
Lernpfad
SQL Grundlagen
26 Std.
In relationalen Datenbanken ist der Primärschlüssel super wichtig, um sicherzustellen, dass die Daten in einer Tabelle eindeutig und korrekt sind. Ein Primärschlüssel ist eine Einschränkung, die jeden Datensatz in einer Tabelle eindeutig identifiziert und als grundlegendes Element für die Indizierung, die Durchsetzung der Entitätsintegrität und die Herstellung von Beziehungen zwischen Tabellen dient.
In diesem Tutorial zeige ich dir ausführlich, was SQL-Primärschlüssel sind, wie sie funktionieren, wie man sie einsetzt und wie man sie optimiert. Ich werde auch auf ein paar häufige Fehler und bewährte Vorgehensweisen eingehen und dir Beispiele aus der Praxis zeigen. Wenn du gerade SQL lernst, schau dir am besten unsere umfassende SQL-Roadmap an und mach unseren Lernpfad „SQL-Grundlagen“.
Ein SQL-Primärschlüssel ist eine Spalte oder ein Satz von Spalten, die jede Zeile in einer Tabelle eindeutig identifizieren. Das heißt, keine zwei Zeilen können denselben Primärschlüsselwert haben. Eine Tabelle kann nur einen Primärschlüssel haben, der aus einer oder mehreren Spalten bestehen kann.
Primärschlüssel sind super wichtig, um die Datenintegrität zu halten und effiziente Abfragen zu ermöglichen. Schauen wir uns mal ein paar grundlegende Sachen an.
Primärschlüssel sind super wichtig für die Normalisierung von Datenbanken und die relationale Integrität.
Wenn ein Primärschlüssel festgelegt wird, erstellt die Datenbank automatisch einen eindeutigen Index, um die Einschränkung durchzusetzen. Dieser Index macht Abfragen schneller, vor allem bei Suchvorgängen.
Mit diesem Indexsystem helfen Primärschlüssel der Datenbank-Engine dabei, den Ausführungsplan zu optimieren. Dadurch werden deine Abfragen schneller ausgeführt.
Primärschlüssel können aus verschiedenen Datentypen bestehen. Hier sind ein paar verschiedene Typen, die verwendet werden:
INTEGER oder SERIAL: Effizient und am häufigsten verwendet.BIGINT: Nützlich für Tabellen, in denen Milliarden von Zeilen gespeichert werden sollen.UUID: Gut für verteilte Systeme und um sequenzielle Vorhersagbarkeit zu vermeiden.CHAR/VARCHAR: Vorsichtig einsetzen, normalerweise in natürlichen Tonarten, wenn nötig.Primärschlüssel können je nach ihrer Struktur und Herkunft in verschiedene Typen eingeteilt werden. Ein paar Beispiele:
SERIAL “, „ BIGSERIAL “ oder „ UUID “ umgesetzt werden. Die Verwendung solcher Schlüssel sorgt für Stabilität, Privatsphäre und einfachere Wartung.Wenn wir sie anhand ihrer Funktionen vergleichen, können wir ihre Unterschiede in der folgenden Tabelle zusammenfassen:
|
Funktion |
Natürliche Schlüssel |
Ersatzschlüssel |
|
Geschäftliche Bedeutung |
Ja |
Nein |
|
Stabilität |
Oft instabil |
Super stabil |
|
Leistung |
Kann große Felder brauchen |
Im Allgemeinen kompakt |
|
Datenschutzbedenken |
Höher |
Niedriger |
Ein zusammengesetzter Primärschlüssel ist eine gängige Methode, um einen eindeutigen Schlüssel in Tabellen zu erstellen. Der Schlüssel wird normalerweise aus den Daten in zwei oder mehr Spalten abgeleitet.
Solche Schlüssel sind in Verknüpfungs- oder assoziativen Tabellen üblich, wo die Beziehung selbst Eindeutigkeit erfordert.
course_enrollments “ könnte einen zusammengesetzten Schlüssel aus „ student_id “ und „ course_id “ verwenden.Überlegungen:
Neben dem Primärschlüssel gibt's noch ein paar andere Schlüssel, die man verwenden kann, zum Beispiel:
Wenn du dich für ein Datenfeld als Primärschlüssel entscheidest, solltest du die folgenden Faktoren berücksichtigen:
Als Nächstes schauen wir uns an, wie man Primärschlüssel in PostgreSQL mit SQL-Befehlen deklarieren und verwalten kann.
Wir gehen verschiedene Szenarien durch, darunter das Erstellen von Tabellen, das Ändern vorhandener Tabellen und das Verwalten von Einschränkungen.
Bei der Erstellung der Tabellen solltest du Felder anlegen, die wahrscheinlich gebraucht werden. In diesem Fall erstellen wir eine Mitarbeiter-ID, die aus eindeutigen ganzen Zahlen besteht.
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY, -- Automatically generates unique integers
name TEXT NOT NULL, -- Basic text field, required
email TEXT UNIQUE -- Unique constraint to prevent duplicate emails
);Mehr zu SQL-Befehlen findest du in unserem SQL-Grundlagen-Spickzettel.

Dieses Beispiel zeigt, wie man einen Primärschlüssel inline mit dem Pseudo-Typ SERIAL definiert. PostgreSQL sieht SERIAL als eine automatisch hochgezählte Ganzzahl-Spalte, die super für Ersatzschlüssel ist. Die E-Mail-Spalte hat auch eine UNIQUE-Einschränkung, sodass sie als alternativer Schlüssel genutzt werden kann.
Jetzt legen wir „ employee_id “ als Primärschlüssel fest.
ALTER TABLE employees ADD PRIMARY KEY (employee_id);Dieser Befehl wird verwendet, wenn eine Tabelle bereits ohne Primärschlüssel erstellt wurde und du später einen hinzufügen möchtest. Pass auf, dass die Spalte, zu der du den Primärschlüssel hinzufügst, keine NULL-Werte oder doppelte Werte enthält, sonst klappt der Befehl nicht.
Jetzt, wo wir den Primärschlüssel festgelegt haben, kannst du auch die Primärschlüsselbeschränkung löschen.
ALTER TABLE employees DROP CONSTRAINT employees_pkey;Mit dieser Anweisung kannst du eine vorhandene Primärschlüsselbeschränkung löschen. Der Name der Einschränkung „ In PostgreSQL ist der Standardname für Primärschlüssel „ Mehr Infos zu PostgreSQL findest du in unserem Spickzettel. NULL-Werte sind in Primärschlüsselspalten nicht erlaubt. Doppelte Werte führen auch zu Fehlern wegen Verstoßes gegen Einschränkungen. Ein paar Strategien, um damit umzugehen, sind: Die PostgreSQL-Typen „ Außerdem bieten UUIDs sichere globale Identifikatoren. Ihre nicht sequenzielle und unvorhersehbare Natur erhöht auch die Sicherheit, vor allem bei der Verhinderung von Enumerationsangriffen. Hier ist eine Implementierung, wie eine UUID erstellt und als Primärschlüssel verwendet werden kann Primärschlüssel sind wichtig, um die Konsistenz in relationalen Tabellen zu halten und die Leistung zu verbessern. Die Integrität der Entitäten wird durch Primärschlüssel sichergestellt, indem NULL-Werte und Duplikate nicht erlaubt sind. Mit einer eindeutigen Kennung kannst du Datenfehler beim Einfügen oder Aktualisieren vermeiden. Fremdschlüssel müssen mit den Primärschlüsselwerten in der referenzierten Tabelle übereinstimmen. Referenzielle Integrität sorgt dafür, dass alle Verweise zwischen Tabellen gültig bleiben und verhindert „verwaiste Datensätze”, bei denen Datensätze auf nicht vorhandene Daten verweisen. Kaskadierende Aktionen sorgen für Konsistenz, wenn sich referenzierte Primärschlüssel ändern. Das kann gängige Kaskadenfunktionen beinhalten, wie zum Beispiel: Eindeutige Indizes auf Primärschlüsseln machen Abfragen wie „ Wenn deine Abfragen langsam sind und du denkst, dass das an einer schlechten Indizierung liegt, schau dir mit „ Ein gutes Schlüsseldesign macht die Wartung einfacher, sorgt für gute Leistung und lässt sich gut skalieren. Schauen wir uns mal ein paar bewährte Vorgehensweisen und häufige Fehler an. Die Fehlerbehebungen umfassen: Wenn du eine Datenbanklösung erstellst, die skalierbar sein soll, versuch, Ersatzschlüssel zu verwenden, um die Einheitlichkeit großer Datensätze zu gewährleisten. Vermeide in verteilten Systemen zusammengesetzte Schlüssel, wenn es nicht unbedingt nötig ist. Regelmäßige Überwachung der Größe deiner Tabellen/Indizes ist ebenfalls ein Muss. Der Umgang mit Primärschlüsseln in komplexen Systemen, wie verteilten Datenbanken oder Altsystemen, braucht echt gute Strategien. Verteilte Datenbanken sind komplizierter. Du musst sicherstellen, dass die Schlüsselgenerierung über alle Knoten hinweg konfliktfrei ist. Dafür kannst du UUIDs und zentralisierte Schlüsselverwaltungsdienste ausprobieren. Überlegungen zur Partitionierung: Wenn du eine Systemmigration von einer alten Datenbank machst, solltest du zuerst die vorhandenen eindeutigen Bezeichner herausfinden. Als Nächstes fügst du nach und nach Ersatzschlüssel neben den natürlichen Schlüsseln ein. Sei lieber vorsichtig und probier die Dual-Key-Unterstützung erst mal aus, bevor du komplett umstellst. Migrationsprozess: Bevor du Tabellen erstellen und Daten einfügen kannst, brauchst du eine funktionierende PostgreSQL-Umgebung. Dieser Abschnitt beginnt mit einer kurzen Anleitung zum Einrichten von PostgreSQL, gefolgt von Anweisungen zum Definieren und Verwenden eines Beispiel-Datensatzes zum Üben der Primärschlüsselkonzepte. Wenn du PostgreSQL noch nicht installiert hast, mach einfach Folgendes, um loszulegen: CREATE DATABASE pk_tutorial; Sobald deine Umgebung fertig ist, kannst du mit dem Rest der Datensatzkonfiguration fortfahren, wie bereits im Tutorial beschrieben. Schauen wir uns jetzt mal Schritt für Schritt an, wie man mit PostgreSQL einen Beispiel-Datensatz erstellt. Der Datensatz besteht aus zwei miteinander verbundenen Tabellen: Die Tabelle „ Zuerst musst du das Schema festlegen und Primärschlüsselbeschränkungen für beide Tabellen festlegen. Wir legen auch eine Fremdschlüsselbeziehung zwischen „ Für die Tabelle „ Für die Tabelle „ Erklärung: So sollte das in der pgAdmin-Oberfläche aussehen: Als Nächstes füllen wir die Tabellen mit Beispielsätzen, um zu sehen, wie Primär- und Fremdschlüssel bei typischen Einfügevorgängen funktionieren. Diese Daten zeigen ein einfaches E-Commerce-Szenario. So sollte das in der pgAdmin-Oberfläche aussehen: Zum Schluss machen wir eine SQL- Hier ist der Code, den wir ausführen werden: Hier ist die Beispielausgabe: Wie du in der Abbildung oben sehen kannst, zeigt die Ausgabetabelle Daten aus beiden Tabellen. Die verbundene Tabelle enthält zum Beispiel das Feld „ SQL-Primärschlüssel sind das A und O von relationalen Datenbanken. Sie sorgen dafür, dass alles eindeutig ist, Abfragen schnell laufen und die Daten intakt bleiben. Wir haben die Grundlagen, Klassifizierungen, Syntax, Best Practices und fortgeschrittenen Strategien für SQL-Primärschlüssel behandelt. Wenn du mehr lernen willst, check mal unseren Kurs „Einführung in relationale Datenbanken in SQL“ oder den Kurs „Daten in SQL verbinden“ aus. Wenn du lieber Tutorials liest, sind der Leitfaden zu Integritätsbeschränkungen in SQL oder das SQL-Joins-Spickzettel eine super Hilfe.employees_pkey ” folgt der Standard-Namenskonvention von PostgreSQL (table_name_pkey “.
Null-Behandlung und Kollisionsmanagement
INSERT ... ON CONFLICT verwenden, um Duplikate zu vermeiden.Strategien für automatische Inkrementierung und globale Identifikatoren
SERIAL “, „ BIGSERIAL “ und „ IDENTITY “ machen die ID-Generierung echt einfach.CREATE EXTENSION IF NOT EXISTS "pgcrypto";
CREATE TABLE users (
user_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
username TEXT NOT NULL
);Primärschlüssel in Beziehungen und Leistungssteigerung
Durchsetzung der Entitätsintegrität
Fremdschlüssel und referenzielle Integrität
ON DELETE CASCADEON UPDATE CASCADESET NULL und SET DEFAULTIndexierung und Abfrageoptimierung
SELECT “ und „ JOIN “ schneller. Ein schlechtes Schlüsseldesign kann aber zu überladenen Indizes und schlechter Leistung führen.EXPLAIN ANALYZE “ die Abfragepläne an und überprüfe die Indexnutzung.Best Practices für das Design und mögliche Fallstricke
Wichtige Auswahlkriterien
INT “, „ UUID “).Häufige Fehler bei der Umsetzung
ALTER TABLE “ hinzufügen.Überlegungen zur Skalierbarkeit
Erweiterte Implementierungsszenarien
Verteilte Datenbanksysteme
Migration von Altsystemen
Demonstration von Primärschlüsseln mit PostgreSQL
Schritt 1: Erste Schritte mit PostgreSQL
pgAdmin “ (eine grafische Benutzeroberfläche) zusammen mit dem PostgreSQL-Server installierst.
systemctl “ unter Linux).
pgAdmin “ kannst du Datenbanken ganz einfach verwalten und durchsuchen.postgres “ durch deinen echten PostgreSQL-Benutzernamen, falls anders.
pgAdmin “ mit der rechten Maustaste auf „Databases“ und wähle „Create > Database“.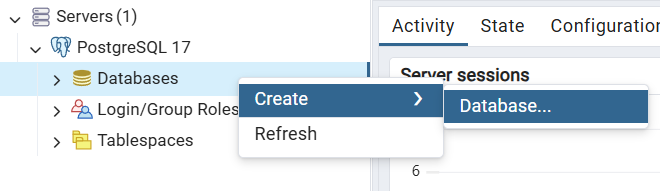
Connect to the new database in psql with:```bash
\c pk_tutorialcustomers und orders.customers “ verwendet der Einfachheit halber einen Ersatzschlüssel, während die Tabelle „ orders “ einen UUID-basierten Primärschlüssel verwendet, um die globale Eindeutigkeit zu veranschaulichen.Schritt 2: Tabellen erstellen
orders.customer_id ” und „ customers.customer_id ” fest, um die relationale Integrität zu zeigen.customers “ ist der Primärschlüssel „ customer_id “.orders “ ist der Primärschlüssel „ order_id “.CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY, -- Auto-incremented surrogate key
name TEXT NOT NULL,
email TEXT UNIQUE -- Ensures no duplicate email addresses
);
CREATE TABLE orders (
order_id UUID DEFAULT gen_random_uuid() PRIMARY KEY, -- Globally unique identifier
order_date DATE NOT NULL,
customer_id INT REFERENCES customers(customer_id) ON DELETE CASCADE -- Enforces referential integrity
);
customer_id verwendet das Schlüsselwort „ SERIAL “, um automatisch eindeutige IDs zu generieren.email hat eine Einschränkung „ UNIQUE “, um Duplikate zu vermeiden.order_id ist eine „ UUID ”, die automatisch über gen_random_uuid() generiert wird.ON DELETE CASCADE “ sorgt dafür, dass beim Löschen eines Kunden auch alle zugehörigen Bestellungen gelöscht werden.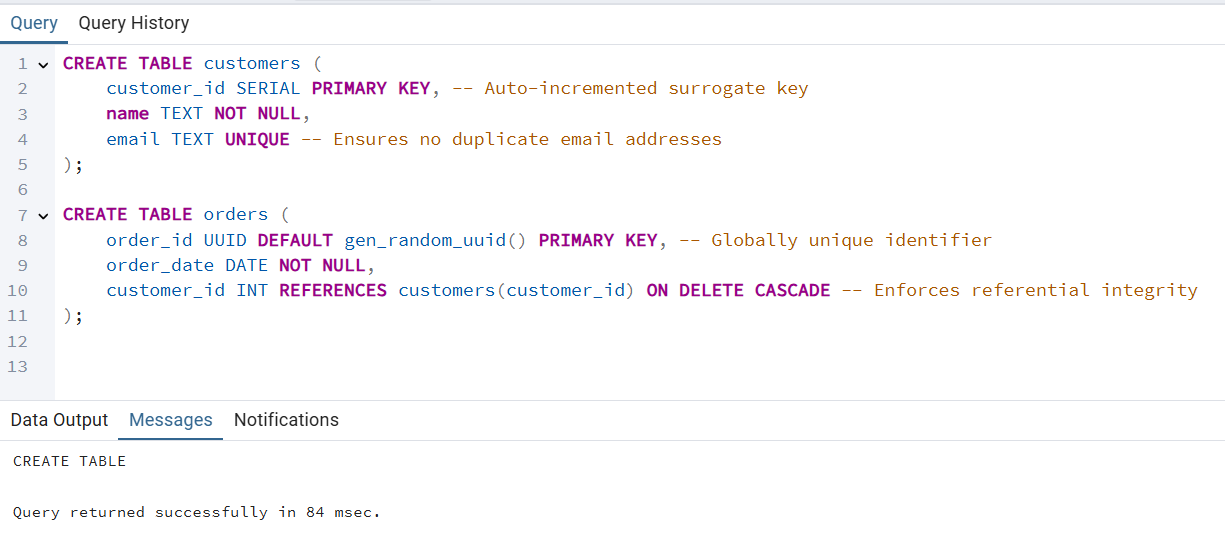
Schritt 3: Beispieldaten einfügen
INSERT INTO customers (name, email) VALUES
('Alice Tan', 'alice@example.com'),
('Ben Koh', 'ben@example.com'),
('Clara Lim', 'clara@example.com');
INSERT INTO orders (order_date, customer_id) VALUES
('2025-07-01', 1),
('2025-07-02', 2),
('2025-07-03', 3);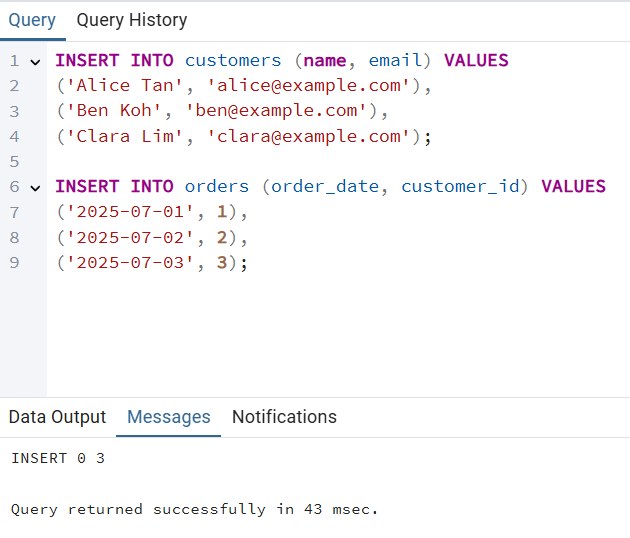
Schritt 4: Daten abfragen
JOIN -Abfrage, um Infos aus beiden Tabellen zu holen, und zeigen, wie der Fremdschlüssel nahtlose relationale Verknüpfungen zwischen Bestellungen und Kunden ermöglicht.SELECT o.order_id, o.order_date, c.name, c.email
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;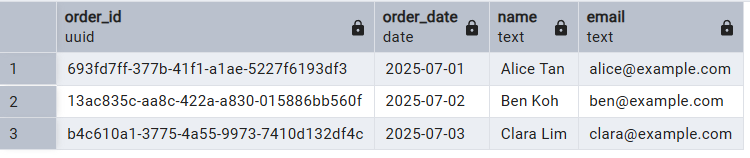
order_date “ aus der Tabelle „ orders “ und das Feld „ name “ aus der Tabelle „ customers “.Fazit
_pkey). Das ist praktisch, wenn du das Schema der Tabelle umgestalten oder zu einer anderen Primärschlüsselspalte wechseln willst.
Die besten SQL-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
Tutorial
DataCamp Team

