
Programa
Fundamentos de SQL
26 h
Em bancos de dados relacionais, a chave primária é super importante pra garantir que os dados de uma tabela sejam únicos e fiquem certinhos. Uma chave primária é uma restrição que identifica de forma única cada registro em uma tabela, servindo como um elemento fundamental para indexação, garantindo a integridade da entidade e estabelecendo relações entre tabelas.
Neste tutorial, vou te mostrar tudo sobre chaves primárias SQL, falando sobre os princípios básicos, métodos de implementação e técnicas de otimização. Também vou falar sobre alguns erros comuns e melhores práticas, além de dar exemplos reais. Se você ainda está aprendendo SQL, recomendo que dê uma olhada no nosso roteiro completo de SQL e faça o nosso programa de habilidades Fundamentos de SQL.
Uma chave primária SQL é uma coluna ou um conjunto de colunas que identifica de forma única cada linha de uma tabela. Isso quer dizer que não pode ter duas linhas com o mesmo valor de chave primária. Uma tabela só pode ter uma chave primária, que pode ser uma ou várias colunas.
As chaves primárias são essenciais para garantir a integridade dos dados e permitir consultas eficientes. Vamos ver alguns pontos básicos.
As chaves primárias são essenciais para a normalização do banco de dados e a integridade relacional.
Quando uma chave primária é definida, o banco de dados cria automaticamente um índice exclusivo para fazer valer a restrição. Esse índice deixa as consultas mais rápidas, principalmente quando você está procurando algo.
Com esse sistema de índices, as chaves primárias ajudam o mecanismo do banco de dados a otimizar o plano de execução. Isso vai fazer com que suas consultas sejam mais rápidas.
As chaves primárias podem variar entre vários tipos de dados. Aqui estão alguns tipos diferentes que estão sendo usados:
INTEGER ou SERIAL: Eficiente e mais usado.BIGINT: É útil para tabelas que devem guardar bilhões de linhas.UUID: Ótimo pra sistemas distribuídos e pra evitar previsibilidade sequencial.CHAR/VARCHAR: Use com cuidado, geralmente em tons naturais quando for preciso.As chaves primárias podem ser classificadas em vários tipos com base na sua estrutura e origem. Alguns exemplos são:
SERIAL, BIGSERIAL ou UUID. Usar essas chaves dá estabilidade, privacidade e facilita a manutenção.Comparando-os com base nas características, podemos ver as diferenças na tabela resumida a seguir:
|
Recurso |
Chave natural |
Chave substituta |
|
Significado comercial |
Sim |
Não |
|
Estabilidade |
Muitas vezes instável |
Super estável |
|
Desempenho |
Pode precisar de campos grandes |
Geralmente compacto |
|
Preocupações com a privacidade |
Mais alto |
Mais baixo |
Uma chave primária composta é uma maneira comum de criar uma chave única nas tabelas. A chave geralmente vem dos dados que estão em duas ou mais colunas.
Essas chaves são comuns em tabelas de junção ou associativas, onde a própria relação exige exclusividade.
course_enrollments pode usar uma chave composta de student_id e course_id.Considerações:
Além da chave primária, tem várias outras chaves que podem ser usadas, tipo:
Se você está decidindo qual campo de dados usar como chave primária, pode considerar os seguintes fatores:
Agora, vamos ver como declarar e gerenciar chaves primárias no PostgreSQL usando comandos SQL.
Vamos ver vários cenários, como criar tabelas, mexer nas tabelas que já existem e controlar o comportamento das restrições.
Na fase de criação da tabela, você deve criar campos que provavelmente serão encontrados. Nesse caso, vamos criar um ID de funcionário que é composto por números inteiros únicos.
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY, -- Automatically generates unique integers
name TEXT NOT NULL, -- Basic text field, required
email TEXT UNIQUE -- Unique constraint to prevent duplicate emails
);Mais informações sobre comandos SQL em nossa Folha de Referência Básica sobre SQL.

Esse exemplo mostra como definir uma chave primária inline usando o pseudo-tipo SERIAL. O PostgreSQL trata SERIAL como uma coluna inteira com autoincremento, ideal para chaves substitutas. A coluna e-mail também tem uma restrição UNIQUE, que permite que ela seja usada como uma chave alternativa.
Agora, vamos definir o campo “ employee_id ” como a chave primária.
ALTER TABLE employees ADD PRIMARY KEY (employee_id);Esse comando é usado quando uma tabela já foi criada sem uma chave primária e você quer adicionar uma depois. Certifique-se de que a coluna à qual você está adicionando a chave primária não tem valores NULL ou duplicados, ou o comando vai falhar.
Com a nossa chave primária definida, você também pode remover a restrição da chave primária.
ALTER TABLE employees DROP CONSTRAINT employees_pkey;Use essa instrução para remover uma restrição de chave primária existente. O nome da restrição “ No PostgreSQL, o nome padrão da restrição para chaves primárias é Saiba mais sobre o PostgreSQL na nossa folha de dicas. Valores NULL não são permitidos em colunas de chave primária. Valores duplicados também vão causar erros de violação de restrição. Algumas estratégias pra lidar com isso são: Os tipos ` Além disso, os UUIDs são identificadores globais seguros. A natureza não sequencial e imprevisível deles também aumenta a segurança, principalmente na prevenção de ataques de enumeração. Aqui tá como dá pra criar um UUID e usar como chave primária As chaves primárias são essenciais para garantir a consistência entre tabelas relacionais e melhorar o desempenho. A integridade da entidade é garantida por chaves primárias, que não aceitam valores NULL nem duplicatas. Ter um identificador único ajuda a evitar anomalias nos dados durante as operações de inserção/atualização. As chaves estrangeiras precisam combinar com os valores da chave primária que já estão na tabela que você está referenciando. A integridade referencial garante que todas as referências entre tabelas continuem válidas e evita “registros órfãos”, que são registros que fazem referência a dados que não existem. As ações em cascata mantêm a consistência quando as chaves primárias referenciadas mudam. Isso pode incluir funções em cascata comuns, como: Índices exclusivos nas chaves primárias aceleram as consultas Se suas consultas estão lentas e você acha que é por causa de uma indexação ruim, use Um bom design de chave facilita a manutenção, o desempenho e a escalabilidade. Vamos dar uma olhada em algumas das melhores práticas e erros comuns. As correções incluem: Quando estiver criando uma solução de banco de dados que pode crescer, tente usar chaves substitutas para manter tudo uniforme em conjuntos de dados grandes. Evite chaves compostas em sistemas distribuídos, a menos que seja necessário. Também é importante ficar de olho no tamanho das tabelas/índices. Lidar com chaves primárias em sistemas complexos, como bancos de dados distribuídos ou sistemas antigos, precisa de estratégias avançadas. Os bancos de dados distribuídos são mais complicados. Você precisa garantir que a geração de chaves não tenha conflitos entre os nós. Pra isso, você pode tentar usar UUIDs e serviços de gerenciamento de chaves centralizadas. Considerações sobre particionamento: Quando estiver migrando um sistema de um banco de dados antigo, primeiro veja quais são os identificadores únicos que já existem. Depois, vá introduzindo as chaves substitutas junto com as chaves naturais. Seja cuidadoso e use o suporte para chaves duplas antes de fazer a transição completa. Processo de migração: Antes de criar tabelas e inserir dados, você precisa de um ambiente PostgreSQL que funcione. Esta seção começa com um guia rápido sobre como configurar o PostgreSQL, seguido de instruções para definir e usar um conjunto de dados de exemplo para praticar os conceitos básicos de chave primária. Se você ainda não instalou o PostgreSQL, siga estas etapas para começar: Criar banco de dados pk_tutorial; Quando o seu ambiente estiver pronto, você pode continuar com o resto da configuração do conjunto de dados, como já foi explicado no tutorial. Agora, vamos ver um guia passo a passo pra criar um conjunto de dados de exemplo usando o PostgreSQL. O conjunto de dados tem duas tabelas relacionadas: A tabela “ O primeiro passo é definir o esquema e estabelecer restrições de chave primária para ambas as tabelas. Também definimos uma relação de chave estrangeira entre Para a tabela " Para a tabela " Explicação: É assim que deve aparecer na interface do pgAdmin: Depois, preenchemos as tabelas com registros de exemplo pra ver como as chaves primárias e estrangeiras se comportam durante operações típicas de inserção. Esses dados mostram um cenário básico de comércio eletrônico. É assim que deve aparecer na interface do pgAdmin: Por fim, fazemos uma consulta SQL “ Aqui tá o código que vamos rodar: Aqui tá um exemplo de resultado: Como você pode ver na imagem acima, a tabela de saída mostra os dados das duas tabelas. Por exemplo, a tabela unida inclui o campo “ As chaves primárias SQL são essenciais para bancos de dados relacionais, garantindo a exclusividade, permitindo consultas eficientes e mantendo a integridade dos dados. A gente falou sobre os princípios, classificações, sintaxe, melhores práticas e estratégias avançadas para chaves primárias SQL. Se quiser mais recursos de aprendizagem, dá uma olhada no nosso curso Introdução a bancos de dados relacionais em SQL ou no curso Junção de dados em SQL. Se você curte ler tutoriais, o guia Restrições de integridade no SQL ou a Folha de dicas sobre junções SQL também podem ajudar bastante.employees_pkey ” segue a convenção de nomenclatura padrão do PostgreSQL (table_name_pkey.
Tratamento de valores nulos e gerenciamento de colisões
INSERT ... ON CONFLICT pra evitar duplicatas.Estratégias de autoincremento e identificador global
SERIAL`, ` BIGSERIAL` e ` IDENTITY ` do PostgreSQL facilitam a geração de IDs.CREATE EXTENSION IF NOT EXISTS "pgcrypto";
CREATE TABLE users (
user_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
username TEXT NOT NULL
);Chaves primárias em relações e aumento do desempenho
Aplicação da integridade da entidade
Chaves estrangeiras e integridade referencial
ON DELETE CASCADEON UPDATE CASCADESET NULL e SET DEFAULTIndexação e otimização de consultas
SELECT e JOIN. Mas, um design ruim das chaves pode deixar os índices pesados e o desempenho meio ruim.EXPLAIN ANALYZE para dar uma olhada nos planos de consulta e ver como está o uso do índice.Melhores práticas de design e possíveis armadilhas
Diretrizes importantes para a escolha
INT, UUID).Erros comuns de implementação
ALTER TABLE.Considerações sobre escalabilidade
Cenários de implementação avançada
Sistemas de banco de dados distribuídos
Migração do sistema antigo
Demonstração de chaves primárias usando PostgreSQL
Passo 1: Configuração inicial para PostgreSQL
pgAdmin (uma interface gráfica) junto com o servidor PostgreSQL.
systemctl no Linux).
pgAdmin para gerenciar e consultar bancos de dados de forma visual.postgres pelo seu nome de usuário PostgreSQL, se for diferente.
pgAdmin ”, clique com o botão direito do mouse em “Databases” e selecione “Create > Database”.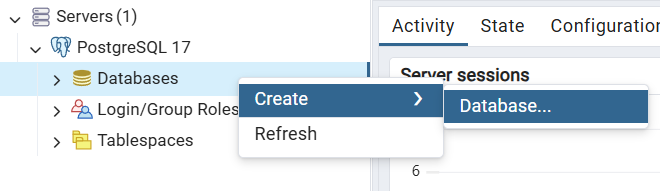
Connect to the new database in psql with:```bash
\c pk_tutorialcustomers e orders.customers ” usa uma chave substituta para simplificar, enquanto a tabela “ orders ” usa uma chave primária baseada em UUID para mostrar a exclusividade global.Passo 2: Criando tabelas
orders.customer_id e customers.customer_id para mostrar a integridade relacional.customers ", a chave primária é " customer_id".orders ", a chave primária é " order_id".CREATE TABLE customers (
customer_id SERIAL PRIMARY KEY, -- Auto-incremented surrogate key
name TEXT NOT NULL,
email TEXT UNIQUE -- Ensures no duplicate email addresses
);
CREATE TABLE orders (
order_id UUID DEFAULT gen_random_uuid() PRIMARY KEY, -- Globally unique identifier
order_date DATE NOT NULL,
customer_id INT REFERENCES customers(customer_id) ON DELETE CASCADE -- Enforces referential integrity
);
customer_id usa a palavra-chave “ SERIAL ” para criar IDs únicos automaticamente.email tem uma restrição " UNIQUE " para evitar duplicatas.order_id é um arquivo de configuração ( UUID ) gerado automaticamente pelo site gen_random_uuid().ON DELETE CASCADE ” garante que, ao excluir um cliente, também sejam excluídos os pedidos associados a ele.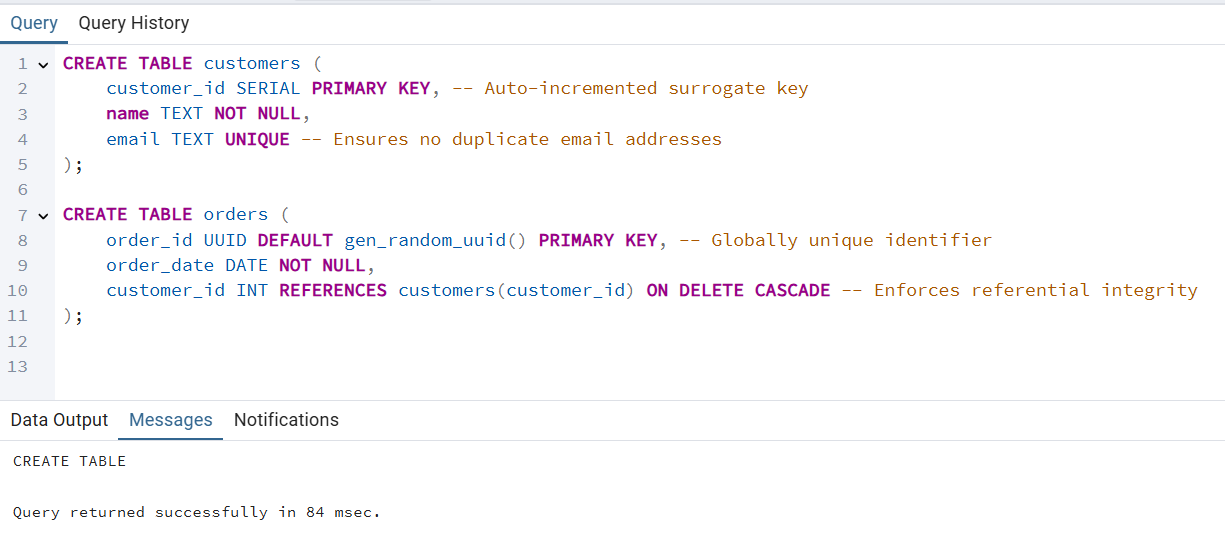
Passo 3: Inserindo dados de amostra
INSERT INTO customers (name, email) VALUES
('Alice Tan', 'alice@example.com'),
('Ben Koh', 'ben@example.com'),
('Clara Lim', 'clara@example.com');
INSERT INTO orders (order_date, customer_id) VALUES
('2025-07-01', 1),
('2025-07-02', 2),
('2025-07-03', 3);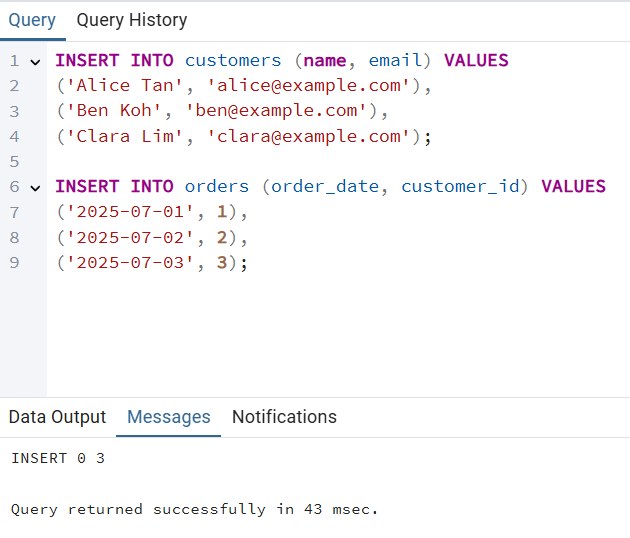
Passo 4: Consultando dados
JOIN ” pra pegar as informações das duas tabelas, mostrando como a chave estrangeira permite junções relacionais perfeitas entre pedidos e clientes.SELECT o.order_id, o.order_date, c.name, c.email
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id;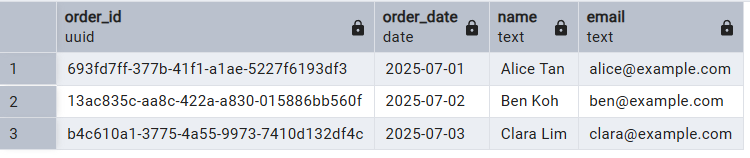
order_date ” da tabela “ orders ” e o campo “ name ” da tabela “ customers ”.Conclusão
_pkey). Isso é útil quando você está redesenhando o esquema da tabela ou mudando para uma coluna de chave primária diferente.
Os melhores cursos de SQL
Programa
Curso
Curso
blog
Summer Worsley
13 min
blog
Natassha Selvaraj
11 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Kevin Babitz


