Curso
Introducción al Natural Language Processing en Python
4 h
141K
El procesamiento del lenguaje natural (PLN) mejora la forma en que los humanos y los ordenadores se comunican entre sí, utilizando el aprendizaje automático para indicar la estructura y el significado del texto. Con las aplicaciones de procesamiento del lenguaje natural, las organizaciones pueden aumentar la productividad y reducir los costes analizando el texto y extrayendo información más significativa para mejorar la experiencia del cliente.
No podemos decir que pensemos a menudo en las sutilezas de nuestra lengua. Es un comportamiento intuitivo que se basa en claves semánticas como palabras, signos o imágenes para transmitir información y significado. A veces se dice que aprender una lengua es más fácil en la adolescencia porque es un comportamiento repetible que se puede inculcar, como caminar. Además, las lenguas no siguen reglas estrictas y tienen muchas excepciones.
La adquisición del lenguaje, aunque natural para los humanos, es extremadamente compleja para los ordenadores porque tiene muchos datos no estructurados, carece de reglas estrictas y no tiene una perspectiva o contexto concretos. Sin embargo, los seres humanos dependen cada vez más de los sistemas informáticos para comunicarse y realizar tareas. Por eso el aprendizaje automático (ML) y la inteligencia artificial (IA) están ganando tanta atención y popularidad. El procesamiento del lenguaje natural sigue el desarrollo de la IA. Aunque estos dos términos puedan evocar imágenes de robots futuristas, ya existen aplicaciones sencillas del procesamiento del lenguaje natural en la vida cotidiana.
La PNL es un componente de la IA que se centra en la comprensión del lenguaje humano escrito y/o hablado. Para ello, se desarrollan programas informáticos específicos; un ordenador típico requiere que las instrucciones se transmitan en un lenguaje de programación muy preciso, marcado, estructurado y sin ambigüedades. Por desgracia, el lenguaje humano natural es impreciso, equívoco y confuso. Para que un programa comprenda el significado de las palabras, es necesario utilizar algoritmos capaces de analizar el significado y la estructura para hacer comprensibles las palabras, reconocer determinadas referencias y, a continuación, generar el lenguaje.
Los algoritmos de PNL realizan diversos análisis sintácticos y semánticos para evaluar el significado de las frases basándose en reglas gramaticales. Para ello
Entre las técnicas habituales de PNL se incluyen:
La PNL se utiliza en una gran variedad de aplicaciones. Éstas son algunas de las zonas más comunes.
Los filtros de mensajería son una de las primeras aplicaciones básicas de procesamiento del lenguaje natural en línea. La técnica se utilizó por primera vez para crear filtros de spam que identificaran los mensajes no deseados basándose en determinadas palabras o frases. A medida que evolucionaba el procesamiento del lenguaje natural, también lo hacían los filtros.
Una de las aplicaciones más comunes y recientes de esta técnica es la clasificación de correos electrónicos de Gmail. Este sistema puede clasificar un correo electrónico en tres categorías (Principal, Redes Sociales o Promociones) en función de su contenido. Esto permite a los usuarios de Gmail gestionar mejor sus bandejas de entrada para ver y responder rápidamente a los correos importantes.
Los asistentes inteligentes como Siri (Apple) y Alexa (Amazon) utilizan el reconocimiento de voz para identificar patrones de habla, inferir significados y sugerir una respuesta útil. Hoy en día, parece normal hacer una pregunta a Siri y que ella nos entienda y responda de forma pertinente. Del mismo modo, nos estamos acostumbrando a interactuar a diario con Siri o Alexa a través de nuestro termostato, luces, coche, etc.
Ahora esperamos que asistentes como Alexa y Siri capten señales contextuales para ayudarnos en nuestra vida cotidiana y realizar determinadas tareas (por ejemplo, pedir artículos). Incluso disfrutamos con sus respuestas divertidas o cuando nos hablan de sí mismos. Nuestras interacciones se vuelven más personales a medida que nos van conociendo. Según el artículo del New York Times Why We May Soon Be Living in Alexa's World, "Se avecina un cambio importante. Lo más probable es que Alexa se convierta en la tercera gran plataforma de consumo de esta década".
Los motores de búsqueda utilizan el procesamiento del lenguaje natural para mostrar resultados relevantes basados en comportamientos de búsqueda similares o en la intención del usuario. Esto permite que todo el mundo encuentre lo que necesita sin tener ninguna habilidad especial.
Por ejemplo, cuando empiezas a escribir una consulta, Google te muestra búsquedas populares relacionadas, pero también puede reconocer el significado general de tu consulta más allá de la redacción exacta. Si tecleas un número de vuelo en Google, sabrás su estado. Obtendrás un informe bursátil si tecleas un símbolo bursátil. Si tecleas una ecuación matemática, aparecerá una calculadora. Tu búsqueda puede ofrecer una variedad de resultados porque la técnica de procesamiento del lenguaje natural que utiliza asocia una consulta ambigua con una entidad determinada para ofrecer resultados útiles.
Funciones como autocorrección, autocompletar e introducción intuitiva son tan comunes hoy en día en nuestros teléfonos inteligentes que las damos por sentadas. La autoescritura y la escritura intuitiva son comparables a los motores de búsqueda en el sentido de que se basan en lo que se escribe para sugerir el final de una palabra o frase. La autocorrección a veces incluso cambia algunas palabras para mejorar el significado general de tu mensaje.
Además, estas funciones evolucionan a medida que tú lo haces. Por ejemplo, la mecanografía intuitiva se adapta con el tiempo a tus giros específicos. Esto a veces da lugar a divertidos intercambios de mensajes, con frases basadas totalmente en la intuición. El resultado puede ser sorprendentemente personal e informativo, e incluso a veces ha atraído la atención de los medios de comunicación.
Si tu ejercicio de lengua extranjera está lleno de errores gramaticales, es probable que tu profesor sepa que has hecho trampas utilizando tecnología de procesamiento del lenguaje natural. Por desgracia, muchas lenguas no se prestan a la traducción directa porque tienen construcciones oracionales diferentes, que a veces han sido pasadas por alto por los servicios de traducción. Sin embargo, estos sistemas han avanzado mucho.
Gracias al procesamiento del lenguaje natural, las herramientas de traducción en línea ofrecen traducciones más precisas y gramaticalmente correctas. Por lo tanto, son extremadamente útiles si necesitas comunicarte con alguien que no habla tu idioma. Si necesitas traducir un texto extranjero, estas herramientas pueden incluso reconocer el idioma del texto introducido para su traducción.
Al llamar a algunas empresas, es probable que la mayoría de nosotros hayamos oído el anuncio "esta llamada puede ser grabada con fines de formación". Aunque estas grabaciones pueden utilizarse con fines de entrenamiento (por ejemplo, para analizar un intercambio con un cliente descontento), normalmente se almacenan en una base de datos que permite a un sistema de procesamiento del lenguaje natural aprender y crecer. Los sistemas automatizados redirigen las llamadas de los clientes a un agente o chatbot online, que les proporcionará información relevante para responder a sus peticiones. Esta técnica de procesamiento del lenguaje natural ya la utilizan muchas empresas, entre ellas los principales operadores telefónicos.
La tecnología de llamadas telefónicas digitales también permite que un ordenador imite la voz humana. Así, es posible planificar llamadas telefónicas automatizadas para concertar una cita en el taller o en la peluquería.
Las capacidades del lenguaje natural están ahora integradas en los flujos de trabajo analíticos. De hecho, cada vez más proveedores de BI ofrecen una interfaz de lenguaje natural para sus visualizaciones de datos. Una codificación visual más inteligente permite, por ejemplo, proponer la mejor visualización posible para una tarea concreta, en función de la semántica de los datos. Cualquiera puede explorar los datos mediante declaraciones en lenguaje natural o fragmentos de preguntas cuyas palabras clave se interpretan y comprenden.
Explorar los datos mediante el lenguaje los hace más accesibles y abre la analítica a toda la empresa, más allá del círculo habitual de analistas y desarrolladores informáticos.
El análisis de textos convierte los datos textuales no estructurados en datos analizables mediante diversas técnicas lingüísticas, estadísticas y de aprendizaje automático.
El análisis del sentimiento puede parecer un reto de enormes proporciones para las marcas (especialmente en el caso de una gran base de clientes). Sin embargo, una herramienta basada en el procesamiento del lenguaje natural normalmente puede examinar las interacciones de los clientes (como comentarios o reseñas en las redes sociales, o incluso menciones de nombres de marcas) para ver cuáles son. Después, las marcas pueden analizar estas interacciones para evaluar la eficacia de su campaña de marketing o seguir la evolución de los problemas de los clientes. Entonces pueden decidir cómo responder o mejorar su servicio para ofrecer una mejor experiencia.
El procesamiento del lenguaje natural también contribuye al análisis de texto extrayendo palabras clave e identificando patrones o tendencias en datos de texto no estructurados. ¿Cuáles son los principales modelos de PNL?
Aunque la PNL existe desde hace tiempo, los avances recientes han sido notables, sobre todo con el auge de los modelos basados en transformadores y los modelos lingüísticos a gran escala desarrollados por las principales empresas tecnológicas. Algunos de los modelos más avanzados son
Modelos basados en transformadores:
Grandes modelos lingüísticos (LLM):
En este tutorial, veremos más de cerca cómo se utiliza el BERT para la PNL.
BERT, del acrónimo "Bidirectional Encoder Representations from Transformers", es un modelo lanzado por Google AI. Esta técnica innovadora se basa en el procesamiento del lenguaje natural (PLN).
El algoritmo utiliza esencialmente el aprendizaje automático y la inteligencia artificial para comprender las consultas realizadas por los internautas. Así, intenta interpretar sus intenciones de búsqueda, es decir, el lenguaje natural que utilizan.
En este sentido, el BERT se asocia a los asistentes de voz personales, como Google Home. La herramienta ya no se basa en cada palabra introducida por el usuario, sino que tiene en cuenta toda la expresión y el contexto en el que se sitúa. Esto se hace para afinar los resultados. Es más eficaz en el tratamiento de búsquedas complejas, independientemente del medio utilizado.
Más concretamente, el BERT permite al motor de búsqueda :
Para otras aplicaciones, el BERT se utiliza en :
Así, el impacto de Google BERT sería de aproximadamente un 10% en las consultas más largas, escritas de forma natural.
El procesamiento del lenguaje natural se centra en el análisis de las palabras tecleadas por el usuario. Se examinan la palabra clave, sus predecesoras y sus sucesoras para comprender mejor la consulta. Éste es el principio de análisis que adoptan los "transformadores".
El algoritmo es especialmente eficaz para las búsquedas de cola larga, en las que las preposiciones influyen en el significado. En cambio, su impacto en las consultas genéricas es menos importante, puesto que Google ya las conoce bien. Por tanto, las demás herramientas de comprensión siguen funcionando.
Tanto si la consulta se formula de forma desordenada como precisa, el motor de búsqueda sigue siendo capaz de procesarla. Pero para mayor eficacia, es mejor utilizar términos más apropiados.
El contexto desempeña un papel importante en el análisis que realiza el BERT. Se optimizan la traducción automática y el modelado lingüístico. También se observan mejoras significativas en la generación de textos de calidad.
Para utilizar este modelo, primero vamos a importar las bibliotecas y paquetes necesarios, como se muestra aquí:
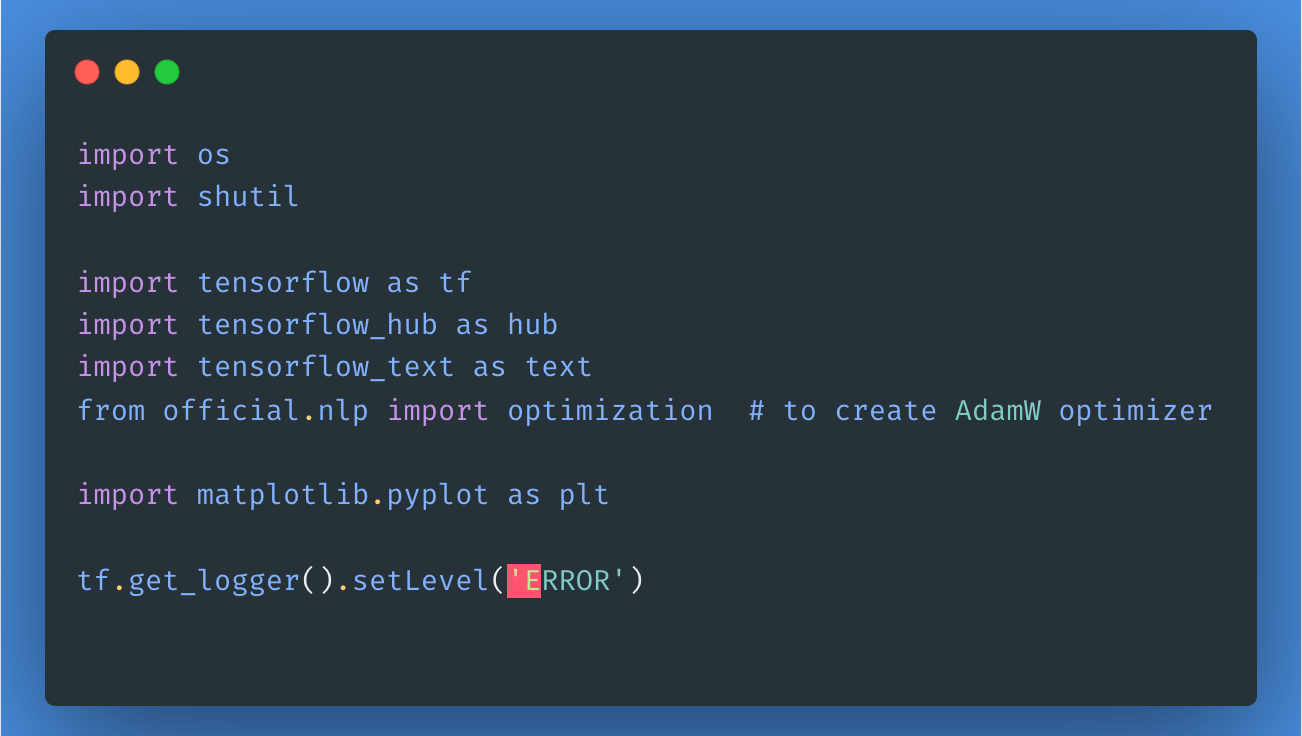
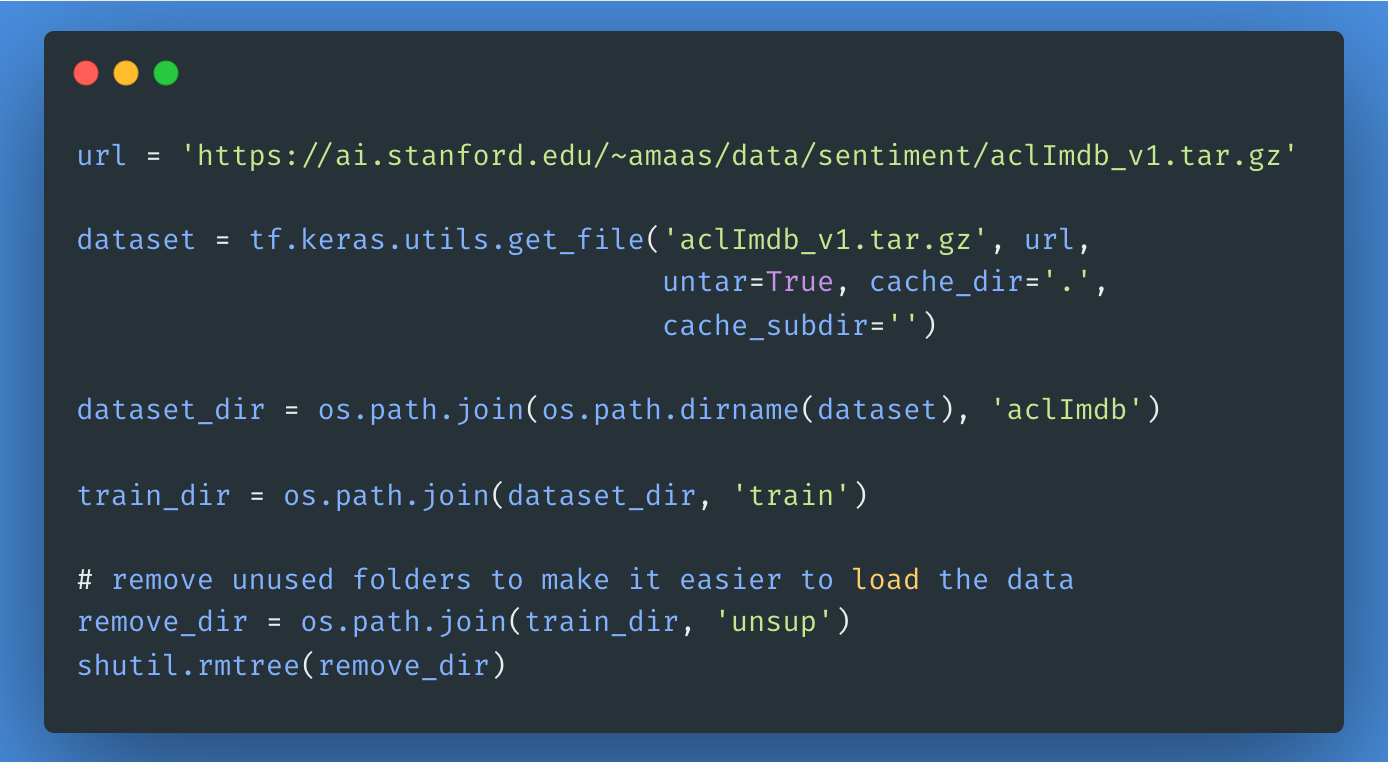
A continuación, descarguemos y extraigamos el Gran Conjunto de Datos de Críticas de Películas, y luego exploremos la estructura del directorio.
Para crear un tf.data.Dataset etiquetado utilizaremos el text_dataset_from_directory como se muestra a continuación. A continuación, crearemos un conjunto de validación utilizando una división 80:20 de los datos de entrenamiento mediante el argumento división_validación.
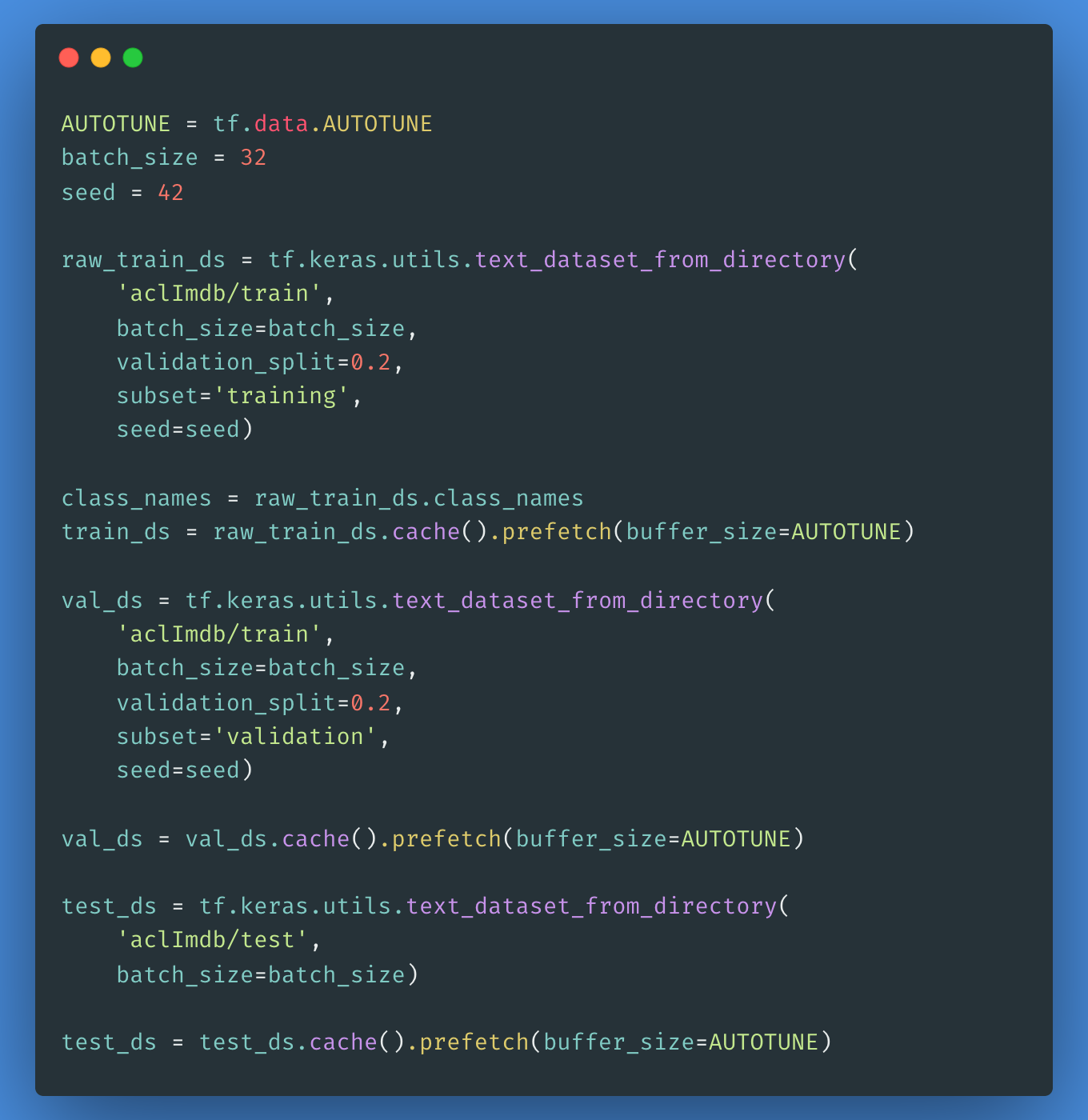
Es importante especificar una semilla aleatoria al utilizar validation_split para que las divisiones de validación y entrenamiento no se solapen.
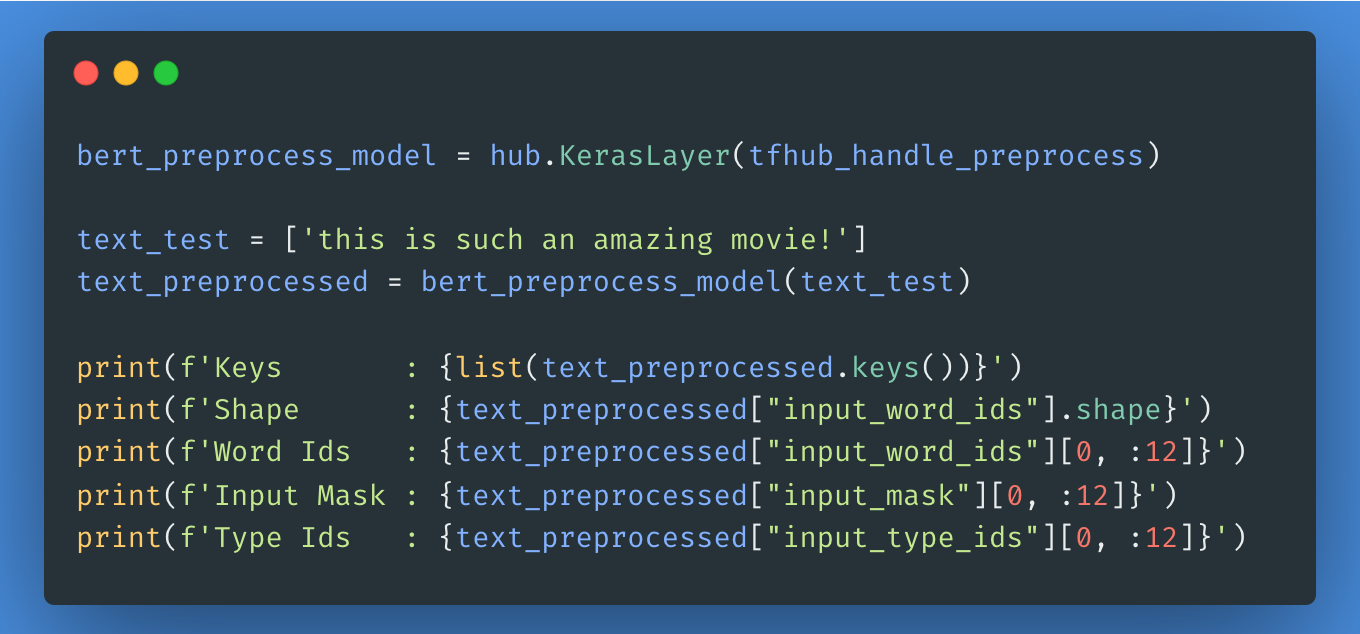
El siguiente paso será elegir qué modelo BERT quieres cargar y ajustar desde Tensorflow Hub, puedes utilizar hub.KerasLayer para componer tu modelo ajustado. A continuación, probaremos el modelo de preprocesamiento con algún texto y veremos el resultado.
A continuación, construirás un modelo sencillo compuesto por el modelo de preprocesamiento, el modelo BERT que seleccionaste en los pasos anteriores, una capa densa y una capa de abandono.
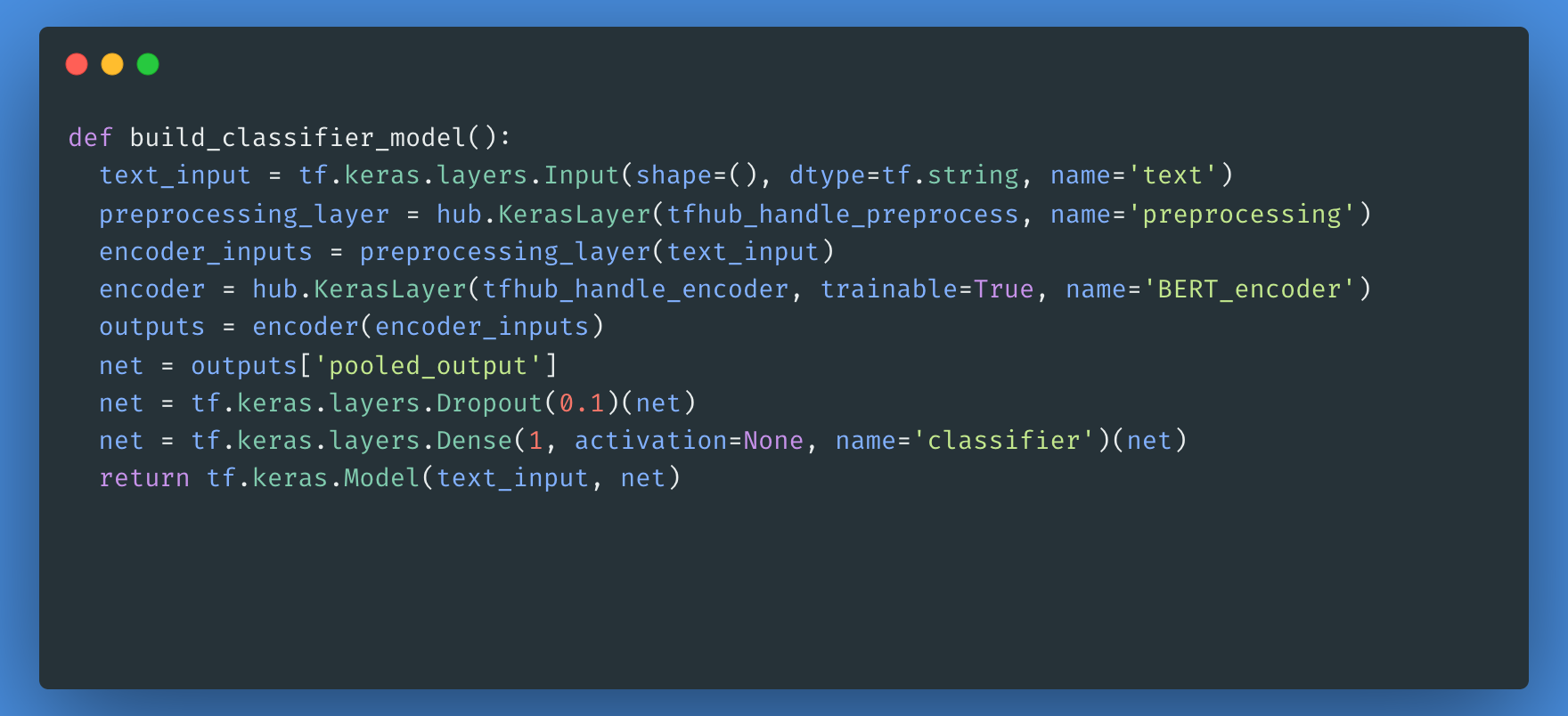
Ahora puedes comprobar si tu modelo funciona con la salida del modelo de preprocesamiento.

La función de pérdida es un paso necesario aquí, optaremos por la función de pérdida losses.BinaryCrossentropy ya que se trata de un problema de clasificación binaria.

Para el ajuste fino, vamos a utilizar el mismo optimizador con el que se entrenó originalmente el BERT: los "Momentos Adaptativos" (Adam). Este optimizador minimiza la pérdida de predicción y realiza la regularización por decaimiento del peso, lo que también se conoce como AdamW.

Utilizando el clasificador_modelo que creaste anteriormente, puedes compilar el modelo con la pérdida, la métrica y el optimizador.

Ten en cuenta que tu modelo puede tardar menos o más tiempo en entrenarse dependiendo de la complejidad del modelo BERT que hayas elegido.

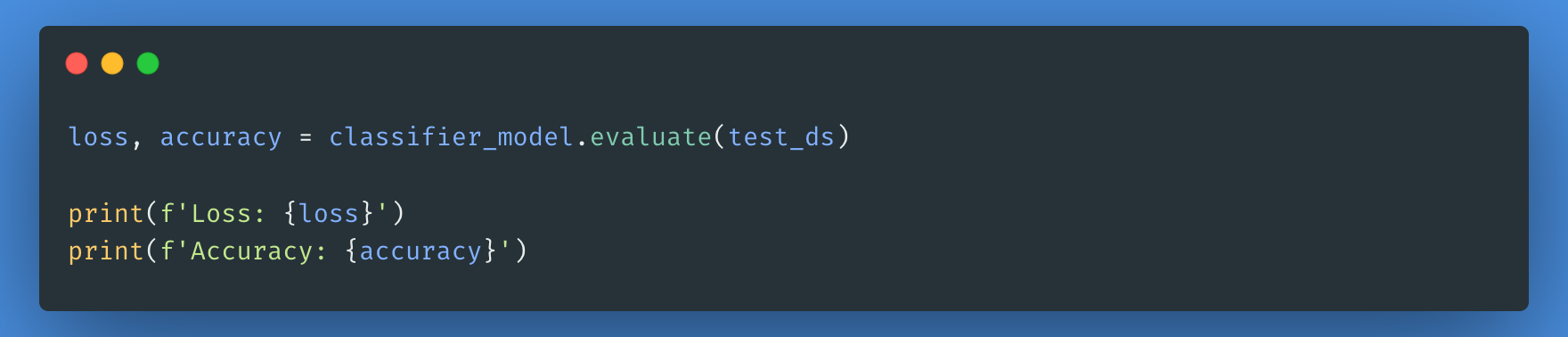
Ahora evaluaremos el rendimiento de nuestro modelo comprobando la pérdida y la precisión del modelo.
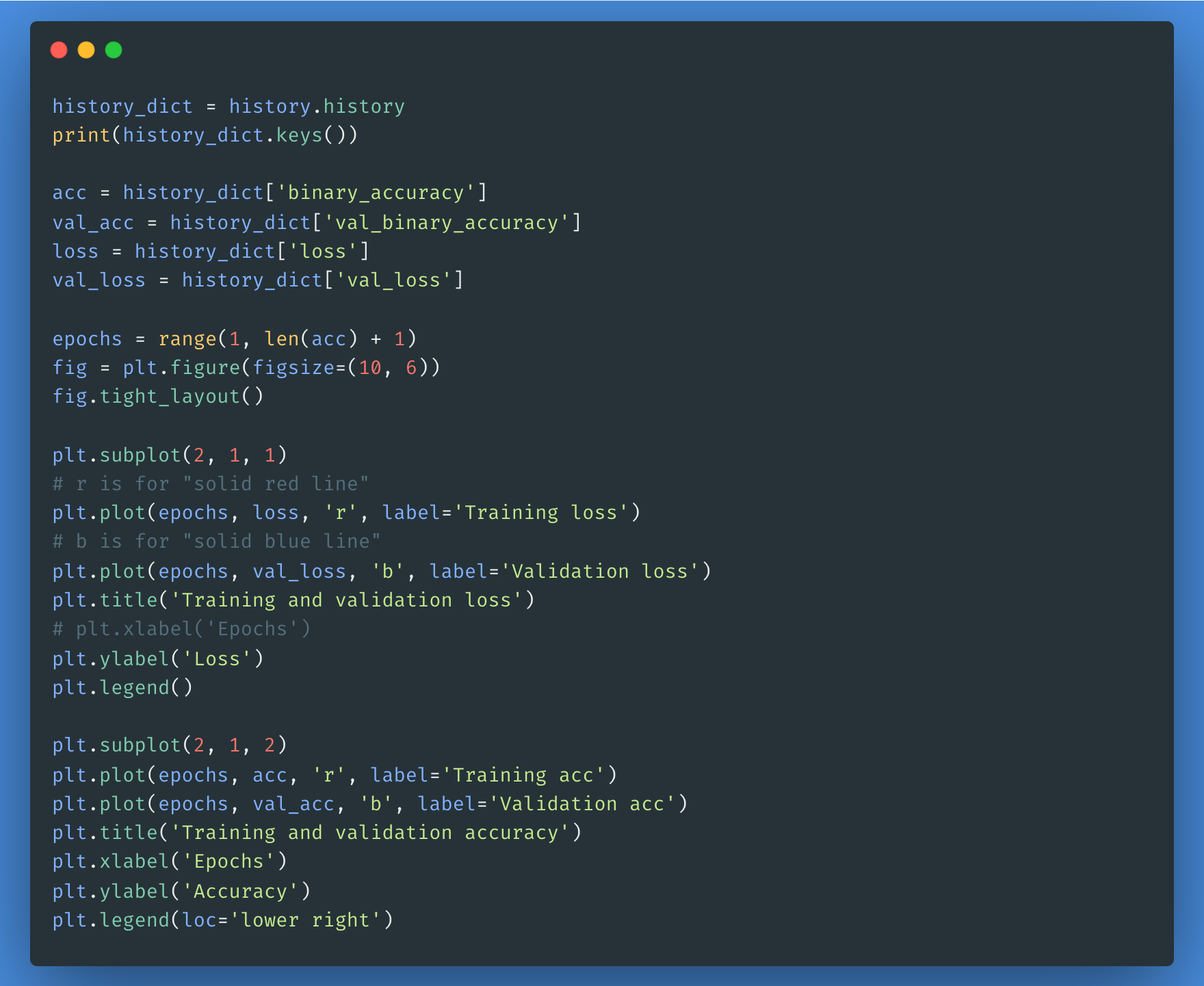
Puedes utilizar el objeto historial si quieres trazar las pérdidas y la precisión de los conjuntos de entrenamiento y validación:
Todos los pasos anteriores se detallan en este cuaderno. Puedes practicar los pasos anteriores y ejecutar el código para ver los resultados de cada modelo BERT de la lista.
El procesamiento del lenguaje natural ya está bien establecido en el mundo digital. Sus aplicaciones se multiplicarán a medida que las empresas e industrias descubran sus ventajas y lo adopten. Aunque la intervención humana seguirá siendo esencial para los problemas de comunicación más complejos, el procesamiento del lenguaje natural será nuestro aliado cotidiano, gestionando y automatizando las tareas menores al principio y encargándose luego de las cada vez más complejas a medida que avance la tecnología.
Para saber más sobre cómo funciona la PNL y cómo utilizarla, consulta nuestro curso de Aprendizaje Profundo para PNL en Python.
Aprende más sobre PNL con estos cursos
Curso
Curso
Curso
blog
Dimitri Didmanidze
7 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita

