
programa
Fundamentos de SQL
26 h
En las bases de datos relacionales, la clave principal desempeña un papel crucial para garantizar la unicidad y la integridad de los datos dentro de una tabla. Una clave principal es una restricción que identifica de forma única cada registro de una tabla, actuando como elemento fundamental para la indexación, la aplicación de la integridad de la entidad y el establecimiento de relaciones entre tablas.
En este tutorial, te guiaré a través de una exploración en profundidad de las claves primarias SQL, cubriendo los principios básicos, los métodos de implementación y las técnicas de optimización. También abordaré algunos errores comunes y mejores prácticas, así como situaciones reales. Si aún estás aprendiendo SQL, te recomiendo que consultes nuestra completa hoja de ruta de SQL y realices nuestro programa de habilidades Fundamentos de SQL.
Una clave principal SQL es una columna o un conjunto de columnas que identifican de forma única cada fila de una tabla. Esto significa que no puede haber dos filas con el mismo valor de clave principal. Una tabla solo puede tener una clave principal, que puede estar formada por una o varias columnas.
Las claves primarias son fundamentales para garantizar la integridad de los datos y permitir consultas eficientes. Veamos algunos aspectos fundamentales.
Las claves primarias son esenciales para la normalización de bases de datos y la integridad relacional.
Cuando se define una clave principal, la base de datos crea automáticamente un índice único para aplicar la restricción. Este índice acelera el rendimiento de las consultas, especialmente en operaciones de búsqueda.
A través de este sistema de índices, las claves primarias ayudan al motor de la base de datos a optimizar el plan de ejecución. Esto hará que tus consultas se ejecuten más rápido.
Las claves primarias pueden ser de varios tipos de datos. Aquí hay algunos tipos que se utilizan:
INTEGER o SERIAL: Eficaz y más utilizado.BIGINT: Útil para tablas que se espera que almacenen miles de millones de filas.UUID: Ideal para sistemas distribuidos y para evitar la previsibilidad secuencial.CHAR/VARCHAR: Úsese con precaución, normalmente en tonalidades naturales cuando sea necesario.Las claves primarias se pueden clasificar en varios tipos según su estructura y origen. Algunos ejemplos son:
SERIAL, BIGSERIAL o UUID. El uso de estas claves ofrece estabilidad, privacidad y un mantenimiento más sencillo.Comparándolos en función de sus características, podemos revelar sus diferencias en la siguiente tabla resumen:
|
Característica |
Clave natural |
Clave sustituta |
|
Significado comercial |
Sí |
No |
|
Estabilidad |
A menudo inestable |
Muy estable |
|
Rendimiento |
Puede requerir campos grandes. |
Generalmente compacto |
|
Preocupaciones sobre la privacidad |
Más alto |
Más bajo |
Una clave principal compuesta es una forma habitual de generar una clave única en las tablas. La clave se deriva normalmente de los datos que se encuentran en dos o más columnas.
Estas claves son comunes en tablas de unión o asociativas, donde la relación en sí misma requiere unicidad.
course_enrollments podría utilizar una clave compuesta de student_id y course_id.Consideraciones:
Además de la clave principal, hay otras claves que se pueden utilizar, como por ejemplo:
Si estás decidiendo qué campo de datos utilizar como clave principal, puedes tener en cuenta los siguientes factores:
A continuación, veamos cómo se pueden declarar y gestionar las claves primarias en PostgreSQL utilizando comandos SQL.
Recorreremos varios escenarios, incluyendo la creación de tablas, la modificación de tablas existentes y la gestión del comportamiento de las restricciones.
En la fase de creación de la tabla, debes crear campos que sea probable que se encuentren. En este caso, generaremos un ID de empleado que consta de números enteros únicos.
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY, -- Automatically generates unique integers
name TEXT NOT NULL, -- Basic text field, required
email TEXT UNIQUE -- Unique constraint to prevent duplicate emails
);Más información sobre los comandos SQL en nuestra hoja de referencia rápida sobre conceptos básicos de SQL.

Este ejemplo muestra cómo definir una clave principal en línea utilizando el pseudotipo SERIAL. PostgreSQL trata SERIAL como una columna entera con autoincremento, ideal para claves sustitutivas. A la columna de correo electrónico también se le asigna una restricción UNIQUE, lo que le permite servir como clave alternativa.
Ahora, establezcamos el campo « employee_id » como clave principal.
ALTER TABLE employees ADD PRIMARY KEY (employee_id);Este comando se utiliza cuando ya se ha creado una tabla sin una clave principal y deseas añadir una posteriormente. Asegúrate de que la columna a la que estás añadiendo la clave principal no contiene valores NULL ni duplicados, ya que, de lo contrario, el comando fallará.
Ahora que ya has establecido la clave principal, también puedes eliminar la restricción de clave principal.
ALTER TABLE employees DROP CONSTRAINT employees_pkey;Utiliza esta instrucción para eliminar una restricción de clave principal existente. El nombre de la restricción En PostgreSQL, el nombre predeterminado de la restricción para las claves primarias es Obtén más información sobre PostgreSQL en nuestra hoja de referencia. No se permiten valores NULL en columnas de clave primaria. Los valores duplicados también provocarán errores de violación de restricciones. Algunas estrategias para gestionar esto incluyen: Los tipos de PostgreSQL « Además, los UUID proporcionan identificadores globales seguros. Su naturaleza no secuencial e impredecible también mejora la seguridad, especialmente en la prevención de ataques de enumeración. A continuación se muestra una implementación de cómo se puede crear un UUID y utilizarlo como clave principal. Las claves primarias son esenciales para garantizar la coherencia entre las tablas relacionales y mejorar el rendimiento. La integridad de las entidades se garantiza mediante claves primarias, que no admiten valores NULL ni duplicados. Contar con un identificador único ayuda a evitar anomalías en los datos durante las operaciones de inserción/actualización. Las claves externas deben coincidir con los valores de clave primaria existentes en la tabla a la que se hace referencia. La integridad referencial garantiza que todas las referencias entre tablas sigan siendo válidas y evita los «registros huérfanos», en los que los registros hacen referencia a datos inexistentes. Las acciones en cascada mantienen la coherencia cuando cambian las claves primarias a las que se hace referencia. Esto puede incluir funciones en cascada comunes como: Los índices únicos en las claves primarias aceleran las consultas Si tus consultas son lentas y sospechas que se debe a una indexación incorrecta, utiliza Un buen diseño de claves favorece el mantenimiento, el rendimiento y la escalabilidad. Veamos algunas prácticas recomendadas y errores comunes. Las correcciones incluyen: Al crear una solución de base de datos escalable, intenta utilizar claves sustitutivas para mantener la uniformidad en conjuntos de datos de gran tamaño. Evita las claves compuestas en sistemas distribuidos a menos que sea necesario. También es imprescindible supervisar periódicamente el tamaño de tus tablas/índices. El manejo de claves primarias en sistemas complejos, como bases de datos distribuidas o sistemas heredados, requiere estrategias avanzadas. Las bases de datos distribuidas son más complicadas. Deberás asegurarte de que la generación de claves no presente conflictos entre los nodos. Para ello, puedes probar a utilizar UUID y servicios de gestión de claves centralizados. Consideraciones sobre la partición: Cuando realices una migración del sistema desde una base de datos heredada, identifica primero los identificadores únicos existentes. A continuación, introduce gradualmente claves sustitutivas junto con las claves naturales. Adopta un enfoque prudente y prueba la compatibilidad con doble clave antes de realizar la transición completa. Proceso de migración: Antes de crear tablas e insertar datos, necesitas un entorno PostgreSQL operativo. Esta sección comienza con una breve guía para configurar PostgreSQL, seguida de instrucciones para definir y utilizar un conjunto de datos de ejemplo para practicar los conceptos básicos de las claves primarias. Si aún no has instalado PostgreSQL, sigue estos pasos para empezar: CREAR BASE DE DATOS pk_tutorial; Una vez que tu entorno esté listo, puedes continuar con el resto de la configuración del conjunto de datos tal y como se ha descrito en el tutorial. A continuación, veamos una guía paso a paso para crear un conjunto de datos de muestra utilizando PostgreSQL. El conjunto de datos consta de dos tablas relacionadas: La tabla « El primer paso es definir el esquema y establecer restricciones de clave primaria para ambas tablas. También definimos una relación de clave externa entre Para la tabla « Para la tabla « Explicación: Así es como debería verse en la interfaz de pgAdmin: A continuación, rellenamos las tablas con registros de muestra para observar cómo se comportan las claves primarias y externas durante las operaciones de inserción típicas. Estos datos simulan un escenario básico de comercio electrónico. Así es como debería verse en la interfaz de pgAdmin: Por último, realizamos una consulta SQL « Este es el código que vamos a ejecutar: Aquí tienes un ejemplo del resultado: Como puedes ver en la imagen anterior, la tabla de salida muestra datos de ambas tablas. Por ejemplo, la tabla unida incluye el campo « Las claves primarias SQL son fundamentales para las bases de datos relacionales, ya que garantizan la unicidad, permiten realizar consultas eficientes y respaldan la integridad de los datos. Hemos cubierto los principios, clasificaciones, sintaxis, mejores prácticas y estrategias avanzadas para las claves primarias SQL. Para obtener más recursos de aprendizaje, consulta nuestro curso Introducción a las bases de datos relacionales en SQL o el curso Unión de datos en SQL. Si prefieres leer tutoriales, la guía Restricciones de integridad en SQL o la hoja de referencia rápida sobre uniones SQL también te serán de gran ayuda.employees_pkey sigue la convención de nomenclatura predeterminada de PostgreSQL (table_name_pkey.
Gestión de valores nulos y gestión de colisiones
INSERT ... ON CONFLICT para evitar duplicados.Estrategias de autoincremento e identificador global
SERIAL », « BIGSERIAL » y « IDENTITY » simplifican la generación de ID.CREATE EXTENSION IF NOT EXISTS "pgcrypto";
CREATE TABLE users (
user_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
username TEXT NOT NULL
);Claves primarias en relaciones y mejora del rendimiento
Aplicación de la integridad de entidades
Claves externas e integridad referencial
ON DELETE CASCADEON UPDATE CASCADESET NULL y SET DEFAULTOptimización de indexación y consultas
SELECT y JOIN. Sin embargo, un diseño deficiente de las claves puede provocar índices inflados y un rendimiento degradado.EXPLAIN ANALYZE para inspeccionar los planes de consulta y evaluar el uso de los índices.Mejores prácticas de diseño y posibles dificultades
Directrices clave para la selección
INT, UUID).Errores comunes en la implementación
ALTER TABLE.Consideraciones sobre la escalabilidad
Escenarios de implementación avanzada
Sistemas de bases de datos distribuidas
Migración de sistemas heredados
Demostración de claves primarias utilizando PostgreSQL
Paso 1: Configuración inicial para PostgreSQL
pgAdmin (una interfaz gráfica) junto con el servidor PostgreSQL.
systemctl en Linux).
pgAdmin para gestionar y consultar bases de datos de forma visual.postgres por tu nombre de usuario real de PostgreSQL si es diferente.
pgAdmin, haz clic con el botón derecho en «Bases de datos» y selecciona «Crear > Base de datos».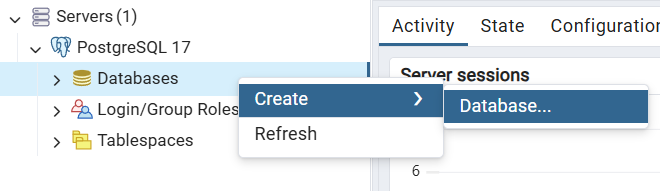
Connect to the new database in psql with:```bash
\c pk_tutorialcustomers y orders.customers » utiliza una clave sustituta para simplificar, mientras que la tabla « orders » utiliza una clave primaria basada en UUID para ilustrar la unicidad global.Paso 2: Creación de tablas
orders.customer_id y customers.customer_id para demostrar la integridad relacional.customers », la clave principal es « customer_id ».orders », la clave principal es « order_id ».CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY, -- Auto-incremented surrogate key
name TEXT NOT NULL,
email TEXT UNIQUE -- Ensures no duplicate email addresses
);
CREATE TABLE orders (
order_id UUID DEFAULT gen_random_uuid() PRIMARY KEY, -- Globally unique identifier
order_date DATE NOT NULL,
customer_id INT REFERENCES customers(customer_id) ON DELETE CASCADE -- Enforces referential integrity
);
customer_id utiliza la palabra clave « SERIAL » para generar identificadores únicos automáticamente.email tiene una restricción « UNIQUE » para evitar duplicados.order_id es un archivo « UUID » generado automáticamente a través de gen_random_uuid().ON DELETE CASCADE » garantiza que al eliminar un cliente también se eliminan los pedidos asociados a él.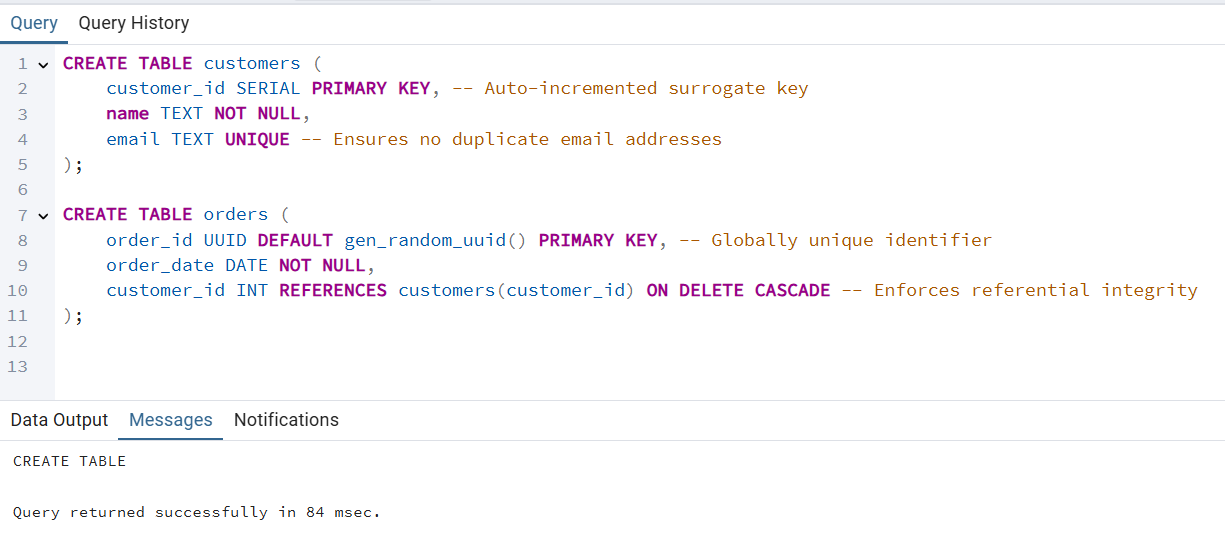
Paso 3: Insertar datos de muestra
INSERT INTO customers (name, email) VALUES
('Alice Tan', 'alice@example.com'),
('Ben Koh', 'ben@example.com'),
('Clara Lim', 'clara@example.com');
INSERT INTO orders (order_date, customer_id) VALUES
('2025-07-01', 1),
('2025-07-02', 2),
('2025-07-03', 3);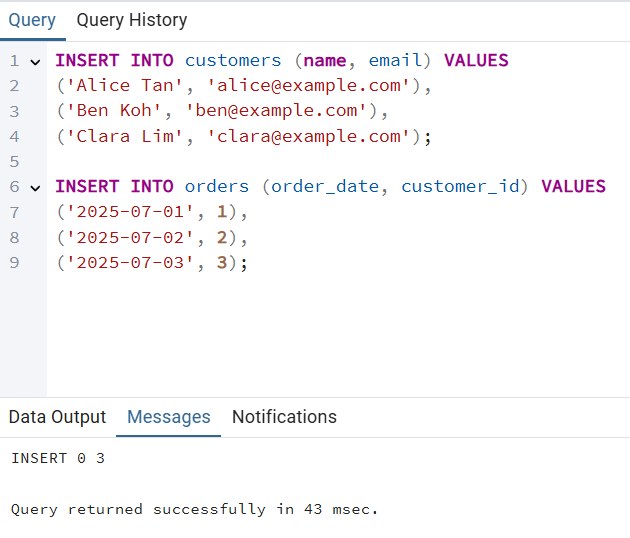
Paso 4: Consulta de datos
JOIN » para recuperar información de ambas tablas, lo que demuestra cómo la clave externa permite uniones relacionales perfectas entre pedidos y clientes.SELECT o.order_id, o.order_date, c.name, c.email
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;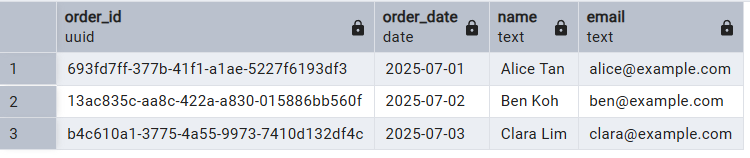
order_date » de la tabla « orders » y el campo « name » de la tabla « customers ».Conclusión
_pkey). Esto resulta útil cuando se rediseña el esquema de la tabla o se cambia a una columna de clave principal diferente.
Los mejores cursos de SQL
programa
Curso
Curso
blog
Mona Khalil
5 min
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Joleen Bothma
Tutorial
Travis Tang
