Curso
Python intermedio
4 h
1.4M
El análisis del sentimiento es una técnica utilizada para determinar el tono emocional o sentimiento expresado en un texto. Consiste en analizar las palabras y frases utilizadas en el texto para identificar el sentimiento subyacente, ya sea positivo, negativo o neutro.
El análisis del sentimiento tiene una amplia gama de aplicaciones, como la monitorización de las redes sociales, el análisis de las opiniones de los clientes y la investigación de mercado.
Uno de los principales retos del análisis del sentimiento es la complejidad inherente al lenguaje humano. Los datos textuales suelen contener sarcasmo, ironía y otras formas de lenguaje figurado que pueden ser difíciles de interpretar con los métodos tradicionales.
Sin embargo, los recientes avances en el procesamiento del lenguaje natural (PLN) y el machine learning han hecho posible realizar análisis del sentimiento en grandes volúmenes de datos de texto con un alto grado de precisión.
Hay varias formas de realizar análisis del sentimiento en datos de texto, con distintos grados de complejidad y precisión. Los métodos más comunes incluyen un enfoque basado en el léxico, un enfoque basado en machine learning (ML) y un enfoque de deep learning basado en transformadores preentrenados. Veamos cada uno de ellos con más detalle:
Este tipo de análisis, como el analizador de sentimientos NLTK Vader, consiste en utilizar un conjunto de reglas y heurísticas predefinidas para determinar el sentimiento de un texto. Estas reglas suelen basarse en características léxicas y sintácticas del texto, como la presencia de palabras y frases positivas o negativas.
Aunque el análisis basado en léxico puede ser relativamente sencillo de aplicar e interpretar, puede no ser tan preciso como los enfoques basados en ML o en transformaciones, sobre todo cuando se trata de datos de texto complejos o ambiguos.
Este enfoque consiste en entrenar un modelo para identificar el sentimiento de un texto a partir de un conjunto de datos de entrenamiento etiquetados. Estos modelos pueden entrenarse utilizando una amplia gama de algoritmos de ML, como árboles de decisión, máquinas de vectores de soporte (SVM) y redes neuronales.
Los enfoques basados en ML pueden ser más precisos que el análisis basado en reglas, especialmente cuando se trata de datos de texto complejos, pero requieren una mayor cantidad de datos de entrenamiento etiquetados y pueden ser más costosos computacionalmente.
Un enfoque basado en el deep learning, como se ha visto con BERT y GPT-4, implica utilizar modelos preentrenados y entrenados en cantidades masivas de datos de texto. Estos modelos utilizan redes neuronales complejas para codificar el contexto y el significado del texto, lo que les permite alcanzar una precisión de vanguardia en una amplia gama de tareas de PNL, incluido el análisis del sentimiento. Sin embargo, estos modelos requieren importantes recursos informáticos y pueden no ser prácticos para todos los casos de uso.
La elección del enfoque dependerá de las necesidades y limitaciones específicas del proyecto en cuestión.
Para utilizar la biblioteca NLTK, debes tener un entorno Python en tu ordenador. La forma más sencilla de instalar Python es descargar e instalar la distribución Anaconda. Esta distribución incluye el entorno base de Python 3 y otros extras, como Jupyter Notebook. Tampoco necesitas instalar la biblioteca NLTK, ya que viene preinstalada con NLTK y muchas otras bibliotecas útiles.
Si decides instalar Python sin ninguna distribución, puedes descargar e instalar Python directamente desde python.org. En este caso, tendrás que instalar NLTK una vez que tu entorno Python esté listo.
Para instalar la biblioteca NLTK, abre el terminal de comandos y escribe
pip install nltkVale la pena señalar que NLTK también requiere que se descarguen algunos datos adicionales antes de poder utilizarlo eficazmente. Estos datos incluyen modelos preentrenados, corpus y otros recursos que NLTK utiliza para realizar diversas tareas de PNL. Para descargar estos datos, ejecuta el siguiente comando en el terminal o en tu script Python:
import nltk
nltk.download('all')El preprocesamiento del texto es un paso crucial en la realización del análisis del sentimiento, ya que ayuda a limpiar y normalizar los datos de texto, lo cual facilita su análisis. El paso de preprocesamiento implica una serie de técnicas que ayudan a transformar los datos de texto sin procesar en una forma que puedas utilizar para el análisis. Algunas técnicas habituales de preprocesamiento de texto son la tokenización, la eliminación de palabras vacías, la separación de palabras y la lematización.
La tokenización es un paso del preprocesamiento del texto en el análisis del sentimiento que consiste en descomponer el texto en palabras individuales o tokens. Este es un paso esencial en el análisis de datos de texto, ya que ayuda a separar las palabras individuales del texto en bruto y facilita su análisis y comprensión. La tokenización se suele realizar mediante la función word_tokenize integrada en NLTK, que puede dividir el texto en palabras individuales y signos de puntuación.
La eliminación de las palabras vacías es un paso crucial del preprocesamiento del texto en el análisis del sentimiento, que consiste en eliminar las palabras comunes e irrelevantes que probablemente no transmitan mucho sentimiento. Las palabras vacías son palabras muy comunes en una lengua y que no tienen mucho significado, como "y", "el", "de" y "ello". Estas palabras pueden causar ruido y sesgar el análisis si no se eliminan.
Al eliminar las palabras vacías, es más probable que las palabras restantes del texto indiquen el sentimiento expresado. Esto puede ayudar a mejorar la precisión del análisis del sentimiento. NLTK proporciona una lista integrada de palabras de parada para varios idiomas, que puede utilizarse para filtrar estas palabras de los datos del texto.
La separación de palabras y la lematización son técnicas que se utilizan para reducir las palabras a su raíz. La separación de palabras consiste en eliminar los sufijos de las palabras, como "ndo" o "ado", para reducirlas a su forma básica. Por ejemplo, la palabra "saltando" se derivaría a "salta".
La lematización, en cambio, consiste en reducir las palabras a su forma básica en función de su parte de la oración. Por ejemplo, la palabra "saltó" se lematizaría a "saltar", pero la palabra "saltando" se lematizaría a "saltando", ya que es un participio.
Para saber más sobre la separación de palabras y la lematización, consulta nuestro tutorial sobre Separación de palabras y lematización en Python.
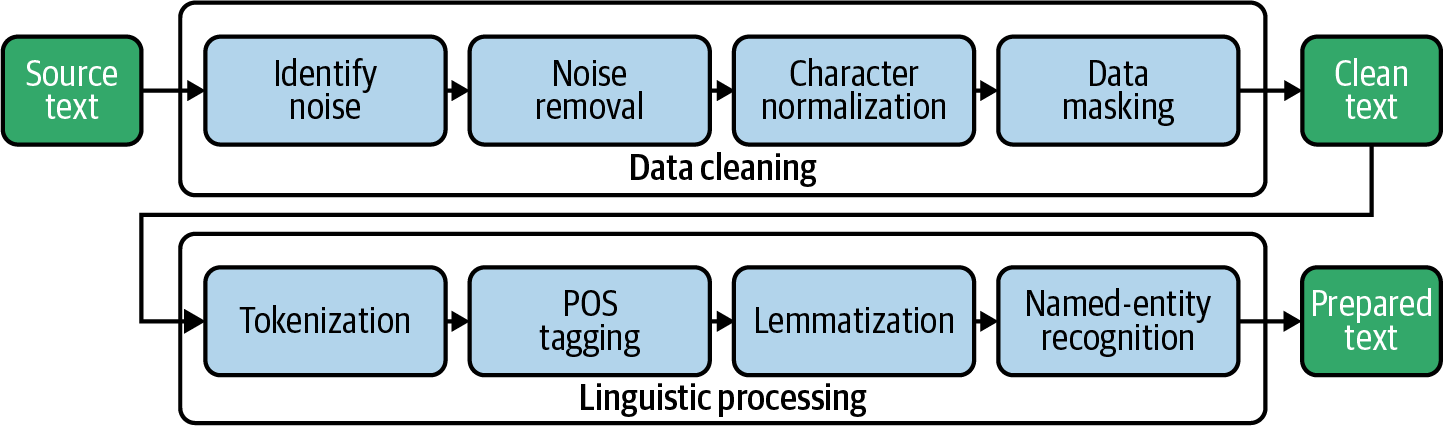
El modelo de bolsa de palabras es una técnica utilizada en el procesamiento del lenguaje natural (PLN) para representar datos de texto como un conjunto de características numéricas. En este modelo, cada documento o fragmento de texto se representa como una "bolsa" de palabras, en la que cada palabra del texto está representada por una característica o dimensión independiente en el vector resultante. El valor de cada característica viene determinado por el número de veces que aparece la palabra correspondiente en el texto.
El modelo de bolsa de palabras es útil en PNL porque nos permite analizar datos de texto mediante algoritmos de machine learning, que suelen requerir una entrada numérica. Al representar los datos de texto como características numéricas, podemos entrenar modelos de machine learning para clasificar texto o analizar sentimientos.
El ejemplo de la siguiente sección utilizará el modelo NLTK Vader para el análisis del sentimiento en el conjunto de datos de clientes de Amazon. En este ejemplo concreto, no necesitamos realizar este paso porque la API Vader de NLTK acepta texto como entrada en lugar de vectores numéricos, pero si estuvieras construyendo un modelo de machine learning supervisado para predecir el sentimiento (suponiendo que tengas datos etiquetados), tendrías que transformar el texto procesado en un modelo de bolsa de palabras antes de entrenar el modelo de machine learning.
Para realizar un análisis del sentimiento con NLTK en Python, primero hay que preprocesar los datos de texto mediante técnicas como la tokenización, la eliminación de palabras vacías y la lematización. Una vez preprocesado el texto, lo pasaremos al analizador de sentimiento Vader para que analice el sentimiento del texto (positivo o negativo).
En primer lugar, importaremos las bibliotecas necesarias para el análisis de texto y el análisis del sentimiento, como pandas para el tratamiento de datos, nltk para el procesamiento del lenguaje natural y SentimentIntensityAnalyzer para el análisis del sentimiento.
A continuación, descargaremos todo el corpus NLTK (una colección de datos lingüísticos) mediante nltk.download().
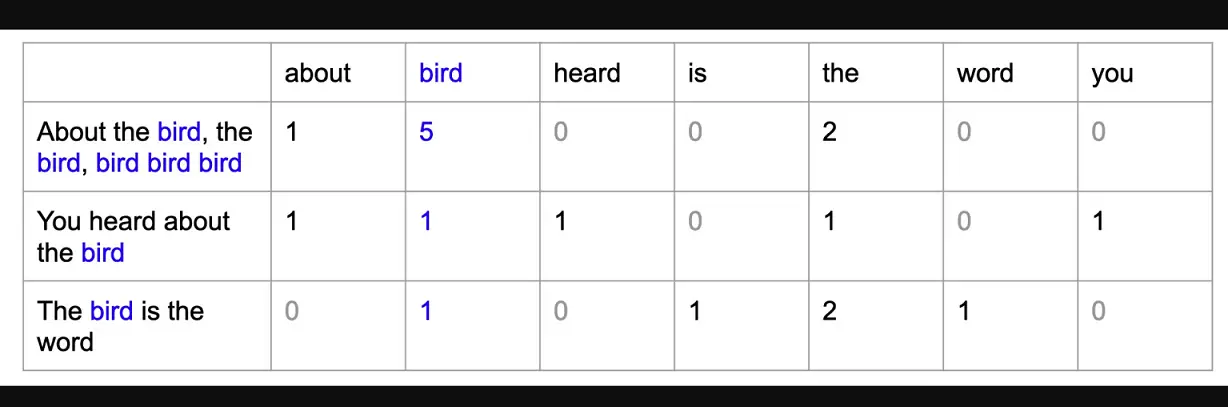
Una vez configurado el entorno, cargaremos un conjunto de datos de reseñas de Amazon mediante pd.read_csv(). Esto creará un objeto DataFrame en Python que podremos utilizar para analizar los datos. Mostraremos el contenido del DataFrame mediante df.
# import libraries
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# download nltk corpus (first time only)
import nltk
nltk.download('all')
# Load the amazon review dataset
df = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/amazon.csv')
df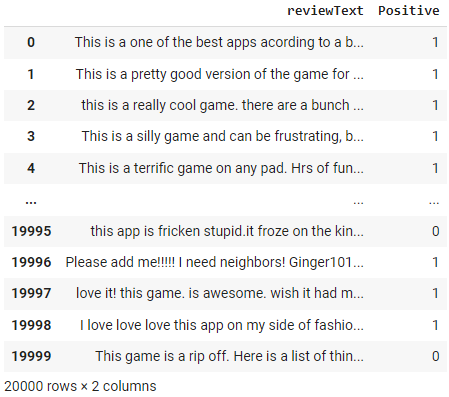
Vamos a crear una función preprocess_text en la que primero tokenizamos los documentos utilizando la función word_tokenize de NLTK, luego eliminamos las palabras escalonadas utilizando el módulo stepwords de NLTK y, por último, lematizamos los filtered_tokens utilizando WordNetLemmatizer de NLTK.
# create preprocess_text function
def preprocess_text(text):
# Tokenize the text
tokens = word_tokenize(text.lower())
# Remove stop words
filtered_tokens = [token for token in tokens if token not in stopwords.words('english')]
# Lemmatize the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into a string
processed_text = ' '.join(lemmatized_tokens)
return processed_text
# apply the function df
df['reviewText'] = df['reviewText'].apply(preprocess_text)
df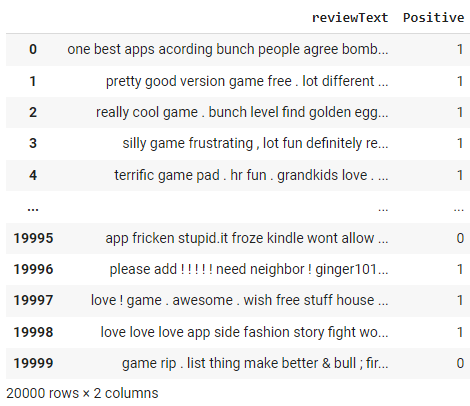
Observa los cambios en la columna "texto de revisión" como resultado de la función preprocess_text que hemos aplicado en el paso anterior.
En primer lugar, inicializaremos un objeto de analizador de intensidad del sentimiento de la biblioteca nltk.sentiment.vader.
A continuación, definiremos una función llamada get_sentiment que toma como entrada una cadena de texto. La función llama al método polarity_scores del objeto analizador para obtener un diccionario de puntuaciones de sentimiento del texto, que incluye una puntuación para el sentimiento positivo, negativo y neutro.
A continuación, la función comprobará si la puntuación positiva es mayor que 0 y devuelve una puntuación de sentimiento de 1 si lo es, y de 0 en caso contrario. Esto significa que cualquier texto con una puntuación positiva se clasificará como de sentimiento positivo, y cualquier texto con una puntuación no positiva se clasificará como de sentimiento negativo.
Por último, aplicaremos la función get_sentiment a la columna reviewText del DataFrame df mediante el método apply. Esto crea una nueva columna llamada sentimiento en el DataFrame, que almacena la puntuación de sentimiento de cada opinión. A continuación, mostraremos el DataFrame actualizado utilizando df.
# initialize NLTK sentiment analyzer
analyzer = SentimentIntensityAnalyzer()
# create get_sentiment function
def get_sentiment(text):
scores = analyzer.polarity_scores(text)
sentiment = 1 if scores['pos'] > 0 else 0
return sentiment
# apply get_sentiment function
df['sentiment'] = df['reviewText'].apply(get_sentiment)
df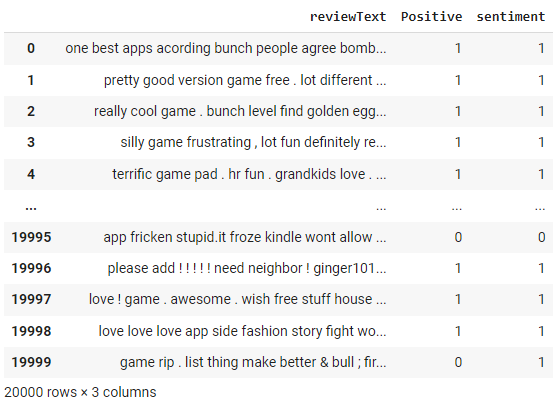
El analizador de sentimientos NLTK devuelve una puntuación entre -1 y +1. Hemos utilizado un umbral de corte de 0 en la función get_sentiment anterior. Todo lo que sea superior a 0 se clasifica como 1 (es decir, positivo). Como disponemos de etiquetas reales, podemos evaluar el rendimiento de este método construyendo una matriz de confusión.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(df['Positive'], df['sentiment']))Salida:
[[ 1131 3636]
[ 576 14657]]También podemos consultar el informe de clasificación:
from sklearn.metrics import classification_report
print(classification_report(df['Positive'], df['sentiment']))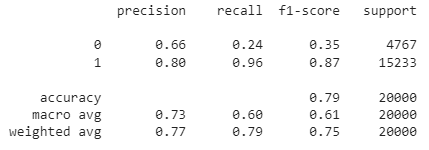
Como puedes ver, la precisión global de este modelo de análisis del sentimiento basado en reglas es del 79%. Como se trata de datos etiquetados, también puedes intentar construir un modelo ML para evaluar si un enfoque basado en ML dará como resultado una mayor precisión.
Consulta el cuaderno completo en el espacio de trabajo Datacamp.
NLTK es una biblioteca potente y flexible para realizar análisis del sentimiento y otras tareas de procesamiento del lenguaje natural en Python. Utilizando NLTK, podemos preprocesar datos de texto, convertirlos en un modelo de bolsa de palabras y realizar un análisis del sentimiento utilizando el analizador de sentimientos de Vader.
A través de este tutorial, hemos explorado los fundamentos del análisis del sentimiento NLTK, incluido el preprocesamiento de datos de texto, la creación de un modelo de bolsa de palabras y la realización de análisis del sentimiento utilizando NLTK Vader. También hemos discutido las ventajas y limitaciones del análisis del sentimiento NLTK, y hemos proporcionado sugerencias para futuras lecturas y exploraciones.
En general, NLTK es una herramienta potente y muy utilizada para realizar análisis del sentimiento y otras tareas de procesamiento del lenguaje natural en Python. Si dominas las técnicas y herramientas presentadas en este tutorial, podrás obtener información valiosa sobre el sentimiento de los datos de texto y utilizarla para tomar decisiones basadas en datos en una amplia gama de aplicaciones.
Si quieres aprender a aplicar la PNL a datos del mundo real, como charlas TED, artículos y críticas de películas, utilizando bibliotecas y marcos de trabajo de Python, como NLTK, scikit-learn, spaCy y SpeechRecognition, consulta los siguientes recursos:
Proporciona una base sólida para procesar y analizar datos de texto utilizando Python. Tanto si eres nuevo en el PNL como si quieres ampliar tus conocimientos, este curso te dotará de las herramientas y los conocimientos necesarios para convertir datos no estructurados en información valiosa.
Cursos de Python
Curso
Curso
Curso
Tutorial
Kurtis Pykes
Tutorial
Duong Vu
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali