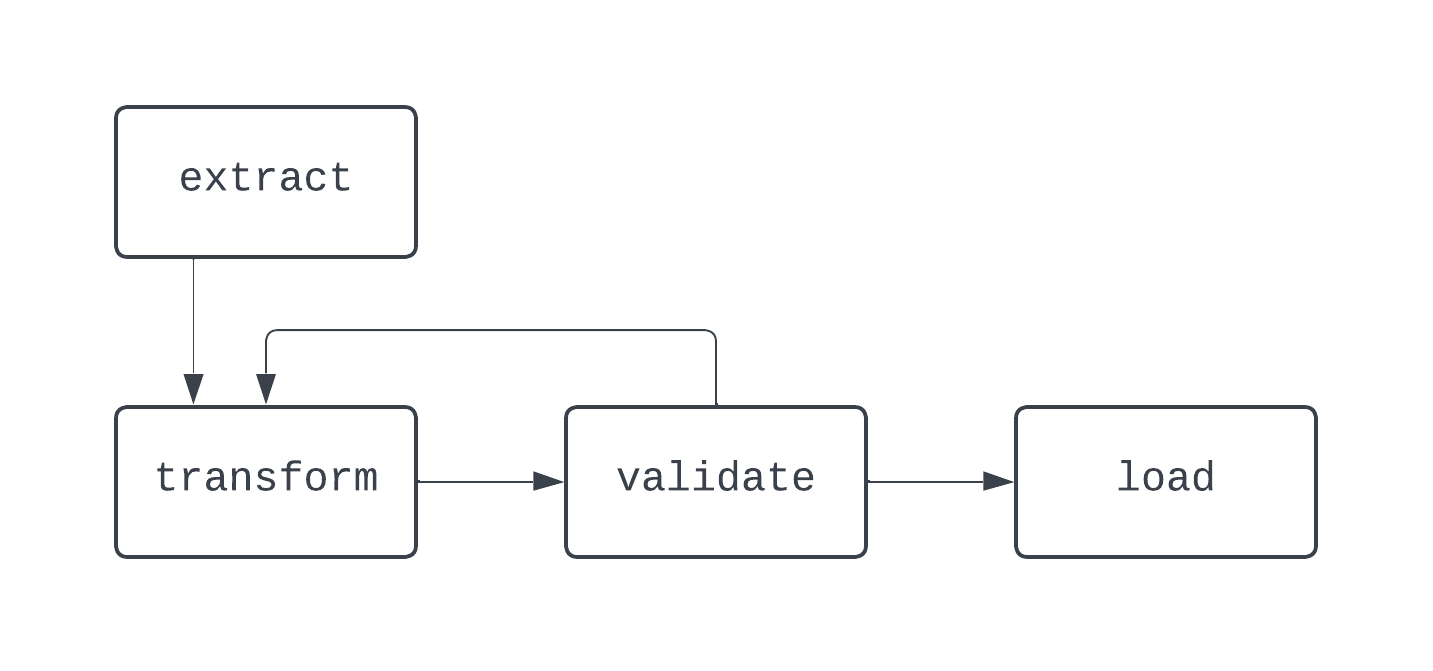
En este diagrama, hay un bucle distinto entre las tareas transform y validate. En algunos casos, este DAG puede funcionar eternamente, si no hay forma de salir de este bucle.
Cuando construyas canalizaciones de datos, incluso fuera de Airflow, es una buena práctica no crear flujos de trabajo que no puedan representarse como DAGs, ya que puedes perder características clave, como el determinismo o la idempotencia.
Para programar DAGs, ejecutar tareas y proporcionar visibilidad de los detalles de ejecución de la canalización de datos, Airflow aprovecha una arquitectura basada en Python formada por los componentes que se indican a continuación:
Tanto si se ejecuta Airflow localmente como en un entorno de producción, cada uno de estos componentes debe estar en funcionamiento para que Airflow funcione correctamente.
El programador es responsable de (probablemente lo hayas adivinado) programar los DAG. Para programar un DAG, hay que proporcionar una fecha de inicio y un intervalo de programación para el DAG cuando se escribe el DAG como código Python.
Una vez programado un DAG, las tareas dentro de esos DAGs necesitan ejecutarse, que es donde entra en juego el ejecutor. El ejecutor no ejecuta la lógica dentro de cada tarea; sólo asigna la tarea para que la ejecuten los recursos que estén configurados para ello. La base de metadatos almacena información sobre las ejecuciones del DAG, como si el DAG y sus tareas asociadas se ejecutaron con éxito o no.
La base de metadatos también almacena información como variables definidas por el usuario y conexiones, que ayudan a la hora de construir canalizaciones de datos de nivel de producción. Por último, el servidor web proporciona la interfaz de usuario con Airflow.
Esta interfaz de usuario, o UI, proporciona a los equipos de datos una herramienta central para gestionar la ejecución de sus pipelines. En la interfaz de usuario de Airflow, los equipos de datos pueden ver el estado de sus DAG, volver a ejecutarlos manualmente, almacenar variables y conexiones, y mucho más. La interfaz de usuario de Airflow proporciona una visibilidad centralizada de los procesos de ingestión y entrega de datos, lo que ayuda a mantener a los equipos de datos informados y al tanto del rendimiento de su canalización de datos.
Hay varias formas de instalar Apache Airflow. Cubriremos dos de los más comunes.
pipRequisitos previos:
python3 instaladoPara instalar Airflow con pip, la forma de paquetes de Python, puedes ejecutar el siguiente comando:
pip install apache-airflowUna vez que el paquete haya terminado de instalarse, tendrás que crear todos los componentes de un proyecto Airflow, como establecer tu directorio de inicio Airflow, crear un archivo airflow.cfg, poner en marcha la base de datos de metadatos y mucho más. Esto puede suponer mucho trabajo y requerir bastante experiencia previa con Airflow. Por suerte, hay una forma mucho más fácil con la CLI de Astro.
Requisitos previos:
python3 instaladoAstronomer, proveedor de Airflow gestionado, proporciona una serie de herramientas gratuitas para facilitar el trabajo con Airflow. Una de estas herramientas es el Astro CLI.
La CLI de Astro facilita la creación y gestión de todo lo que necesitas para hacer funcionar Airflow. Para empezar, primero tendrás que instalar el CL. Para hacerlo en tu máquina, consulta este enlace a la documentación de Astronomer, y sigue los pasos correspondientes a tu sistema operativo.
Una vez instalada la CLI de Astro, configurar todo un proyecto Airflow sólo requiere un comando:
astro dev initEsto configurará todos los recursos necesarios para un proyecto Airflow en tu directorio de trabajo actual. Tu directorio de trabajo actual tendrá entonces este aspecto:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Una vez creado el proyecto, para iniciarlo, ejecuta astro dev start. Al cabo de aproximadamente un minuto, podrás abrir la interfaz de usuario de Airflow en tu navegador, en la dirección https://localhost:8080/. Ahora, ¡ya estás listo para escribir tu primer DAG!
Hemos cubierto los aspectos básicos y las características más avanzadas del marco y la arquitectura de Airflow. Ahora que Airflow está instalado, estás listo para escribir tu primer DAG. En primer lugar, crea un archivo llamado sample_dag.py en el directorio dags/ del proyecto Airflow que acabas de crear. Con tu editor de texto o IDE favorito, abre el archivo sample_dag.py. En primer lugar, vamos a instanciar el DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Arriba, utilizamos la función DAG del módulo airflow para definir un DAG junto con el gestor de contextos with.
Se proporciona un start_date, un intervalo schedule y un valor para catchup. Este DAG se ejecutará cada día a las 9:00 AM UTC. Como catchup está configurado como Verdadero, este DAG se ejecutará cada día entre el día en que se active por primera vez y el 1 de enero de 2024, y max_active_runs=1 garantiza que sólo pueda ejecutarse un DAG a la vez.
Ahora, ¡añadamos algunas tareas! En primer lugar, crearemos una tarea para simular la extracción de datos de una API. Consulta el código a continuación:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
A continuación, querremos crear una tarea para transformar los datos devueltos por la tarea extract_data. Esto se puede hacer con el siguiente código. Aquí, estamos utilizando una función de Airflow llamada XComs para recuperar datos de la tarea anterior.
Puesto que render_templat_as_native_obj se establece en True, estos valores se comparten como objetos Python en lugar de cadenas. A continuación, los datos brutos de la tarea extract_data se pasan a transform_data_callable como argumento de palabra clave. A continuación, estos datos se transforman y se devuelven, donde serán utilizados por la tarea load_data de forma similar.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Por último, se establecen dependencias entre las tareas. Aquí el código establece dependencias entre las tareas extract_data, transform_data, y load_data para crear un ETL DAG básico.
...
extract_data >> transform_data >> load_data
El producto final tendrá este aspecto
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Una vez que hayas definido tu pipeline como código Python, puedes utilizar la interfaz de usuario de Airflow para activar tu DAG. Haz clic en el DAG weather_etl y activa el interruptor de la parte superior izquierda. Observa cómo se completan con éxito tus tareas y la ejecución del DAG.
Enhorabuena, ¡has escrito y puesto en marcha tu primer Airflow DAG!
Además de utilizar los operadores tradicionales, Airflow ha introducido la API TaskFlow, que facilita la definición de DAGs y tareas mediante decoradores y código Python nativo.
En lugar de utilizar explícitamente XComs para compartir datos entre tareas, la API TaskFlow abstrae esta lógica y utiliza XComs entre bastidores. El código siguiente muestra exactamente la misma lógica y funcionalidad que el anterior, esta vez implementada con la API TaskFlow, que es más intuitiva para los analistas y científicos de datos acostumbrados a construir lógica ETL basada en scripts.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Construir DAGs de flujo de aire puede ser complicado. Hay algunas buenas prácticas que debes tener en cuenta cuando construyas canalizaciones de datos y flujos de trabajo, no sólo con Airflow, sino con otras herramientas.
Con las tareas, Airflow ayuda a que la modularidad sea más fácil de visualizar. No intentes hacer demasiado en una sola tarea. Aunque se puede construir todo un canal ETL en una sola tarea, esto dificultaría la resolución de problemas. También dificultaría la visualización del rendimiento de un DAG.
Al crear una tarea, es importante asegurarse de que sólo hará una cosa, como las funciones en Python.
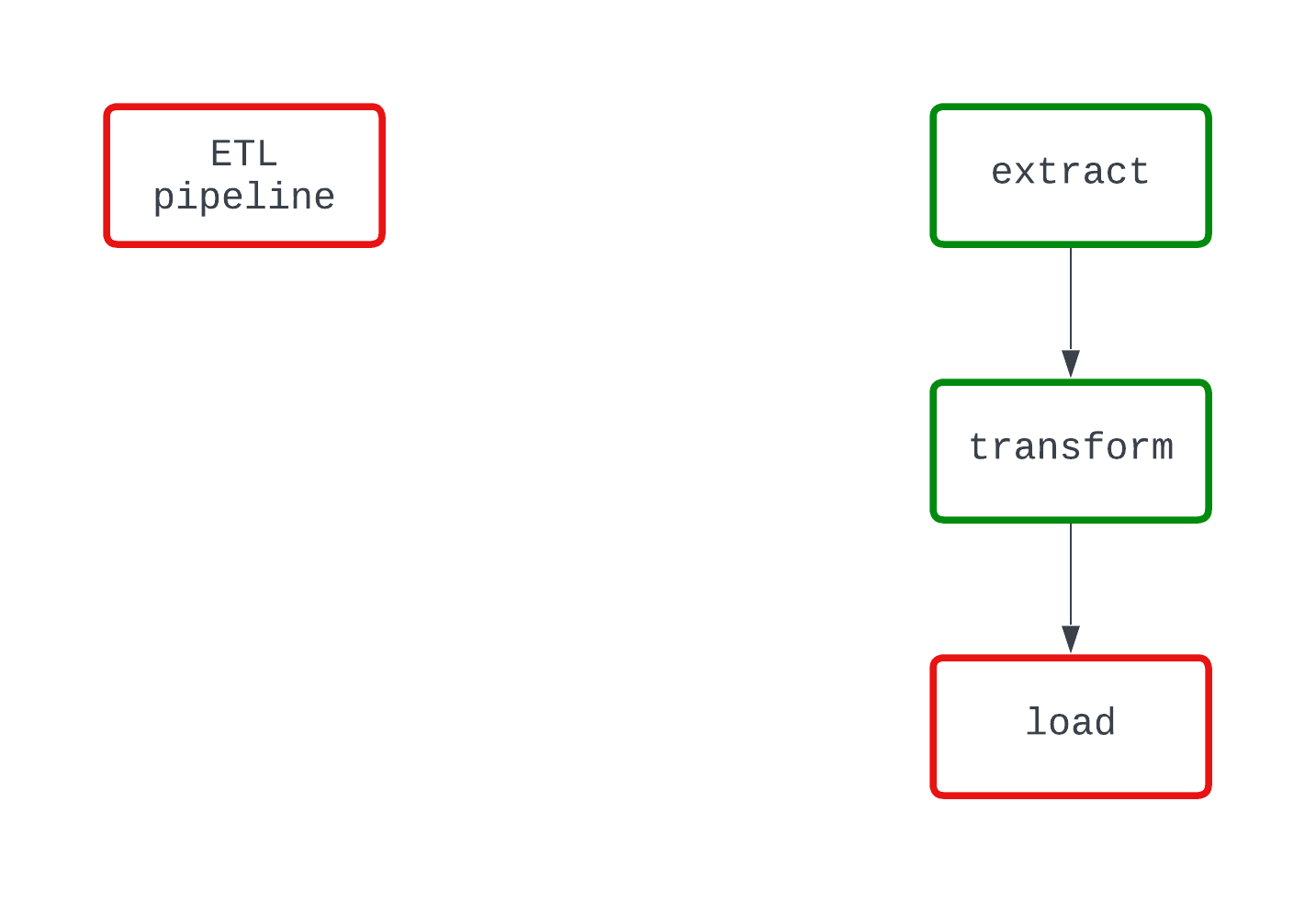
Mira el siguiente ejemplo. Ambos DAG hacen lo mismo y fallan en el mismo punto del código. Sin embargo, en el DAG de la izquierda, está claro que la lógica load es la causante del fallo, mientras que esto no queda del todo claro en el DAG de la derecha.
Un proceso determinista es aquel que produce el mismo resultado, dada la misma entrada. Cuando un DAG se ejecuta durante un intervalo determinado, debe generar siempre los mismos resultados. Aunque es una característica más compleja de los conductos de datos, el determinismo es importante para garantizar resultados coherentes.
Con Airflow, aprovecha Jinja-templating para pasar campos templados a los operadores Airflow en lugar de utilizar la función datetime.now() para crear datos temporales.
¿Qué ocurre si ejecutas un DAG para el mismo intervalo dos veces? ¿Qué tal 10 veces? ¿Terminarás con datos duplicados en tu medio de almacenamiento de destino? La idempotencia garantiza que, aunque una canalización de datos se ejecute varias veces, sea como si sólo se hubiera ejecutado una vez.
Para que los conductos de datos sean deterministas, piensa en incorporar la siguiente lógica a tus DAG:
INSERTing, que puede provocar duplicados.Airflow no está pensado para procesar grandes cantidades de datos. Si quieres ejecutar transformaciones en más de un par de gigabytes de datos, Airflow sigue siendo la herramienta adecuada para el trabajo; sin embargo, Airflow debería invocar otra herramienta, como dbt o Databricks, para ejecutar la transformación.
Normalmente, las tareas se ejecutan localmente en tu máquina o con nodos trabajadores en producción. De cualquier forma, sólo unos pocos gigabytes de memoria estarán disponibles para cualquier trabajo computacional que se necesite.
Céntrate en el uso de Airflow para transformaciones de datos muy ligeras y como herramienta de orquestación cuando manipules datos más grandes.
Gracias a la capacidad de Airflow para definir canalizaciones de datos como código y a su amplia variedad de conectores y operadores, empresas de todo el mundo confían en Airflow para potenciar sus plataformas de datos.
En la industria, un equipo de datos puede trabajar con una amplia variedad de herramientas, desde sitios SFTP a sistemas de almacenamiento de archivos en la nube, pasando por un lago de datos. Para construir una plataforma de datos, es primordial que estos sistemas dispares estén integrados.
Con una vibrante comunidad de código abierto, hay miles de conectores preconstruidos para ayudarte a integrar tus herramientas de datos. ¿Quieres soltar un archivo de S3 en Snowflake? Por suerte para ti, S3ToSnowflakeOperator te lo pone fácil. ¿Qué te parecen las comprobaciones de la calidad de los datos con Grandes Expectativas? Eso también se ha construido ya.
Si no encuentras la herramienta prefabricada adecuada para el trabajo, no pasa nada. Airflow es extensible, lo que te facilita la creación de tus propias herramientas personalizadas para satisfacer tus necesidades.
Al ejecutar Airflow en producción, también deberás pensar en las herramientas que utilizas para gestionar la infraestructura. Hay varias formas de hacerlo, con ofertas premium como Astronomer, opciones nativas de la nube como MWAA, o incluso una solución propia.
Normalmente, esto implica un compromiso entre el coste y la gestión de la infraestructura; las soluciones más caras pueden significar menos que gestionar, mientras que ejecutar todo en una única instancia EC2 puede ser barato pero difícil de mantener.
Apache Airflow es una herramienta líder en el sector para ejecutar canalizaciones de datos en producción. Al proporcionar funciones como la programación, la extensibilidad y la capacidad de observación, al tiempo que permite a los analistas de datos, científicos e ingenieros definir canalizaciones de datos como código, Airflow ayuda a los profesionales de los datos a centrarse en lograr un impacto empresarial.
Es fácil empezar a trabajar con Airflow, especialmente con la CLI Astro, y los operadores tradicionales y la API TaskFlow facilitan la escritura de tus primeros DAG. Cuando construyas canalizaciones de datos con Airflow, asegúrate de mantener la modularidad, el determinismo y la idempotencia al frente de tus decisiones de diseño; estas prácticas recomendadas te ayudarán a evitar dolores de cabeza en el futuro, especialmente cuando tus DAGs encuentren un error.
Con Airflow, hay mucho que aprender. Para tu próximo proyecto de análisis o ciencia de datos, prueba Airflow. Experimenta con operadores preconstruidos, o construye los tuyos propios. Prueba a compartir datos entre tareas con los operadores tradicionales y la API TaskFlow. No tengas miedo de superar los límites. Si estás listo para empezar, échale un vistazo al curso Introducción a Airflow en Python de DataCamp, que cubre los aspectos básicos de Airflow y explora cómo implementar canalizaciones complejas de ingeniería de datos en producción.
También puedes empezar nuestro curso Introducción a las canalizaciones de datos, que te ayudará a perfeccionar las habilidades para construir canalizaciones de datos eficaces, eficaces y fiables. Por último, puedes consultar nuestra comparativa de Airflow vs Prefect para ver cuál es la mejor herramienta para ti.
Si quieres más, consulta algunos de los recursos que se indican a continuación. Mucha suerte y ¡feliz codificación!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Comienza hoy mismo tu viaje por los Data Pipelines
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
Tim Lu
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
Tutorial
Kurtis Pykes
