Curso
Machine learning con modelos basados en árboles en Python
5 h
116.3K
Podría decirse que el aprendizaje automático es responsable de los casos de uso más destacados y visibles de la ciencia de datos y la inteligencia artificial. Desde los coches autoconducidos de Tesla hasta el algoritmo AlphaFold de DeepMind, las soluciones basadas en el aprendizaje automático han producido resultados asombrosos y han generado un gran revuelo. Pero, ¿qué es exactamente el aprendizaje automático? ¿Cómo funciona? Y lo más importante, ¿merece la pena tanto bombo? Este artículo ofrece una definición intuitiva de los principales algoritmos de aprendizaje automático, esboza algunas de sus principales aplicaciones y proporciona recursos para iniciarse en el aprendizaje automático.
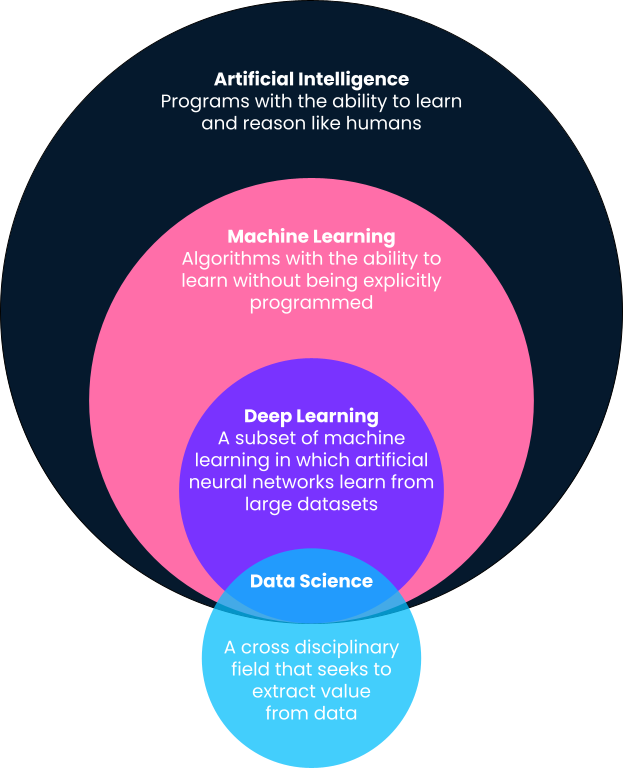
En pocas palabras, el aprendizaje automático es un subcampo de la inteligencia artificial en el que los ordenadores proporcionan predicciones basadas en patrones aprendidos directamente de los datos sin ser programados explícitamente para ello. Observarás en esta definición que el aprendizaje automático es un subcampo de la inteligencia artificial. Por ello, vamos a desglosar las definiciones con más detalle, ya que a menudo se utilizan indistintamente términos como aprendizaje automático, inteligencia artificial, aprendizaje profundo e incluso ciencia de datos.
Una de las mejores definiciones de inteligencia artificial procede de Andrew Ng, cofundador de Google Brain y antiguo Jefe Científico de Baidu. Según Andrew, la inteligencia artificial es un "enorme conjunto de herramientas para hacer que los ordenadores se comporten de forma inteligente". Esto puede incluir desde sistemas definidos explícitamente, como calculadoras, hasta soluciones basadas en el aprendizaje automático, como detectores de correo basura.
Como se ha señalado anteriormente, el aprendizaje automático es un subcampo de la inteligencia artificial en el que los algoritmos aprenden patrones a partir de datos históricos y proporcionan predicciones basadas en estos patrones aprendidos aplicándolos a nuevos datos. Tradicionalmente, los sistemas inteligentes sencillos, como las calculadoras, son programados explícitamente por los desarrolladores como pasos y procedimientos claramente definidos (es decir, si esto, entonces aquello). Sin embargo, esto no es escalable ni posible para problemas más avanzados.
Tomemos el ejemplo de los filtros de spam del correo electrónico. Los desarrolladores pueden intentar crear filtros de spam definiéndolos explícitamente. Por ejemplo, pueden definir un programa que active un filtro antispam si un correo electrónico tiene un asunto determinado o contiene ciertos enlaces. Sin embargo, este sistema resultará ineficaz en cuanto los spammers cambien de táctica.
Por otro lado, una solución basada en el aprendizaje automático tomará millones de correos spam como datos de entrada, aprenderá las características más comunes de los correos spam mediante asociación estadística, y hará predicciones sobre futuros correos basándose en las características aprendidas.
El aprendizaje profundo es un subcampo del aprendizaje automático y es probablemente el responsable de los casos de uso del aprendizaje automático más visibles de la cultura popular. Los algoritmos de aprendizaje profundo se inspiran en la estructura del cerebro humano y requieren cantidades increíbles de datos para su entrenamiento. A menudo se utilizan para los problemas "cognitivos" más complejos, como la detección del habla, la traducción de idiomas, los coches autoconducidos, etc. Consulta nuestra comparación entre aprendizaje profundo y aprendizaje automático para obtener más contexto.
A diferencia del aprendizaje automático, la inteligencia artificial y el aprendizaje profundo, la ciencia de datos tiene una definición bastante amplia. En pocas palabras, la ciencia de datos consiste en extraer valor y conocimientos de los datos. Ese valor puede ser en forma de modelos predictivos que utilicen el aprendizaje automático, pero también puede significar hacer aflorar las percepciones con un cuadro de mandos o un informe. Lee más sobre las tareas diarias de los científicos de datos en este artículo.
Aparte de la detección de spam por correo electrónico, algunas de las aplicaciones de aprendizaje automático más conocidas son la segmentación de clientes basada en datos demográficos (ventas y marketing), la predicción del precio de las acciones (finanzas), la automatización de la aprobación de reclamaciones (seguros), las recomendaciones de contenidos basadas en el historial de visionado (medios de comunicación y entretenimiento), y muchas más. El aprendizaje automático se ha hecho omnipresente y encuentra variadas aplicaciones en nuestra vida cotidiana.
Al final de este artículo, compartiremos muchos recursos para iniciarte en el aprendizaje automático.
Ahora que hemos dado una visión general del aprendizaje automático y de dónde encaja dentro de otras palabras de moda que puedes encontrar en este espacio, echemos un vistazo más profundo a los diferentes tipos de algoritmos de aprendizaje automático. Los algoritmos de aprendizaje automático se clasifican a grandes rasgos en aprendizaje supervisado, no supervisado, de refuerzo y autosupervisado. Entendámoslos con más detalle y sus casos de uso más comunes.
La mayoría de los casos de uso del aprendizaje automático giran en torno a algoritmos que aprenden patrones a partir de datos históricos y los aplican a nuevos datos en forma de predicciones. A menudo se denomina aprendizaje supervisado. A los algoritmos de aprendizaje supervisado se les muestran tanto las entradas como las salidas históricas de un problema concreto que intentamos resolver, donde las entradas son esencialmente características o dimensiones de la observación que intentamos predecir, y donde las salidas son los resultados que queremos predecir. Ilustrémoslo con nuestro ejemplo de detección de spam.
En el caso de uso de la detección de spam, se entrenaría un algoritmo de aprendizaje supervisado con un conjunto de datos de correos spam. Las entradas serían características o dimensiones de los correos electrónicos, como el asunto del correo electrónico, la dirección de correo electrónico del remitente, el contenido del correo electrónico, si el correo electrónico contenía enlaces de aspecto peligroso y otra información relevante que pudiera dar pistas sobre si un correo electrónico es spam.
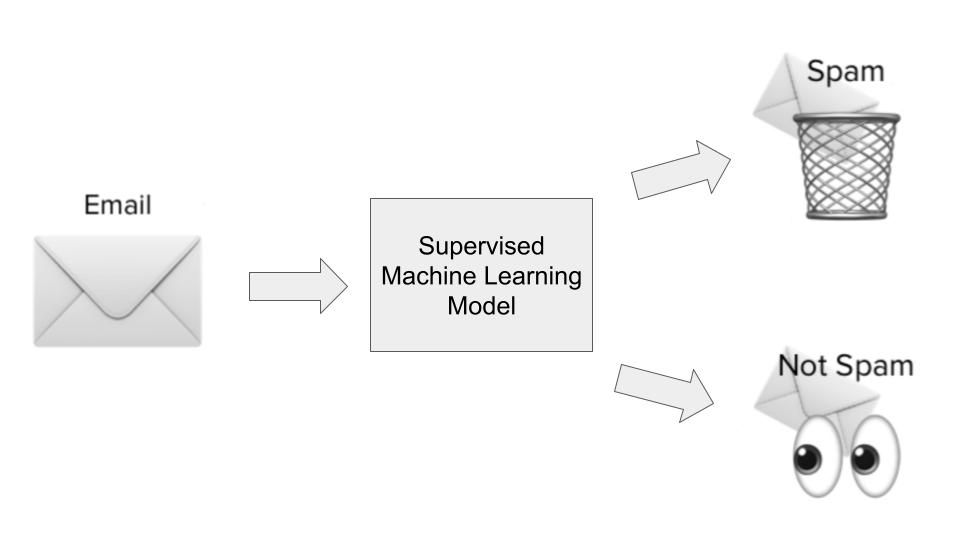
El resultado sería si, efectivamente, ese correo electrónico era spam o no. Durante la fase de aprendizaje del modelo, el algoritmo aprende una función para mapear la relación estadística entre el conjunto de variables de entrada (las distintas dimensiones del correo spam) y la variable de salida (si era spam o no). Este mapeo funcional se utiliza entonces para predecir la salida de los datos no vistos anteriormente.
A grandes rasgos, hay dos tipos de casos de uso del aprendizaje supervisado:
En una próxima sección, examinaremos con más detalle algoritmos específicos de aprendizaje supervisado y algunos de sus casos de uso.
En lugar de aprender patrones que asignan entradas a salidas, los algoritmos de aprendizaje no supervisado descubren patrones generales en los datos sin que se les muestren explícitamente las salidas. Los algoritmos de aprendizaje no supervisado se utilizan habitualmente para agrupar y agrupar diferentes objetos y entidades. Un gran ejemplo de aprendizaje no supervisado es la segmentación de clientes. Las empresas suelen tener una variedad de clientes a los que sirven. A menudo, las organizaciones quieren tener un enfoque basado en hechos para identificar a sus segmentos de clientes y atenderlos mejor. Entra en el aprendizaje no supervisado.
En este caso de uso, un algoritmo de aprendizaje no supervisado aprendería a agrupar a los clientes en función de varios atributos, como el número de veces que utilizaron un producto, sus datos demográficos, cómo interactúan con los productos, etc. Luego, el mismo algoritmo puede predecir a qué segmento probable pertenecen los nuevos clientes basándose en las mismas dimensiones.
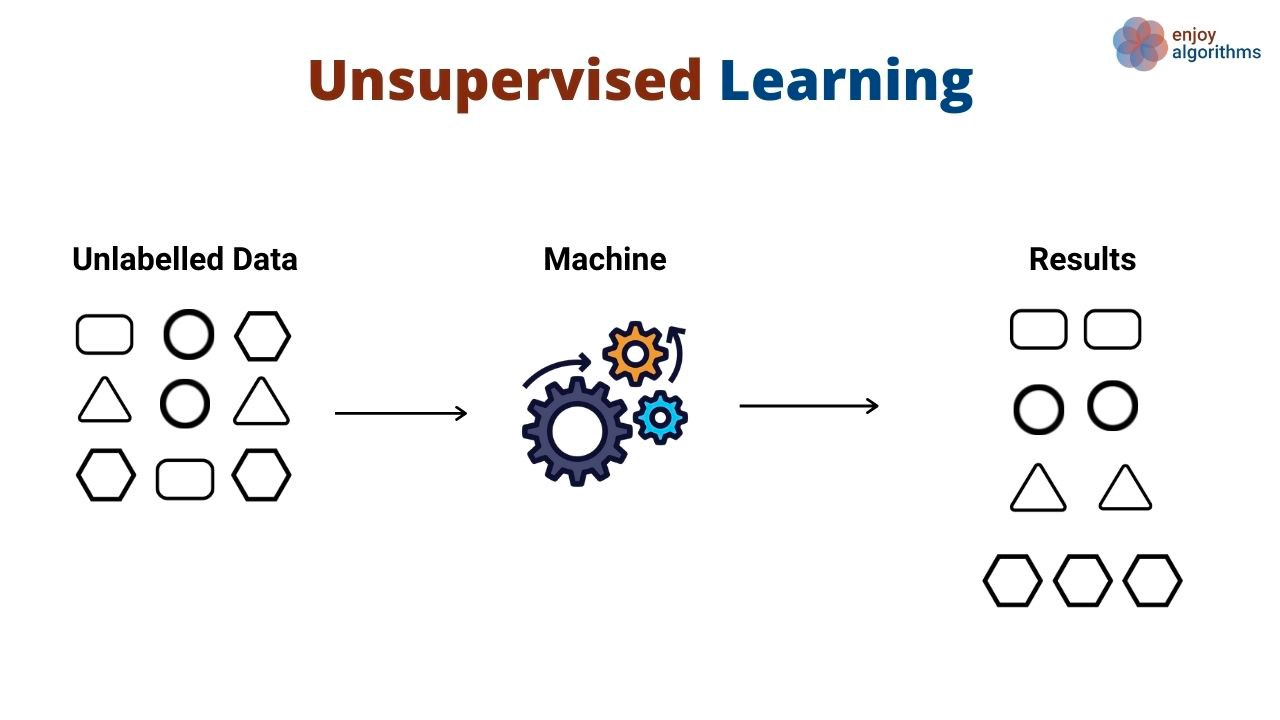
Los algoritmos no supervisados también se utilizan para reducir las dimensiones de un conjunto de datos (es decir, el número de características) mediante técnicas de reducción de la dimensionalidad. Estos algoritmos suelen utilizarse como paso intermedio en el entrenamiento de un algoritmo de aprendizaje supervisado.
Una gran disyuntiva a la que se enfrentan a menudo los científicos de datos cuando entrenan algoritmos de aprendizaje automático es el rendimiento frente a la precisión predictiva. En general, cuanta más información tengan sobre un problema concreto, mejor. Sin embargo, eso también podría provocar tiempos de entrenamiento y rendimiento lentos. Las técnicas de reducción de la dimensionalidad ayudan a reducir el número de características presentes en un conjunto de datos sin sacrificar el valor predictivo.
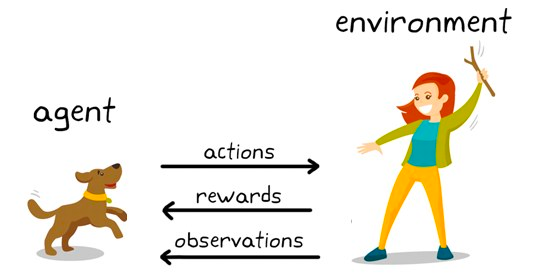
El aprendizaje por refuerzo es un subconjunto de algoritmos de aprendizaje automático que utilizan recompensas para promover un comportamiento o predicción deseados y una penalización en caso contrario. Aunque sigue siendo relativamente un área de investigación dentro del aprendizaje automático, el aprendizaje por refuerzo es responsable de algoritmos que superan la inteligencia humana en juegos como el ajedrez, el Go y otros.
Es una técnica de modelado conductual en la que el modelo aprende mediante un mecanismo de ensayo y error a medida que sigue interactuando con el entorno. Ilustrémoslo con el ejemplo del ajedrez. A alto nivel, a un algoritmo de aprendizaje por refuerzo (a menudo denominado agente) se le proporciona un entorno (tablero de ajedrez) en el que puede tomar diversas decisiones (jugadas).
Cada movimiento tiene un conjunto de puntuaciones asociadas, una recompensa para las acciones que llevan al agente a ganar, y una penalización para los movimientos que llevan al agente a perder.
El agente sigue interactuando con el entorno para aprender las acciones que le reportan más recompensas y sigue repitiendo esas acciones. Esta repetición del comportamiento promovido se denomina fase de explotación. Cuando el agente busca nuevas vías para obtener recompensas, se denomina fase de exploración. En términos más generales, esto se denomina paradigma de exploración-explotación.
El aprendizaje autosupervisado es una técnica de aprendizaje automático eficiente en cuanto a datos, en la que el modelo aprende a partir de un conjunto de datos de muestra sin etiquetar. Como se muestra en el ejemplo siguiente, el primer modelo recibe algunas imágenes de entrada sin etiquetar, que agrupa utilizando características generadas a partir de esas imágenes.
Algunos de estos ejemplos tendrían una alta confianza de pertenecer a las agrupaciones, mientras que otros no. El segundo paso utiliza los datos etiquetados de alta confianza del primer paso para entrenar un clasificador que tiende a ser más potente que un enfoque de agrupación de un solo paso.
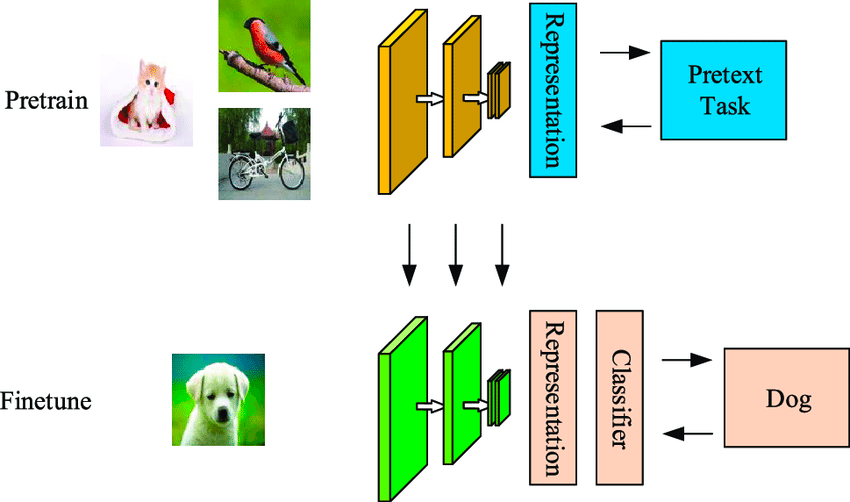
La diferencia entre los algoritmos autosupervisados y supervisados es que la salida clasificada en los primeros aún no tendrá las clases asignadas a objetos reales. Se diferencia del aprendizaje supervisado en que no depende del conjunto etiquetado manualmente y genera etiquetas por sí mismo, de ahí el nombre de autoaprendizaje.
A continuación, hemos esbozado algunos de los principales algoritmos de aprendizaje automático y sus casos de uso más comunes.
Un algoritmo simple modela una relación lineal entre una o varias variables explicativas y una variable numérica continua de salida. Es más rápido de entrenar que otros algoritmos de aprendizaje automático. Su mayor ventaja reside en la capacidad de explicar e interpretar las predicciones del modelo. Es un algoritmo de regresión utilizado para predecir resultados como el valor del ciclo de vida del cliente, el precio de la vivienda y el precio de las acciones.
Puedes aprender más sobre ello en este tutorial sobre los fundamentos de la regresión lineal en Python. Si te interesa ponerte manos a la obra con el análisis de regresión, este curso tan solicitado en DataCamp es el recurso adecuado para ti.
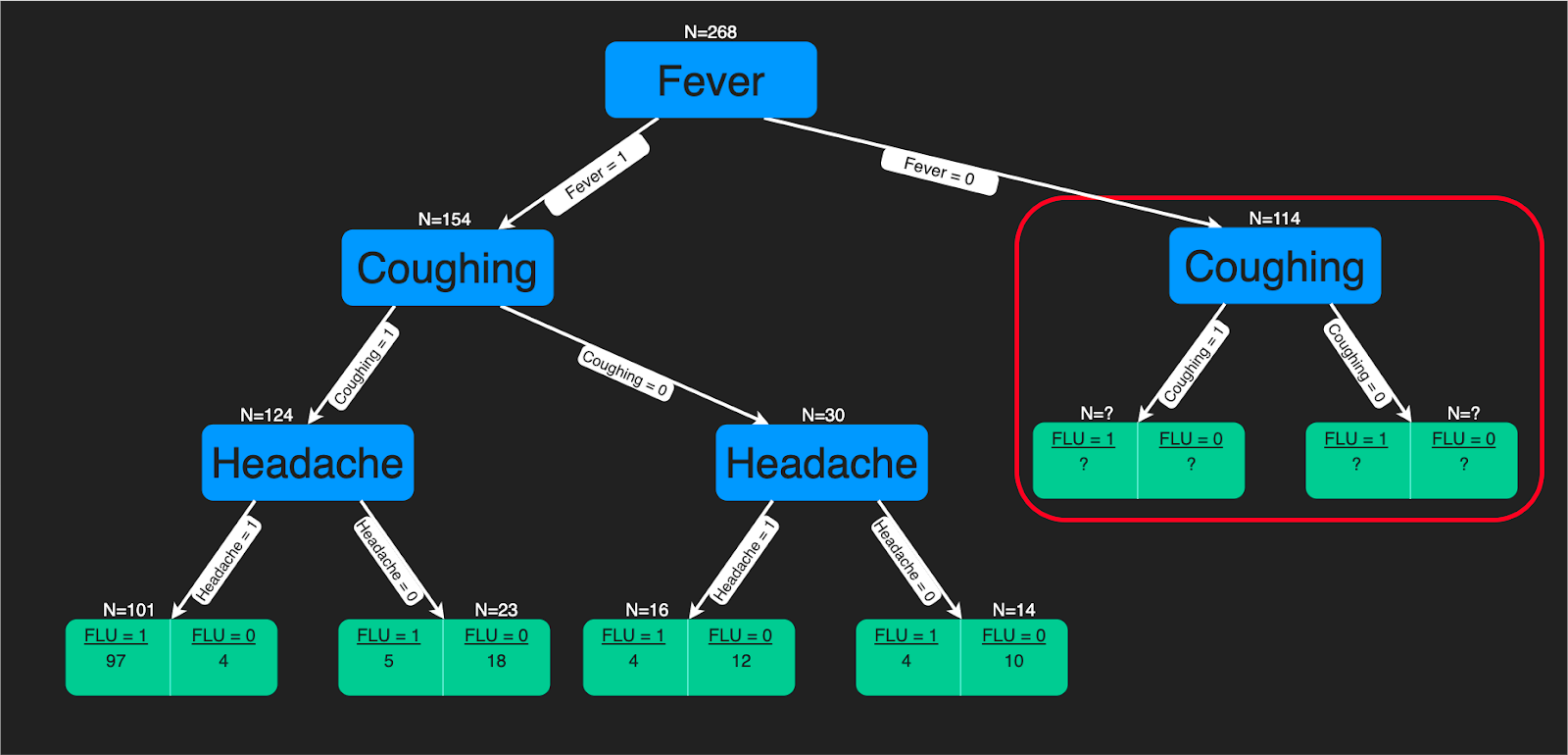
Un algoritmo de árbol de decisión es una estructura en forma de árbol de reglas de decisión que se aplican a las características de entrada para predecir los posibles resultados. Puede utilizarse para clasificación o regresión. Las predicciones de los árboles de decisión son una buena ayuda para los expertos sanitarios, ya que es sencillo interpretar cómo se hacen esas predicciones.
Puedes consultar este tutorial si te interesa aprender a construir un clasificador de árbol de decisión utilizando Python. Además, si te sientes más cómodo utilizando R, entonces te beneficiarás de este tutorial. También hay un curso completo sobre árboles de decisión en DataCamp.
Podría decirse que es uno de los algoritmos más populares y se basa en los inconvenientes del sobreajuste que se observan de forma prominente en los modelos de árbol de decisión. La sobreadaptación se produce cuando los algoritmos se entrenan con los datos de entrenamiento demasiado bien, y cuando no consiguen generalizar o proporcionar predicciones precisas sobre datos no vistos. El bosque aleatorio resuelve el problema del sobreajuste construyendo múltiples árboles de decisión sobre muestras seleccionadas aleatoriamente de los datos. El resultado final en forma de la mejor predicción se obtiene de la votación por mayoría de todos los árboles del bosque.
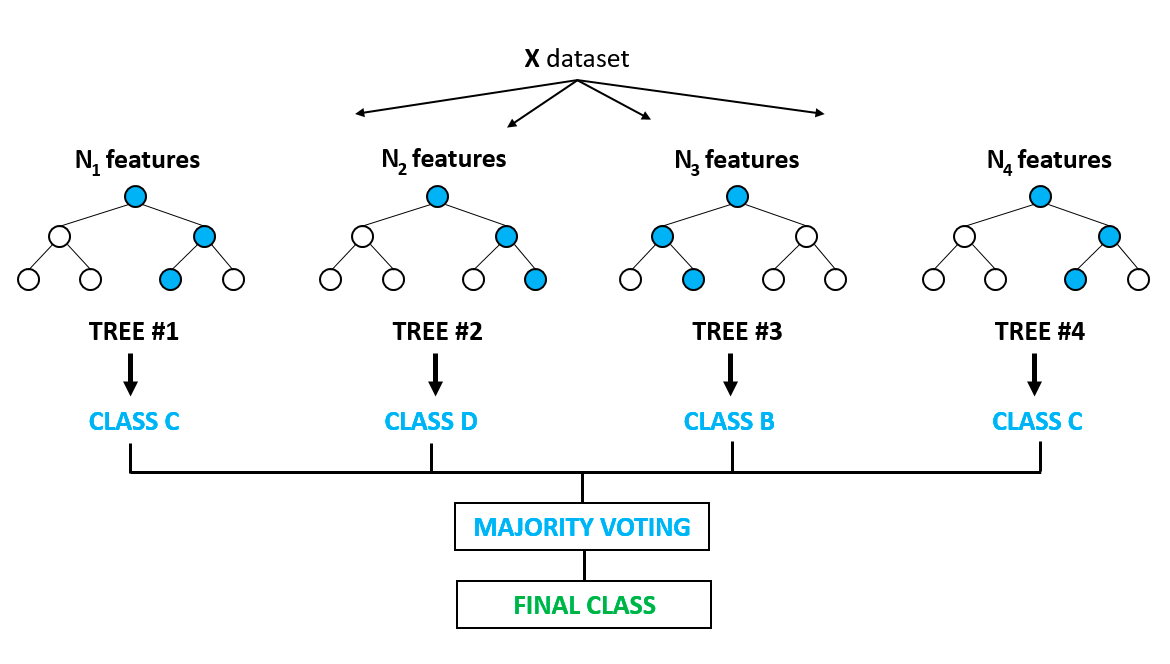
Se utiliza tanto para problemas de clasificación como de regresión. Tiene aplicación en la selección de rasgos, la detección de enfermedades, etc. Puedes aprender más sobre modelos basados en árboles y conjuntos (que combinan diferentes modelos individuales) en este curso muy popular de DataCamp. También puedes aprender más en este tutorial basado en Python sobre la implementación del modelo de bosque aleatorio.
Las Máquinas de Vectores Soporte, comúnmente conocidas como SVM, se utilizan generalmente para problemas de clasificación. Como se muestra en el ejemplo siguiente, una SVM encuentra un hiperplano (línea en este caso), que segrega las dos clases (rojo y verde) y maximiza el margen (distancia entre las líneas de puntos) entre ellas.
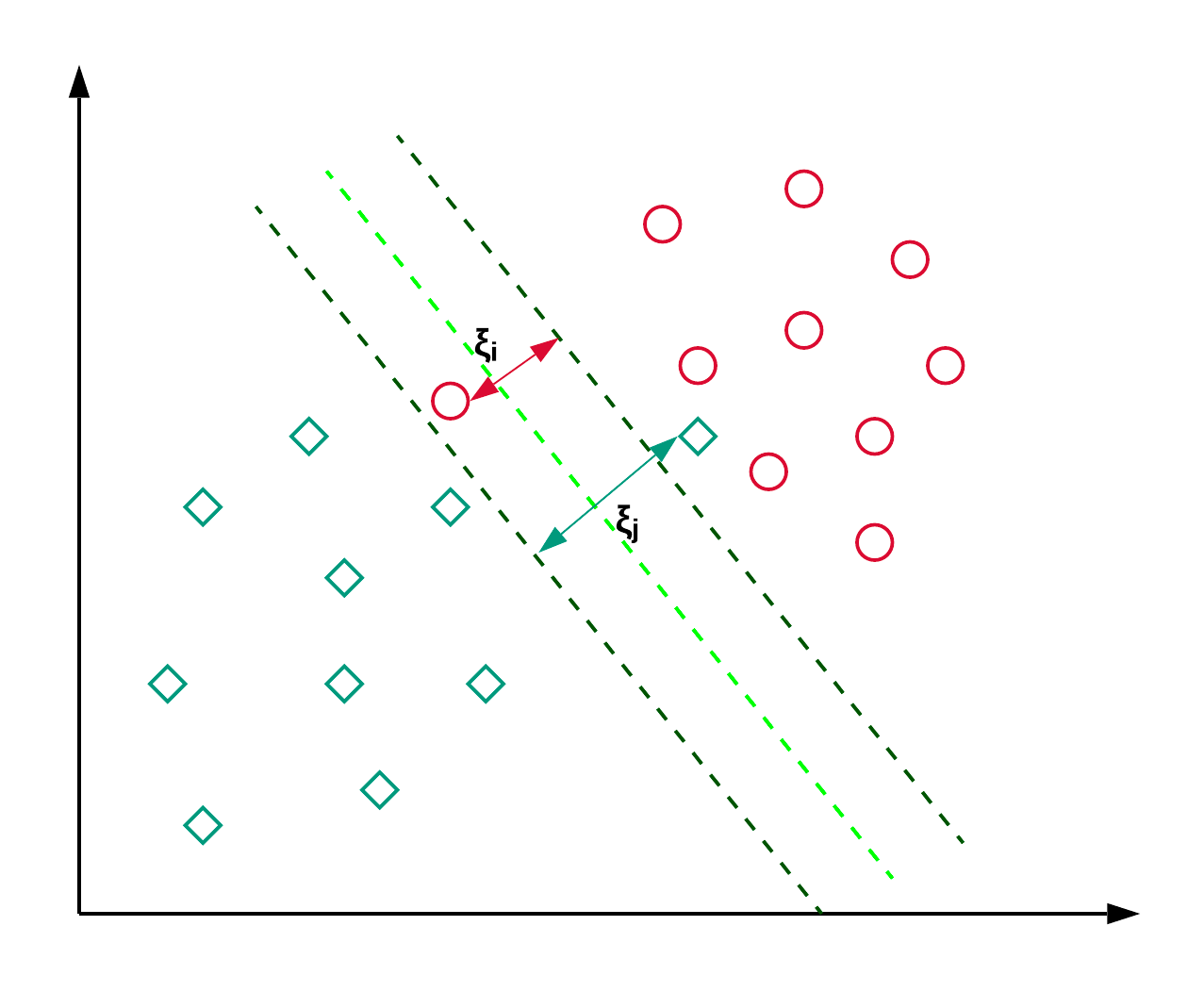
La SVM se utiliza generalmente para problemas de clasificación, pero también puede emplearse en problemas de regresión. Se utiliza para clasificar artículos de noticias y reconocimiento de escritura. Puedes leer más sobre los diferentes tipos de trucos de kernel junto con la implementación en python en este tutorial de SVM de scikit-learn. También puedes seguir este tutorial, donde reproducirás la implementación de la SVM en R
La Regresión por Impulso Gradiente es un modelo conjunto que combina varios aprendices débiles para crear un modelo predictivo robusto. Es bueno para tratar las no linealidades de los datos y los problemas de multicolinealidad.
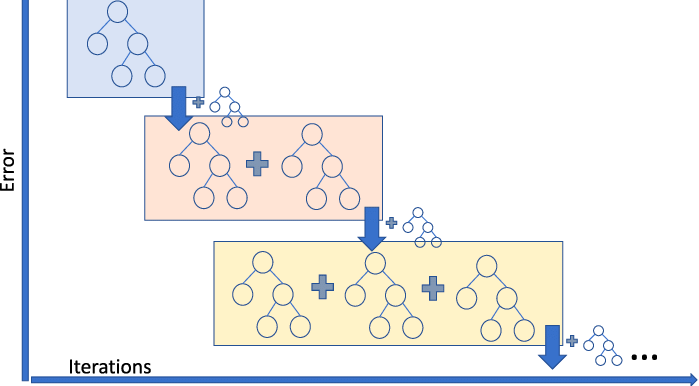
Si tienes un negocio de viajes compartidos y necesitas predecir el importe del viaje, puedes utilizar un regresor de aumento de gradiente. Si quieres entender los diferentes sabores del refuerzo de gradiente, puedes ver este vídeo en DataCamp.
K-Means es el enfoque de agrupación más utilizado: determina K grupos basándose en la distancia euclidiana. Es un algoritmo muy popular para la segmentación de clientes y los sistemas de recomendación.
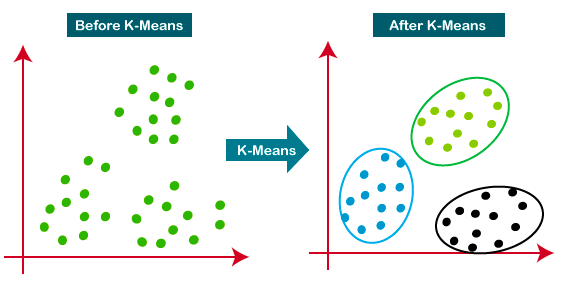
Este tutorial es un gran recurso para aprender más sobre la agrupación de K-means.
El análisis de componentes principales (ACP) es un procedimiento estadístico que se utiliza para resumir la información de un gran conjunto de datos proyectándola a un subespacio de menor dimensión. También se denomina técnica de reducción de la dimensionalidad, que garantiza la conservación de las partes esenciales de los datos con mayor información.
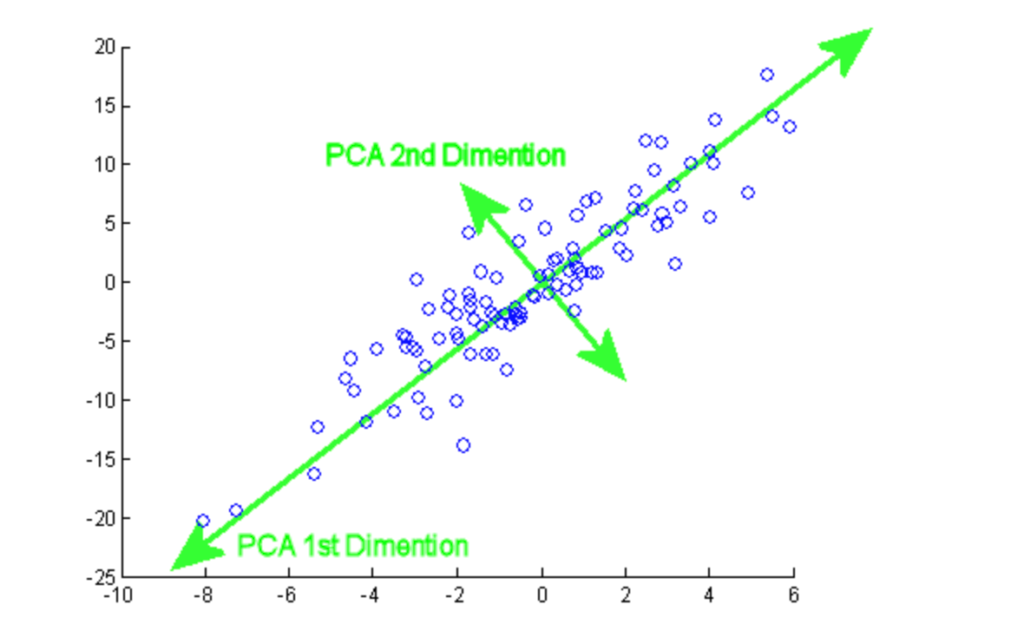
En este tutorial, puedes practicar la implementación práctica del PCA en dos conjuntos de datos populares, Cáncer de Mama y CIFAR-10.
Se trata de un enfoque ascendente en el que cada punto de datos se trata como su propio conglomerado, y luego los dos conglomerados más cercanos se fusionan de forma iterativa. Su mayor ventaja sobre la agrupación de K-medias es que no requiere que el usuario especifique el número previsto de conglomerados al principio. Encuentra aplicación en la agrupación de documentos basada en la similitud.
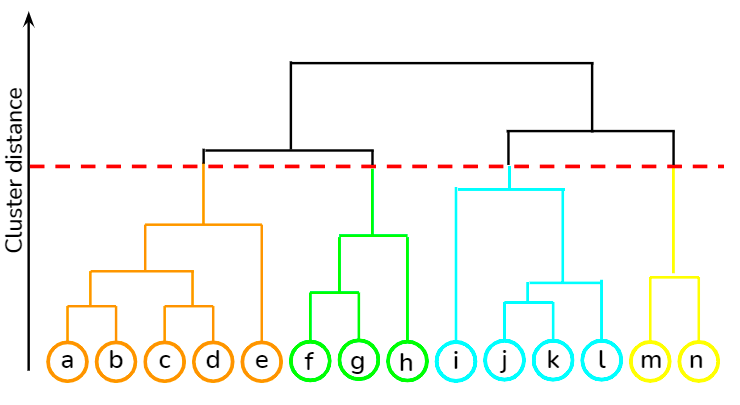
Puedes aprender varias técnicas de aprendizaje no supervisado, como la agrupación jerárquica y la agrupación de K-means, utilizando la biblioteca scipy desde este curso en DataCamp. Además, en este curso también puedes aprender a aplicar técnicas de agrupación para generar ideas a partir de datos no etiquetados utilizando R.
Es un modelo probabilístico para modelar conglomerados distribuidos normalmente dentro de un conjunto de datos. Se diferencia de los algoritmos de agrupación estándar en que estima la probabilidad de que una observación pertenezca a un determinado conglomerado y, a continuación, se sumerge en la realización de inferencias sobre su subpoblación.
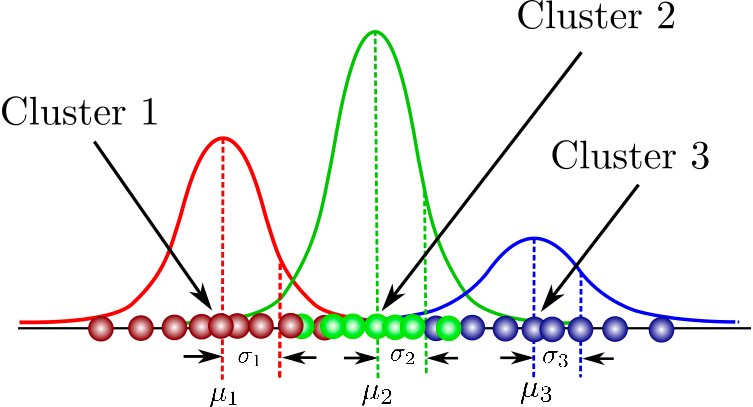
Aquí encontrarás una recopilación de cursos que abarca los conceptos fundamentales de la agrupación basada en modelos, la estructura de los Modelos de Mezcla y mucho más. También podrás practicar el modelado de mezclas gaussianas con el paquete flexmix.
Un enfoque basado en reglas que identifica el conjunto de elementos más frecuente en un conjunto de datos dado, en el que se utiliza el conocimiento previo de las propiedades de los conjuntos de elementos frecuentes. El análisis de la cesta de la compra emplea este algoritmo para ayudar a gigantes como Amazon y Netflix a traducir los montones de información sobre sus usuarios en sencillas reglas de recomendación de productos. Analiza las asociaciones entre millones de productos y descubre reglas reveladoras.
DataCamp ofrece un curso completo de ambos lenguajes: Python y R.
El aprendizaje automático ya no es sólo una palabra de moda. Muchas organizaciones están desplegando modelos de aprendizaje automático y ya están obteniendo beneficios de los conocimientos predictivos. Ni que decir tiene que hay mucha demanda de profesionales altamente cualificados en aprendizaje automático en el mercado. A continuación, encontrarás una lista de recursos que pueden iniciarte rápidamente en el perfeccionamiento de los conceptos del aprendizaje automático:
Empieza con el aprendizaje automático
Curso
Curso
blog
DataCamp Team
11 min
blog
Zoumana Keita
14 min
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Javier Canales Luna
8 min