
Cursus
Principes fondamentaux de SQL
26 h
Dans les bases de données relationnelles, la clé primaire joue un rôle crucial pour garantir l'unicité et l'intégrité des données d'un tableau. Une clé primaire est une contrainte qui identifie de manière unique chaque enregistrement d'un tableau. Elle sert d'élément fondamental pour l'indexation, le renforcement de l'intégrité des entités et l'établissement de relations entre les tableaux.
Dans ce tutoriel, je vous guiderai à travers une exploration approfondie des clés primaires SQL, en couvrant les principes fondamentaux, les méthodes de mise en œuvre et les techniques d'optimisation. Je présenterai également quelques erreurs courantes et les meilleures pratiques, ainsi que des scénarios concrets. Si vous êtes encore en train d'apprendre le langage SQL, je vous recommande de consulter notre feuille de route SQL complète et de suivre notre cursus sur les fondamentaux du langage SQL.
Une clé primaire SQL est une colonne ou un ensemble de colonnes qui identifie de manière unique chaque ligne d'un tableau. Cela signifie qu'aucune ligne ne peut avoir la même valeur de clé primaire. Un tableau ne peut avoir qu'une seule clé primaire, qui peut être constituée d'une ou plusieurs colonnes.
Les clés primaires sont essentielles pour garantir l'intégrité des données et permettre des requêtes efficaces. Examinons quelques aspects fondamentaux.
Les clés primaires sont indispensables à la normalisation des bases de données et à l'intégrité relationnelle.
Lorsqu'une clé primaire est définie, la base de données crée automatiquement un index unique afin d'appliquer la contrainte. Cet index accélère les performances des requêtes, en particulier pour les opérations de recherche.
Grâce à ce système d'indexation, les clés primaires facilitent l'optimisation du plan d'exécution du moteur de base de données. Cela permettra d'accélérer l'exécution de vos requêtes.
Les clés primaires peuvent être de plusieurs types. Voici quelques types utilisés :
INTEGER ou SERIAL: Efficace et le plus couramment utilisé.BIGINT: Utile pour les tableaux susceptibles de stocker des milliards de lignes.UUID: Idéal pour les systèmes distribués et pour éviter la prévisibilité séquentielle.CHAR/VARCHAR: À utiliser avec précaution, généralement dans les tonalités naturelles lorsque cela est nécessaire.Les clés primaires peuvent être classées en différents types en fonction de leur structure et de leur origine. Voici quelques exemples :
SERIAL, l'BIGSERIAL ou l'UUID. L'utilisation de telles clés offre stabilité, confidentialité et facilité de maintenance.En les comparant sur la base de leurs caractéristiques, nous pouvons mettre en évidence leurs différences dans le tableau récapitulatif suivant :
|
Caractéristique |
Clé naturelle |
Clé de substitution |
|
Signification commerciale |
Oui |
Non |
|
Stabilité |
Souvent instable |
Très stable |
|
Performance |
Peut nécessiter de grands champs |
Généralement compact |
|
Préoccupations relatives à la confidentialité |
Supérieur |
Plus bas |
Une clé primaire composite est une méthode courante pour générer une clé unique dans les tableaux. La clé est généralement dérivée des données trouvées dans deux colonnes ou plus.
Ces clés sont courantes dans les tables de jonction ou associatives où la relation elle-même exige l'unicité.
course_enrollments pourrait utiliser une clé composite composée de student_id et course_id.Considérations :
Outre la clé primaire, plusieurs autres clés peuvent être utilisées, telles que :
Si vous hésitez sur le champ de données à utiliser comme clé primaire, vous pouvez tenir compte des facteurs suivants :
Ensuite, examinons comment déclarer et gérer les clés primaires dans PostgreSQL à l'aide de commandes SQL.
Nous examinerons divers scénarios, notamment la création de tableaux, la modification de tableaux existants et la gestion du comportement des contraintes.
Lors de la création des tableaux, il est recommandé de créer des champs susceptibles d'être trouvés. Dans ce cas, nous allons générer un identifiant d'employé composé d'entiers uniques.
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY, -- Automatically generates unique integers
name TEXT NOT NULL, -- Basic text field, required
email TEXT UNIQUE -- Unique constraint to prevent duplicate emails
);Pour en savoir plus sur les commandes SQL, veuillez consulter notre aide-mémoire sur les bases du SQL.

Cet exemple illustre la définition d'une clé primaire en ligne à l'aide du pseudo-type SERIAL. PostgreSQL traite SERIAL comme une colonne entière à incrémentation automatique, idéale pour les clés de substitution. La colonne « email » est également soumise à une contrainte UNIQUE, ce qui lui permet de servir de clé alternative.
Maintenant, définissons l'employee_id e comme clé primaire.
ALTER TABLE employees ADD PRIMARY KEY (employee_id);Cette commande est utilisée lorsqu'un tableau a déjà été créé sans clé primaire et que vous souhaitez en ajouter une par la suite. Veuillez vous assurer que la colonne à laquelle vous ajoutez la clé primaire ne contient pas de valeurs NULL ou de valeurs en double, sinon la commande échouera.
Maintenant que notre clé primaire est définie, vous pouvez également supprimer la contrainte de clé primaire.
ALTER TABLE employees DROP CONSTRAINT employees_pkey;Utilisez cette instruction pour supprimer une contrainte de clé primaire existante. Le nom de la contrainte « Dans PostgreSQL, le nom de contrainte par défaut pour les clés primaires est « Pour en savoir plus sur PostgreSQL, veuillez consulter notre fiche pratique. Les valeurs NULL ne sont pas autorisées dans les colonnes de clé primaire. Les valeurs en double entraîneront également des erreurs de violation de contrainte. Voici quelques stratégies pour gérer cette situation : Les types PostgreSQL « De plus, les UUID fournissent des identifiants globaux sécurisés. Leur nature non séquentielle et imprévisible renforce également la sécurité, en particulier dans la prévention des attaques par énumération. Voici une implémentation illustrant comment créer un UUID et l'utiliser comme clé primaire. Les clés primaires sont indispensables pour garantir la cohérence entre les tableaux relationnels et améliorer les performances. L'intégrité des entités est garantie par des clés primaires qui interdisent les valeurs NULL et les doublons. Disposer d'un identifiant unique permet d'éviter les anomalies dans les données lors des opérations d'insertion/mise à jour. Les clés étrangères doivent correspondre aux valeurs de clé primaire existantes dans le tableau référencé. L'intégrité référentielle garantit que toutes les références entre les tableaux restent valides et empêche les « enregistrements orphelins » où les enregistrements font référence à des données inexistantes. Les actions en cascade garantissent la cohérence lorsque les clés primaires référencées changent. Cela peut inclure des fonctions en cascade courantes telles que : Les index uniques sur les clés primaires accélèrent les requêtes d' Si vos requêtes sont lentes et que vous soupçonnez une mauvaise indexation, veuillez utiliser Une conception efficace des clés favorise la maintenabilité, les performances et l'évolutivité. Examinons quelques bonnes pratiques et erreurs courantes. Les corrections incluent : Lorsque vous créez une solution de base de données évolutive, essayez d'utiliser des clés de substitution afin de garantir l'uniformité des grands ensembles de données. Évitez les clés composites dans les systèmes distribués, sauf si cela est nécessaire. Il est également indispensable de surveiller régulièrement la taille de vos tableaux/index. La gestion des clés primaires dans des systèmes complexes, tels que les bases de données distribuées ou les systèmes hérités, nécessite des stratégies avancées. Les bases de données distribuées sont plus complexes. Vous devrez vous assurer que la génération de clés ne présente aucun conflit entre les nœuds. Pour ce faire, vous pouvez essayer d'utiliser des UUID et des services de gestion centralisée des clés. Considérations relatives au partitionnement : Lors de la migration d'un système à partir d'une base de données existante, veuillez commencer par identifier les identifiants uniques existants. Ensuite, introduisez progressivement des clés de substitution parallèlement aux clés naturelles. Adoptez une approche prudente en activant la prise en charge de la double clé avant de procéder à la transition complète. Processus de migration : Avant de créer des tableaux et d'y insérer des données, vous devez disposer d'un environnement PostgreSQL opérationnel. Cette section commence par un guide succinct sur la configuration de PostgreSQL, suivi d'instructions pour définir et utiliser un exemple de jeu de données afin de mettre en pratique les concepts de base. Si vous n'avez pas encore installé PostgreSQL, veuillez suivre ces étapes pour commencer : CRÉER UNE BASE DE DONNÉES pk_tutorial ; Une fois votre environnement prêt, vous pouvez poursuivre la configuration du jeu de données comme indiqué dans le tutoriel. Ensuite, nous allons examiner un guide étape par étape pour créer un exemple d'ensemble de données à l'aide de PostgreSQL. L'ensemble de données se compose de deux tableaux connexes : Le tableau « La première étape consiste à définir le schéma et à établir les contraintes de clé primaire pour les deux tableaux. Nous définissons également une relation de clé étrangère entre Pour le tableau Pour le tableau Explication : Voici à quoi cela devrait ressembler dans l'interface pgAdmin : Ensuite, nous remplissons les tableaux avec des exemples d'enregistrements afin d'observer le comportement des clés primaires et étrangères lors d'opérations d'insertion typiques. Ces données simulent un scénario de commerce électronique de base. Voici à quoi cela devrait ressembler dans l'interface pgAdmin : Enfin, nous effectuons une requête SQL « Voici le code que nous allons exécuter : Voici un exemple de résultat : Comme vous pouvez le constater sur l'image ci-dessus, le tableau de sortie affiche les données des deux tableaux. Par exemple, le tableau joint comprend le champ « Les clés primaires SQL sont fondamentales pour les bases de données relationnelles. Elles garantissent l'unicité, permettent des requêtes efficaces et assurent l'intégrité des données. Nous avons abordé les principes, les classifications, la syntaxe, les meilleures pratiques et les stratégies avancées relatives aux clés primaires SQL. Pour plus de ressources d'apprentissage, veuillez consulter notre cours Introduction aux bases de données relationnelles en SQL ou le cours Joindre des données en SQL. Si vous préférez les tutoriels, le guide Contraintes d'intégrité dans SQL ou l'aide-mémoire SQL Joins devraient également vous être très utiles.employees_pkey » respecte la convention de nommage par défaut de PostgreSQL (table_name_pkey ».
Gestion des valeurs nulles et des collisions
INSERT ... ON CONFLICT pour éviter les doublons.Stratégies d'auto-incrémentation et d'identifiant global
SERIAL », « BIGSERIAL » et « IDENTITY » simplifient la génération d'identifiants.CREATE EXTENSION IF NOT EXISTS "pgcrypto";
CREATE TABLE users (
user_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
username TEXT NOT NULL
);Clés primaires dans les relations et amélioration des performances
Application de l'intégrité des entités
Clés étrangères et intégrité référentielle
ON DELETE CASCADEON UPDATE CASCADESET NULL et SET DEFAULTIndexation et optimisation des requêtes
SELECT t et de JOIN. Cependant, une conception inadéquate des clés peut entraîner des index volumineux et une dégradation des performances.EXPLAIN ANALYZE pour inspecter les plans de requête et évaluer l'utilisation des index.Meilleures pratiques en matière de conception et pièges potentiels
Principales lignes directrices pour la sélection
INT, UUID).Erreurs courantes de mise en œuvre
ALTER TABLE.Considérations relatives à l'évolutivité
Scénarios de mise en œuvre avancés
Systèmes de bases de données distribuées
Migration des systèmes existants
Démonstration des clés primaires à l'aide de PostgreSQL
Étape 1 : Configuration initiale de PostgreSQL
pgAdmin (une interface graphique) avec le serveur PostgreSQL.
systemctl sous Linux).
pgAdmin pour gérer et interroger visuellement les bases de données.postgres par votre nom d'utilisateur PostgreSQL réel s'il est différent.
pgAdmin, cliquez avec le bouton droit sur « Bases de données » et sélectionnez « Créer > Base de données ».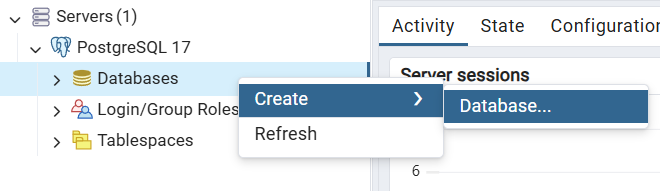
Connect to the new database in psql with:```bash
\c pk_tutorialcustomers et orders.customers » utilise une clé de substitution pour plus de simplicité, tandis que le tableau « orders » utilise une clé primaire basée sur un UUID pour illustrer l'unicité globale.Étape 2 : Création de tableaux
orders.customer_id et customers.customer_id afin de démontrer l'intégrité relationnelle.customers, la clé primaire est customer_id.orders, la clé primaire est order_id.CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY, -- Auto-incremented surrogate key
name TEXT NOT NULL,
email TEXT UNIQUE -- Ensures no duplicate email addresses
);
CREATE TABLE orders (
order_id UUID DEFAULT gen_random_uuid() PRIMARY KEY, -- Globally unique identifier
order_date DATE NOT NULL,
customer_id INT REFERENCES customers(customer_id) ON DELETE CASCADE -- Enforces referential integrity
);
customer_id utilise le mot-clé « SERIAL » pour générer automatiquement des identifiants uniques.email dispose d'une contrainte d'UNIQUE pour éviter les doublons.order_id Il s'agit d'un fichier de configuration ( UUID ) généré automatiquement via gen_random_uuid().ON DELETE CASCADE » garantit que la suppression d'un client entraîne également la suppression des commandes qui lui sont associées.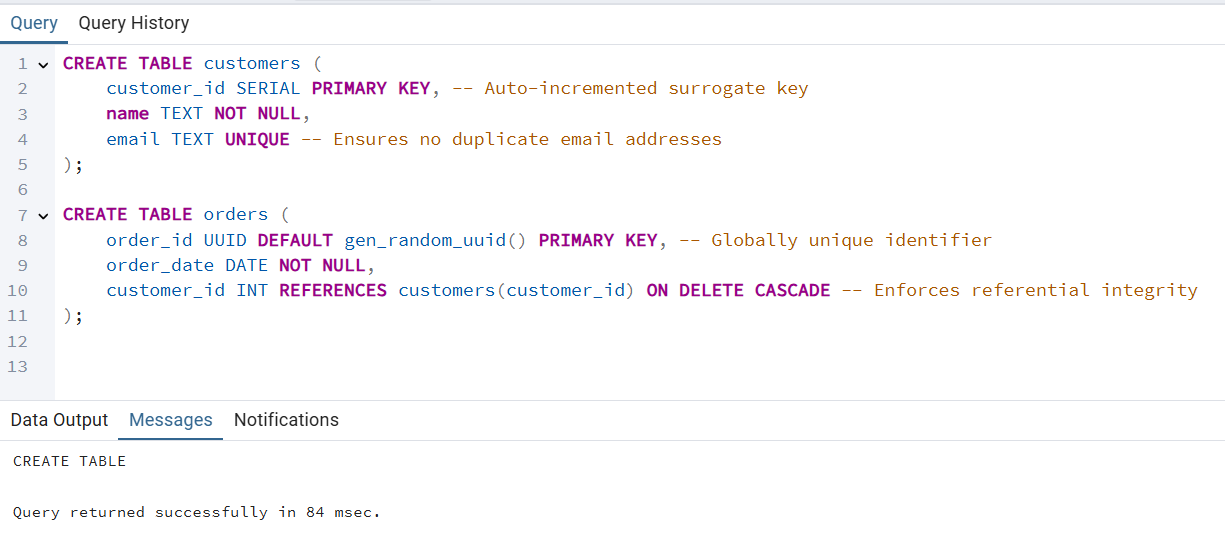
Étape 3 : Insertion de données d'exemple
INSERT INTO customers (name, email) VALUES
('Alice Tan', 'alice@example.com'),
('Ben Koh', 'ben@example.com'),
('Clara Lim', 'clara@example.com');
INSERT INTO orders (order_date, customer_id) VALUES
('2025-07-01', 1),
('2025-07-02', 2),
('2025-07-03', 3);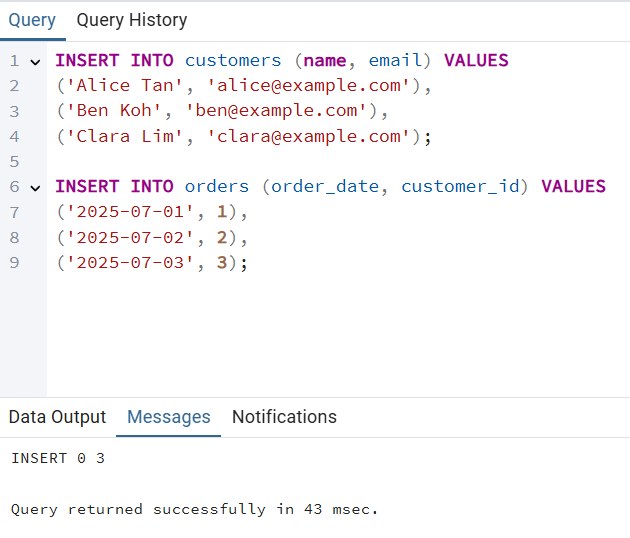
Étape 4 : Requête de données
JOIN » pour récupérer les informations des deux tableaux, démontrant ainsi comment la clé étrangère permet des jointures relationnelles transparentes entre les commandes et les clients.SELECT o.order_id, o.order_date, c.name, c.email
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;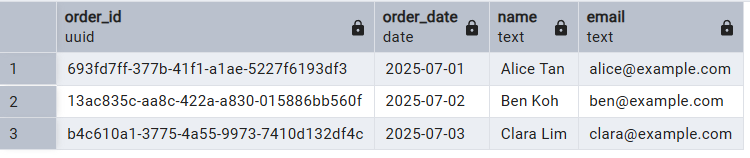
order_date » du tableau « orders » et le champ « name » du tableau « customers ».Conclusion
_pkey). Ceci est utile lors de la refonte du schéma du tableau ou lors du passage à une autre colonne de clé primaire.
Meilleures formations SQL
Cursus
Cours
Cours